TL;DR#
Prompt optimization is critical for harnessing the power of large language models (LLMs), but existing methods often overlook the cost of evaluating many candidate prompts. This is especially problematic when LLMs involve financial and time costs, and when human evaluation is required for tasks that involve subjective assessment. This makes prompt selection an important but under-researched area.
The paper introduces TRIPLE, a novel framework that efficiently addresses this problem by connecting prompt optimization to the fixed-budget best-arm identification (BAI-FB) problem from multi-armed bandit theory. TRIPLE systematically leverages the rich toolbox from BAI-FB and incorporates the unique characteristics of prompt optimization. Experimental results show significant performance improvements across multiple tasks and LLMs, all while satisfying budget constraints. The work also proposes extensions of TRIPLE to efficiently select examples for few-shot prompts.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in prompt engineering and machine learning due to its novel approach of applying fixed-budget best-arm identification to prompt optimization. It addresses the significant cost associated with prompt selection using LLMs by providing a principled framework, TRIPLE, to efficiently find optimal prompts under budget constraints. The work bridges a gap between prompt engineering and multi-armed bandits, opening exciting new avenues for research and potentially impacting various downstream NLP tasks. The superior empirical performance of TRIPLE over existing methods is a key highlight.
Visual Insights#
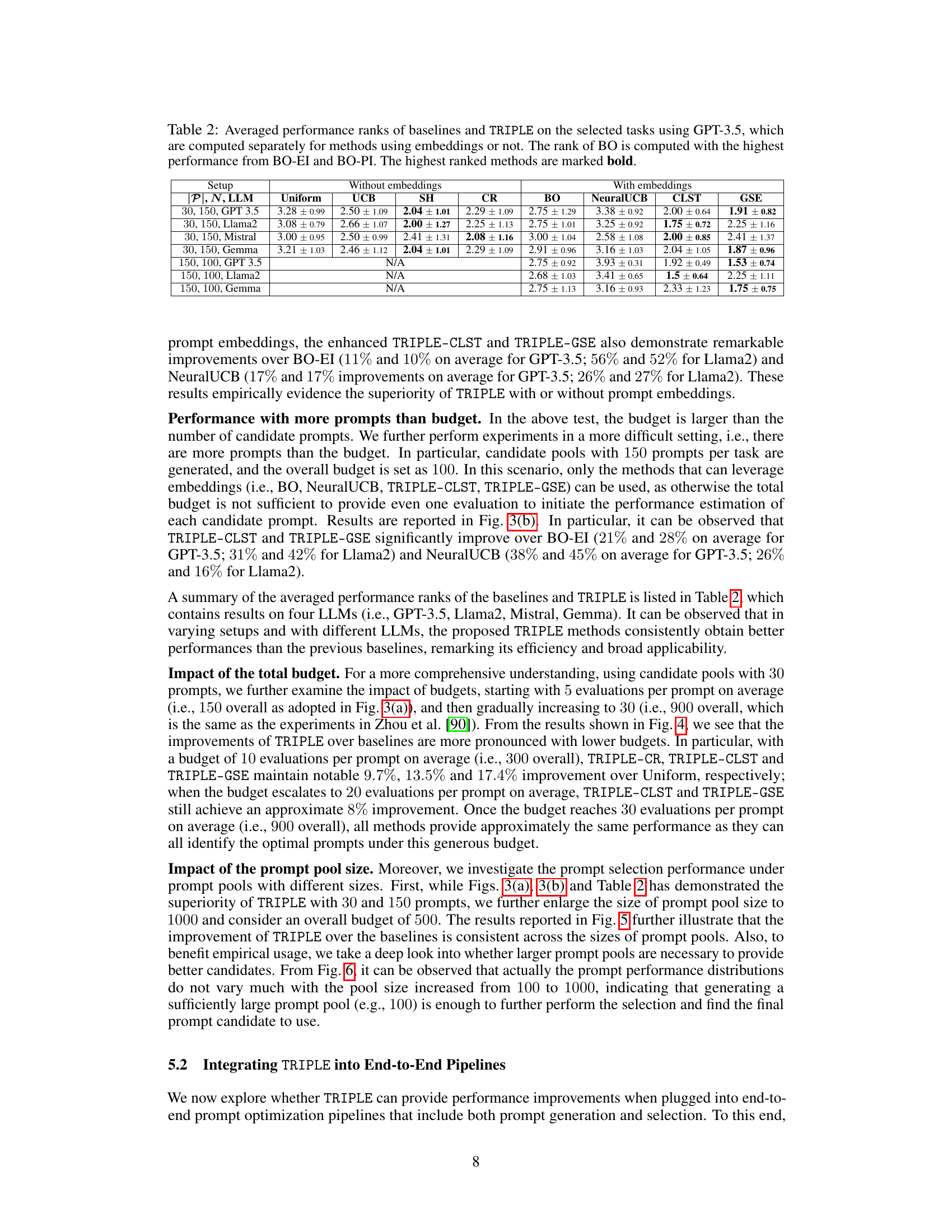
🔼 This figure illustrates the common pipeline for prompt optimization. Previous works mainly focused on generating a pool of candidate prompts. This paper focuses on selecting the best prompt from that pool, which is often overlooked but is resource-intensive. The selection process is depicted with an emphasis on the budget constraint and the iterative loop that might be present in certain methods.
read the caption
Figure 1: The commonly adopted prompt optimization pipeline. Previous works mostly investigate the generation component and ignore costs during selection, where GrIPS and APE are proposed in Prasad et al. [59], Zhou et al. [90]. This work, instead, focuses on the selection component under an explicit budget constraint.

🔼 This table draws a parallel between the prompt optimization problem and the multi-armed bandit (MAB) problem, specifically focusing on the fixed-budget best arm identification (BAI-FB) setting. It maps concepts from prompt optimization, such as the pool of prompts, interacting with the LLM using a prompt, the score function, randomness in inputs and outputs, and the overall performance of a prompt, to their corresponding equivalents within the MAB framework. The final row emphasizes that the prompt optimization problem under a limited budget aligns directly with the BAI-FB objective of identifying the best arm efficiently under a fixed budget.
read the caption
Table 1: Prompt Optimization and MAB.
In-depth insights#
Prompt Optimization#
Prompt optimization is a crucial area in natural language processing, aiming to efficiently discover effective prompts for large language models (LLMs). This involves balancing prompt generation strategies with effective selection methods. Traditional approaches often focus solely on generating a large pool of candidate prompts, leading to computationally expensive and time-consuming evaluations. This paper advocates for a more principled framework that explicitly considers the budget constraints of LLM interactions, arguing that prompt selection itself is a significant challenge. By framing prompt selection as a best-arm identification problem within the multi-armed bandit framework, the authors present a novel, efficient, and principled approach to optimize prompt selection under resource limitations.
BAI-FB in Prompting#
The application of fixed-budget best-arm identification (BAI-FB) in prompt optimization for large language models (LLMs) offers a novel approach to efficient prompt selection. BAI-FB elegantly addresses the cost constraint inherent in LLM interaction, by optimally allocating a limited budget across candidate prompts to maximize the chance of finding the best performing one. This framework is particularly beneficial given the financial, time, and usage limits associated with LLMs. The core idea is to frame prompt selection as a multi-armed bandit problem, where each prompt represents an arm and the evaluation score of the prompt on a downstream task is the reward. Instead of exploring all prompts exhaustively, BAI-FB leverages algorithms designed for efficient best arm identification within a budget, thus significantly improving efficiency. The connection between prompt optimization and BAI-FB provides a principled framework to systematically incorporate characteristics of prompt optimization, such as the discrete and black-box nature of LLMs, into established BAI-FB techniques. This approach enables more efficient exploration, leading to improved prompt performance while respecting budget constraints.
