TL;DR#
Large language models based on Transformers are powerful but computationally expensive due to quadratic-time self-attention. Recent subquadratic models like SSMs offer faster inference, but lack the computational resources of their Transformer counterparts, resulting in comparatively weaker performance. This creates a need for methods that can transfer the powerful knowledge learned by large Transformers to these more efficient architectures.
The paper introduces MOHAWK, a three-phase distillation method to effectively transfer the knowledge from a pre-trained Transformer to a subquadratic SSM. MOHAWK tackles this by progressively matching different aspects of the Transformer architecture (mixing matrices, hidden units, and end-to-end predictions) within the SSM. The resulting distilled SSM model, called Phi-Mamba, significantly outperforms existing open-source non-Transformer models, despite using drastically less training data. This work demonstrates that leveraging knowledge from computationally expensive models can significantly boost the performance of more efficient alternatives.
Key Takeaways#
Why does it matter?#
This paper is highly important as it presents MOHAWK, a novel method that efficiently distils knowledge from large Transformer models into smaller, faster subquadratic models like SSMs. This significantly reduces training costs and improves the performance of subquadratic models, opening new avenues for research in efficient large language models. It also offers a new perspective on the relationship between Transformers and SSMs, paving the way for further exploration of their underlying mathematical connections.
Visual Insights#
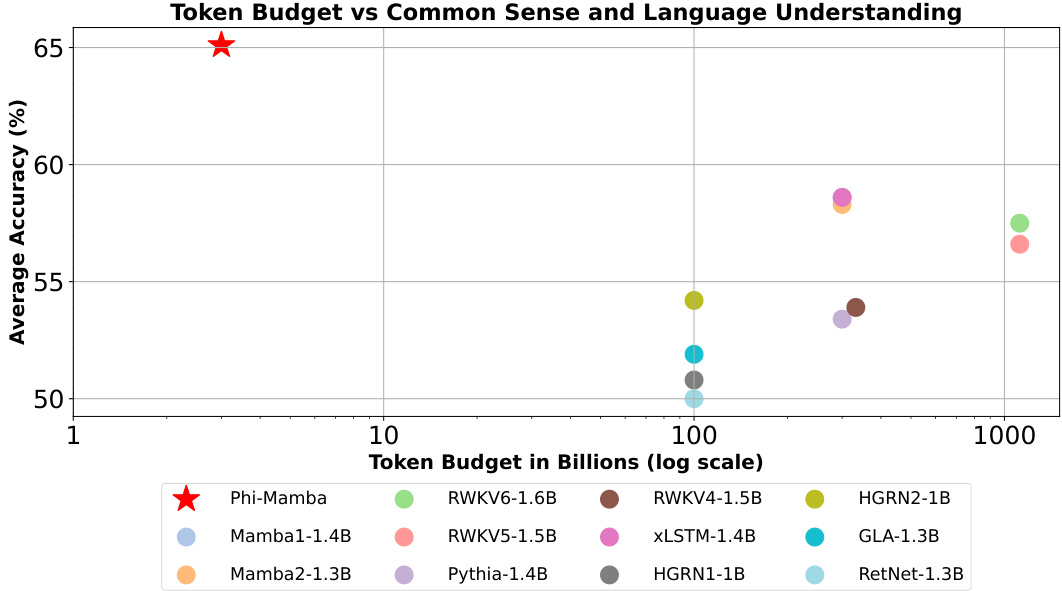
🔼 This figure shows a log-scale plot of the relationship between the number of tokens used for training language models and their average accuracy across five different benchmark datasets (Winogrande, Arc-E, Arc-C, PIQA, and Hellaswag). The plot includes various open-source language models, mostly those not based on transformer architectures. The key takeaway is that the Phi-Mamba model, developed by the authors, achieves significantly higher accuracy (5% better than the next best model) while using substantially fewer training tokens (more than 33 times less). This highlights the efficiency of the proposed distillation method.
read the caption
Figure 1: Plot of trained token budget to averaged accuracy on Winogrande, Arc-E, Arc-C, PIQA, and Hellaswag on various open-source models (mainly non-Transformer-based models). Our model (Phi-Mamba) uses more than 33× less token budget to achieve 5% higher average accuracy than the next best model.
