↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Cross-modal hashing (CMH) faces a significant hurdle: incomplete labels hinder accurate similarity learning, especially for negative pairs. Existing methods struggle because missing labels introduce uncertainty in identifying positive and negative relationships, which are crucial for training effective CMH models. This creates an imbalance in the training data, leading to suboptimal performance.
To overcome this, the authors propose PCRIL, a novel approach that uses a prompt-based contrastive learning strategy. PCRIL progressively identifies promising positive classes and searches for other relevant labels, effectively addressing the label incompleteness. It also incorporates augmentation techniques to handle extreme cases of missing labels and scarce negative pairs. Experiments show that PCRIL significantly outperforms state-of-the-art CMH methods, demonstrating its effectiveness in improving cross-modal retrieval accuracy in scenarios with incomplete labels.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in cross-modal retrieval due to its innovative solution for handling incomplete labels, a common and challenging problem. The proposed method significantly improves retrieval accuracy, opening up new avenues for research in this area and impacting applications reliant on efficient cross-modal search. Its focus on leveraging vision-language models’ prior knowledge is particularly relevant to current research trends in few-shot and zero-shot learning.
Visual Insights#
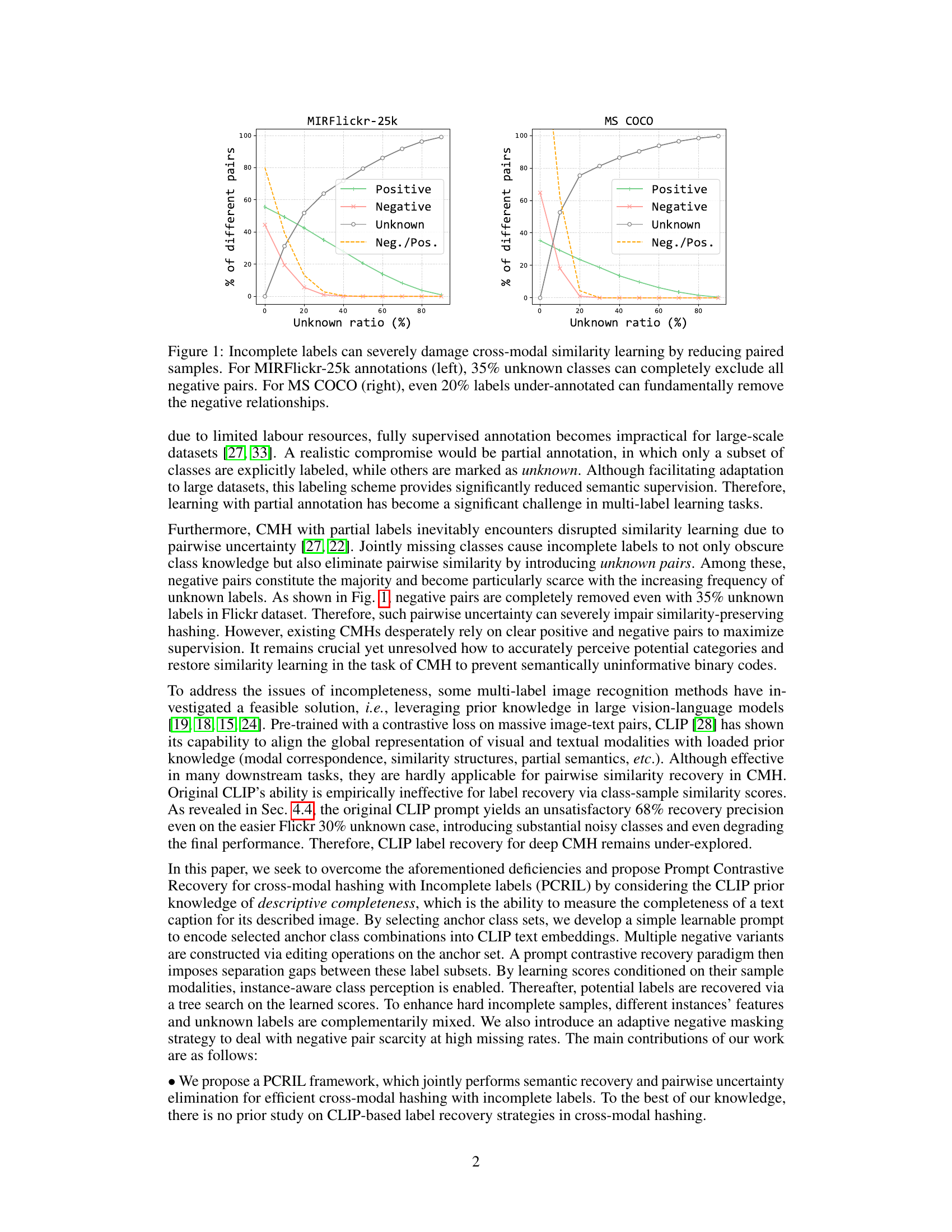
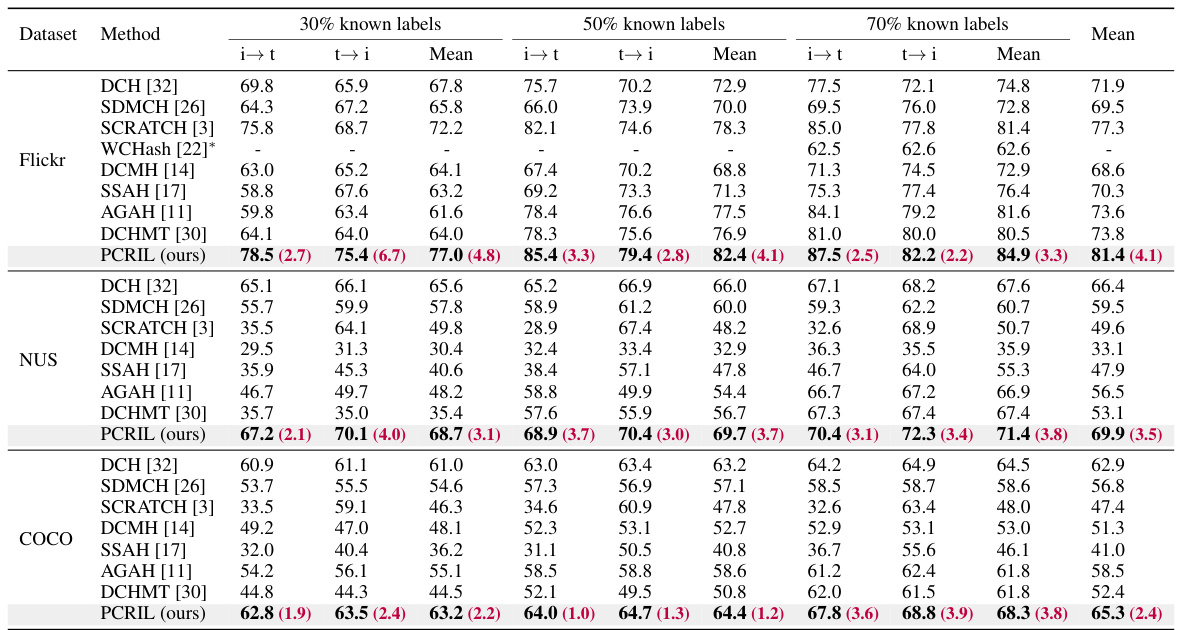
This figure shows the impact of incomplete labels on the number of different pairs available for cross-modal similarity learning. In both the MIRFlickr-25k and MS COCO datasets, the percentage of positive, negative, and unknown pairs is plotted against the percentage of unknown labels. The results demonstrate that as the percentage of unknown labels increases, the number of negative pairs dramatically decreases, making cross-modal similarity learning significantly more challenging.
