TL;DR#
High-fidelity image generation using diffusion models has seen significant advancements. However, generating images at ultra-high resolutions remains challenging due to the high computational costs associated with scaling up pre-trained models. Existing methods often necessitate multiple GPUs or extensive training, resulting in limitations in accessibility and scalability. This research paper tackles the problem of generating high-resolution images efficiently using a single GPU.
This paper introduces Pixelsmith, a novel framework that addresses the challenges of high-resolution image generation. Pixelsmith employs a cascading approach, using the output of lower-resolution generation as a baseline for higher-resolution sampling. A key innovation is the introduction of the ‘Slider,’ a mechanism that allows dynamic control over the balance between structural integrity and fine-grained detail enhancement. By denoising patches instead of the entire latent space, Pixelsmith minimizes memory requirements, making gigapixel image generation feasible on a single GPU. Experimental results demonstrate that Pixelsmith significantly improves image quality, diversity, and sampling speed, surpassing the limitations of existing approaches.
Key Takeaways#
Why does it matter?#
This paper is highly important because it presents Pixelsmith, a novel framework that enables gigapixel image generation using a single GPU. This addresses a critical limitation in current high-resolution image synthesis, opening up exciting possibilities for various applications requiring extremely high-resolution images, such as gigapixel photography and medical imaging, previously unattainable due to computational constraints. It introduces a new technique that significantly improves both image quality and generation efficiency, advancing the state-of-the-art in image generation.
Visual Insights#

🔼 This figure shows examples of images generated by Pixelsmith at various resolutions, comparing them to images from the base model. It highlights Pixelsmith’s ability to generate higher-resolution images without additional training, showcasing its scalability and the preservation of image quality and diversity.
read the caption
Figure 1: Examples of generated images using Pixelsmith. The proposed framework generates images on higher-resolutions than the pre-trained model without any fine-tuning. Images at different resolutions are shown with cut-out areas for both Pixelsmith and the base model. The higher-resolution images are in scale with the images generated by the base model. Only the lower resolution version of the gigapixel image has been resized for a better visualisation. Some cut-outs of the gigapixel generation have resolution close to the base model which is 10242 and it can be seen that the images are comparable in aesthetics showing that our framework is capable of true gigapixel generations (zoom in to see in better detail).

🔼 This table presents the results of an ablation study conducted to evaluate the impact of different components of the proposed framework on the image quality. The metrics used are FID, KID, IS, and CLIP. The ablation study considers the Slider position, the impact of amplitude and phase in the latent space, the effectiveness of masking during guidance, and the benefit of averaging overlapping patches.
read the caption
Table 1: A quantitative examination of our framework through ablations.
In-depth insights#
Gigapixel Synthesis#
Gigapixel synthesis, the generation of images with billions of pixels, presents a significant challenge in the field of image generation. Traditional methods struggle with the massive computational resources and memory demands required for such high-resolution outputs. However, recent advancements in diffusion models and other deep learning techniques offer exciting new possibilities. One key area of focus is developing efficient algorithms that can effectively scale up existing models without requiring extensive retraining or excessive computational power. This involves creative approaches like cascading methods that build upon lower-resolution images or patch-based sampling strategies that process smaller image sections independently. Furthermore, innovative guidance mechanisms are needed to maintain coherent and high-quality results across gigapixel images. Effectively fusing overall image structure with fine details is crucial. Balancing computational efficiency and visual fidelity remains a major hurdle, requiring careful consideration of memory management, sampling strategies, and artifact reduction techniques. Ultimately, gigapixel synthesis has the potential to revolutionize various fields, but overcoming the computational barriers is critical to realizing its full potential.
Patch Denoising#
Patch denoising, in the context of diffusion models for image generation, offers a memory-efficient alternative to processing the entire latent space at each denoising step. By dividing the image into smaller patches, the model processes and denoises them individually, thereby reducing computational costs and memory requirements. This approach is particularly useful when generating high-resolution images where processing the full latent space can be computationally expensive and may exceed available GPU memory. The effectiveness of patch denoising hinges on how well the model handles the transitions and boundaries between patches. Careful consideration must be given to how patches are selected (randomly or deterministically), their overlap, and the strategy for combining the denoised patches to reconstruct the final image. Addressing issues like artifacts at patch boundaries and ensuring coherence across the entire image are key challenges, and advanced techniques such as averaging or masking might be employed. Moreover, patch denoising’s impact on image quality and generation speed needs to be carefully evaluated in relation to the trade-off with increased computational complexity and potential artifacts.
Slider Guidance#
The concept of ‘Slider Guidance’ in the context of a generative image model is intriguing. It suggests a dynamic control mechanism that allows users to interactively balance the influence of pre-existing image structure and newly generated details. This is crucial for high-resolution image generation where maintaining consistency and preventing artifacts is paramount. The slider likely acts as a tunable parameter, perhaps controlling the weighting between a guidance signal derived from an upscaled lower-resolution image and a purely generative process. Lower slider values would prioritize fine details, potentially leading to novel, diverse, and high-fidelity output, but possibly also increased artifacts or inconsistencies. Higher values would emphasize preserving the overall structure, resulting in more stable and coherent images, though with potentially less diversity or detail. The success of this approach depends on a carefully designed method for fusing these two sources of information, likely involving techniques from signal processing or image manipulation. Ultimately, the ‘Slider’ offers a user-friendly way to manage the trade-off between fidelity and coherence in high-resolution image synthesis, addressing a challenging aspect of generative models.
