TL;DR#
Deepfakes, realistic AI-generated forged faces, pose a significant challenge to existing detection methods due to their diverse nature and ability to evade detection across different domains. Current methods often struggle with generalization, failing to perform well on unseen types of forgeries. This limitation arises from the focus on specific forgery artifacts, leaving models vulnerable to new, unseen manipulation techniques. The lack of universally effective features further hinders the development of robust detection systems.
To address these issues, the paper introduces DiffusionFake, a novel plug-and-play framework that enhances the generalization capability of existing deepfake detectors. DiffusionFake injects features extracted by a detector into a pre-trained Stable Diffusion model. This process compels the model to reconstruct the source and target images used in creating the deepfake, forcing the detector to learn richer, more disentangled representations. Extensive experiments demonstrate that DiffusionFake significantly improves cross-domain generalization without requiring additional parameters, showcasing its potential for creating more robust and generalizable deepfake detection systems.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on deepfake detection because it introduces a novel framework that significantly improves the generalization capabilities of existing detection models. The plug-and-play nature of DiffusionFake makes it easily adaptable to various architectures, opening new avenues for research in cross-domain generalization and robust deepfake detection. The findings challenge current approaches and provide a valuable new direction for enhancing the resilience of deepfake detectors against unseen forgeries.
Visual Insights#
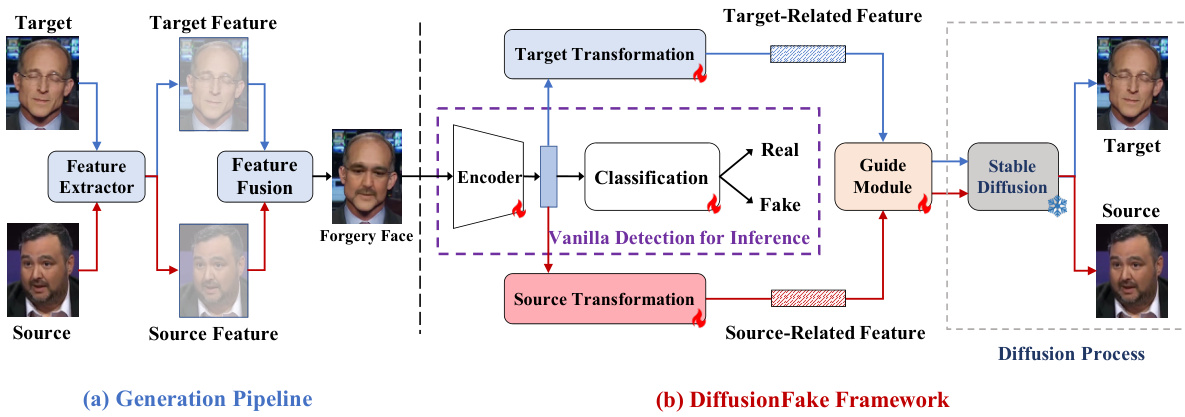
🔼 This figure illustrates the process of generating a deepfake image and the proposed DiffusionFake framework. (a) shows the Deepfake generation pipeline, which includes two key steps: 1) a feature extractor module that extracts features from both the source and target images, and 2) a feature fusion module that seamlessly blends these features to synthesize a new Deepfake image. (b) shows the DiffusionFake framework, which injects the features extracted by a detection model into a pre-trained Stable Diffusion model to guide the reconstruction of the source and target images. This guided reconstruction process helps the detection model learn rich and disentangled representations that are more resilient to unseen forgeries.
read the caption
Figure 1: Pipeline of the generation process of Deepfake (a) and our proposed DiffusionFake (b).