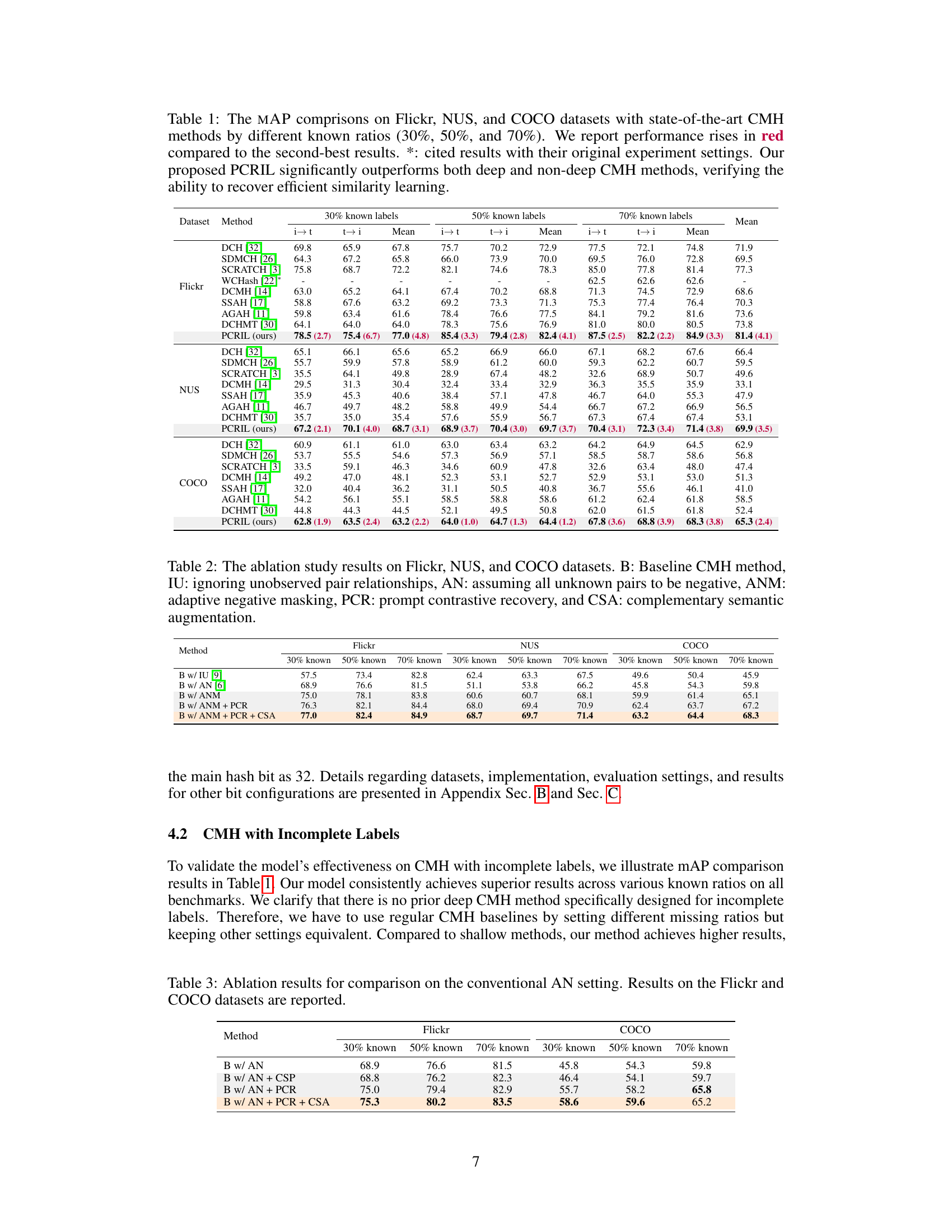
This table presents a comparison of the mean average precision (mAP) achieved by the proposed PCRIL method and several state-of-the-art cross-modal hashing (CMH) methods on three benchmark datasets (Flickr, NUS-WIDE, and COCO). The comparison is performed under three different scenarios of incomplete labels, where 30%, 50%, and 70% of the labels are known. The table highlights the superior performance of PCRIL across all datasets and label completeness levels, demonstrating its effectiveness in recovering efficient similarity learning from incomplete data.
In-depth insights#
Incomplete Label CMH#
Cross-modal hashing (CMH) with incomplete labels presents a significant challenge due to the inherent uncertainty in distinguishing between positive and negative sample pairs. The scarcity of negative samples, in particular, severely hampers the effectiveness of traditional CMH methods which rely heavily on clear positive/negative pair definitions for training. This necessitates novel approaches to address the problem of incomplete supervision. Methods addressing this might involve leveraging prior knowledge from external sources, such as pre-trained vision-language models, to infer missing labels or augmenting the training data with techniques like data mixup or negative sampling strategies. The key is to effectively estimate the completeness of label sets and employ techniques that can reliably generate informative pseudo-labels for unknown samples. Evaluating the success of such methods requires careful consideration of evaluation metrics, such as mean average precision (mAP), that are robust to the presence of uncertainty. Future research directions could explore more sophisticated generative models or advanced contrastive learning methods designed to handle the ambiguity introduced by incomplete labels.