TRIPLE Framework#
The TRIPLE framework, designed for efficient prompt optimization, cleverly leverages the principles of fixed-budget best-arm identification (BAI-FB) from the multi-armed bandit (MAB) field. Its core innovation lies in directly addressing the cost of prompt evaluation by explicitly incorporating a budget constraint. Unlike previous approaches that predominantly focus on prompt generation, TRIPLE systematically optimizes prompt selection. This is achieved through two main variants, TRIPLE-SH and TRIPLE-CR, inspired by established BAI-FB algorithms. To further enhance scalability and performance, especially with large prompt pools, TRIPLE introduces prompt embeddings, enabling the use of TRIPLE-CLST and TRIPLE-GSE, which incorporate clustering and function approximation techniques, respectively. The framework’s versatility is showcased by its seamless integration into existing prompt optimization pipelines, significantly improving performance across multiple tasks and various LLMs. Importantly, TRIPLE extends beyond single-prompt optimization to few-shot learning scenarios, demonstrating adaptability and broader applicability within the field of prompt engineering.
Budget-Aware Methods#
Budget-aware methods in prompt optimization address the significant cost associated with querying large language models (LLMs). Prior work often overlooked the expense of evaluating numerous prompts, leading to inefficient exploration. Budget-aware techniques aim to maximize prompt selection performance within a predetermined budget. This involves careful strategies for selecting a subset of prompts for evaluation. Methods such as those based on multi-armed bandit (MAB) algorithms are particularly relevant, as they provide a framework for balancing exploration (testing new prompts) and exploitation (using the best-performing prompts identified so far). Fixed-budget best-arm identification (BAI-FB) is specifically well-suited as it directly addresses the problem of selecting the single best prompt from a pool of candidates within a given budget. Effective budget-aware methods leverage techniques like prompt embeddings to reduce computational cost by utilizing information sharing among prompts and thereby reducing the number of LLMs queries needed. Efficient prompt selection significantly enhances the practicality of prompt optimization, making it feasible for tasks with limited resources.
Future of Prompting#
The future of prompting large language models (LLMs) appears bright, driven by a need for efficiency and control. Current methods often rely on exhaustive prompt pools and lack principled selection strategies. Future research will likely focus on more efficient prompt optimization algorithms such as those inspired by multi-armed bandits. Incorporating prompt embeddings will be crucial for handling large candidate pools and exploiting prompt similarities. Adaptive prompting, where prompts adjust dynamically based on LLM feedback, will also emerge. Few-shot prompting, though already impactful, demands more sophisticated example selection strategies. The field must also address the cost and latency associated with LLM interactions, suggesting a shift towards strategies minimizing both. Finally, a deeper investigation into the underlying theory behind prompt effectiveness is crucial, enabling the development of more robust and predictable prompting methodologies. Addressing these challenges will unlock the full potential of LLMs across diverse applications.
More visual insights#
More on figures
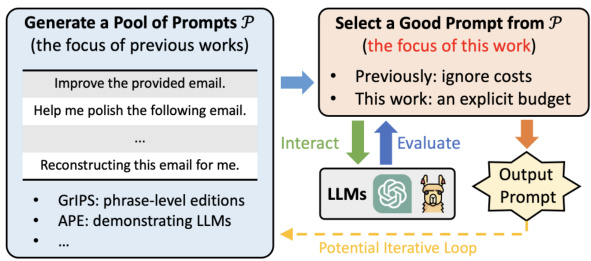
🔼 This figure shows the results of clustering 30 prompts for two different tasks, ‘movie recommendation’ and ‘rhymes.’ Each prompt is represented as a point in a 2D space created using t-SNE dimensionality reduction. Prompts are grouped into clusters based on their similarity. The color and shape of each point indicate the cluster it belongs to. The size of the point represents the prompt’s performance, with larger points indicating better performance. The figure visually demonstrates that prompts within the same cluster tend to exhibit similar performance, supporting the effectiveness of clustering for prompt optimization.