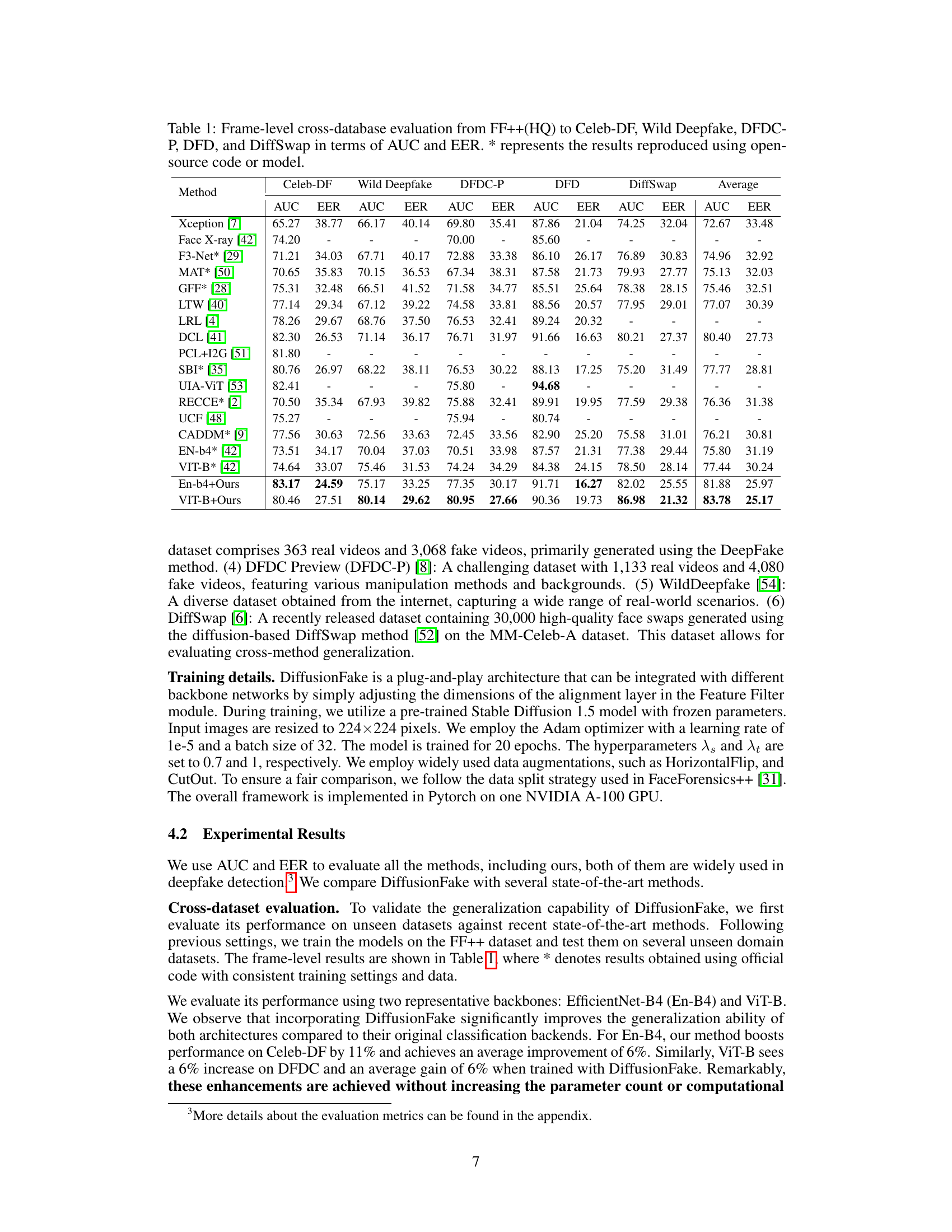
🔼 This table presents the frame-level cross-database evaluation results comparing the performance of different deepfake detection methods. The evaluation is performed across five different datasets: Celeb-DF, Wild Deepfake, DFDC-P, DFD, and DiffSwap, with each method’s performance measured using the Area Under the Curve (AUC) and Equal Error Rate (EER) metrics. The results show the performance when models trained on the FaceForensics++ (FF++) high-quality dataset are tested on the other unseen datasets, evaluating the generalization capabilities of the models.
read the caption
Table 1: Frame-level cross-database evaluation from FF++(HQ) to Celeb-DF, Wild Deepfake, DFDC-P, DFD, and DiffSwap in terms of AUC and EER. * represents the results reproduced using open-source code or model.
