TL;DR#
Human motion generation from text is challenging due to the complexity of human poses and the difficulty of accurately representing continuous movements. Existing methods often face issues such as approximation errors during quantization and loss of spatial relationships between joints. These limitations hinder the generation of realistic and high-quality motions.
MoGenTS tackles these issues head-on. It innovatively quantizes each individual joint into a vector, simplifying the quantization process and preserving spatial relationships. By arranging these vectors into a 2D token map, the model effectively leverages 2D operations like convolution and attention mechanisms, commonly used in image processing, to model spatial and temporal patterns simultaneously. The superior performance of MoGenTS on HumanML3D and KIT-ML datasets demonstrates the effectiveness of the proposed approach in generating high-fidelity human motions from textual descriptions. The novel 2D motion quantization and the spatial-temporal modeling framework are key contributions that improve both the accuracy and efficiency of human motion generation.
Key Takeaways#
Why does it matter?#
This paper is important because it significantly advances motion generation by proposing a novel spatial-temporal joint modeling approach. It addresses limitations of previous methods by improving motion quantization accuracy and leveraging the strengths of 2D operations for efficient and high-quality motion generation. This opens new avenues for research in areas like film making, gaming, and robotics, where realistic human motion synthesis is crucial. The improved method’s superior performance on benchmark datasets makes it highly relevant to the current research trends in human motion generation and inspires future research on efficient spatial-temporal modeling techniques.
Visual Insights#

🔼 This figure illustrates the overall framework of the proposed method. (a) shows the motion quantization process, where human motion is quantized into a 2D token map using a joint Vector Quantized Variational Autoencoder (VQ-VAE). (b) shows the motion generation process, which involves temporal-spatial 2D masking, followed by a spatial-temporal 2D transformer to predict the masked tokens and generate the motion sequence.
