TL;DR#
The sheer volume of research publications, particularly in fast-paced fields like AI, makes writing comprehensive literature surveys extremely challenging. Traditional methods are time-consuming and resource-intensive, often lagging behind the rapid evolution of knowledge. This is a critical problem as surveys are essential for knowledge synthesis, trend identification, and guiding future research directions.
AutoSurvey offers a novel methodology that leverages the power of Large Language Models (LLMs) to automatically generate comprehensive literature surveys. This addresses the challenges of context window limitations, parametric knowledge constraints, and the lack of evaluation benchmarks in existing LLM-based approaches. The system incorporates a multi-stage process, including initial retrieval and outline generation, subsection drafting using specialized LLMs, integration and refinement, and rigorous evaluation. This results in a significantly faster, more efficient, and reliable process for generating high-quality surveys, enabling researchers to stay abreast of rapidly evolving research fields.
Key Takeaways#
Why does it matter?#
This paper is crucial for AI researchers due to the rapid growth of research in LLMs. It provides a practical solution to creating comprehensive literature surveys, a time-consuming task previously done manually. This offers significant efficiency gains, enabling researchers to stay updated and accelerates progress. The methodology is adaptable and the proposed evaluation method is robust, paving the way for more reliable survey generation across various fields.
Visual Insights#
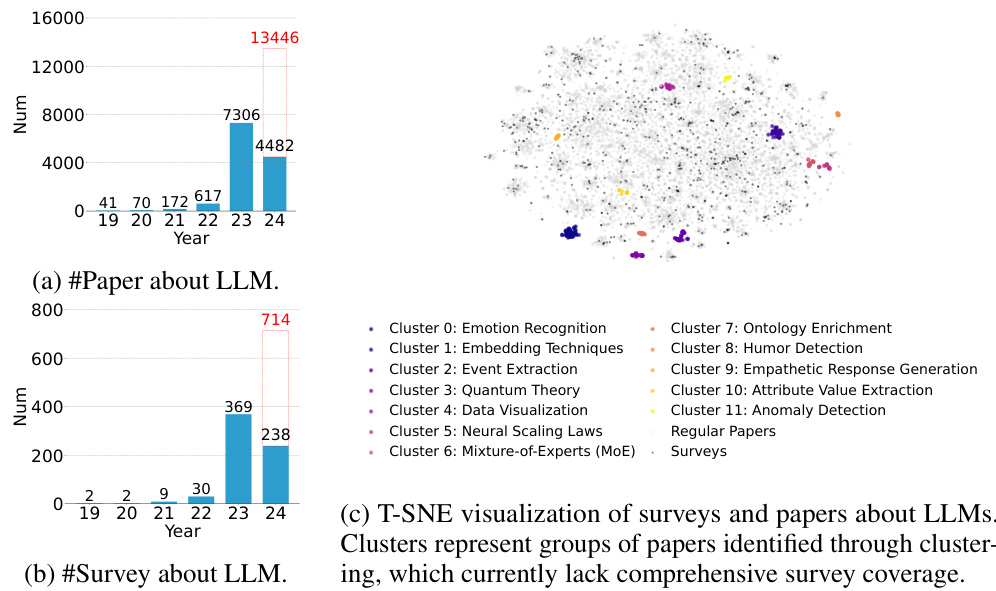
🔼 This figure shows the growth trend of research papers and surveys related to LLMs from 2019 to 2024. Subfigure (a) displays the sharp increase in the number of LLM-related papers over time. Subfigure (b) shows a similar, but less dramatic, increase in the number of LLM-related surveys. Subfigure (c) is a t-SNE visualization that clusters related papers, highlighting areas where comprehensive surveys are currently lacking, despite the overall increase in the number of surveys. The figure uses this data to demonstrate the need for AutoSurvey, highlighting the cost and time savings it offers.
read the caption
Figure 1: Depicting growth trends from 2019 to 2024 in the number of LLMs-related papers (a) and surveys (b) on arXiv, accompanied by a T-SNE visualization. The data for 2024 is up to April, with a red bar representing the forecasted numbers for the entire year. While the number of surveys is increasing rapidly, the visualization reveals areas where comprehensive surveys are still lacking, despite the overall growth in survey numbers. The research topics of the clusters in the T-SNE plot are generated using GPT-4 to describe their primary focus areas. These clusters of research voids can be addressed using AutoSurvey at a cost of $1.2 (cost analysis in Appendix D) and 3 minutes per survey. An example survey focused on Emotion Recognition using LLMs is in Appendix F.

