TL;DR#
Current video LLMs struggle to balance high-quality frame-level semantic details with comprehensive temporal information, hindering fine-grained video understanding. This is because they often rely on sparse sampling of video frames, leading to a loss of crucial temporal details. This paper tackles this limitation.
The proposed SlowFocus mechanism addresses this issue by strategically identifying query-related temporal segments and performing dense sampling within those segments. It combines these high-frequency details with global low-frequency contexts using a novel multi-frequency attention module, significantly improving the model’s ability to understand and reason about fine-grained temporal information. The method is evaluated on existing video understanding benchmarks and a new benchmark specifically designed for fine-grained tasks, demonstrating superior performance.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in video understanding because it directly addresses the limitations of current video LLMs in handling fine-grained temporal information. It introduces a novel mechanism, SlowFocus, that significantly improves the accuracy of video LLMs by improving both the quality of frame-level details and comprehensive video-level temporal information. This enhances the ability of video LLMs to perform more complex reasoning tasks, which is a critical area of current research. The paper also provides a new benchmark for evaluating fine-grained temporal understanding, which is valuable for future research in this area. This work opens exciting avenues for enhancing the capabilities of Video LLMs and facilitating their applications in various real-world scenarios.
Visual Insights#
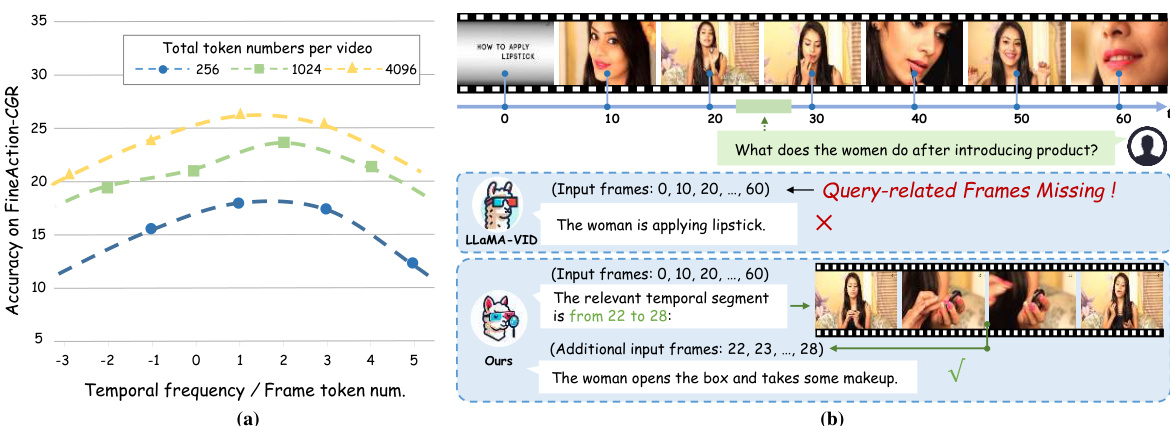
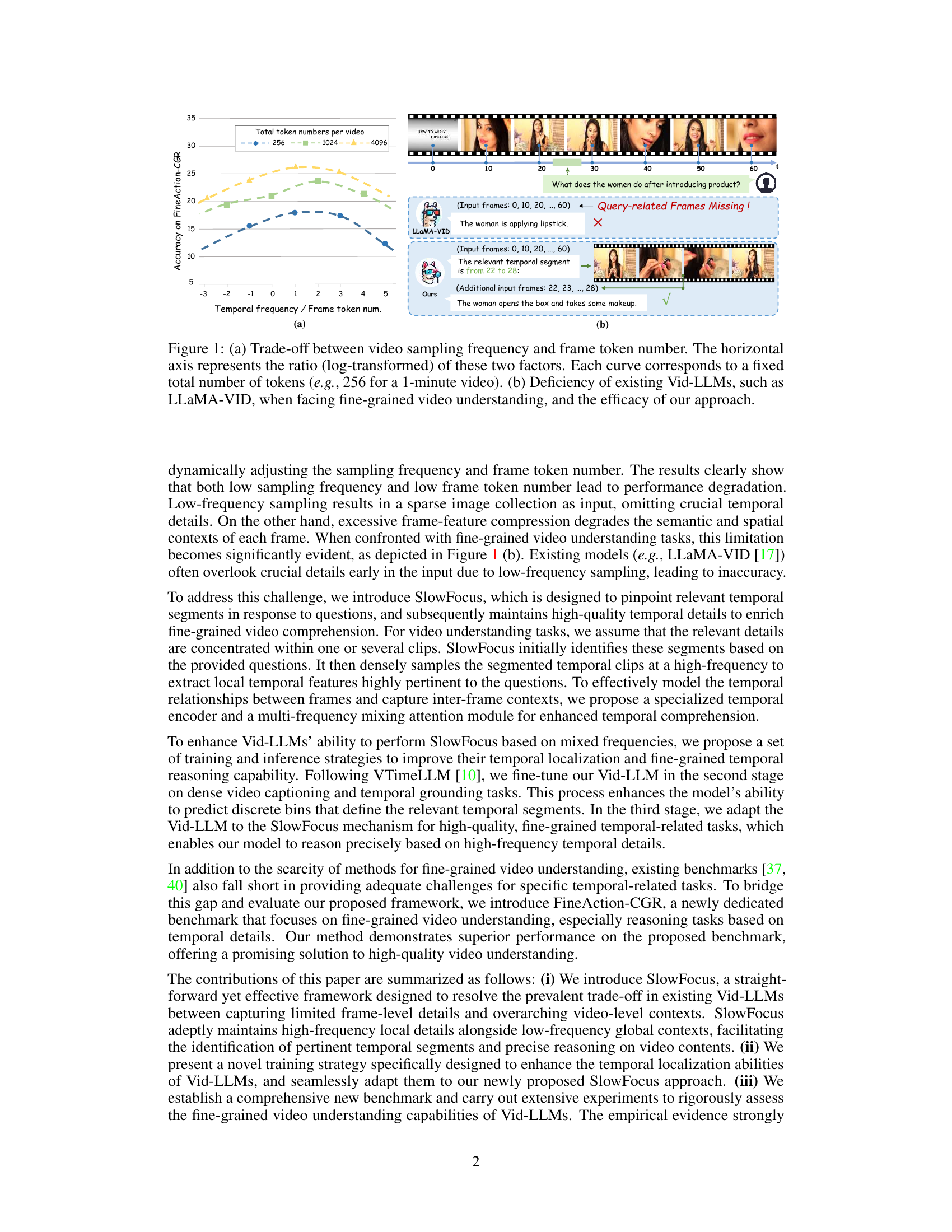
🔼 This figure illustrates the trade-off between video sampling frequency and the number of tokens per frame in video LLMs. Subfigure (a) shows that with a fixed number of total tokens, increasing the sampling frequency (more frames) reduces the number of tokens per frame, and vice versa. This creates a limitation for fine-grained understanding because too few frames miss crucial details, while compressing frames too much reduces the quality of visual information. Subfigure (b) demonstrates how the proposed SlowFocus method addresses this limitation by focusing on relevant temporal segments with high-frequency sampling while maintaining sufficient global context.
read the caption
Figure 1: (a) Trade-off between video sampling frequency and frame token number. The horizontal axis represents the ratio (log-transformed) of these two factors. Each curve corresponds to a fixed total number of tokens (e.g., 256 for a 1-minute video). (b) Deficiency of existing Vid-LLMs, such as LLaMA-VID, when facing fine-grained video understanding, and the efficacy of our approach.
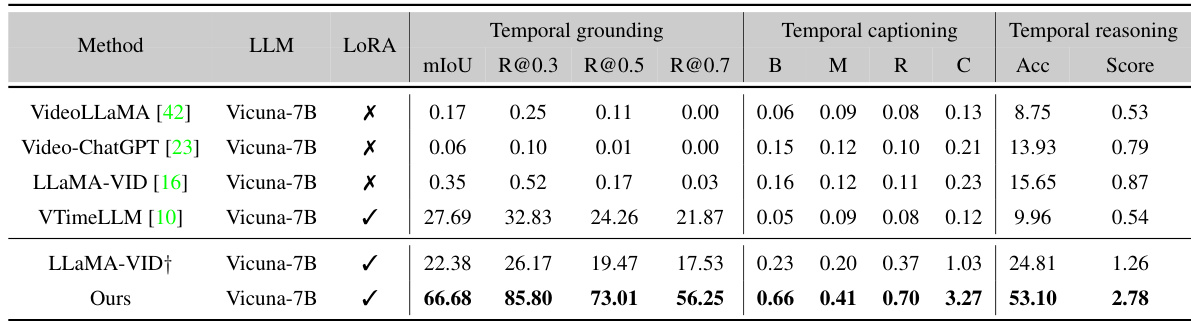
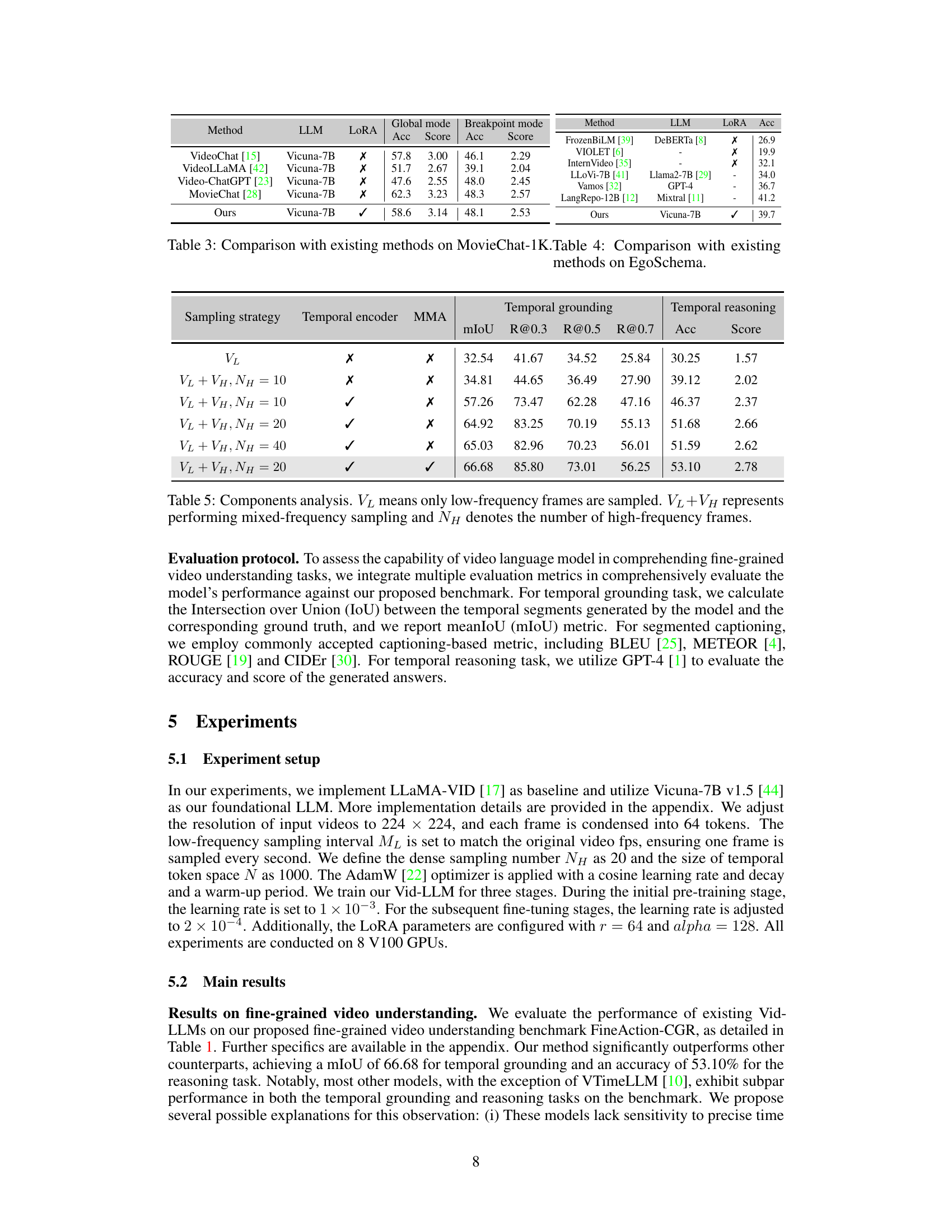
🔼 This table presents the main results of the proposed SlowFocus method on the FineAction-CGR benchmark. It compares the performance of various Video LLMs (VideoLLaMA, Video-ChatGPT, LLaMA-VID, VTimeLLM) against the proposed method, indicating whether LoRA (low-rank adaptation) was used for fine-tuning. Metrics include temporal grounding (mIoU, R@0.3, R@0.5, R@0.7), temporal captioning (B, M, R, C), and temporal reasoning (Acc, Score). The results showcase the significant improvement achieved by the SlowFocus approach.
read the caption
Table 1: Main results on FineAction-CGR benchmark. The column LoRA represents whether the LLM is fine-tuned fully or using LoRA. †: Model is re-trained on the stage 3's data. B: B@4. M: METEOR. R: ROUGE. C: CIDEr.
In-depth insights#
Vid-LLM Challenges#
