↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Current Multimodal Large Language Models (MLLMs) struggle with multi-image reasoning due to limitations in processing multiple visual inputs and bridging the semantic gap between visual and textual data. Existing methods either use discrete visual symbols (lacking fine-grained details) or continuous representations (computationally expensive for multiple images).
MaVEn, a novel framework, effectively addresses these issues by integrating both discrete and continuous visual encoding. It uses discrete symbols for high-level semantic understanding and continuous sequences for detailed information, enhancing the model’s capacity to interpret complex multi-image contexts. A dynamic reduction mechanism further optimizes processing efficiency for long sequences. Experiments show that MaVEn substantially enhances MLLM performance across various multi-image and single-image benchmarks.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on multimodal large language models (MLLMs) and multi-image reasoning. It introduces a novel framework that significantly improves the performance of MLLMs in complex multi-image scenarios, directly addressing a major limitation of current MLLMs. The proposed multi-granularity hybrid visual encoding approach, along with the dynamic reduction mechanism, offers a more efficient and effective way to process visual information, opening new avenues for research in multimodal understanding and applications.
Visual Insights#
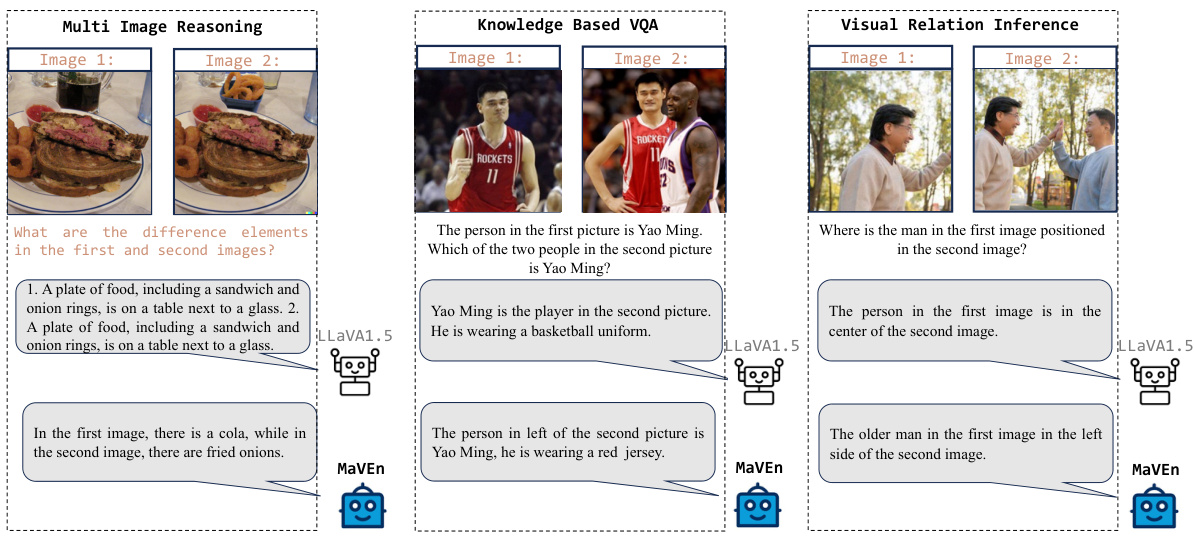
This figure showcases a comparison between the performance of a classic single-image trained multi-modal large language model (MLLM) called LLaVA1.5 and the authors’ proposed model, MaVEn, across three different multi-image scenarios: Multi-Image Reasoning, Knowledge-Based VQA, and Visual Relation Inference. The results visually demonstrate that LLaVA1.5 struggles significantly with multi-image tasks, highlighting the limitations of single-image trained models on such scenarios and the improved performance of MaVEn in these complex, multi-image situations.