read the caption
Figure 1: Framework overview. (a) In motion quantization, human motion is quantized into a spatial-temporal 2D token map by a joint VQ-VAE. (b) In motion generation, a temporal-spatial 2D masking is performed to obtain a masked map, and then a spatial-temporal 2D transformer is designed to infer the masked tokens.
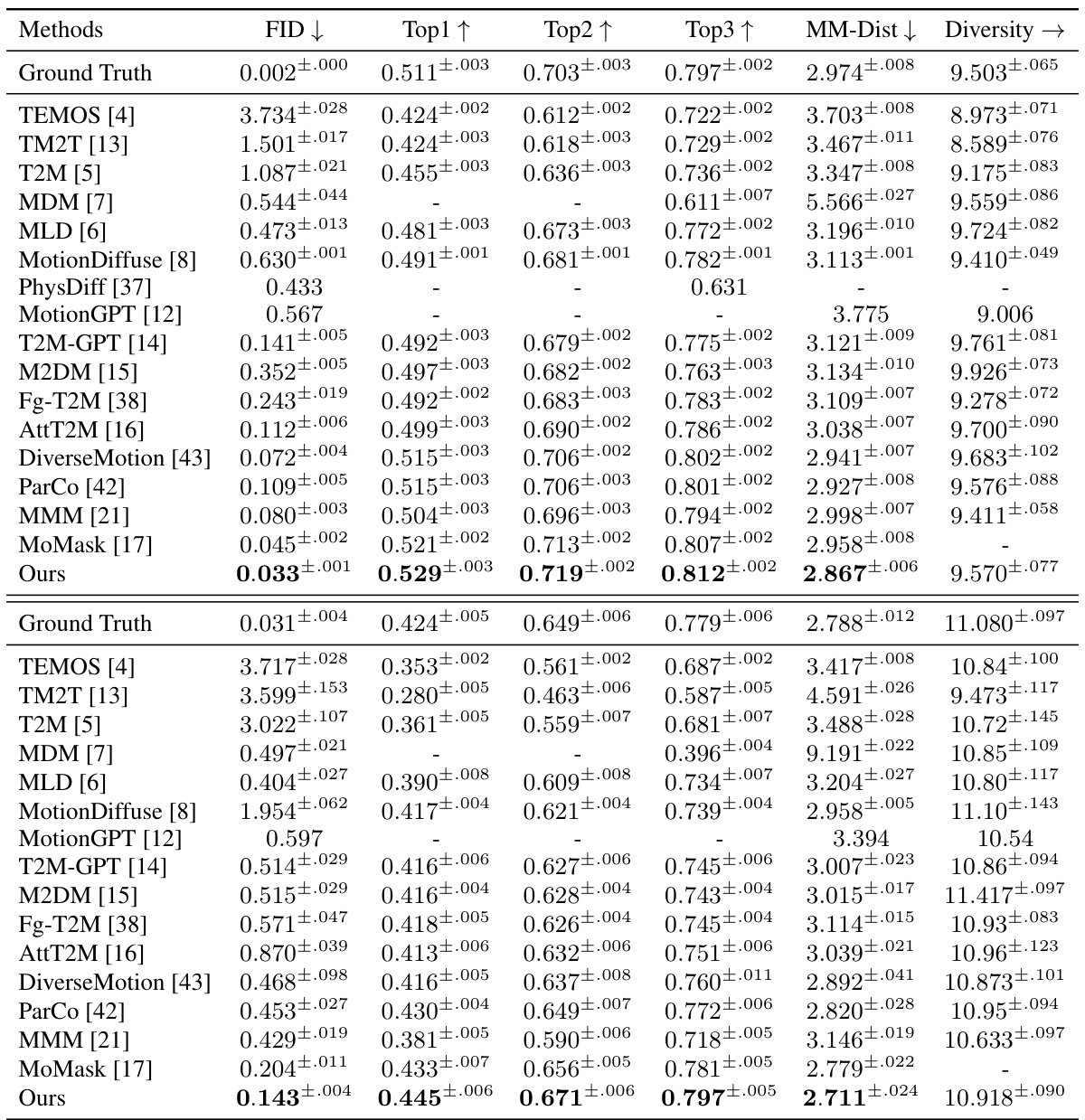
🔼 This table presents a comparison of the proposed MoGenTS model with several state-of-the-art methods for text-to-motion generation on two benchmark datasets: HumanML3D and KIT-ML. The evaluation metrics include FID (Frechet Inception Distance), Top-k accuracy (Top1, Top2, Top3, indicating how often the generated motion is ranked in the top k places relative to the ground truth motions given the text prompt), MM-Dist (MultiModal-Distance), and Diversity. Lower FID indicates better motion quality, while higher Top-k accuracy and Diversity indicate better text-motion alignment and motion variety, respectively. The results showcase MoGenTS’s superior performance compared to existing methods on both datasets.
read the caption
Table 1: Evaluation on the HumanML3D dataset (upper half) and the KIT-ML dataset (lower half).
In-depth insights#
2D Motion Quantization#
The concept of “2D Motion Quantization” presents a novel approach to representing human motion data. Instead of encoding the entire body pose into a single vector, each joint is individually quantized, resulting in a 2D token map where spatial relationships between joints and temporal dynamics are preserved. This method offers several key advantages. First, it simplifies the quantization process, reducing the complexity associated with encoding a complete pose. Second, it retains crucial spatial and temporal information, making it superior to methods that lose such relationships. This 2D structure allows the use of various 2D operations widely used in image processing, improving computational efficiency and feature extraction. The use of a 2D VQ-VAE further enhances the effectiveness by learning efficient representations of the joint movements. Overall, the 2D Motion Quantization technique provides a more refined and efficient approach to human motion representation for downstream tasks like motion generation and analysis.