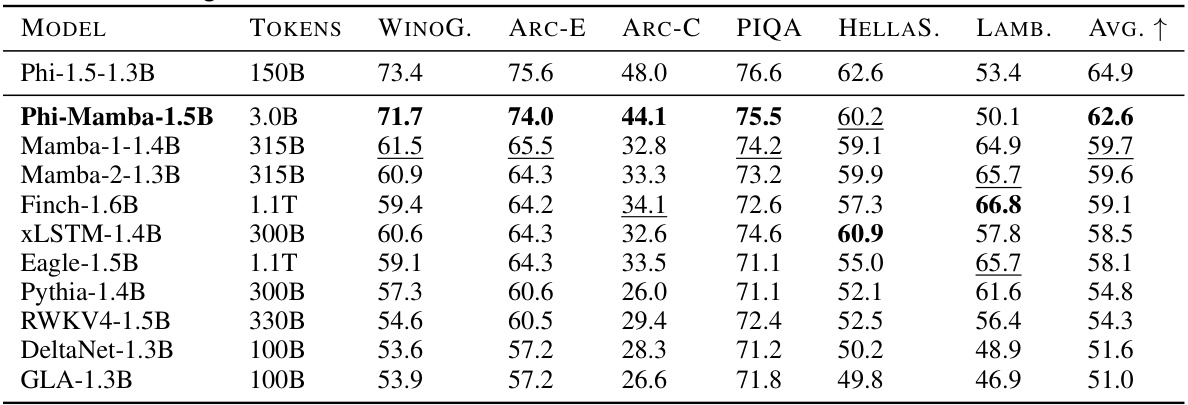
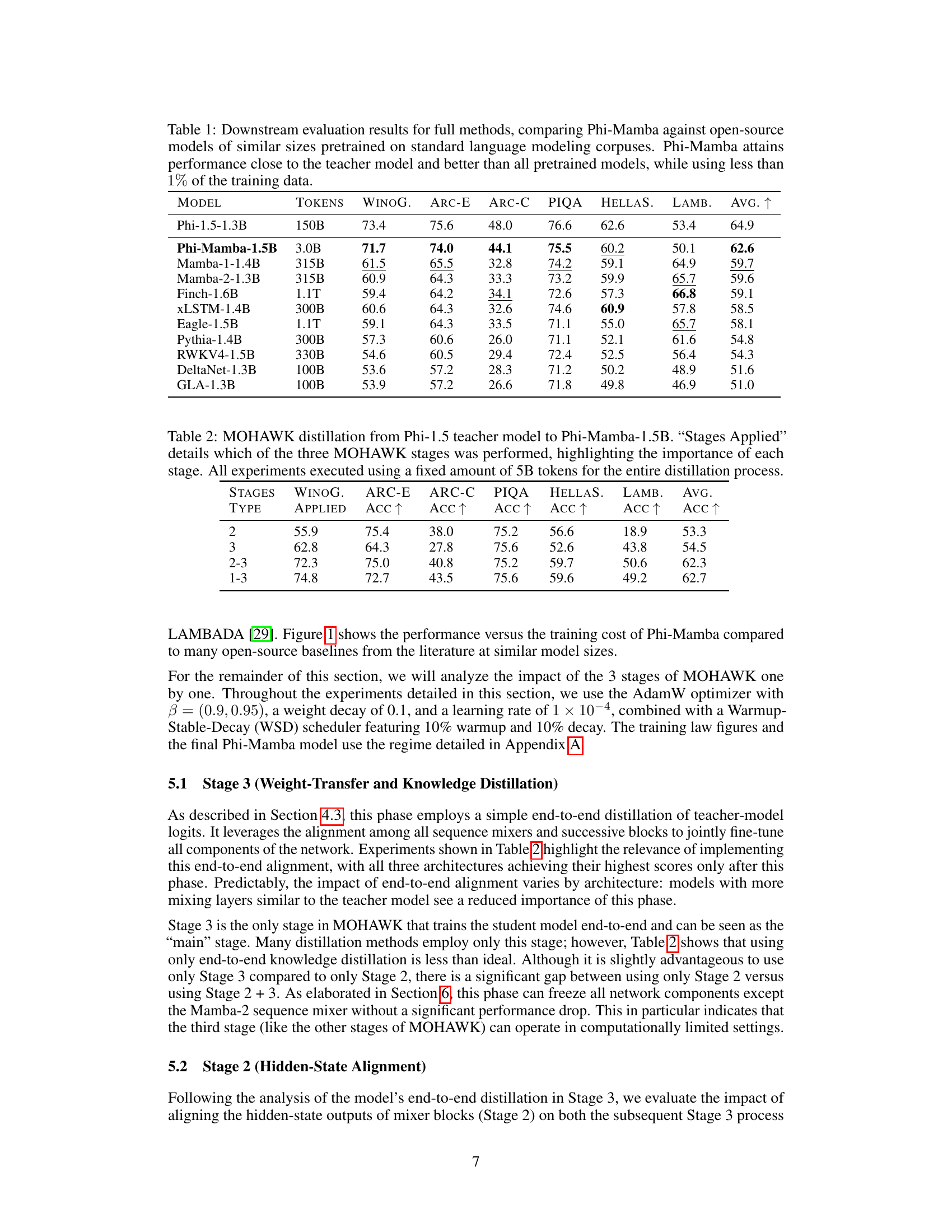
🔼 This table presents a comparison of the performance of various language models on several downstream tasks. The key model being evaluated is Phi-Mamba, a distilled model trained with significantly less data than the other models. The table shows that Phi-Mamba achieves comparable performance to the original (teacher) model and outperforms other open-source models of similar size. This highlights the effectiveness of the knowledge distillation approach used in training Phi-Mamba.