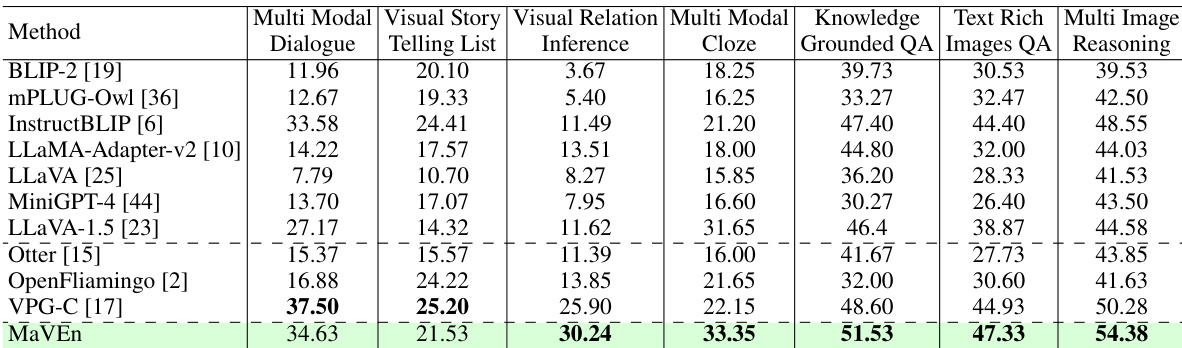
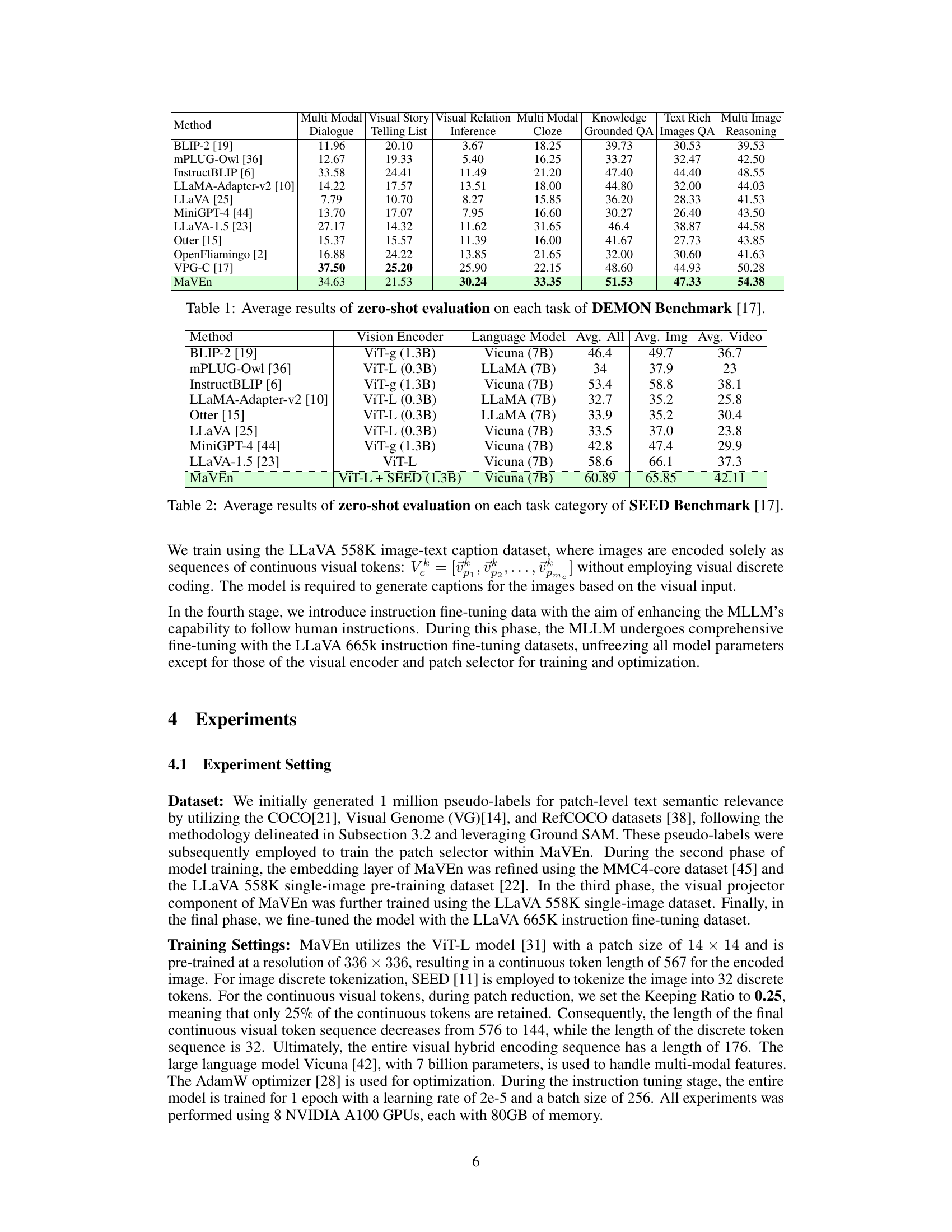
This table presents the performance of different multimodal large language models (MLLMs) on seven different tasks within the DEMON benchmark. The benchmark focuses on multi-image visual understanding and reasoning, covering scenarios such as Visual Relation Inference, Multi-Modal Dialogue, Knowledge Grounded QA, and Multi-Image Reasoning. The results are reported as average scores for each model across the seven tasks, providing a comparative analysis of their capabilities in complex multi-image scenarios.