Spatial-Temporal Model#
A spatial-temporal model integrates both spatial and temporal data to capture the dynamics of a system evolving over time and space. The core idea is to model interactions not just as isolated events, but as processes unfolding in a specific context. This requires representing data with both spatial coordinates (e.g., latitude/longitude, x/y coordinates) and timestamps. Effective modeling techniques often combine spatial and temporal features using methods such as convolutional neural networks (CNNs) for spatial aspects and recurrent neural networks (RNNs) or transformers for temporal dependencies. The model’s effectiveness hinges on the ability to learn patterns and relationships across both spatial and temporal dimensions. Challenges include the high dimensionality of spatiotemporal data and the computational demands of handling long sequences and large spatial regions. Successful applications leverage clever data representations, efficient architectures, and appropriate loss functions. Ultimately, spatial-temporal models are powerful tools for understanding and predicting complex dynamic systems across diverse domains.
Masked Motion Gen#
The heading ‘Masked Motion Gen’ suggests a method for generating motion data that incorporates masking techniques. This likely involves a process where parts of the motion sequence are masked or hidden, forcing a model to learn to predict or ‘fill in’ the missing information. This approach has several potential benefits. Masking could improve model robustness by preventing overfitting to specific parts of the input data. It could also help to learn more generalized motion representations, capturing underlying patterns rather than memorizing specific instances. The use of a generative model (implied by ‘Gen’) suggests the system likely uses a deep learning approach to create novel motion sequences that are both realistic and consistent with the masked portions. This could be especially useful in applications requiring motion completion, editing, or inpainting where masked regions need to be seamlessly filled in. A key area of focus is likely on the choice of masking strategy: Is it random, rule-based, or strategically targeted to specific parts of the motion, such as those deemed less important? The success of this ‘Masked Motion Gen’ will be measured by its ability to generate smooth, natural-looking motion data while correctly predicting missing parts. Finally, the effectiveness might be further analyzed by its efficiency, computational cost, and the quality of the generated motion compared to existing methods.
Ablation Study#
An ablation study systematically evaluates the contribution of individual components within a machine learning model. In the context of this motion generation model, the ablation study likely investigated the impact of key elements, such as the 2D joint VQ, temporal-spatial 2D masking, 2D positional encoding, and spatial-temporal 2D attention. By removing or modifying each component individually, researchers could quantify its effect on performance metrics like FID (Fréchet Inception Distance) and MPJPE (Mean Per-Joint Position Error). The results would reveal which components were crucial for achieving high accuracy and which ones offered marginal benefits. Identifying such dependencies highlights the architectural strengths and weaknesses, allowing for refined model designs and a deeper understanding of what drives model performance. A well-executed ablation study not only strengthens the model’s credibility but also offers valuable insights into the design principles and data-driven aspects of the proposed motion generation method.
Future Work#
The paper’s ‘Future Work’ section suggests several promising avenues. Improving the quantization process is paramount, aiming to reduce approximation errors inherent in representing continuous motion as discrete tokens. This could involve exploring more sophisticated quantization techniques or leveraging larger, higher-quality datasets for pre-training the quantization model. Another crucial area is enhancing the motion generation framework, potentially by incorporating more advanced attention mechanisms or exploring alternative architectures beyond the transformer model. Addressing limitations of the current masking strategy is also vital, perhaps through the development of more context-aware masking techniques that better preserve crucial spatial and temporal relationships within the motion data. Finally, the authors highlight the need for more extensive evaluation, considering a wider range of datasets and metrics, to provide a more robust assessment of the model’s capabilities and its generalizability.