Single-GPU Scaling#
Single-GPU scaling in large language models (LLMs) for image generation presents a significant challenge due to the high memory demands of processing high-resolution images. Approaches that successfully enable single-GPU scaling often involve techniques to reduce memory footprint such as patch-based processing where the image is divided into smaller patches, processed individually, and then recombined. This significantly lowers the memory requirements at each step. Furthermore, efficient sampling methods are crucial; techniques like denoising only a subset of the image at each timestep or employing a cascading approach where lower-resolution generations guide higher-resolution ones help manage memory usage. The choice of upscaling method also plays a role. While simple upscaling can be memory efficient, it may sacrifice image quality. A well-designed framework needs to carefully consider these factors to strike a balance between memory efficiency and the quality and speed of the generation process. Optimization of the underlying model architecture for memory efficiency is also a key aspect to enabling single-GPU scaling.
Future Directions#
Future research could explore several promising avenues. Improving the Slider mechanism to allow for more nuanced control over the balance between global structure and fine details would enhance the framework’s flexibility and reduce artifacts. Investigating alternative upsampling techniques beyond Lanczos interpolation could lead to better quality higher-resolution images. Exploring different patch sampling strategies might optimize memory usage and reduce computation time further. Finally, extending Pixelsmith to other generative models beyond Stable Diffusion would broaden its applicability and assess its scalability across different architectural designs. These advancements would significantly advance ultra-high resolution image generation and contribute to the development of more powerful, efficient, and versatile generative frameworks.
More visual insights#
More on figures

🔼 This figure illustrates the patch denoising process used in the Pixelsmith framework. The top shows the latent space at different timesteps, with patches being denoised sequentially. The bottom shows how the timesteps are tracked for each pixel, ensuring that each pixel is denoised only once per timestep. The process handles overlapping patches by temporarily reverting denoised pixels to their previous state before applying the denoising process again, and then restoring the denoised values. This ensures efficient memory management and prevents redundant computations.
read the caption
Figure 2: Overview of the patch denoising process proposed by DiffInfinite: The top row represents the latent space, while the bottom row tracks the timesteps for each pixel. Each pixel should be denoised only once per timestep, so when overlapping occurs, already denoised pixels revert to their previous values from the prior timestep. After denoising, these reverted pixels are restored to their original denoised state from the current timestep.
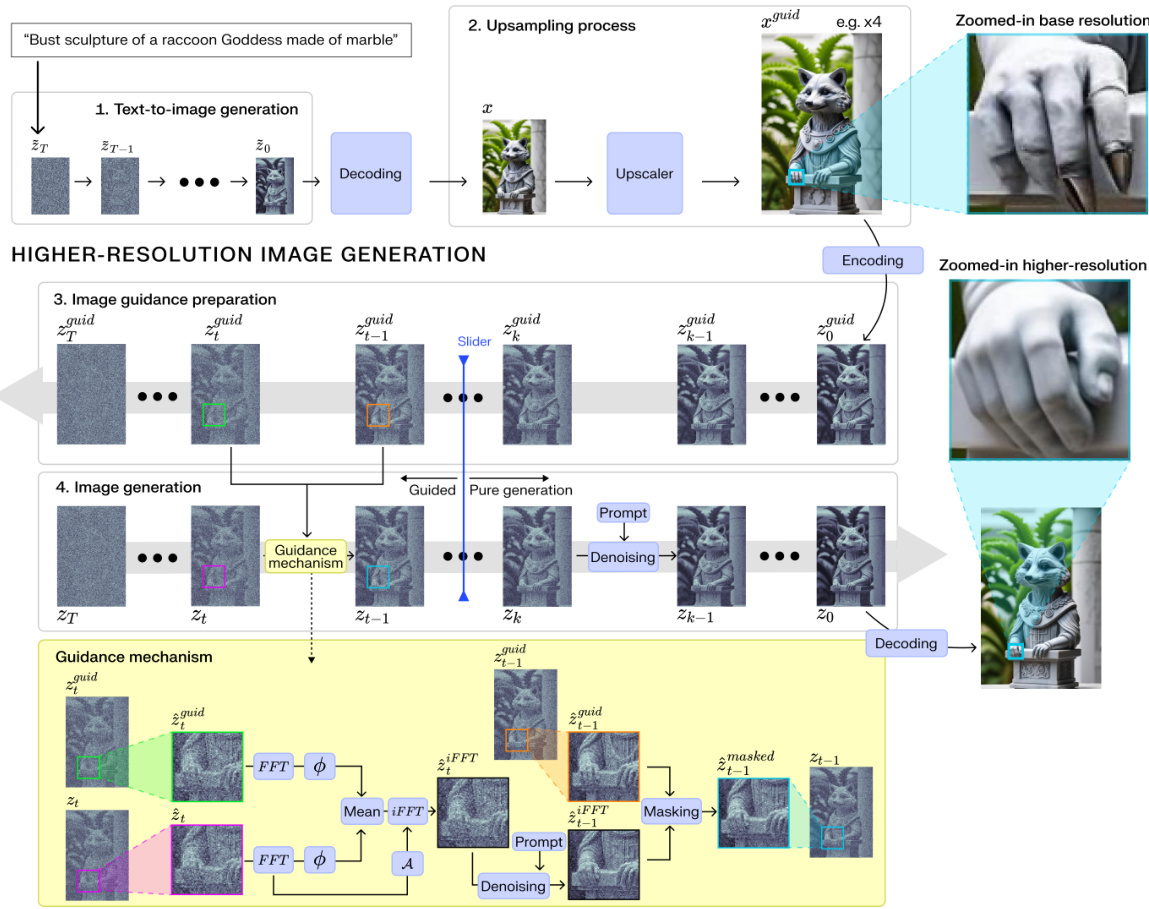
🔼 This figure illustrates the Pixelsmith framework’s four main steps: text-to-image generation, upsampling, guidance preparation, and image generation. The upsampling and image guidance steps leverage a novel ‘Slider’ mechanism to control the balance between using the original image’s structure and generating new details. The image generation stage uses a fast Fourier transform (FFT) to fuse guidance latents with higher-resolution latents and a masking technique to reduce artifacts. The comparison highlights how Pixelsmith improves on the base model’s results, avoiding distortions and enhancing detail.
read the caption