In-depth insights#
Multimodal Encoding#
Multimodal encoding in large language models (LLMs) aims to effectively integrate information from various modalities, such as text and images. A key challenge lies in finding a way to represent disparate data types within a unified framework that the LLM can effectively process. Current approaches often involve separate encoders for each modality, followed by fusion mechanisms to combine the resulting representations. The choice of fusion method is crucial, with options ranging from simple concatenation to more sophisticated attention mechanisms. Another important aspect is the granularity of the encoding: some approaches focus on coarse-grained semantic features (e.g., object labels), while others aim for finer-grained details. A hybrid approach, combining both coarse and fine-grained features, could be highly beneficial for resolving ambiguity and improving overall understanding. Finally, efficient encoding is vital, especially for handling multiple images. The development of innovative encoding strategies remains an active area of research, focusing on more efficient methods to represent rich multimodal information while avoiding computational bottlenecks.
Hybrid Approach#
A hybrid approach in a research paper often signifies a synergistic combination of distinct methods or techniques to leverage their individual strengths while mitigating weaknesses. This strategy is particularly valuable when dealing with complex problems that don’t lend themselves to a single solution. A successful hybrid approach hinges on careful selection and integration of complementary methods. For instance, combining a rule-based system with a machine learning model might harness the interpretability and precision of rules with the adaptability and scalability of machine learning. Similarly, a hybrid approach could blend qualitative and quantitative data analysis to provide a more holistic understanding. The design and evaluation of a hybrid approach necessitate a thorough understanding of the individual components and their interplay. Factors such as computational cost, data requirements, and potential biases should be carefully considered. Ultimately, a well-designed hybrid approach can offer a powerful tool for achieving superior performance, enhanced robustness, and richer insights than any single methodology alone could provide. The key to success lies in justifying the choice of components, demonstrating their compatibility, and rigorously evaluating the overall system’s performance. Careful consideration of limitations and potential challenges is crucial for a credible and impactful contribution.
Dynamic Reduction#
Dynamic reduction, in the context of a multimodal large language model (MLLM) processing multiple images, is a crucial mechanism for managing computational complexity. The core idea is to selectively reduce the dimensionality of continuous visual feature sequences, which often become excessively long when multiple images are involved. This reduction is not arbitrary; it leverages the contextual information from discrete visual symbols and textual input to identify and retain only the most relevant and essential features. This selective approach prevents information overload and improves processing efficiency while preserving fine-grained detail. The dynamic nature of this reduction is key, ensuring that the model adapts to the specific information needs of each input, rather than using a fixed reduction strategy that may be suboptimal for various input types. The effectiveness of this dynamic approach hinges on a robust mechanism for identifying semantically relevant features. This could involve techniques such as attention mechanisms, ranking algorithms, or a combination thereof, to prioritize the most significant visual information before feeding it into the LLM.
Multi-stage Training#
A multi-stage training approach for multimodal large language models (MLLMs) is a valuable strategy to enhance performance, particularly in complex scenarios involving multiple images. Each stage focuses on a specific aspect of the model, allowing for more targeted optimization. For example, one stage might train a patch selector that identifies salient image regions. Another could refine the visual projector to align continuous visual features with the model’s semantic space. A further stage could leverage pre-trained models for initial weights, using transfer learning to accelerate learning and potentially improve generalization. A final stage might incorporate instruction tuning to enhance the model’s ability to follow instructions. This modular approach is advantageous as it allows for greater control over the training process and can help to mitigate issues such as vanishing gradients or overfitting that can arise in simpler training paradigms. The division into stages is critical for managing complexity and efficiently integrating different visual feature encodings (discrete and continuous). This approach also allows researchers to experiment with different model architectures and training techniques in a more systematic way. Finally, a multi-stage training regime can offer a way to address potential class imbalance and data heterogeneity issues through targeted stage-wise data augmentation and selection.
