TL;DR#
Transformer models have achieved remarkable success in various machine learning tasks, yet their internal mechanisms remain poorly understood. Existing research often focuses on transformers’ expressive power, lacking a comprehensive understanding of their post-training operations. In particular, the role of multiple heads within transformer layers remains an open question, especially regarding their impact on the process of in-context learning. This paper tackles this limitation by investigating how trained transformers leverage multi-head attention during in-context learning.
This study addresses this issue by analyzing a trained transformer’s performance on a sparse linear regression task. Through a combination of experiments and theoretical analysis, the researchers demonstrate that multi-head attention exhibits distinct patterns across different layers. Importantly, the first layer primarily focuses on data preprocessing using all available heads, while subsequent layers perform simple optimization steps using a single dominant head. The team proves that this two-stage ‘preprocess-then-optimize’ strategy surpasses standard approaches like gradient descent and ridge regression in terms of performance. This finding offers new insights into the workings of transformer models, and could potentially guide future improvements in model design and training.
Key Takeaways#
Why does it matter?#
This paper is crucial because it sheds light on the inner workings of transformer models, a dominant force in modern machine learning. By unraveling the role of multi-head attention, it offers insights into improving model efficiency and performance and opens avenues for more advanced theoretical analysis.
Visual Insights#

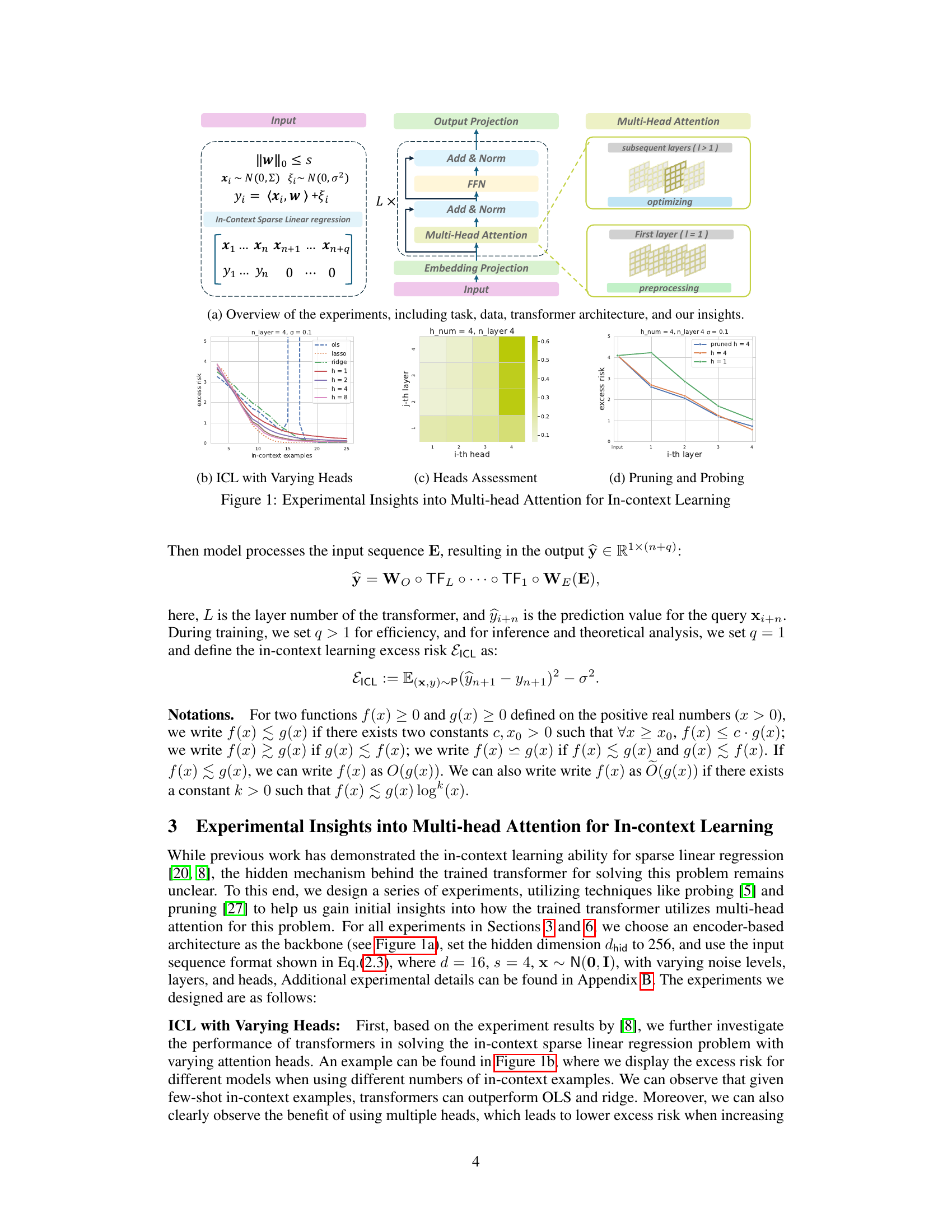
🔼 This figure presents experimental results that offer insights into the utilization patterns of multi-head attention across different layers within a trained transformer model. Specifically, it shows that multiple heads are utilized and essential in the first layer, while usually only one single head is dominantly utilized for the subsequent layers. This observation suggests that a multi-layer transformer may exhibit a preprocess-then-optimize algorithm on the context examples, a hypothesis that the paper subsequently explores.
