TL;DR#
Current 3D point cloud recognition models often overfit to specific patterns, making them vulnerable to real-world corruptions like sensor noise and occlusions. This significantly limits their applicability in real-world scenarios demanding robust 3D perception. This paper tackles this critical challenge by introducing a novel approach that enhances the model’s ability to capture global structure, reducing reliance on easily corrupted localized patterns.
The proposed method, APCT, uses two key modules. The Adversarial Significance Identifier identifies important features, while the Target-guided Promptor directs attention away from potentially corrupted parts of the point cloud. Through iterative training, APCT progressively learns to rely on a broader range of patterns, improving its resilience. This approach achieves state-of-the-art performance on multiple benchmarks, highlighting its potential for building more robust and reliable 3D perception systems.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in 3D point cloud recognition because it directly addresses the critical issue of robustness against real-world data corruption. The proposed APCT method significantly improves the state-of-the-art, offering a novel adversarial representation learning approach that is both effective and efficient. This work opens exciting avenues for further research into more robust and reliable 3D perception systems, particularly important for applications such as autonomous driving and robotics.
Visual Insights#
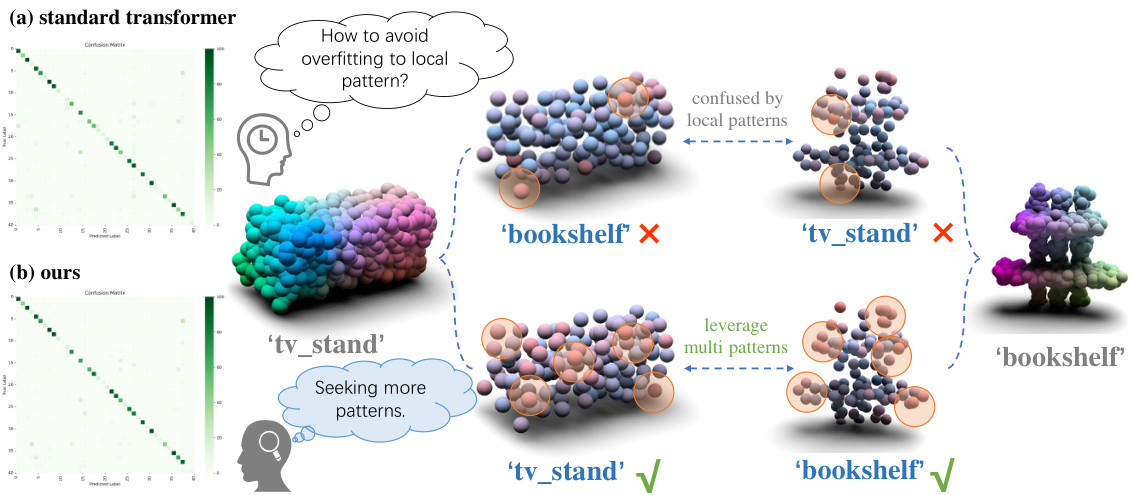
🔼 This figure illustrates the core idea of the proposed method. The left panel shows confusion matrices to compare the standard transformer and the proposed method. The right panel shows the classification results of both methods when dealing with objects containing similar local patterns. The proposed method is more robust against overfitting to localized patterns.
read the caption
Figure 1: Overall motivation. We advocate for the model to broaden its attention to diverse patterns, mitigating the tendency to overfit to localized patterns. The left segment of the figure contrasts the confusion matrices of the standard transformer with our approach. The right portion showcases the performances of both the standard transformer and our methodology when confronted with objects exhibiting similar local patterns. Tokens with high / low contributions to classification are in red / blue, respectively. Standard transformer tends to overfit to localized patterns. While our method, by modulating tokens with significant contributions, enables the model to garner features from a varied spectrum of target segments, thereby ensuring greater robustness.