Benchmark Results#
The Benchmark Results section of a research paper is crucial for demonstrating the effectiveness and generalizability of a proposed method. A strong presentation would include detailed comparisons against state-of-the-art baselines on multiple established benchmarks. It should highlight superior performance on key metrics, ideally with statistically significant improvements, and offer clear visualizations like tables and graphs. The choice of benchmarks is vital; a comprehensive evaluation would include diverse datasets representing different scenarios and complexities, showing robustness beyond specific use cases. A thoughtful discussion of results would analyze not just the quantitative scores, but also the qualitative aspects, offering potential explanations for observed strengths and weaknesses and suggesting areas for future work. Limitations of the benchmark datasets themselves should also be addressed, acknowledging any potential biases or shortcomings that could affect the overall interpretation of the results. Finally, a robust analysis would involve ablative studies to isolate the effects of specific components of the model, demonstrating the actual contributions made by the proposed techniques.
More visual insights#
More on figures
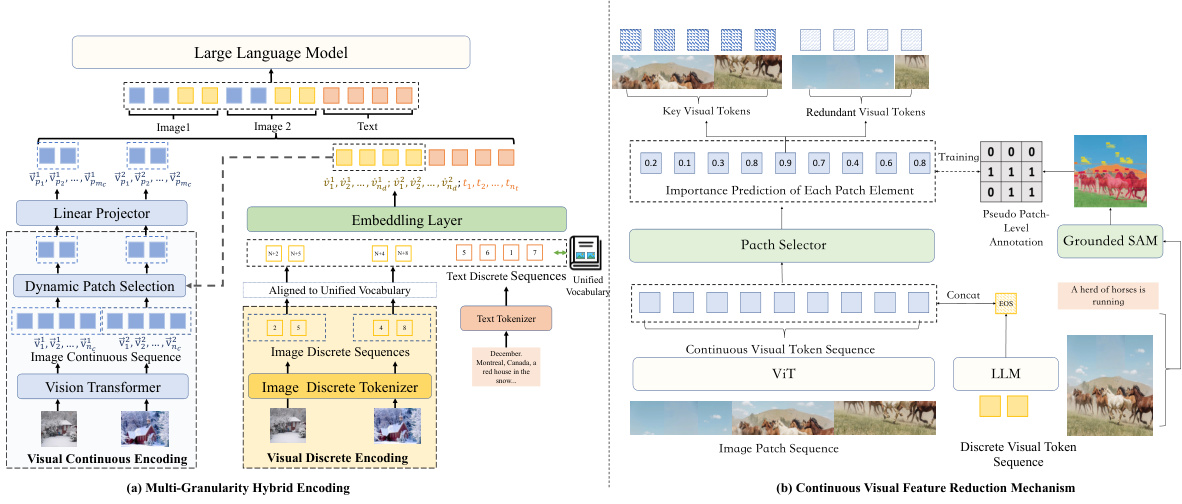
This figure shows the architecture of MaVEn, a multi-granularity hybrid visual encoding framework. (a) illustrates the hybrid encoding process combining discrete and continuous visual representations. Images are encoded using both a Vision Transformer (ViT) for continuous features and a discrete visual encoder (SEED) for discrete symbols. These are then aligned to a unified vocabulary before being input to the large language model. (b) details the dynamic reduction of continuous visual features. A patch selector, guided by text semantics, identifies and retains only the most relevant patches, reducing computational overhead and improving efficiency.
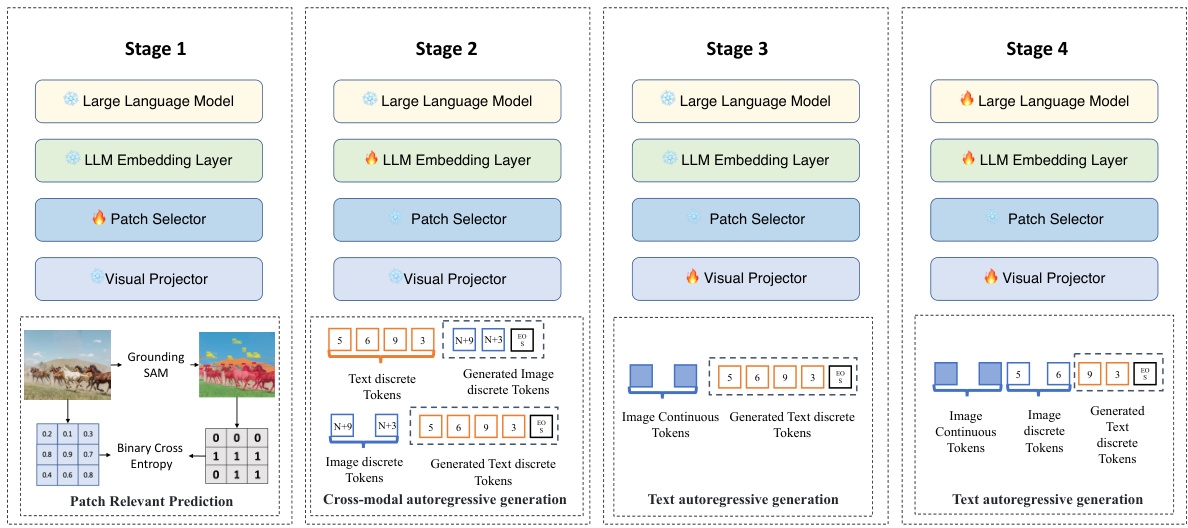
This figure illustrates the four-stage training process of the MaVEn model. Each stage focuses on training specific components while freezing others. Stage 1 trains the patch selector using Grounding SAM and image-text data. Stage 2 fine-tunes the LLM embedding layer to adapt to a unified multimodal vocabulary. Stage 3 trains the visual projector. Stage 4 performs instruction fine-tuning on the entire model.
