TL;DR#
Prior research on human behavior modeling often focused on either implicit (early-stage) or explicit (later-stage) behaviors in isolation, and usually limited to specific visual content types. This limitation hindered the development of comprehensive models that capture the full spectrum of human responses to visual stimuli. A unified approach is crucial for numerous applications such as UI/UX design and content optimization.
This paper introduces UniAR, a unified model that addresses these limitations. UniAR uses a multimodal transformer to predict both implicit behaviors (attention heatmaps, viewing sequences) and explicit behaviors (subjective preferences). Trained on diverse public datasets, UniAR achieves state-of-the-art performance across multiple benchmarks spanning various image domains and behavior tasks. Its ability to handle diverse data types and tasks makes it a highly versatile tool with wide-ranging applications.
Key Takeaways#
Why does it matter?#
This paper is highly important as it presents UniAR, a unified model that significantly advances human behavior modeling. By achieving state-of-the-art results across diverse visual content and tasks, it offers valuable tools for UI/UX design, content creation, and other applications requiring an understanding of human attention and preferences. It also opens new avenues for research into multimodal models and cross-domain generalization.
Visual Insights#

🔼 The figure provides a high-level overview of the UniAR model, a multimodal model designed to predict human attention and responses to visual content. The left side shows example inputs (images, web pages, etc.) and their corresponding outputs (saliency heatmaps, scanpaths, and ratings). The right side details the model architecture, illustrating how image and text inputs are processed through a transformer encoder to generate the various outputs. The caption highlights the model’s unique ability to unify the prediction of both implicit (early-stage perceptual) and explicit (later-stage decision-making) human behavior, a significant advancement in the field.
read the caption
Figure 1: Overview of our UniAR model. UniAR is a multimodal model that takes an image (could be a natural image, screenshot of a webpage, graphic design, or UI) along with a text prompt as input, and outputs heatmaps of human attention/interaction, scanpath or sequence of viewing/interaction, and subjective preference/likes. Example inputs and corresponding outputs for saliency, scanpath, and rating are shown on the left side, and the detailed model architecture is shown on the right side. To the best of our knowledge, a unified approach is still missing to modeling human visual behavior, ranging from implicit, early-perceptual behavior of what draws human attention, to explicit, later-stage decision-making on subjective preferences or likes.
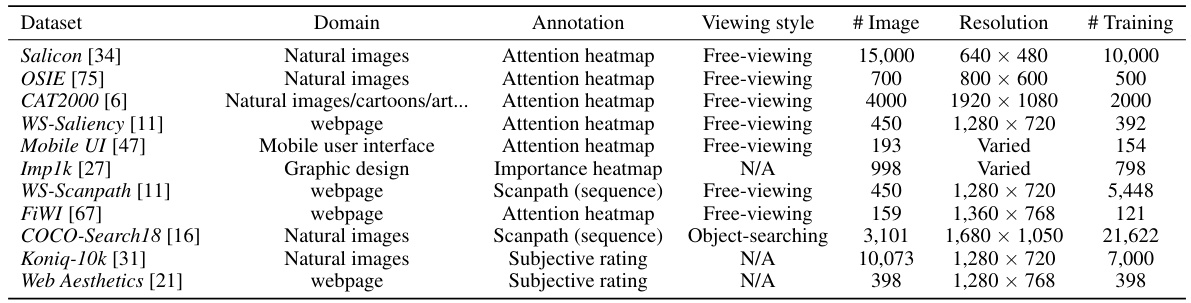
🔼 This table lists eleven publicly available datasets used to train the UniAR model. Each dataset is characterized by its domain (e.g., natural images, webpages), the type of annotation provided (attention heatmap, scanpath, subjective rating), the viewing style used for data collection (free-viewing or object-searching), the number of unique images, the image resolution, and the number of training samples. Note that the number of training samples for scanpath datasets is significantly higher than the number of images because multiple scanpaths are recorded per image.
read the caption
Table 1: List of all public datasets used to train our model. '# Image' denotes the number of unique images in the entire dataset. Note that for annotation 'scanpath', there are multiple scanpaths recorded from a group of users associated with one image, so '# Training Sample' is much larger than '# Image'. During training, we randomly sample from all training datasets with an equal sampling rate.