More visual insights#
More on figures
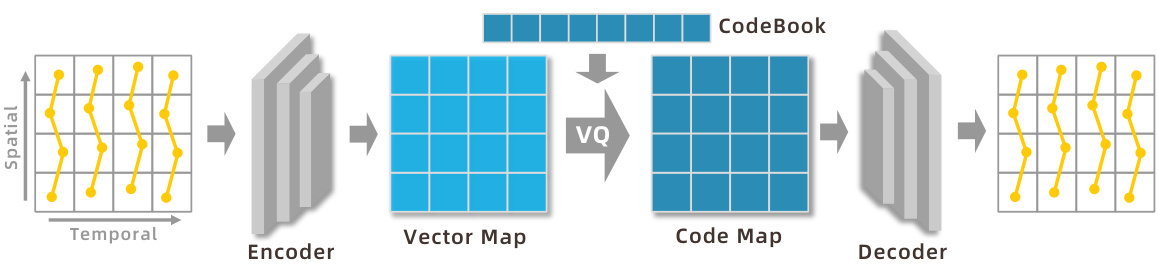
🔼 This figure illustrates the architecture of the spatial-temporal 2D Joint VQ-VAE used for motion quantization. The input is a motion sequence represented as a spatial-temporal 2D vector map. An encoder processes this map, converting it into a lower-dimensional representation. Vector Quantization (VQ) then maps these vectors to a discrete codebook, creating a code map. Finally, a decoder reconstructs the original motion from the code map. This process is designed to simplify the quantization, reduce approximation errors, and preserve the spatial relationships between joints.
read the caption
Figure 2: The structure of our spatial-temporal 2D Joint VQ-VAE for motion quantization. Independently. This not only makes the quantization task more tractable and reduces approximation errors, but also preserves crucial spatial information between the joints.

🔼 This figure illustrates the proposed framework for human motion generation. Part (a) shows the motion quantization process, where human motion is converted into a 2D token map by a joint Vector Quantized Variational Autoencoder (VQ-VAE). This 2D representation maintains spatial and temporal relationships between joints. Part (b) illustrates the motion generation process. A temporal-spatial 2D masking technique