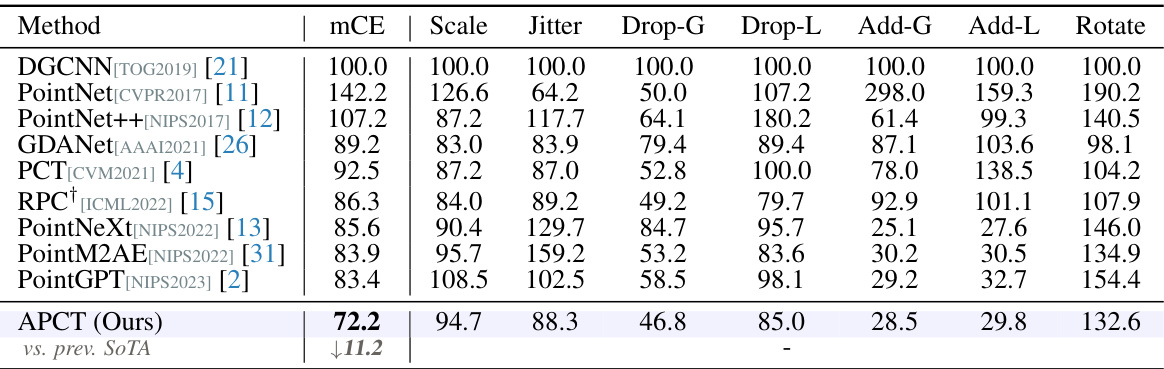
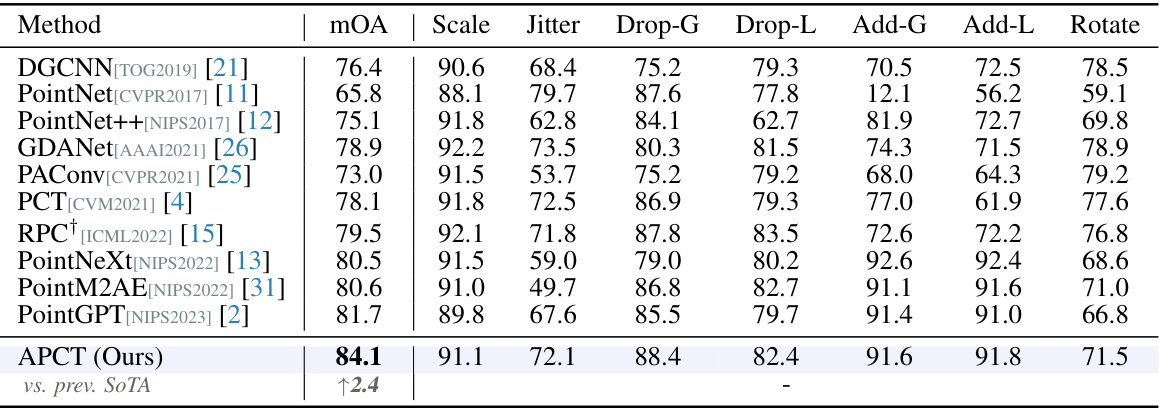
🔼 This table presents a comparison of different point cloud classification methods on the ModelNet-C dataset, which is a benchmark dataset for evaluating robustness against real-world corruptions. The metric used is mean corruption error (mCE), a lower value indicates better performance. The table includes results for several existing state-of-the-art methods (DGCNN, PointNet, etc.) and the proposed APCT method, highlighting APCT’s superior performance across different corruption types. The corruption types include variations in scale, jitter, drop (global/local), add (global/local), and rotation.
read the caption
Table 1: Classification results on the ModelNet-C dataset, mCE(%, ↓) is reported, the best performance is bold. † denotes method designed specifically against corruption.
In-depth insights#
Robust 3D Perception#
Robust 3D perception is a crucial area in computer vision research focusing on creating systems capable of reliable 3D scene understanding despite real-world challenges. These challenges include noisy sensor data, occlusions, varying lighting conditions, and unpredictable object poses. Traditional methods often struggle in these scenarios, which highlights the need for robust algorithms. This area utilizes techniques such as data augmentation, adversarial training, and deep learning architectures specifically designed for resilience. Key research focuses on improving the accuracy and reliability of 3D object detection, segmentation, and scene reconstruction, leading to advancements in robotics, autonomous driving, and augmented reality. Ensuring robustness against corruption is paramount and requires methods that go beyond simply improving model accuracy on clean data, focusing instead on generalizability and the ability to deal with a wide range of challenging scenarios.
Adversarial Training#
Adversarial training, in the context of machine learning, is a robust technique aimed at enhancing model resilience against adversarial attacks. It functions by introducing intentionally perturbed data, or adversarial examples, into the training process. These adversarial examples are crafted to mislead the model, forcing it to learn more discriminative features and, consequently, improving its generalization capabilities. The core idea is to expose the model to a wider range of inputs, encompassing both benign and maliciously altered data, thereby reducing overfitting and enhancing robustness to real-world noise or corruption. Effectiveness depends on the type of adversarial attack used to generate the perturbed data and the model’s architecture. While enhancing robustness, it can lead to increased computational complexity and potentially slower convergence during training. Careful selection of attack methods and regularization techniques is crucial to optimize the balance between enhanced robustness and model performance.