CLIP Prompt Contrastive Learning#
CLIP Prompt Contrastive Learning represents a novel approach to leveraging the power of vision-language models like CLIP for cross-modal hashing tasks, especially when dealing with incomplete labels. The core idea revolves around constructing informative prompts that encapsulate sets of labels, rather than individual labels. This allows the model to learn richer semantic relationships between visual and textual modalities. By employing a contrastive learning paradigm, the model learns to distinguish between sets of positive labels and carefully generated negative label sets. This contrastive objective effectively guides the model to better understand the completeness of label sets, thus improving the accuracy of label recovery for unknown instances. The strength of this approach lies in its ability to address the challenges posed by incomplete supervision, a common issue in large-scale datasets where full annotation is impractical. It offers a potentially significant improvement over traditional methods by harnessing the contextual understanding offered by CLIP, resulting in more accurate and robust cross-modal retrieval.
PCRIL Architecture#
The PCRIL architecture is a two-stage process designed for cross-modal hashing with incomplete labels. The first stage, prompt contrastive recovery, cleverly uses CLIP’s capabilities to progressively identify positive classes from unknown label sets. This is achieved by creating and contrasting various prompts based on subsets of positive labels, guiding the model to learn completeness and perform a greedy tree search for missing labels. The second stage, augmented pairwise similarity learning, addresses the scarcity of negative sample pairs common in incomplete label settings. This is done via two key augmentation strategies: complementary semantic augmentation blends samples to fill uncertainty gaps and adaptive negative masking strategically creates artificial negative pairs to enhance training. The whole process is elegantly designed to overcome data limitations inherent in incomplete-label scenarios, enabling more robust cross-modal hashing. CLIP’s prior knowledge is central to both stages, providing effective guidance and semantic understanding.
Extreme Case Augmentation#
The concept of “Extreme Case Augmentation” in the context of cross-modal hashing with incomplete labels addresses the challenges posed by scenarios with highly imbalanced data and significant label uncertainty. These situations, where a large portion of labels are unknown and negative pairs are scarce, severely hamper the effectiveness of standard training methods. The augmentation strategies employed tackle these issues by introducing techniques to synthesize complementary data (mixup with unknown-complementary samples) and artificially generate negative pairs (adaptive negative masking) This is crucial as conventional approaches struggle to learn robust representations in the presence of such extreme data imbalances. The introduction of augmentations improves robustness and helps balance the training process, enabling more effective similarity learning despite the challenging circumstances.
CMH Future Directions#
Future research in Cross-Modal Hashing (CMH) should prioritize handling incomplete or noisy labels, a common real-world challenge. Addressing this requires developing robust methods that leverage uncertainty quantification and semi-supervised learning techniques. Incorporating advanced representation learning methods, such as transformers and graph neural networks, will likely improve CMH’s ability to capture complex inter-modal relationships. Furthermore, exploring new evaluation metrics that go beyond simple accuracy and consider aspects like semantic similarity and retrieval efficiency is crucial. Finally, expanding CMH’s applicability to diverse modalities and large-scale datasets is vital. A focus on developing efficient and scalable algorithms, while maintaining accuracy, will pave the way for wider adoption of CMH in practical applications.
More visual insights#
More on figures
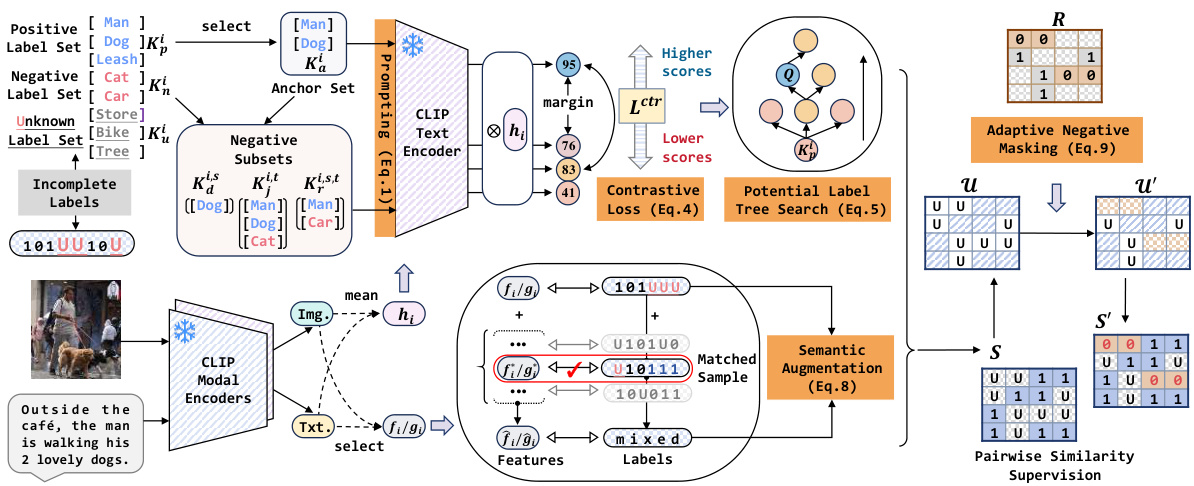
This figure illustrates the PCRIL framework, which consists of two main stages: prompt contrastive recovery and augmented pairwise similarity learning. The first stage uses CLIP to learn contrastive matching scores between anchor label sets and their negative variants, progressively identifying promising positive classes from unknown labels. This helps to recover informative semantics. The second stage addresses extreme cases of unknown labels and negative pair scarcity through two augmentation strategies: complementary semantic augmentation (mixup of unknown-complementary samples) and adaptive negative masking. These augmentations enhance similarity learning by enriching the pairwise similarity supervision.
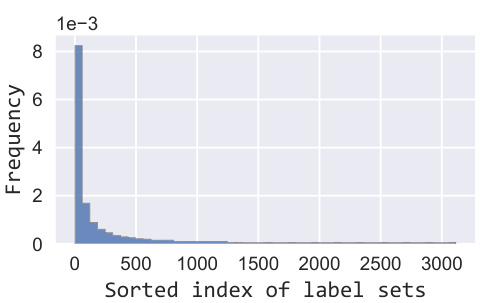
The figure shows the distribution of the frequency of unique positive label sets in the MIRFlickr-25k dataset when 70% of the labels are known. The x-axis represents the sorted index of label sets, and the y-axis represents the frequency of each label set. The distribution is heavily skewed towards a small number of frequent label sets, indicating a long-tail distribution. This imbalance can negatively affect model training due to limited training samples for less frequent label sets.
