↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Current trajectory prediction methods often struggle when dealing with incomplete or short observation data. This is a significant problem in real-world applications like autonomous driving, where immediate decisions are essential even with limited data. The lack of robust methods for handling these situations leads to inaccurate predictions and potentially dangerous outcomes.
The research introduces a new framework called LaKD (Length-agnostic Knowledge Distillation) that solves this problem. LaKD uses a novel dynamic knowledge distillation mechanism, transferring information between trajectories of different lengths to improve performance. It also incorporates a dynamic soft-masking technique to prevent conflicts when using a single model as both teacher and student. Experiments show LaKD significantly outperforms existing methods on various benchmark datasets. This demonstrates LaKD’s effectiveness and potential for significant impact in autonomous driving and related fields.
Key Takeaways#
Why does it matter?#
This paper is important because it addresses a critical challenge in trajectory prediction—handling varying lengths of observed data—which is common in real-world autonomous driving scenarios. The proposed LaKD framework offers a practical solution, improving the accuracy and reliability of prediction models, and its compatibility with existing models makes it highly valuable for researchers in the field.
Visual Insights#

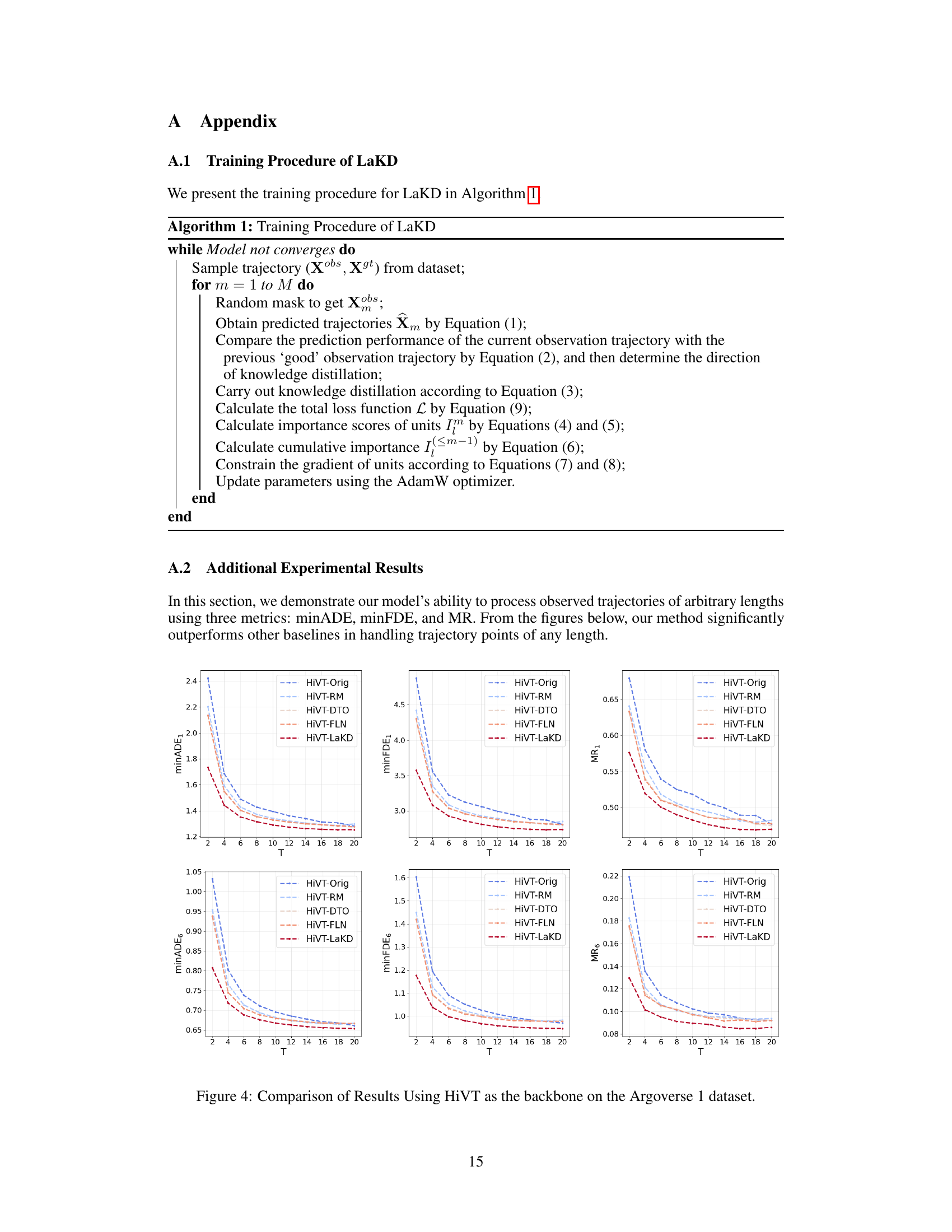
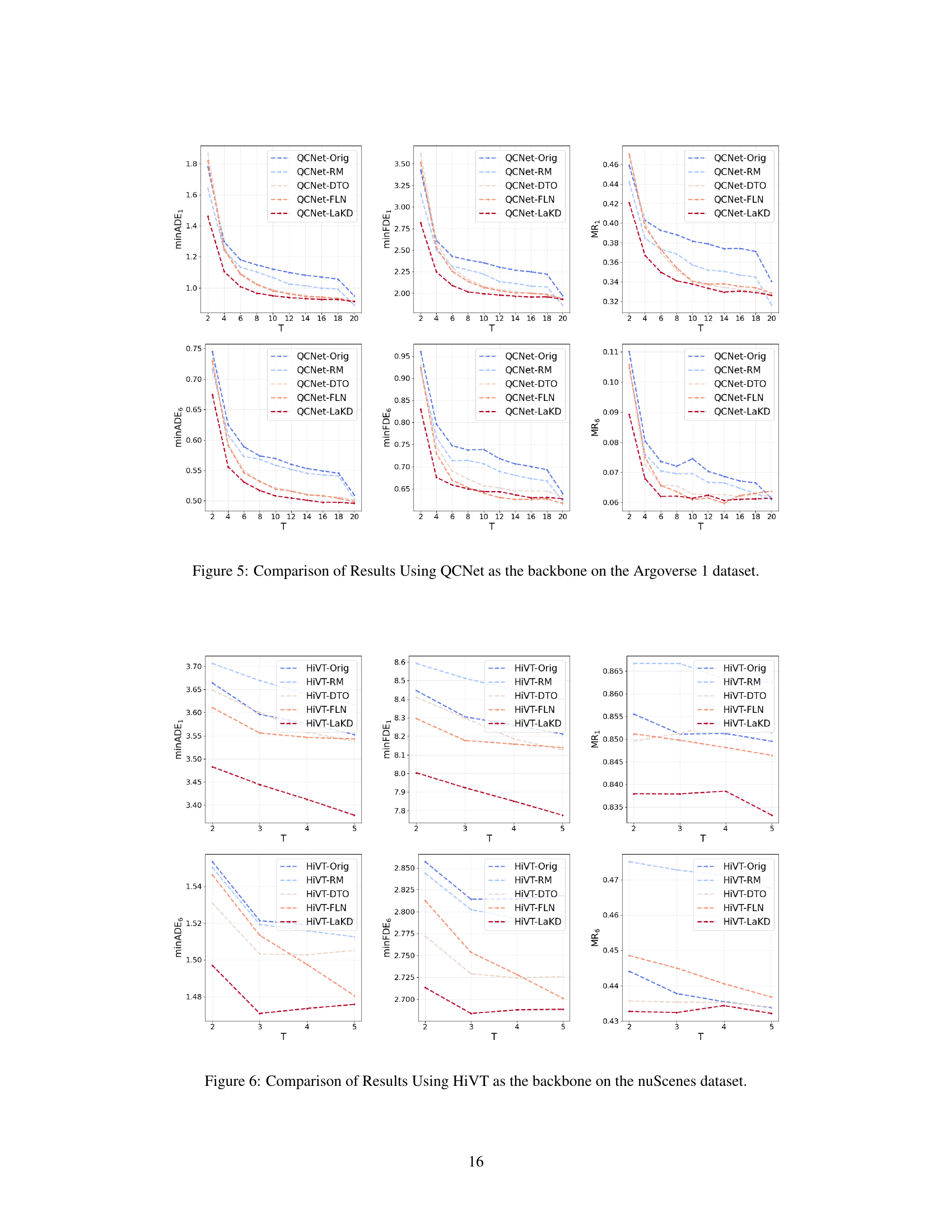
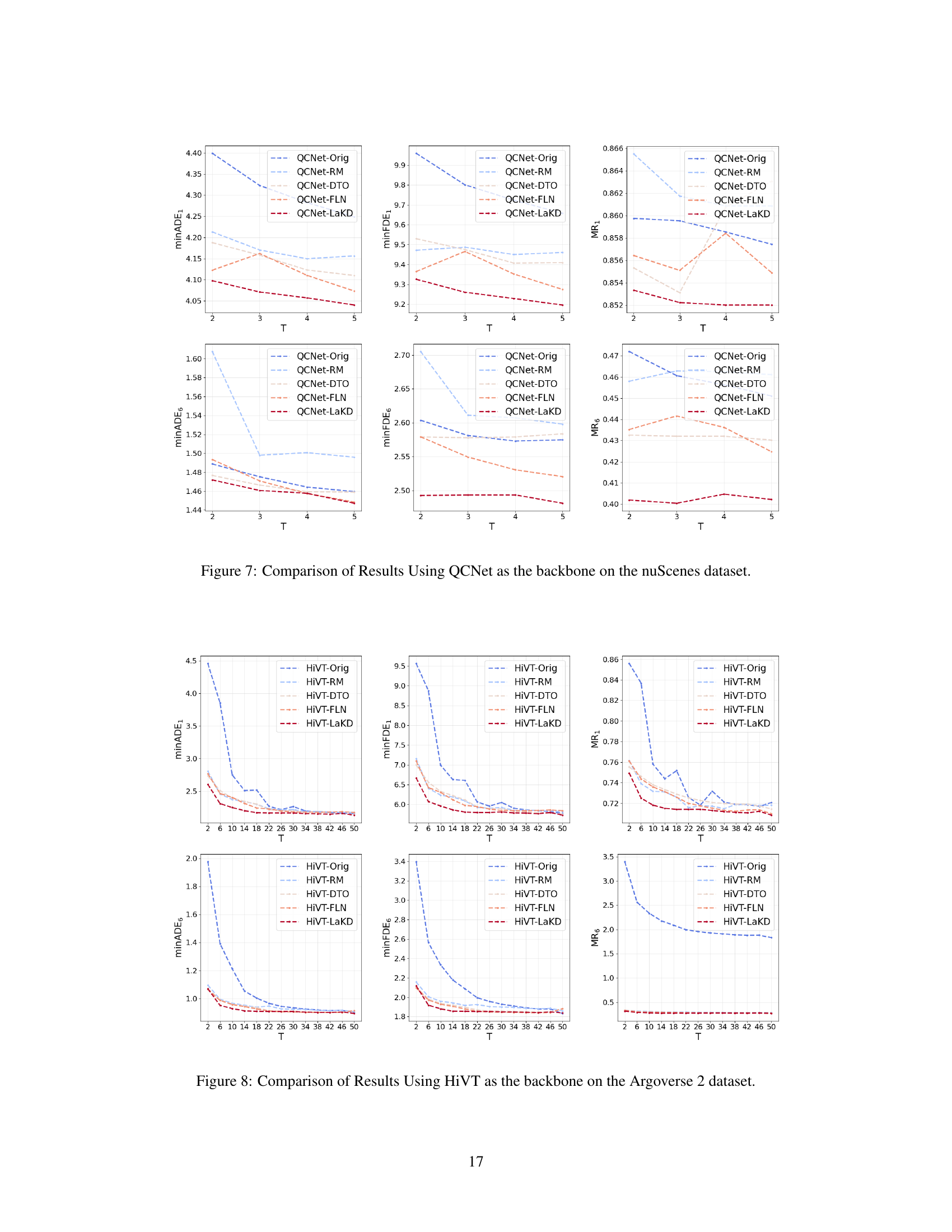
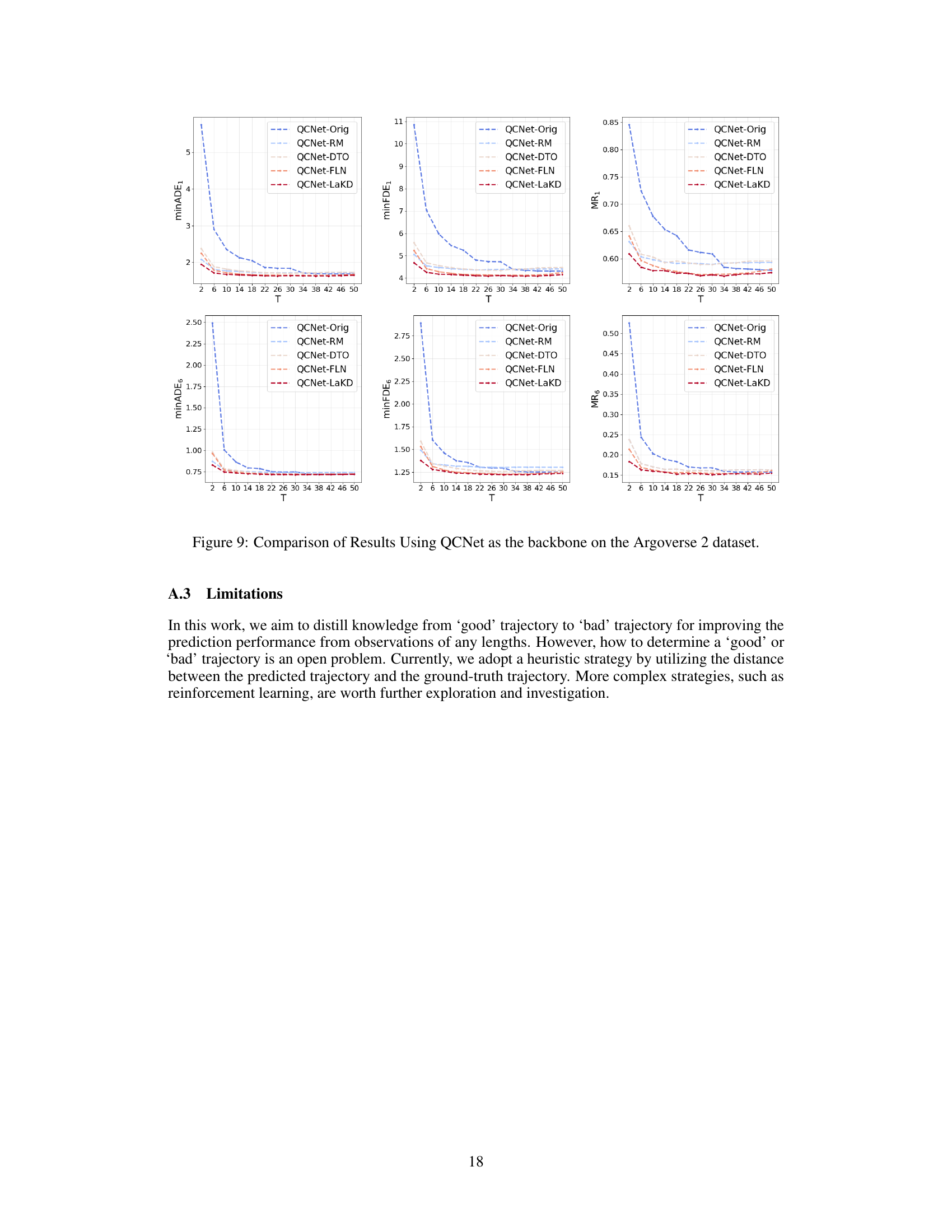