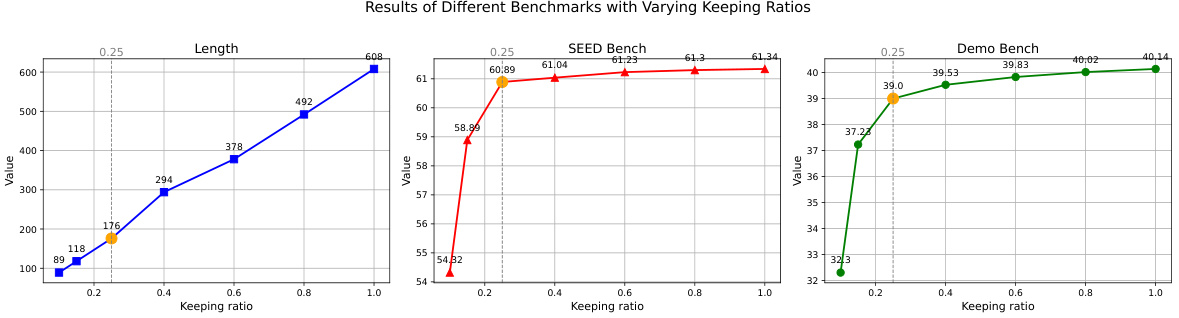
This figure shows the performance of MaVEn on different benchmarks (SEED-Bench, DEMONBench, VQA, and MMBench) while varying the ‘Keeping Ratio’ parameter. The Keeping Ratio controls the number of continuous visual tokens retained after a reduction mechanism. The graph displays how the model’s performance on various benchmarks changes as this ratio changes. Different colors represent different benchmarks, and the x-axis represents the Keeping Ratio, while the y-axis represents the performance metric (e.g., accuracy). It demonstrates the impact of the dynamic reduction mechanism on the efficiency and accuracy of MaVEn.