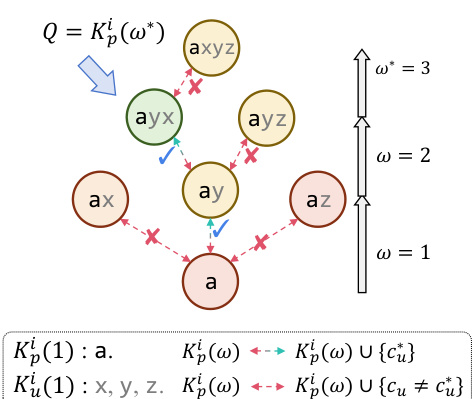
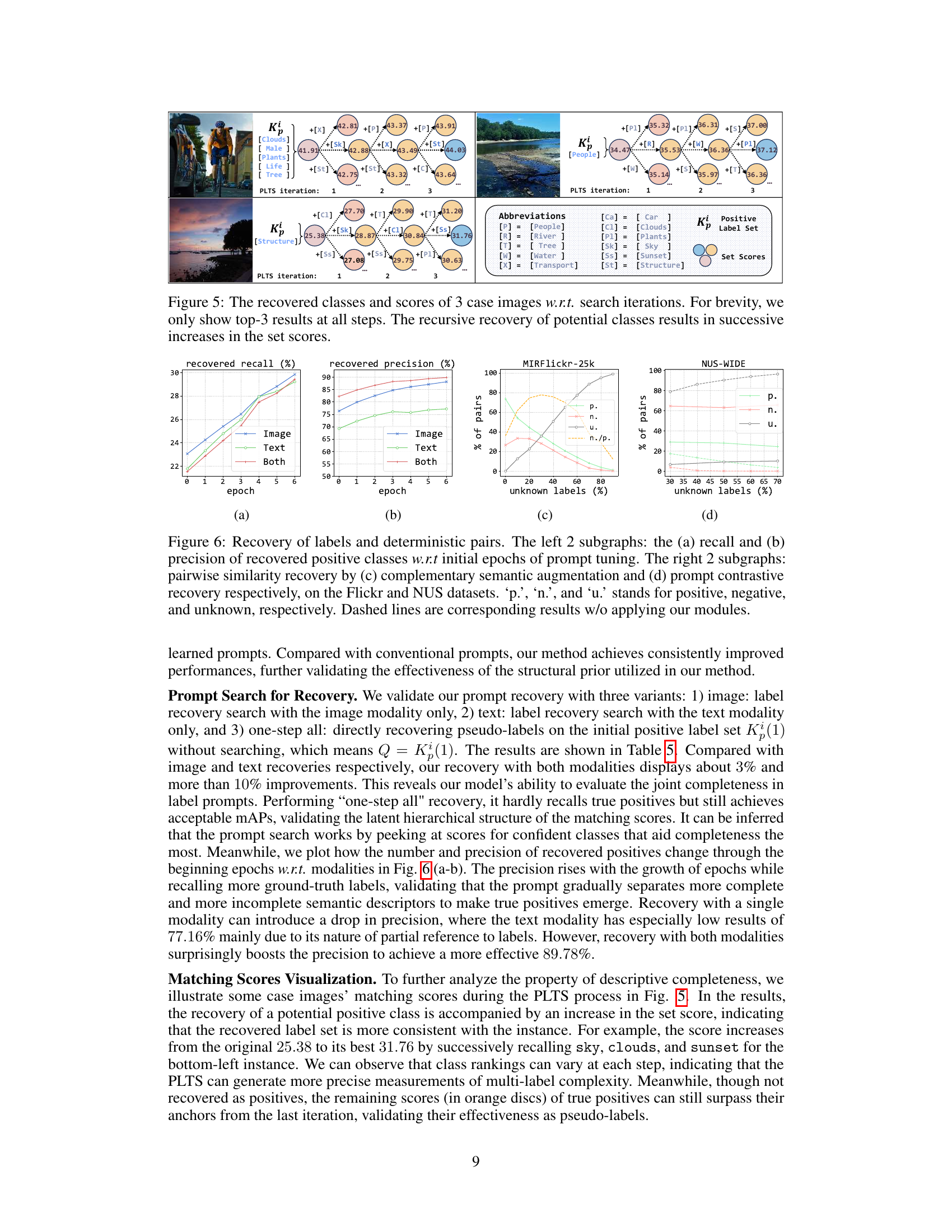
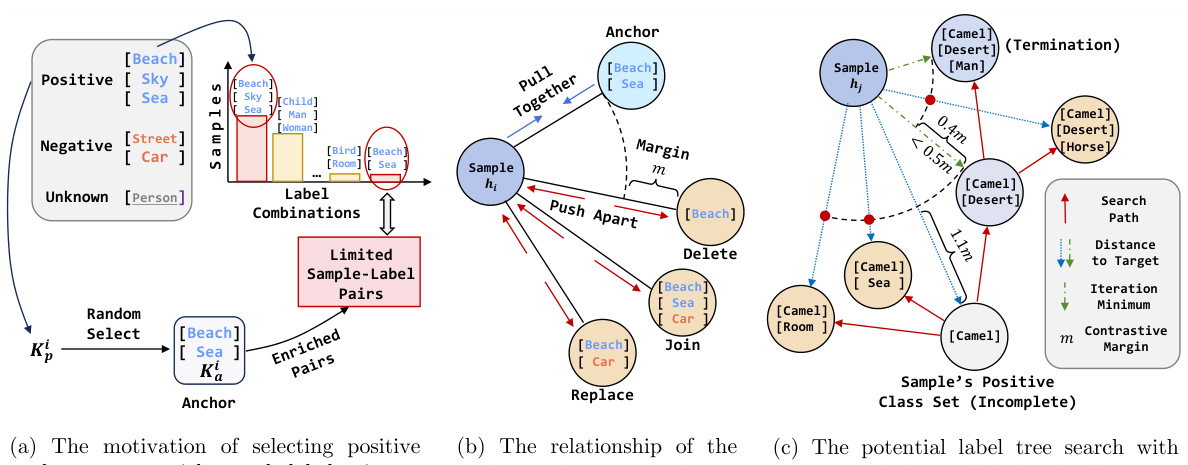
This figure illustrates the Potential Label Tree Search (PLTS) algorithm used in the PCRIL framework. It shows a greedy search process for identifying potential positive labels from an unknown set. The algorithm starts with an initial set of known positive labels (Kp(1)) and iteratively adds unknown labels (cu) that maximize the class set score (Φ²(Kp(ω) U {cu})), as represented by the nodes and arrows. The process continues until the score improvement falls below a threshold. The color-coding helps distinguish between known positives (yellow-gold), unknown labels being considered (green), and rejected unknown labels (red). Each node represents a subset of labels, and the arrows represent the iterative addition or rejection of unknown labels during the search process.