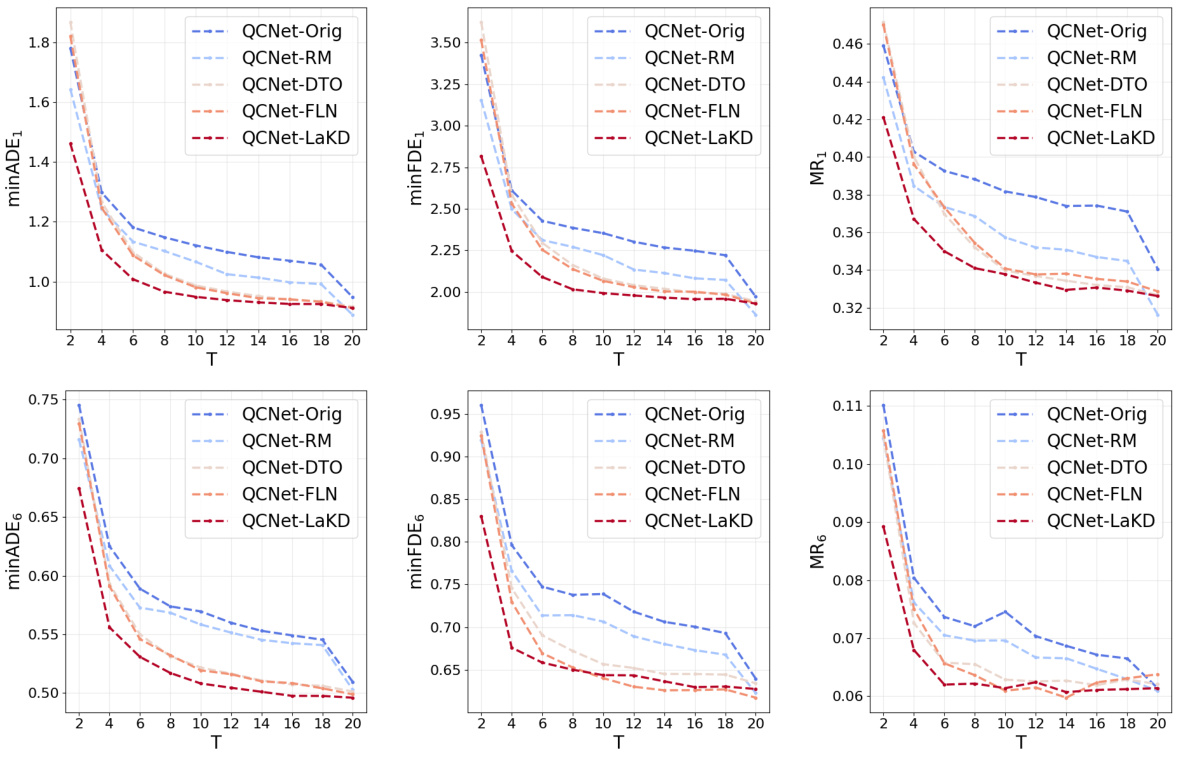
This figure compares the trajectory prediction performance of two models (HiVT and QCNet) using observed trajectories of varying lengths on two datasets (Argoverse 1 and Argoverse 2). Subfigures (a) and (b) show the model performance as a function of the length of the observed trajectory. Subfigures (c) and (d) illustrate scenarios where longer or shorter observed trajectories lead to better prediction accuracy, highlighting the challenges of using fixed-length trajectory observations in real-world scenarios.