Figure 3: Proposed framework overview. 1. Text-to-image Generation: A pre-trained text-to-image diffusion model generates an initial image based on the input text prompt. 2. Upsampling process: The generated image is upscaled (in this use case by a factor x4) and encoded into the latent space to guide the creation of a higher-resolution image. 3. Image guidance preparation: The encoded image is degraded through the diffusive forward model, creating the guidance latents. 4. Image generation: the Slider (indicated by a blue line) adjusts the extent of guidance. Left of Slider (Guided Generation): guidance latents control the image generation. The framework fuses guidance latents (green patches) with high-resolution latents (purple patches) using the Fast Fourier Transformation (FFT). The phases are averaged and combined with the amplitude, then transformed back via the inverse FFT (iFFT). A chess-like mask integrates information from the successive guidance step (orange), resulting in fully processed patches (cyan). Right of Slider (Pure Generation): the generation relies only on the prompt. Higher-Resolution Comparison: while the base model upscales the bust with disfigured hands, the proposed method enhances details, corrects distortions, and prevents new artifacts.

🔼 This figure compares images generated by SDXL (left), Pixelsmith with masking (center), and Pixelsmith without masking (right). All images have a resolution 16 times higher than the original. The figure showcases how masking helps reduce artifacts which commonly occur when upscaling images without additional guidance, as seen in the image on the right. This demonstrates the effectiveness of Pixelsmith’s masking technique in preserving image coherence and accuracy at higher resolutions. The artifacts are highlighted with red arrows.
read the caption
Figure 4: Masking effects on higher-resolution generation (×16 the original resolution). (left) Image generated using SDXL. (center) Image generated with Pixelsmith with masking. (right) Image generated with Pixelsmith without masking. We highlighted the artifacts introduced by generating at higher scales. These artifacts demonstrate the challenges of maintaining coherence and accuracy when scaling up the resolution without additional guidance.

🔼 This figure compares the qualitative results of Pixelsmith with other state-of-the-art high-resolution image generation methods. Two examples of images, a zebra and a portrait of Robert De Niro, are shown at 2048x2048 and 4096x4096 resolutions. The figure highlights the artifacts (duplications and high-frequency pattern issues) introduced by other methods, while showing that Pixelsmith generates cleaner images with significantly fewer artifacts.
read the caption
Figure 5: Qualitative comparisons: This figure highlights how other models suffer from duplications (red arrows) and introduce artifacts in areas with complex, high-frequency patterns (purple arrows). In contrast, Pixelsmith effectively eliminates these issues. (zoom in to see in better detail).

🔼 This figure shows an example of how Pixelsmith improves image generation at higher resolutions. The base model generates a low-resolution image (1024x1024), which is then upscaled by Pixelsmith to 2048x2048 and then 4096x4096. The higher resolution images show significant improvements in detail, particularly in the facial features of the subject. The detailed view shows that finer details, such as individual hairs, are better captured at the higher resolutions.
read the caption
Figure 6: We show an example of a two-step image generation process here. The base model provides a 10242 image which our method then uses to iteratively generate a 20482 and a 40962 image. It is evident from this example that the higher-resolutions overall have increasingly improved facial characteristics, demonstrating the effectiveness of our framework (zoom in to see in better detail).