🔼 This table presents a comparison of the performance of three different methods for generating surveys: Naive RAG, human writing, and AutoSurvey. The comparison is made across four different survey lengths (8k, 16k, 32k, and 64k tokens) and includes metrics for citation quality (recall and precision), content quality (coverage, structure, and relevance), and speed. Claude-haiku was used as the LLM writer for both Naive RAG and AutoSurvey. Notably, human-written surveys used for evaluation were excluded from the retrieval process when generating the results for Naive RAG and AutoSurvey.
read the caption
Table 2: Results of Naive RAG, Human writing and AutoSurvey. Both of AutoSurvey and Naive RAG use Claude-haiku as the writer. Note that human writing surveys used for evaluation are excluded during the retrieval process.
In-depth insights#
AutoSurvey: LLM Surveys#
AutoSurvey leverages LLMs to automate the creation of comprehensive literature surveys, addressing the challenges of information overload in rapidly evolving fields like AI. Its methodology systematically progresses through several phases: initial retrieval and outline generation, subsection drafting using specialized LLMs, integration and refinement, and rigorous evaluation and iteration. A key innovation is the parallel generation of subsections, significantly accelerating the survey writing process. AutoSurvey also incorporates a real-time knowledge update mechanism to ensure the survey reflects the most current research. Evaluation is crucial, using a multi-LLM-as-judge approach combined with human expert assessment for reliability and adherence to academic standards. Experimental results show AutoSurvey surpasses traditional methods in speed while achieving near-human-level quality, highlighting its potential as a valuable tool for researchers.
LLM Survey Pipeline#
An LLM survey pipeline would systematically automate the creation of literature reviews. It would likely begin with initial retrieval, gathering relevant papers via advanced search techniques. Outline generation would follow, structuring the review using LLMs to identify key themes and subtopics. The pipeline’s core would be parallel subsection drafting, where specialized LLMs simultaneously generate text for each section, ensuring efficiency and consistency. A crucial step would be integration and refinement, leveraging LLMs to polish the text, ensuring coherence, and removing redundancies. Finally, rigorous evaluation with multiple LLMs would assess quality and identify areas needing revision, leading to an iterative refinement process. Real-time knowledge updates are also essential, ensuring the survey reflects the most current research. The entire pipeline aims to drastically speed up the survey creation process while maintaining high standards of academic quality.
Multi-LLM Evaluation#
A multi-LLM evaluation strategy offers a robust and reliable approach to assessing the quality of automatically generated content, especially for complex tasks like creating comprehensive literature surveys. By leveraging multiple LLMs as evaluators, the approach mitigates individual LLM biases and limitations, producing more consistent and objective results. The use of multiple LLMs for evaluation is crucial because different LLMs have distinct strengths and weaknesses. Combining their judgments provides a more holistic and nuanced evaluation, effectively accounting for diverse aspects of the generated text. This approach goes beyond simplistic metrics and considers qualitative aspects, such as coherence, accuracy, and relevance, ensuring a comprehensive assessment. The resulting evaluation scores are more reliable and less susceptible to individual LLM idiosyncrasies. This method significantly contributes to the validation of LLM-based systems, providing a crucial element for establishing confidence in the quality and reliability of their output. The use of human experts to refine the evaluation metrics further improves the precision and alignment with academic standards, bolstering the trustworthiness and credibility of the results. Such a multi-faceted approach can pave the way for a new standard of quality control in automated text generation, especially in academic writing where accuracy and consistency are paramount.
AutoSurvey Limitations#
AutoSurvey, while innovative, faces limitations primarily in citation accuracy. Manual analysis reveals significant errors categorized as misalignment (incorrect connections between claims and sources), misinterpretation (inaccurate representation of source information), and overgeneralization (extending source conclusions beyond their scope). Overgeneralization is the most prevalent issue, suggesting reliance on inherent model knowledge rather than thorough source understanding. This highlights a challenge in ensuring factual accuracy, crucial for academic surveys. While AutoSurvey utilizes multiple LLMs for evaluation, addressing these issues requires further improvements, potentially involving enhanced source analysis and fact-checking mechanisms. The reliance on LLMs also introduces limitations regarding the scalability and cost of generating longer surveys, and the need for human oversight to guarantee quality remains, partially offsetting the claimed automation benefits. These shortcomings impact the overall reliability of AutoSurvey despite its speed and efficiency.