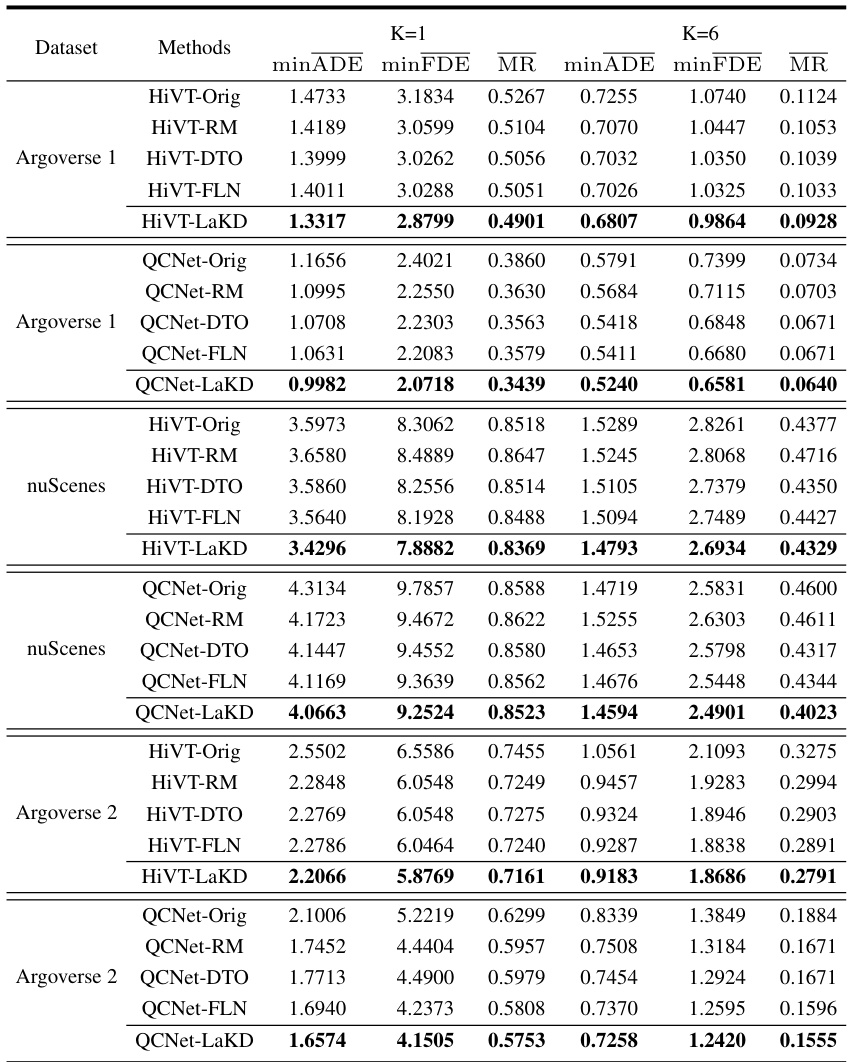
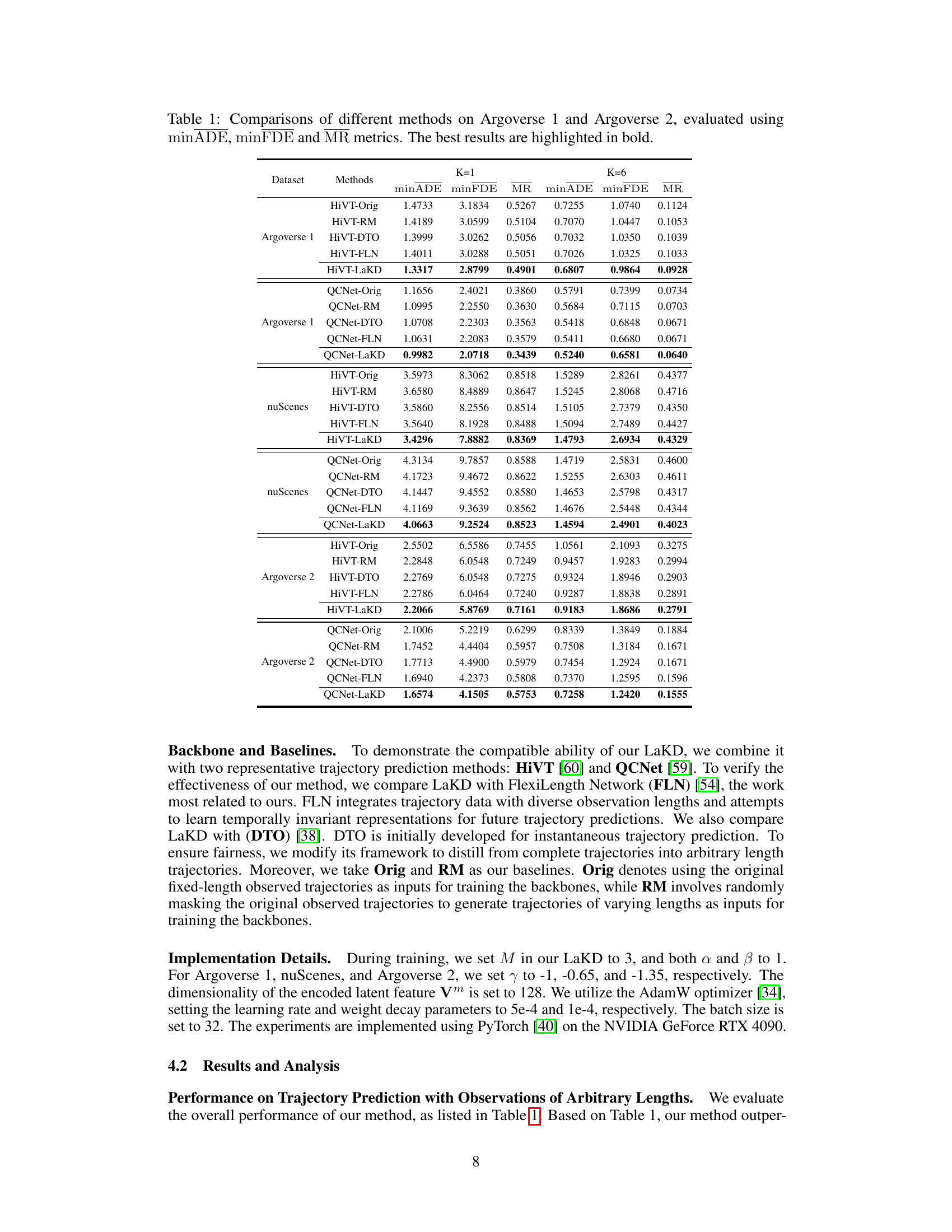
This table presents a comparison of various trajectory prediction methods on two benchmark datasets, Argoverse 1 and Argoverse 2. The methods are evaluated using three metrics: minimum average displacement error (minADE), minimum final displacement error (minFDE), and miss rate (MR). The results are shown for different numbers of predicted trajectories (K=1 and K=6). The best performing method for each metric and dataset is highlighted in bold. The table allows for a quantitative comparison of the performance of different methods in the context of trajectory prediction, providing insights into their relative strengths and weaknesses.