🔼 This figure compares the image generation results of Pixelsmith against other state-of-the-art models at a resolution of 4096x4096 pixels. Three different image prompts are used: a character in a suit, a warrior’s face, and a Japanese landscape. The figure highlights that Pixelsmith generates images without artifacts and noise while other models show significant artifacts and noise indicated by red and purple arrows.
read the caption
Figure 7: We show additional qualitative comparisons against our competitors here. All generated images have a resolution of 40962. Other models suffer from artifacts (red arrows) along with highly prominent high-frequency noise (purple arrows), some of which are indicated by arrows (zoom in to see in better detail).

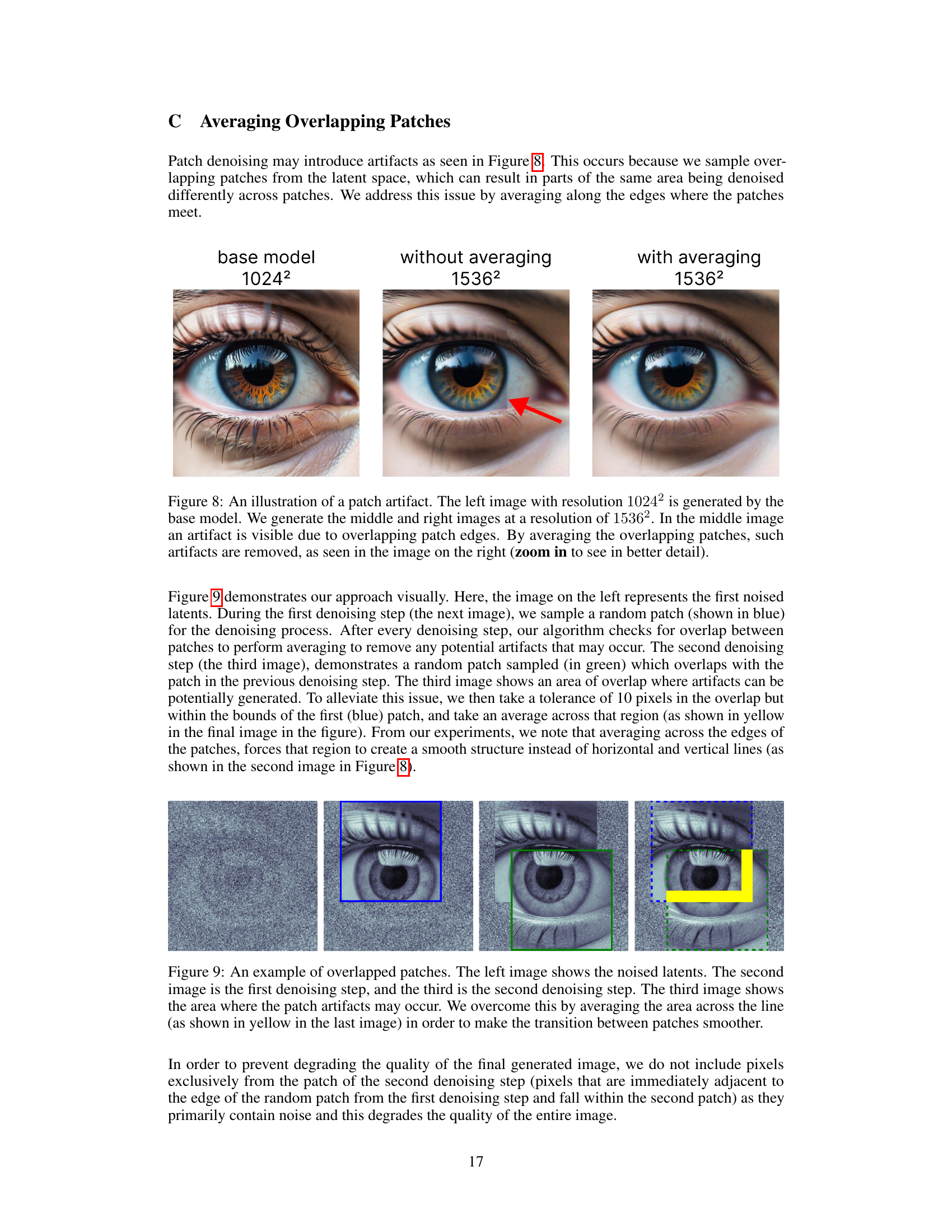
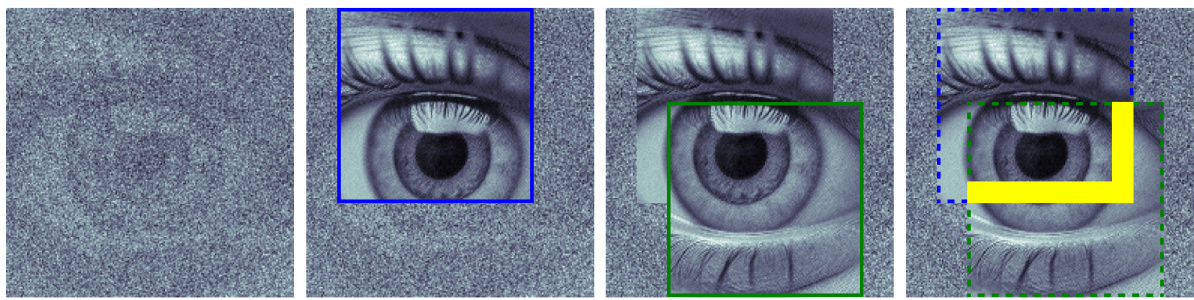
🔼 This figure shows an example of an artifact caused by overlapping patches during the image generation process. The left image is the original image from the base model. The middle image shows an artifact created when overlapping patches are not handled correctly. The image on the right shows the same image after processing with a patch averaging method, which resolves the artifact. This illustrates the effectiveness of the averaging method used in the Pixelsmith framework to produce higher-quality images.
