TL;DR#
Federated Instruction Tuning (FIT) improves model capabilities while safeguarding data privacy. However, current FIT methods struggle with cross-domain training due to domain-aware data heterogeneity, leading to catastrophic forgetting where models perform poorly on individual domains.
DoFIT, a novel Domain-aware FIT framework, tackles this issue. It uses two key strategies: 1) finely aggregating overlapping weights across domains to reduce interference and 2) initializing intra-domain weights by incorporating inter-domain information for better retention. This leads to significant improvements over existing methods, showcasing DoFIT’s effectiveness in alleviating catastrophic forgetting and enhancing performance in cross-domain collaborative training.
Key Takeaways#
Why does it matter?#
This paper is important because it addresses the crucial issue of catastrophic forgetting in federated instruction tuning, a significant challenge hindering the effective adaptation of large language models in privacy-preserving collaborative settings. By proposing a novel domain-aware framework, DoFIT, the research opens new avenues for improving the performance and robustness of federated learning systems for LLMs and other machine learning models. The work is relevant to researchers interested in federated learning, large language models, and techniques to improve model efficiency and prevent catastrophic forgetting.
Visual Insights#

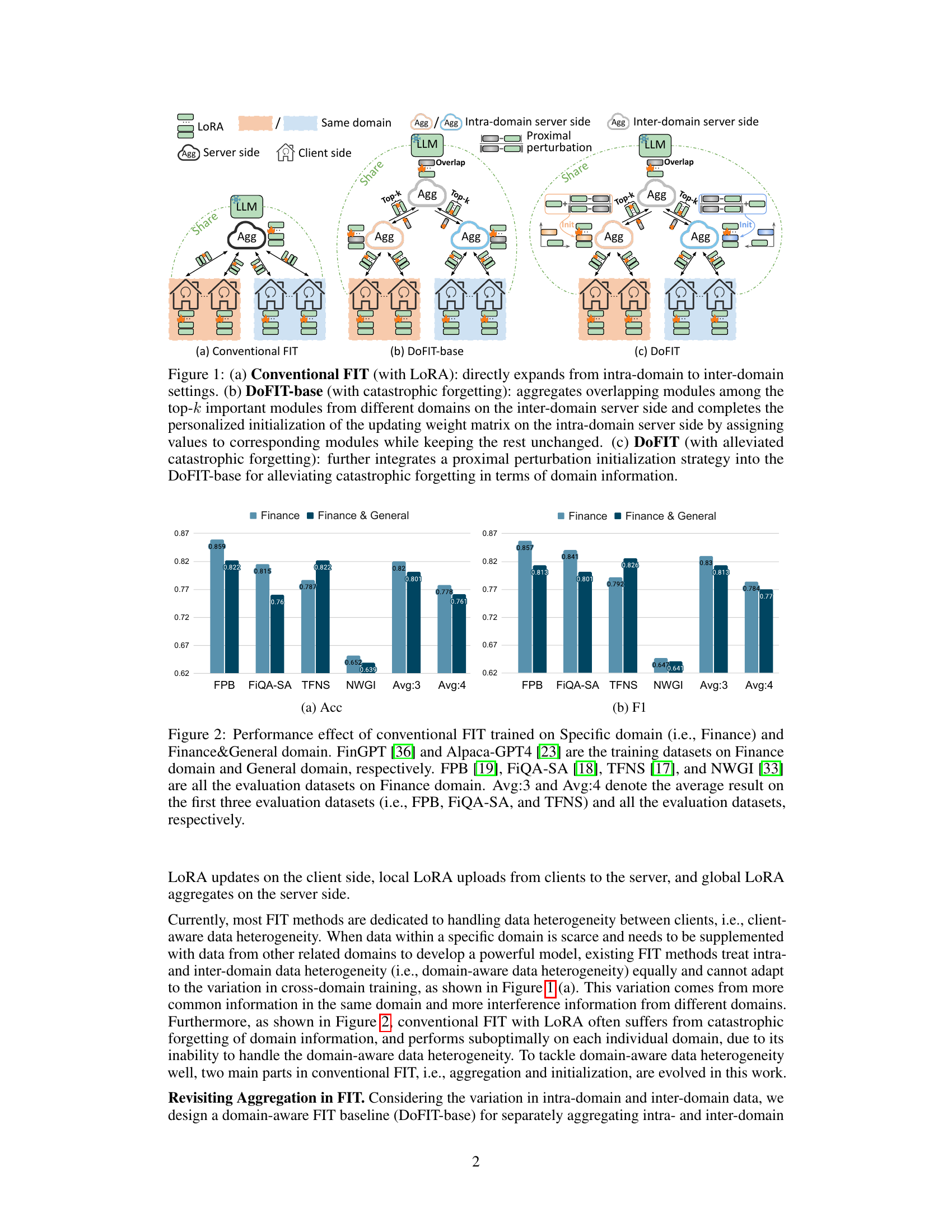
🔼 This figure illustrates the difference between conventional FIT and the proposed DoFIT method in handling domain-aware data heterogeneity. (a) shows conventional FIT, which directly expands from intra-domain to inter-domain settings without considering the domain differences. (b) shows DoFIT-base, which aggregates overlapping modules from different domains on the inter-domain server side and initializes updating weights on the intra-domain side. (c) shows the complete DoFIT method, which incorporates a proximal perturbation initialization strategy to alleviate catastrophic forgetting by better preserving domain information. The figure highlights the key differences in aggregation and initialization strategies between conventional FIT and the proposed DoFIT.