is applied to the 2D token map, creating a masked representation. A spatial-temporal 2D transformer then uses this masked data and text input to predict the masked tokens, generating a new motion sequence.
read the caption
Figure 1: Framework overview. (a) In motion quantization, human motion is quantized into a spatial-temporal 2D token map by a joint VQ-VAE. (b) In motion generation, a temporal-spatial 2D masking is performed to obtain a masked map, and then a spatial-temporal 2D transformer is designed to infer the masked tokens.
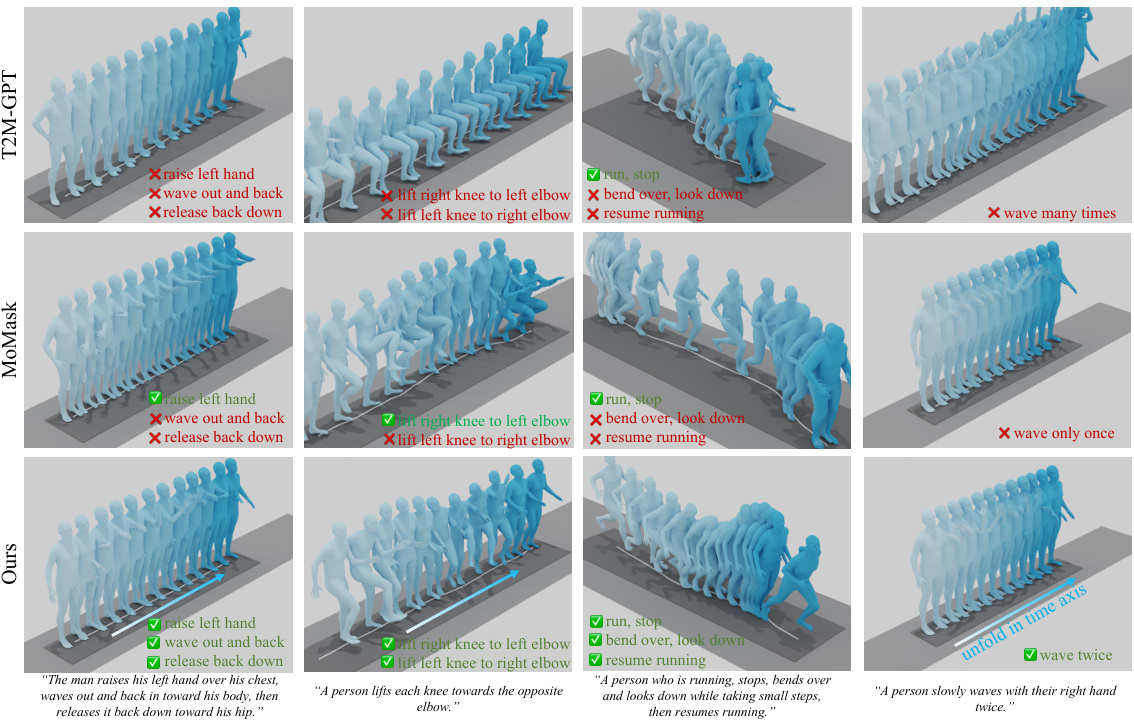
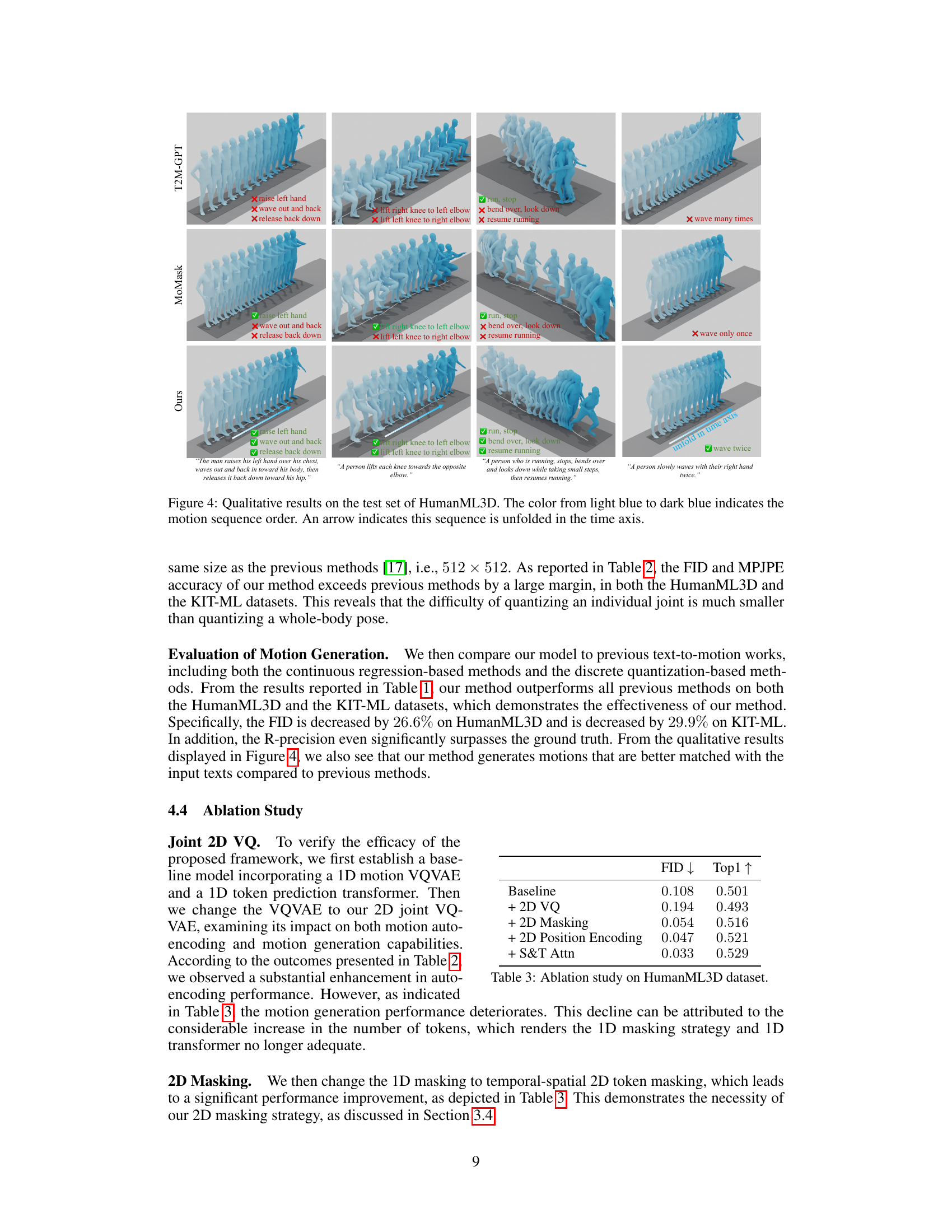
🔼 This figure shows several examples of motion sequences generated by three different methods: T2M-GPT, MoMask, and the proposed method. Each row represents a different text prompt, and the columns show the generated motion sequences. The color gradient from light blue to dark blue indicates the order of the frames in each sequence. An arrow indicates that the sequence is shown unfolded in time. The figure aims to demonstrate the qualitative differences in the generated motions, highlighting the superiority of the proposed method in generating more accurate and realistic motions aligning with the text prompt. It showcases the ability of the proposed method to generate smooth, natural movements consistent with the descriptions.