In-depth insights#
UniAR Model#
The UniAR model represents a significant advancement in multimodal visual behavior prediction. Its unified architecture, leveraging a transformer to process both image and textual data, allows it to effectively predict various aspects of human attention and response, such as saliency, scanpath, and subjective preferences. This multi-tasking capability across diverse visual content domains (natural images, webpages, graphic designs) is a key strength, surpassing the limitations of previous models that were typically limited to a single task or domain. The model’s generalization ability is highlighted by its performance on multiple benchmarks, often exceeding state-of-the-art results. While there are acknowledged limitations, particularly around handling unseen data and the inherent complexities of human perception, the UniAR model stands as a robust and promising approach for numerous applications, particularly in UI/UX design and content creation, where immediate feedback on design effectiveness can drastically improve the human experience.
Unified Approach#
A unified approach in this context likely refers to the model’s ability to handle diverse visual content and predict various human behaviors from a single framework. Instead of separate models for each task (like saliency prediction or preference prediction) and content type (like natural images or webpages), a unified model offers increased efficiency and generalizability. This approach is particularly valuable because human attention and preferences are deeply intertwined and influenced by multiple factors, making a holistic model potentially more accurate and insightful. The success of this unified approach hinges on the model’s architecture which needs to be flexible enough to adapt to various input modalities and output types. Multimodal transformers, for instance, are well-suited for this purpose. However, a unified approach also presents challenges; training data must be diverse enough to capture the complexity of these multifaceted relationships, while ensuring sufficient samples for every behavior and content combination to prevent overfitting. It is also crucial to carefully evaluate the model’s performance not only on tasks and datasets seen during training, but also on unseen ones, to demonstrate true generalizability and avoid biases inherent to specific datasets.
Experimental Setup#
An ideal experimental setup for evaluating a visual attention prediction model like UniAR would involve diverse and representative datasets encompassing various visual content types (natural images, webpages, graphic designs, etc.) and behavior types (saliency heatmaps, scanpaths, aesthetic ratings). Careful data preprocessing is crucial, addressing issues like resolution inconsistencies and ensuring appropriate sampling techniques for balanced representation across datasets. The setup should include rigorous evaluation metrics that are well-established and appropriate for the various task types. Careful handling of evaluation metrics including those used for saliency prediction (e.g., AUC-Judd, NSS, CC), scanpath prediction (e.g., SequenceScore, MultiMatch) and aesthetic rating prediction (e.g., SRCC, PLCC) should also be considered, potentially using multiple metrics per task for a more comprehensive assessment. Finally, the experimental setup must ensure reproducibility by including detailed specifications of model architecture, hyperparameters, training procedures, and data splits to enable replication and validation of findings.
Future Work#
The authors acknowledge the limitations of their current model and propose several avenues for future research. Addressing ethical considerations related to AI bias and responsible AI practices in the context of human preference prediction is a crucial next step. They plan to develop methods for more accurately modeling diverse human preferences, including personalized models, to overcome the limitations of a single, unified model. The use of more representative datasets that capture a wider range of demographics and user experiences is highlighted, along with techniques for adapting the model to evolving preferences using continual learning methods. Finally, they suggest extending the model to incorporate diverse interaction modalities for enhanced accessibility and improved representation of users with diverse needs. These future directions showcase a commitment to responsible innovation and the creation of a truly inclusive and human-centric AI system.
Limitations#
The research paper’s limitations section would critically discuss the model’s reliance on specific datasets and the potential for bias introduced by these datasets’ inherent characteristics. The study acknowledges that generalizability might be limited due to this reliance. The methodology’s evaluation metrics, while standard in the field, may not fully capture all aspects of human attention and preference. The zero-shot generalizability experiments, although promising, are still subject to limitations, given they only test performance on unseen combination of tasks and domains. Finally, the study’s scope does not encompass all aspects of human behavior, thus limiting the extent of the conclusions that can be drawn. Addressing these limitations would strengthen the research.
