↗ arXiv ↗ Hugging Face ↗ Hugging Face ↗ Chat
TL;DR#
Current research uses synthetic data generated by models like Stable Diffusion to train vision models, assuming it improves upon training directly with real data. However, this assumption is rarely empirically tested.
This paper directly compares fine-tuning vision models on synthetic data versus real data, both selectively chosen to be relevant to the task. The study finds that using real data retrieved from the source dataset consistently matches or surpasses the performance of synthetic data across various classification tasks. This indicates that generative models may not add any extra value beyond their training data and highlights the importance of retrieval as a baseline for future work.
Key Takeaways#
Why does it matter?#
This paper is crucial because it challenges the common assumption that synthetic data always improves model performance. It introduces a simple yet powerful baseline—retrieving real data—that significantly outperforms current methods in many cases. This finding redirects research efforts towards more effective synthetic data generation strategies and data curation methods, advancing the field of model training.
Visual Insights#
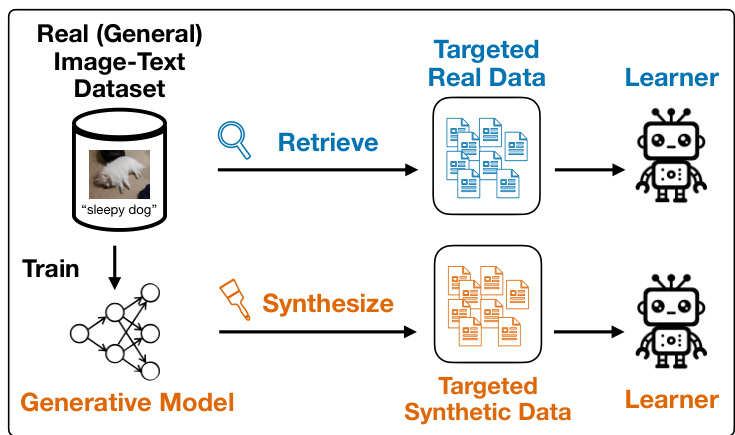
🔼 This figure illustrates the two approaches used in the paper to create a targeted dataset for training a machine learning model. The first approach involves retrieving targeted real images directly from an existing, large dataset. The second approach involves training a generative model on the large dataset and then using the model to synthesize new, targeted images. The goal is to compare the effectiveness of these two methods for training a model on a specific task.
read the caption
Figure 1: Given an upstream dataset of general real image-text pairs, we aim to curate a targeted dataset to train a learner on some target task. We can either (1) retrieve targeted real images directly from the upstream dataset, or we can (2) first train an intermediate generative model and then synthesize targeted synthetic images. By comparing these two approaches, our paper seeks to measure what value training on generated synthetic data adds.
