↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Visual grounding, a crucial task in vision-language understanding, faces challenges with complex text descriptions. Existing methods use intricate fusion modules, limiting performance. The inherent difficulty lies in insufficient downstream data to fully learn multi-modal feature interactions, especially with diverse textual input. This leads to suboptimal performance and computational cost.
SimVG tackles these issues by decoupling visual-linguistic feature fusion from downstream tasks. It leverages pre-trained models and introduces object tokens for better integration. A dynamic weight-balance distillation method is incorporated to improve the simpler branch’s representation. This unique approach significantly simplifies the architecture and achieves faster inference speeds. Extensive experiments across multiple datasets demonstrate SimVG’s superior performance and efficiency, setting new state-of-the-art benchmarks.
Key Takeaways#
Why does it matter?#
This paper is crucial because it introduces SimVG, a novel and efficient framework for visual grounding that outperforms existing methods in accuracy and speed. Its simple architecture and innovative dynamic weight-balance distillation method make it highly relevant to researchers working on improving the efficiency and performance of vision-language models, especially those dealing with complex textual data. SimVG opens up new research avenues for optimizing multi-modal pre-trained models and for applying them to various downstream vision-language tasks.
Visual Insights#
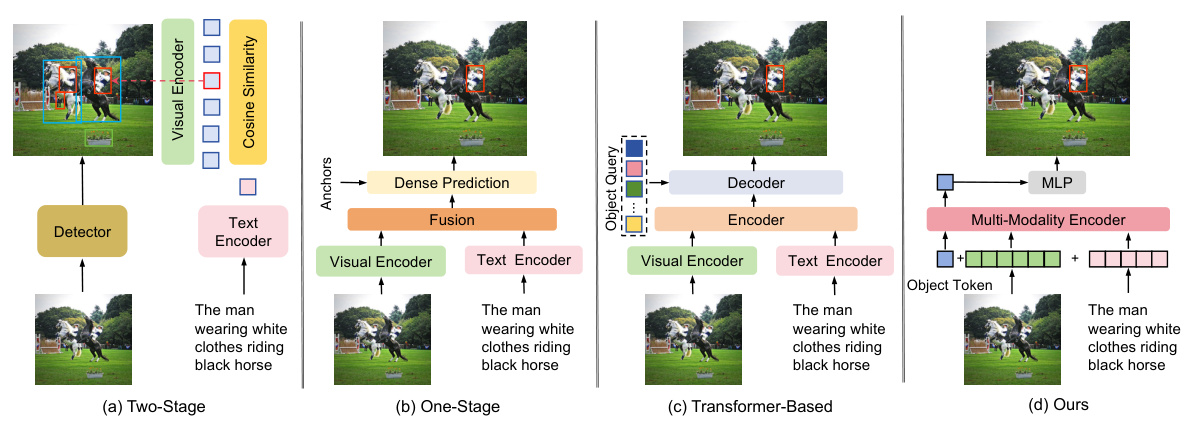
This figure provides a visual comparison of four different visual grounding architectures. (a) shows a two-stage approach using object detection to propose regions, followed by separate image and text encoding and a similarity measure for matching. (b) illustrates a one-stage method performing dense prediction on fused image-text features. (c) presents a transformer-based architecture employing an encoder-decoder to handle the task. Finally, (d) shows the proposed SimVG architecture, which uses a decoupled multimodal encoder and a lightweight MLP for efficient grounding.