Video Large Language Models (Vid-LLMs) face significant hurdles in achieving robust fine-grained temporal understanding. A primary challenge stems from the inherent trade-off between maintaining high-quality frame-level semantic information and incorporating comprehensive video-level temporal context. Sparse sampling of frames, often employed due to computational constraints, leads to the loss of crucial temporal details and hinders the model’s ability to capture nuanced interactions and events. Furthermore, current Vid-LLMs struggle with the dilemma of balancing frame-level feature richness against the total number of tokens, often compromising on either detailed visual features or sufficient temporal information. Addressing these challenges necessitates innovative mechanisms that efficiently integrate mixed-frequency temporal features, enhancing the model’s ability to both localize relevant temporal segments and reason about their precise content. Effective solutions might involve novel attention mechanisms, tailored training strategies, and the development of more comprehensive benchmarks designed specifically to assess fine-grained temporal understanding tasks.
SlowFocus Mechanism#
The SlowFocus mechanism tackles the challenge of fine-grained temporal understanding in video LLMs. Existing models struggle to balance high-quality frame-level detail with comprehensive video-level temporal information due to the limitations of sparse sampling. SlowFocus cleverly addresses this by first identifying query-relevant temporal segments. It then performs dense sampling within these segments, capturing high-frequency features crucial for precise understanding. A multi-frequency mixing attention module integrates these high-frequency details with global, low-frequency contexts for holistic comprehension. This innovative approach enhances the model’s capability to process fine-grained temporal information without sacrificing either frame-level detail or overall temporal context. Training strategies are also tailored to improve the Vid-LLM’s ability to perform accurate temporal grounding and detailed reasoning. The effectiveness of SlowFocus is demonstrated through improved performance on existing benchmarks, particularly in tasks demanding fine-grained temporal understanding.
FineAction-CGR#
The heading “FineAction-CGR” suggests a benchmark dataset designed for evaluating fine-grained temporal understanding in video LLMs. FineAction likely refers to a base video dataset with fine-grained annotations of actions, while CGR possibly stands for “Captioning, Grounding, Reasoning,” reflecting the types of tasks the benchmark facilitates. This implies a move beyond simple video captioning towards more nuanced evaluations, such as locating precise temporal segments related to text queries (temporal grounding) and performing logical reasoning based on temporal events in the video. The benchmark likely assesses the model’s capability to handle detailed temporal information and complex relationships between actions within a video. This is crucial because current video LLMs often struggle with fine-grained understanding, often using sparse sampling techniques that may sacrifice temporal precision. Therefore, FineAction-CGR aims to provide a more rigorous and complete evaluation of a video LLM’s capabilities in processing fine-grained temporal details. It offers a valuable contribution by addressing the limitations of existing benchmarks, providing a more comprehensive assessment of video understanding models.
Training Strategies#
The effectiveness of video LLMs hinges significantly on training strategies. A well-designed training strategy should address the inherent trade-offs between frame-level detail and video-level temporal coherence. Modality alignment during pre-training is crucial to ensure proper integration between visual and textual data, typically by aligning visual features with the LLM’s embedding space. This step lays the foundation for subsequent fine-tuning. Boundary enhancement follows, focusing on bolstering temporal grounding and reasoning. This often involves training on datasets rich in temporal annotations and captions, such as dense video captioning and temporal grounding tasks. Finally, SlowFocus adaptation fine-tunes the model to the specific requirements of mixed-frequency sampling and multi-frequency attention. This is a key stage as it incorporates a sophisticated approach to handling both low-frequency global context and high-frequency local detail in video processing, ultimately enhancing fine-grained temporal understanding. The success of this multifaceted approach relies heavily on the chosen datasets and the training methodologies employed to achieve a robust and efficient model that is capable of high-quality temporal video analysis.