In-depth insights#
Synth vs. Real Data#
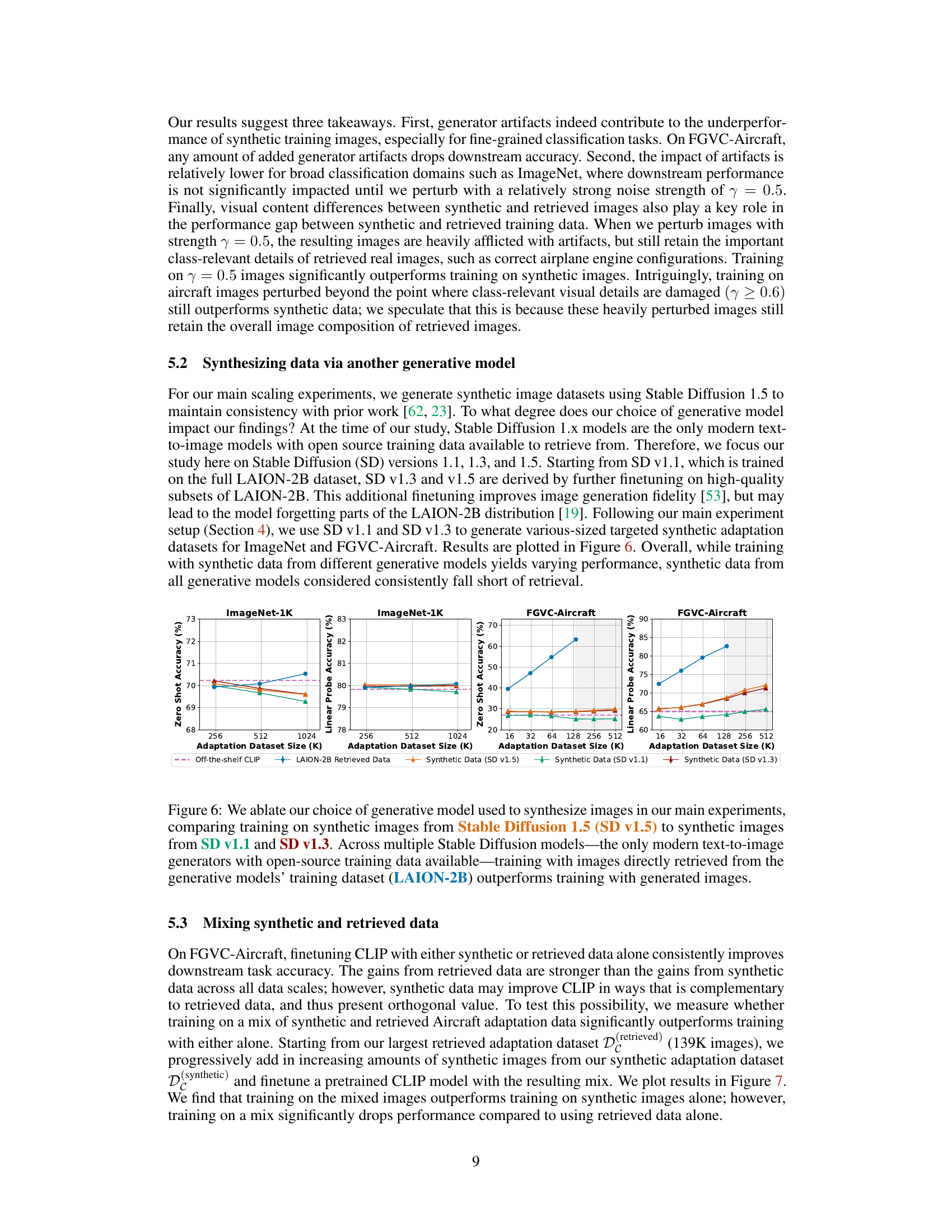
The comparative analysis of synthetic versus real data in training machine learning models reveals critical limitations in using synthetic data as a standalone solution. While synthetic data offers advantages like controllability and scalability, the study demonstrates that real data, particularly when carefully selected and targeted, consistently outperforms synthetic data. Generator artifacts and inaccuracies in synthetic images are identified as key factors contributing to their underperformance. The study highlights the need to consider a retrieval baseline for task-relevant real data from the generative model’s training data before declaring any synthetic data superior. This underscores the importance of carefully evaluating the added value of synthetic data over a direct approach and suggests further research to address the limitations of existing synthetic data generation techniques.
Retrieval Baselines#
The concept of “Retrieval Baselines” in evaluating synthetic data for training machine learning models is crucial. It highlights that synthetic data, while seemingly offering unlimited samples, fundamentally derives from an existing dataset (like LAION-2B). Therefore, directly using relevant subsets of this original dataset as a baseline provides a powerful comparison. Ignoring this baseline can lead to overestimating the value of synthetic data. A well-designed retrieval method can efficiently extract task-relevant real images, establishing a strong performance benchmark. Comparing synthetic data to this baseline helps isolate the true added value of the generative process, beyond simply re-representing existing data. This approach is essential for determining if synthetic data truly offers advantages over carefully curated real data subsets, particularly when considering resource constraints and potential biases in generated data.