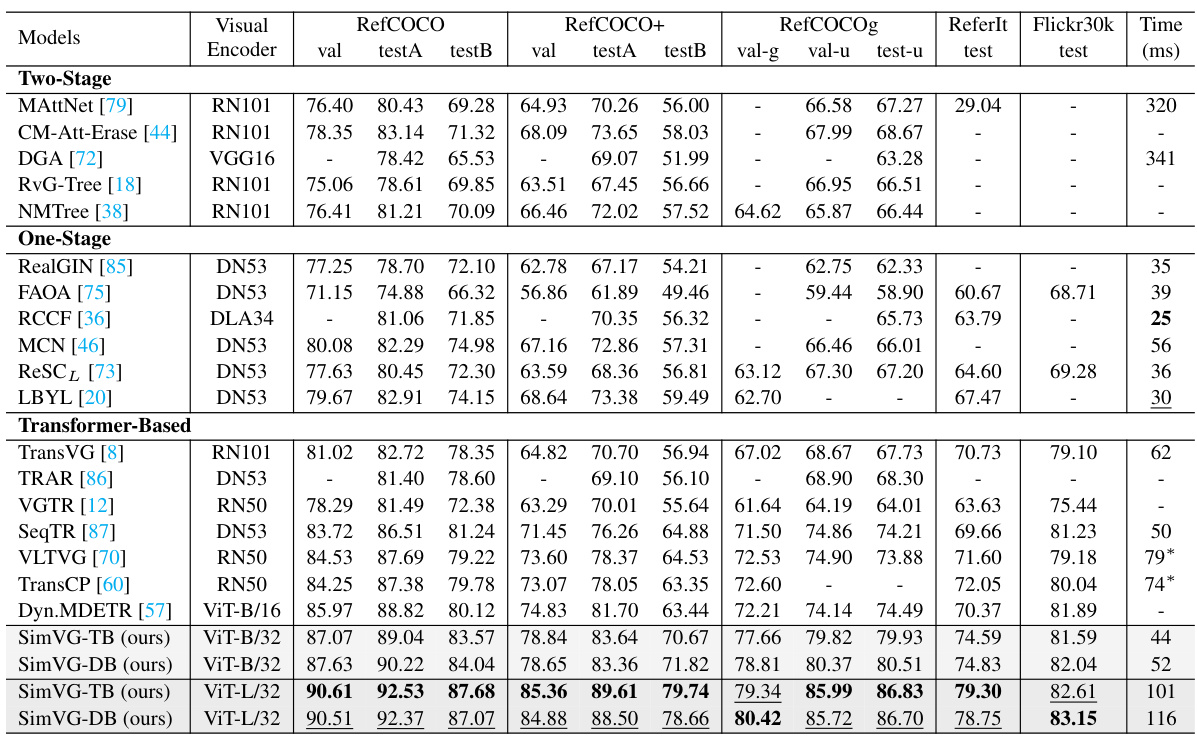
This table compares the performance of SimVG against other state-of-the-art (SOTA) visual grounding models on six widely used datasets (RefCOCO, RefCOCO+, RefCOCOg, ReferIt, Flickr30k, and GRefCOCO). The results are presented in terms of Precision@0.5 (for RefCOCO, RefCOCO+, RefCOCOg, ReferIt, and Flickr30K) and Precision@(F1=1, IoU≥0.5) and N-acc (for GRefCOCO). The table also indicates the visual encoder used (ResNet101, DarkNet53, VGG16, or ViT-Base), inference time (in milliseconds), and whether an RTX 3090 or GTX 1080Ti GPU was used for testing. It also shows results for SimVG using only the token branch (SimVG-TB) and only the decoder branch (SimVG-DB) for comparison.
In-depth insights#
SimVG Framework#
The SimVG framework presents a novel approach to visual grounding by emphasizing simplicity and efficiency. Its core innovation lies in decoupling visual-linguistic feature fusion from downstream tasks, leveraging the power of pre-trained multimodal models. This decoupling allows for a more streamlined architecture, reducing complexity and improving reasoning speed. The framework incorporates object tokens to enhance the integration between pre-training and downstream tasks, resulting in a more robust and effective model. Further enhancements, such as the dynamic weight-balance distillation method, further boost the performance of the lightweight MLP branch. This careful design leads to a system that not only achieves state-of-the-art results on various benchmarks but also demonstrates significant improvements in efficiency and convergence speed. The text-guided query generation module adds another layer of sophistication by incorporating textual prior knowledge, adapting well to scenarios involving diverse and complex text inputs. Simplicity and robustness are therefore central to the design philosophy of the SimVG framework, making it a significant contribution to the field of visual grounding.
Decoupled Fusion#
Decoupled fusion in multi-modal learning, specifically visual grounding, offers a compelling approach to improve model efficiency and performance. By separating the fusion of visual and linguistic features from downstream tasks like object localization, the method mitigates the limitations of traditional fusion modules that struggle with complex expressions. This decoupling allows for leveraging pre-trained models to perform the initial fusion, capitalizing on their substantial multimodal understanding learned from massive datasets. This is a key advantage as limited downstream data would otherwise constrain the fusion model’s capability. Furthermore, decoupled fusion facilitates the integration of additional object tokens to help bridge the gap between pre-training and downstream tasks, leading to better feature integration. This modularity also enhances the architecture’s flexibility, enabling the incorporation of techniques like dynamic weight-balance distillation to improve performance. By simplifying downstream components—as in replacing a complex decoder with a simpler module like a lightweight MLP—the overall architecture benefits from improved speed and efficiency. Therefore, a decoupled fusion approach is vital for handling the complexity and diversity inherent in visual grounding, ultimately enabling more effective and efficient visual grounding models.