APCT Architecture#
The APCT architecture is a novel approach to 3D point cloud recognition that enhances robustness against real-world corruptions. It leverages a transformer-based model, integrating two key modules: an Adversarial Significance Identifier and a Target-guided Promptor. The identifier analyzes token significance using global contextual information and an auxiliary loss, identifying crucial tokens for accurate classification. The prompter then strategically increases the dropout probability for these high-significance tokens during the self-attention process. This adversarial approach forces the network to rely on less dominant patterns, making it robust to corruptions that might affect only localized object features. This progressive adversarial training process enables the model to learn from a broader range of patterns, improving overall accuracy and resilience in challenging conditions.
Benchmark Results#
A dedicated ‘Benchmark Results’ section would ideally present a thorough comparison of the proposed method (APCT) against existing state-of-the-art (SOTA) techniques. This would involve multiple tables showcasing performance metrics across diverse datasets, each table focusing on a specific type of corruption (e.g., ‘Scale’, ‘Jitter’, ‘Drop-Global’). Key metrics should include mean corruption error (mCE), overall accuracy (OA), and potentially additional metrics relevant to the specific task and datasets used. The results would be crucial for demonstrating APCT’s robustness and superiority. Visualizations, such as graphs plotting mCE across various corruption severities for different methods, could enhance clarity and impact. The analysis within this section should highlight APCT’s strengths compared to competitors, noting areas of significant improvement and where performance is comparable. Ablative studies comparing variations of APCT (e.g., with or without certain modules) would further support the claims of the paper’s contributions, offering insights into the relative importance of individual components.
Future Directions#
Future research could explore enhancing APCT’s robustness by integrating more sophisticated corruption modeling techniques. This might involve simulating diverse real-world scenarios, incorporating various noise types beyond those currently tested, and exploring more complex corruption combinations. Further investigation is warranted into the generalizability of the adversarial approach across diverse point cloud datasets and downstream tasks. Exploring the trade-off between computational efficiency and model accuracy would also be beneficial. For example, can the process be optimized for resource-constrained environments? Finally, future work could investigate novel adversarial training strategies that could further improve the model’s resilience. The potential benefits of utilizing different feature extraction mechanisms alongside APCT are also worth exploring.
More visual insights#
More on figures
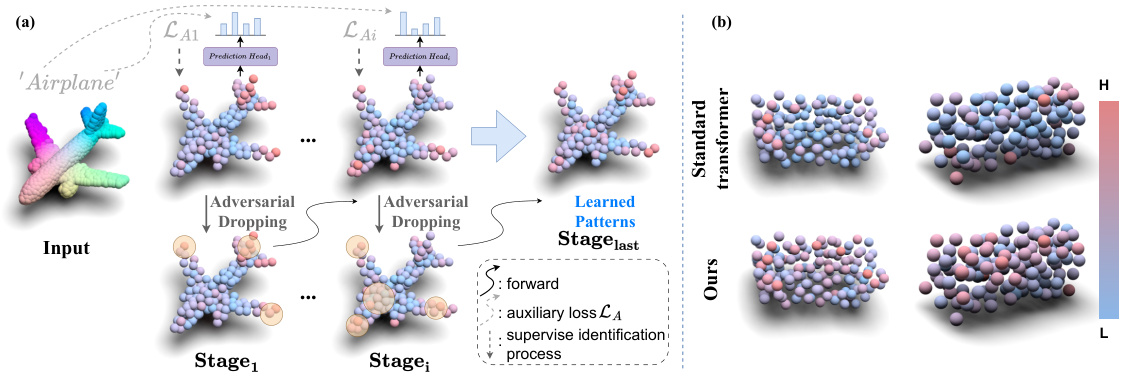
🔼 Figure 2(a) shows the progressive adversarial dropping process of the APCT model. The model iteratively identifies and drops tokens based on their significance, encouraging the model to learn from more diverse patterns. Figure 2(b) visually compares the token weights learned by the standard transformer and the APCT model. The APCT model shows a more balanced distribution of weights, indicating that it learns from a broader range of patterns.
read the caption
Figure 2: (a) Process of progressive adversarial dropping. The first line means token learned in each stage. (b) Visualization of token weights learned by the classifier. Compared with standard transformer, ours has an advantage in mining sample patterns.