read the caption
Table 1: Downstream evaluation results for full methods, comparing Phi-Mamba against open-source models of similar sizes pretrained on standard language modeling corpuses. Phi-Mamba attains performance close to the teacher model and better than all pretrained models, while using less than 1% of the training data.
In-depth insights#
Quadratic Bottleneck#
The term “Quadratic Bottleneck” aptly describes a critical limitation in many Transformer-based models. The core issue stems from the quadratic complexity of self-attention, where computational cost scales proportionally to the square of the input sequence length. This rapidly becomes prohibitive for longer sequences, significantly impacting processing speed and memory requirements for tasks involving extensive contexts. Addressing this bottleneck is paramount for advancing the field, as it restricts the handling of long-range dependencies and limits the potential of Transformer architectures. Solutions range from approximating self-attention mechanisms to exploring alternative architectures altogether, each with trade-offs between accuracy, efficiency and scalability. Overcoming this quadratic limitation is key to unlocking the true potential of Transformers and enabling breakthroughs in diverse applications such as very long-context natural language processing and more complex sequence modeling tasks.
MOHAWK Distillation#
MOHAWK distillation is a novel three-phase approach for effectively transferring knowledge from a large pretrained Transformer model to a smaller, more efficient subquadratic model, specifically a variant of the Mamba architecture. Phase 1 (Matrix Orientation) focuses on aligning the sequence transformation matrices, ensuring similar mixing behavior. Phase 2 (Hidden-State Alignment) matches the hidden-state representations at each block, preserving learned features. Finally, Phase 3 (Weight-Transfer and Knowledge Distillation) fine-tunes the entire model, leveraging the teacher’s knowledge. This progressive approach allows for significant performance gains even with limited training data, showcasing the potential to leverage pre-trained Transformer resources for enhanced subquadratic model development. The key insight is viewing both Transformers and SSMs as applying different mixing matrices to token sequences, enabling this efficient knowledge transfer.
Phi-Mamba Model#
The Phi-Mamba model represents a significant advancement in efficient large language models. It leverages knowledge distillation from a powerful Transformer-based model (Phi-1.5) to a more computationally efficient architecture, Mamba-2. This hybrid approach allows Phi-Mamba to achieve strong performance with a substantially reduced training data budget, demonstrating the effectiveness of the MOHAWK distillation framework. Key to its success is the three-phase distillation process: aligning mixing matrices, aligning hidden states, and finally performing end-to-end knowledge distillation. This structured approach to knowledge transfer enables Phi-Mamba to overcome the limitations of training large-scale subquadratic models from scratch, thus highlighting a promising path for future efficient language model development.
Ablation Studies#
Ablation studies systematically remove components of a model to assess their individual contribution. In this context, removing different stages of the MOHAWK distillation process (matrix orientation, hidden-state alignment, knowledge distillation) would reveal the impact of each stage on the final model’s performance. A successful ablation study would show a clear performance degradation when removing any single stage, demonstrating the importance of each component. Furthermore, analyzing the effects of removing combinations of stages could unveil potential synergistic interactions between different components. The results could quantitatively highlight the relative contributions of each stage, and also guide future model designs by focusing on components which offer the highest improvements in performance.