read the caption
Figure 1: Experimental Insights into Multi-head Attention for In-context Learning
In-depth insights#
Multi-Head Roles#
The concept of “Multi-Head Roles” in transformer models is crucial for understanding their effectiveness. Each head specializes in capturing different aspects of the input data, leading to a richer, more nuanced representation. Early layers might focus on feature extraction and preprocessing, using multiple heads to identify various patterns and relationships within the input. Subsequent layers then refine these representations, potentially leveraging only a single dominant head to perform efficient optimization steps. This specialization of roles across layers and heads allows for a more powerful and efficient processing of information than simpler single-head approaches. Understanding the interplay between these specialized roles is key to further advancements in transformer architecture and the development of even more effective and interpretable models. Future work could explore adaptive head allocation or dynamic role assignment to further enhance performance and efficiency.
Preprocess-Optimize#
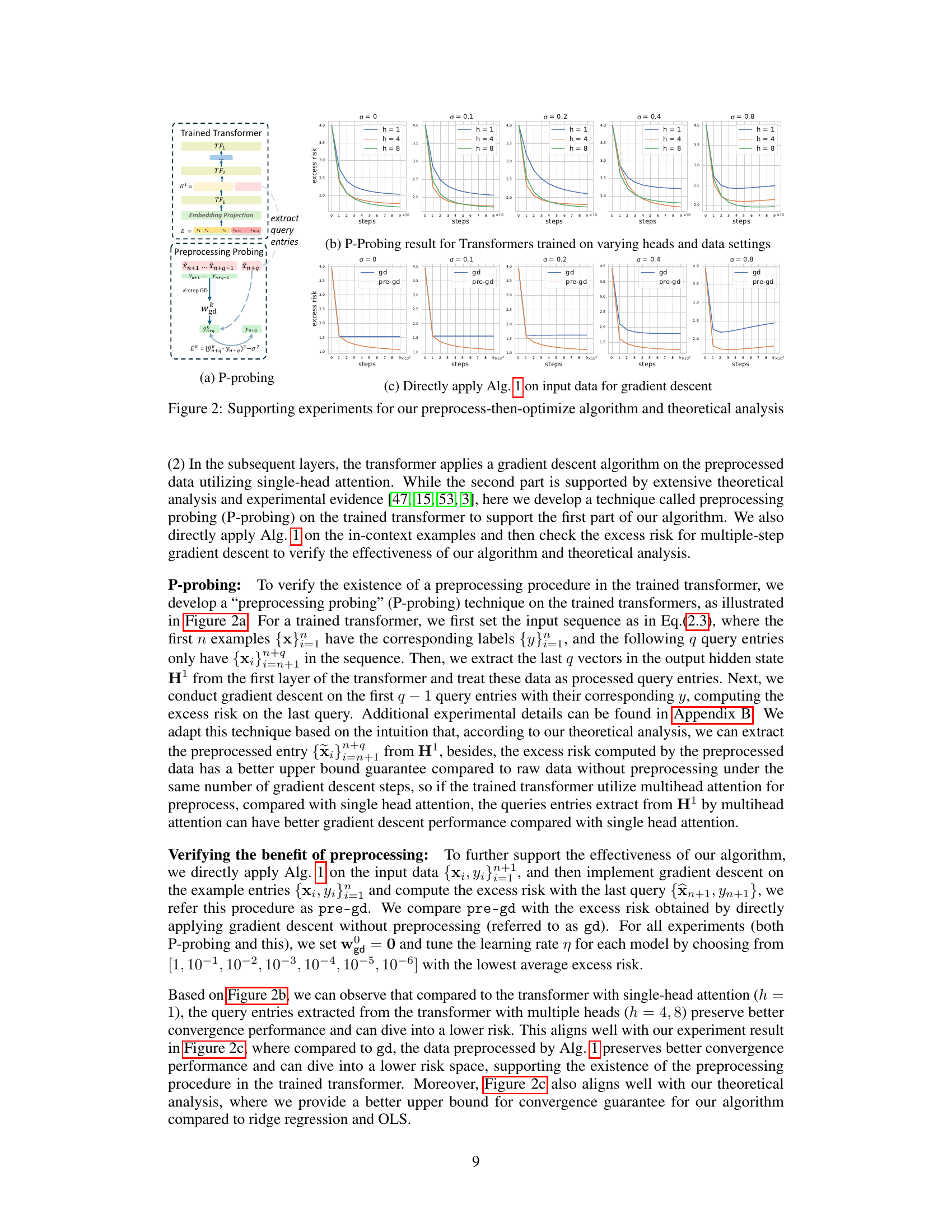
The “preprocess-then-optimize” approach, a novel framework proposed in this research, offers a compelling explanation for how transformers utilize multi-head attention in in-context learning. The framework posits that the initial layer of the transformer serves as a preprocessing stage, effectively preparing contextual examples for subsequent layers. This preprocessing involves multi-head attention, which allows for the extraction of diverse, possibly non-linear, features from the input data. Subsequent layers then adopt a simpler, single-head optimization algorithm, like gradient descent, acting on this