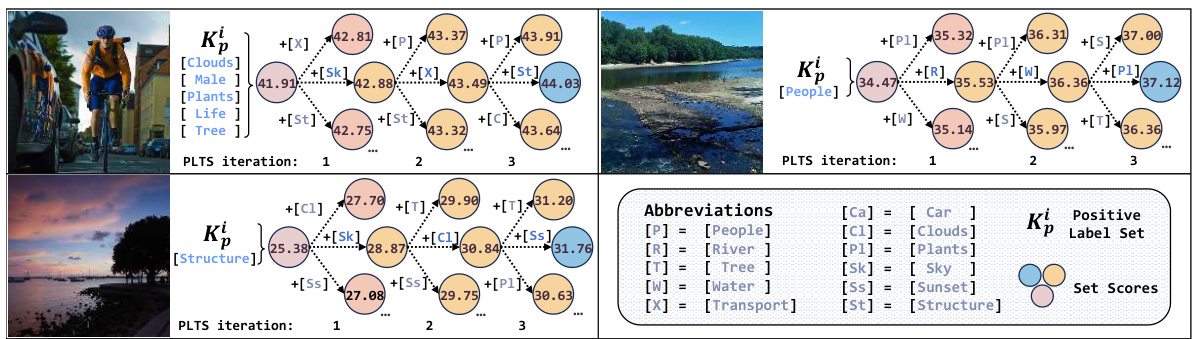
This figure visualizes the prompt contrastive recovery process using three example images. Each image shows the initial positive label set (Kp) and the scores obtained for potential labels at different iterations of the potential label tree search (PLTS) algorithm. The visualization demonstrates that the PLTS algorithm iteratively identifies and adds promising positive classes to the Kp, resulting in an increase in the overall set score with each iteration. This illustrates the algorithm’s ability to progressively refine its understanding of the relevant labels for each image, leading to improved label recovery.

This figure demonstrates the effectiveness of the proposed methods in recovering labels and pairwise similarities. The left two subplots show the recall and precision of recovered positive classes over training epochs, highlighting the improvement achieved by the prompt tuning process. The right two subplots illustrate the recovery of pairwise similarities using complementary semantic augmentation and prompt contrastive recovery, respectively, for both the MIRFlickr-25K and NUS-WIDE datasets. The plots clearly show how the proposed methods address the scarcity of negative pairs, especially when there is a high proportion of unknown labels. The dashed lines represent the baseline performance without the proposed methods.
This figure illustrates the PCRIL framework, which is composed of two main stages: prompt contrastive recovery and augmented pairwise similarity learning. The first stage uses label prompts to identify promising positive classes and to learn contrastive matching scores between the anchor set and negative variants. A tree search process is then employed to recover potential labels. The second stage addresses issues of significant unknown labels and lack of negative pairs using complementary sampling and adaptive negative masking. This figure shows a diagram that presents the overall workflow of the PCRIL method, illustrating its two major stages and sub-components.

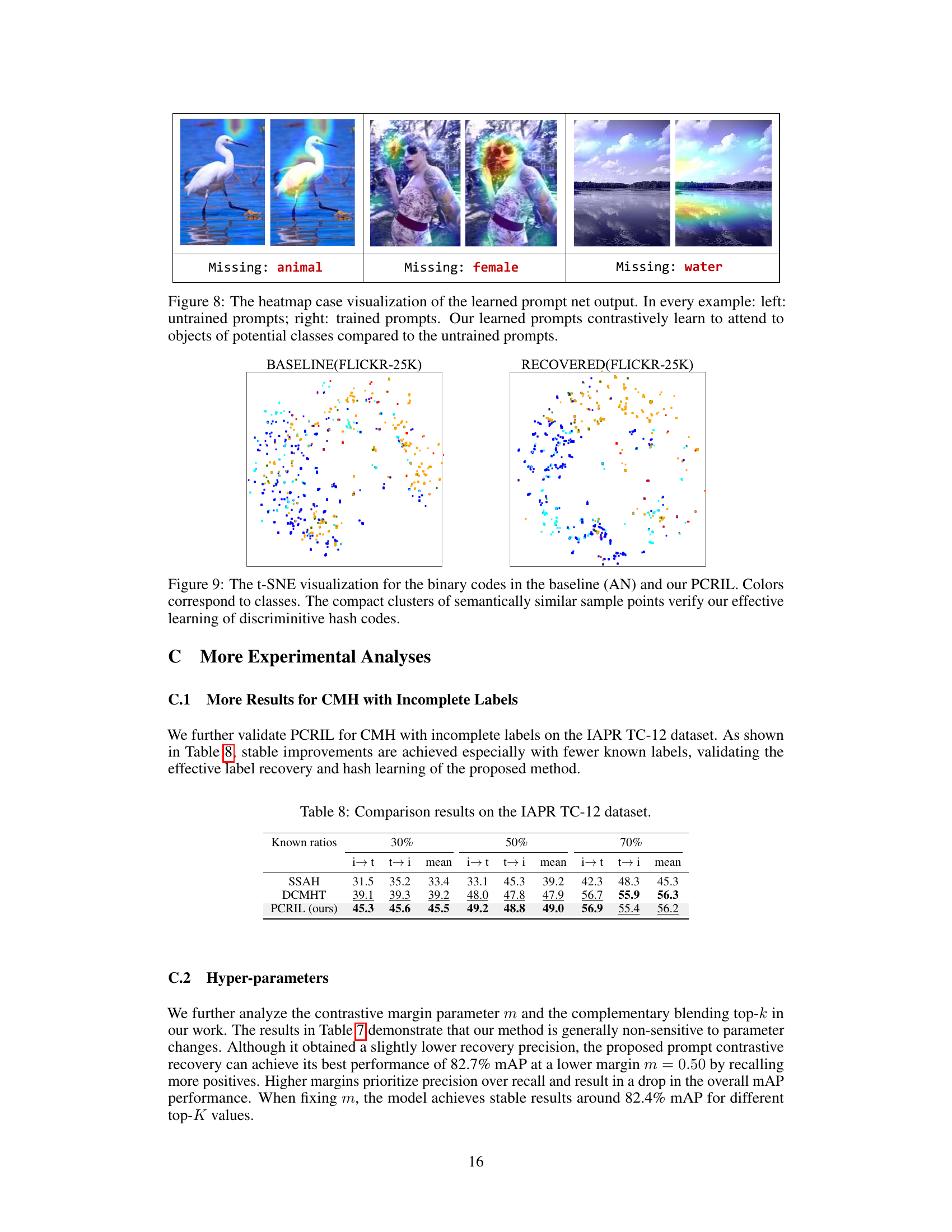
This figure shows three examples of heatmap visualizations that compare the attention mechanisms of untrained versus trained prompt networks. Each example focuses on a different missing label (animal, female, water). The leftmost image in each set shows the attention map produced by an untrained network; the rightmost image shows the attention map produced after training. The heatmaps highlight which parts of the image the network focuses on when generating its outputs. The trained network is shown to focus more strongly on the parts of the image related to the missing labels, suggesting it has successfully learned to attend to objects of potential classes.