Future Directions#
Future research could explore several promising avenues. Improving the efficiency of the distillation process is crucial, potentially through the development of more sophisticated loss functions or more advanced training techniques. Investigating alternative subquadratic architectures beyond SSMs, such as those based on linear attention mechanisms or other efficient sequence transformations, could reveal additional opportunities for knowledge transfer from Transformer models. Exploring the applicability of MOHAWK to other modalities, such as images or audio, would significantly broaden its impact. Finally, a deeper understanding of how different architectural choices in the student model affect the distillation process would allow for more informed and targeted model design, enabling the creation of even more powerful and efficient subquadratic models. This might involve analyzing the interplay between different model components and identifying key architectural elements crucial for successful knowledge distillation.
More visual insights#
More on figures
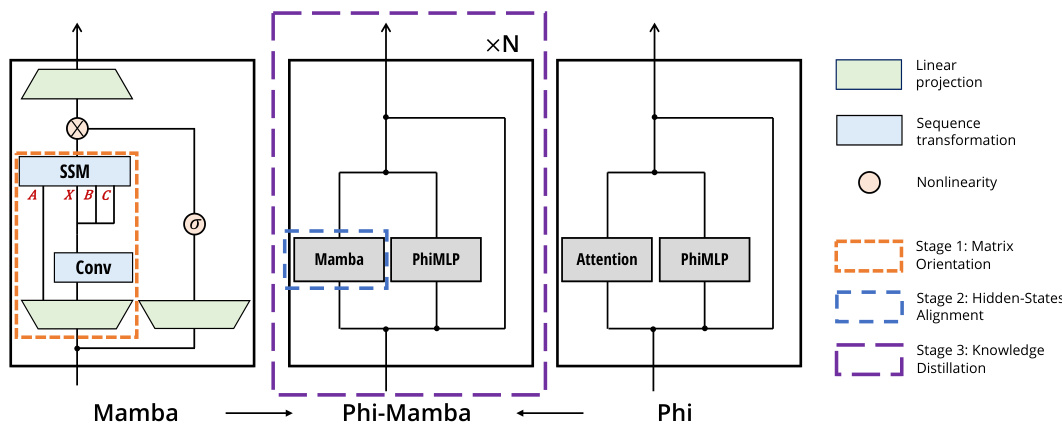
🔼 This figure illustrates the Phi-Mamba architecture, a hybrid model combining elements of Mamba and Phi-1.5 Transformer models. It shows the structure of a single block, composed of a simplified Mamba block and an MLP block. The figure also highlights the three stages of the MOHAWK distillation process: matrix orientation (aligning the mixing matrices), hidden-state alignment (aligning the hidden states at each block), and knowledge distillation (end-to-end fine-tuning).
read the caption
Figure 2: The Phi-Mamba architecture consists of a stack of blocks, each of which contains a Mamba block and an MLP block. The Mamba block is a simplified version of the Mamba-2 block [8] that omits the non-linear activation function after the convolutional operation and the layer normalization present before the output projection, so that the parts of the model outside the matrix mixer can be transferred from the teacher model. The MOHAWK distillation process involves progressively matching fine-to-coarse parts of the model to the corresponding part of the teacher model: (1) the mixer mixer itself (2) the full Mamba vs. Attention blocks, and (3) the end-to-end model.