read the caption
Figure 8: An illustration of a patch artifact. The left image with resolution 10242 is generated by the base model. We generate the middle and right images at a resolution of 15362. In the middle image an artifact is visible due to overlapping patch edges. By averaging the overlapping patches, such artifacts are removed, as seen in the image on the right (zoom in to see in better detail).
🔼 This figure illustrates the patch denoising process in the DiffInfinite method. It shows how pixels are denoised one at a time per timestep, preventing redundant processing. When patches overlap, already denoised pixels are temporarily reverted to their previous state before being updated again with the current timestep’s denoising. This ensures that each pixel is processed only once per timestep, even with overlapping patches.
read the caption
Figure 2: Overview of the patch denoising process proposed by DiffInfinite: The top row represents the latent space, while the bottom row tracks the timesteps for each pixel. Each pixel should be denoised only once per timestep, so when overlapping occurs, already denoised pixels revert to their previous values from the prior timestep. After denoising, these reverted pixels are restored to their original denoised state from the current timestep.

🔼 This figure compares the multi-step generation approach of DemoFusion with Pixelsmith’s single-step approach. DemoFusion shows amplified artifacts at higher resolutions (2048x2048 and 3072x3072) indicated by red arrows, while Pixelsmith maintains image quality across resolutions. This highlights Pixelsmith’s ability to generate high-resolution images without intermediate steps, thus avoiding artifact amplification.
read the caption
Figure 10: Comparison between a state-of-the-art method, DemoFusion Du et al. [2023] and our work, Pixelsmith. This figure shows how artifacts are amplified at higher-resolutions in DemoFusion (as denoted by the red arrows). We directly generate a 30722 image from the base without any artifacts. The flexibility of our approach allows for any resolution to be generated right after the base resolution minimizing seeing artifacts at every intermediate step (zoom in to see in better detail).
🔼 This figure compares the results of two different approaches to image generation: one-step and two-step. The one-step approach directly generates the final image, while the two-step approach first generates a lower resolution image and then upscales it to the desired resolution. The figure shows that the two-step approach leads to a higher quality image with more details, especially in amplified sections where intermediate steps are used.
read the caption
Figure 11: A comparison between two-step and one-step generations. On the top, we show that the base model first generates the image following which we generate the final resolution we desire. At the bottom, we use an intermediate step for better local image feature refinement. From the amplified region of the generation where we employ the intermediate generation step, we see that all the steps contribute to enhancing the features in the image to create a sharper image at the higher-resolution (zoom in to see in better detail).

🔼 This figure shows a qualitative comparison of images generated using a super-resolution model and the proposed Pixelsmith framework. The comparison highlights the enhanced detail and richness of the images produced by Pixelsmith, particularly in finer details, textures, and overall image clarity. The highlighted regions show noticeable differences in detail between the two methods. Pixelsmith demonstrates superior performance in preserving and enhancing the quality and diversity of image details.
read the caption
Figure 12: Qualitative comparison with the latent upscaler. The fine details generated by our framework are richer in comparison to the super-resolution model.