Artifacts & Details#
An ‘Artifacts & Details’ section in a research paper would likely delve into the specifics of the methodology used, including limitations and potential sources of error. This would be crucial for reproducibility and critical assessment. Specific details of data acquisition, preprocessing steps, algorithm choices, and parameter settings should be thoroughly detailed. A discussion of potential artifacts introduced by the methods employed, such as bias in data selection or limitations in the algorithms, would ensure transparency and allow readers to critically evaluate the findings. The section should also offer a complete account of any limitations in the research design, highlighting areas where future work could refine and improve upon the methodology. This might include discussions of dataset size, generalizability of results, and potential confounding factors. Attention to detail here builds trust and allows for rigorous validation of the study’s conclusions.
Scaling & Limits#
A hypothetical ‘Scaling & Limits’ section for a research paper on synthetic training data would explore the limitations of using synthetic data at scale. It might discuss how the quality of synthetic images can degrade as the quantity increases, impacting model performance. Generator artifacts and inaccuracies in visual details could also be significant factors limiting scalability. The section should analyze whether the cost-effectiveness of synthetic data generation outweighs the potential performance drawbacks, especially compared to efficiently retrieving relevant real images. Furthermore, it would examine the extent to which the generalizability of models trained on synthetic data matches those trained on real-world data, addressing the issue of domain shift and potential biases within synthetic datasets. Finally, ethical considerations related to the use of massive datasets in synthetic data generation would be covered. Privacy, bias, and potential misuse would be key concerns to address in this discussion.