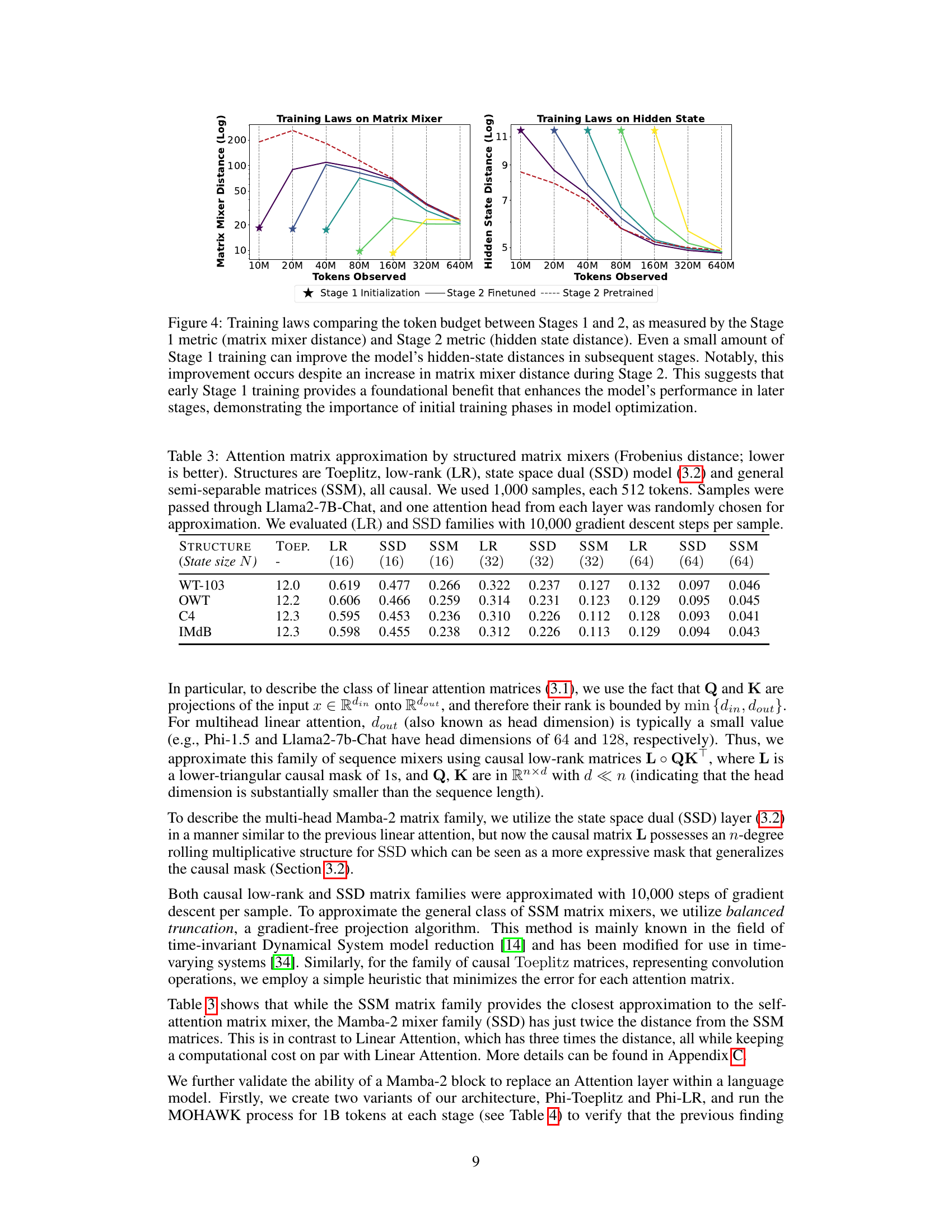
🔼 This figure shows the training curves for hidden state distance (left) and perplexity (right) during different training stages. It compares the performance of models initialized with Stage 2 weights and those trained from scratch with knowledge distillation. The results demonstrate the effectiveness of the proposed three-stage distillation approach.
read the caption
Figure 3: Training laws comparing the token budget between Stages 2 and 3, as measured by the Stage 2 metric (hidden state distance) and Stage 3 metric (perplexity). Stage 2 initializations are used as the starting checkpoint for their respective Stage 3 finetuning models. Stage 3 pretrained is trained from scratch only with weight transfer and knowledge distillation. Despite training for less tokens on Stage 3 than the Stage 3 from scratch, almost all Stage 2 initialized models eventually outperform the baseline in perplexity on a fixed budget. In general, better aligned Stage 2 initializations improve post-Stage 3 performance.

🔼 This figure shows the training laws for Stage 2 (hidden state distance) and Stage 3 (perplexity) of the MOHAWK method. It compares models initialized with various amounts of Stage 2 training and then finetuned in Stage 3, to models trained from scratch using only weight transfer and knowledge distillation. The results demonstrate that better alignment in Stage 2 leads to improved performance in Stage 3, even with fewer training tokens.
read the caption
Figure 3: Training laws comparing the token budget between Stages 2 and 3, as measured by the Stage 2 metric (hidden state distance) and Stage 3 metric (perplexity). Stage 2 initializations are used as the starting checkpoint for their respective Stage 3 finetuning models. Stage 3 pretrained is trained from scratch only with weight transfer and knowledge distillation. Despite training for less tokens on Stage 3 than the Stage 3 from scratch, almost all Stage 2 initialized models eventually outperform the baseline in perplexity on a fixed budget. In general, better aligned Stage 2 initializations improve post-Stage 3 performance.