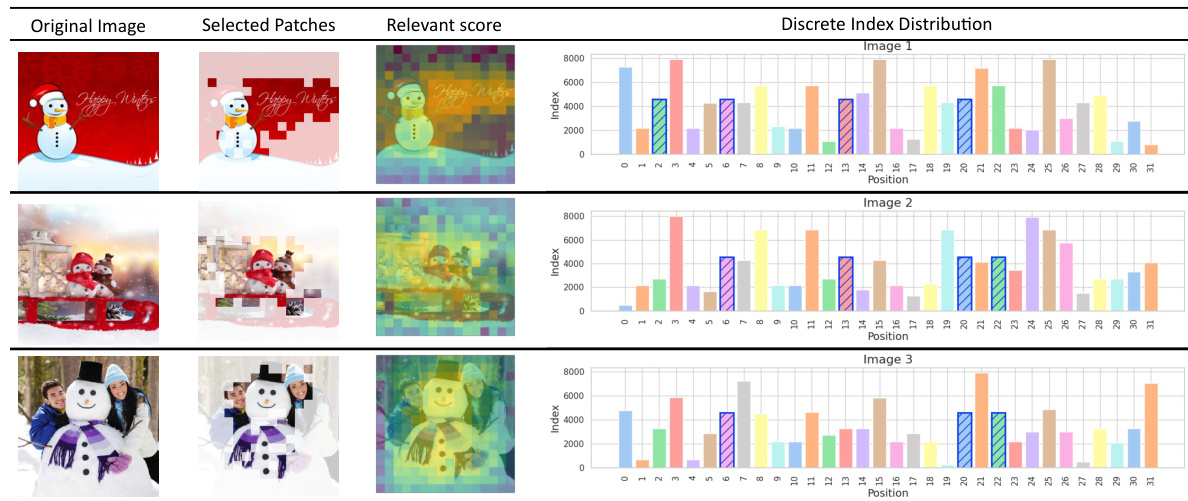
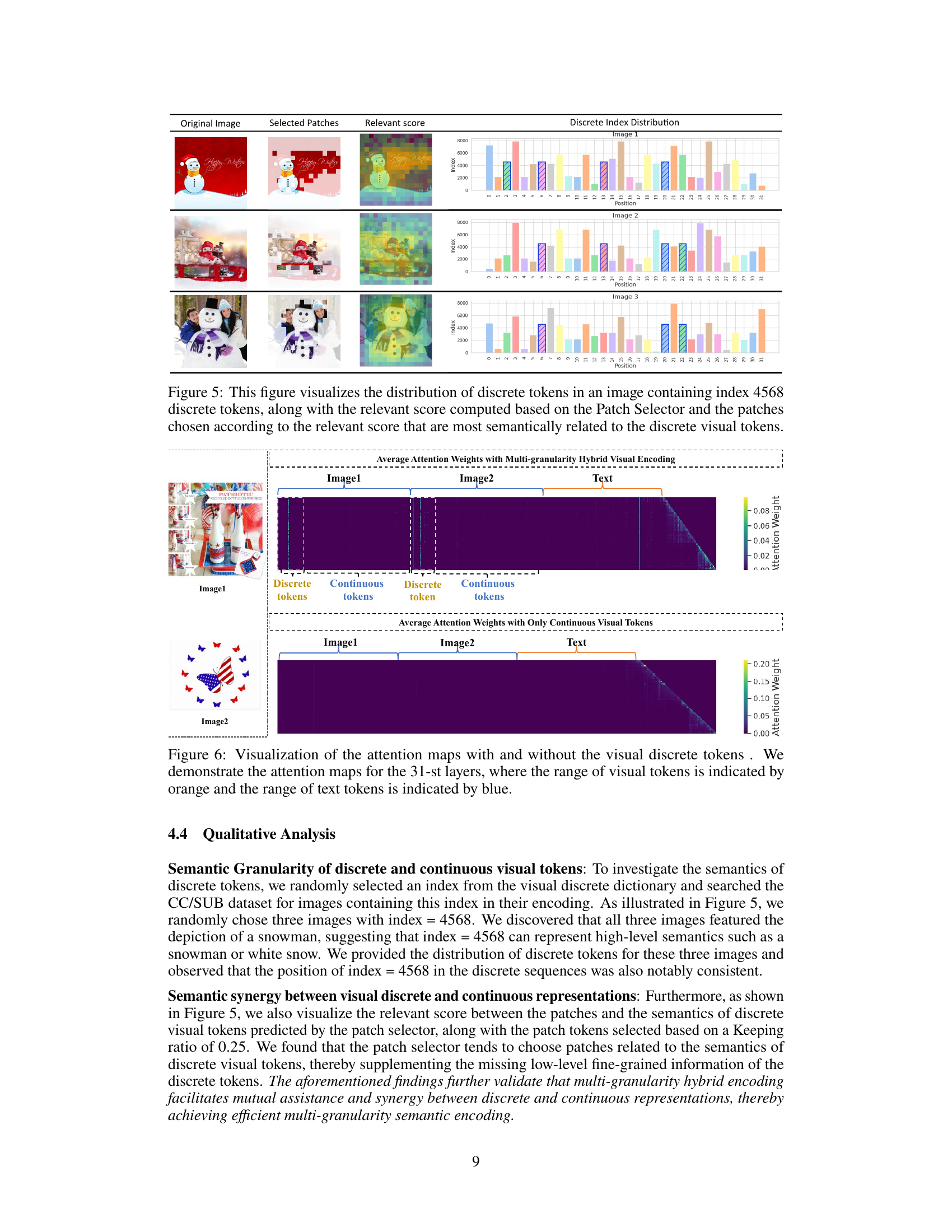
This figure shows the distribution of discrete tokens (visual vocabulary) in three example images. For each image, it displays the original image, the patches selected by the Patch Selector based on their semantic relevance to the discrete tokens, the relevance scores, and finally the distribution of those discrete tokens across the image’s patches. This illustrates the model’s ability to select semantically relevant patches based on the discrete token vocabulary, highlighting the multi-granularity approach of MaVEn.