already-processed information to minimize loss. This two-stage approach effectively combines the strengths of feature engineering and optimization, potentially contributing to transformers’ remarkable ability to perform in-context learning. Theoretical analysis supports this framework, indicating a potential advantage of this method over naive gradient descent and ridge regression in terms of excess risk, especially in sparse linear regression problems. The results demonstrate a sophisticated interplay between the layers, emphasizing the importance of multi-head attention in the initial layer for effective data preprocessing.
Theoretical Rationale#
A theoretical rationale section in a research paper would justify the experimental findings by connecting them to existing theoretical frameworks. In the context of a study on transformers and multi-head attention, a strong rationale would likely involve demonstrating that the observed patterns of multi-head utilization (e.g., multiple heads in early layers, single head dominance in later layers) are a consequence of the transformer’s inherent architecture and learning process. The rationale might explain how the first layer acts as a data pre-processor, leveraging multiple heads to extract diverse features from the input data, potentially transforming the data in a way that facilitates efficient optimization in subsequent layers. This might involve showing how the transformation achieved in the first layer improves the conditioning of the optimization problem or reduces the impact of data sparsity. A strong rationale should prove that the algorithm implemented by the multi-layer transformer (preprocess-then-optimize) theoretically outperforms naive gradient descent or ridge regression algorithms in terms of convergence rate or error bounds. The argument might involve rigorous mathematical analysis and potentially simulations, demonstrating that the observed multi-head behavior is not arbitrary but rather a reflection of an optimal or near-optimal strategy for solving the problem.