Future Works#
Future work in video LLMs could explore several promising avenues. Improving the efficiency and scalability of SlowFocus, perhaps through optimized architectures or approximate methods, is crucial for broader adoption. Extending SlowFocus to other video understanding tasks, beyond those in FineAction-CGR, like video summarization or event prediction, would showcase its versatility. Investigating the impact of different visual encoders and LLMs on SlowFocus’s performance is essential. Addressing the limitations of low-frequency sampling remains important; perhaps novel sampling strategies or alternative tokenization methods can mitigate the trade-off between temporal and frame-level detail. Finally, developing more sophisticated temporal reasoning modules within the Vid-LLM framework is necessary to handle complex temporal relationships and ambiguities in long videos. A more thorough investigation into the effects of various training strategies and their impact on fine-grained temporal understanding is also warranted.
More visual insights#
More on figures
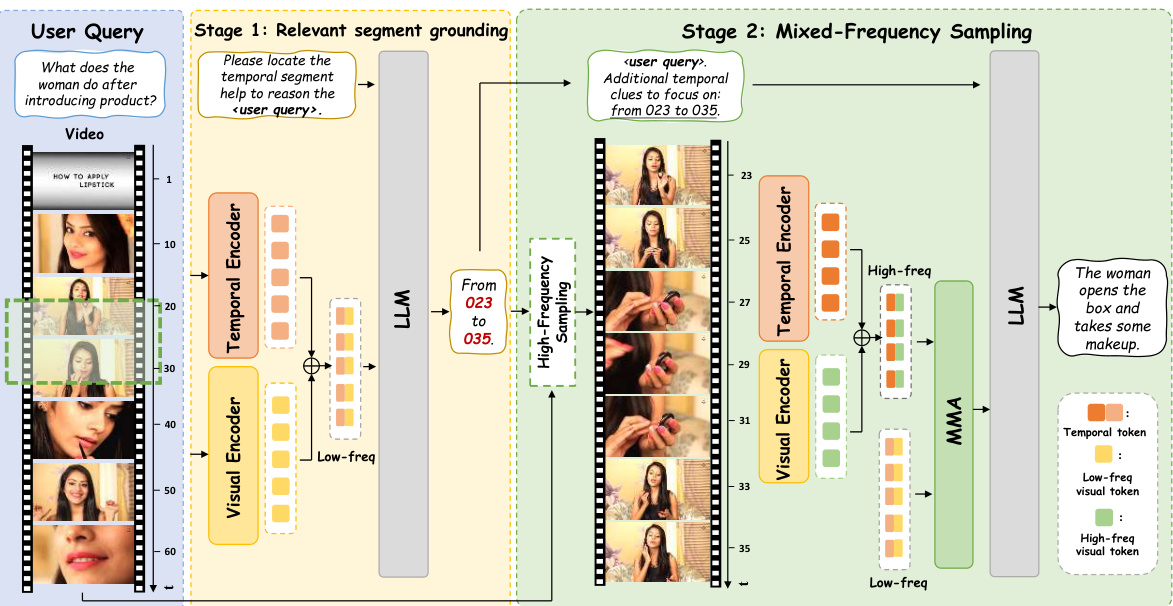
🔼 This figure illustrates the SlowFocus framework, which consists of two main stages. In Stage 1: Relevant segment grounding, a low-frequency sampling of the video is fed to an LLM to identify the relevant temporal segment based on the query. Stage 2: Mixed-Frequency Sampling then performs high-frequency sampling on the identified segment, combining it with the low-frequency sampling to generate mixed-frequency visual tokens for the LLM to answer the query more accurately. The diagram visually represents the process flow, showing the input video, query, processing stages, and the final output.
read the caption
Figure 2: The framework of SlowFocus. We initially identify the relevant temporal segments based on the given query. Subsequently the high-frequency sampling is performed on these segmented clips. Combined with low-frequency sampling across the entire video, our SlowFocus mechanism maintains mixed-frequency visual tokens to accurately answer the query.
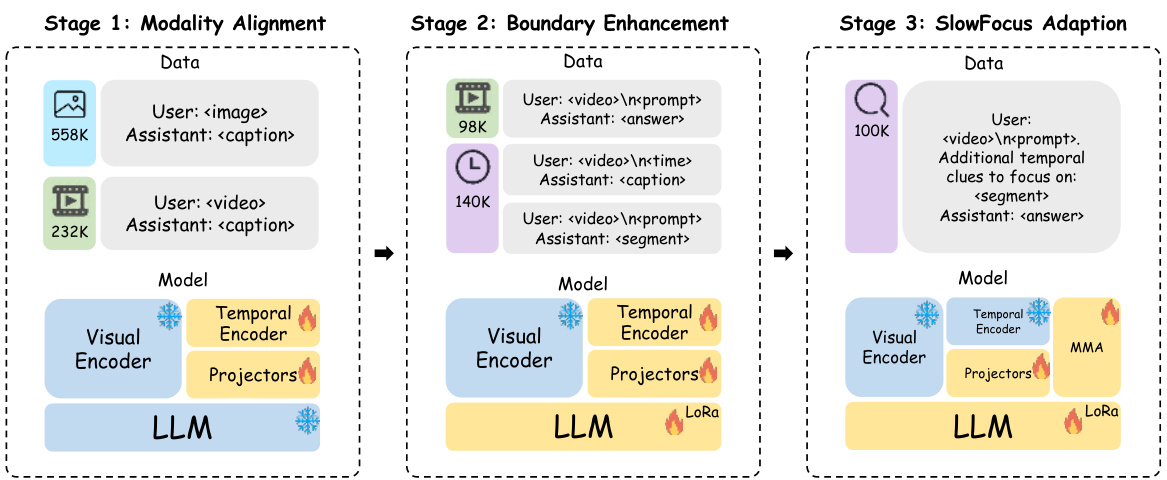
🔼 This figure illustrates the three-stage training process for the SlowFocus model. Stage 1 involves modality alignment using image-text and video-text data to align visual and text embeddings. Stage 2 focuses on boundary enhancement by fine-tuning on tasks such as dense video captioning, segment captioning, and temporal grounding, using a large video dataset. Finally, stage 3 introduces the SlowFocus adaptation, focusing on fine-grained temporal reasoning using specific datasets. Each stage updates the parameters of different model components, including visual encoder, temporal encoder, and LLM.
read the caption
Figure 3: The training strategy of SlowFocus, including data distribution and parameter updating in each stage.and
🔼 The figure illustrates the SlowFocus framework, which involves two stages: 1) identifying query-relevant temporal segments and performing dense sampling (high-frequency) within those segments, and 2) combining these high-frequency features with low-frequency features from the entire video using a multi-frequency mixing attention module. This approach aims to improve fine-grained temporal understanding by preserving both local and global temporal context.
read the caption
Figure 2: The framework of SlowFocus. We initially identify the relevant temporal segments based on the given query. Subsequently the high-frequency sampling is performed on these segmented clips. Combined with low-frequency sampling across the entire video, our SlowFocus mechanism maintains mixed-frequency visual tokens to accurately answer the query.