DWBD Distillation#
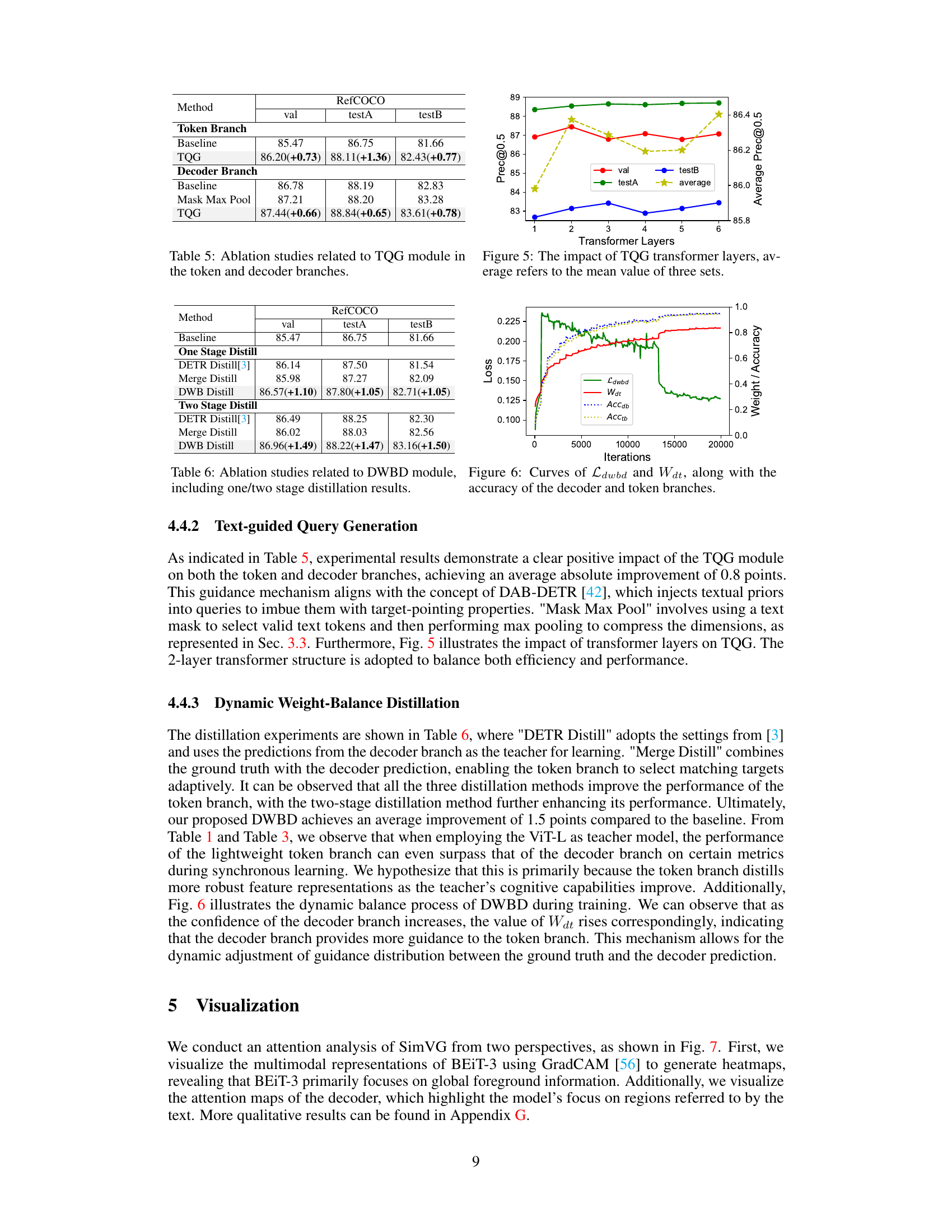
Dynamic Weight-Balance Distillation (DWBD) is a novel knowledge distillation method designed to enhance the performance of a lightweight branch within a visual grounding model. It addresses the challenge of effectively transferring knowledge between two branches with shared features by dynamically adjusting weights assigned to the decoder’s predictions and ground truth during training. This dynamic weighting prevents the teacher model (decoder branch) from dominating the learning process, particularly in earlier training phases, allowing the student model (lightweight branch) to learn effectively from both the ground truth and the teacher’s refined predictions. The weight balance adapts based on the decoder’s confidence, gradually shifting from ground truth-based guidance to teacher-based guidance as the decoder’s predictive ability improves. This approach promotes efficient inference because the lightweight token branch alone can be used for prediction at the end, simplifying the overall architecture and speeding up the inference time. The effectiveness of DWBD is experimentally validated, showing improvements in performance and convergence speed, even surpassing the teacher model under certain conditions.