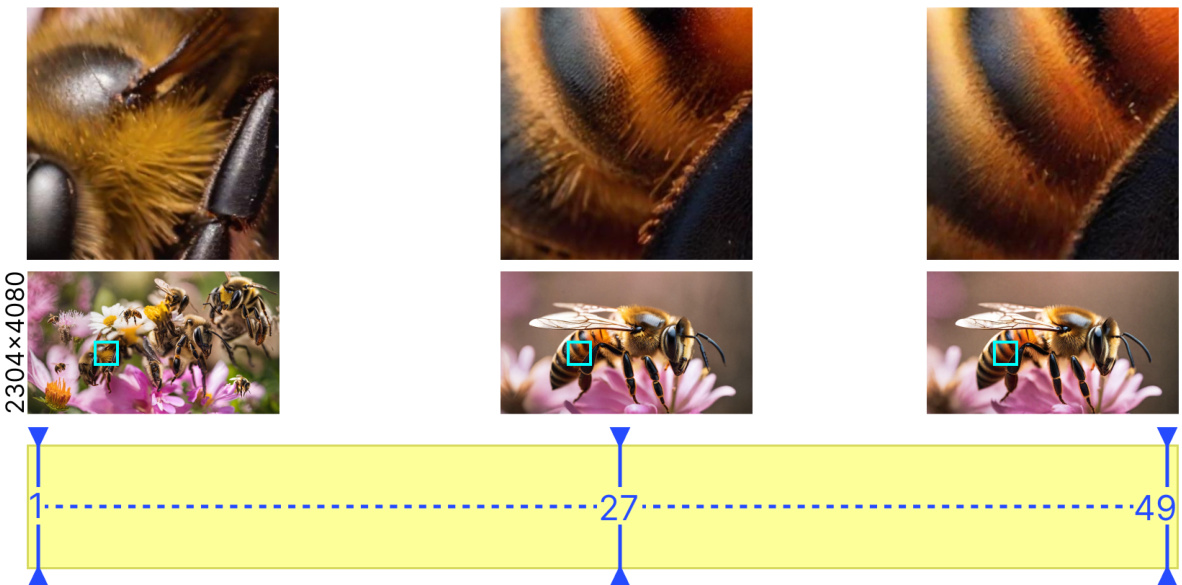
🔼 This figure shows how the slider parameter affects the generated images. The slider controls the balance between detail and overall image structure. A low slider value (1) generates images with fine details but structural errors, a high slider value (49) preserves the overall structure but lacks detail, and a mid-range value (27) provides a good balance.
read the caption
Figure 13: Experimenting with different positions of The Slider. The image on the left contains finer details but loses the overall structure, generating artifacts. The image on the right has a good global structure but lacks any high frequency details due to the Slider constraining the image generation process. The central position, in this case, is the most optimal generation where the overall structure of the image is preserved and at the same time, finer details are also introduced such as the individual hair strands on the bees' body. We observed that by generating multiple resolutions in a cascaded framework, each intermediate generation will contribute to creating a more detailed final image.

🔼 This figure shows two examples of the masking technique used in the Pixelsmith framework. The left image shows a random pattern, representing the latent space before denoising, where a patch of pixels has been selected for processing. The right image is a chessboard pattern. This mask is applied to the selected patch. Half of the pixels in the denoised patch are masked (taken from the image guidance) and replaced with values from the image guidance to mitigate the problem of generating duplicate structures and artifacts. This helps maintain coherence and reduce artifacts during the image generation process.
read the caption
Figure 14: Mask visualisation. Half of the pixels in the denoised patch are masked and replaced with values from the image guidance, significantly reducing duplications.