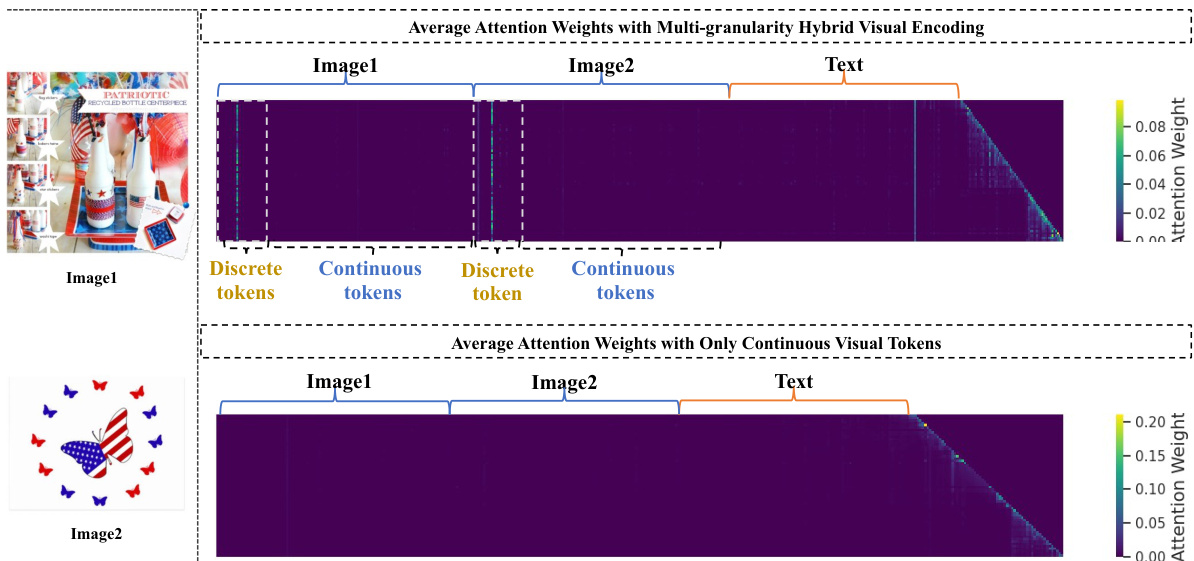
This figure compares attention maps from the 31st layer of the LLM when using both discrete and continuous visual tokens (top) versus only continuous visual tokens (bottom). The visualizations show how attention weights are distributed across image tokens (Image1 and Image2) and text tokens. The top image shows that with multi-granularity hybrid visual encoding, the model attends to both discrete and continuous visual tokens when answering multi-image questions. In contrast, the bottom image demonstrates that when using only continuous visual tokens, the model primarily focuses its attention on text tokens and largely ignores visual information.
More on tables

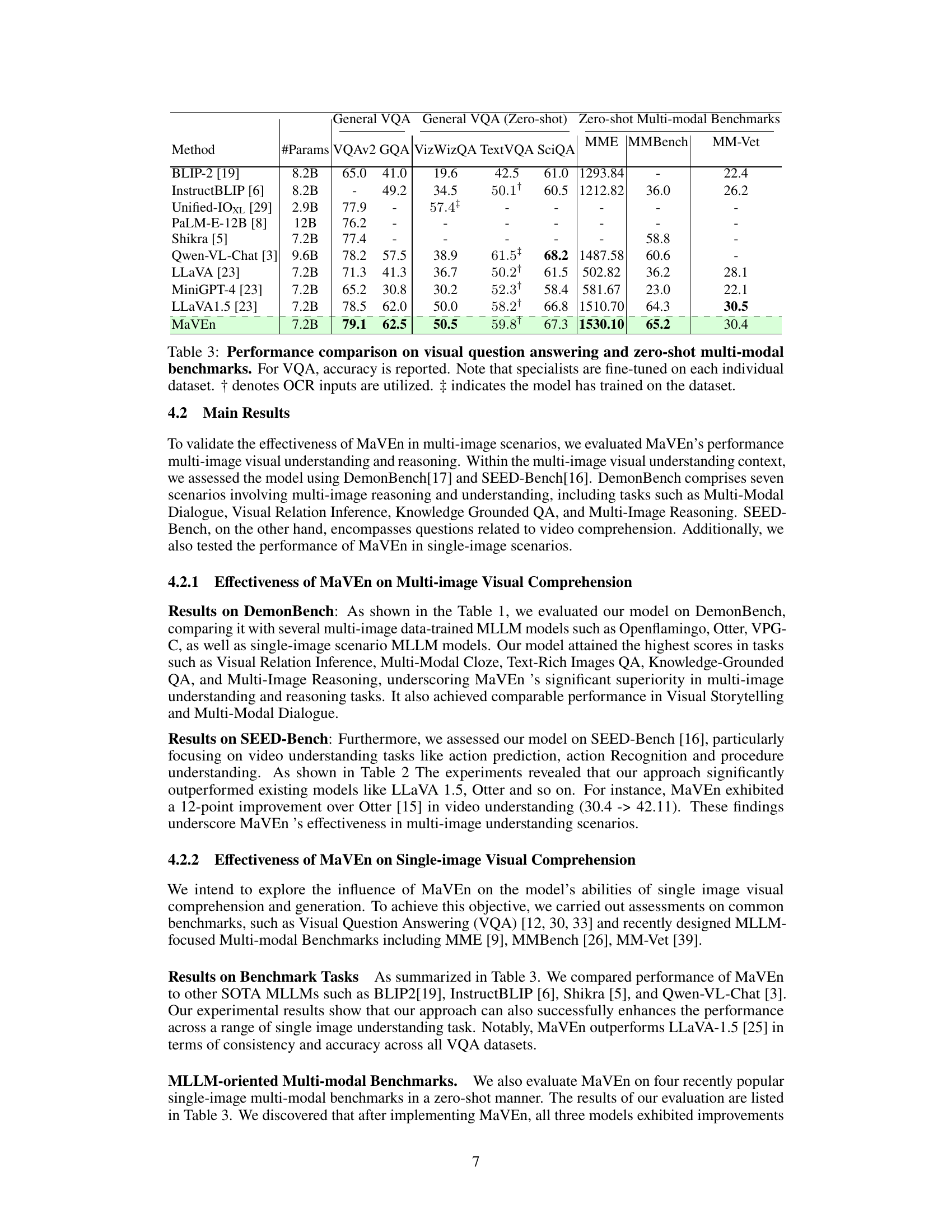
This table presents a comparison of different multimodal large language models (MLLMs) on the SEED benchmark, focusing on zero-shot evaluation. The benchmark assesses video understanding capabilities across various tasks. The table lists each model’s vision encoder, language model, average score across