In-depth insights#
Deepfake Generation#
Deepfake generation techniques are rapidly evolving, raising significant concerns. The core of deepfake creation involves sophisticated AI models that learn to manipulate facial features and expressions. This often starts with acquiring source and target face images, which are then processed to extract relevant features. These processes leverage advanced techniques like GANs and diffusion models, which can generate highly realistic and seamless face swaps. One crucial aspect is feature extraction and alignment, ensuring the source face seamlessly integrates into the target’s context. This requires handling facial geometry, texture, lighting, and expression consistency across different images. Post-processing steps are often used to enhance realism and address artifacts generated during the synthesis, fine-tuning details to enhance the convincingness of the forgery. The increasing sophistication of these methods presents challenges for detection and underscores the importance of developing countermeasures to mitigate the harmful effects of deepfakes.
DiffusionFake Framework#
The DiffusionFake framework presents a novel approach to deepfake detection by leveraging the generative process of Stable Diffusion. Instead of directly classifying images, it injects features extracted by a pre-trained detection model into the Stable Diffusion model. This forces the model to reconstruct the source and target images underlying the deepfake, compelling the detector to learn disentangled representations of these identities. The framework’s plug-and-play nature allows seamless integration with various detector architectures, improving cross-domain generalization without increasing inference parameters. Reverse engineering the deepfake creation process is key, highlighting the inherent fusion of source and target features within forged images, a characteristic absent in real faces. This clever strategy focuses the detector on learning meaningful feature differences, leading to more robust and generalized deepfake detection.
Cross-Domain Results#
A dedicated ‘Cross-Domain Results’ section would be crucial for evaluating the generalizability of a deepfake detection model. It should present results on multiple, diverse datasets, demonstrating performance beyond the training data. Key metrics such as AUC, precision, recall, and F1-score should be reported for each dataset, along with statistical significance measures to confirm the robustness of the results. Visualizations, such as ROC curves and precision-recall curves, can enhance the analysis. Furthermore, a qualitative analysis of the model’s failure cases on each dataset would provide valuable insights into the model’s limitations and potential areas for improvement. This section would critically demonstrate the model’s ability to generalize its detection capability to unseen data, ultimately highlighting its real-world applicability.
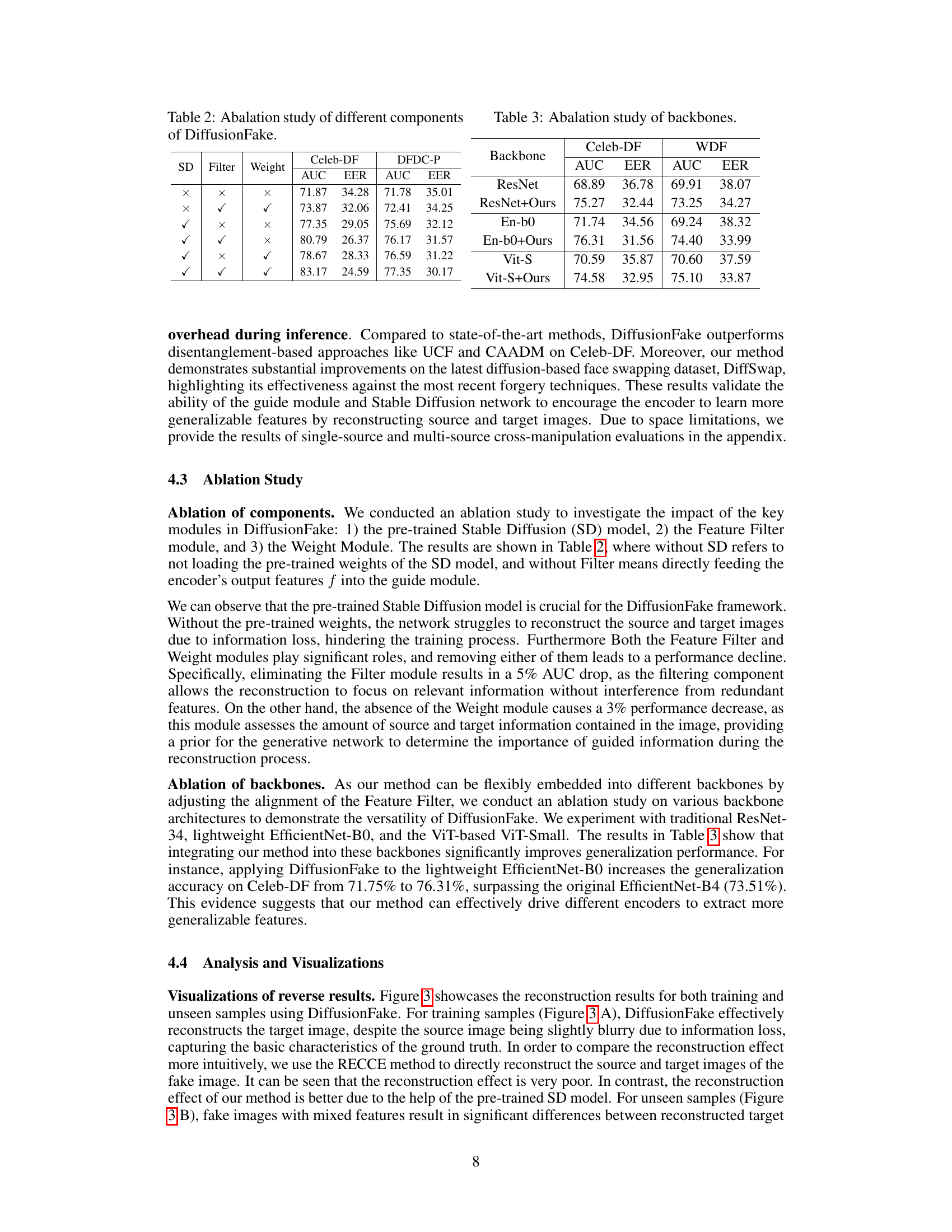
Ablation Studies#