Future Research#
Future research directions stemming from this work could explore several promising avenues. Improving the quality of synthetic data is paramount; this might involve developing techniques to mitigate generator artifacts and better capture fine-grained visual details. Investigating alternative data sourcing strategies beyond simple retrieval from a pre-trained model’s dataset is crucial. This could entail generating synthetic images that are demonstrably absent from the upstream training data or leveraging other large-scale datasets for training and retrieval. Furthermore, exploring the generalizability of findings to other pretrained models and datasets beyond CLIP is warranted. Finally, examining how different adaptation methods (e.g., prompt engineering, fine-tuning) impact the relative performance of real vs. synthetic data would offer valuable insights. Careful attention should be paid to mitigating potential biases in both synthetic and real datasets and to rigorously evaluating the performance of each approach in diverse contexts.
More visual insights#
More on figures

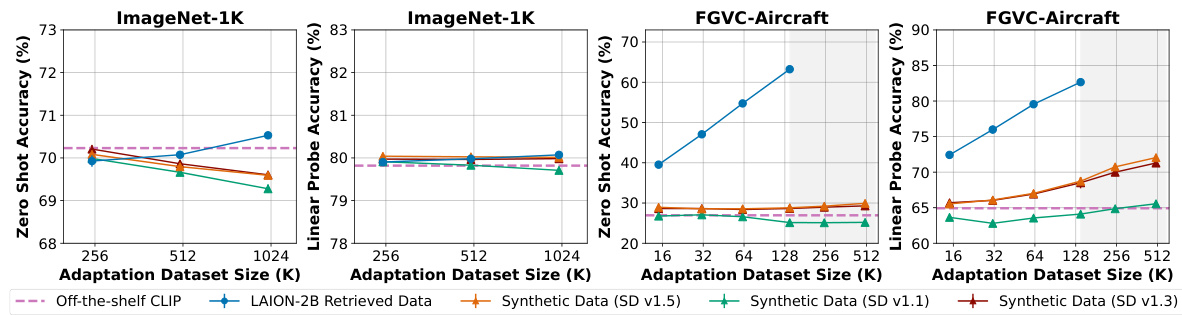
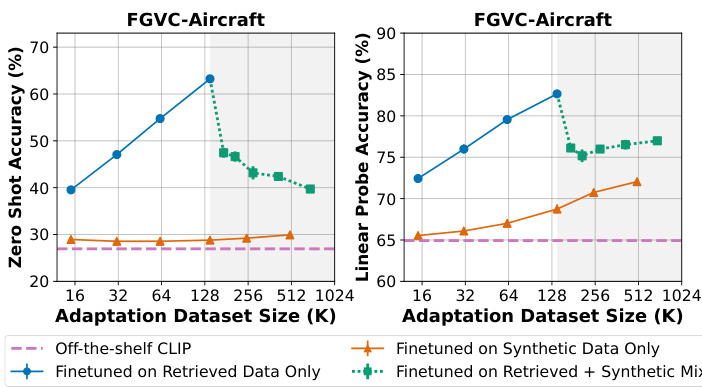
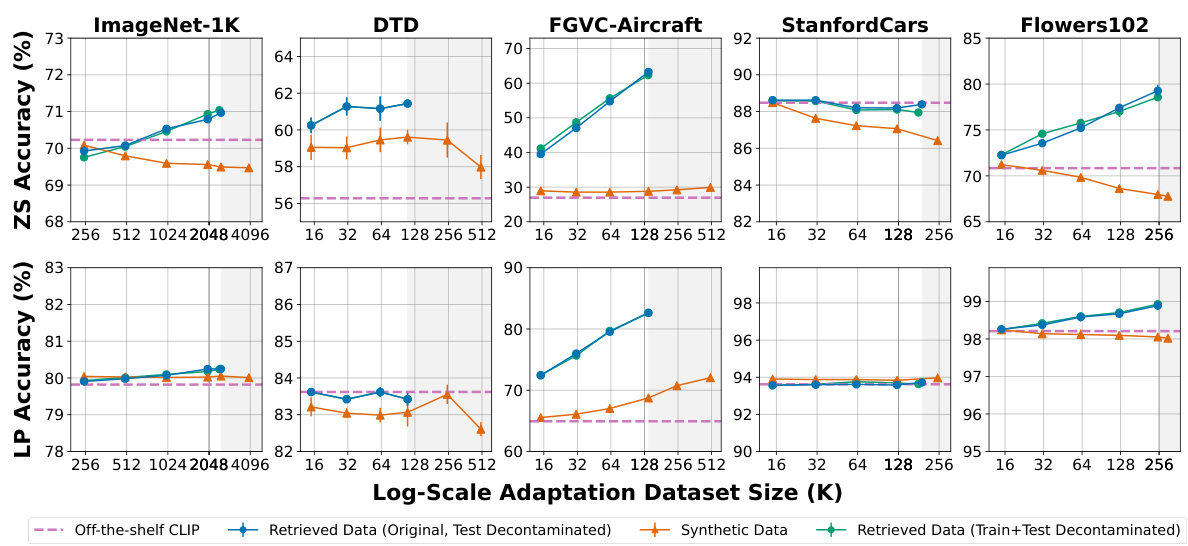
🔼 This figure shows the results of adapting a pretrained CLIP model to five different downstream image classification tasks using either targeted synthetic data generated by Stable Diffusion or targeted real data retrieved from LAION-2B. It compares the zero-shot and linear probing accuracy of the model trained on synthetic vs. real data across various dataset sizes. The key finding is that real data consistently outperforms synthetic data, even when the size of the synthetic dataset is significantly larger.