In-depth insights#
Length-Agnostic KD#
The proposed Length-Agnostic Knowledge Distillation (KD) framework offers a novel approach to trajectory prediction by addressing the challenge of varying trajectory lengths. Traditional methods struggle with inconsistent input lengths, but this method leverages dynamic knowledge transfer between trajectories of different lengths. This dynamic aspect is crucial because longer trajectories, while offering rich temporal information, can also contain noise or irrelevant details. The adaptive mechanism dynamically determines the transfer direction – from longer to shorter, or vice-versa, depending on the prediction performance of each trajectory. This addresses the limitations of existing KD methods which often assume a fixed teacher-student relationship. Furthermore, the use of a dynamic soft-masking mechanism during the distillation process prevents knowledge collisions and maintains the integrity of essential features during gradient updates. The framework’s plug-and-play nature allows integration with various existing trajectory prediction models, demonstrating its versatility and potential for significant improvements in accuracy and robustness.
Dynamic Soft Masking#
The proposed Dynamic Soft Masking mechanism is a crucial contribution to the LaKD framework, addressing the potential issue of knowledge collision during the knowledge distillation process. Traditional knowledge distillation often involves a separate teacher and student model. However, LaKD employs a unique design where a single encoder serves as both, which could lead to conflicts when attempting to simultaneously transfer knowledge and maintain performance across varying length trajectories. The Dynamic Soft Masking elegantly tackles this challenge by calculating the importance score of each neuron unit based on the gradients during the training of the ‘good’ trajectory. This importance score, dynamically adjusted using a soft-masking strategy and a decay coefficient, then guides the updating of neuron weights during distillation. Crucial neurons critical for the ‘good’ trajectory’s performance are protected by being given lower update weights, while less important neurons receive larger updates. This dynamic adaptation allows LaKD to successfully navigate the complexities of knowledge transfer across varying trajectory lengths without disrupting critical parts of the model and ensuring efficient and effective knowledge distillation.
Trajectory Prediction#
Trajectory prediction is a critical area in autonomous driving and robotics, aiming to anticipate the future movement of dynamic agents. Accurate prediction is crucial for safety, enabling proactive collision avoidance and efficient path planning. Traditional methods often rely on fixed-length trajectory observations, limiting their effectiveness in real-world scenarios where observation lengths may vary. This limitation is addressed by length-agnostic approaches, which seek to predict accurately regardless of available trajectory data. These methods leverage techniques like knowledge distillation, where knowledge from longer trajectories is transferred to shorter ones, addressing the challenge of making accurate predictions with limited data. Dynamic length-agnostic knowledge distillation is a key innovation, adapting the knowledge transfer based on the prediction performance of various trajectory lengths. Another significant improvement is the introduction of dynamic soft-masking, preventing knowledge collisions when using a unified model to serve as both teacher and student. This improves performance significantly in real-world scenarios.
Experimental Results#
The experimental results section of a research paper is crucial for demonstrating the validity and effectiveness of the proposed method. A strong results section will present a comprehensive evaluation across multiple metrics, datasets, and baselines, allowing for a robust comparison of the new approach against existing state-of-the-art techniques. Statistical significance should be explicitly addressed to ensure that observed improvements are not merely due to chance. The results should be presented clearly, with appropriate visualizations such as graphs and tables, making it easy for the reader to understand the findings. Ideally, the paper will include an ablation study that systematically analyzes the contributions of different components of the model, further solidifying the findings and offering insights into the method’s design. Any limitations or shortcomings of the experimental setup should be openly acknowledged, ensuring transparency and fostering trust in the research’s integrity. Overall, a well-written experimental results section provides compelling evidence to support the paper’s claims, leaving a lasting impression on the reader and showcasing the true value of the contribution.
Future Work#
Future research directions stemming from this length-agnostic knowledge distillation (LaKD) framework for trajectory prediction could explore several promising avenues. Improving the dynamic soft-masking mechanism to more effectively handle knowledge collisions during the distillation process is crucial. A more sophisticated method for determining the optimal transfer direction between trajectories of varying lengths could significantly enhance performance. The current heuristic approach based on prediction performance warrants further investigation. Exploring alternative knowledge transfer strategies beyond KL divergence could uncover more effective ways to exchange information between trajectories. Investigating the framework’s robustness to noise and outliers in real-world trajectory data is vital. Finally, extending LaKD to handle more complex scenarios, such as those involving multiple interacting agents or varying environmental conditions, would greatly expand its practical applicability.
More visual insights#
More on figures

This figure illustrates the LaKD framework, showing the three main components: random masking of historical trajectories to create varying lengths, length-agnostic knowledge distillation for dynamic knowledge transfer between trajectories of different lengths, and dynamic soft masking to prevent knowledge collisions during the distillation process. The diagram visually depicts the flow of information and the interactions between these components during both training and inference phases.