More visual insights#
More on figures
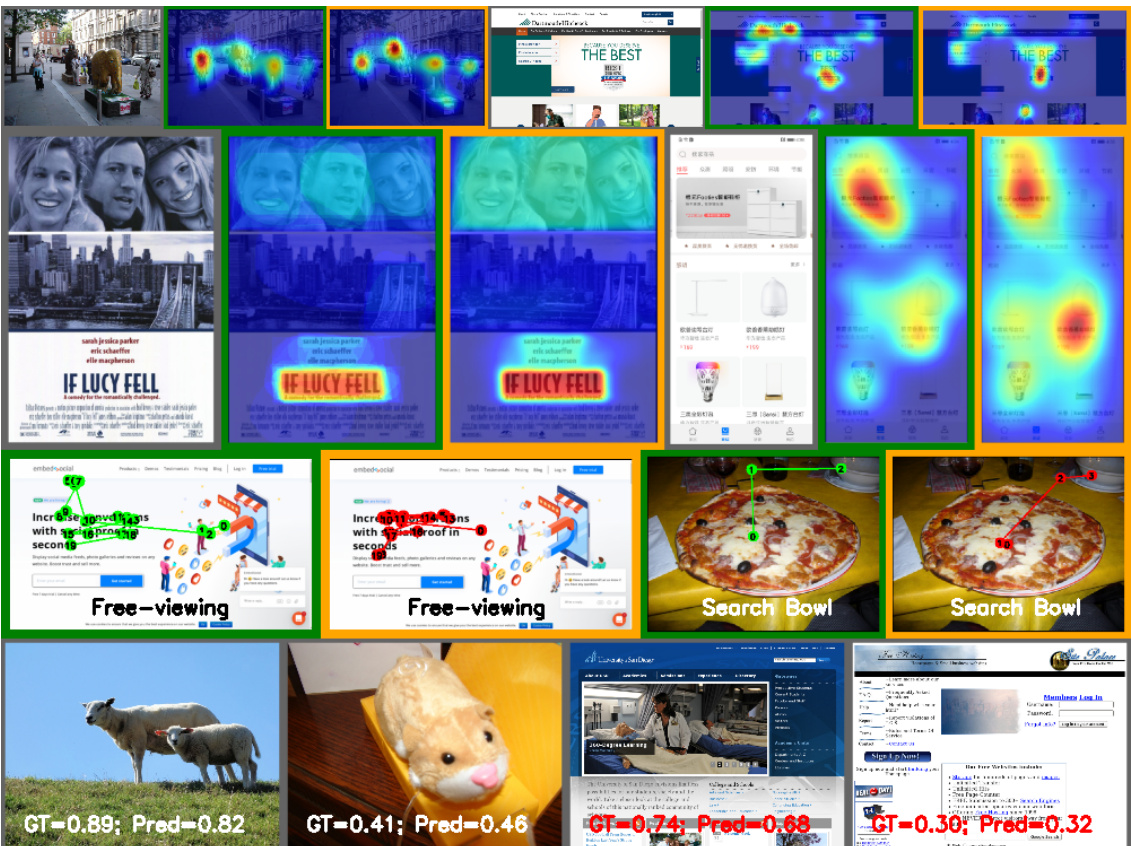
🔼 This figure showcases examples of UniAR’s predictions across various tasks and data domains. Each row demonstrates a different task: saliency heatmap prediction, importance heatmap prediction, scanpath prediction, and rating prediction. Within each row, the left image shows the ground truth and the right image shows UniAR’s prediction for the same input image. This highlights the model’s ability to generalize across different types of visual content and prediction tasks.
read the caption
Figure 2: Examples of UniAR's predictions across different tasks/domains. Images in green border are ground-truth, while images in orange border are UniAR's predictions. First row: attention/saliency heatmap prediction on natural images (Salicon) and webpages (WS-Saliency). Second row: importance heatmap on graphic designs (Imp1k), and saliency heatmap on Mobile UI. Third row: scanpath-sequence during free-viewing of webpages (WS-Scanpath) and object-searching within images (COCO-Search18). Fourth row: preference/rating prediction for natural images (Koniq-10k) and webpages (Web Aesthetics).