TQG Module#
The Text-guided Query Generation (TQG) module is a crucial component enhancing the SimVG framework’s performance. Its primary function is to intelligently integrate textual information directly into the object queries, thereby improving the model’s ability to locate relevant image regions. Instead of relying on generic, pre-defined object queries, the TQG module dynamically generates queries informed by the input text, leading to a more contextually relevant and accurate grounding process. This dynamic approach is particularly beneficial when dealing with complex or nuanced textual descriptions, as it allows the model to adapt its search based on the specific information contained within the text. The TQG module acts as a bridge, effectively aligning the visual and textual modalities by enriching object queries with semantic meaning extracted from the text. This design choice significantly improves mutual understanding between modalities and enables the model to perform more effectively in challenging visual grounding tasks. The incorporation of the TQG module is a significant step towards a more sophisticated and robust approach to visual grounding, showcasing a move away from simpler, static query methods towards a more dynamic and adaptable framework.
Future VG#
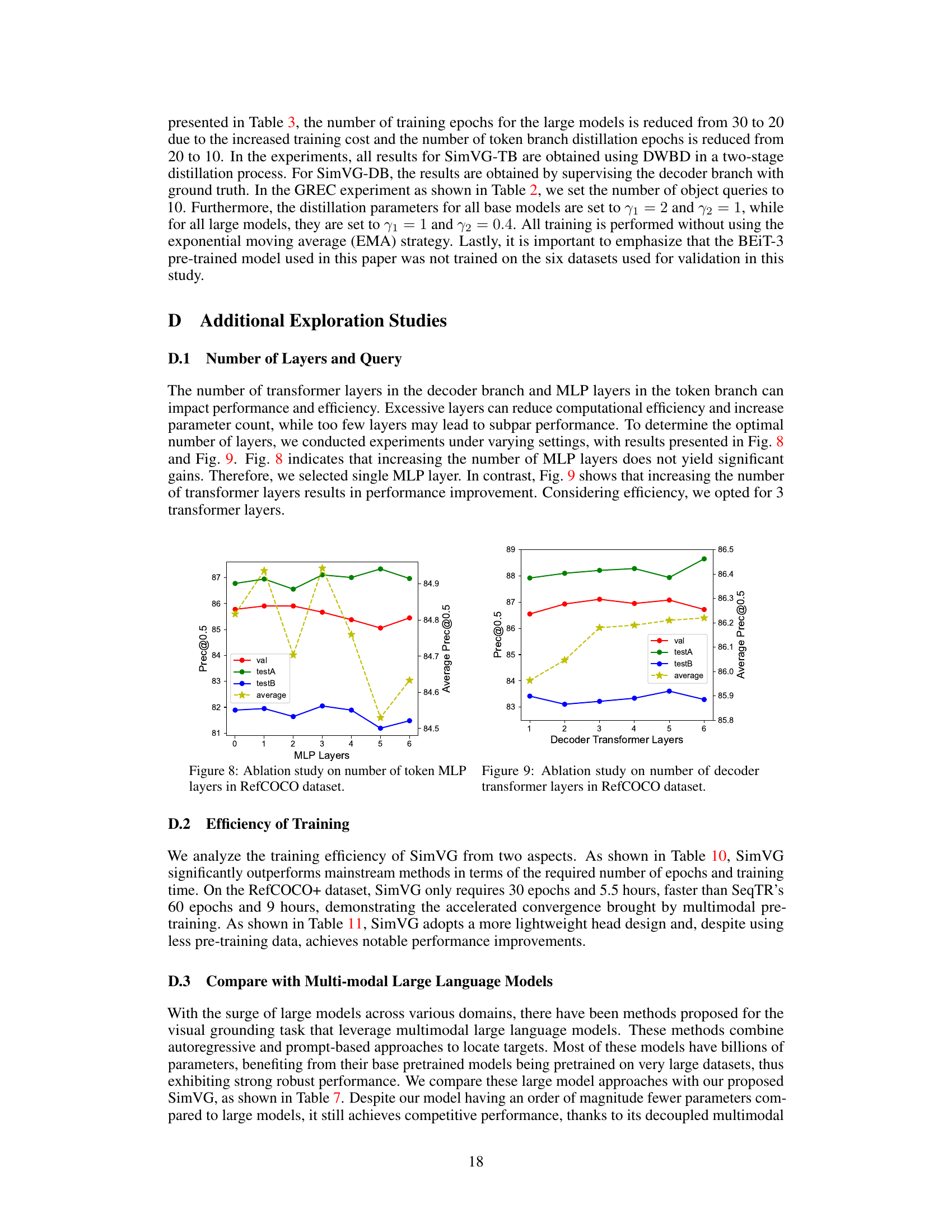
Future research in Visual Grounding (VG) should prioritize addressing the limitations of current methods. This includes improving robustness to complex linguistic expressions and handling scenarios with multiple or ambiguous references. Developing more efficient and scalable models, perhaps through lightweight architectures or more effective knowledge distillation techniques, is crucial. Addressing the inherent bias present in existing datasets is another major challenge that needs to be tackled. Furthermore, exploring novel fusion mechanisms that go beyond simple concatenation or attention-based approaches could unlock significant performance improvements. Zero-shot and few-shot learning capabilities would enhance the generalizability and practical applications of VG. Finally, incorporating external knowledge sources and contextual information will pave the way to more sophisticated and nuanced visual grounding capabilities. This could lead to advancements across various application domains, including image retrieval, question answering, and human-computer interaction. Investigating the ethical implications of advanced VG models should also be a focus area for future research.