read the caption
Figure 1: (a) Conventional FIT (with LoRA): directly expands from intra-domain to inter-domain settings. (b) DoFIT-base (with catastrophic forgetting): aggregates overlapping modules among the top-k important modules from different domains on the inter-domain server side and completes the personalized initialization of the updating weight matrix on the intra-domain server side by assigning values to corresponding modules while keeping the rest unchanged. (c) DoFIT (with alleviated catastrophic forgetting): further integrates a proximal perturbation initialization strategy into the DoFIT-base for alleviating catastrophic forgetting in terms of domain information.

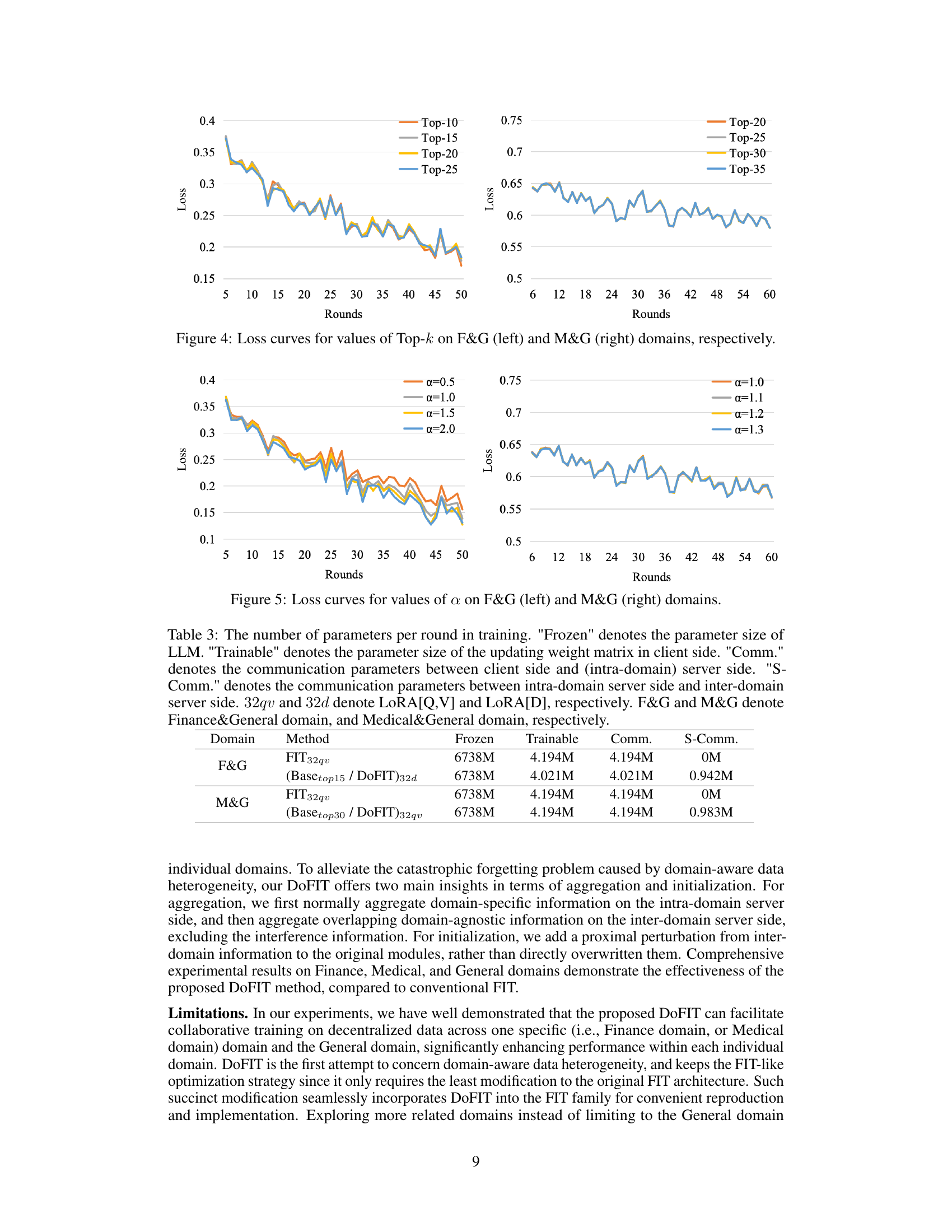
🔼 This table compares the performance of four different methods (Local, Conventional FIT, DoFIT-base, and DoFIT) on two datasets (Finance and Finance&General) using several metrics (Accuracy and F1-score). It shows how the proposed DoFIT method improves upon existing methods by alleviating catastrophic forgetting and considering domain-aware data heterogeneity.