Future Survey Research#
Future survey research will likely be characterized by a stronger emphasis on automation and efficiency, leveraging advancements in large language models (LLMs) and natural language processing (NLP) to streamline the survey creation and analysis process. Real-time knowledge updates integrated into survey methodologies will become increasingly important, ensuring that surveys reflect the most current research. Multi-modal data integration will also be a key focus, incorporating diverse data sources beyond textual information to provide a richer, more nuanced understanding. However, ethical considerations and addressing the limitations of LLMs, such as bias and hallucination, will be crucial. Future research should focus on robust evaluation methods and developing strategies to improve the quality and reliability of automated surveys while upholding academic rigor. The development of innovative solutions to the challenges presented by massive datasets and rapid information growth is vital for the future of effective survey research.
More visual insights#
More on figures
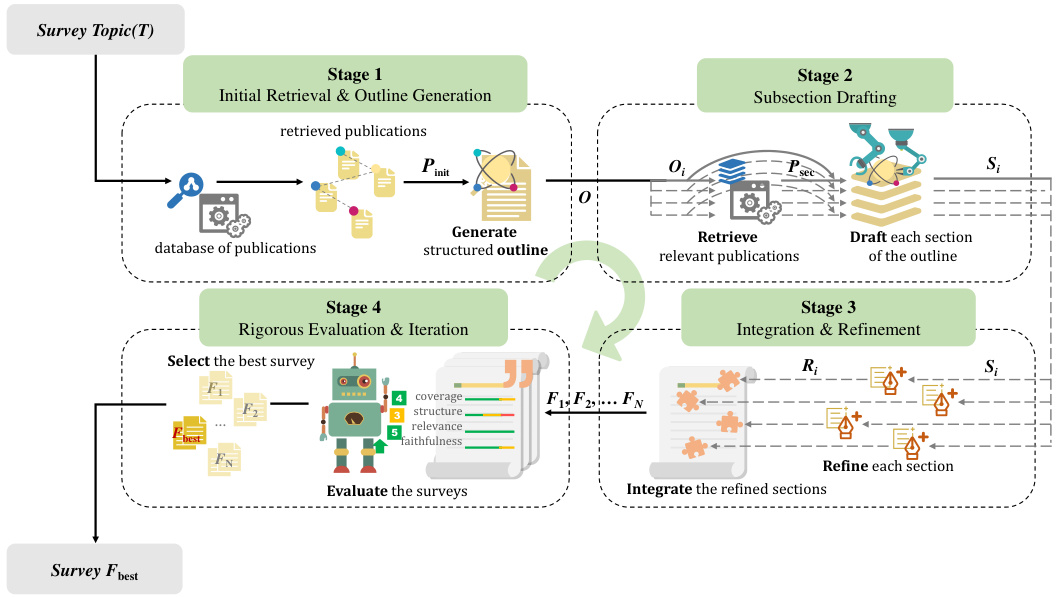
🔼 This figure illustrates the four-stage pipeline of AutoSurvey. Stage 1 involves initial retrieval and outline generation, using a database of publications to generate a structured outline. Stage 2 is subsection drafting, where specialized LLMs draft each section of the outline based on relevant publications. Stage 3 integrates and refines the drafted subsections. Finally, Stage 4 involves rigorous evaluation and iteration to select the best survey. The pipeline highlights the parallel processing of different components and the iterative evaluation steps to ensure the quality of the generated survey.
read the caption
Figure 2: The AutoSurvey Pipeline for Generating Comprehensive Surveys.
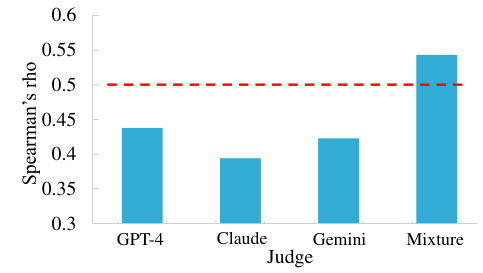
🔼 This figure shows the correlation between the rankings of surveys produced by LLMs and those given by human experts. The Spearman’s rho correlation coefficient is used to measure the strength of the monotonic relationship between the two sets of rankings. A higher Spearman’s rho value indicates a stronger correlation. The figure displays the Spearman’s rho value for each LLM (GPT-4, Claude, Gemini) and the mixture of models. The mixture of models shows the highest correlation with the human experts’ ratings (rho = 0.5429).
read the caption
Figure 3: Spearman's rho values indicating the degree of correlation between rankings given by LLMs and human experts. Note that A value over 0.3 indicates a positive correlation and over 0.5 indicates a strong positive correlation.