read the caption
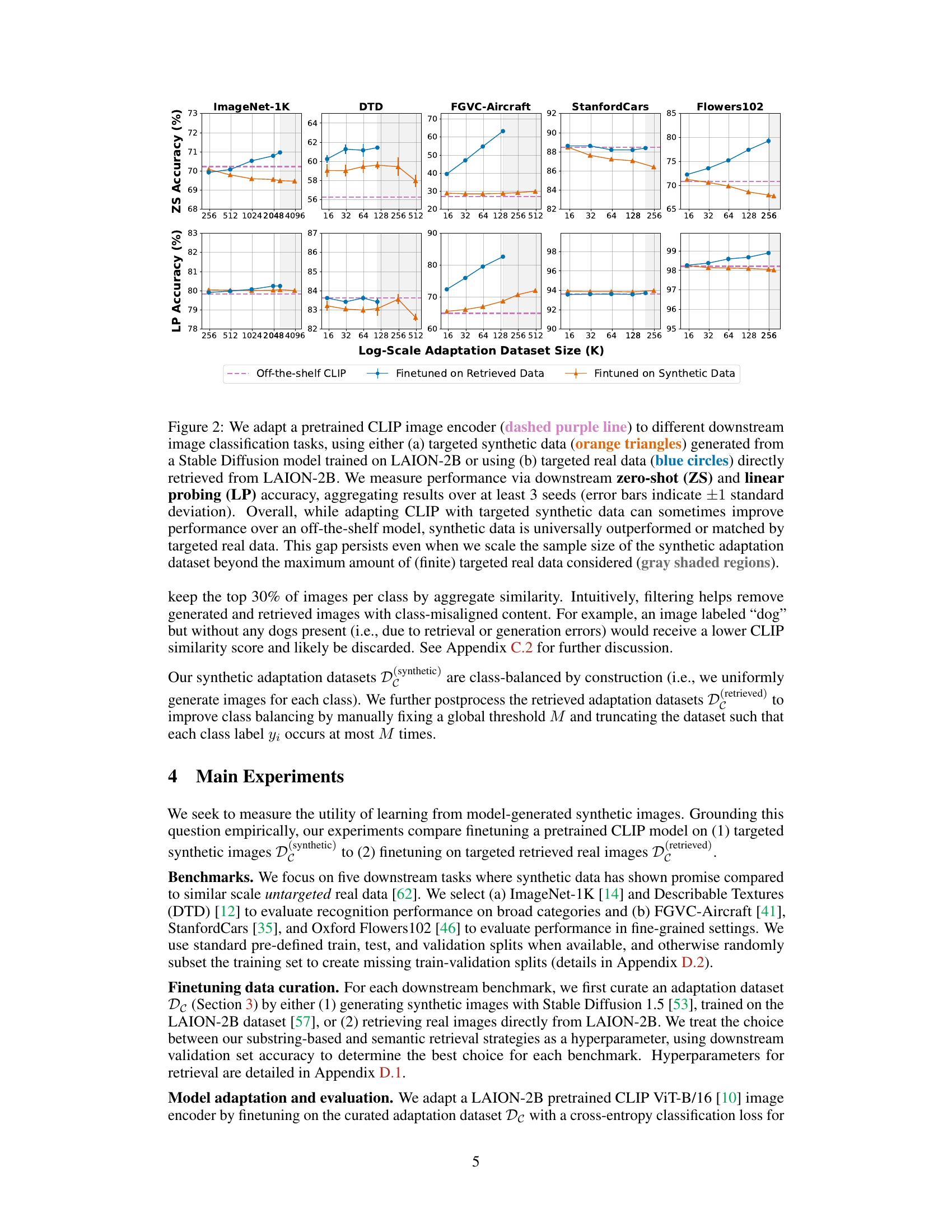
Figure 2: We adapt a pretrained CLIP image encoder (dashed purple line) to different downstream image classification tasks, using either (a) targeted synthetic data (orange triangles) generated from a Stable Diffusion model trained on LAION-2B or using (b) targeted real data (blue circles) directly retrieved from LAION-2B. We measure performance via downstream zero-shot (ZS) and linear probing (LP) accuracy, aggregating results over at least 3 seeds (error bars indicate ±1 standard deviation). Overall, while adapting CLIP with targeted synthetic data can sometimes improve performance over an off-the-shelf model, synthetic data is universally outperformed or matched by targeted real data. This gap persists even when we scale the sample size of the synthetic adaptation dataset beyond the maximum amount of (finite) targeted real data considered (gray shaded regions).