🔼 This figure shows more examples of UniAR’s predictions across different tasks and datasets. It visually compares the model’s output (orange border) against ground truth (green border) for various visual content types. The rows represent different tasks: saliency heatmaps, importance heatmaps, scanpaths (sequences of eye movements), and rating predictions. Each column shows results for a specific dataset, indicating the model’s performance across various scenarios.
read the caption
Figure 3: Another set of visualizations on UniAR's predictions. Images in green border are ground-truth, while images in orange border are UniAR's predictions. First row: saliency heatmap on Salicon and WS-Saliency. Second row: importance heatmap on Imp1k, and saliency heatmap on Mobile UI. Third row: free-viewing scanpath on WS-Scanpath and object-searching scanpath on COCO-Search18. Fourth row: rating prediction on Koniq-10k and Web Aesthetics datasets.
More on tables
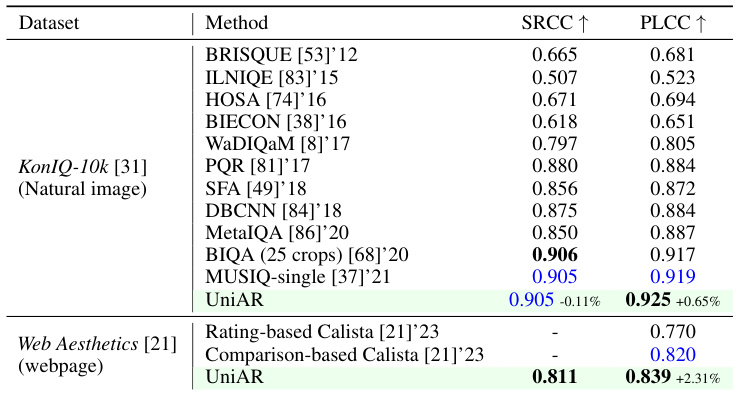
🔼 This table presents the results of subjective rating prediction on two datasets: KonIQ-10k (natural images) and Web Aesthetics (webpages). It compares the performance of UniAR against several state-of-the-art (SOTA) methods using SRCC and PLCC metrics, which measure the rank correlation and Pearson linear correlation between predicted and ground truth ratings, respectively. The table shows that UniAR achieves competitive or superior performance to the existing SOTA models on these two datasets.
read the caption
Table 2: Subjective rating prediction results on Natural image image dataset KonIQ-10k and webpage dataset Web Aesthetics.