read the caption
Figure 4: Qualitative results on the test set of HumanML3D. The color from light blue to dark blue indicates the motion sequence order. An arrow indicates this sequence is unfolded in the time axis.

🔼 This figure demonstrates the motion editing capabilities of the proposed model. The leftmost image shows the original generated motion sequence. The middle image shows temporal editing, where a portion of the motion sequence has been replaced with a different sequence (indicated in green), altering the overall motion pattern. The rightmost image demonstrates both temporal and spatial editing, where not only the temporal sequence but also specific joints within the sequence are changed (again indicated in green). This showcases the model’s capacity to alter existing generated motions in both temporal and spatial domains.
read the caption
Figure 5: Motion Editing. The edited regions are indicated in green.

🔼 This figure shows qualitative results of motion generation for four different text prompts. The results from three different methods are compared: T2M-GPT, MoMask, and the authors’ method. Each row corresponds to one text prompt, and each column represents one of the four motions generated in response. The color gradient from light to dark blue indicates the temporal progression of the motion. An arrow indicates that the sequence of motions has been unfolded across the time axis, meaning the frames have been rearranged to emphasize the complete motion for each individual action.
read the caption
Figure 6: More qualitative results of our method are presented. The color from light blue to dark blue indicates the motion sequence order. An arrow indicates this sequence is unfolded in the time axis.

🔼 This figure illustrates the two main steps of the motion generation process in the MoGenTS model. (a) shows the temporal-spatial masking process, where frames are randomly masked in the temporal dimension, and then joints are randomly masked within the remaining frames in the spatial dimension. (b) shows the spatial-temporal attention mechanism, which consists of three types of attention: spatial-temporal 2D attention, joint spatial attention, and joint temporal attention. This mechanism takes into account both the spatial relationships between joints and the temporal sequence of motions.
read the caption
Figure 3: The temporal-spatial masking strategy (a) and the spatial-temporal attention (b) for motion generation.
More on tables
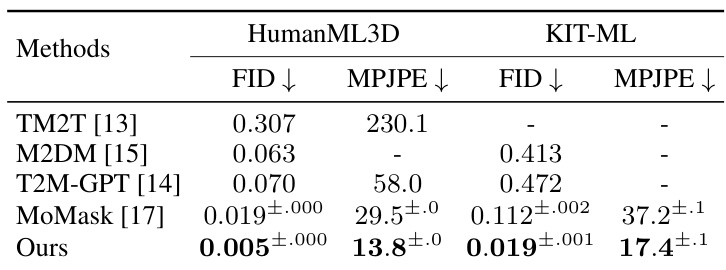
🔼 This table presents the quantitative results of the proposed MoGenTS model and compares it with several state-of-the-art methods on two benchmark datasets: HumanML3D and KIT-ML. The metrics used to evaluate the models’ performance are FID (Frechet Inception Distance), Top-1, Top-2, Top-3 accuracy (for text-to-motion retrieval), MM-Dist (MultiModal-Distance), and Diversity. Lower FID indicates better motion generation quality, while higher Top-k and Diversity scores indicate better alignment with text prompts and more diverse motion generation, respectively. The upper half of the table shows results for the HumanML3D dataset, while the lower half displays results for the KIT-ML dataset.
read the caption
Table 1: Evaluation on the HumanML3D dataset (upper half) and the KIT-ML dataset (lower half).