Ablation studies systematically remove components of a model or system to assess their individual contributions. In deepfake detection, this might involve removing parts of a proposed architecture (e.g., specific modules, attention mechanisms), or disabling certain data augmentation strategies. The goal is to isolate the effects of each component, helping to understand their relative importance and identify potential weaknesses or redundancies. Analyzing results across these ablation experiments reveals which components are crucial for achieving high performance and which, if any, can be removed without significant impact on accuracy. This provides valuable insights into model design, guiding future improvements and potentially simplifying the model while maintaining performance. For example, if removing a specific feature extractor only marginally reduces accuracy, it might be pruned to create a leaner, more efficient model. Conversely, a substantial drop in accuracy after removing a particular component highlights its critical role in the system and suggests that it needs further refinement or investigation.
Future Directions#
Future research could explore improving the efficiency and scalability of DiffusionFake, potentially through optimized architectures or more efficient training methods. Investigating the generalizability of DiffusionFake to various forgery techniques beyond those tested (e.g., those involving multiple sources or subtle manipulations) is crucial. Additionally, examining the robustness to different image qualities and resolutions would further validate its effectiveness. Exploring how DiffusionFake’s underlying principles can be adapted for cross-modal forgery detection (e.g., audio or text deepfakes) represents a significant opportunity. Finally, a detailed investigation into the potential for misuse of the technique, and the development of corresponding safeguards, is critical to responsible AI development.
More visual insights#
More on figures

🔼 This figure shows a detailed architecture of the DiffusionFake framework. It illustrates the flow of features extracted from an input image through various modules. The features are split into target-related and source-related components using filter modules, and their weights are adjusted by weight modules. These features are then passed through the Guide Module, which injects them into a pre-trained Stable Diffusion model to reconstruct source and target images. This process guides the encoder in learning disentangled representations, improving generalization for forgery detection. The diagram visually explains the interplay of different components and feature transformations, making the methodology more understandable.
read the caption
Figure 2: The details of the DiffusionFake method. The blue arrow represents the target branch, the red arrow represents the source branch, the represents the parameter frozen and does not participate in training, and the represents the trainable module.