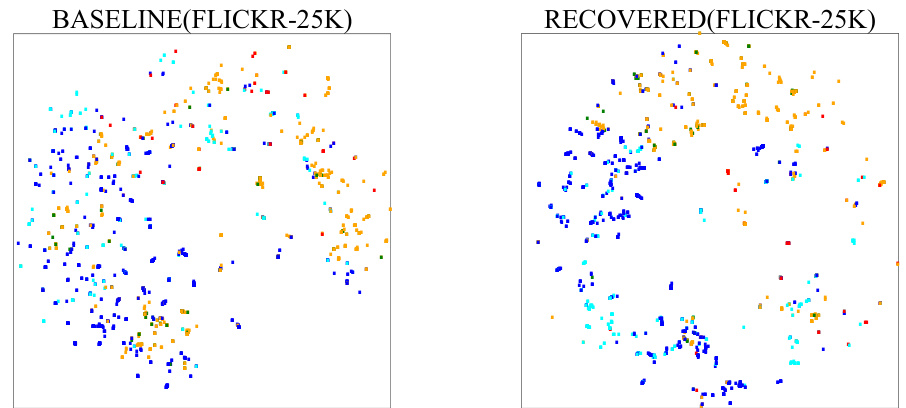
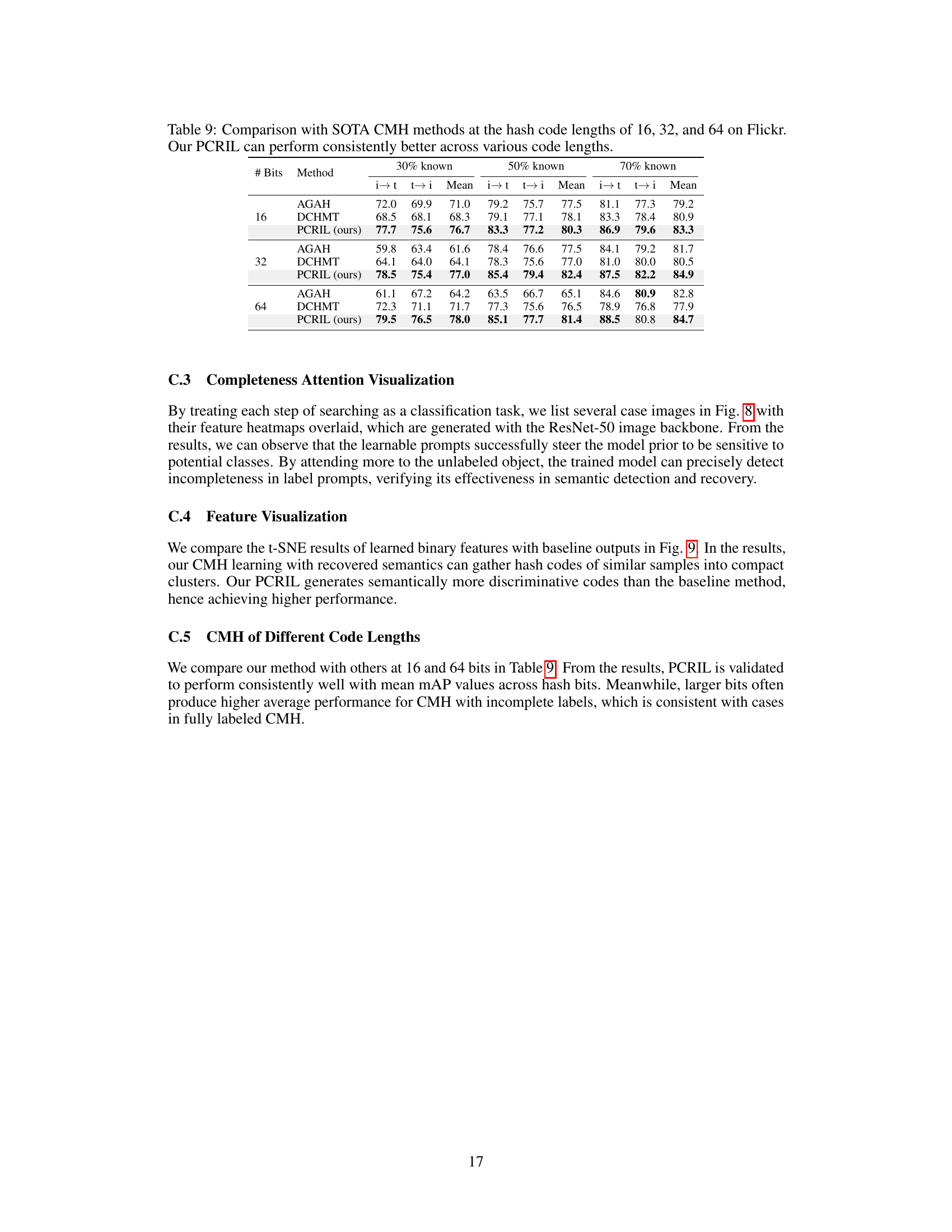
This figure compares the t-distributed Stochastic Neighbor Embedding (t-SNE) visualizations of the binary hash codes generated by the baseline method (AN, which uses the assumption that all unknown labels are negative) and the proposed PCRIL method. Different colors represent different semantic classes. The PCRIL visualization shows tighter, more distinct clusters of points belonging to the same class, indicating that PCRIL learns more discriminative and effective hash codes that better preserve semantic similarities compared to the baseline.