🔼 This table presents the performance of the UniAR model and other state-of-the-art models on heatmap prediction tasks across seven different datasets. The datasets cover various image types (natural images, art, cartoons, mobile UIs, webpages) and tasks (saliency and importance heatmaps). The table shows the results for multiple evaluation metrics, highlighting UniAR’s performance relative to the best-performing models for each dataset and metric.
read the caption
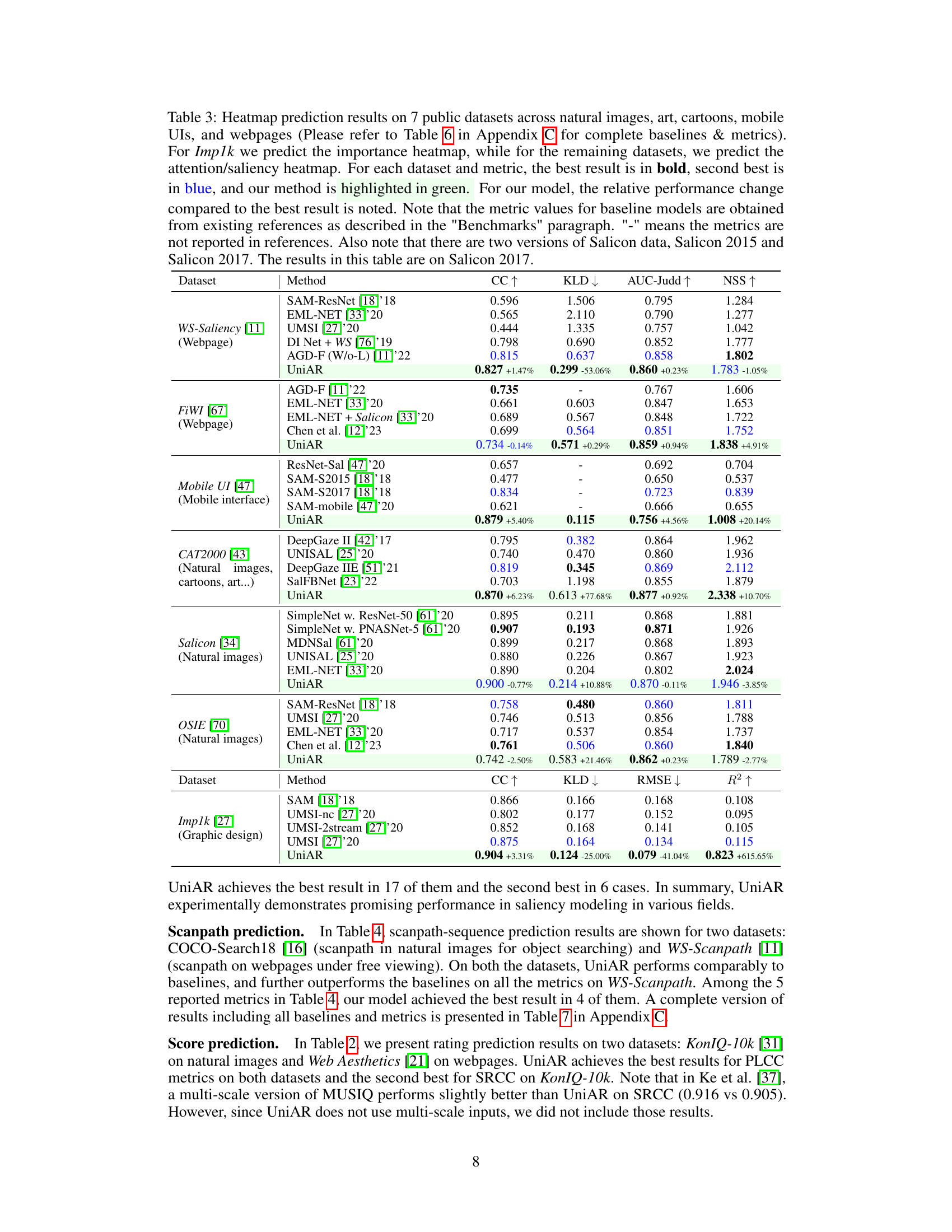
Table 3: Heatmap prediction results on 7 public datasets across natural images, art, cartoons, mobile UIs, and webpages (Please refer to Table 6 in Appendix C for complete baselines & metrics). For Imp1k we predict the importance heatmap, while for the remaining datasets, we predict the attention/saliency heatmap. For each dataset and metric, the best result is in bold, second best is in blue, and our method is highlighted in green. For our model, the relative performance change compared to the best result is noted. Note that the metric values for baseline models are obtained from existing references as described in the 'Benchmarks' paragraph. '-' means the metrics are not reported in references. Also note that there are two versions of Salicon data, Salicon 2015 and Salicon 2017. The results in this table are on Salicon 2017.
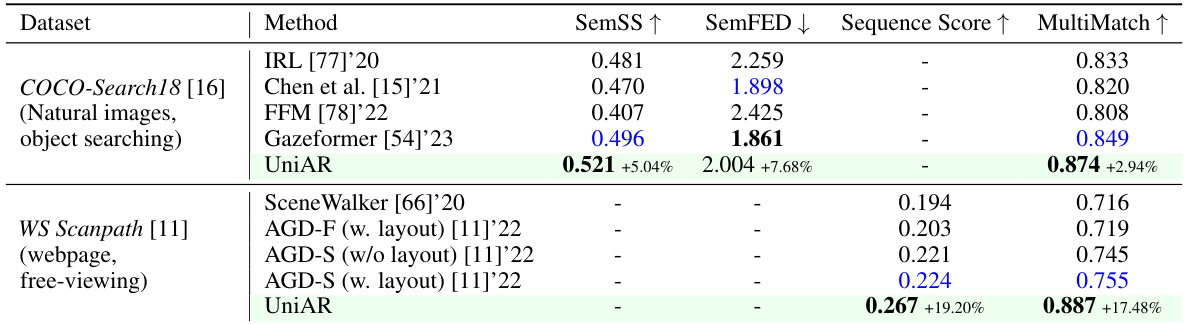
🔼 This table presents the performance of UniAR and other methods on scanpath prediction tasks using two datasets: COCO-Search18 (object searching in natural images) and WS-Scanpath (free viewing of webpages). It compares the models’ performance across several metrics designed to evaluate the accuracy of predicted scanpaths, including their shape, direction, length, position, and an overall multi-match score.