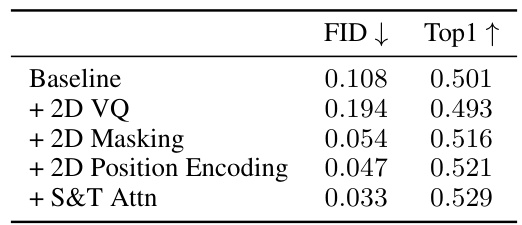
🔼 This table presents the ablation study results on the HumanML3D dataset, showing the impact of different components of the proposed model on FID and Top1 scores. It demonstrates the effectiveness of 2D VQ, 2D Masking, 2D Position Encoding, and Spatial and Temporal Attention in improving the model’s performance.
read the caption
Table 3: Ablation study on HumanML3D dataset.

🔼 This table presents the quantitative results of the proposed MoGenTS model and compares it with other state-of-the-art methods on two benchmark datasets: HumanML3D and KIT-ML. The metrics used for evaluation include FID (Frechet Inception Distance), which measures the similarity between generated and ground truth motion, Top1, Top2, and Top3 accuracy for text-to-motion alignment, MM-Dist (MultiModal Distance) representing the distance between text and motion features, and Diversity. Lower FID values indicate better generation quality; higher accuracy values are better for text-to-motion alignment; lower MM-Dist and higher diversity indicate better performance. The table shows that the MoGenTS model outperforms existing methods on both datasets across all metrics.
read the caption
Table 1: Evaluation on the HumanML3D dataset (upper half) and the KIT-ML dataset (lower half).

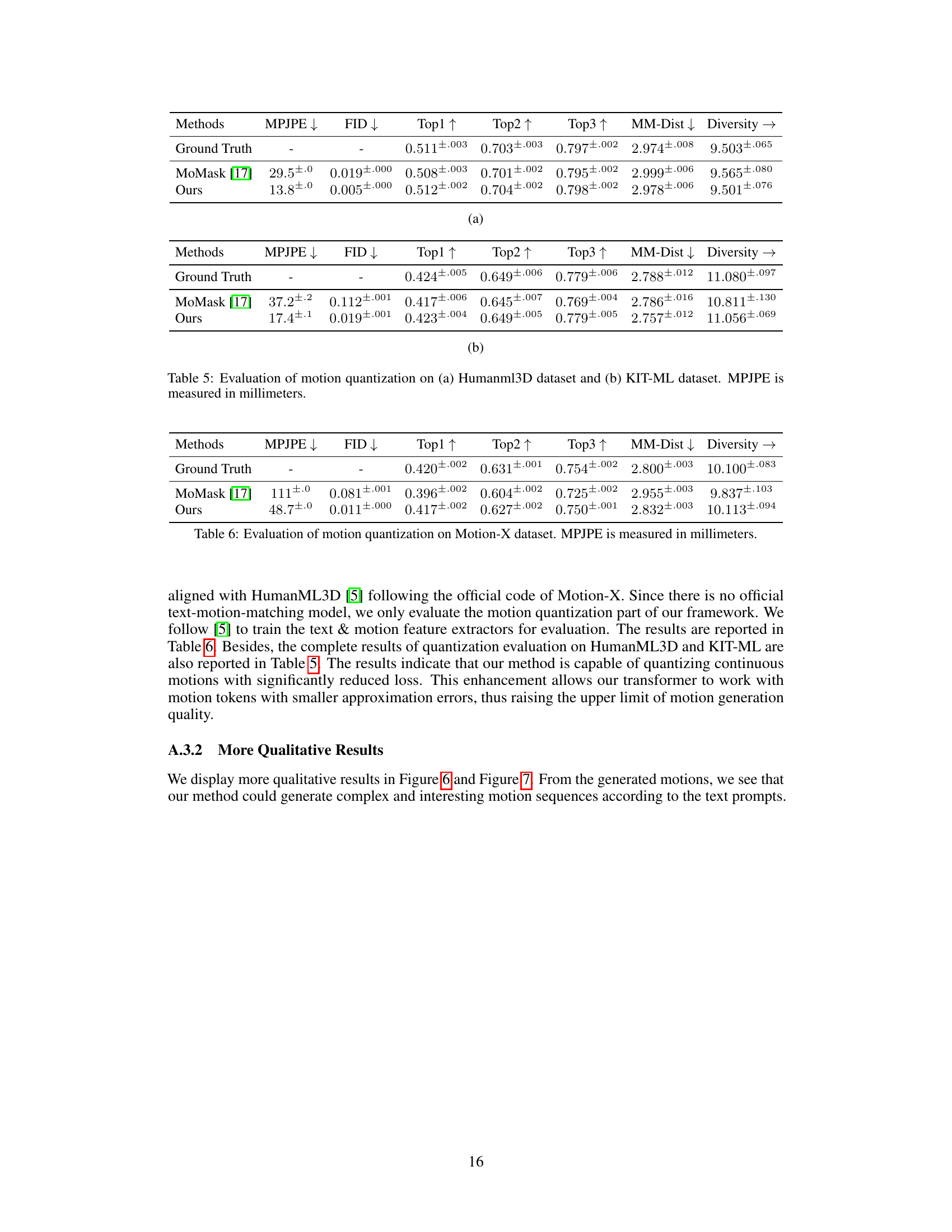
🔼 This table presents the results of motion quantization experiments on two datasets: HumanML3D and KIT-ML. The metrics used to evaluate the quality of the quantization are Mean Per Joint Position Error (MPJPE), Frechet Inception Distance (FID), and R-precision (Top1, Top2, Top3). Additionally, MultiModal Distance (MM-Dist) and Diversity are reported to show the overall performance of the quantization method. Lower MPJPE and FID values, along with higher R-precision values indicate better quantization performance.
read the caption