More on tables

This table presents the ablation study results, comparing different components of the proposed PCRIL method. It shows the impact of each component on the overall performance across three datasets: Flickr, NUS, and COCO. The baseline CMH method (B) is compared with variants that incorporate ignoring unobserved pairs (IU), assuming all unknowns as negatives (AN), using adaptive negative masking (ANM), prompt contrastive recovery (PCR), and finally, combining PCR with complementary semantic augmentation (CSA). The results demonstrate the incremental contribution of each component to the final performance.

This ablation study evaluates the contribution of each component of the proposed PCRIL method on three benchmark datasets (Flickr, NUS, and COCO). It compares the baseline CMH method with various combinations of techniques: ignoring unobserved pairs (IU), assuming all unknowns as negative (AN), adaptive negative masking (ANM), prompt contrastive recovery (PCR), and complementary semantic augmentation (CSA). The results show the impact of each component on the overall performance of the system, highlighting their individual contributions to improving cross-modal hashing with incomplete labels.

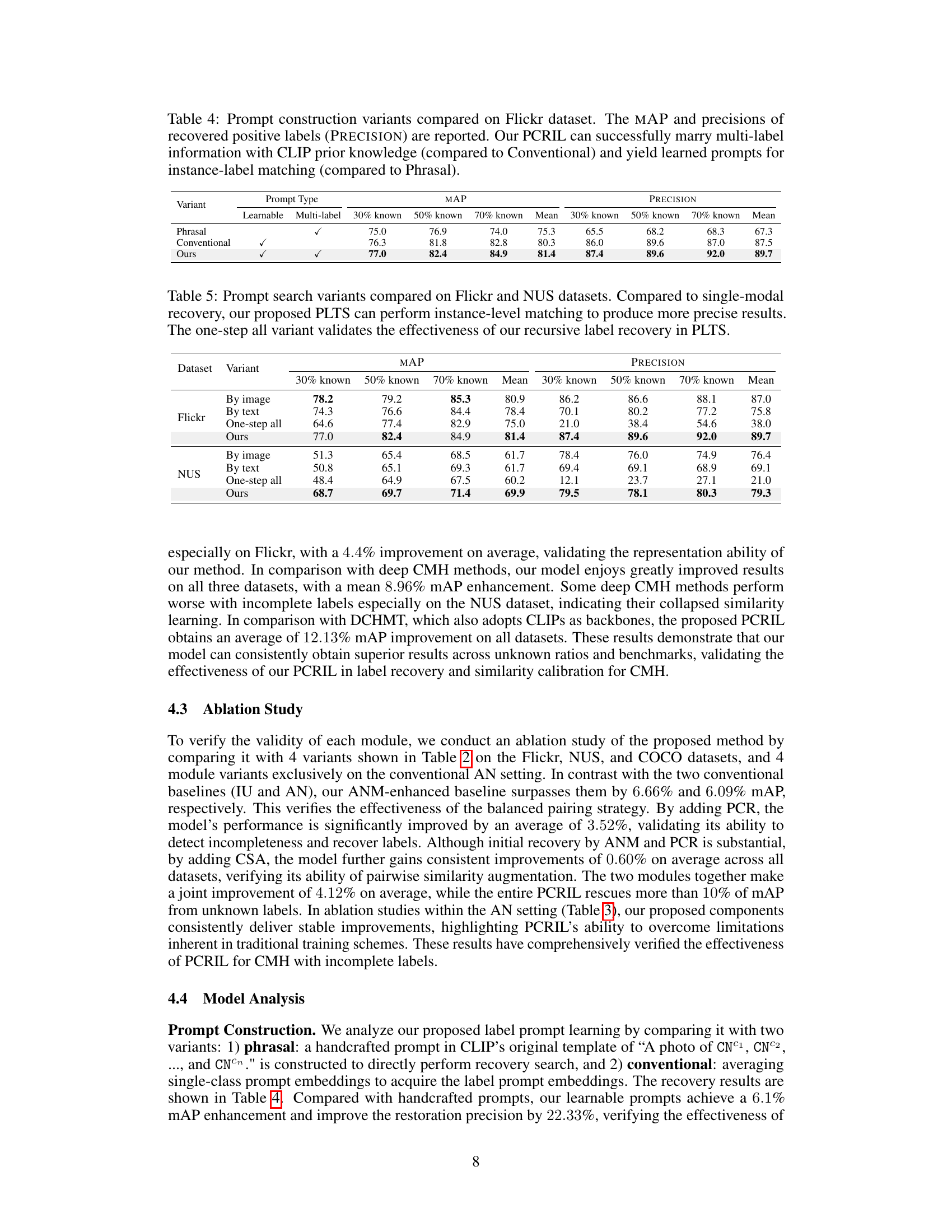
This table compares the performance of three different prompt construction methods on the Flickr dataset in terms of mean average precision (MAP) and precision of recovered positive labels. The methods are: 1) Phrasal (handcrafted prompt), 2) Conventional (averaging single-class prompts), and 3) Ours (learnable multi-label prompt). The results demonstrate that the proposed ‘Ours’ method significantly outperforms the other two methods, indicating its effectiveness in leveraging CLIP’s prior knowledge and learning instance-specific prompts for improved label recovery. The table also shows precision results for each method at three different known label ratios (30%, 50%, 70%), highlighting the consistent improvement provided by the ‘Ours’ method across various data conditions.