read the caption
Figure 2: Clusters for 30 prompts for “movie recommendation” (left) [69] and “rhymes” (right) [30]. Prompts in the same cluster are labeled by the same color and shape. The performance of each prompt is represented by the size of its shape (the larger the better). The embeddings are projected using t-SNE [29].
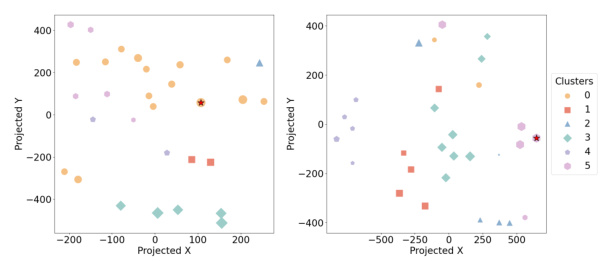
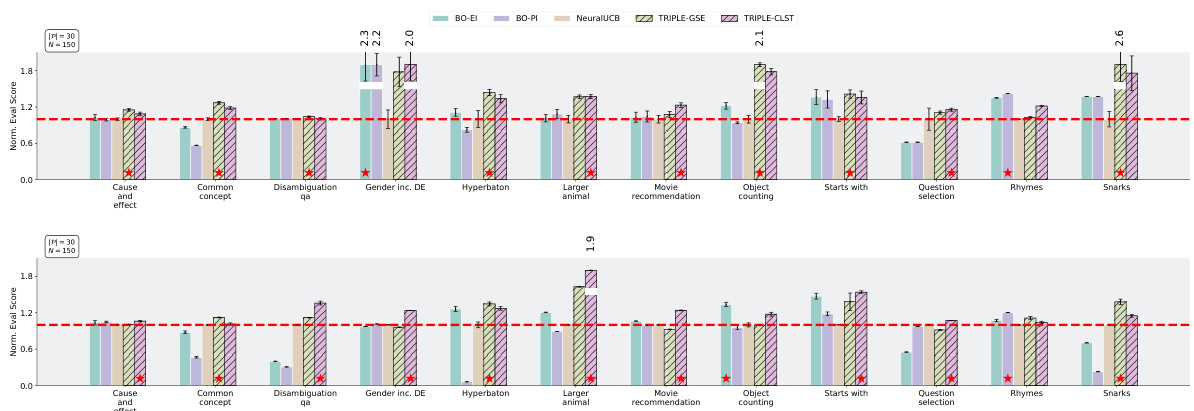
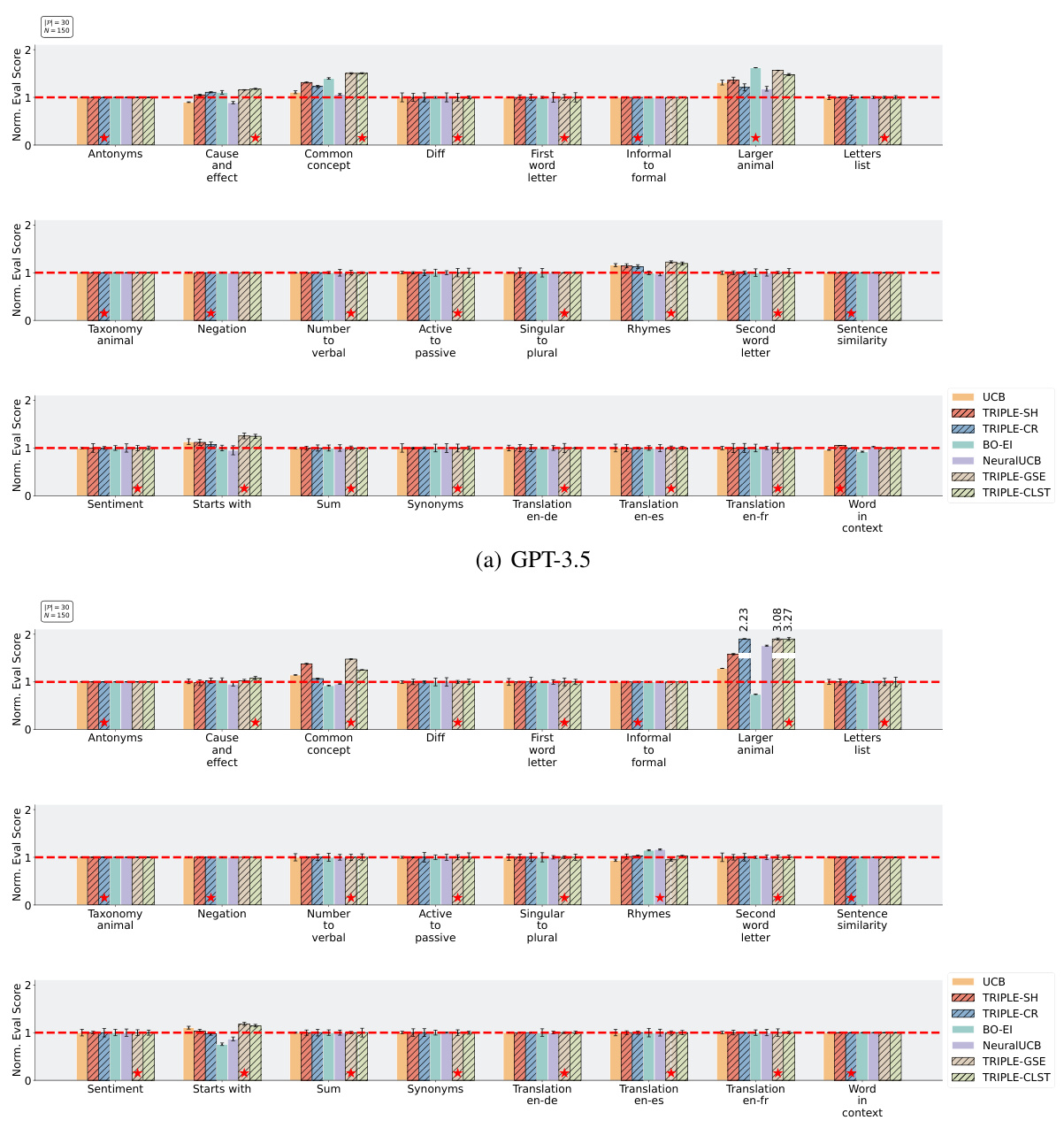
🔼 This figure compares the performance of different prompt selection methods (Uniform, UCB, BO-EI, BO-PI, NeuralUCB, TRIPLE-SH, TRIPLE-CR, TRIPLE-CLST, TRIPLE-GSE) across multiple tasks using two different LLMs (GPT-3.5 and Llama2). It shows normalized evaluation scores for each method with different budget constraints (N=150 and N=100) and various number of candidate prompts (|P|=30 and |P|=150). Red dashed lines represent the average performance of the ‘Uniform’ method, and red stars mark the best performing method in each task.
read the caption
Figure 3: Performance comparisons of various prompt selection methods on the selected tasks. The red dashed lines label the performances normalized over (i.e., 1 on the y-axis) and the red stars mark the best methods. The reported results are aggregated over 20 independent runs. The full results on 47 tasks are reported in Appendix F.
🔼 This figure compares the performance of different prompt selection methods across multiple tasks using two different LLMs (GPT-3.5 and Llama2). It shows normalized test accuracy for each method against a baseline (‘Uniform’). The results indicate that the TRIPLE methods (TRIPLE-SH, TRIPLE-CR, TRIPLE-CLST, TRIPLE-GSE) generally outperform other baselines (Uniform, UCB, BO-EI, BO-PI, NeuralUCB) across different budget and prompt pool sizes, highlighting the effectiveness of the proposed TRIPLE framework.
read the caption
Figure 3: Performance comparisons of various prompt selection methods on the selected tasks. The red dashed lines label the performances normalized over (i.e., 1 on the y-axis) and the red stars mark the best methods. The reported results are aggregated over 20 independent runs. The full results on 47 tasks are reported in Appendix F.
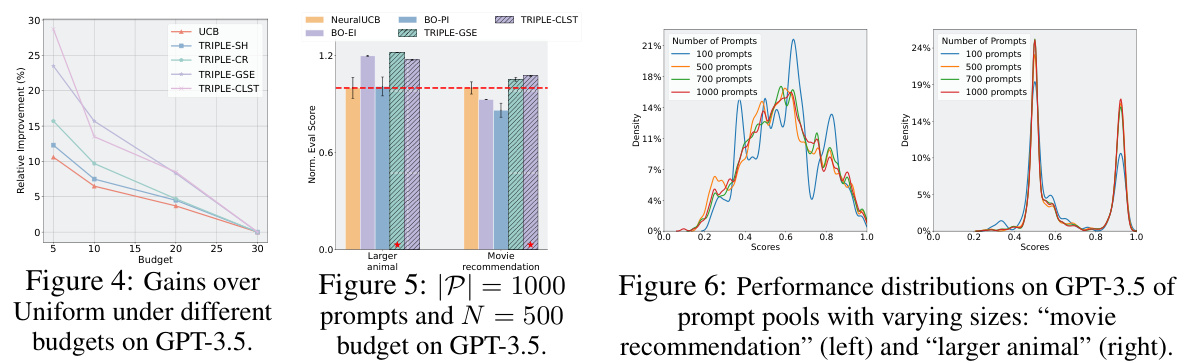
🔼 This figure displays the relative improvement in performance of various prompt selection methods, including TRIPLE variants and baselines like UCB and BO, compared to a uniform selection approach. The x-axis represents the budget allocated for prompt selection, while the y-axis shows the relative improvement in performance. The results demonstrate the increasing superiority of TRIPLE methods, especially at lower budgets, highlighting their efficiency in finding good prompts with limited resources.
read the caption
Figure 4: Gains over Uniform under different budgets on GPT-3.5.
🔼 This figure shows the result of clustering 30 prompts into clusters based on their embeddings for two different tasks: movie recommendation and rhymes. The visualization uses t-SNE to project the high-dimensional embeddings into a 2D space. Each point represents a prompt, with color and shape indicating cluster membership. The size of the point represents the prompt’s performance, with larger points indicating better performance. The figure visually demonstrates that prompts within the same cluster tend to have similar performance, supporting the effectiveness of the clustering approach.
read the caption
Figure 2: Clusters for 30 prompts for “movie recommendation” (left) [69] and “rhymes” (right) [30]. Prompts in the same cluster are labeled by the same color and shape. The performance of each prompt is represented by the size of its shape (the larger the better). The embeddings are projected using t-SNE [29].