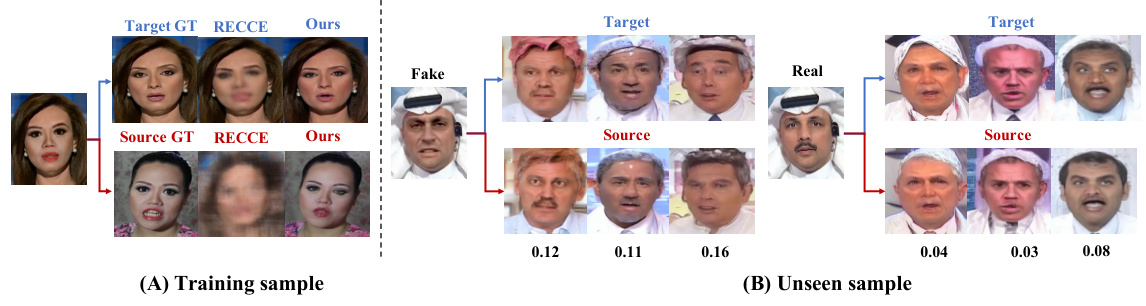
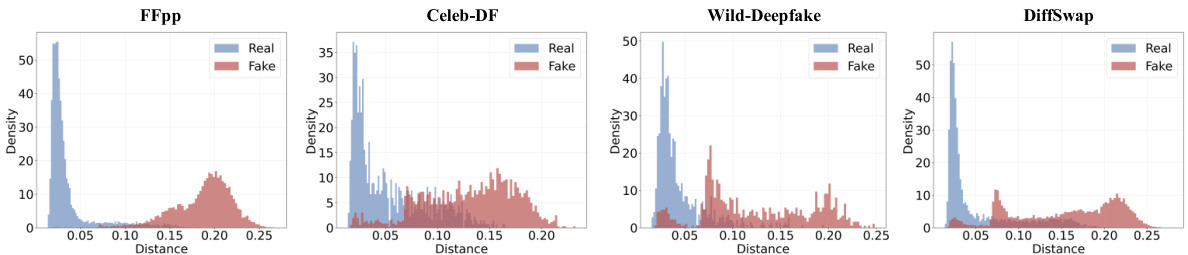
🔼 This figure shows the reconstruction results of the proposed DiffusionFake method for both training and unseen samples. The top row shows the ground truth target image, followed by the reconstruction results using the RECCE method and the proposed DiffusionFake method. The bottom row shows the same for the source image. The unseen samples show three reconstructions with different random noise but with the same injected features, showing the consistency of the method. Euclidean distances between corresponding source and target features are shown below.
read the caption
Figure 3: Reconstruction results of DiffusionFake for training (A) and unseen (B) samples. For unseen samples, the model is provided with three sets of initial Gaussian noise, differing only in the injected guide information. The numbers below represent the Euclidean distance between the corresponding source and target features.
🔼 This figure shows a detailed diagram of the DiffusionFake framework. It illustrates the process of injecting features extracted by the encoder (from a forgery detection model) into a pre-trained Stable Diffusion model. The process involves two main stages: 1. Feature Transformation: The input features are passed through two filter networks (Fs and Ft) to generate source-related (fs) and target-related (ft) representations. These features are weighted by two weight modules (Ws and Wt) that dynamically adjust the influence of source and target information. 2. Guide Module: The weighted source and target features are injected into the Stable Diffusion model. A trainable copy of the encoder block (UE) is created and the features are combined with the locked decoder features using zero convolution layers to guide the reconstruction of source and target images. This guides the encoder to learn rich and discriminative features that benefit generalization of the detection model.
read the caption
Figure 2: The details of the DiffusionFake method. The blue arrow represents the target branch, the red arrow represents the source branch, the represents the parameter frozen and does not participate in training, and the represents the trainable module.

🔼 This figure visualizes the feature distributions of two models (original EfficientNet-B4 and EfficientNet-B4 trained with DiffusionFake) on two unseen datasets (Celeb-DF and Wild-Deepfake) using t-SNE. It demonstrates the impact of DiffusionFake on enhancing the separability of real and fake samples in the feature space. The improved separation in the DiffusionFake-trained model indicates better generalization.
read the caption
Figure 5: Feature distribution of En-b4 model and the En-b4 model trained with our DiffusionFace on two unseen datasets Celeb-DF and Wild-Deepfake via t-SNE. The red represents the real samples while the blue represents the fake ones.