Sparse Regression#
Sparse regression, a crucial aspect of high-dimensional data analysis, focuses on identifying a small subset of significant predictors among numerous variables. This sparsity constraint is critical because it reduces model complexity, improves prediction accuracy, and enhances interpretability by highlighting the most influential factors. The core challenge lies in effectively identifying these relevant features, often using techniques that incorporate regularization penalties (like LASSO or elastic net) to shrink less important coefficients towards zero. The choice of regularization method and the tuning of its hyperparameters are key aspects influencing the success of sparse regression. Furthermore, the effectiveness of sparse regression heavily depends on the data characteristics, such as the level of noise, the correlation structure among predictors, and the true underlying relationship between predictors and the outcome. Advanced techniques like SCAD (smoothly clipped absolute deviation) and MCP (minimax concave penalty) aim to address limitations of standard LASSO by handling outliers better and providing more accurate coefficient estimation in the presence of highly correlated features. Understanding the nuances of these methods and their impact on the final model is paramount for successful application in real-world contexts where dimensionality reduction and clear interpretations are highly desirable.
Future Work#
The paper’s core finding, demonstrating that transformers utilize a preprocess-then-optimize strategy in in-context learning, opens several exciting avenues for future research. Extending the analysis beyond sparse linear regression to more complex tasks such as natural language processing and image recognition would significantly enhance the understanding of this strategy’s generalizability. Investigating the role of MLP layers, currently neglected in the simplified model, is crucial to determine their contribution to the overall process. Furthermore, analyzing training dynamics of multi-layer transformers, currently opaque, could reveal how this preprocess-then-optimize mechanism emerges during training. A more in-depth exploration could focus on different architectural variations and their impact on the efficiency of this learning process. Finally, exploring the implications of this strategy in broader applications such as developing more efficient and robust in-context learning algorithms is a high impact area for future work.
More visual insights#
More on figures

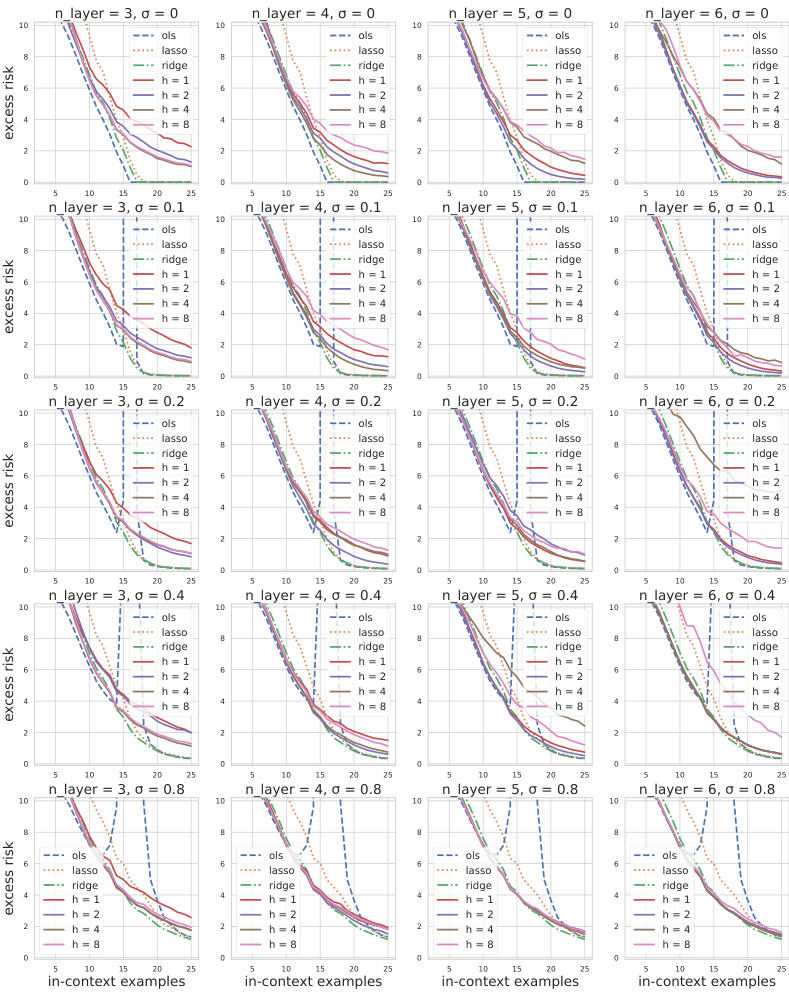
🔼 This figure presents experimental results illustrating the role of multi-head attention in transformer-based in-context learning for sparse linear regression. Subfigure (a) provides an overview of the experimental setup, including the task, data generation process, and transformer architecture. Subfigures (b), (c), and (d) showcase experimental findings demonstrating how multi-head attention is utilized differently across layers: multiple heads are crucial in the first layer, whereas usually only a single head is dominant in subsequent layers. The experiments involve varying the number of heads, assessing their importance, and selectively pruning less important heads. These results support the proposed theory that the transformer employs a preprocess-then-optimize algorithm.
read the caption