🔼 This figure shows the results of clustering prompts based on their embeddings for two different tasks: movie recommendation and rhymes. Each point represents a prompt, with color and shape indicating cluster membership. The size of the point corresponds to the prompt’s performance (larger points indicate better performance). T-SNE is used to reduce the dimensionality of the embeddings for visualization.
read the caption
Figure 2: Clusters for 30 prompts for “movie recommendation” (left) [69] and “rhymes” (right) [30]. Prompts in the same cluster are labeled by the same color and shape. The performance of each prompt is represented by the size of its shape (the larger the better). The embeddings are projected using T-SNE [29].
🔼 This figure shows the results of clustering prompts for two different tasks: ‘movie recommendation’ and ‘rhymes’. Prompts are clustered based on their embeddings, and prompts within the same cluster are visually grouped by color and shape. The size of each shape represents the prompt’s performance, with larger shapes indicating better performance. t-SNE is used to project the high-dimensional embeddings into a 2D space for visualization.
read the caption
Figure 2: Clusters for 30 prompts for “movie recommendation” (left) [69] and “rhymes” (right) [30]. Prompts in the same cluster are labeled by the same color and shape. The performance of each prompt is represented by the size of its shape (the larger the better). The embeddings are projected using t-SNE [29].

🔼 This figure visualizes the results of clustering 30 prompts for two different tasks, ‘movie recommendation’ and ‘rhymes.’ Each prompt is represented as a point in a 2D embedding space, generated using t-SNE for dimensionality reduction. Prompts within the same cluster (same color and shape) have similar performances, as indicated by the size of the shape, with larger shapes signifying better performance. The visualization helps illustrate the effectiveness of clustering similar prompts together before applying best-arm identification.
read the caption
Figure 2: Clusters for 30 prompts for “movie recommendation” (left) [69] and “rhymes” (right) [30]. Prompts in the same cluster are labeled by the same color and shape. The performance of each prompt is represented by the size of its shape (the larger the better). The embeddings are projected using t-SNE [29].
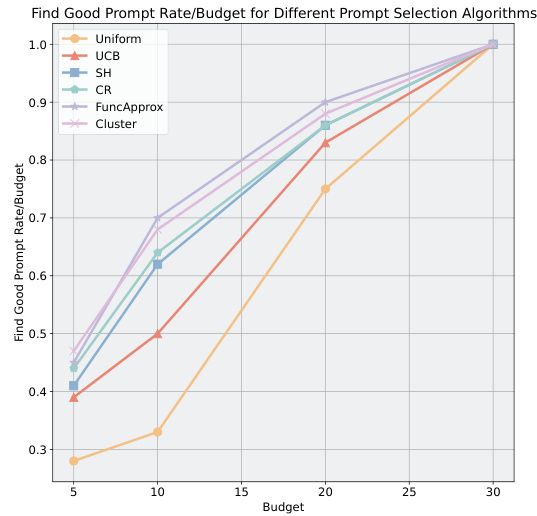
🔼 This figure shows the probability of different prompt selection algorithms (Uniform, UCB, SH, CR, FuncApprox, Cluster) to select a good prompt (either the optimal prompt or one achieving at least 95% of the optimal prompt’s performance) under various budget constraints. The x-axis represents the budget, and the y-axis represents the probability of selecting a good prompt. The results are obtained using GPT-3.5 and averaged over 5 runs. The figure demonstrates how the probability of selecting a good prompt improves with increasing budget and how the different algorithms compare in terms of their efficiency in finding good prompts under budget limitations.
read the caption
Figure 11: Probability for different algorithms to select a good prompt under different budgets (right), collected with GPT-3.5 and averaged over 5 runs.

🔼 This figure compares different prompt selection methods across several tasks using GPT-3.5 and Llama2 language models. The y-axis represents normalized evaluation scores (test accuracy), with 1 indicating the average performance of the ‘Uniform’ baseline. The x-axis displays the various tasks. The red dashed line represents the average ‘Uniform’ performance. Red stars highlight the best-performing method for each task. The figure shows that TRIPLE methods (TRIPLE-SH, TRIPLE-CR, TRIPLE-CLST, and TRIPLE-GSE) consistently outperform baselines such as Uniform, UCB, BO, and NeuralUCB across various tasks. The results are averaged over 20 runs for robustness.
read the caption
Figure 3: Performance comparisons of various prompt selection methods on the selected tasks. The red dashed lines label the performances normalized over (i.e., 1 on the y-axis) and the red stars mark the best methods. The reported results are aggregated over 20 independent runs. The full results on 47 tasks are reported in Appendix F.

🔼 This figure compares the performance of different prompt selection methods across various tasks. It shows normalized test accuracy for each method on several tasks, using two different numbers of candidate prompts (30 and 150) and budgets. The red dashed line represents the baseline performance, and red stars indicate the best performing method for each task. The results highlight the performance improvement of TRIPLE over existing methods.
read the caption
Figure 3: Performance comparisons of various prompt selection methods on the selected tasks. The red dashed lines label the performances normalized over (i.e., 1 on the y-axis) and the red stars mark the best methods. The reported results (y-axis) are test accuracies of each method normalized to the mean performance of “Uniform” on that task. The reported results are aggregated over 20 independent runs. The full results on 47 tasks are reported in Appendix F.
🔼 This figure compares the performance of different prompt selection methods across multiple tasks. The y-axis represents normalized evaluation scores, with 1.0 indicating the average performance of the Uniform baseline. The figure shows that TRIPLE methods (TRIPLE-SH, TRIPLE-CR, TRIPLE-CLST, TRIPLE-GSE) generally outperform the baselines (Uniform, UCB, BO-EI, BO-PI, NeuralUCB) across various tasks and with both small and large numbers of candidate prompts. Red stars show the best performing method for each task.
read the caption
Figure 3: Performance comparisons of various prompt selection methods on the selected tasks. The red dashed lines label the performances normalized over (i.e., 1 on the y-axis) and the red stars mark the best methods. The reported results are aggregated over 20 independent runs. The full results on 47 tasks are reported in Appendix F.