🔼 This figure displays the training laws, showing the relationship between the token budget and the average accuracy across multiple downstream evaluation metrics. It compares three different training approaches: Stage 2 initialization (using the weights from Stage 2 as a starting point for Stage 3), Stage 3 finetuned (fine-tuning the model from scratch using only Stage 3), and Stage 3 pretrained (training the model entirely from scratch). The zoomed-in portion highlights the performance differences at larger token budgets. The results illustrate the benefit of aligning the hidden state outputs before the final fine-tuning stage.
read the caption
Figure 5: Training laws comparing the amount of token budget between Stages 2 and 3, as measured by the average accuracy of downstream evaluation metrics.
More on tables
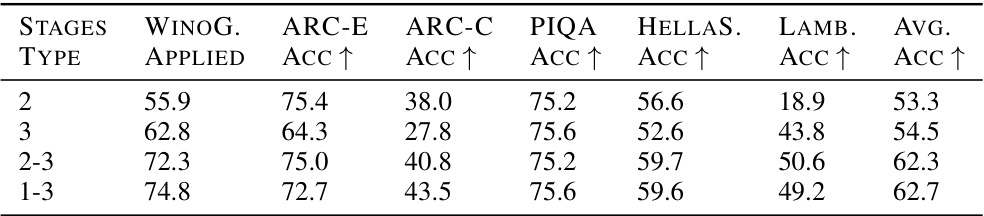
🔼 This table presents the results of applying different stages of the MOHAWK distillation process. It shows the impact of each stage on several downstream tasks, highlighting the importance of using all three stages for optimal performance. A fixed token budget was used across all experiments.
read the caption
Table 2: MOHAWK distillation from Phi-1.5 teacher model to Phi-Mamba-1.5B. 'Stages Applied' details which of the three MOHAWK stages was performed, highlighting the importance of each stage. All experiments executed using a fixed amount of 5B tokens for the entire distillation process.

🔼 This table shows the Frobenius distance between self-attention matrices from Llama2-7B-Chat and their approximations using different structured matrix families: Toeplitz, low-rank, state-space dual (SSD), and semi-separable matrices (SSM). Lower values indicate better approximation quality. The experiment used 1000 samples of 512 tokens each, and the (LR) and SSD families were optimized using 10,000 gradient descent steps.
read the caption