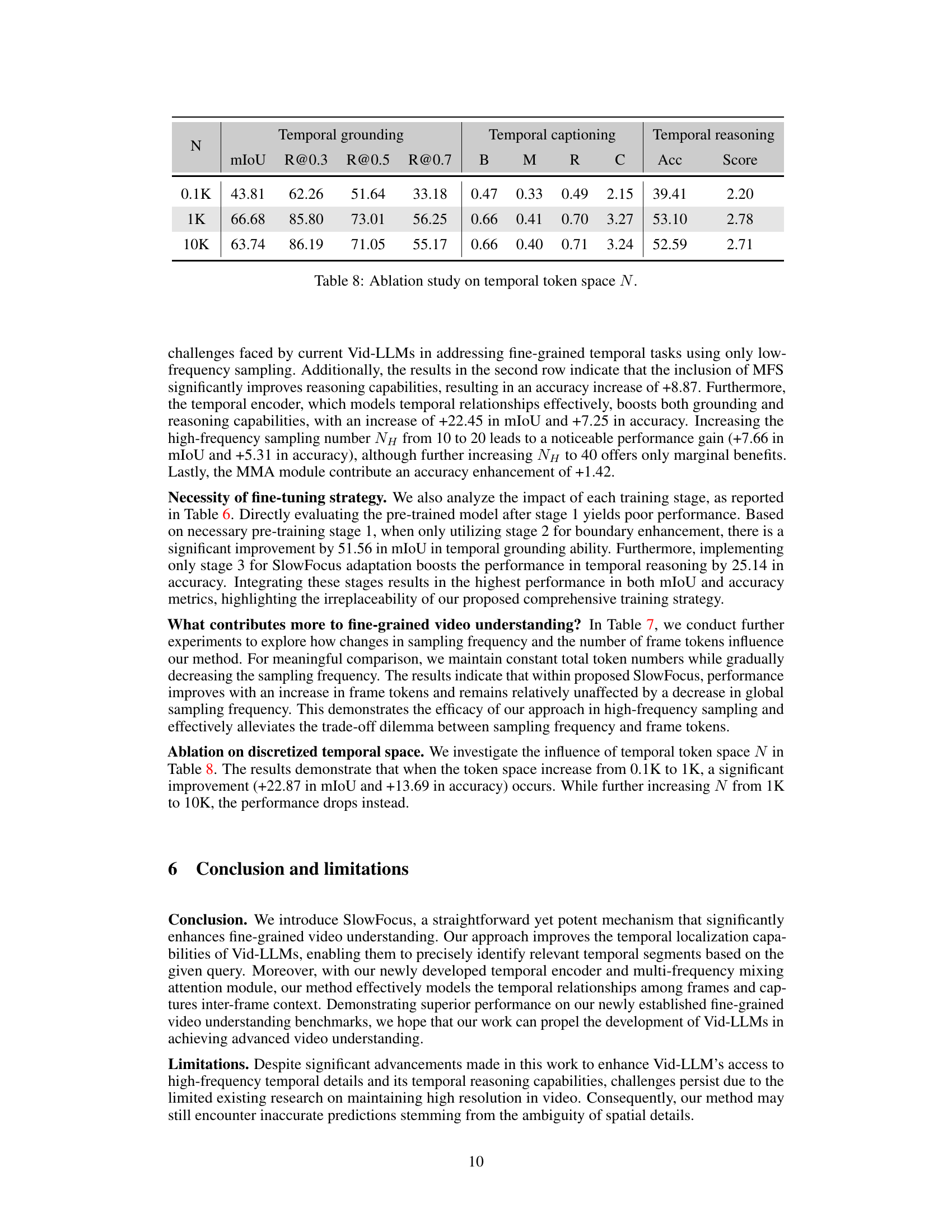
🔼 This figure shows two example scenarios where the SlowFocus model successfully answers fine-grained temporal questions by leveraging segmented temporal information. In the first example, the model correctly identifies that a shot at a specific time in a sports video is not scored, despite only being provided with a sparse set of frames. The second example shows the model correctly predicting the next action in a music video (switching from keyboard to drums) after being provided with contextual cues, also from a limited number of input frames. These examples highlight SlowFocus’s ability to effectively focus on and reason about relevant temporal segments for enhanced fine-grained video understanding, even with sparse input data.
read the caption
Figure 5: Qualitative examples. Our proposed SlowFocus can effectively leverages the segmented temporal clues to accurately answer the posed question.
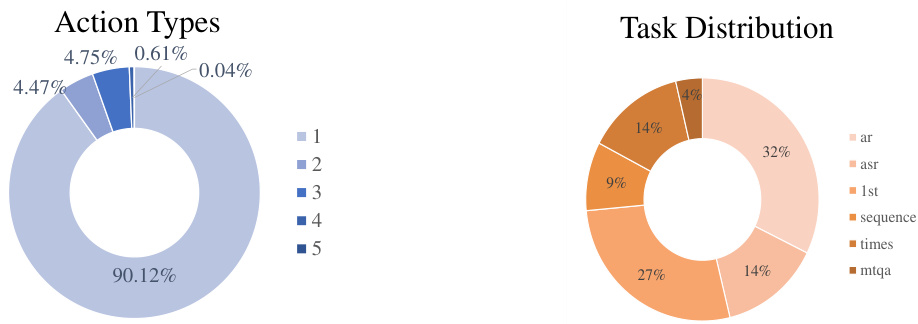
🔼 This figure shows two donut charts visualizing the data distribution in the FineAction-CGR benchmark. The left chart displays the distribution of action types per video, indicating that most videos contain only one type of action. The right chart illustrates the distribution of different tasks within the benchmark, revealing that temporal reasoning and captioning tasks are the most prevalent.
read the caption
Figure 6: Video Statistics in FineAction-CGR. It contains a diverse distribution of action types and tasks
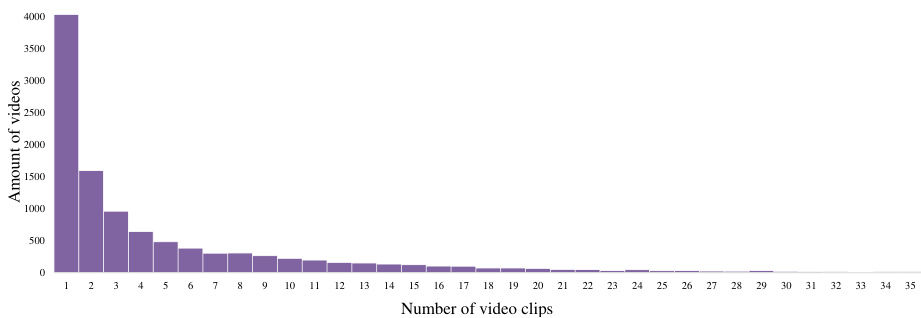
🔼 This figure shows the distribution of the number of video clips per video in the FineAction-CGR dataset. The x-axis represents the number of clips, and the y-axis shows the number of videos containing that many clips. The distribution is heavily skewed to the left, indicating that most videos are composed of a small number of clips, while a much smaller number of videos have a large number of clips. This visualization helps to understand the distribution of video lengths and complexities within the dataset.
read the caption
Figure 7: Distribution of clips number in FineAction-CGR