More visual insights#
More on figures

This figure shows the average expression length and the relative improvement of SimVG over Dynamic MDETR on six different visual grounding datasets. The datasets are ordered from longest average expression length (RefCOCOg) to shortest (Flickr30k). The results indicate that SimVG shows a more significant improvement on datasets with longer expressions, suggesting that its decoupled multi-modal understanding approach is particularly beneficial for more complex sentences.
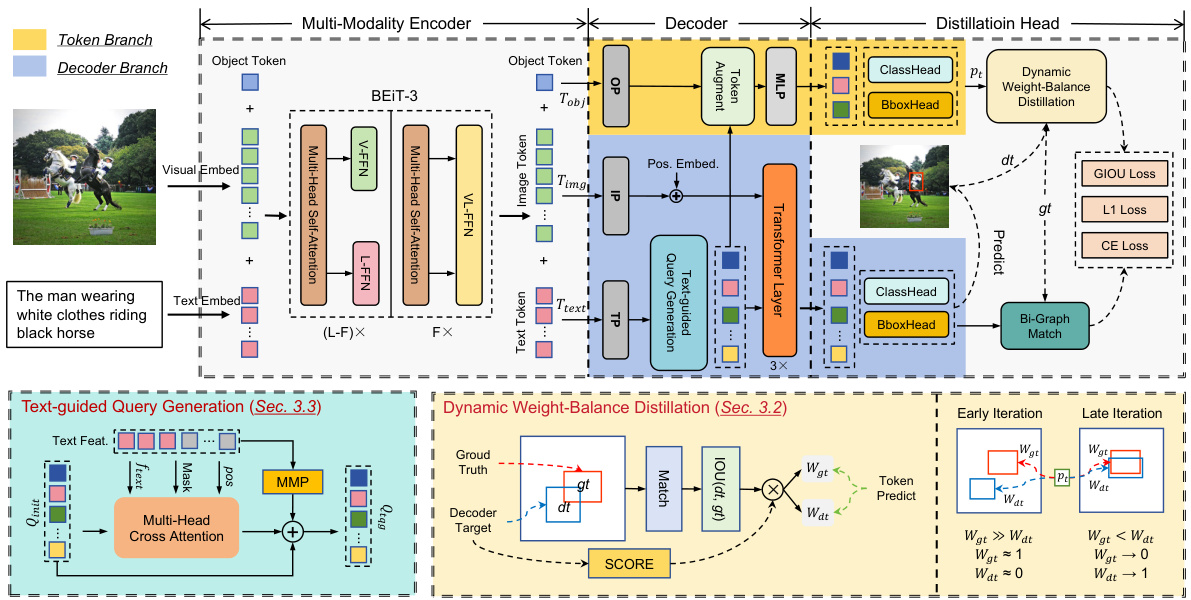
This figure shows the overall architecture of SimVG, a visual grounding framework. It highlights the multi-modality encoder which processes image, text, and object tokens. The decoder is split into two branches: a heavier transformer-based decoder branch and a lightweight MLP-based token branch. A dynamic weight-balance distillation method is employed to train these two branches synchronously, with the decoder branch acting as a teacher to guide the token branch. The text-guided query generation (TQG) module is also shown, which incorporates text information into object queries. The figure further illustrates the distillation head, which computes losses to guide the learning process, and how it uses weights to dynamically balance the contributions of the decoder and token branches during training.

This figure shows the training curves for three different multimodal pre-training architectures: BEiT-3, CLIP, and ViLT. The y-axis represents the precision@0.5 metric, a common evaluation metric for visual grounding tasks, indicating the accuracy of the model in locating the correct region of an image given a textual description. The x-axis represents the number of training epochs. The plot demonstrates that BEiT-3 and ViLT converge significantly faster than CLIP, reaching higher precision scores with fewer training iterations. This suggests that decoupling multimodal fusion from downstream tasks, as done in BEiT-3 and ViLT, offers benefits in terms of training efficiency.
The figure shows the training curves for three different multimodal pre-training architectures (CLIP, ViLT, and BEiT-3) on the RefCOCO dataset, focusing on the convergence speed of Prec@0.5. It demonstrates that models using decoupled multimodal fusion (ViLT and BEiT-3) converge significantly faster than the CLIP model, which performs only cross-modal alignment. The faster convergence of BEiT-3 and ViLT suggests the benefit of separating multimodal fusion from downstream tasks in the overall model architecture.