🔼 This figure shows the overall architecture of the Target-Guided Adversarial Point Cloud Transformer (APCT). It consists of three stages, each containing multiple blocks. The core components are the Adversarial Significance Identifier and the Target-guided Promptor. The identifier determines the importance of each token and assigns a dropping rate. The prompter then uses these rates to selectively drop tokens during the self-attention mechanism, forcing the network to focus on a broader range of patterns and preventing overfitting.
read the caption
Figure 3: Overall architecture of our algorithm, composed of two key modules: Adversarial Significance Identifier and Target-guided Promptor. The former evaluates token significance within the context of the global perception, with the help of dominant feature indexing process from an auxiliary supervising loss that can bolster the precision of the index selection, then producing dropping rate for tokens. Subsequently, Target-guided Promptor enhances key dropout probabilities influenced by rate above, driving the model to explore auxiliary segments for pivotal information. This mechanism mitigates the propensity of the model to overfit to localized patterns.

🔼 This figure illustrates the process of the Adversarial Significance Identifier module. The input is a set of tokens, each with C-dimensional features. The module uses an auxiliary supervision process to identify the most significant tokens (indicated by darker blue squares) for each feature channel. These significant tokens are used to generate per-token dropout rates, with higher rates assigned to more significant tokens. The dropout rates are then used by the Target-guided Promptor in subsequent stages to selectively drop these key tokens, forcing the network to learn from less dominant features and achieve greater robustness.
read the caption
Figure 4: Workflow of Adversarial Significance Identifier. Squares with light/dark blue means low/high values, respectively.
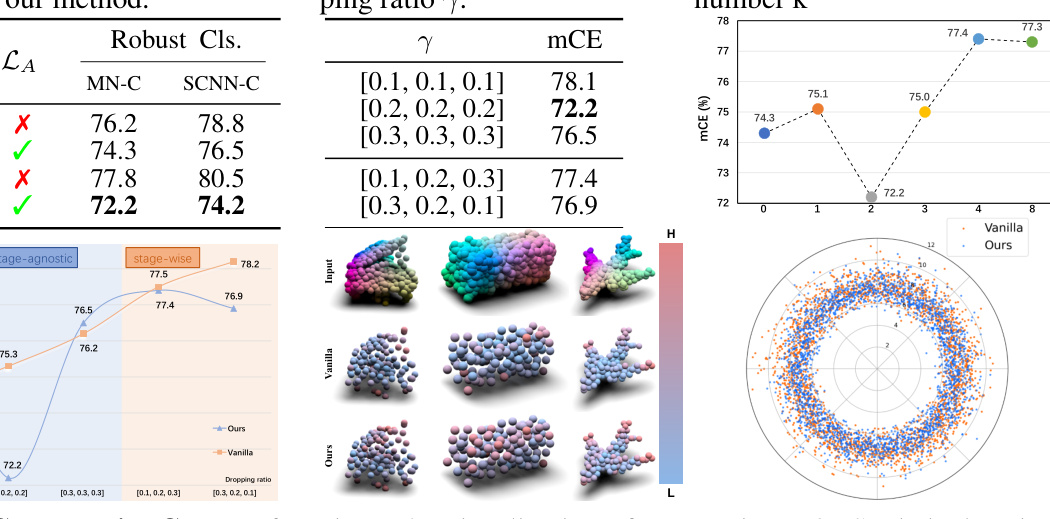
🔼 This figure shows the comparison results between the proposed APCT method and the vanilla dropout method. The x-axis represents different dropout ratios, and the y-axis represents the mean corruption error (mCE). The curves for different methods and configurations show that the proposed APCT consistently outperforms the vanilla dropout method in terms of robustness.
read the caption
Figure 7: Comparative Curves of our algorithm and vanilla dropout strategy.

🔼 This figure shows examples of point cloud corruptions in the ModelNet-C dataset. It illustrates seven different types of corruption (Scale, Jitter, Drop-Global, Drop-Local, Add-Global, Add-Local, Rotate), each with five levels of severity. The image displays the effects of each corruption type at severity level 2 on a single airplane model. The leftmost image shows the clean airplane model, and subsequent images show the progressive degradation caused by each corruption type.
read the caption
Figure 10: Visualization of samples in ModelNet-C, which is constructed by seven types of corruptions with five levels of severity. Listed examples are from severity level 2.

🔼 This figure compares confusion matrices of a standard transformer-based point cloud model and the proposed APCT model under various corruption types (Scale, Jitter, Drop-Global, Drop-Local, Add-Global, Add-Local, Rotate) from the ModelNet-C dataset. Each sub-figure shows the confusion matrix for a specific corruption type. The top row represents the standard model, while the bottom row represents the APCT model. The color intensity in the matrices indicates the frequency of misclassifications between different classes.
read the caption
Figure 11: Side-by-side comparison of the confusion matrices for two distinct architectures: the standard transformer-based point cloud model (top row) and ours (bottom row).