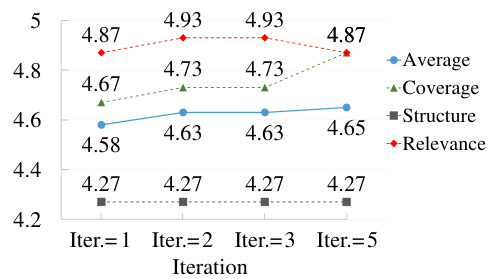
🔼 This figure shows how the number of iterations in the AutoSurvey process affects the quality of the generated surveys. The x-axis represents the number of iterations (1, 2, 3, or 5), while the y-axis shows the average scores for three aspects of the survey quality: overall average score, coverage, and relevance. The scores for ‘Structure’ remain relatively consistent across iterations. The results show that increasing the number of iterations from one to five leads to a slight improvement in overall content quality, with diminishing returns after the second iteration. The figure visually demonstrates the trade-off between the computational cost of additional iterations and the resulting improvement in survey quality.
read the caption
Figure 4: Impact of Iteration on AutoSurvey Performance.

🔼 This figure shows the growth trend of LLM-related papers and surveys from 2019 to 2024. It highlights the rapid increase in the number of papers, outpacing the number of surveys. A t-SNE visualization further illustrates research areas that lack comprehensive survey coverage despite numerous published papers. This emphasizes the need for efficient survey generation methods such as the one proposed in the paper.
read the caption
Figure 1: Depicting growth trends from 2019 to 2024 in the number of LLMs-related papers (a) and surveys (b) on arXiv, accompanied by a T-SNE visualization. The data for 2024 is up to April, with a red bar representing the forecasted numbers for the entire year. While the number of surveys is increasing rapidly, the visualization reveals areas where comprehensive surveys are still lacking, despite the overall growth in survey numbers. The research topics of the clusters in the T-SNE plot are generated using GPT-4 to describe their primary focus areas. These clusters of research voids can be addressed using AutoSurvey at a cost of $1.2 (cost analysis in Appendix D) and 3 minutes per survey. An example survey focused on Emotion Recognition using LLMs is in Appendix F.
More on tables

🔼 This table lists the five-point scoring rubric used to evaluate the content quality of the generated surveys. The scoring criteria are broken down into three sub-indicators: Coverage, Structure, and Relevance, each with a detailed description for each score (1-5).
read the caption
Table 1: Content Quality Criteria.
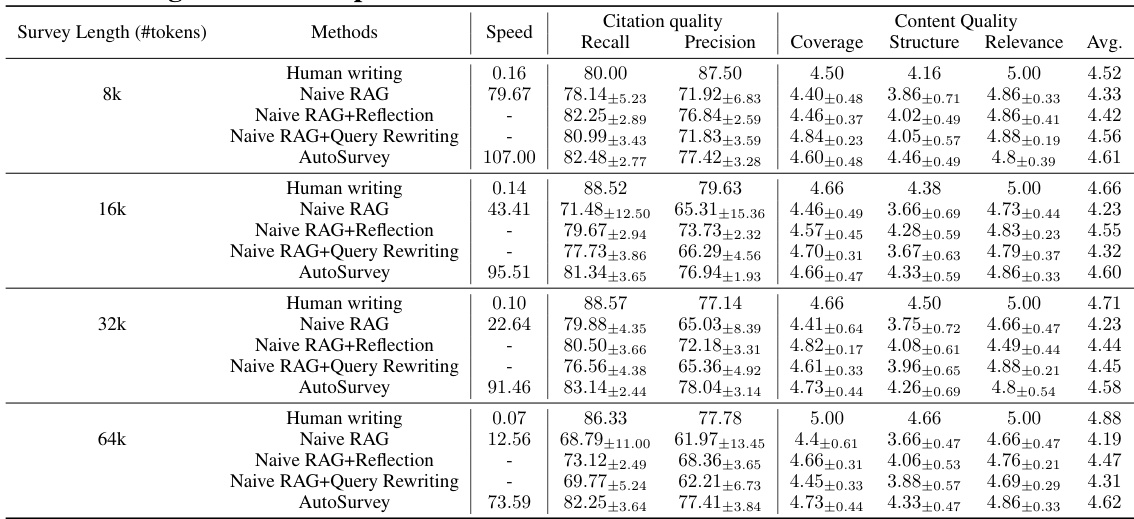
🔼 This table presents the results of an experiment comparing three different methods for generating academic surveys: human writing, a naive RAG approach, and the proposed AutoSurvey method. The table shows performance metrics for each method across four different survey lengths (8k, 16k, 32k, and 64k tokens). The metrics reported include speed, citation quality (recall and precision), and content quality (coverage, structure, relevance, and average). This allows for a comparison of the efficiency, accuracy, and overall quality of the three methods for generating academic surveys.