🔼 This figure visualizes Class Activation Maps (CAMs) for both the baseline model (EfficientNet-B4) and the model enhanced with DiffusionFake. It demonstrates the differences in attention focusing on three different datasets: Celeb-DF, Wild Deepfake (WDF), and DiffSwap. The CAMs highlight the regions of the input image that the model considers most important for classification. By comparing the CAMs of the baseline model with those of the DiffusionFake-enhanced model, it is possible to observe whether DiffusionFake improves the focus and precision of the model’s attention when classifying fake faces from different sources.
read the caption
Figure 6: CAM maps of the baseline model (EN-b4) and En-b4 trained with DiffusionFake method on three unseen datasets: Celeb-DF, WDF (Wild-Deepfake), and DiffSwap.

🔼 This figure shows the weights assigned to source and target features by the Weight Module for four different deepfake generation methods: Deepfakes, Face2Face, FaceSwap, and NeuralTextures. The blue arrows represent the weights for target features, and the red arrows represent the weights for source features. The numbers on the arrows indicate the similarity score between the input image and its corresponding source or target image, which is used to calculate the weights. Higher values indicate a stronger similarity, thus more weight is given to either the source or the target feature. The figure visually demonstrates that different deepfake methods have different weight distributions.
read the caption
Figure 7: Visualization of weights for different attack types. The blue lines connect the target weights, while the red lines connect the source weights.

🔼 This figure shows the reconstruction results of the DiffusionFake model for both training and unseen samples. The top row (A) displays the results on training data. The bottom row (B) shows the results on unseen data where the model was given three different initial Gaussian noise sets, only differing in the injected guide information. The numbers under each image represent the Euclidean distance between the reconstructed source and target features, giving a visual representation of how well the model reconstructs the features.
read the caption
Figure 3: Reconstruction results of DiffusionFake for training (A) and unseen (B) samples. For unseen samples, the model is provided with three sets of initial Gaussian noise, differing only in the injected guide information. The numbers below represent the Euclidean distance between the corresponding source and target features.

🔼 This figure shows two examples of images that the model in the paper misclassified. The first row shows profile view images which are difficult to reconstruct due to information loss, and the second row shows low-quality images which are blurry and difficult to extract useful features from. These examples illustrate the limitations of the model in handling certain types of images.
read the caption
Figure 9: Visualization of two typical misprediction samples. Represents Profile view Images and Low-quality Images respectively.
More on tables
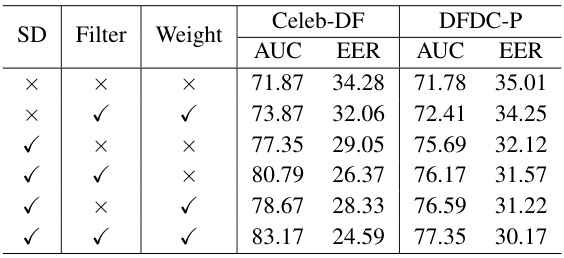
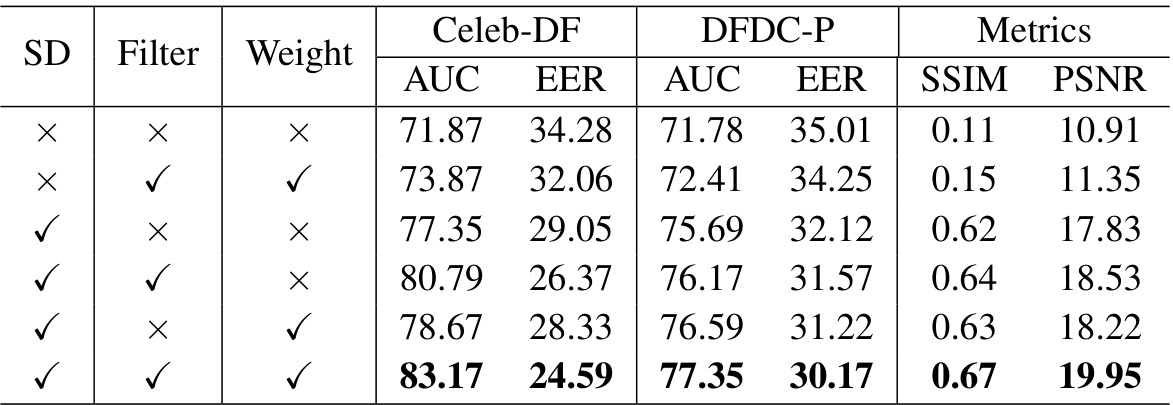
🔼 This table presents the ablation study results for different components of the DiffusionFake model. It shows the impact of removing the pre-trained Stable Diffusion model, the Feature Filter Module, and the Weight Module on the model’s performance. The results are evaluated using AUC and EER metrics on two datasets: Celeb-DF and DFDC-P. Each row represents a different configuration of components, with ‘✓’ indicating that the component was included, and ‘X’ indicating that it was excluded. The table demonstrates the importance of each component for the model’s overall performance.