🔼 This figure visualizes the patterns learned by the classifier on the ModelNet-C dataset. It shows examples of point clouds after being processed by a standard transformer and the proposed APCT method. The color intensity of each point represents its contribution to the final classification, with red indicating high contribution and blue indicating low contribution. The figure aims to demonstrate that the APCT method learns a more diverse set of patterns compared to the standard transformer, making it more robust to real-world corruptions.
read the caption
Figure 12: More visualization results of patterns learned by the classifier on ModelNet-C. Tokens with high / low scores are in red / blue, respectively.
More on tables
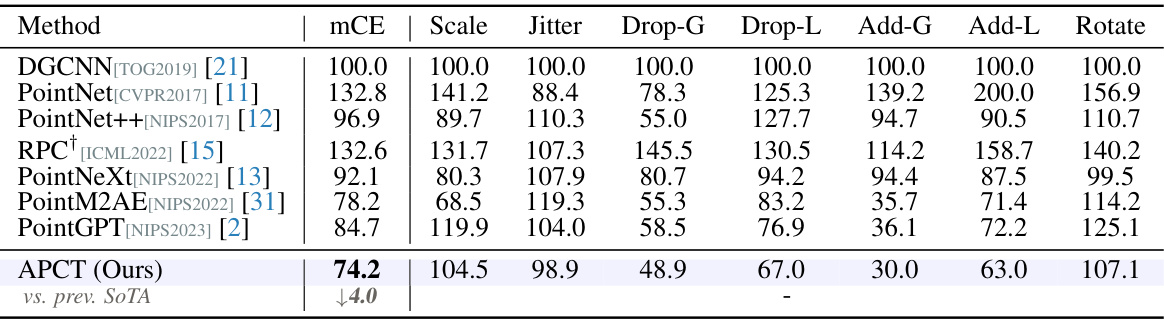
🔼 This table presents a comparison of the mean corruption error (mCE) rates achieved by various point cloud classification methods on the ModelNet-C dataset. The ModelNet-C dataset is a corrupted version of the standard ModelNet40 dataset and includes seven types of corruptions (Scale, Jitter, Drop-Global, Drop-Local, Add-Global, Add-Local, Rotate) each with five levels of severity. The table highlights the performance of the proposed APCT method in comparison to state-of-the-art methods, showcasing its robustness against real-world corruptions.
read the caption
Table 1: Classification results on the ModelNet-C dataset, mCE(%, ↓) is reported, the best performance is bold. † denotes method designed specifically against corruption.
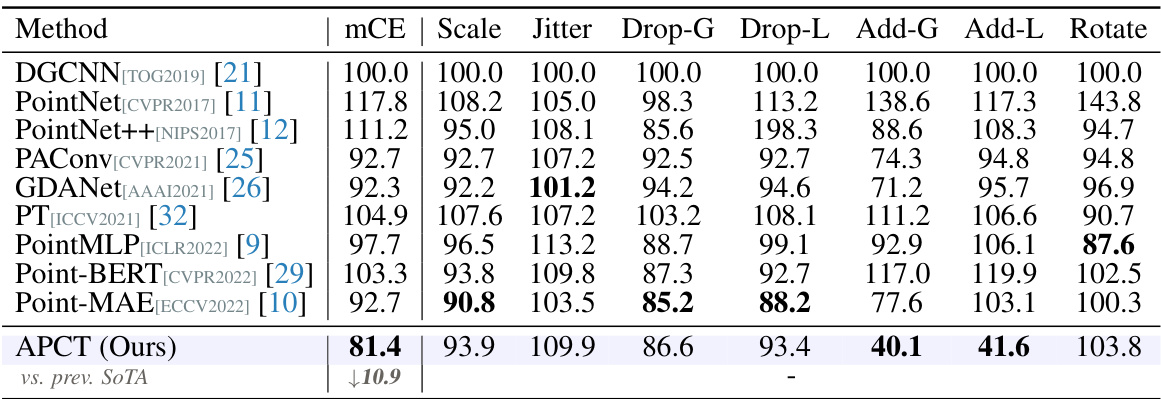
🔼 This table presents the results of several point cloud classification methods on the ModelNet-C dataset, which is a benchmark dataset for evaluating the robustness of 3D models to common real-world corruptions. The table shows the mean corruption error (mCE) for each method across seven different types of corruptions (Scale, Jitter, Drop-G, Drop-L, Add-G, Add-L, and Rotate) at five severity levels. The best performance for each corruption type is highlighted in bold. The methods are categorized into those designed specifically against corruption and those that are not.
read the caption
Table 1: Classification results on the ModelNet-C dataset, mCE(%, ↓) is reported, the best performance is bold. † denotes method designed specifically against corruption.