read the caption
Table 2: Results of Naive RAG, Human writing and AutoSurvey. Both of AutoSurvey and Naive RAG use Claude-haiku as the writer. Note that human writing surveys used for evaluation are excluded during the retrieval process.

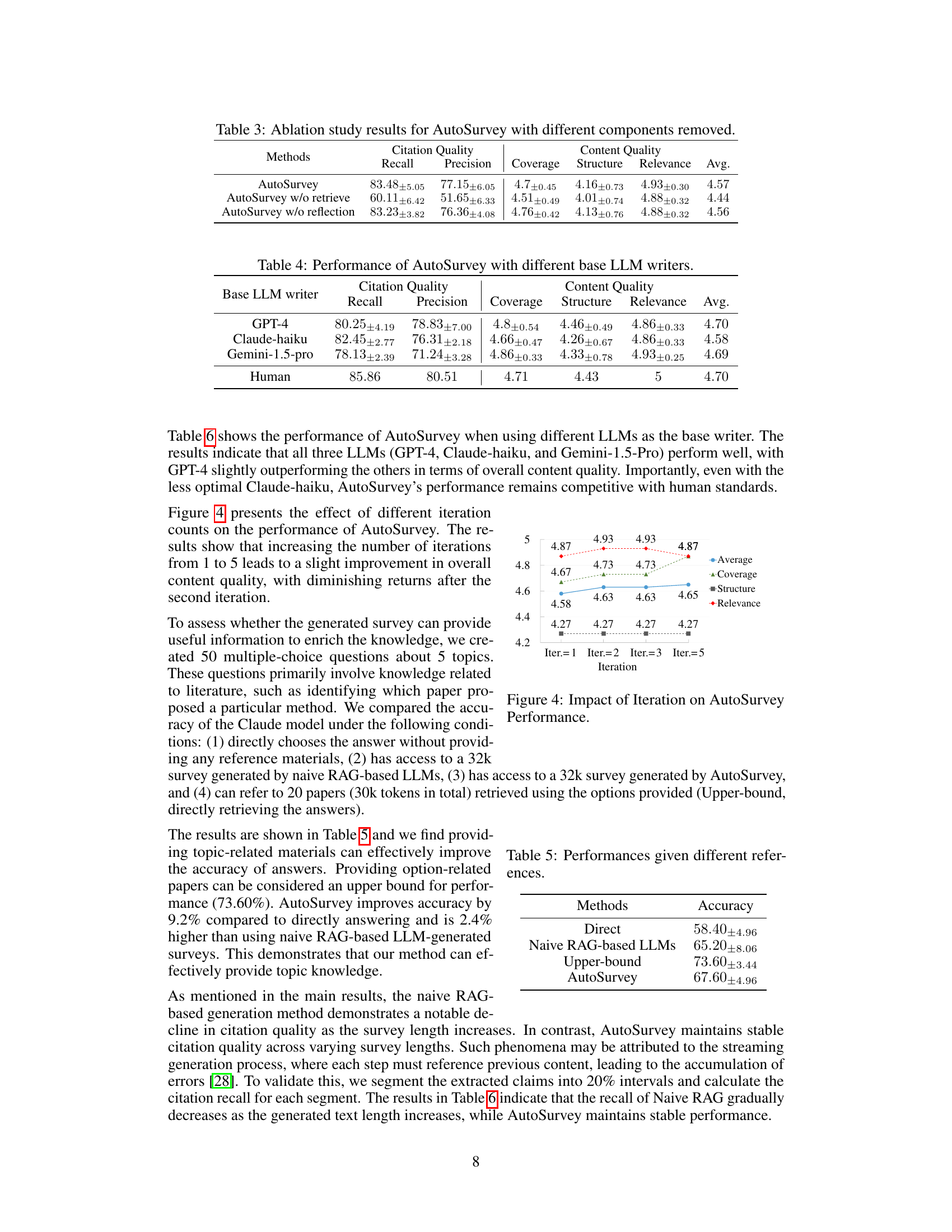
🔼 This table presents the results of an ablation study conducted on the AutoSurvey model. The study systematically removes key components of the model (retrieval mechanism and reflection phase) to assess their individual contributions to the overall performance. The table shows the performance metrics for citation quality (recall and precision) and content quality (coverage, structure, relevance, and average) for each ablation variant compared to the full AutoSurvey model.