Table 3: Attention matrix approximation by structured matrix mixers (Frobenius distance; lower is better). Structures are Toeplitz, low-rank (LR), state space dual (SSD) model (3.2) and general semi-separable matrices (SSM), all causal. We used 1,000 samples, each 512 tokens. Samples were passed through Llama2-7B-Chat, and one attention head from each layer was randomly chosen for approximation. We evaluated (LR) and SSD families with 10,000 gradient descent steps per sample.

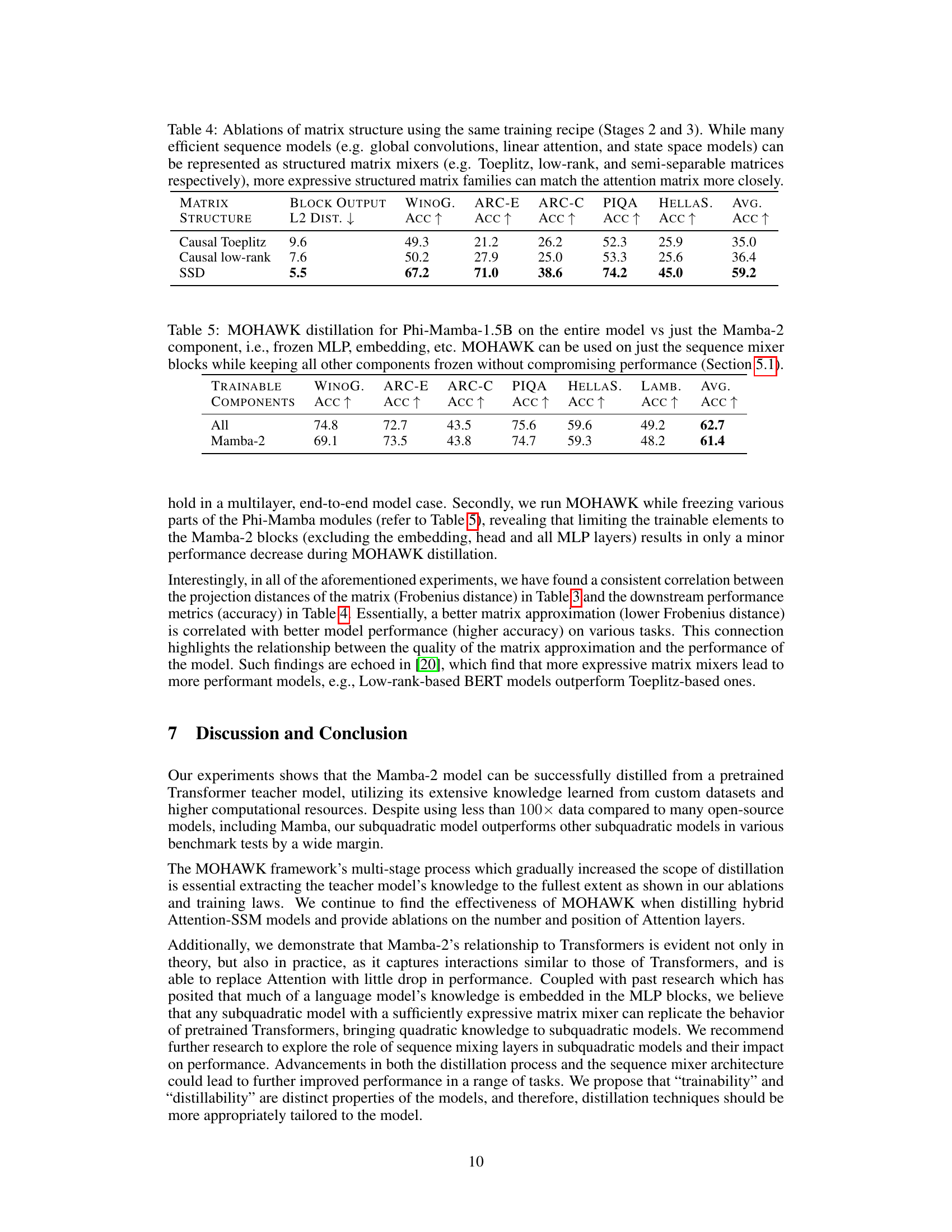
🔼 This table presents an ablation study comparing different matrix structures (Toeplitz, low-rank, SSD, and semi-separable) used in the Phi-Mamba model’s sequence mixer. It shows that more expressive structures, like the semi-separable matrices, better approximate the original Transformer’s attention matrix, leading to improved performance on downstream tasks (Winogrande, ARC-E, ARC-C, PIQA, HellaSwag). The L2 distance metric quantifies the difference between the student model’s matrix mixer and the teacher model’s attention matrix. Lower L2 distance implies a better approximation.
read the caption
Table 4: Ablations of matrix structure using the same training recipe (Stages 2 and 3). While many efficient sequence models (e.g. global convolutions, linear attention, and state space models) can be represented as structured matrix mixers (e.g. Toeplitz, low-rank, and semi-separable matrices respectively), more expressive structured matrix families can match the attention matrix more closely.

🔼 This table compares the performance of Phi-Mamba-1.5B model when fine-tuning the entire model versus only the Mamba-2 component using the MOHAWK method. It shows that MOHAWK can be effectively applied by only fine-tuning the sequence mixer blocks while keeping other components frozen, demonstrating the method’s efficiency and modularity.
read the caption
Table 5: MOHAWK distillation for Phi-Mamba-1.5B on the entire model vs just the Mamba-2 component, i.e., frozen MLP, embedding, etc. MOHAWK can be used on just the sequence mixer blocks while keeping all other components frozen without compromising performance (Section 5.1).