🔼 This figure illustrates the SlowFocus framework, which consists of two main stages. The first stage is relevant segment grounding, where the model identifies the query-related temporal segment. The second stage is mixed-frequency sampling, where the model performs dense sampling on the identified segment and combines it with low-frequency sampling across the entire video to generate mixed-frequency visual tokens. These tokens are then used to accurately answer the query.
read the caption
Figure 2: The framework of SlowFocus. We initially identify the relevant temporal segments based on the given query. Subsequently the high-frequency sampling is performed on these segmented clips. Combined with low-frequency sampling across the entire video, our SlowFocus mechanism maintains mixed-frequency visual tokens to accurately answer the query.

🔼 The figure illustrates the SlowFocus framework, which involves two stages. First, relevant temporal segments are identified based on the user query. These segments undergo dense, high-frequency sampling to extract detailed visual features. Second, these high-frequency features are combined with low-frequency samples from the entire video. This mixed-frequency approach is used to generate visual tokens fed into an LLM for accurate query answering. The figure highlights the integration of high-frequency and low-frequency sampling to enhance temporal understanding.
read the caption
Figure 2: The framework of SlowFocus. We initially identify the relevant temporal segments based on the given query. Subsequently the high-frequency sampling is performed on these segmented clips. Combined with low-frequency sampling across the entire video, our SlowFocus mechanism maintains mixed-frequency visual tokens to accurately answer the query.