Figure 1: Experimental Insights into Multi-head Attention for In-context Learning

🔼 This figure summarizes the key experimental findings of the paper regarding the role of multi-head attention in transformer models for in-context learning. It shows the performance of transformers with varying numbers of heads and layers on a sparse linear regression task, and also includes the results of head assessment and probing experiments, which shed light on the working mechanisms of the model in different layers.
read the caption
Figure 1: Experimental Insights into Multi-head Attention for In-context Learning

🔼 This figure presents experimental results on the role of multi-head attention in transformers for in-context learning in a sparse linear regression task. It shows the importance of multiple heads in the first layer, with only one head being predominantly used in subsequent layers. The figure also supports the ‘preprocess-then-optimize’ algorithm proposed in the paper by comparing the performance of transformers with varying numbers of heads and layers.
read the caption
Figure 1: Experimental Insights into Multi-head Attention for In-context Learning

🔼 This figure displays the results of pruning and probing experiments on a transformer model with 3 layers. The experimenters investigated the effects of selectively masking attention heads (pruning) and subsequently using linear probes to evaluate the model’s performance. Specifically, it shows the excess risk across different layers for three scenarios: using all heads, using only the most significant head, and a single-head transformer as baseline. The results are shown for different noise levels. The aim is to support the hypothesis that multi-head attention has different roles across layers, primarily in the first layer for preprocessing data before subsequent layers perform optimization.
read the caption
Figure 5: Pruning and Probing, 3 layers
🔼 This figure summarizes the key experimental findings of the paper regarding the utilization of multi-head attention in transformers for in-context learning. Subfigure (a) provides an overview of the experimental setup, including the task (sparse linear regression), data generation, transformer architecture, and the insights gained. Subfigure (b) shows the performance of the transformer model with varying numbers of heads and in-context examples. Subfigure (c) presents the assessment of the importance of each head in different layers, showing that multiple heads are crucial in the first layer while a single head dominates in subsequent layers. Finally, Subfigure (d) demonstrates the effect of pruning and probing on the model’s performance.
read the caption
Figure 1: Experimental Insights into Multi-head Attention for In-context Learning

🔼 This figure summarizes experimental results and insights into the role of multi-head attention in transformers’ in-context learning performance for a sparse linear regression task. Subfigures (a) through (d) show experimental setups, results on varying the number of heads, the relative importance of individual heads across layers, and pruning experiments respectively. These results highlight the distinct pattern of multi-head usage across layers (all heads utilized in the first layer, single dominant head in subsequent layers), suggesting the transformer operates using a two-phase preprocess-then-optimize mechanism.