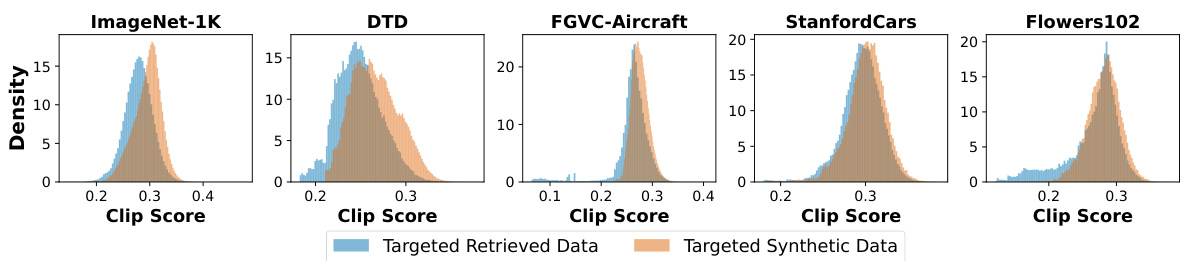
🔼 This figure shows a comparison of real images retrieved from LAION-2B and synthetic images generated by Stable Diffusion for four different classes (Airbus A320, Cessna 172, Flute, Tabby Cat). The left column displays a ground truth image for each class. The next column displays several examples of real images that were retrieved from LAION-2B dataset. The right column presents synthetic images generated by Stable Diffusion model. The figure aims to illustrate the presence of artifacts and distortions of class-relevant details in synthetic images as compared to their real counterparts. The authors hypothesize that these artifacts and distortions in the synthetic images are the reasons for the underperformance of synthetic training data when compared to real training data.
read the caption
Figure 3: We visualize retrieved real images and synthetic images from our targeted adaptation datasets for FGVC-Aircraft (top two rows) and ImageNet-1K (bottom two rows), alongside ground truth images (left column) for reference. Compared to retrieved real images, synthetic images often (1) contain generator artifacts (e.g., the blur on the edges of the “Cessna 172”, the eyes and mouth of the “Tabby Cat”) and also (2) distort class-relevant visual content, such as the engine configuration of a true “Airbus A320” (i.e., exactly one engine per wing) and the entire visual appearance of a “Flute”. We hypothesize that both factors contribute to synthetic training data’s underperformance versus real training data.

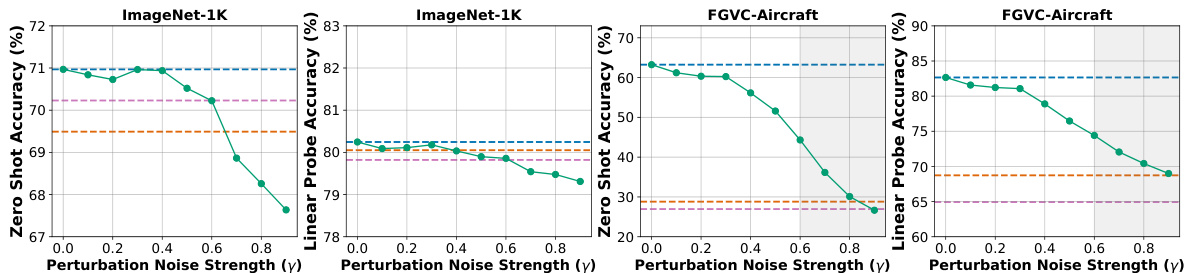
🔼 This figure visualizes the effect of synthetically perturbing real images using Stable Diffusion with varying noise strength (γ). The top row shows an ‘Airbus A320’ image and the bottom row shows a ‘Tabby Cat’ image, both subjected to increasing levels of perturbation (γ = 0.2, 0.4, 0.6, 0.8). The goal is to demonstrate how increasing noise affects image quality and detail, especially for fine-grained recognition tasks. As γ increases, noticeable artifacts and distortions appear, impacting the visual details important for correct classification. The impact of artifacts is more pronounced in fine-grained classification (Airbus) compared to broader categories (Cat).