read the caption
Table 1: Comparing 'Local', Conventional FIT ('FIT'), DoFIT-base ('Base'), and 'DoFIT' on Finance (F) domain and Finance&General (F&G) domain datasets. FinGPT [36] and Alpaca-GPT4 [23] are the training datasets on F domain and G domain, respectively. FPB [19], FiQA-SA [18], TFNS [17], and NWGI [33] are the evaluation datasets on F domain. Avg:3 and Avg:4 denote the average result on the first three evaluation datasets (i.e., FPB, FiQA-SA, and TFNS) and all the evaluation datasets, respectively. ↑ refers to the performance improvement compared to the alternative marked with the same color (i.e., using the same LoRA configuration) on F domain. ↓ denotes performance degradation, oppositely.
In-depth insights#
DoFIT Framework#
The DoFIT framework presents a novel approach to Federated Instruction Tuning (FIT) by directly addressing domain-aware data heterogeneity. Unlike conventional FIT methods that primarily focus on client-level data variations, DoFIT tackles the challenge of differing data distributions across various domains. This is achieved through a two-pronged strategy: fine-grained aggregation of overlapping weights across domains on the inter-domain server and informed initialization of intra-domain weights using inter-domain information to minimize catastrophic forgetting. This innovative design enables effective cross-domain collaborative training, leveraging data from related fields to enhance model performance on individual domains. DoFIT’s key strength lies in its ability to selectively aggregate information, reducing interference from less relevant domains and preserving crucial domain-specific knowledge. The experimental results demonstrate the framework’s superiority over existing FIT methods in handling cross-domain settings and mitigating the adverse effects of catastrophic forgetting.
Cross-Domain FIT#
Cross-domain Federated Instruction Tuning (FIT) tackles the challenge of enhancing model performance in scenarios with limited data within a specific domain. By leveraging data from related domains, cross-domain FIT aims to mitigate catastrophic forgetting while maintaining data privacy. Key challenges lie in effectively aggregating information from diverse domains to avoid interference and ensure that the model retains crucial domain-specific knowledge. Successful approaches will need to carefully balance the contributions from different domains, potentially through weighting schemes or selective aggregation techniques. The trade-off between generalization and retention of domain-specific characteristics will need to be carefully considered when developing such methods. Ultimately, the effectiveness of cross-domain FIT will depend on the ability to retain domain-specific information while leveraging the benefit of diverse data. This requires sophisticated methods for data aggregation and model initialization that are sensitive to the differences and commonalities across domains.
Catastrophic Forgetting#
Catastrophic forgetting, a significant challenge in machine learning, especially plagues incremental learning scenarios. In the context of federated instruction tuning (FIT), catastrophic forgetting manifests as the model’s inability to retain knowledge from previously learned domains when adapting to new ones. This is particularly problematic when dealing with scarce data in a specific domain, necessitating the use of data from related fields. Traditional FIT methods often struggle with this cross-domain data heterogeneity, leading to suboptimal performance. The core issue is the interference between information from different domains, causing the model to ‘forget’ previously acquired knowledge. Effective solutions must address this interference and preserve domain-specific information. This could involve techniques like carefully designed aggregation strategies to filter out irrelevant information during model updates, specific weight initialization strategies that prioritize the retention of previous domain knowledge, or employing regularization methods to balance the learning process across all domains. Overcoming catastrophic forgetting in FIT is crucial for developing robust and adaptable large language models that can effectively handle diverse and decentralized data.
