↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Deep learning models are vulnerable to adversarial attacks and membership inference attacks, creating a tension between robustness and privacy. Adversarial training enhances robustness but compromises privacy. Visual prompting, a model reprogramming technique, improves model performance, but its security remains unexplored. This paper investigates the adversarial robustness and privacy of label mapping visual prompting (LM-VP) models.
The study finds that the standard adversarial training approach is ineffective for LM-VP models. Instead, it proposes transferred adversarial training, which achieves a better balance between transferred adversarial robustness and privacy. The research highlights that the choice of pre-trained models significantly influences LM-VP’s white-box adversarial robustness. This work offers a novel perspective on adversarial robustness and privacy, particularly in the context of visual prompting, and provides valuable insights for developing more secure and private AI models.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in AI security and privacy. It challenges existing assumptions about the trade-off between adversarial robustness and privacy in deep learning models, particularly in the novel context of label mapping visual prompting. By introducing the concept of transferred adversarial training, the study opens new avenues for developing more robust and private models.
Visual Insights#
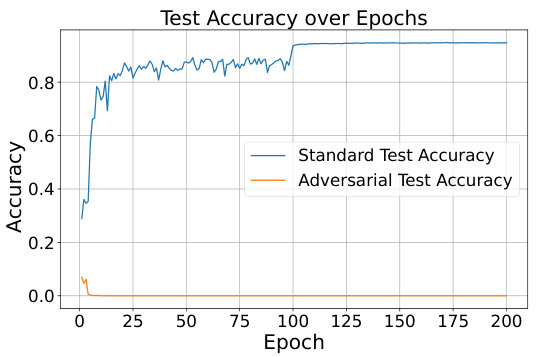
This figure shows the trade-off between adversarial robustness and privacy in standard and adversarial training. The left plots (a and c) depict standard training, demonstrating high standard test accuracy but also a high membership inference attack (MIA) success rate. The right plots (b and d) show adversarial training, which significantly improves adversarial robustness (reducing adversarial test error) but at the cost of increased MIA success rate, highlighting the privacy-robustness trade-off.
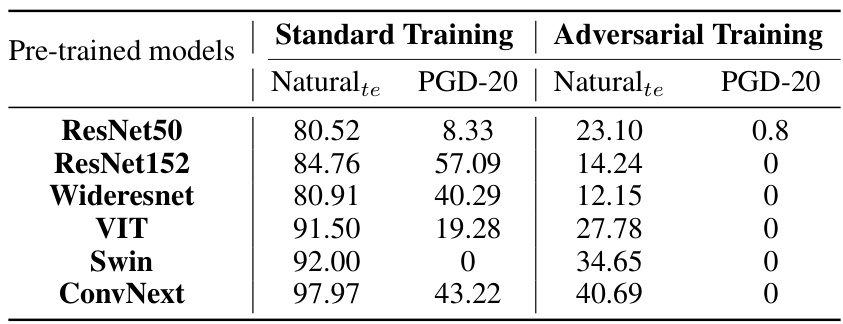
This table presents the performance of LM-VP models trained with different pre-trained models under white-box adversarial attacks. It shows the natural accuracy and accuracy under PGD-20 attacks for both standard training and adversarial training methods. The results highlight how the choice of pre-trained model significantly impacts the adversarial robustness of LM-VP models.
In-depth insights#
LM-VP Security#
LM-VP, a label mapping visual prompting model, presents a unique security challenge. While it leverages pre-trained models for downstream tasks, enhancing efficiency, its security posture is intricately tied to the pre-trained model’s inherent robustness and susceptibility to adversarial attacks and membership inference attacks (MIAs). Standard adversarial training (AT), effective for general models, proves ineffective for LM-VP, highlighting its unique vulnerabilities. The choice of pre-trained model significantly influences the LM-VP model’s white-box adversarial robustness, with no clear pattern emerging across different models. However, transfer AT, which trains against adversarial examples generated by another model, offers a promising approach. This technique demonstrably enhances LM-VP’s transferred adversarial robustness while simultaneously improving its privacy, showcasing a favorable trade-off against the inherent limitations of standard AT. This implies that the LM-VP model’s security needs to be considered in the context of the chosen pre-trained model and a targeted approach like transfer AT.
Transfer AT#
The concept of “Transfer Adversarial Training” (Transfer AT) in the context of LM-VP models presents a novel approach to enhancing adversarial robustness. Instead of training the LM-VP model directly on adversarial examples generated from the same model, Transfer AT leverages a separate, pre-trained model to generate adversarial samples. This method is particularly valuable because it addresses the limitations of standard adversarial training within the LM-VP framework. Standard AT often proves ineffective for LM-VP, as the process of generating adversarial examples relies on the pre-trained model, leading to a domain shift that negatively impacts performance. Transfer AT circumvents this by using a different model for generating adversarial samples, thus better mimicking real-world attacks and transferring learned robustness to the LM-VP model. The results consistently demonstrate that Transfer AT achieves a superior trade-off between transferred adversarial robustness and privacy compared to standard AT. The approach offers a robust and efficient way to improve the security of LM-VP models in various applications, emphasizing its practical implications for real-world deployment. This technique highlights the significance of considering the transferability of adversarial robustness, moving beyond the constraints of within-model adversarial training.