read the caption
Figure 4: We use Stable Diffusion to synthetically perturb real images according to a noise strength parameter γ∈ [0, 1], where larger γ increases the severity of generator-specific artifacts added by the perturbation. When γ ≥ 0.6, the introduced artifacts can be strong enough to damage task-relevant visual details for finegrained tasks like FGVC-Aircraft (e.g., the airplane's engine and rear wheels). For broad tasks like ImageNet, artifacts have a lesser impact on class-relevant details; the “Tabby Cat” is recognizable as a cat even after perturbing with high γ.
🔼 The figure shows the results of adapting a pretrained CLIP image encoder to five different downstream image classification tasks using either targeted synthetic data generated from a Stable Diffusion model or targeted real data retrieved from the LAION-2B dataset. The results demonstrate that using real data consistently outperforms synthetic data across various dataset sizes and evaluation metrics (zero-shot and linear probing accuracy).
read the caption
Figure 2: We adapt a pretrained CLIP image encoder (dashed purple line) to different downstream image classification tasks, using either (a) targeted synthetic data (orange triangles) generated from a Stable Diffusion model trained on LAION-2B or using (b) targeted real data (blue circles) directly retrieved from LAION-2B. We measure performance via downstream zero-shot (ZS) and linear probing (LP) accuracy, aggregating results over at least 3 seeds (error bars indicate ±1 standard deviation). Overall, while adapting CLIP with targeted synthetic data can sometimes improve performance over an off-the-shelf model, synthetic data is universally outperformed or matched by targeted real data. This gap persists even when we scale the sample size of the synthetic adaptation dataset beyond the maximum amount of (finite) targeted real data considered (gray shaded regions).
🔼 This figure compares the performance of fine-tuning a pre-trained CLIP model on targeted synthetic data generated from Stable Diffusion versus targeted real data retrieved from LAION-2B across five downstream image classification tasks. The results show that while synthetic data can sometimes improve performance over an off-the-shelf model, it’s consistently outperformed or matched by real data retrieved directly from LAION-2B, even when scaling the amount of synthetic data.
read the caption
Figure 2: We adapt a pretrained CLIP image encoder (dashed purple line) to different downstream image classification tasks, using either (a) targeted synthetic data (orange triangles) generated from a Stable Diffusion model trained on LAION-2B or using (b) targeted real data (blue circles) directly retrieved from LAION-2B. We measure performance via downstream zero-shot (ZS) and linear probing (LP) accuracy, aggregating results over at least 3 seeds (error bars indicate ±1 standard deviation). Overall, while adapting CLIP with targeted synthetic data can sometimes improve performance over an off-the-shelf model, synthetic data is universally outperformed or matched by targeted real data. This gap persists even when we scale the sample size of the synthetic adaptation dataset beyond the maximum amount of (finite) targeted real data considered (gray shaded regions).
🔼 This figure compares the performance of fine-tuning a pretrained CLIP model on targeted synthetic data generated from a Stable Diffusion model versus fine-tuning on targeted real data retrieved directly from the LAION-2B dataset. The results show that across various downstream image classification tasks and dataset sizes, the real data consistently outperforms or matches the synthetic data, even when the synthetic dataset is significantly larger.
read the caption
Figure 2: We adapt a pretrained CLIP image encoder (dashed purple line) to different downstream image classification tasks, using either (a) targeted synthetic data (orange triangles) generated from a Stable Diffusion model trained on LAION-2B or using (b) targeted real data (blue circles) directly retrieved from LAION-2B. We measure performance via downstream zero-shot (ZS) and linear probing (LP) accuracy, aggregating results over at least 3 seeds (error bars indicate ±1 standard deviation). Overall, while adapting CLIP with targeted synthetic data can sometimes improve performance over an off-the-shelf model, synthetic data is universally outperformed or matched by targeted real data. This gap persists even when we scale the sample size of the synthetic adaptation dataset beyond the maximum amount of (finite) targeted real data considered (gray shaded regions).