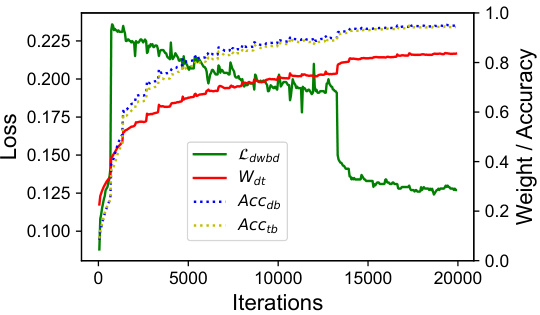
This figure shows the curves of the dynamic weight-balance distillation loss (Ldwbd) and the dynamic weight (Wdt) during the training process. It also displays the accuracy of both the decoder branch (Accdb) and the token branch (Acctb). The plot illustrates how the loss and weights change over iterations, and how these changes relate to the performance of the two branches. The dynamic weight (Wdt) initially favors the ground truth, shifting towards the decoder branch’s prediction as training progresses. This shows the effectiveness of the dynamic weight-balance distillation in balancing the learning between the two branches.

This figure shows a detailed overview of the SimVG architecture, highlighting the multi-modality encoder, decoder branch (with transformer layers, multi-head self-attention, and feed-forward network), and token branch (with object token, text-guided query generation, and MLP). It emphasizes the dynamic weight-balance distillation method used to train both branches synchronously, improving the token branch’s performance while maintaining efficiency. The figure shows the loss calculation for both branches, indicating how the decoder branch acts as a teacher to guide the lighter token branch. The diagram illustrates the early and late iterations of training with differing weights to balance the influence of the teacher and ground truth.
This figure provides a detailed overview of the SimVG architecture, highlighting its three main components: the multi-modality encoder, the decoder branch, and the token branch. The multi-modality encoder processes image, text, and object tokens. The decoder branch, similar to DETR’s decoder, produces predictions. The novel token branch, a lightweight MLP, learns