Privacy Tradeoffs#
The concept of ‘privacy tradeoffs’ in the context of machine learning models, particularly deep learning models, is a critical area of research. Improved adversarial robustness, often achieved through techniques like adversarial training (AT), frequently comes at the cost of reduced privacy. AT enhances a model’s resistance to adversarial attacks by incorporating adversarial examples into the training process. However, this very process makes the model more susceptible to membership inference attacks (MIAs), which can reveal sensitive information about the training data. This inherent tension arises because AT often leads to overfitting on adversarial examples, increasing the model’s reliance on specific training data points, thus making it more vulnerable to MIAs. Therefore, researchers must carefully consider the balance between security and privacy when employing techniques like AT. Finding methods that enhance robustness without significantly compromising privacy is a key challenge in the field. This necessitates innovative approaches that go beyond traditional adversarial training and explore more privacy-preserving mechanisms for strengthening the security of machine learning systems.
Pre-trained Impact#
The choice of pre-trained models significantly impacts the performance of Label Mapping Visual Prompting (LM-VP) models. Pre-trained models’ inherent adversarial robustness heavily influences the white-box adversarial robustness of LM-VP, meaning that a robust pre-trained model leads to a more robust LM-VP model, while a less robust pre-trained model results in a weaker LM-VP model. This highlights the crucial role of the pre-trained model selection process in achieving desired robustness. Standard adversarial training is shown to be ineffective in improving the adversarial robustness of LM-VP models and may even degrade their performance, emphasizing the limitations of applying standard adversarial training techniques to this novel model architecture. In contrast, transfer adversarial training demonstrates a superior trade-off between transferred adversarial robustness and privacy, consistently across various pre-trained models, showcasing its effectiveness as a suitable approach for enhancing the security of LM-VP models.
Future Work#
Future research directions stemming from this work could focus on several key areas. First, a deeper investigation into the interplay between pre-trained model architecture and LM-VP model robustness and privacy is warranted. The study reveals a strong influence of pre-trained models, suggesting the need for a more nuanced understanding of this interaction. Second, developing more robust and efficient label mapping techniques is crucial. While the current method shows promise, exploring alternative methods that could improve efficiency and performance would significantly enhance the LM-VP framework. Third, the exploration of different adversarial training techniques beyond standard and transfer AT is essential to further improve the adversarial robustness and privacy trade-off. Investigating alternative attack methods and defense strategies could reveal additional insights. Fourth, expanding the evaluation to a wider range of datasets and vision tasks is needed to verify the generalizability of the LM-VP model’s properties. Finally, thorough theoretical analysis is needed to provide deeper insights and improve the interpretability of the LM-VP framework. This could involve developing new theoretical frameworks or adapting existing ones to better understand and explain the observed phenomena.
More visual insights#
More on figures
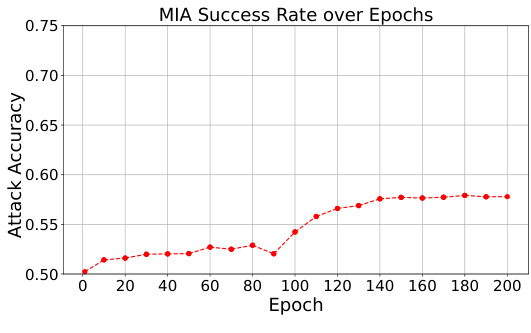
This figure shows the trade-off between adversarial robustness and privacy in standard and adversarial training. The left panels (a and c) illustrate standard training, while the right panels (b and d) show adversarial training. The top panels (a and b) display test accuracy (both standard and adversarial) against the number of training epochs. The bottom panels (c and d) show the membership inference attack (MIA) success rate over epochs. Adversarial training significantly improves adversarial robustness but increases susceptibility to MIA, particularly after a point called ‘robust overfitting’ where adversarial robustness decreases despite natural accuracy increasing.
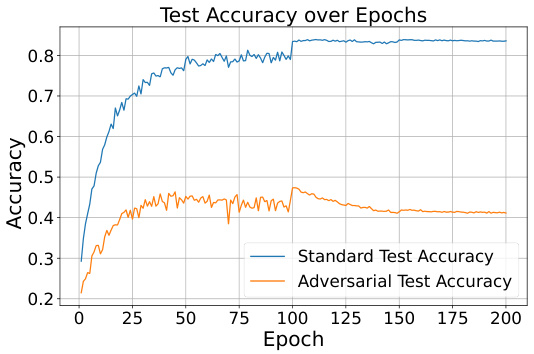
This figure illustrates the trade-off between adversarial robustness and privacy in standard and adversarial training. The left two subfigures show the test accuracy over epochs for standard and adversarial training. The right two subfigures show the membership inference attack (MIA) success rate over epochs for standard and adversarial training. The results demonstrate that adversarial training significantly improves adversarial robustness but increases susceptibility to MIAs, particularly after robust overfitting (around 100-150 epochs).