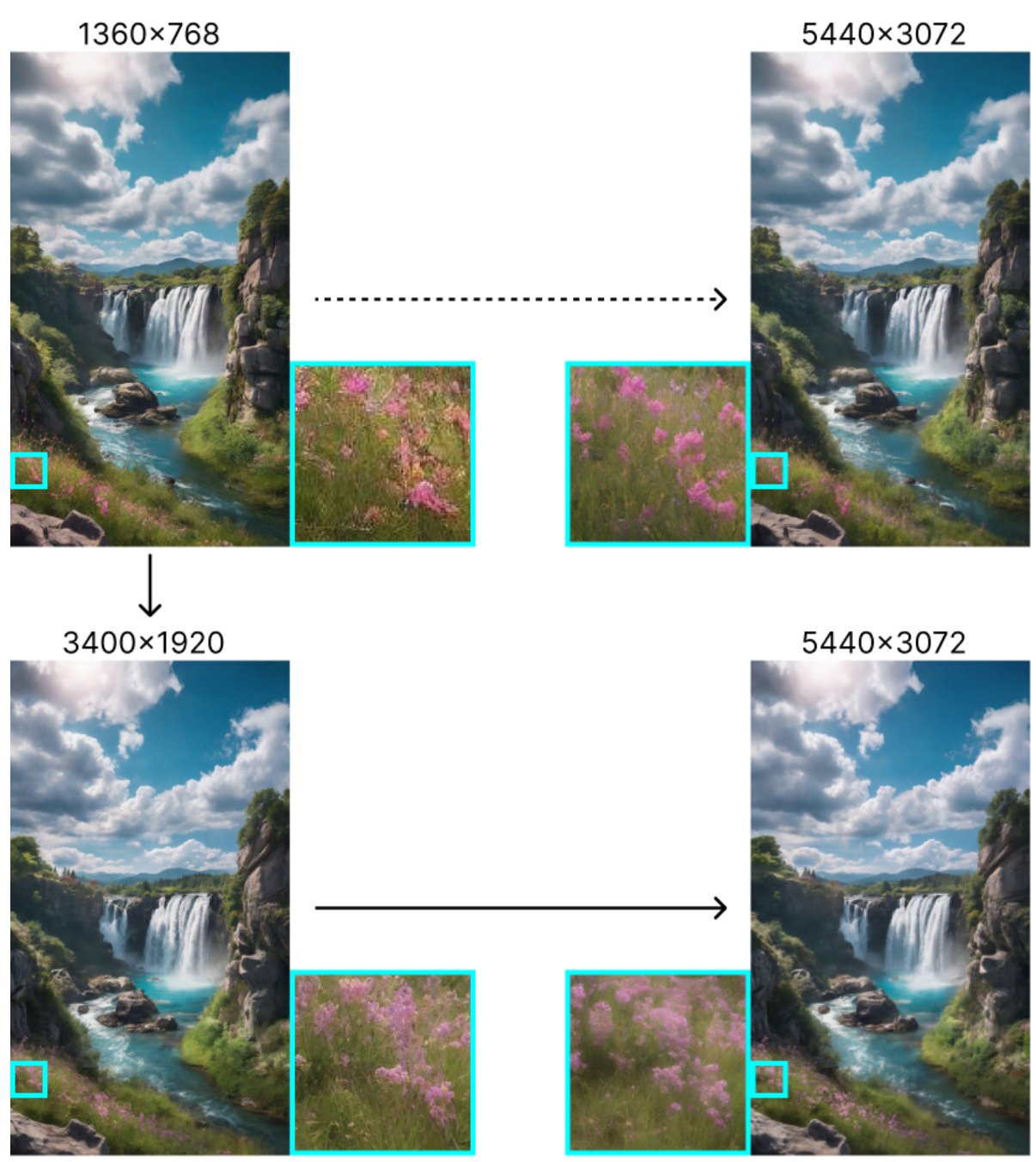
🔼 This figure shows examples of images generated at different resolutions using the Pixelsmith framework. The images illustrate how the quality and detail of the generated images improve as the resolution increases. The close-ups highlight the enhanced detail in the facial features as the resolution scales up.
read the caption
Figure 15: Example of 16× (5440 × 3072) images. The amplified cut-outs illustrate how facial features become increasingly well-defined with each generation (zoom in to view in greater detail).

🔼 This figure shows examples of images generated by Pixelsmith at various resolutions, comparing them to images from the base model. It highlights Pixelsmith’s ability to generate higher-resolution images without additional training, maintaining comparable aesthetics and detail.
read the caption
Figure 1: Examples of generated images using Pixelsmith. The proposed framework generates images on higher-resolutions than the pre-trained model without any fine-tuning. Images at different resolutions are shown with cut-out areas for both Pixelsmith and the base model. The higher-resolution images are in scale with the images generated by the base model. Only the lower resolution version of the gigapixel image has been resized for a better visualisation. Some cut-outs of the gigapixel generation have resolution close to the base model which is 10242 and it can be seen that the images are comparable in aesthetics showing that our framework is capable of true gigapixel generations (zoom in to see in better detail).
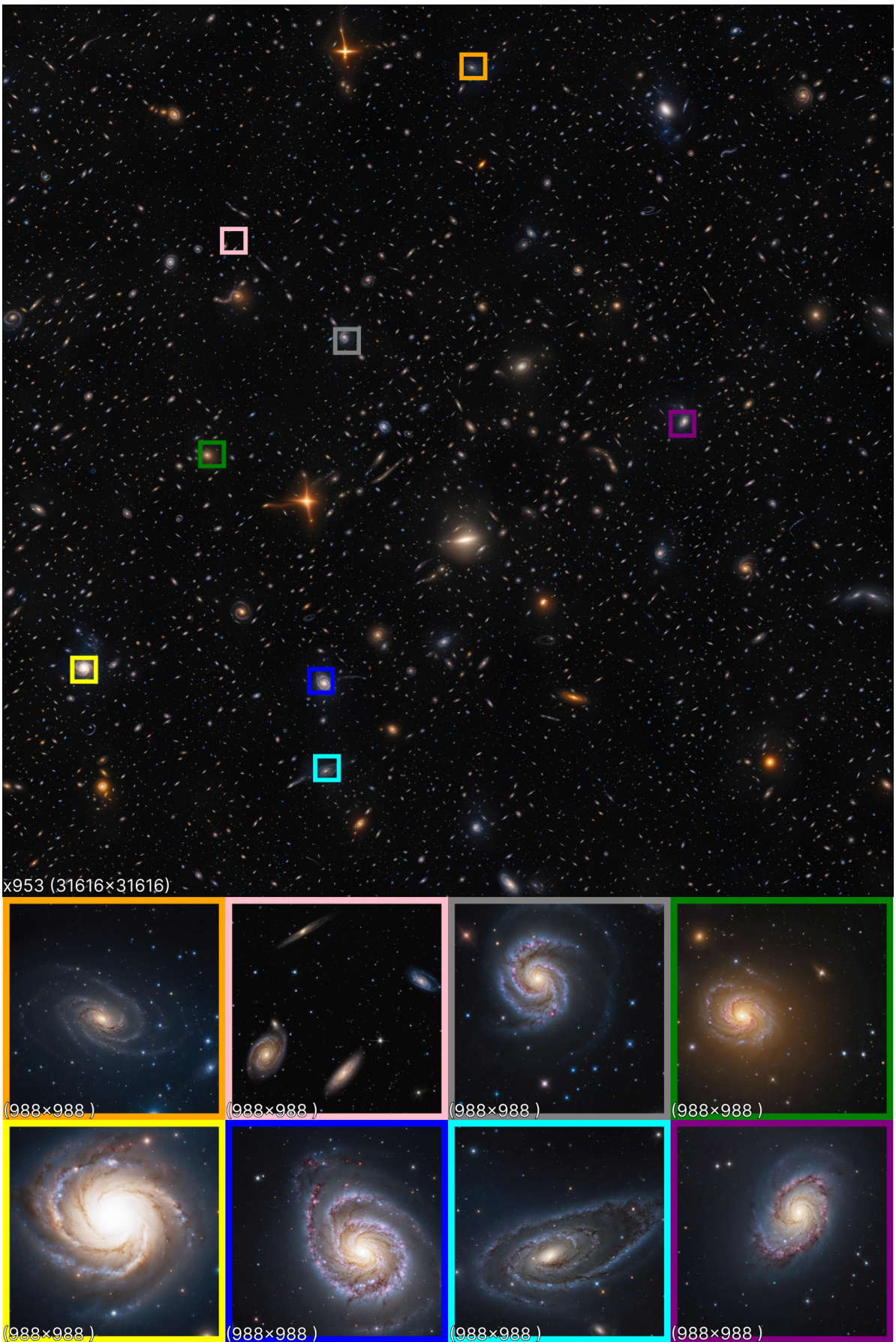