from the decoder branch using dynamic weight-balance distillation (DWBD). The figure also illustrates the TQG (Text-guided Query Generation) module which incorporates textual prior information. Notably, during inference, the lightweight token branch can be used independently for faster processing and reduced model complexity.

This figure shows the convergence speed of three different multimodal pretraining architectures (CLIP, ViLT, and BEiT-3) during the training process for visual grounding. It highlights how decoupling multimodal fusion, as implemented in ViLT and BEIT-3, leads to significantly faster convergence compared to CLIP, which only performs cross-modal alignment. The y-axis represents the Precision@0.5 metric, and the x-axis represents the number of training epochs. The graph visually demonstrates the improved efficiency of the decoupled methods.
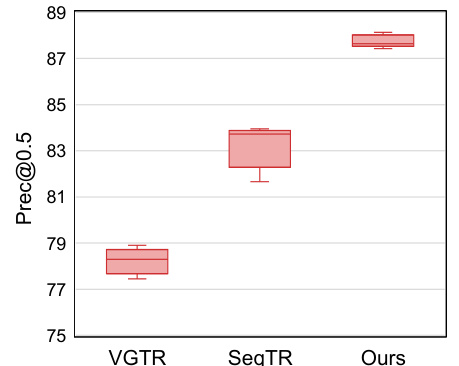
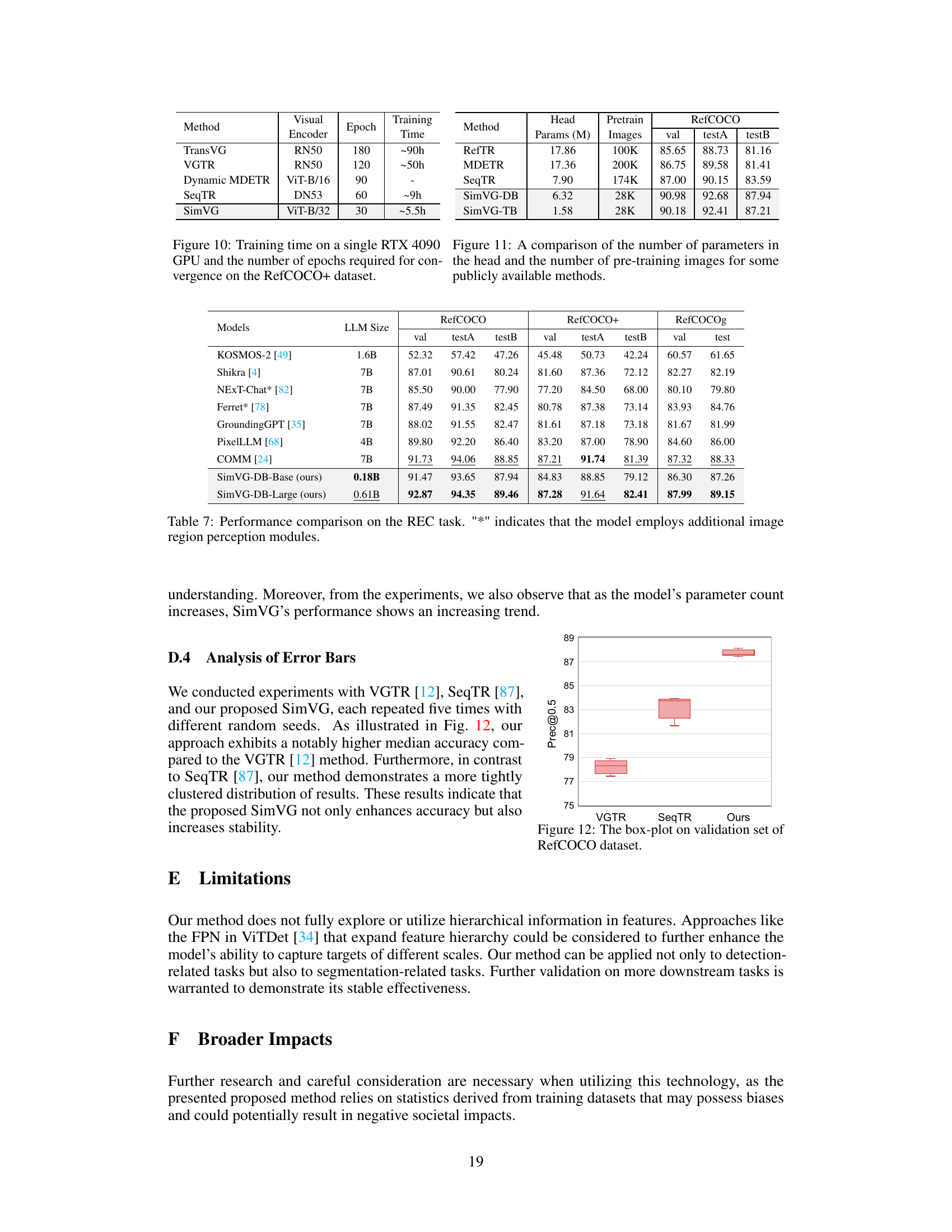
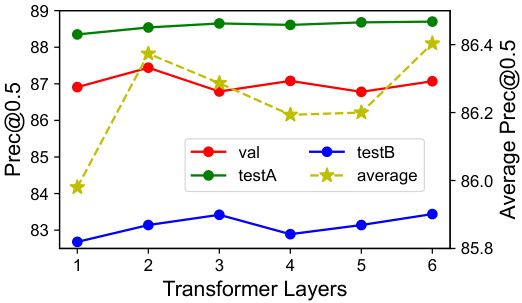
The figure shows the box plot of the validation results on the RefCOCO dataset for three different visual grounding models: VGTR, SeqTR, and the proposed SimVG model. The box plots illustrate the distribution of the Precision@0.5 metric across multiple runs of each model, showing the median, quartiles, and range of the results. The plot visually demonstrates that the proposed SimVG model achieves higher median accuracy and shows better stability (tighter distribution) compared to the other two models.
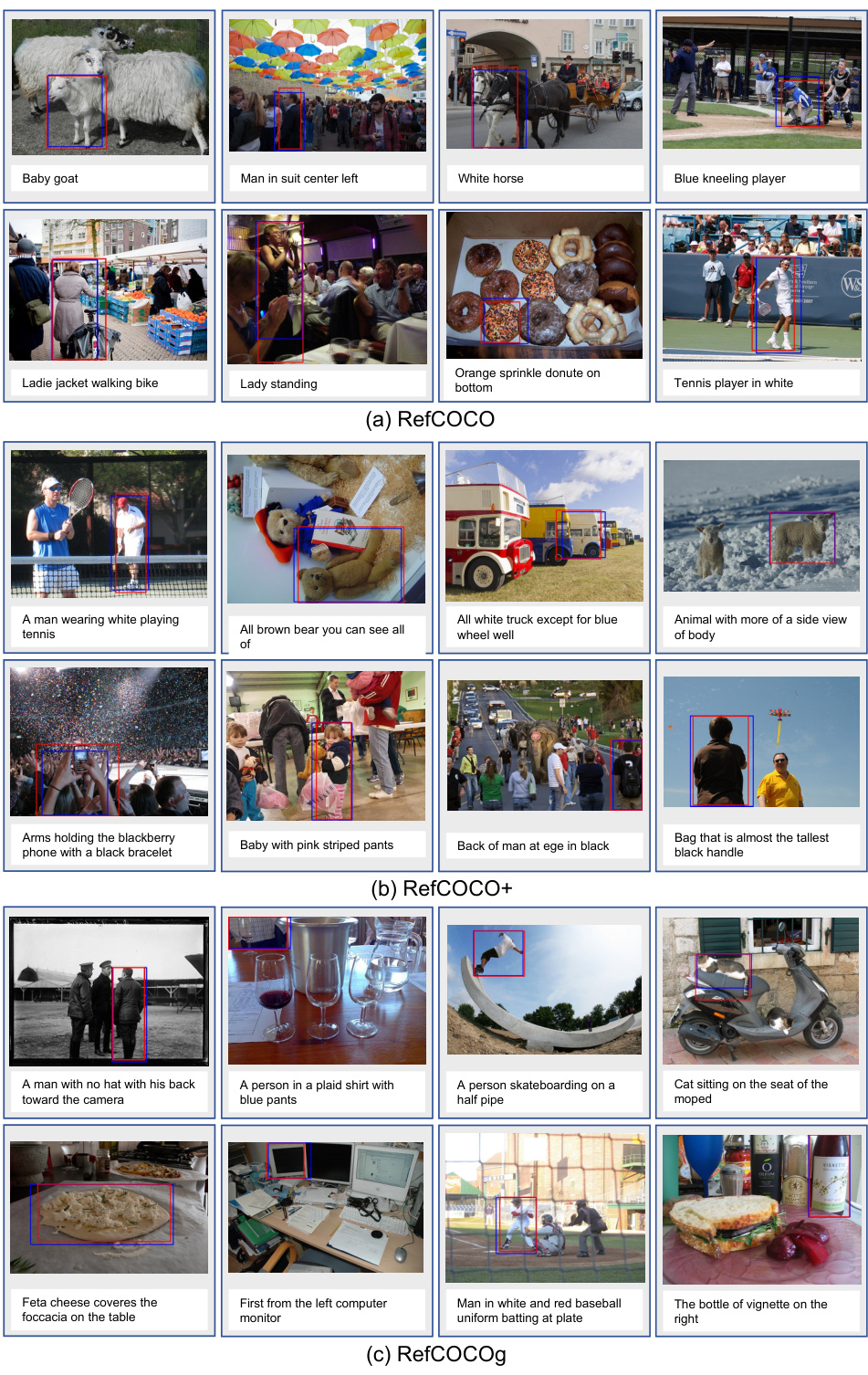