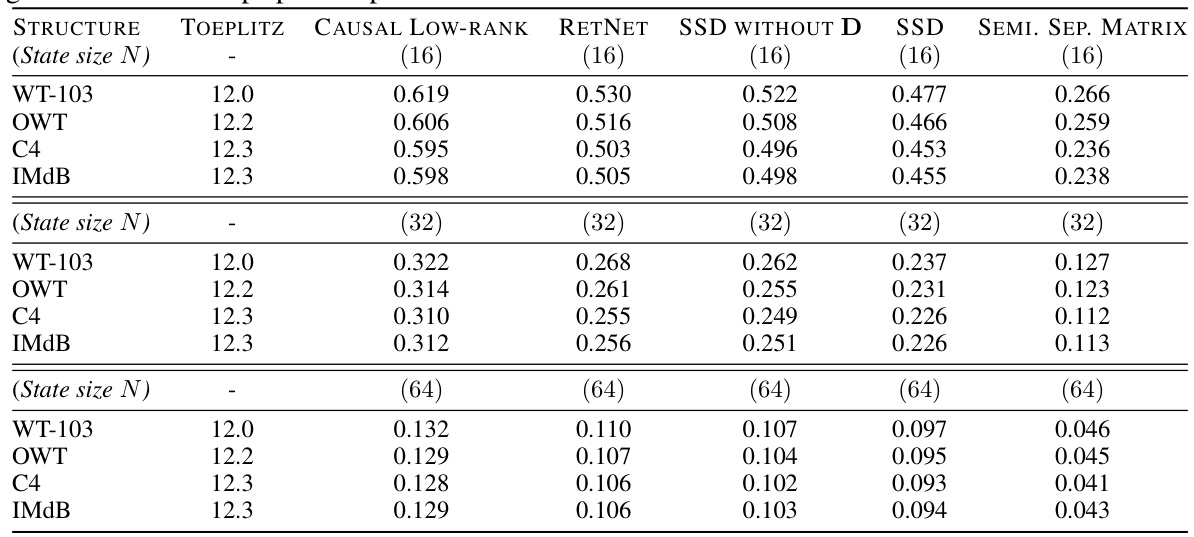
🔼 This table presents the results of approximating attention matrices using various structured matrix families. The Frobenius distance, a measure of the difference between the original attention matrix and its approximation, is used to evaluate the quality of each approximation method. Lower Frobenius distances indicate better approximations. The table compares Toeplitz, low-rank (LR), state space dual (SSD), and general semi-separable matrices (SSM) for their ability to approximate attention matrices. The results are averaged across all layers of a Llama2-7B-Chat model.
read the caption
Table 3: Attention matrix approximation by structured matrix mixers (Frobenius distance; lower is better). Structures are Toeplitz, low-rank (LR), state space dual (SSD) model (3.2) and general semi-separable matrices (SSM), all causal. We used 1,000 samples, each 512 tokens. Samples were passed through Llama2-7B-Chat, and one attention head from each layer was randomly chosen for approximation. We evaluated (LR) and SSD families with 10,000 gradient descent steps per sample.

🔼 This table presents a comparison of the Phi-Mamba model’s performance against other open-source language models on various downstream tasks. It shows that Phi-Mamba, despite being trained with significantly less data (less than 1% of the training data used for other models), achieves comparable or better performance than other models of similar size on tasks such as Winogrande, ARC-E, ARC-C, PIQA, HellaSwag, and LAMBADA. This highlights the effectiveness of the knowledge distillation method used in the paper.
read the caption
Table 1: Downstream evaluation results for full methods, comparing Phi-Mamba against open-source models of similar sizes pretrained on standard language modeling corpuses. Phi-Mamba attains performance close to the teacher model and better than all pretrained models, while using less than 1% of the training data.

🔼 This table presents a comparison of the Phi-Mamba model’s performance against several other open-source language models on various downstream tasks. These tasks assess common sense reasoning and language understanding capabilities. The key takeaway is that Phi-Mamba, despite being trained with significantly less data (less than 1% of the others), achieves comparable or superior performance to the other models. This highlights the effectiveness of the knowledge distillation method used to train Phi-Mamba.
read the caption
Table 1: Downstream evaluation results for full methods, comparing Phi-Mamba against open-source models of similar sizes pretrained on standard language modeling corpuses. Phi-Mamba attains performance close to the teacher model and better than all pretrained models, while using less than 1% of the training data.

🔼 This table compares the performance of the Phi-Mamba model (trained using the MOHAWK method) against other open-source language models on several downstream tasks. The key takeaway is that Phi-Mamba achieves comparable or better performance than models trained with significantly more data (over 100x more tokens). The tasks assessed include commonsense reasoning and language understanding.
read the caption
Table 1: Downstream evaluation results for full methods, comparing Phi-Mamba against open-source models of similar sizes pretrained on standard language modeling corpuses. Phi-Mamba attains performance close to the teacher model and better than all pretrained models, while using less than 1% of the training data.
Full paper#