🔼 This figure compares the performance of fine-tuning a pre-trained CLIP image encoder on both targeted synthetic and real data for five downstream image classification tasks. The results demonstrate that using real data consistently outperforms or matches the performance of synthetic data, even when the amount of synthetic data significantly exceeds the amount of real data available. Zero-shot and linear probing accuracies are presented for various dataset sizes.
read the caption
Figure 2: We adapt a pretrained CLIP image encoder (dashed purple line) to different downstream image classification tasks, using either (a) targeted synthetic data (orange triangles) generated from a Stable Diffusion model trained on LAION-2B or using (b) targeted real data (blue circles) directly retrieved from LAION-2B. We measure performance via downstream zero-shot (ZS) and linear probing (LP) accuracy, aggregating results over at least 3 seeds (error bars indicate ±1 standard deviation). Overall, while adapting CLIP with targeted synthetic data can sometimes improve performance over an off-the-shelf model, synthetic data is universally outperformed or matched by targeted real data. This gap persists even when we scale the sample size of the synthetic adaptation dataset beyond the maximum amount of (finite) targeted real data considered (gray shaded regions).
🔼 This figure shows the results of adapting a pretrained CLIP model to five different downstream image classification tasks using either targeted synthetic data generated by Stable Diffusion or targeted real data retrieved from LAION-2B. The results, shown as zero-shot and linear probing accuracy across various dataset sizes, consistently demonstrate that using real data significantly outperforms using synthetic data, even when the synthetic dataset is much larger than the available real data.
read the caption
Figure 2: We adapt a pretrained CLIP image encoder (dashed purple line) to different downstream image classification tasks, using either (a) targeted synthetic data (orange triangles) generated from a Stable Diffusion model trained on LAION-2B or using (b) targeted real data (blue circles) directly retrieved from LAION-2B. We measure performance via downstream zero-shot (ZS) and linear probing (LP) accuracy, aggregating results over at least 3 seeds (error bars indicate ±1 standard deviation). Overall, while adapting CLIP with targeted synthetic data can sometimes improve performance over an off-the-shelf model, synthetic data is universally outperformed or matched by targeted real data. This gap persists even when we scale the sample size of the synthetic adaptation dataset beyond the maximum amount of (finite) targeted real data considered (gray shaded regions).

🔼 This figure compares the performance of fine-tuning a pre-trained CLIP model on two types of data for various downstream image classification tasks: targeted synthetic images generated by Stable Diffusion and targeted real images retrieved from LAION-2B. The results show that even though synthetic data can sometimes improve performance, real data consistently outperforms synthetic data across all tasks and dataset sizes.
read the caption
Figure 2: We adapt a pretrained CLIP image encoder (dashed purple line) to different downstream image classification tasks, using either (a) targeted synthetic data (orange triangles) generated from a Stable Diffusion model trained on LAION-2B or using (b) targeted real data (blue circles) directly retrieved from LAION-2B. We measure performance via downstream zero-shot (ZS) and linear probing (LP) accuracy, aggregating results over at least 3 seeds (error bars indicate ±1 standard deviation). Overall, while adapting CLIP with targeted synthetic data can sometimes improve performance over an off-the-shelf model, synthetic data is universally outperformed or matched by targeted real data. This gap persists even when we scale the sample size of the synthetic adaptation dataset beyond the maximum amount of (finite) targeted real data considered (gray shaded regions).
Full paper#