read the caption
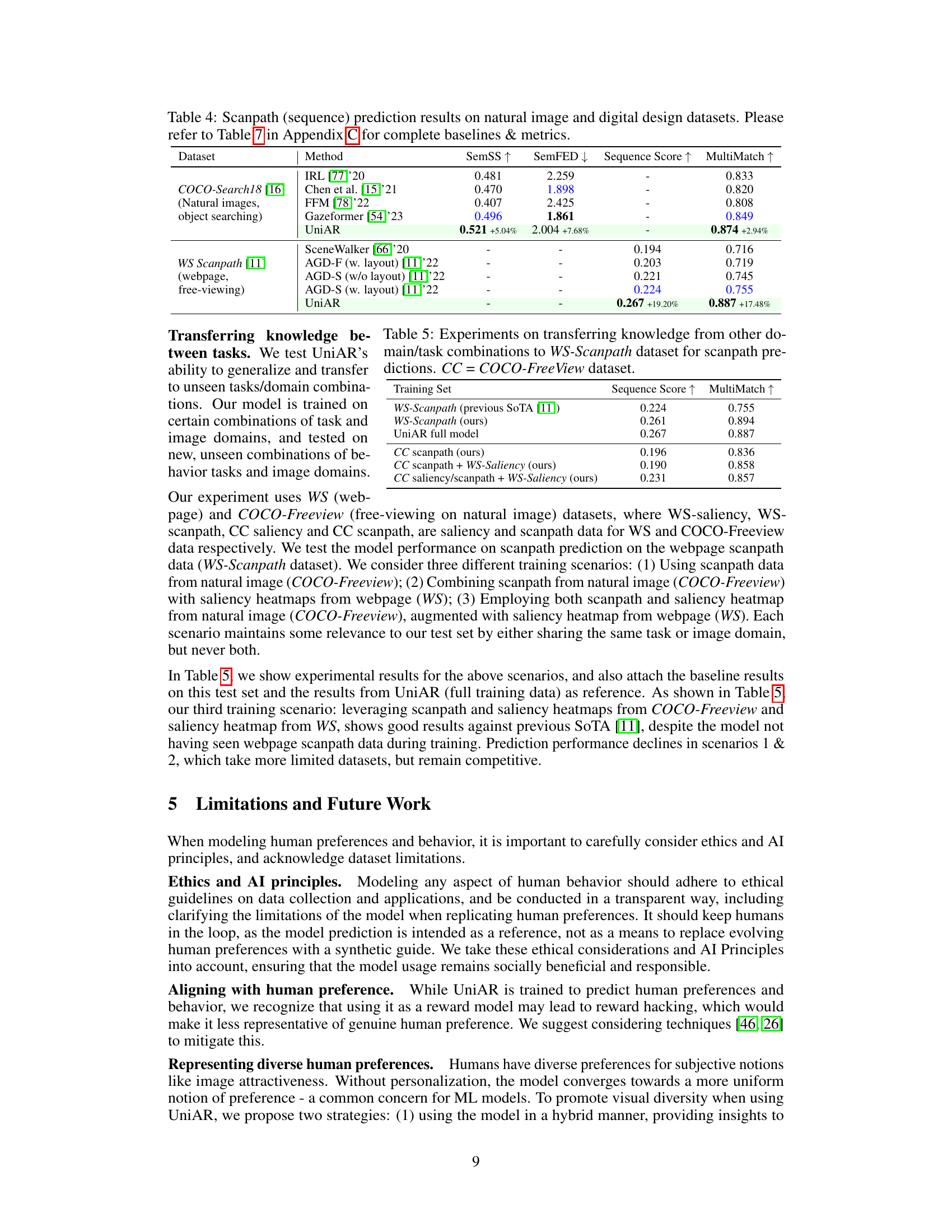
Table 4: Scanpath (sequence) prediction results on natural image and digital design datasets, with object-searching and free-viewing tasks.