Aggregation & Init#
The ‘Aggregation & Init’ section of a federated learning paper likely details how the model updates from multiple clients are combined (aggregation) and how a model is initialized or re-initialized at the start of each round (initialization). Effective aggregation strategies, such as weighted averaging based on client data quality or model performance, are crucial to prevent poor-performing clients from negatively impacting the global model. Smart initialization techniques, perhaps leveraging previously learned weights from related tasks or domains, can significantly mitigate catastrophic forgetting, a major challenge in federated learning. The authors would likely discuss the trade-offs between aggregation methods that prioritize data privacy and those that improve model accuracy. Similarly, they might compare different initialization approaches concerning their computational cost and their impact on the model’s generalization ability and convergence speed. Careful consideration is given to the balance between preserving domain-specific information and preventing interference from other domains when combining multiple sources. In essence, this section represents a significant contribution to improving the efficacy of federated learning by enhancing both the model update mechanism and its initial state.
Future of DoFIT#
The future of DoFIT hinges on addressing its current limitations and exploring new avenues for improvement. Scaling DoFIT to handle a larger number of clients and domains is crucial for real-world applicability. This requires efficient aggregation strategies and potentially novel server architectures. Investigating different aggregation techniques beyond simple averaging, perhaps incorporating more sophisticated weighting schemes based on client reliability or domain relevance, could significantly enhance performance and robustness. Furthermore, research into more advanced initialization methods that better preserve domain-specific information during cross-domain training is warranted. This could involve exploring techniques from orthogonal or meta-learning. Finally, extending DoFIT to other modalities beyond text, such as images or audio, would broaden its applicability and impact. Addressing these challenges will solidify DoFIT’s position as a leading federated instruction tuning framework and unlock its full potential for collaborative learning in diverse and privacy-sensitive settings.
More visual insights#
More on figures

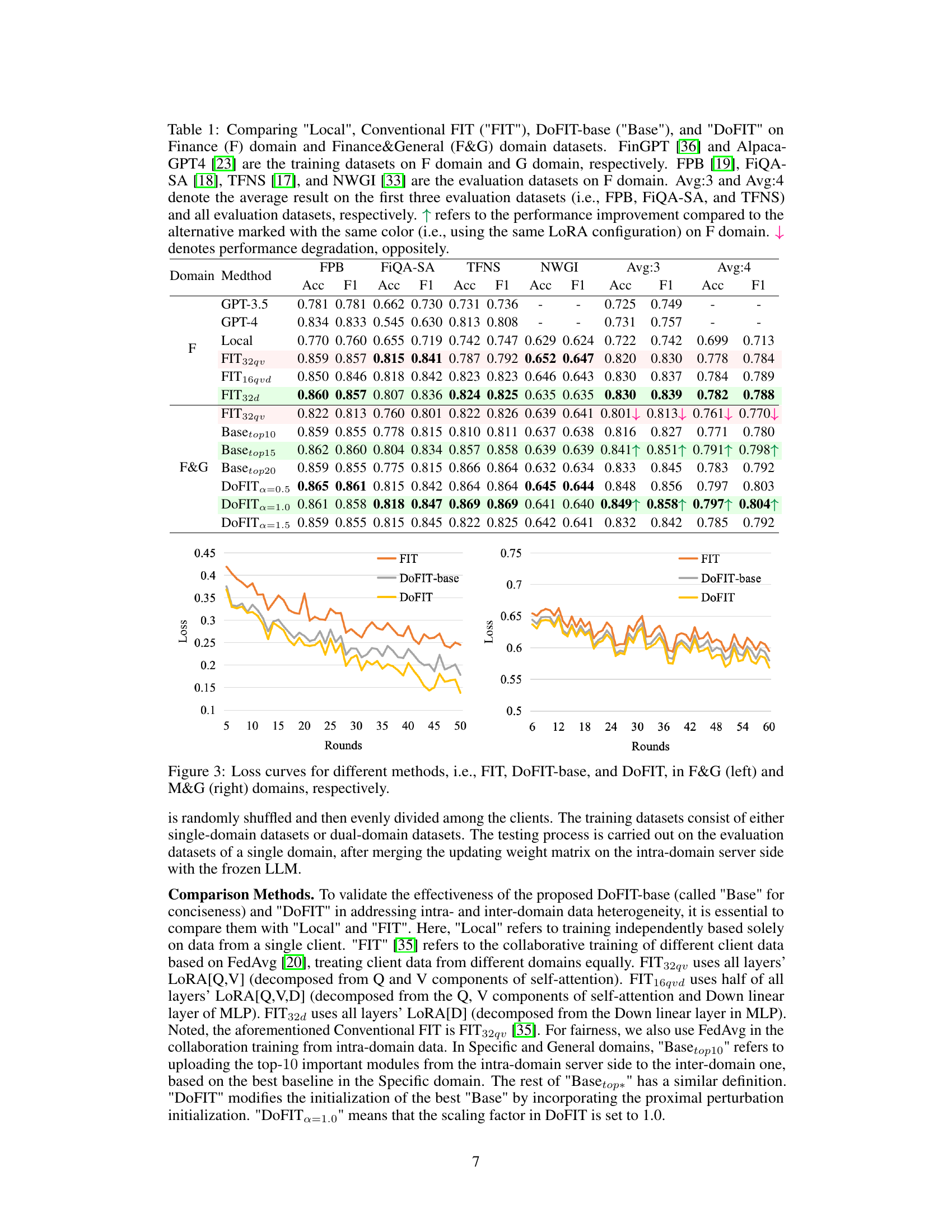
🔼 This figure compares the performance of conventional federated instruction tuning (FIT) when trained on a single domain (Finance) versus multiple domains (Finance and General). It shows accuracy and F1 scores on various evaluation datasets (FPB, FiQA-SA, TFNS, NWGI) for models trained on different datasets (FinGPT for Finance, Alpaca-GPT4 for General). The average scores across three datasets (Avg:3) and all four datasets (Avg:4) are also presented.