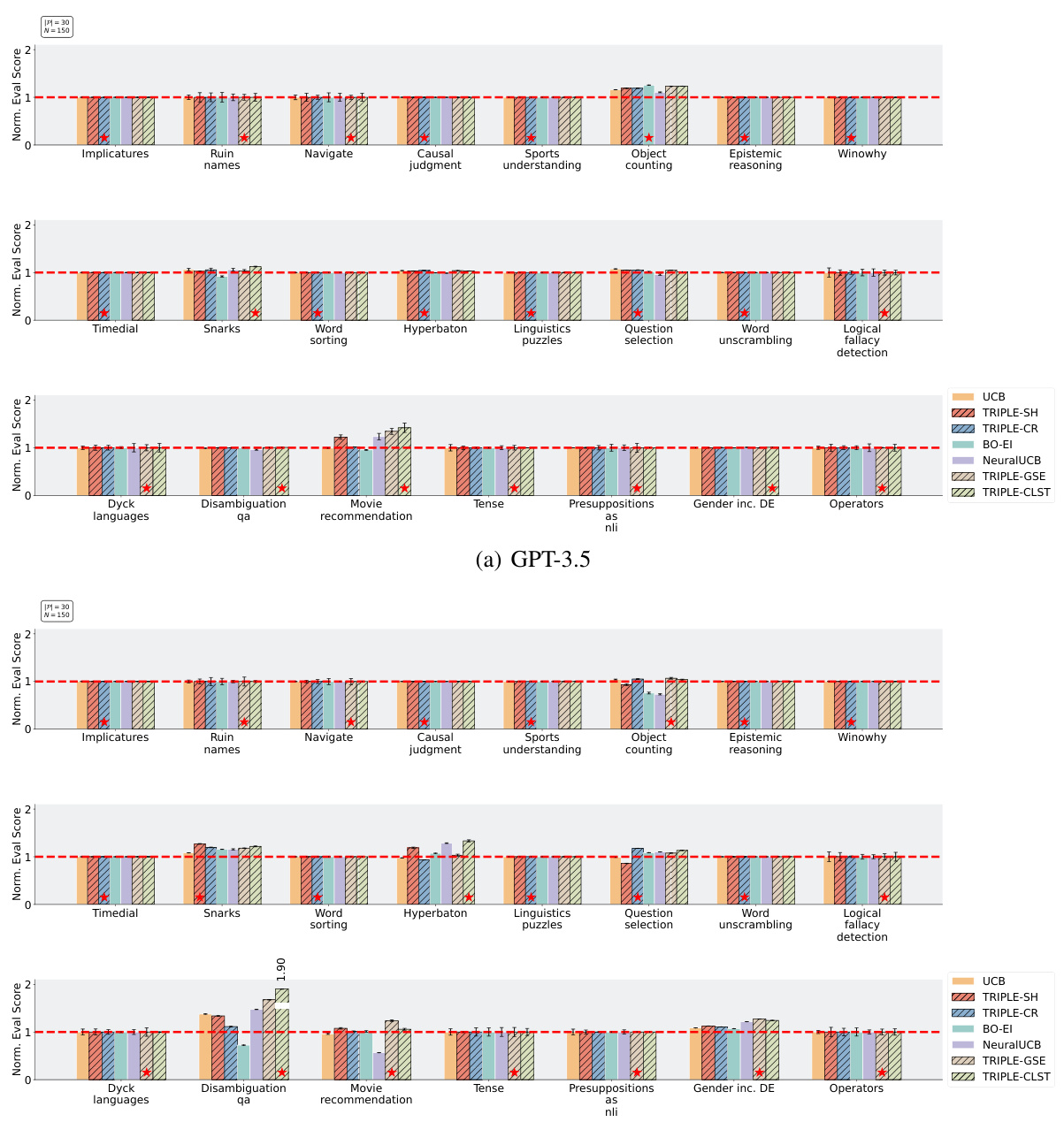
🔼 This figure shows a detailed comparison of various prompt selection methods across multiple tasks from the Instruction-Induction dataset. The results are presented for two different LLMs, GPT-3.5 and Llama2, with a fixed prompt pool size of 30 and a budget of 150. Each bar represents the normalized evaluation score for a specific task and method. This allows for a comprehensive comparison of the relative performance of TRIPLE against other baselines, such as Uniform, UCB, BO, and NeuralUCB. The figure visualizes the effectiveness of TRIPLE across various tasks under the specified budget constraint.
read the caption
Figure 13: Complete results on the Instruction-Induction dataset with |P| = 30 prompts and budget N = 150.
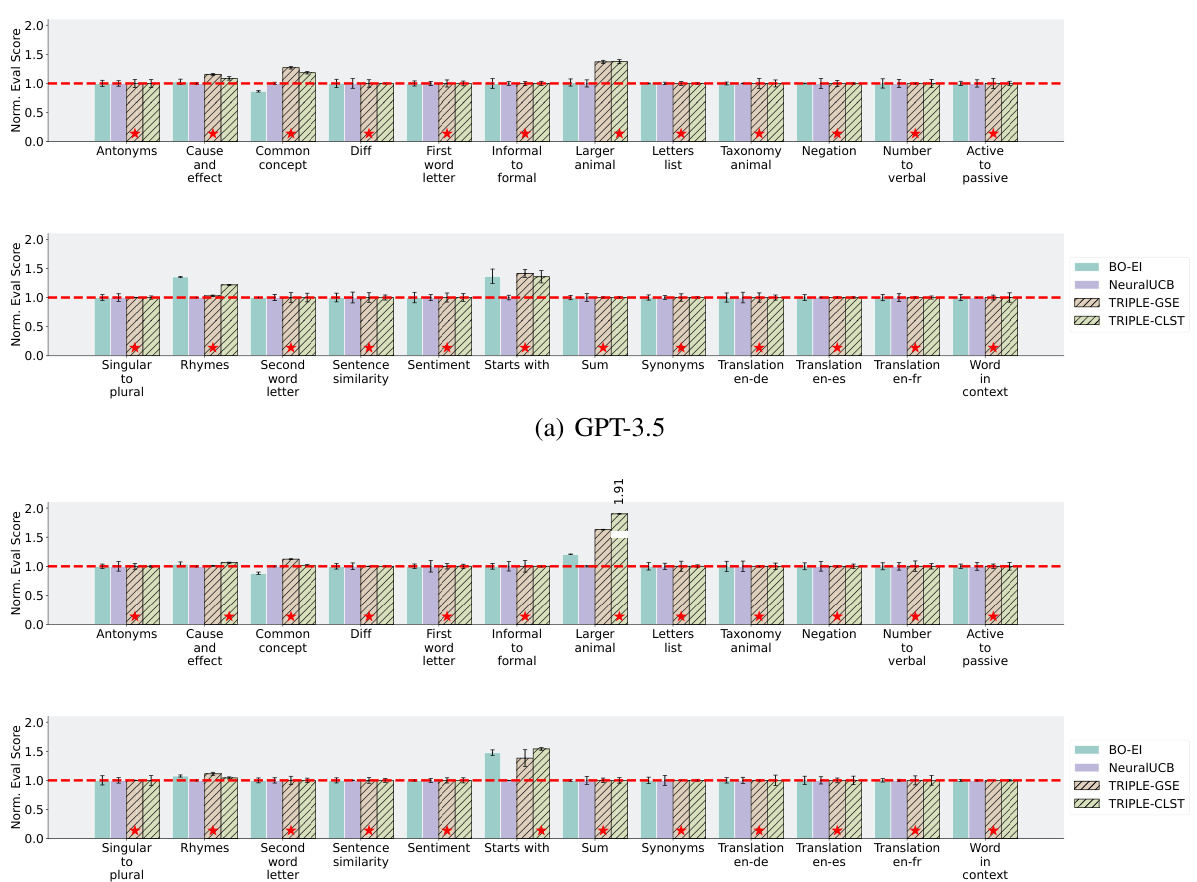
🔼 This figure compares the performance of various prompt selection methods, including TRIPLE variants, against baselines like Uniform, UCB, BO, and NeuralUCB. It shows normalized test accuracy across multiple tasks for GPT-3.5 and Llama2 models, with varying numbers of candidate prompts and budgets. The results highlight TRIPLE’s superior performance, especially when utilizing prompt embeddings.
read the caption
Figure 3: Performance comparisons of various prompt selection methods on the selected tasks. The red dashed lines label the performances normalized over (i.e., 1 on the y-axis) and the red stars mark the best methods. The reported results (y-axis) are test accuracies of each method normalized to the mean performance of “Uniform” (a) or “NeuralUCB” (b) on that task. The reported results are aggregated over 20 independent runs. The full results on 47 tasks are reported in Appendix F.