read the caption
Figure 1: Experimental Insights into Multi-head Attention for In-context Learning
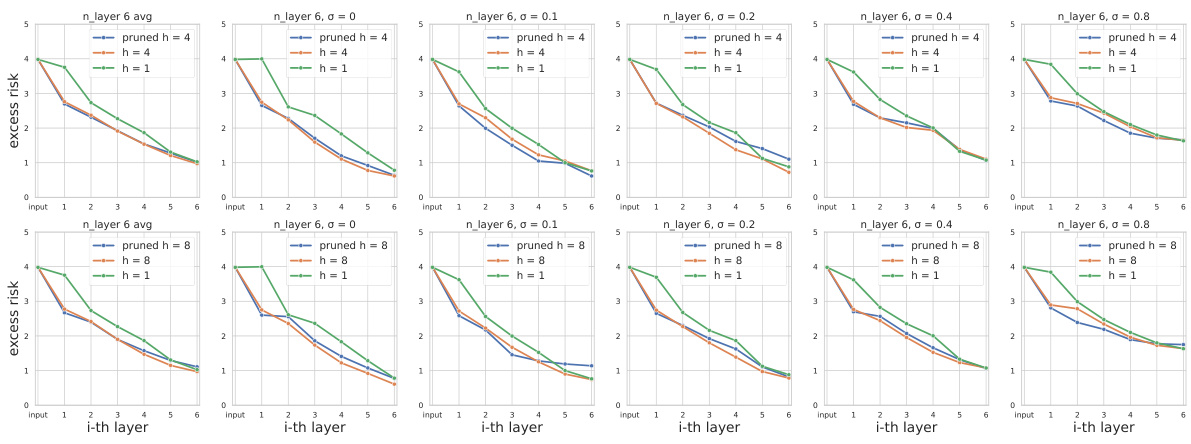
🔼 This figure shows the results of pruning and probing experiments conducted on a transformer model with 3 layers. The experiments aimed to validate the hypothesis that multi-head transformers utilize heads differently across layers. The ‘pruned’ transformer was modified to keep only the most important head in subsequent layers (layers >1). The results compare the excess risk of the full model (all heads used) against the pruned model and a single-head model, across varying noise levels and a range of input examples. The close performance of the full and pruned models supports the hypothesis that only a single head is dominantly used in later layers.
read the caption
Figure 5: Pruning and Probing, 3 layers

🔼 This figure presents experimental results on multi-head attention’s role in in-context learning for sparse linear regression. Subfigures (a) to (d) illustrate the experimental setup, varying the number of heads and their impact, head importance assessment across layers, and pruning and probing results to analyze the transformer’s workings. The findings indicate differing multi-head utilization patterns across layers, crucial in the first layer, but often singular in subsequent ones.
read the caption
Figure 1: Experimental Insights into Multi-head Attention for In-context Learning
🔼 This figure presents experimental results illustrating the role of multi-head attention in in-context learning for a sparse linear regression task. It shows how the utilization of multi-heads varies across layers in a trained transformer model. Subplots visualize the performance with varying heads, head assessment, and the impact of pruning and probing. These findings support the hypothesis that the model utilizes a preprocess-then-optimize approach.
read the caption
Figure 1: Experimental Insights into Multi-head Attention for In-context Learning

🔼 This figure summarizes the key experimental findings regarding the utilization patterns of multi-head attention across different layers of a trained transformer model for a sparse linear regression problem. It includes subfigures illustrating: (a) An overview of the experimental setup, highlighting the task (in-context sparse linear regression), data generation process, transformer architecture, and the main research insights. (b) Excess risk curves for models with different numbers of heads (h) across increasing numbers of in-context examples, demonstrating the impact of multiple heads on performance. (c) The relative importance of different heads (i-th head) within each layer (i-th layer), illustrating uneven head usage across layers. (d) The performance of a pruned model (where only a single dominant head per layer is retained) compared to the original model, further supporting the hypothesis of different roles for heads in different layers.
read the caption
Figure 1: Experimental Insights into Multi-head Attention for In-context Learning
Full paper#