🔼 This figure illustrates the SlowFocus framework. It consists of two main stages: relevant segment grounding and mixed-frequency sampling. First, a temporal segment relevant to the user’s query is identified. Then, high-frequency sampling is performed on that segment, while low-frequency sampling is done on the whole video. These mixed-frequency visual tokens are then used to generate a more precise and complete answer.
read the caption
Figure 2: The framework of SlowFocus. We initially identify the relevant temporal segments based on the given query. Subsequently the high-frequency sampling is performed on these segmented clips. Combined with low-frequency sampling across the entire video, our SlowFocus mechanism maintains mixed-frequency visual tokens to accurately answer the query.

🔼 The figure illustrates the SlowFocus framework’s two-stage process. Stage 1 involves identifying query-relevant temporal segments using a low-frequency sampling of the entire video and a temporal grounding model. Stage 2 performs dense sampling (high-frequency) within these segments, combining these high-frequency details with the global low-frequency context via a multi-frequency mixing attention module. The output is a set of mixed-frequency visual tokens used by the LLM for accurate query answering.
read the caption
Figure 2: The framework of SlowFocus. We initially identify the relevant temporal segments based on the given query. Subsequently the high-frequency sampling is performed on these segmented clips. Combined with low-frequency sampling across the entire video, our SlowFocus mechanism maintains mixed-frequency visual tokens to accurately answer the query.

🔼 This figure illustrates the SlowFocus framework, which involves two main stages. In the first stage, a relevant temporal segment is identified based on the user query. Then, high-frequency sampling is performed densely on this segment to capture fine-grained details. Simultaneously, low-frequency sampling is done for the entire video to provide broader context. These high and low-frequency features are combined using a multi-frequency mixing attention module to generate a unified representation that accurately answers the query.
read the caption
Figure 2: The framework of SlowFocus. We initially identify the relevant temporal segments based on the given query. Subsequently the high-frequency sampling is performed on these segmented clips. Combined with low-frequency sampling across the entire video, our SlowFocus mechanism maintains mixed-frequency visual tokens to accurately answer the query.

🔼 This figure illustrates the trade-off between video sampling frequency and the number of tokens per frame in video LLMs. The left subplot (a) shows curves representing different total token numbers, demonstrating that increasing either sampling frequency or tokens per frame (while maintaining a constant total token number) leads to higher accuracy. The right subplot (b) shows how the proposed SlowFocus approach can overcome the limitations of existing models (like LLaMA-VID) in fine-grained video understanding.
read the caption
Figure 1: (a) Trade-off between video sampling frequency and frame token number. The horizontal axis represents the ratio (log-transformed) of these two factors. Each curve corresponds to a fixed total number of tokens (e.g., 256 for a 1-minute video). (b) Deficiency of existing Vid-LLMs, such as LLaMA-VID, when facing fine-grained video understanding, and the efficacy of our approach.

🔼 This figure illustrates the trade-off between video sampling frequency and the number of tokens per frame in video LLMs. Part (a) shows that with a fixed number of total tokens, increasing the sampling frequency (more frames) decreases the number of tokens per frame, and vice versa. This creates a challenge for Vid-LLMs because high token counts per frame are important for accurate frame-level understanding, while a sufficient number of frames are crucial for capturing temporal information. Part (b) demonstrates how existing models like LLaMA-VID struggle with fine-grained video understanding due to this trade-off, highlighting the proposed SlowFocus approach to overcome this limitation.
read the caption
Figure 1: (a) Trade-off between video sampling frequency and frame token number. The horizontal axis represents the ratio (log-transformed) of these two factors. Each curve corresponds to a fixed total number of tokens (e.g., 256 for a 1-minute video). (b) Deficiency of existing Vid-LLMs, such as LLaMA-VID, when facing fine-grained video understanding, and the efficacy of our approach.

🔼 This figure illustrates the SlowFocus framework, which consists of two stages. Stage 1 involves identifying the relevant temporal segments based on the query using low-frequency sampling of the entire video. Stage 2 then performs dense, high-frequency sampling on those identified segments. The mixed-frequency visual tokens from both stages are then used to answer the query more accurately.
read the caption
Figure 2: The framework of SlowFocus. We initially identify the relevant temporal segments based on the given query. Subsequently the high-frequency sampling is performed on these segmented clips. Combined with low-frequency sampling across the entire video, our SlowFocus mechanism maintains mixed-frequency visual tokens to accurately answer the query.

🔼 This figure illustrates the SlowFocus framework. It shows a two-stage process: first, relevant temporal segments are identified based on the user’s query; second, mixed-frequency sampling (high-frequency on the identified segments and low-frequency across the whole video) is applied to generate visual tokens. These tokens are then used to answer the query, improving fine-grained temporal understanding. The diagram highlights the interplay between query understanding, segment identification, high-frequency sampling, low-frequency sampling, and final answer generation.
read the caption
Figure 2: The framework of SlowFocus. We initially identify the relevant temporal segments based on the given query. Subsequently the high-frequency sampling is performed on these segmented clips. Combined with low-frequency sampling across the entire video, our SlowFocus mechanism maintains mixed-frequency visual tokens to accurately answer the query.

🔼 The figure illustrates the SlowFocus framework. It begins by identifying query-relevant temporal segments within a video. High-frequency sampling is then applied to these segments to capture fine-grained details, while low-frequency sampling covers the entire video to provide context. The resulting mixed-frequency visual tokens are fed into an LLM for question answering.
read the caption
Figure 2: The framework of SlowFocus. We initially identify the relevant temporal segments based on the given query. Subsequently the high-frequency sampling is performed on these segmented clips. Combined with low-frequency sampling across the entire video, our SlowFocus mechanism maintains mixed-frequency visual tokens to accurately answer the query.

🔼 This figure illustrates the SlowFocus framework’s two stages: relevant segment grounding and mixed-frequency sampling. First, the system identifies the relevant temporal segment using a query. Second, it performs dense sampling (high frequency) on that segment and combines it with sparse sampling (low frequency) of the entire video. This approach aims to maintain high-quality frame-level information while also capturing comprehensive video-level temporal information.
read the caption
Figure 2: The framework of SlowFocus. We initially identify the relevant temporal segments based on the given query. Subsequently the high-frequency sampling is performed on these segmented clips. Combined with low-frequency sampling across the entire video, our SlowFocus mechanism maintains mixed-frequency visual tokens to accurately answer the query.

🔼 This figure illustrates the SlowFocus framework. It starts by identifying query-relevant temporal segments. Then, it performs dense sampling (high-frequency) within those segments and combines it with sparse sampling (low-frequency) across the entire video. This mixed-frequency approach aims to provide sufficient high-quality temporal information for accurate query answering.
read the caption
Figure 2: The framework of SlowFocus. We initially identify the relevant temporal segments based on the given query. Subsequently the high-frequency sampling is performed on these segmented clips. Combined with low-frequency sampling across the entire video, our SlowFocus mechanism maintains mixed-frequency visual tokens to accurately answer the query.

🔼 This figure illustrates the SlowFocus framework, which consists of two stages. In the first stage, the system identifies query-relevant temporal segments within a video. In the second stage, the system performs high-frequency sampling within those segments and combines it with low-frequency sampling of the entire video to create mixed-frequency visual tokens. The mixed-frequency tokens are then used to accurately answer the query.
read the caption
Figure 2: The framework of SlowFocus. We initially identify the relevant temporal segments based on the given query. Subsequently the high-frequency sampling is performed on these segmented clips. Combined with low-frequency sampling across the entire video, our SlowFocus mechanism maintains mixed-frequency visual tokens to accurately answer the query.