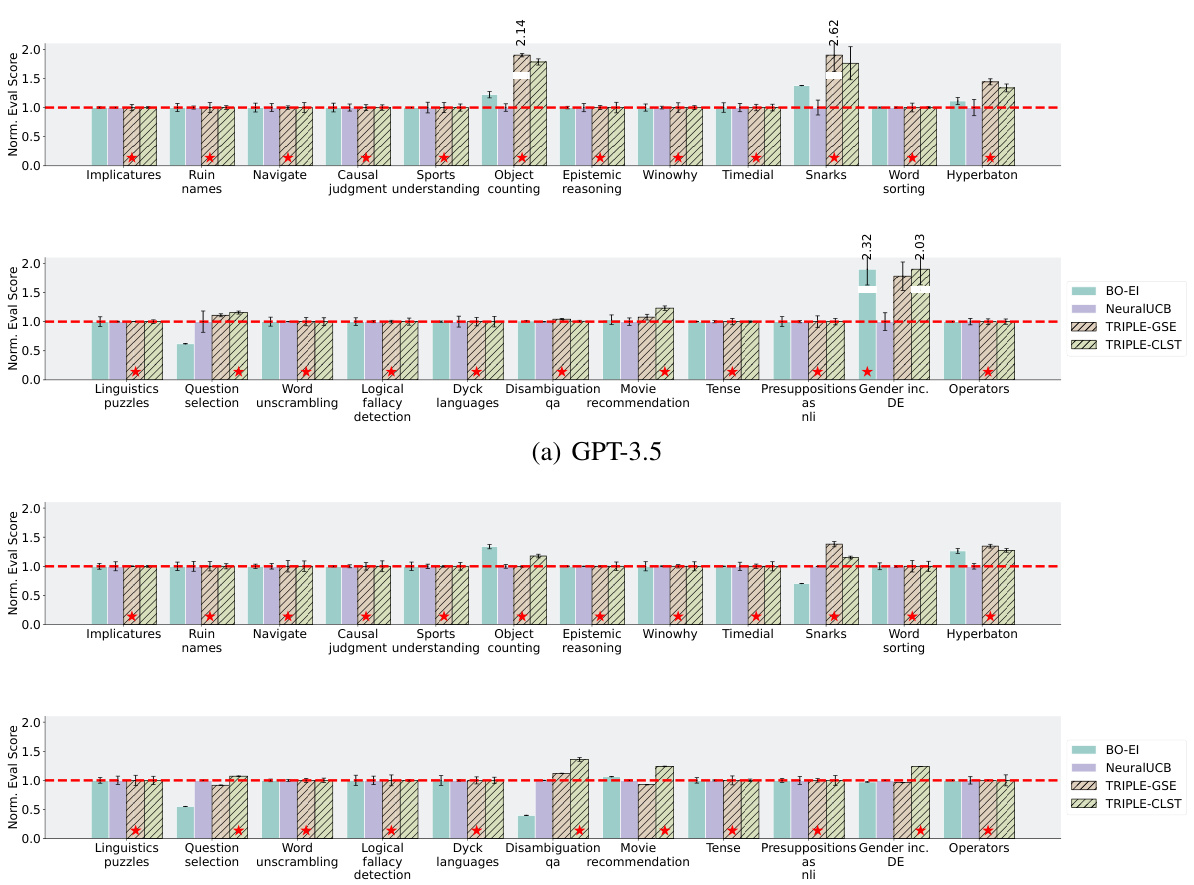
🔼 The figure compares the performance of several prompt selection methods (Uniform, UCB, BO, NeuralUCB, TRIPLE-SH, TRIPLE-CR, TRIPLE-CLST, TRIPLE-GSE) on various tasks using GPT-3.5 and Llama2 language models. It shows the test accuracy of each method, normalized to the baseline method’s performance (Uniform for (a), NeuralUCB for (b)). The results highlight the improved performance of TRIPLE methods, especially when using prompt embeddings.
read the caption
Figure 3: Performance comparisons of various prompt selection methods on the selected tasks. The red dashed lines label the performances normalized over (i.e., 1 on the y-axis) and the red stars mark the best methods. The reported results are aggregated over 20 independent runs. The full results on 47 tasks are reported in Appendix F.
🔼 This figure compares different prompt selection methods across multiple tasks using two different LLMs (GPT-3.5 and Llama2). It shows the normalized evaluation scores for each method, allowing for easy comparison of their relative performance. The red dashed lines represent the baseline performance (Uniform), and red stars indicate the best performing method for each task. The figure highlights the superior performance of TRIPLE methods, especially when considering a limited budget for prompt evaluation.
read the caption
Figure 3: Performance comparisons of various prompt selection methods on the selected tasks. The red dashed lines label the performances normalized over (i.e., 1 on the y-axis) and the red stars mark the best methods. The reported results are aggregated over 20 independent runs. The full results on 47 tasks are reported in Appendix F.
🔼 This figure presents a comprehensive comparison of various prompt selection methods on 24 tasks from the Instruction-Induction dataset. The experiment parameters were a fixed pool size of 30 prompts and a budget of 150 interactions with the language model. Results are shown for GPT-3.5 and Llama2 separately. Each bar represents the normalized evaluation score of a particular method for a given task, enabling a direct comparison of performance. The red dashed line indicates the normalized average performance of the Uniform baseline, which evaluates all prompts uniformly.
read the caption
Figure 13: Complete results on the Instruction-Induction dataset with |P| = 30 prompts and budget N = 150.
More on tables

🔼 This table presents a comparison of the average performance ranks of different prompt selection methods (baselines and TRIPLE variants) across various tasks using the GPT-3.5 language model. The results are divided into two groups: methods that do and do not use prompt embeddings. Within each group, the average rank (lower is better) and standard deviation are shown for each method. The table highlights the superior performance of TRIPLE methods compared to the baselines.
read the caption
Table 2: Averaged performance ranks of baselines and TRIPLE on the selected tasks using GPT-3.5, which are computed separately for methods using embeddings or not. The rank of BO is computed with the highest performance from BO-EI and BO-PI. The highest ranked methods are marked bold.

🔼 This table presents the average performance ranks of different prompt selection methods (Uniform, UCB, SH, CR, BO, NeuralUCB, CLST, GSE) across multiple tasks, using GPT-3.5. The results are separated into two groups: methods without prompt embeddings and methods with prompt embeddings. The rank is based on the average performance across the tasks, with lower ranks indicating better performance. The highest-performing methods in each category are bolded.
read the caption
Table 2: Averaged performance ranks of baselines and TRIPLE on the selected tasks using GPT-3.5, which are computed separately for methods using embeddings or not. The rank of BO is computed with the highest performance from BO-EI and BO-PI. The highest ranked methods are marked bold.