all tasks, average image understanding score, and average video understanding score. It shows MaVEn outperforms other models, particularly in video understanding.
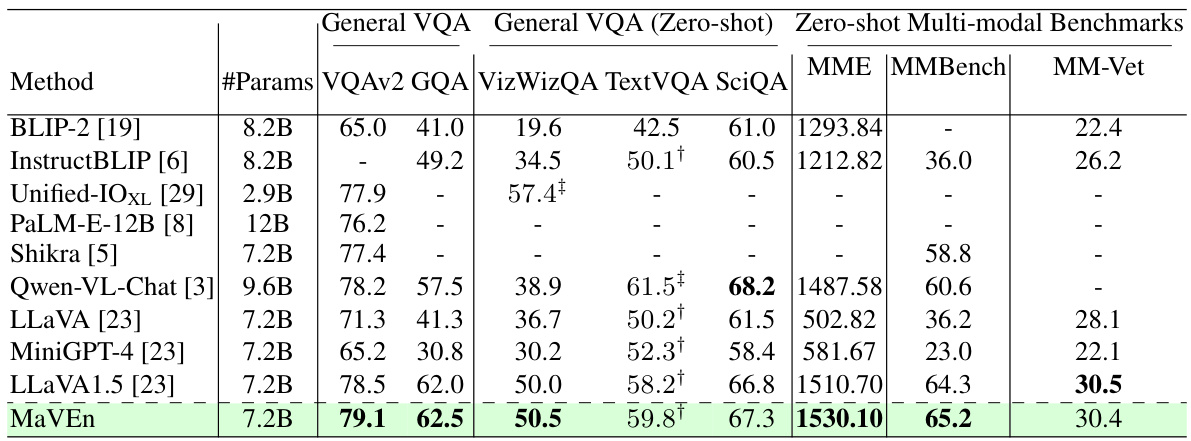
This table compares the performance of MaVEn against other state-of-the-art models on several visual question answering (VQA) benchmarks and multi-modal benchmarks. It shows the accuracy scores achieved by each model on various tasks, including VQAv2, GQA, VizWizQA, TextVQA, SciQA, MME, MMBench, and MM-Vet. The table also indicates whether OCR inputs were used or if the model was trained on the specific dataset.

This table presents the ablation study results, comparing the performance of MaVEn with different configurations of visual encoding (discrete only, continuous only, and both). The performance is evaluated on four benchmarks: SEED-Bench and DEMONBench for multi-image scenarios, and VQA and MMBench for single-image scenarios. It shows the impact of using discrete and/or continuous visual features on model performance.
Full paper#