🔼 This figure shows a gigapixel image (953 times the base resolution) generated by Pixelsmith. The image is composed of many smaller patches, each of which is 988x988 pixels (the same size as the base image from the pre-trained model). The overall image quality and detail are high, and the visual style resembles images taken by the Hubble Space Telescope.
read the caption
Figure 17: An example of a 953× (31616 × 31616) gigapixel image. Each displayed patch is 988 × 988, roughly the size of the base image. The image closely resembles those captured by the Hubble telescope. (zoom in to see in better detail).
More on tables
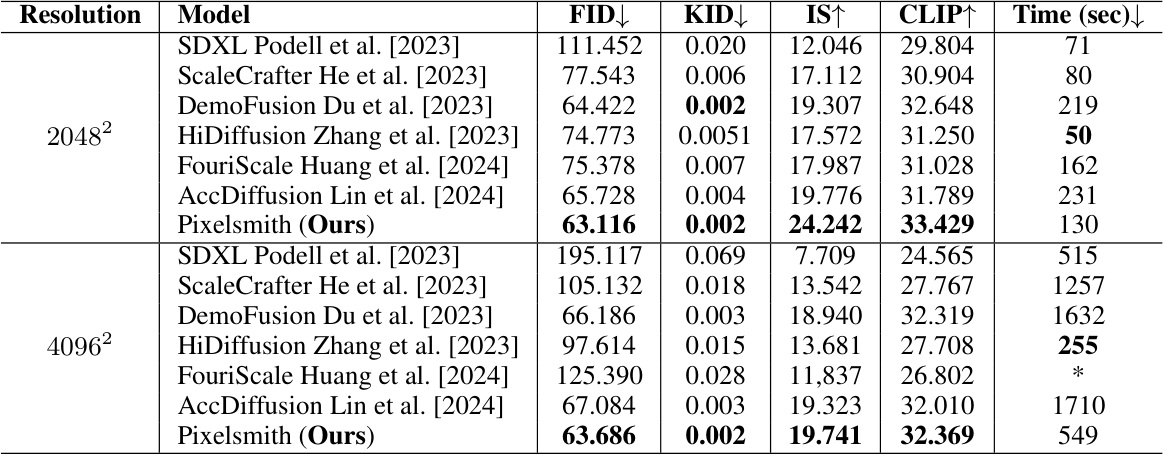
🔼 This table compares the performance of Pixelsmith with other state-of-the-art higher-resolution image generation models on two resolutions, 2048x2048 and 4096x4096. The metrics used for comparison include FID, KID, IS, and CLIP scores, along with the inference time. The table highlights Pixelsmith’s superior performance in terms of FID, KID, IS, and CLIP scores, indicating that Pixelsmith generates higher-quality images with lower inference times compared to the other methods.
read the caption
Table 2: Quantitative comparisons with existing works.

🔼 This table presents a quantitative comparison of Pixelsmith’s performance against a 2x super-resolution model. Both models generate images at a resolution of 2048x2048 pixels. The comparison uses four metrics: FID (Fréchet Inception Distance), KID (Kernel Inception Distance), IS (Inception Score), and CLIP score. Lower FID and KID scores indicate better image quality. Higher IS and CLIP scores indicate better image quality. The results show that Pixelsmith outperforms the super-resolution model on all metrics, even without any fine-tuning (zero-shot).
read the caption
Table 3: Quantitative comparisons with the 2× upscaler trained for the task of super-resolution. The final image resolution for both approaches is 20482. Pixelsmith outperforms the super-resolution model even in a zero-shot setting.
Full paper#