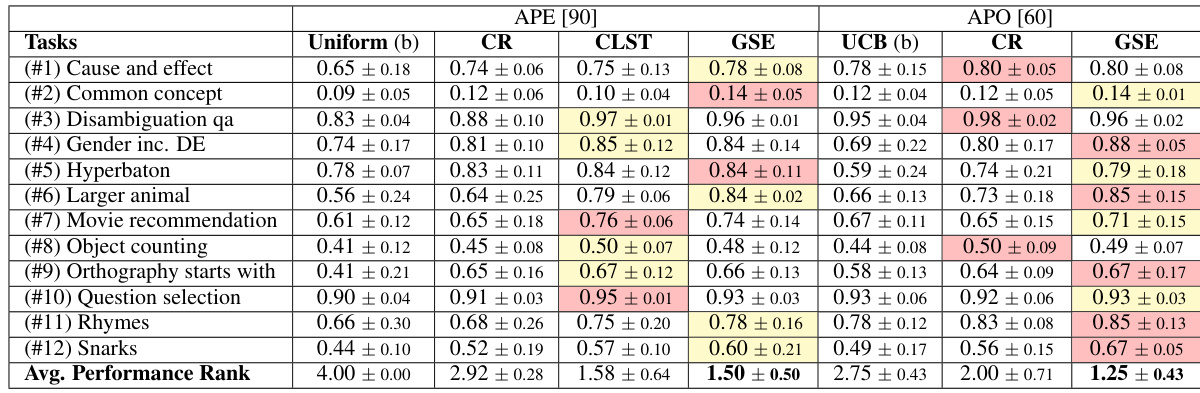
🔼 This table shows the performance of integrating TRIPLE into two end-to-end prompt optimization pipelines: APE and APO. It compares TRIPLE’s performance against baseline methods (Uniform and UCB for APE, and UCB for APO) across twelve tasks. The best performing method for each task in each pipeline is highlighted. The results demonstrate that TRIPLE consistently improves performance across various tasks.
read the caption
Table 3: Performances of integrating TRIPLE in the end-to-end pipelines using GPT-3.5. The baseline methods reported in the original implementations are labeled as (b). For each task, the best score across two pipelines is marked as red, and the best score in the remaining pipeline is highlighted as yellow. TRIPLE-CR are selected over TRIPLE-SH due to its better performance observed in the previous experiments. TRILE-CLST is ignored in the tests with APO, as it is ineffective to cluster only 10 prompts.

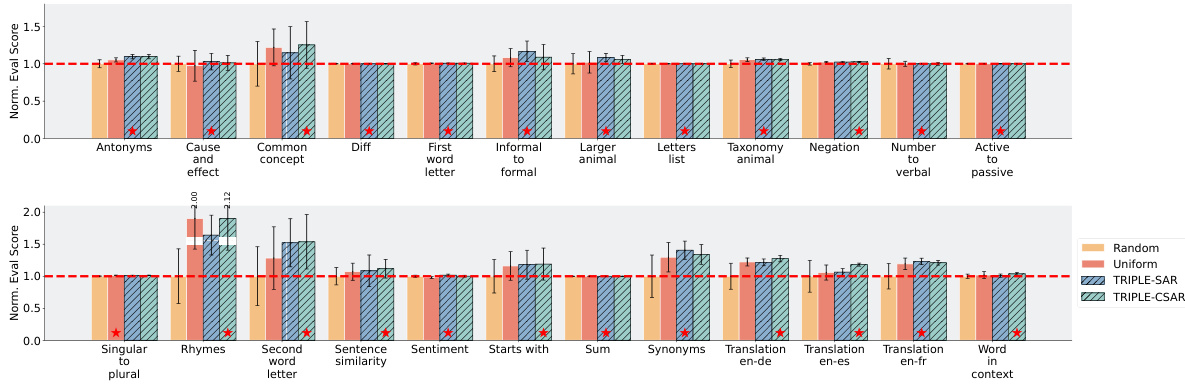
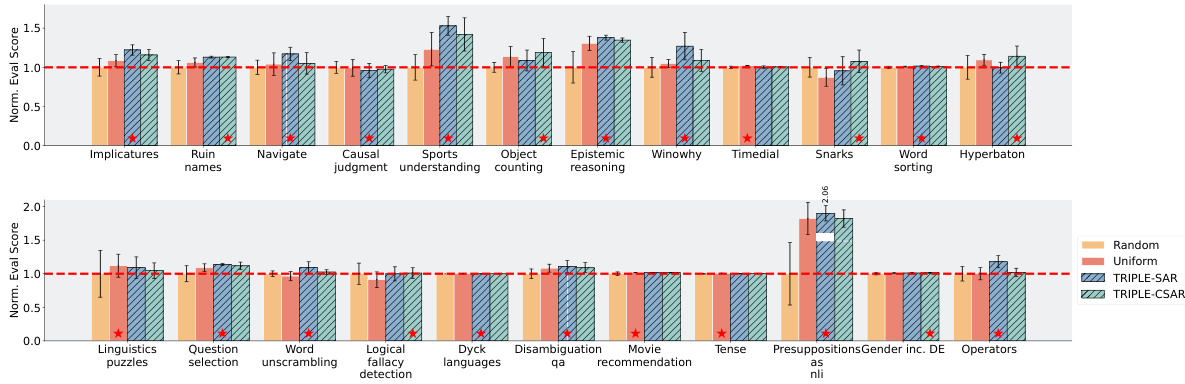
🔼 This table presents the performance comparison of four different example selection methods across twelve tasks using the GPT-3.5 language model. The methods are Random, Uniform, SAR, and CSAR. Each method’s performance is evaluated across four metrics: Average Performance Rank, and the performance on each individual task. The best performing method for each task, and the second-best performing method is highlighted for clarity.
read the caption
Table 4: Performance comparisons of various example selection methods on different tasks using GPT-3.5 with |G| = 50 candidate examples, budget N = 100, and length M = 4. The tasks are numbered according to Table 3. For each task, the best score across is marked as red, and the second best as yellow.

🔼 This table presents the average scores achieved by different prompt selection methods (Uniform, UCB, SH, CR, BO-EI, NeuralUCB, CLST, GSE) on two datasets: GLUE’s ‘Cola’ task and GSM8K. The results are obtained using GPT-3.5 with a fixed prompt pool size of 30 and a budget of 150. The table highlights the superior performance of TRIPLE methods by bolding the best-performing methods for each dataset. The ‘Cola’ task assesses linguistic acceptability, while GSM8K focuses on mathematical reasoning problems.
read the caption
Table 5: Averaged scores of baselines and TRIPLE on the task “Cola” (from the GLUE dataset) and the GSM8K dataset using GPT-3.5, with |P| = 30 candidates and budget N = 150, where the highest ranked methods are marked bold.

🔼 This table presents the average performance ranks of different prompt selection methods (Uniform, UCB, SH, CR, BO, NeuralUCB, CLST, GSE) across multiple tasks using the GPT-3.5 language model. The ranks are calculated separately for methods that use prompt embeddings and those that don’t. A lower rank indicates better performance. The table shows that TRIPLE methods consistently outperform the baseline methods.
read the caption
Table 2: Averaged performance ranks of baselines and TRIPLE on the selected tasks using GPT-3.5, which are computed separately for methods using embeddings or not. The rank of BO is computed with the highest performance from BO-EI and BO-PI. The highest ranked methods are marked bold.