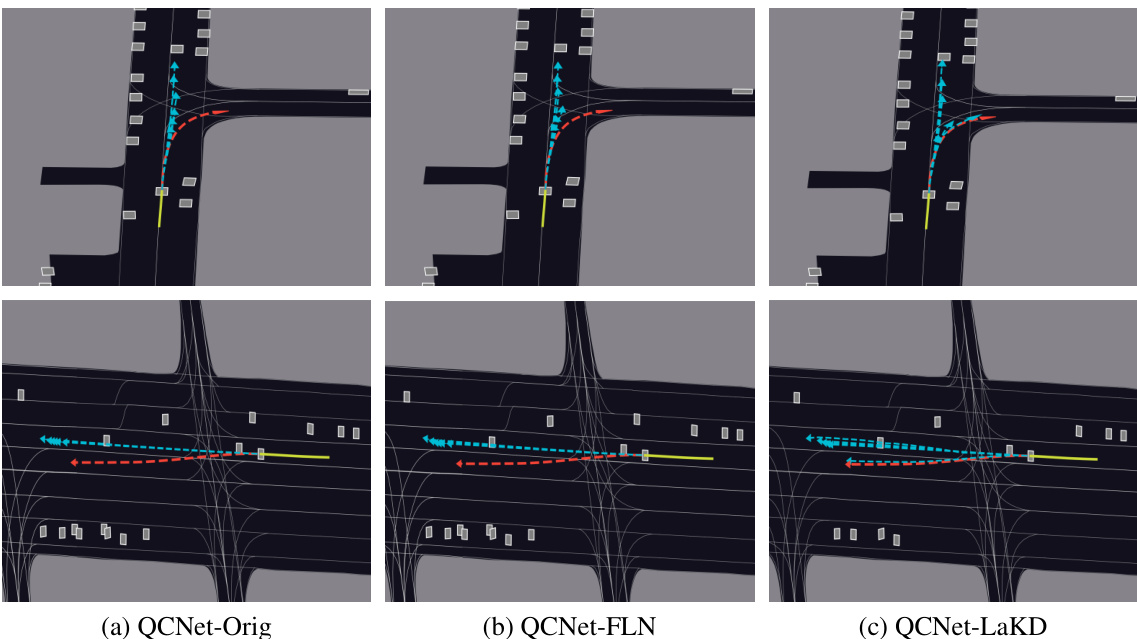
This figure shows a qualitative comparison of trajectory prediction results on the Argoverse 2 dataset using three different methods: QCNet-Orig, QCNet-FLN, and QCNet-LaKD. Each column represents a different method. Within each column, the top row shows a scenario at a T-junction, while the bottom row depicts a scenario at a road fork where a lane change is involved. The green lines represent observed trajectories, the red lines indicate ground truth trajectories, and the blue lines show the model’s predicted trajectories. The figure visually demonstrates that QCNet-LaKD produces predictions that are closer to the ground truth compared to the other two methods, suggesting the superiority of LaKD in trajectory prediction accuracy.
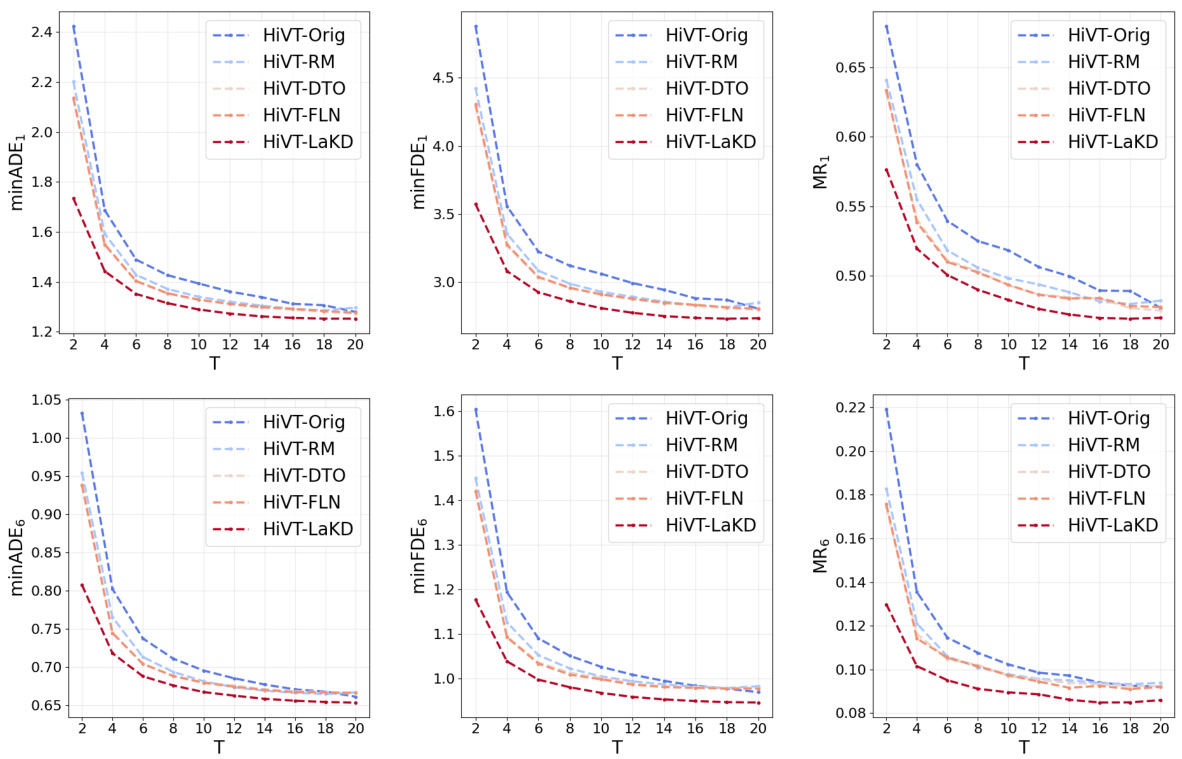
This figure shows the performance of two trajectory prediction models, HiVT and QCNet, using observed trajectories of varying lengths on Argoverse 1 and Argoverse 2 datasets. Subfigures (a) and (b) present quantitative results demonstrating that prediction accuracy can vary with the length of the observed trajectory. Subfigures (c) and (d) illustrate examples of scenarios where either longer or shorter trajectories yield better predictions, highlighting the challenge of handling trajectories of arbitrary lengths.