🔼 This table presents a comparison of various point cloud classification methods on the ModelNet-C dataset, focusing on their robustness against different types of corruption (Jitter, Scale, Drop-Global, Drop-Local, Add-Global, Add-Local, Rotate). The metric used for comparison is the mean corruption error (mCE), which measures the average classification error across all types and levels of corruption. The table includes both methods that were specifically designed to address corruptions (indicated by †) and standard methods. The best performance for each corruption type is highlighted in bold.
read the caption
Table 1: Classification results on the ModelNet-C dataset, mCE(%, ↓) is reported, the best performance is bold. † denotes method designed specifically against corruption.

🔼 This table presents a comparison of the mean corruption error (mCE) rates achieved by various point cloud classification methods on the ModelNet-C dataset. The ModelNet-C dataset is a corrupted version of the standard ModelNet40 dataset, designed to test the robustness of 3D perception models against various real-world corruptions (jitter, scale, rotation, dropping, and adding of points). The table shows the performance of each method across different corruption types and severities, with the best-performing method highlighted in bold. The ‘†’ symbol indicates methods specifically designed to be robust against corruption. The results provide a quantitative evaluation of the resilience of the different approaches to various types of data noise and artifacts.
read the caption
Table 1: Classification results on the ModelNet-C dataset, mCE(%, ↓) is reported, the best performance is bold. † denotes method designed specifically against corruption.

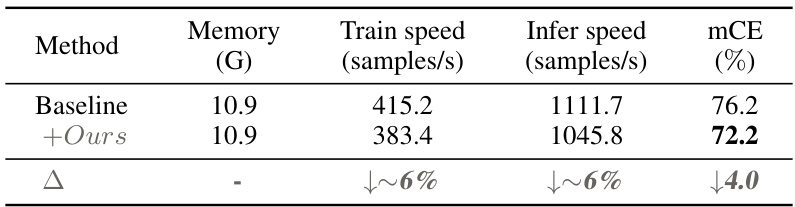
🔼 This table presents the results of point cloud attack defense experiments. It compares the classification accuracy (OA) of a baseline model (no defense) against a model incorporating the proposed APCT method. Several types of attacks are tested, including Perturb, Add-CD, Add-HD, KNN, Drop-100, and Drop-200. The Δ row shows the improvement in OA achieved by the APCT method for each attack type. The results demonstrate the effectiveness of APCT against various point cloud attack methods.
read the caption
Table 8: Results on point cloud attack defense, OA(%, ↑).

🔼 This table presents the classification results on the ModelNet-C dataset, which evaluates the robustness of 3D point cloud recognition models against various corruptions. The metric used is mean corruption error (mCE), with lower values indicating better performance. The table compares the proposed APCT method with several state-of-the-art methods across different corruption types (Scale, Jitter, Drop-Global, Drop-Local, Add-Global, Add-Local, Rotate). The best performance for each corruption type is highlighted in bold.
read the caption
Table 1: Classification results on the ModelNet-C dataset, mCE(%, ↓) is reported, the best performance is bold. † denotes method designed specifically against corruption.

🔼 This table presents a comparison of different point cloud classification methods on the ModelNet-C dataset, which is a corrupted version of the ModelNet40 dataset. The table shows the mean corruption error (mCE) for each method across seven different types of corruptions (Scale, Jitter, Drop-Global, Drop-Local, Add-Global, Add-Local, Rotate) at five different severity levels. The best performing method for each corruption type is highlighted in bold. The methods are categorized into those specifically designed to handle corruptions (indicated with a †) and general-purpose methods. The table allows readers to assess the robustness of various methods against different types of noise and corruptions commonly found in real-world point cloud data.
read the caption
Table 1: Classification results on the ModelNet-C dataset, mCE(%, ↓) is reported, the best performance is bold. † denotes method designed specifically against corruption.

🔼 This table presents a comparison of the mean corruption error (mCE) rates achieved by different methods on the ModelNet-C dataset. ModelNet-C is a benchmark dataset for evaluating the robustness of 3D point cloud recognition models against various types of corruptions (jitter, scale, drop, add, and rotation). The lower the mCE, the better the performance of the method in handling corruptions. The table highlights the state-of-the-art performance achieved by the proposed APCT method.
read the caption
Table 1: Classification results on the ModelNet-C dataset, mCE(%, ↓) is reported, the best performance is bold. † denotes method designed specifically against corruption.