read the caption
Table 2: Abalation study of different components of DiffusionFake.
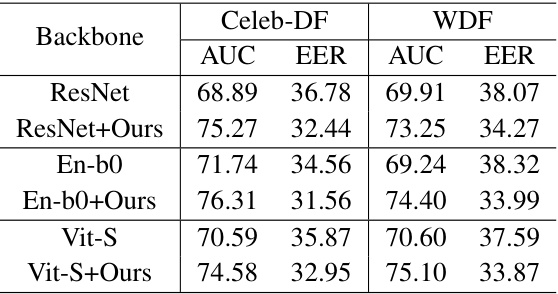
🔼 This table presents the ablation study results on different backbones (ResNet, EfficientNet-B0, ViT-S) with and without the proposed DiffusionFake method. It shows the AUC and EER scores on the Celeb-DF and Wild Deepfake datasets for each backbone to demonstrate the effectiveness and generalizability of DiffusionFake across different architectures.
read the caption
Table 3: Abalation study of backbones.

🔼 This table presents the frame-level cross-database evaluation results comparing different face forgery detection methods. It evaluates performance on several unseen datasets (Celeb-DF, Wild Deepfake, DFDC-P, DFD, and DiffSwap) after training on the FF++(HQ) dataset. The metrics used are Area Under the Curve (AUC) and Equal Error Rate (EER). The asterisk (*) indicates that results were reproduced using publicly available code or pre-trained models.
read the caption
Table 1: Frame-level cross-database evaluation from FF++(HQ) to Celeb-DF, Wild Deepfake, DFDC-P, DFD, and DiffSwap in terms of AUC and EER. * represents the results reproduced using open-source code or model.
🔼 This table presents a frame-level cross-database evaluation of several deepfake detection methods. The models are trained on the high-quality FaceForensics++ (FF++) dataset and then evaluated on five unseen datasets: Celeb-DF, Wild Deepfake, DFDC-Preview, DeepFake Detection, and DiffSwap. The performance is measured using the Area Under the Curve (AUC) and Equal Error Rate (EER) metrics. The table shows AUC and EER scores for each method and dataset, allowing for a comparison of generalization performance across different deepfake datasets and detection models.
read the caption
Table 1: Frame-level cross-database evaluation from FF++(HQ) to Celeb-DF, Wild Deepfake, DFDC-P, DFD, and DiffSwap in terms of AUC and EER. * represents the results reproduced using open-source code or model.

🔼 This table presents a comprehensive evaluation of the DiffusionFake framework’s generalization capabilities. It compares the Area Under the Curve (AUC) and Equal Error Rate (EER) metrics of several state-of-the-art deepfake detection models. The models are trained on the high-quality FaceForensics++ (FF++) dataset and evaluated on five different unseen datasets (Celeb-DF, Wild Deepfake, DFDC-P, DFD, and DiffSwap). This allows for an assessment of cross-dataset generalization performance. The table shows the AUC and EER for each method across different test datasets and provides an average performance across these datasets.
read the caption
Table 1: Frame-level cross-database evaluation from FF++(HQ) to Celeb-DF, Wild Deepfake, DFDC-P, DFD, and DiffSwap in terms of AUC and EER. * represents the results reproduced using open-source code or model.
Full paper#