read the caption
Table 3: Ablation study results for AutoSurvey with different components removed.
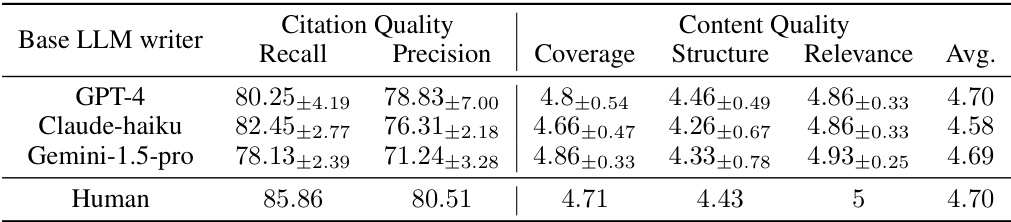
🔼 This table shows the performance of AutoSurvey when using different Large Language Models (LLMs) as the base writer. The results demonstrate the impact of choosing different LLMs on both citation quality (recall and precision) and content quality (coverage, structure, and relevance). The table allows for a comparison of AutoSurvey’s performance using GPT-4, Claude-haiku, and Gemini-1.5-pro, against human-written surveys. The average content quality score is presented to summarize the overall quality achieved by each LLM.
read the caption
Table 4: Performance of AutoSurvey with different base LLM writers.

🔼 This table presents the accuracy results of four different methods in answering multiple-choice questions related to a survey topic. The methods include: 1. Direct: Answering questions without any additional context. 2. Naive RAG-based LLMs: Answering questions with a basic retrieval augmented generation approach, using LLMs. 3. Upper-bound: Answering questions with access to all relevant papers, representing the best possible performance. 4. AutoSurvey: Answering questions using the proposed AutoSurvey methodology. The accuracy is measured as a percentage, with error bars indicating variability. The results demonstrate how AutoSurvey improves accuracy compared to direct answers and a naive RAG-based approach, although not reaching the performance level of the upper-bound (having access to all relevant information).
read the caption
Table 5: Performances given different references.
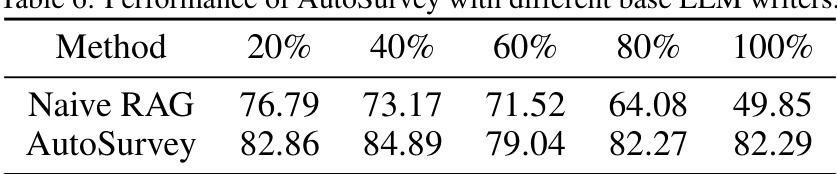
🔼 This table presents the results of an ablation study conducted to evaluate the performance of AutoSurvey when using different Large Language Models (LLMs) as the base writer for generating surveys. The results are shown as recall scores (in percentage) at different points (20%, 40%, 60%, 80%, and 100%) in the generation process. It shows a comparison between the naive RAG (Retrieval-Augmented Generation) approach and AutoSurvey, highlighting AutoSurvey’s relative stability and better performance across various stages of the text generation process. The table helps demonstrate the robustness of AutoSurvey across different LLMs.
read the caption
Table 6: Performance of AutoSurvey with different base LLM writers.
🔼 This table lists 20 different surveys selected for the evaluation of AutoSurvey. Each row represents a survey paper, showing its topic, title, and the number of citations it received from Google Scholar. The surveys were chosen to cover a broad range of topics within the field of large language models (LLMs) and to include surveys with varying citation counts.
read the caption
Table 7: Survey Table

🔼 This table shows the average cost to generate a 32k-tokens survey using three different LLMs: Claude-haiku, Gemini-1.5-pro, and GPT-4. The table indicates the input tokens, output tokens, and the cost in dollars for each LLM.
read the caption
Table 8: Cost of AutoSurvey
Full paper#