🔼 This table presents the classification results on the ModelNet-C dataset, which is a benchmark dataset for evaluating the robustness of 3D point cloud recognition models against various corruptions. The metric used is mean corruption error (mCE), and the lower the mCE, the better the performance. The table compares the proposed APCT method with several state-of-the-art methods, showing its superior performance in handling various types of corruptions, including scale, jitter, drop, add, and rotate.
read the caption
Table 1: Classification results on the ModelNet-C dataset, mCE(%, ↓) is reported, the best performance is bold. † denotes method designed specifically against corruption.

🔼 This table presents a comparison of the mean corruption error (mCE) rates achieved by different methods on the ModelNet-C dataset. ModelNet-C is a corrupted version of the ModelNet40 dataset, used to evaluate the robustness of 3D point cloud recognition models to various types of noise and corruptions. The table includes the performance of several state-of-the-art methods, including those specifically designed to handle corrupted data. The lowest mCE value indicates the best performance, showing which model is most robust to corruption.
read the caption
Table 1: Classification results on the ModelNet-C dataset, mCE(%, ↓) is reported, the best performance is bold. † denotes method designed specifically against corruption.

🔼 This table presents a comparison of the mean corruption error (mCE) rates achieved by various point cloud classification methods on the ModelNet-C dataset. The dataset includes seven types of corruptions at varying severity levels. The table shows that the proposed APCT method achieves the lowest mCE rate, indicating superior robustness to corruption compared to existing methods. The table also highlights the state-of-the-art (SoTA) results for each corruption type.
read the caption
Table 1: Classification results on the ModelNet-C dataset, mCE(%, ↓) is reported, the best performance is bold. † denotes method designed specifically against corruption.
🔼 This table presents the classification results on the ModelNet-C dataset, a benchmark for evaluating the robustness of 3D point cloud models against various corruptions. The metric used is mean corruption error (mCE), which represents the average classification error across different corruption types and levels. The table compares the performance of APCT against several state-of-the-art methods. The lowest mCE values indicate better robustness to corruption. The ‘†’ symbol marks methods specifically designed for robustness against corruption.
read the caption
Table 1: Classification results on the ModelNet-C dataset, mCE(%, ↓) is reported, the best performance is bold. † denotes method designed specifically against corruption.
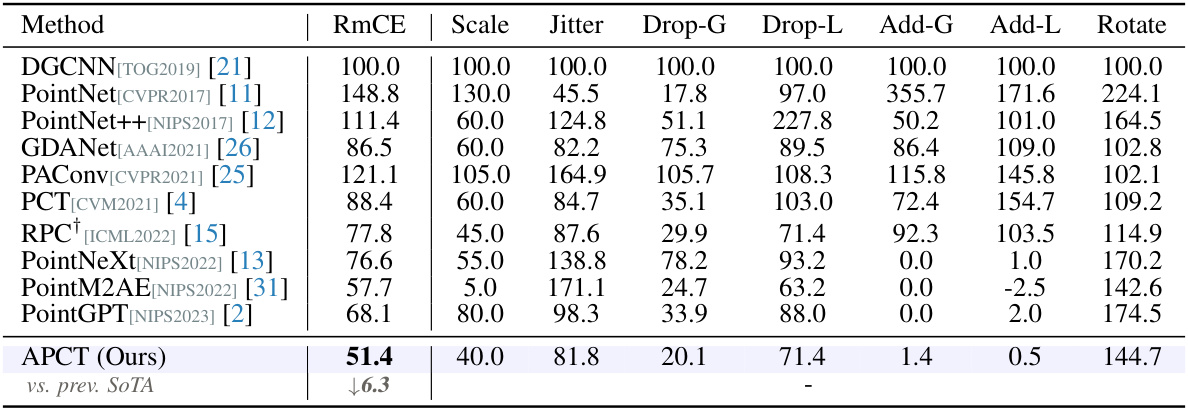
🔼 This table presents a comparison of different methods for point cloud classification on the ModelNet-C dataset, which is a challenging benchmark with several types of corruptions. The main evaluation metric is mean corruption error (mCE), which measures the average error rate across different corruption levels. The table shows that the proposed APCT method achieves state-of-the-art results, outperforming other methods by a significant margin.
read the caption
Table 1: Classification results on the ModelNet-C dataset, mCE(%, ↓) is reported, the best performance is bold. † denotes method designed specifically against corruption.