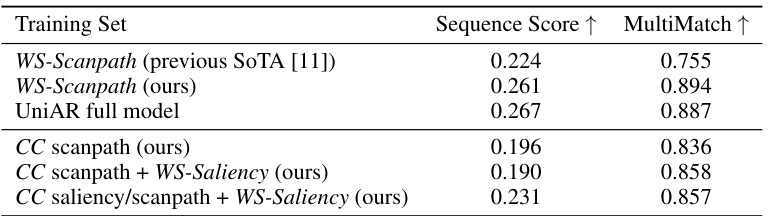
🔼 This table presents the results of experiments designed to evaluate the model’s ability to transfer knowledge learned from one task/domain combination to another unseen task/domain combination. Specifically, it investigates the model’s performance on the WS-Scanpath dataset (webpage scanpath prediction) after being trained on different combinations of data from the WS-Scanpath dataset itself, COCO-FreeView (natural image scanpath and saliency), and WS-Saliency (webpage saliency). The results show the Sequence Score and MultiMatch metrics, which evaluate the accuracy of the predicted scanpaths.
read the caption
Table 5: Experiments on transferring knowledge from other domain/task combinations to WS-Scanpath dataset for scanpath predictions. CC = COCO-FreeView dataset.

🔼 This table presents the performance of UniAR and several baseline methods on seven different public datasets for heatmap prediction. The datasets encompass various visual content types (natural images, art, cartoons, mobile UIs, and webpages), and the task is either predicting saliency heatmaps or importance heatmaps. The table shows several metrics to compare the performance, including Correlation Coefficient (CC), Kullback-Leibler Divergence (KLD), AUC-Judd, shuffled AUC (SAUC), Similarity (SIM), Normalized Scanpath Saliency (NSS), Root Mean Square Error (RMSE), and R-squared (R2). The best performing model for each metric and dataset is highlighted. UniAR’s performance is compared to the previous state-of-the-art (SOTA) models. Note that some datasets have different types of heatmaps (saliency vs. importance).
read the caption
Table 3: Heatmap prediction results on 7 public datasets across natural images, art, cartoons, mobile UIs, and webpages (Please refer to Table 6 in Appendix C for complete baselines & metrics). For Imp1k we predict the importance heatmap, while for the remaining datasets, we predict the attention/saliency heatmap. For each dataset and metric, the best result is in bold, second best is in blue, and our method is highlighted in green. For our model, the relative performance change compared to the best result is noted. Note that the metric values for baseline models are obtained from existing references as described in the 'Benchmarks' paragraph. '-' means the metrics are not reported in references. Also note that there are two versions of Salicon data, Salicon 2015 and Salicon 2017. The results in this table are on Salicon 2017.
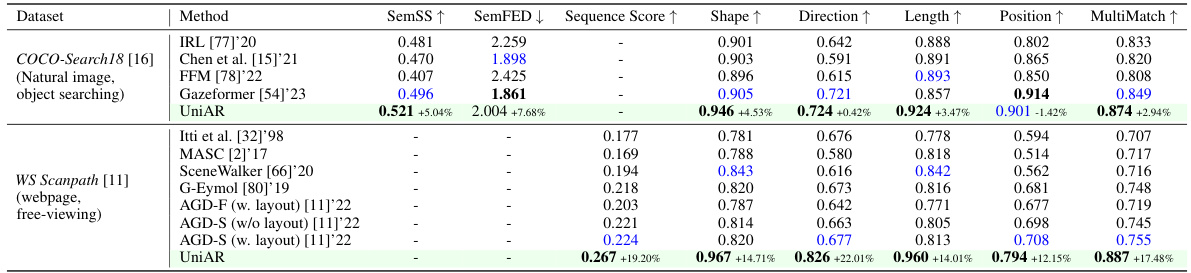
🔼 This table presents the performance of UniAR and other methods on scanpath prediction. It compares the results across two different datasets: COCO-Search18 (object searching in natural images) and WS-Scanpath (free viewing of webpages). The metrics used to evaluate the performance include SemSS, SemFED, Sequence Score, Shape, Direction, Length, Position, and MultiMatch. Each metric quantifies different aspects of the predicted scanpath’s similarity to the ground truth.
read the caption
Table 4: Scanpath (sequence) prediction results on natural image and digital design datasets, with object-searching and free-viewing tasks.
Full paper#