This figure illustrates the trade-off between adversarial robustness and privacy in standard and adversarial training. The left two subfigures show test accuracy over epochs for both standard and adversarial training. The right two subfigures display the membership inference attack (MIA) success rate over epochs for both methods. It highlights that while adversarial training improves adversarial robustness (as measured by test accuracy against adversarial examples), it also significantly increases vulnerability to MIA, especially after a period of robust overfitting, showing that there is a trade-off between these two aspects of model security and privacy.

This figure illustrates two different methods for adding prompts to images in the label mapping visual prompting (LM-VP) model. The top example shows a target image rescaled to match the source domain size, with prompts replacing the edges. The bottom example demonstrates rescaling the target image to a smaller size than the source domain, then adding prompts to reach the source domain’s dimensions. This highlights the difference in preserving edge information between the two approaches.

This figure displays the performance of LM-VP models (using Swin Transformer as the pre-trained model) trained on different subsets of the CIFAR-10 dataset. The x-axis represents the number of training epochs, while the y-axis shows the accuracy. Separate lines represent standard test accuracy and adversarial test accuracy. Four plots show the results for training on subsets of 100, 1000, 10000 samples, and the whole dataset, respectively. The figure demonstrates how different training dataset sizes affect model performance and robustness against adversarial attacks.

This figure demonstrates the trade-off between adversarial robustness and privacy in standard and adversarial training. The left plot shows test accuracy over epochs for standard and adversarial training, illustrating improved adversarial accuracy with adversarial training. The right plot displays the membership inference attack (MIA) success rate, showing that models trained with adversarial training are more vulnerable to MIA attacks, particularly after a point of robust overfitting. This highlights a negative correlation between adversarial robustness and privacy in standard deep learning models.
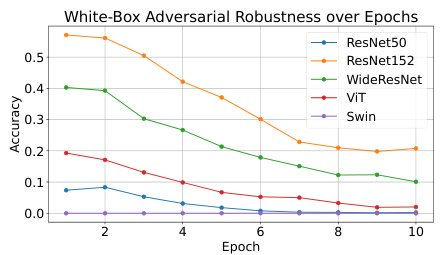
This figure shows the white-box adversarial robustness of LM-VP models over training epochs for different pre-trained models (ResNet50, ResNet152, WideResNet, ViT, Swin). It demonstrates that the adversarial robustness is highest in the early stages and decreases as training progresses. The performance varies significantly across different pre-trained models.

This figure compares the performance of two different rescale ratios (192x192 and 224x224) used in the prompt generation stage of the LM-VP model. The results show the natural accuracy and adversarial accuracy for each ratio. The pre-trained model used in this experiment was Swin Transformer. The comparison highlights the impact of the rescale ratio on model performance, showing that while a larger rescale ratio may improve performance, an excessively large ratio might lead to overfitting to the target domain.
More on tables