🔼 This table presents a comparison of the mean corruption error (mCE) for various point cloud classification methods on the ModelNet-C dataset. The dataset contains point clouds with different types of corruptions (scale, jitter, drop-global, drop-local, add-global, add-local, and rotate), each at five levels of severity. The table shows the mCE for each method under each type of corruption. The best-performing method for each corruption type is highlighted in bold. Methods specifically designed to handle corrupted data are marked with a † symbol. This allows for a quantitative comparison of the robustness of different methods against real-world corruptions.
read the caption
Table 1: Classification results on the ModelNet-C dataset, mCE(%, ↓) is reported, the best performance is bold. † denotes method designed specifically against corruption.
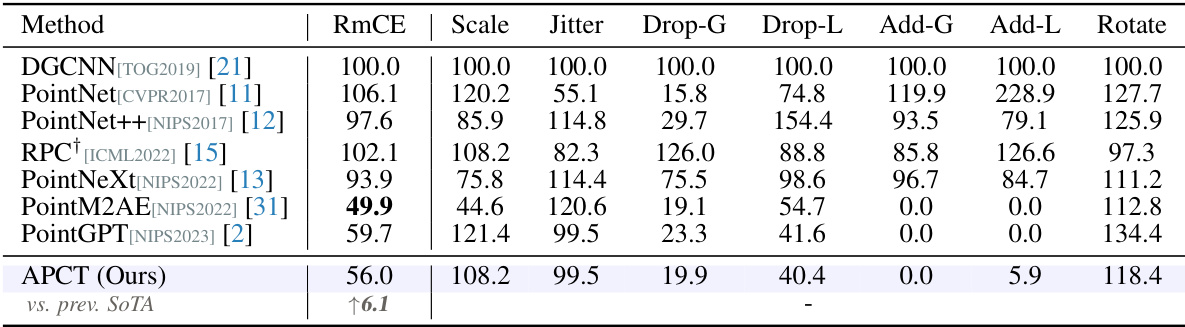
🔼 This table presents a comparison of different point cloud classification methods on the ModelNet-C dataset, which is a benchmark dataset for evaluating the robustness of models against various types of corruptions. The table shows the mean corruption error (mCE) for each method across seven different corruption types: Scale, Jitter, Drop-Global, Drop-Local, Add-Global, Add-Local, and Rotate. The best performance for each corruption type is shown in bold. Methods marked with † are specifically designed to be robust against corruptions. The table provides a quantitative evaluation of different methods’ performance in handling real-world corruptions.
read the caption
Table 1: Classification results on the ModelNet-C dataset, mCE(%, ↓) is reported, the best performance is bold. † denotes method designed specifically against corruption.
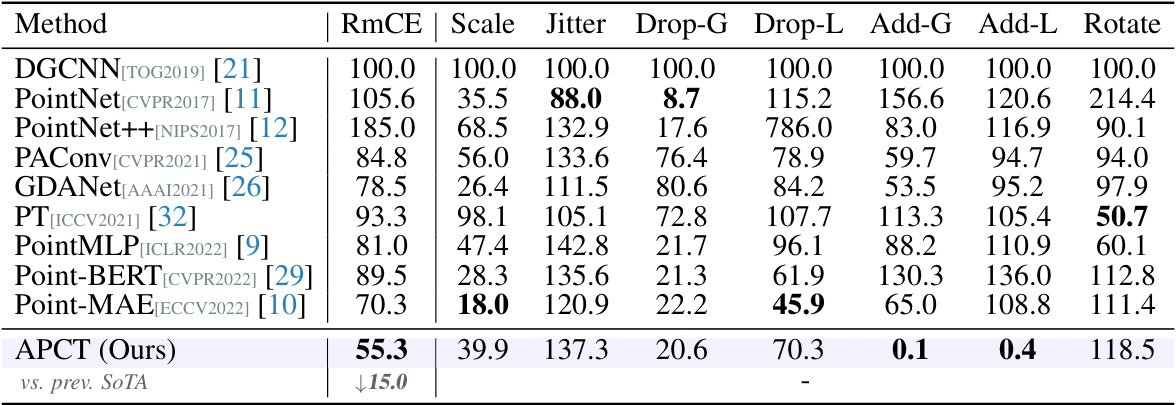
🔼 This table presents a comparison of classification results on the ModelNet-C dataset (a benchmark for evaluating the robustness of point cloud models against various types of corruption) among different methods. The mCE (mean Corruption Error) metric, a percentage representing the average classification error across different types of corruption and severity levels, is used to evaluate the performance of each method. The best performance for each corruption type is highlighted in bold. The † symbol indicates that a method was specifically designed to handle corrupted data. This allows one to directly compare the resilience of standard methods with those tailored for robustness.
read the caption
Table 1: Classification results on the ModelNet-C dataset, mCE(%, ↓) is reported, the best performance is bold. † denotes method designed specifically against corruption.
Full paper#