read the caption
Figure 2: Performance effect of conventional FIT trained on Specific domain (i.e., Finance) and Finance&General domain. FinGPT [36] and Alpaca-GPT4 [23] are the training datasets on Finance domain and General domain, respectively. FPB [19], FiQA-SA [18], TFNS [17], and NWGI [33] are all the evaluation datasets on Finance domain. Avg:3 and Avg:4 denote the average result on the first three evaluation datasets (i.e., FPB, FiQA-SA, and TFNS) and all the evaluation datasets, respectively.

🔼 This figure shows the loss curves for three different federated instruction tuning methods: FIT (conventional FIT), DoFIT-base, and DoFIT. The left panel displays the loss curves for the Finance & General (F&G) domain, while the right panel shows the loss curves for the Medical & General (M&G) domain. The curves illustrate how the loss decreases over training rounds for each method, providing a visual comparison of their performance in reducing loss during cross-domain collaborative training. DoFIT consistently demonstrates faster convergence and lower final loss compared to the other two methods, highlighting its effectiveness in mitigating catastrophic forgetting.
read the caption
Figure 3: Loss curves for different methods, i.e., FIT, DoFIT-base, and DoFIT, in F&G (left) and M&G (right) domains, respectively.

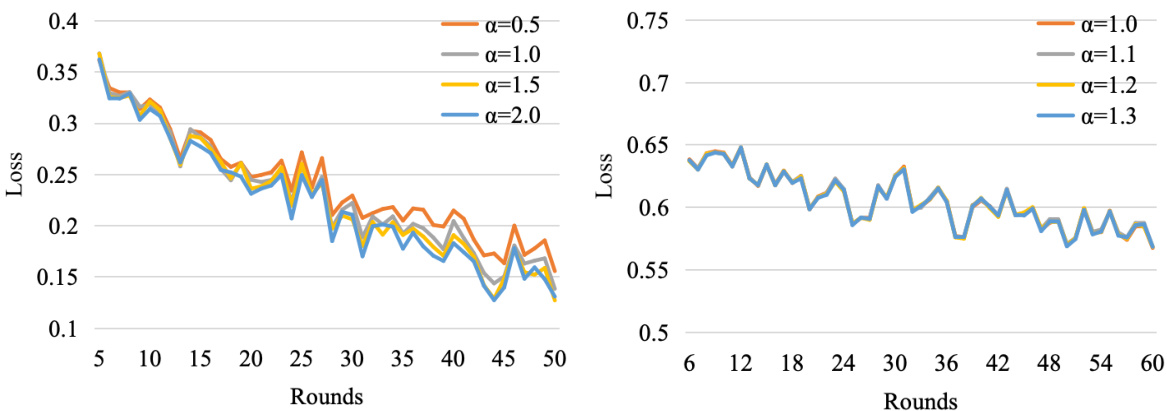
🔼 This figure displays the loss curves for different values of the top-k parameter in the DoFIT model. The left panel shows the results for the Finance & General (F&G) domains, while the right panel shows the results for the Medical & General (M&G) domains. The x-axis represents the number of training rounds, and the y-axis represents the loss value. Different colored lines represent different values of the top-k parameter. This figure helps to illustrate how the choice of the top-k parameter affects the model’s performance during training.
read the caption
Figure 4: Loss curves for values of Top-k on F&G (left) and M&G (right) domains, respectively.