Table 5: Evaluation of motion quantization on (a) Humanml3D dataset and (b) KIT-ML dataset. MPJPE is measured in millimeters.

🔼 This table presents the quantitative results of the proposed MoGenTS model on HumanML3D and KIT-ML datasets. The upper half shows the results for HumanML3D, while the lower half shows the results for KIT-ML. For both datasets, the table compares the MoGenTS model against several state-of-the-art methods, evaluating performance using metrics like FID (Fréchet Inception Distance), Top1, Top2, Top3 (top-k accuracies), MM-Dist (MultiModal-Distance), and Diversity. Lower FID scores indicate better performance in motion generation, while higher values for Top-k, and Diversity suggest better motion generation accuracy and diversity. The MPJPE (Mean Per Joint Position Error) is also provided, measuring the accuracy of motion reconstruction.
read the caption
Table 1: Evaluation on the HumanML3D dataset (upper half) and the KIT-ML dataset (lower half).

🔼 This table presents the quantitative results of the proposed MoGenTS model on HumanML3D and KIT-ML datasets. The upper half shows the results for HumanML3D, while the lower half shows the results for KIT-ML. Each row represents a different method, including the ground truth, various state-of-the-art methods, and the proposed MoGenTS model. The columns present different evaluation metrics: FID (Fréchet Inception Distance), Top1, Top2, Top3 (R-precision at different thresholds), MM-Dist (MultiModal-Distance), and Diversity. Lower values for FID and MM-Dist and higher values for Top1, Top2, Top3 and Diversity indicate better performance. The table demonstrates the superior performance of MoGenTS compared to other methods in terms of both motion fidelity and diversity.
read the caption
Table 1: Evaluation on the HumanML3D dataset (upper half) and the KIT-ML dataset (lower half).
Full paper#