🔼 This figure illustrates the SlowFocus framework, which involves two main stages. First, relevant temporal segments are identified based on the user query using a low-frequency sampling of the video. Second, high-frequency sampling is performed on the identified segment to capture more details. Both high and low-frequency visual tokens are combined to generate an answer. This allows the model to efficiently handle the trade-off between video sampling frequency and frame token number, improving the accuracy of fine-grained temporal understanding.
read the caption
Figure 2: The framework of SlowFocus. We initially identify the relevant temporal segments based on the given query. Subsequently the high-frequency sampling is performed on these segmented clips. Combined with low-frequency sampling across the entire video, our SlowFocus mechanism maintains mixed-frequency visual tokens to accurately answer the query.

🔼 The figure illustrates the SlowFocus framework, showing a two-stage process. Stage 1 involves identifying the query-relevant temporal segment within the video using a low-frequency sampling of the video frames. Stage 2 performs high-frequency sampling within the identified segment to extract detailed temporal information. These high and low-frequency features are then combined to provide the model with a mixed-frequency representation for accurate query answering.
read the caption
Figure 2: The framework of SlowFocus. We initially identify the relevant temporal segments based on the given query. Subsequently the high-frequency sampling is performed on these segmented clips. Combined with low-frequency sampling across the entire video, our SlowFocus mechanism maintains mixed-frequency visual tokens to accurately answer the query.

🔼 This figure illustrates the SlowFocus framework, which consists of two stages. In the first stage, relevant temporal segments are identified based on the user query. In the second stage, mixed-frequency sampling is performed: dense sampling on the identified segments to extract local high-frequency features, and low-frequency sampling across the whole video. This method maintains mixed frequency visual tokens for accurate query answering.
read the caption
Figure 2: The framework of SlowFocus. We initially identify the relevant temporal segments based on the given query. Subsequently the high-frequency sampling is performed on these segmented clips. Combined with low-frequency sampling across the entire video, our SlowFocus mechanism maintains mixed-frequency visual tokens to accurately answer the query.

🔼 This figure shows two example queries and how the SlowFocus model uses segmented temporal information to answer them more accurately than models that only use low-frequency sampling. The first example involves a query about a woman applying lipstick; the low-frequency sampling approach misses crucial details within the relevant segment (the application itself), while SlowFocus identifies and utilizes the high-frequency features, leading to a correct answer. The second query focuses on predicting what action will occur next after a person is playing the keyboard. Again, SlowFocus’ ability to zoom into a relevant segment (the transition to playing the drums) results in a better prediction than the low-frequency sampling method.
read the caption
Figure 5: Qualitative examples. Our proposed SlowFocus can effectively leverages the segmented temporal clues to accurately answer the posed question.

🔼 The figure illustrates the SlowFocus framework, which involves two stages. First, it identifies query-relevant temporal segments using low-frequency sampling of the entire video. Then, it performs dense, high-frequency sampling within those identified segments. Finally, a multi-frequency mixing attention module combines these high and low-frequency features to generate an answer. This approach aims to improve fine-grained temporal understanding by focusing on relevant segments while maintaining context.
read the caption
Figure 2: The framework of SlowFocus. We initially identify the relevant temporal segments based on the given query. Subsequently the high-frequency sampling is performed on these segmented clips. Combined with low-frequency sampling across the entire video, our SlowFocus mechanism maintains mixed-frequency visual tokens to accurately answer the query.

🔼 This figure illustrates the SlowFocus framework. It starts by identifying the relevant temporal segment using a query. Then, it performs dense sampling (high frequency) within that segment and combines these high-frequency features with low-frequency features from the whole video using a multi-frequency mixing attention module. The combined features are fed to the LLM to answer the query. The process is designed to maintain high-quality frame-level information by focusing on the relevant parts of the video.
read the caption
Figure 2: The framework of SlowFocus. We initially identify the relevant temporal segments based on the given query. Subsequently the high-frequency sampling is performed on these segmented clips. Combined with low-frequency sampling across the entire video, our SlowFocus mechanism maintains mixed-frequency visual tokens to accurately answer the query.

🔼 This figure illustrates the SlowFocus framework. It shows how the model first identifies the query-relevant temporal segment in the video. Then, it performs dense sampling on this segment to extract high-frequency features. These high-frequency features are combined with global low-frequency features through a multi-frequency mixing attention module to improve temporal understanding. Finally, these combined features are used by the LLM to generate the accurate answer.
read the caption
Figure 2: The framework of SlowFocus. We initially identify the relevant temporal segments based on the given query. Subsequently the high-frequency sampling is performed on these segmented clips. Combined with low-frequency sampling across the entire video, our SlowFocus mechanism maintains mixed-frequency visual tokens to accurately answer the query.
More on tables