This figure illustrates the LaKD framework, showing the three main components: random masking of historical trajectories, length-agnostic knowledge distillation (transferring knowledge between trajectories of different lengths), and dynamic soft-masking (preventing knowledge conflicts). The process is detailed for training, but during inference, these steps are not used.

This figure illustrates the LaKD framework, showing its three main components: random masking, length-agnostic knowledge distillation, and dynamic soft masking. Random masking creates observed trajectories of different lengths, which are then used in the distillation process. Knowledge distillation dynamically transfers knowledge among trajectories of varying lengths to improve prediction accuracy. Finally, dynamic soft masking prevents knowledge collisions during the distillation process by selectively updating the gradients of different neurons based on their importance. During inference, these three components are not used to make the process more efficient.

This figure illustrates the LaKD framework, showing its three main components: random masking of historical trajectories, length-agnostic knowledge distillation, and dynamic soft-masking. Random masking creates trajectories of various lengths for training. Length-agnostic knowledge distillation dynamically transfers knowledge between trajectories of different lengths, improving predictions from shorter ones. Dynamic soft-masking prevents conflicts during knowledge transfer. Inference uses the framework without the masking and distillation steps.

This figure illustrates the LaKD framework, showing the process of randomly masking historical trajectories to create various lengths of observed trajectories, then dynamically transferring knowledge across these trajectories using length-agnostic knowledge distillation. A dynamic soft-masking mechanism is incorporated to prevent knowledge collision during training. The inference process omits these steps.

This figure illustrates the LaKD framework, which consists of three main parts: random masking of historical trajectories, length-agnostic knowledge distillation, and a dynamic soft-masking mechanism. Random masking creates observed trajectories of various lengths. Length-agnostic knowledge distillation dynamically transfers knowledge between these trajectories, improving prediction accuracy regardless of trajectory length. Finally, the dynamic soft-masking mechanism prevents knowledge conflicts during the distillation process. The illustration visually depicts the flow of information within the framework and the interaction between its different components during training and inference.
More on tables

This table presents a comparison of various trajectory prediction methods on two benchmark datasets, Argoverse 1 and Argoverse 2. The methods are evaluated using three metrics: minimum Average Displacement Error (minADE), minimum Final Displacement Error (minFDE), and Miss Rate (MR). The results are shown for predicting one trajectory (K=1) and six trajectories (K=6). The best performance for each metric is highlighted in bold. The table allows for a direct comparison of the effectiveness of different trajectory prediction models.
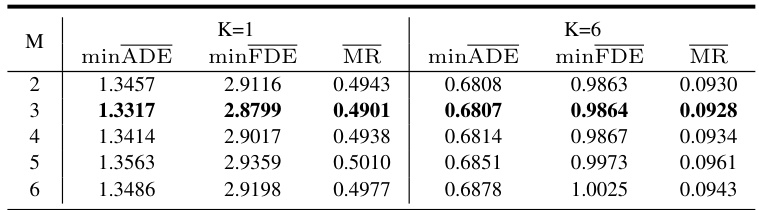
This table presents the ablation study results on the Argoverse 1 dataset, showing the impact of varying the number of random masks (M) applied to the input trajectories during training. The metrics minADE, minFDE, and MR are evaluated for both K=1 and K=6 predictions, with different values of M (2-6). It demonstrates the model’s performance across different trajectory lengths (controlled by M) and its robustness to changes in this hyperparameter.

This table presents a comparison of various trajectory prediction methods on two benchmark datasets, Argoverse 1 and Argoverse 2. The methods are evaluated using three metrics: minimum Average Displacement Error (minADE), minimum Final Displacement Error (minFDE), and Miss Rate (MR). The table shows the performance of each method for predicting 1 and 6 future trajectories (K=1 and K=6). The best performance for each metric and trajectory count is highlighted in bold, allowing for a direct comparison of the effectiveness of different approaches.
Full paper#