This table presents the best performance achieved by LM-VP models trained using standard training on the CIFAR-10 dataset. It shows the natural accuracy and adversarial robustness against various attacks (PGD-10, PGD-20, CW-20) using different pre-trained models (ResNet50, ResNet152, WRN-50-2, ViT, Swin, ConvNext, EVA) and threat models (ResNet18, WRN-34-10). The results highlight the impact of the choice of pre-trained models on the performance of LM-VP models under both standard and adversarial settings.
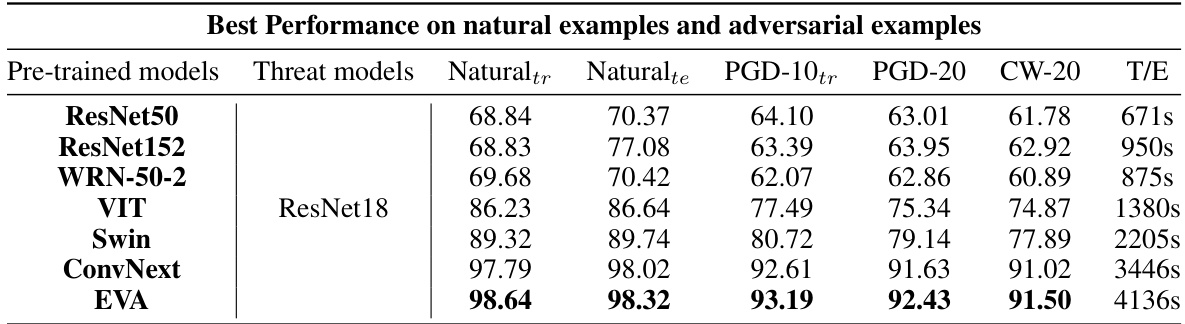
This table presents the performance of LM-VP models trained with Transferred Adversarial Training (Transfered AT) on the CIFAR-10 dataset. The performance is evaluated using different pre-trained models (ResNet50, ResNet152, WRN-50-2, ViT, Swin, ConvNext, EVA) and the ResNet18 model as the threat model. The metrics used for evaluation include natural accuracy (Naturaltr, Naturalte), and adversarial robustness against PGD-10, PGD-20, and CW-20 attacks. The training time (T/E) for each model is also reported.
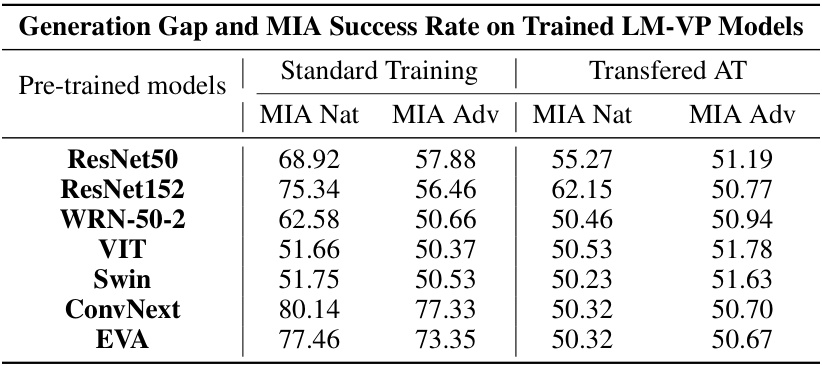
This table presents the Membership Inference Attack (MIA) success rates for various pre-trained models under two training scenarios: standard training and transferred adversarial training. The MIA success rate is given for both natural images and adversarial examples, showing the impact of different pre-trained models and training methods on the privacy of the training data. Lower MIA success rates indicate better privacy protection.
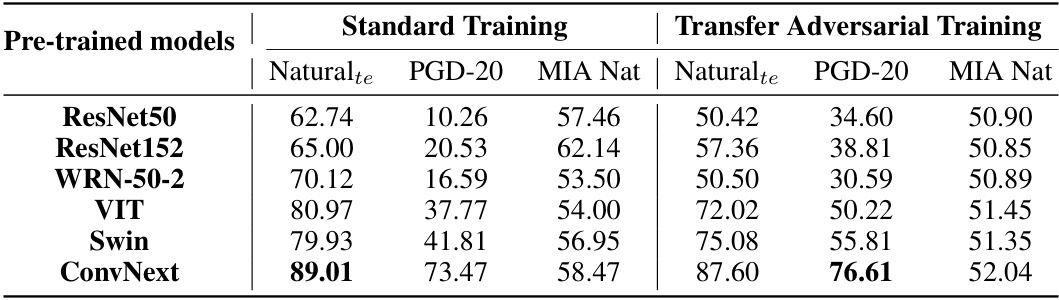
This table presents the performance of LM-VP models on the Tiny-ImageNet dataset using both standard training and transfer adversarial training. It shows the natural accuracy, performance under PGD-20 attacks, and the MIA success rate for various pre-trained models. The results highlight the trade-off between natural accuracy and adversarial robustness, and the impact of transfer adversarial training on these metrics and privacy.

This table shows the performance of LM-VP models with ResNet50 and ConvNext pretrained models under standard training and transfer adversarial training on CIFAR-10. The performance metrics include natural accuracy, PGD-20 adversarial robustness, and MIA natural success rate. The perturbation limit (epsilon) is set to 4/255. The results demonstrate the trade-off between natural accuracy, adversarial robustness, and privacy (measured by MIA success rate) for different training methods and models.
Full paper#



