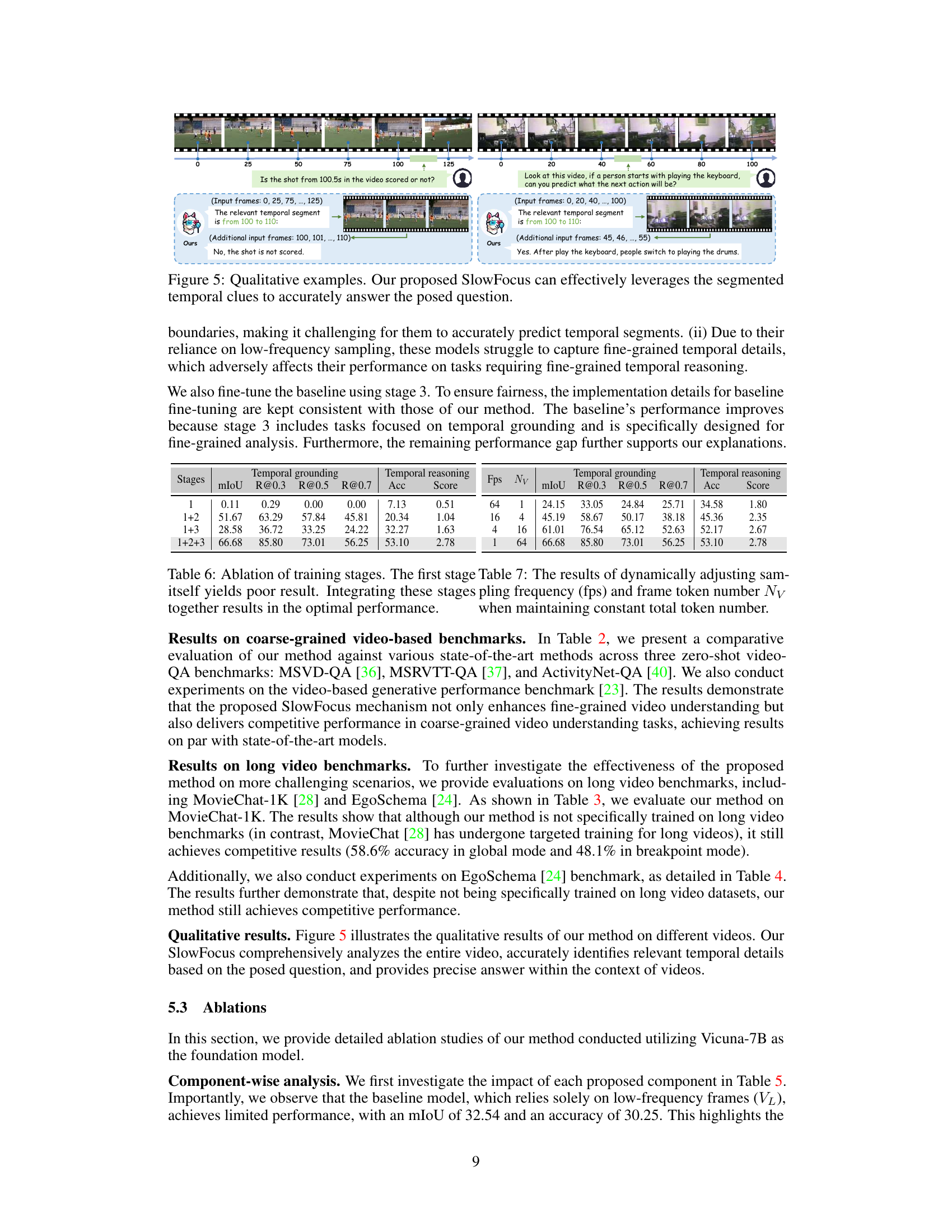
🔼 This table compares the performance of the proposed SlowFocus method against other state-of-the-art models on three widely used coarse-grained video understanding benchmarks: MSVD-QA, MSRVTT-QA, and ActivityNet-QA. The metrics used for evaluation include Accuracy and Score, reflecting overall performance and detailed aspects like correctness, detail, context, temporal aspects and consistency. The results show that SlowFocus achieves comparable performance to the best existing models, highlighting its effectiveness even on tasks that don’t specifically target fine-grained temporal understanding.
read the caption
Table 2: Comparison with existing methods on coarse-grained video understanding benchmarks. Our method achieve on par performance with state-of-the-art models.

🔼 This table presents a comparison of the proposed SlowFocus model’s performance against other state-of-the-art models on two long video understanding benchmarks: MovieChat-1K and EgoSchema. The results show that even without specific training on these long video datasets, SlowFocus achieves competitive performance, highlighting its robustness and generalizability for video understanding.
read the caption
Table 3: Comparison with existing methods on MovieChat-1K.Table 4: Comparison with existing methods on EgoSchema.
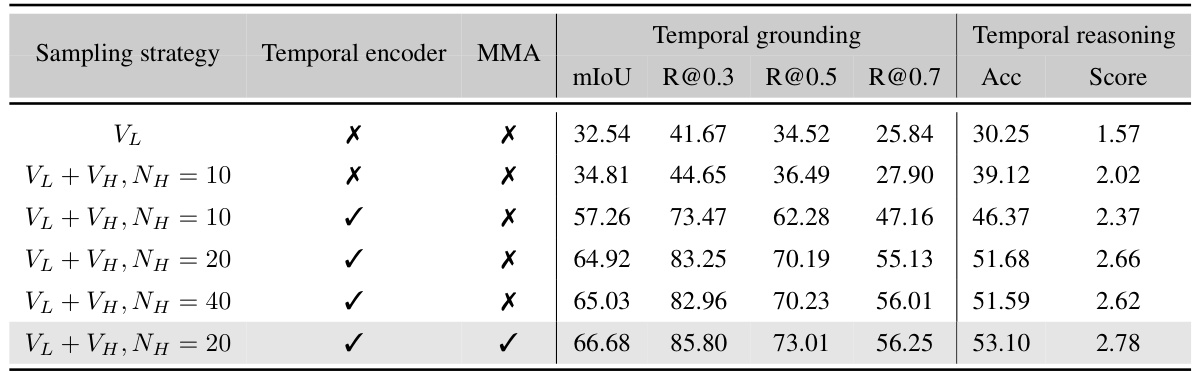
🔼 This table presents the ablation study on different components of the SlowFocus mechanism. It shows the impact of using only low-frequency sampling (VL), adding high-frequency sampling (VL + VH) with varying numbers of high-frequency frames (NH), the effect of the temporal encoder, and the impact of the multi-frequency mixing attention (MMA). The results are evaluated using mIoU, R@0.3, R@0.5, R@0.7 for temporal grounding and Accuracy and Score for temporal reasoning on the FineAction-CGR benchmark.
read the caption
Table 5: Components analysis. VL means only low-frequency frames are sampled. VL+VH represents performing mixed-frequency sampling and NH denotes the number of high-frequency frames.

🔼 This table shows the results of an ablation study on the training stages of the proposed SlowFocus method. It demonstrates that combining all three stages (modality alignment, boundary enhancement, and SlowFocus adaptation) yields the best performance, significantly outperforming models trained with only a subset of the stages.
read the caption
Table 6: Ablation of training stages. The first stage itself yields poor result. Integrating these stages together results in the optimal performance.
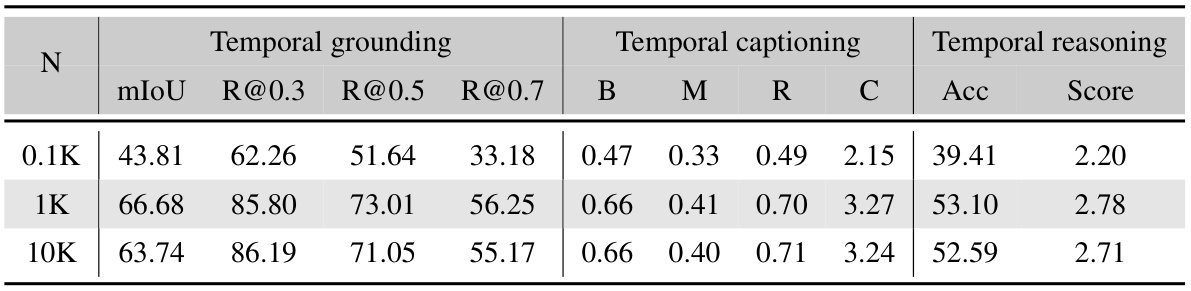
🔼 This table presents the results of an ablation study on the size of the temporal token space (N) used in the SlowFocus mechanism. It shows how changes in N affect the performance of the model across different metrics for temporal grounding, temporal captioning, and temporal reasoning. The results demonstrate the optimal size for N to achieve best performance on fine-grained video understanding tasks.
read the caption
Table 8: Ablation study on temporal token space N.
Full paper#