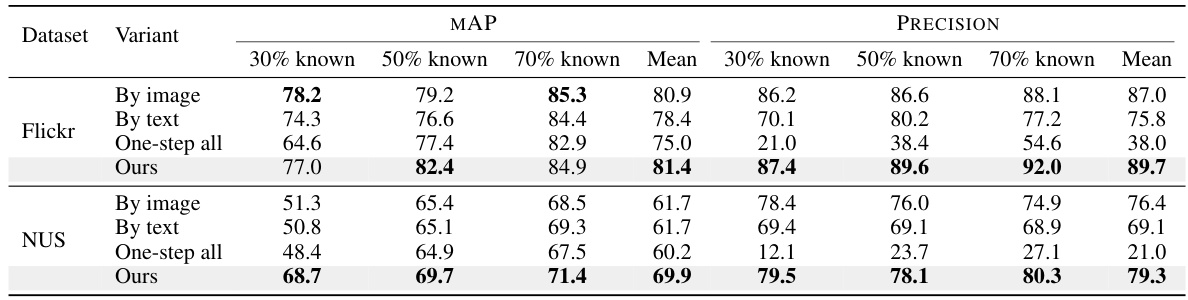
This table presents a comparison of different prompt search variants for cross-modal hashing on the Flickr and NUS datasets. The variants are: using only image modality, using only text modality, a one-step approach that doesn’t use the recursive search, and the authors’ proposed approach (PLTS). The table shows the mean average precision (mAP) and precision scores for each variant, broken down by the percentage of known labels (30%, 50%, 70%). The results demonstrate the superior performance of the PLTS method, particularly in achieving higher precision. This highlights the effectiveness of the recursive label recovery strategy in improving the accuracy of cross-modal retrieval.
This table presents a comparison of the mean average precision (mAP) achieved by the proposed PCRIL method and several state-of-the-art cross-modal hashing (CMH) methods on three benchmark datasets (Flickr, NUS-WIDE, and COCO). The comparison is performed under three different scenarios of label completeness (30%, 50%, and 70% known labels). The table highlights the superior performance of PCRIL in recovering efficient similarity learning, even when dealing with significantly incomplete label information.
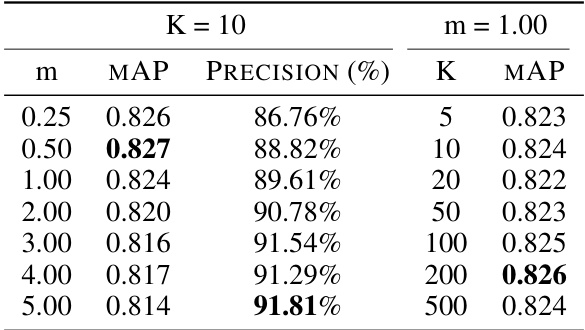
This table shows the impact of two hyperparameters, the number of complementary samples (K) and the margin (m), on the model’s performance, specifically the mean average precision (mAP) and precision, on the Flickr dataset. The results help determine optimal values for these hyperparameters within the prompt contrastive learning and PLTS process.
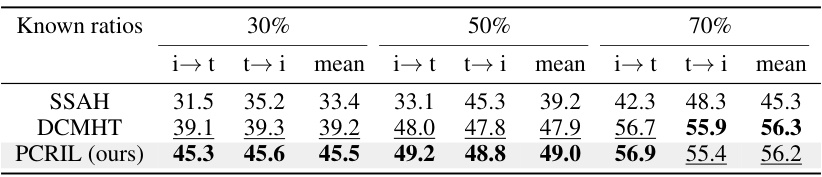
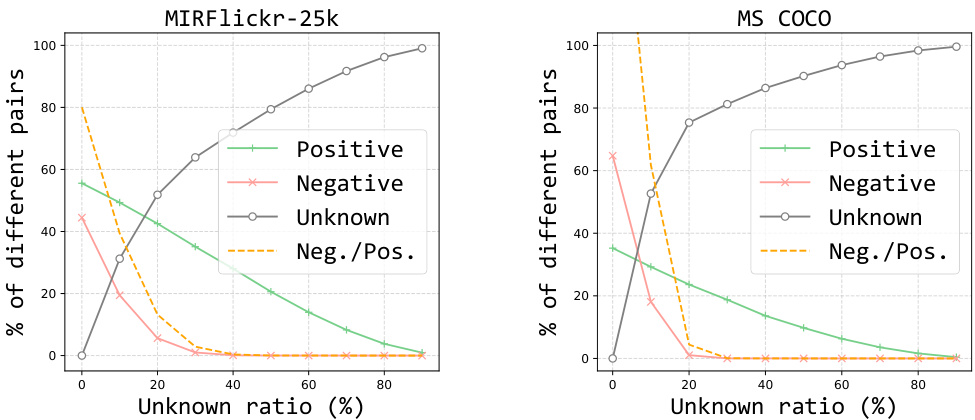
This table shows the comparison results of the proposed PCRIL method with existing methods (SSAH and DCMHT) on the IAPR TC-12 dataset for different known ratios (30%, 50%, 70%). The results are presented as mean average precision (mAP) values for image-to-text (i→t) and text-to-image (t→i) retrieval tasks. It demonstrates the effectiveness of PCRIL in achieving consistent improvements across different known label ratios, particularly when fewer labels are available.
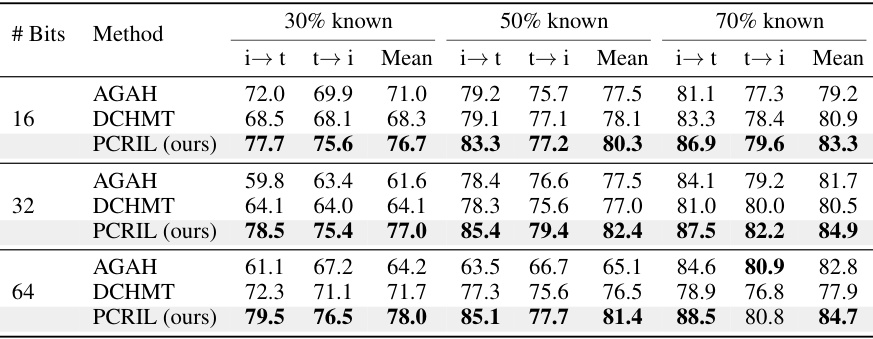
This table presents a comparison of the mean average precision (mAP) achieved by various Cross-modal Hashing (CMH) methods on three benchmark datasets (Flickr, NUS-WIDE, and COCO) across three different levels of label completeness (30%, 50%, and 70% known labels). The results show the performance of the proposed PCRIL method against several state-of-the-art CMH techniques. Performance improvements are highlighted in red, demonstrating the superiority of PCRIL in recovering efficient similarity learning with incomplete labels.
Full paper#