🔼 This figure shows the training loss curves for three different methods: conventional Federated Instruction Tuning (FIT), the DoFIT-base, and the proposed DoFIT method. The curves are plotted for two different domain settings: Finance & General (F&G) and Medical & General (M&G). The plots visualize the training loss over a number of rounds, demonstrating the convergence speed and stability of each method in different domain settings.
read the caption
Figure 3: Loss curves for different methods, i.e., FIT, DoFIT-base, and DoFIT, in F&G (left) and M&G (right) domains, respectively.

🔼 This figure shows the training loss curves for three different methods: FIT (conventional Federated Instruction Tuning), DoFIT-base (a baseline domain-aware method), and DoFIT (the proposed method). The left panel shows the loss curves for the Finance & General domain combination (F&G), while the right panel displays the loss curves for the Medical & General domain combination (M&G). The plots illustrate the convergence speed and final loss achieved by each method, demonstrating DoFIT’s superior performance in reducing training loss.
read the caption
Figure 3: Loss curves for different methods, i.e., FIT, DoFIT-base, and DoFIT, in F&G (left) and M&G (right) domains, respectively.
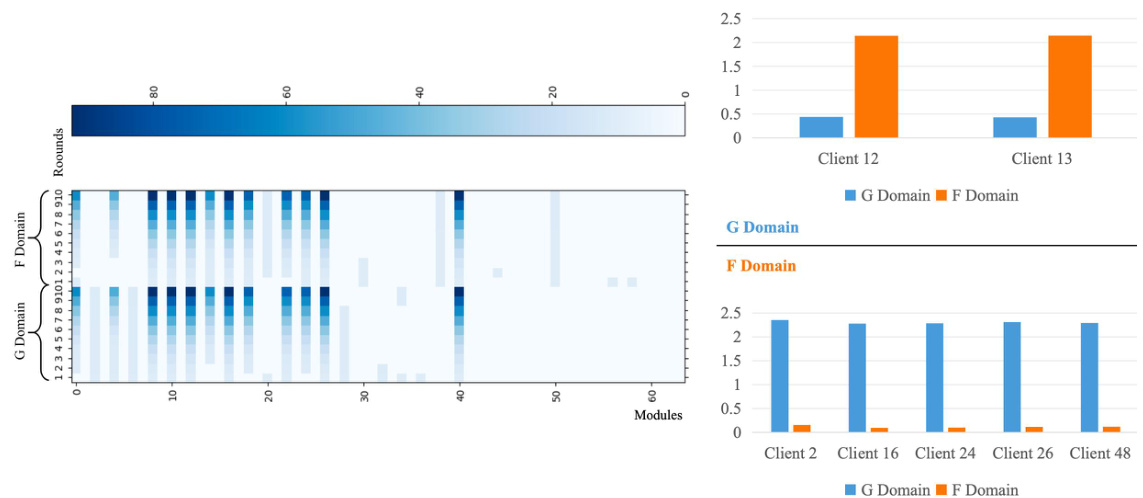
🔼 This figure visualizes the importance scores of modules and their singular value spectrum across different rounds for two domains (F and G). The left panel shows a heatmap representing the importance scores of modules across rounds, while the right panel displays bar charts comparing the singular value spectrum for selected clients in both domains. These visualizations aim to illustrate the differences in module importance and singular value distribution between the two domains, providing insights into the model’s learning behavior and the impact of DoFIT’s domain-aware strategies.
read the caption
Figure 7: Modules important scores (left) and singular value spectrum (right) on F and G domains
More on tables
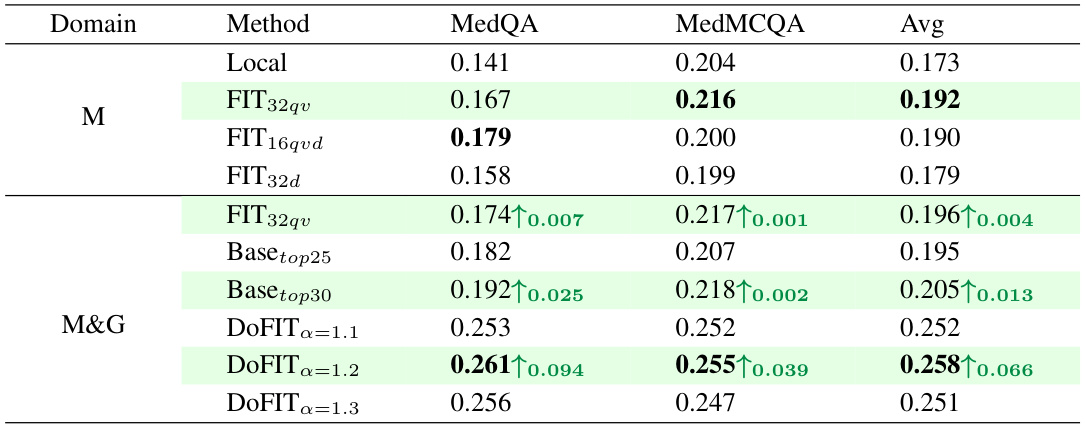
🔼 This table compares the performance of different methods (Local, FIT, DoFIT-base, and DoFIT) on the Medical domain (M) and the combined Medical & General domain (M&G). It shows the accuracy scores on the MedQA and MedMCQA evaluation datasets. The results highlight the impact of using different approaches in handling data heterogeneity in federated instruction tuning, especially the benefits of DoFIT’s strategies in alleviating catastrophic forgetting in cross-domain collaborative training.