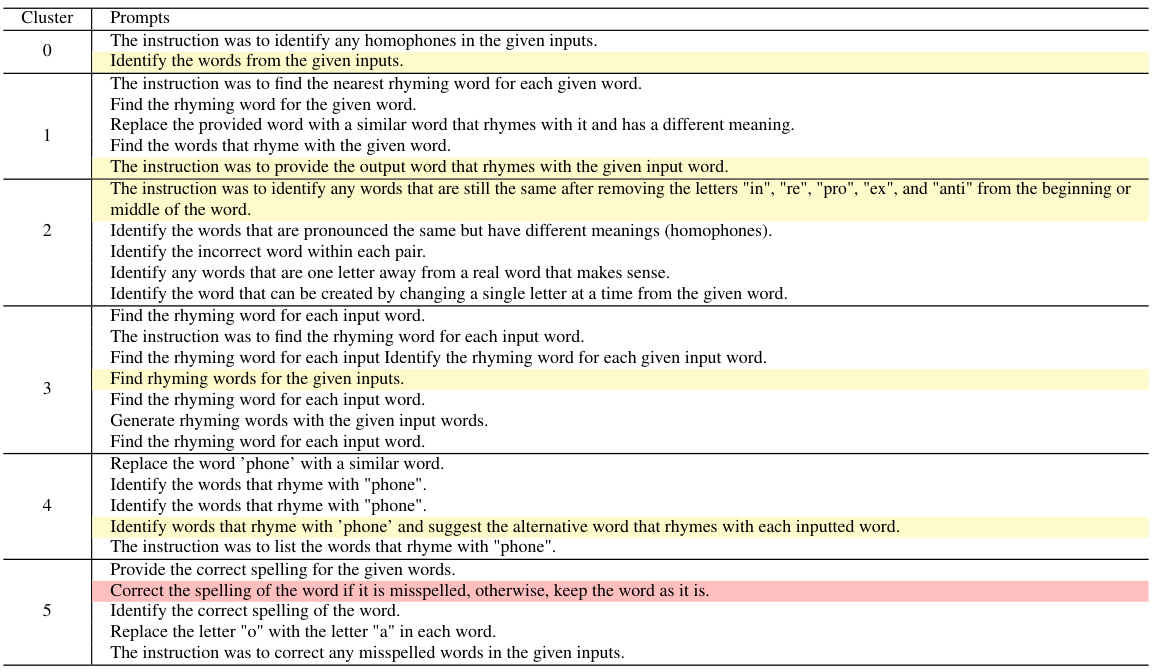
🔼 This table shows the result of clustering 30 prompts for the ‘rhymes’ task. Each row represents a cluster of prompts with similar characteristics, and the best performing prompt in each cluster is highlighted in yellow, with the overall best prompt marked in red. This illustrates the effectiveness of prompt clustering for efficient selection, as similar prompts are grouped together, allowing for faster identification of top performers.
read the caption
Table 7: Clusters for 'rhymes': the best prompt overall is marked in red, and the best prompt in each cluster in yellow.
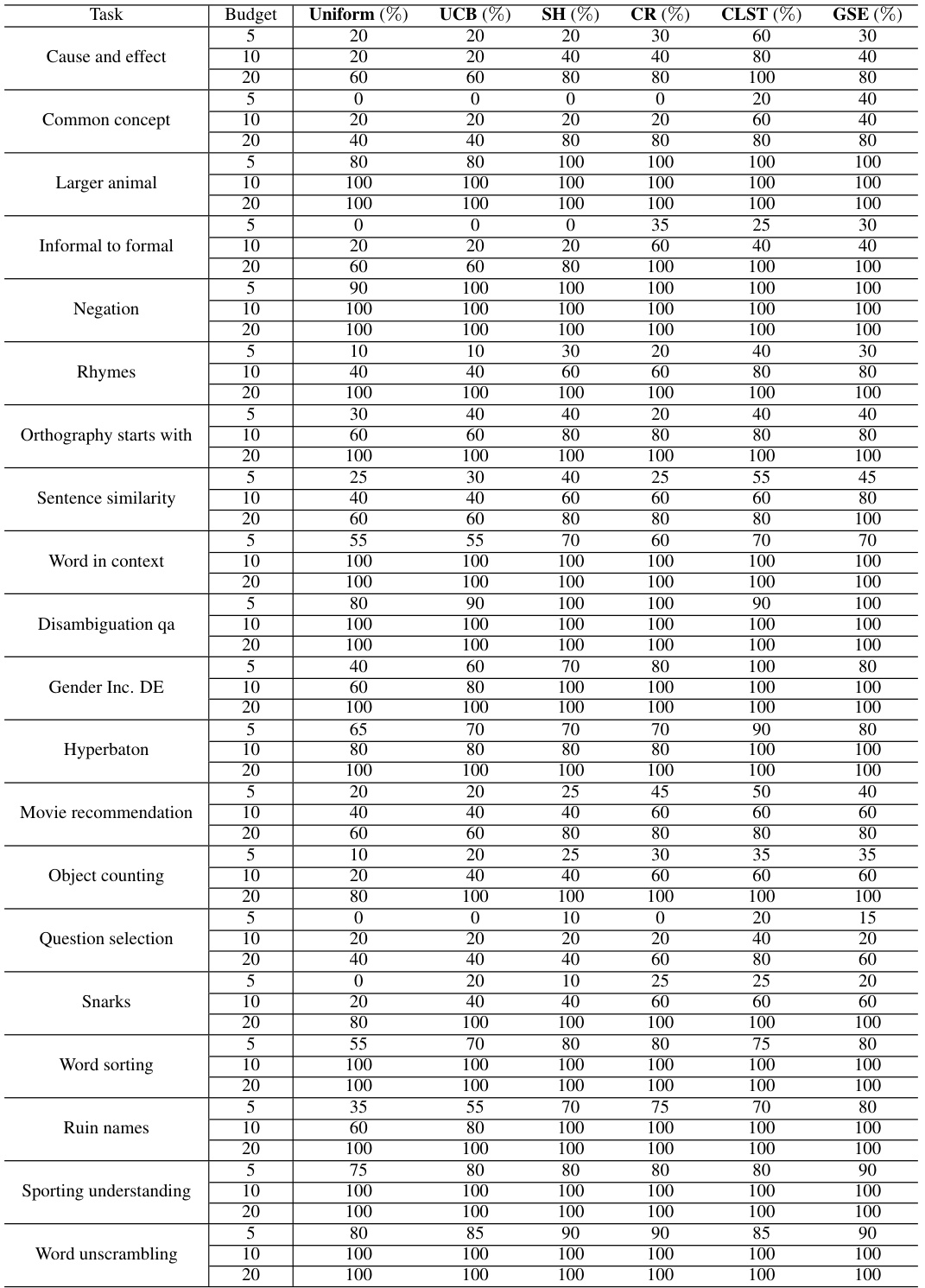
🔼 This table presents the success rates of different prompt selection methods in identifying a good prompt (either the optimal prompt or one achieving at least 95% of the optimal prompt’s performance) from a pool of 30 candidate prompts. The success rate is measured across various tasks and budgets (5, 10, and 20 evaluations per prompt). It showcases the performance of Uniform, UCB, SH, CR, CLST, and GSE algorithms under different budget constraints.
read the caption
Table 8: The ratios of different methods outputting a good prompt with GPT-3.5 from large prompt pools |P| = 30.
Full paper#