read the caption
Table 2: Comparing 'Local', Conventional FIT ('FIT'), DoFIT-base ('Base'), and 'DoFIT' on Medical domain (M), and combined Medical&General domain (M&G). MedAlpaca [2], and Alpaca-GPT4 [23] are the training datasets on M domain, and G domain, respectively. MedQA [10], and MedMCQA [22] are the evaluation datasets on M domain. ↑ refers to the performance improvement compared to the alternative marked with the same color (i.e., using the same LoRA configuration) on M domain.

🔼 This table compares the number of parameters used in different methods (FIT, DoFIT-base, and DoFIT) for training on Finance&General and Medical&General domains. It breaks down the parameters into frozen (LLM), trainable (updating weight matrix), communication between client and intra-domain server, and communication between intra- and inter-domain servers.
read the caption
Table 3: The number of parameters per round in training. 'Frozen' denotes the parameter size of LLM. 'Trainable' denotes the parameter size of the updating weight matrix in client side. 'Comm.' denotes the communication parameters between client side and (intra-domain) server side. 'S-Comm.' denotes the communication parameters between intra-domain server side and inter-domain server side. 32qv and 32d denote LoRA[Q,V] and LoRA[D], respectively. F&G and M&G denote Finance&General domain, and Medical&General domain, respectively.

🔼 This table compares the performance of DoFIT with existing federated domain adaptation methods (FedGP and FedGP-g) on the Finance domain datasets. It shows accuracy and F1 scores on four evaluation datasets (FPB, FiQA-SA, TFNS, NWGI), as well as average scores across the first three datasets and all four. The results highlight DoFIT’s superior performance in handling domain-aware data heterogeneity.
read the caption
Table 4: Comparison with existing federated domain adaptation works.
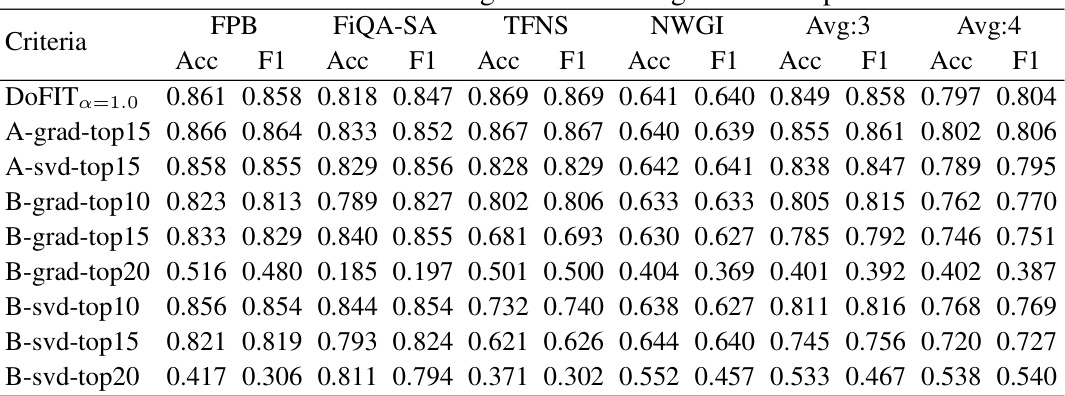
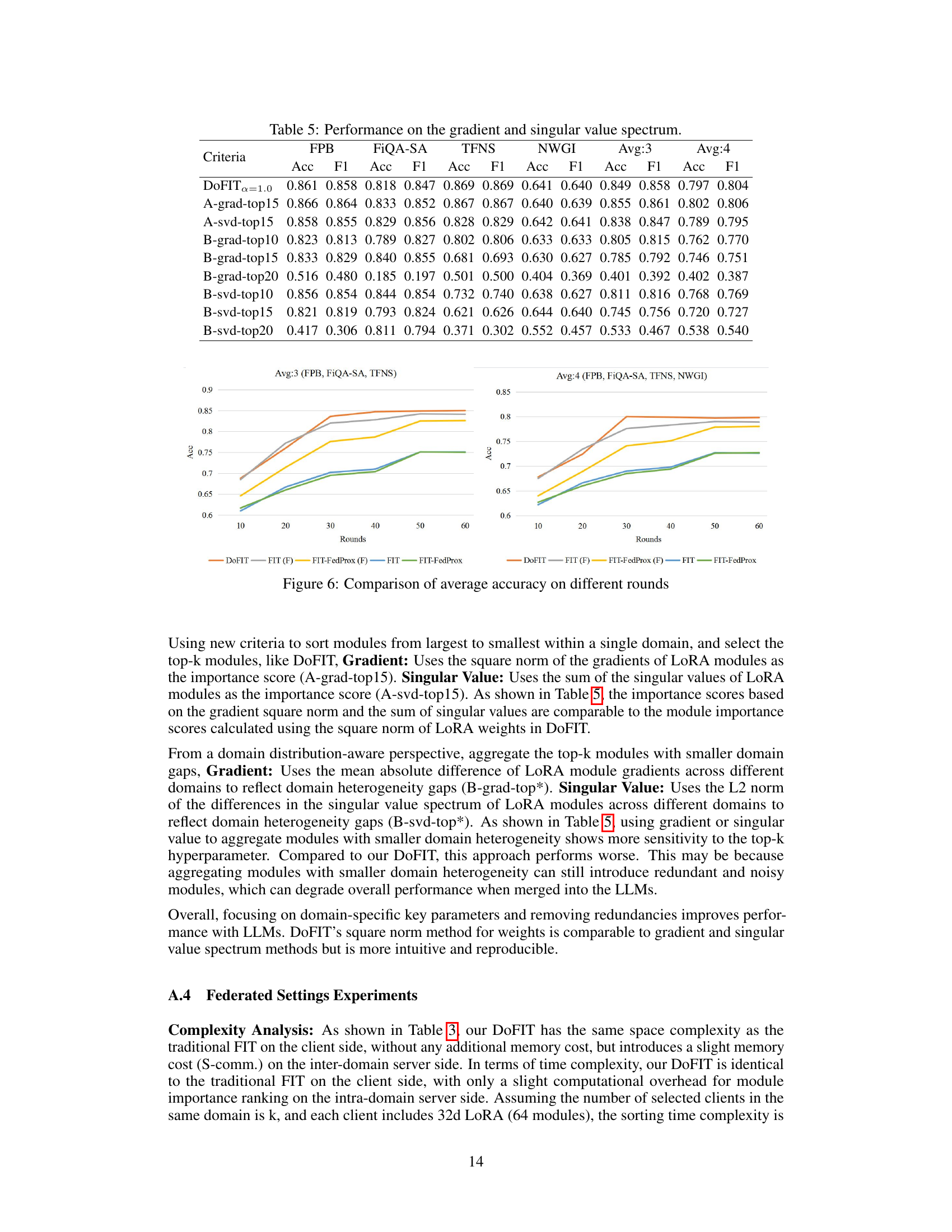
🔼 This table presents the performance results on different criteria for evaluating module importance in the LoRA model. The criteria include using the gradient and singular value spectrum of LoRA modules. The table shows the accuracy and F1 scores on four evaluation datasets (FPB, FiQA-SA, TFNS, NWGI) and their averages across three and all four datasets. It compares the performance of DoFIT with several methods based on gradient or singular value for selecting top-k modules.
read the caption
Table 5: Performance on the gradient and singular value spectrum.
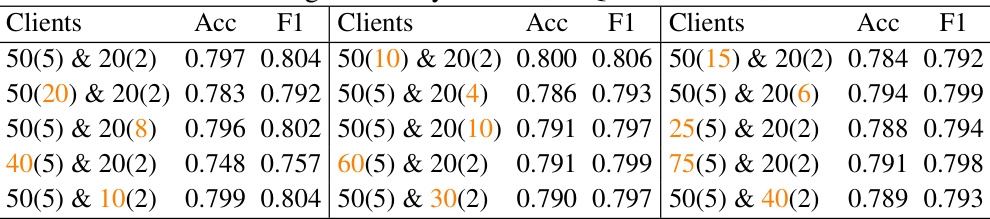
🔼 This table presents the average accuracy and F1 scores achieved on four different evaluation datasets (FPB, FiQA-SA, TFNS, NWGI) for various configurations of clients and number of selected clients per round in the Finance (F) and General (G) domains. It demonstrates how the performance of the DoFIT model varies based on different dataset sizes and how many clients are selected for collaboration in each round.
read the caption
Table 6: Average accuracy on FPB, FiQA-SA, TFNS, NWGI
Full paper#