This figure compares four different visual grounding architectures. (a) Two-Stage: This method uses a detector to generate region proposals, followed by separate image and text encoders and a fusion module that calculates the similarity between features to determine the final grounding. (b) One-Stage: This architecture performs dense prediction to directly determine the location of the grounding. (c) Transformer-based: This uses an encoder-decoder structure with transformers to process image and text features before doing grounding. (d) Ours (SimVG): SimVG uses a multi-modality encoder to process images, text, and object tokens and then employs a lightweight MLP for grounding, separating the fusion and prediction phases.

This figure shows the architecture of SimVG, a visual grounding model. It consists of three main parts: a multi-modality encoder, a decoder branch, and a token branch. The multi-modality encoder processes the image, text, and object tokens. The decoder branch is a standard transformer decoder that generates bounding boxes and class predictions. The token branch consists of a lightweight MLP that also produces bounding boxes and class predictions. A dynamic weight-balance distillation method is used to improve the performance of the token branch by using the decoder branch as a teacher. Text-guided query generation is used to incorporate textual prior information into object queries. During inference, either branch can be used independently, with the token branch preferred for its efficiency.

This figure shows four different visual grounding architectures. (a) illustrates a two-stage approach using a detector for object proposals followed by image and text encoding to find matches. (b) presents a one-stage approach using dense prediction. (c) shows a transformer-based model using an encoder-decoder structure. (d) is the proposed SimVG architecture, which uses a multi-modality encoder and a lightweight MLP for visual grounding.
More on tables
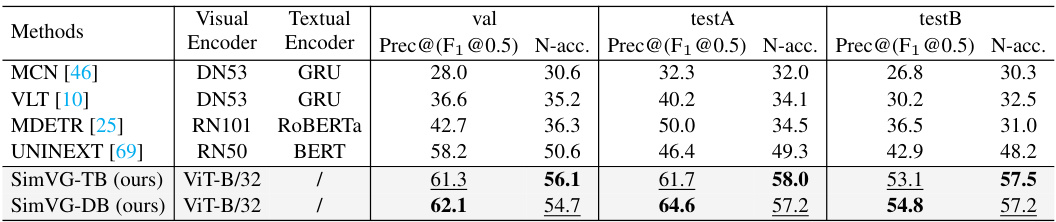
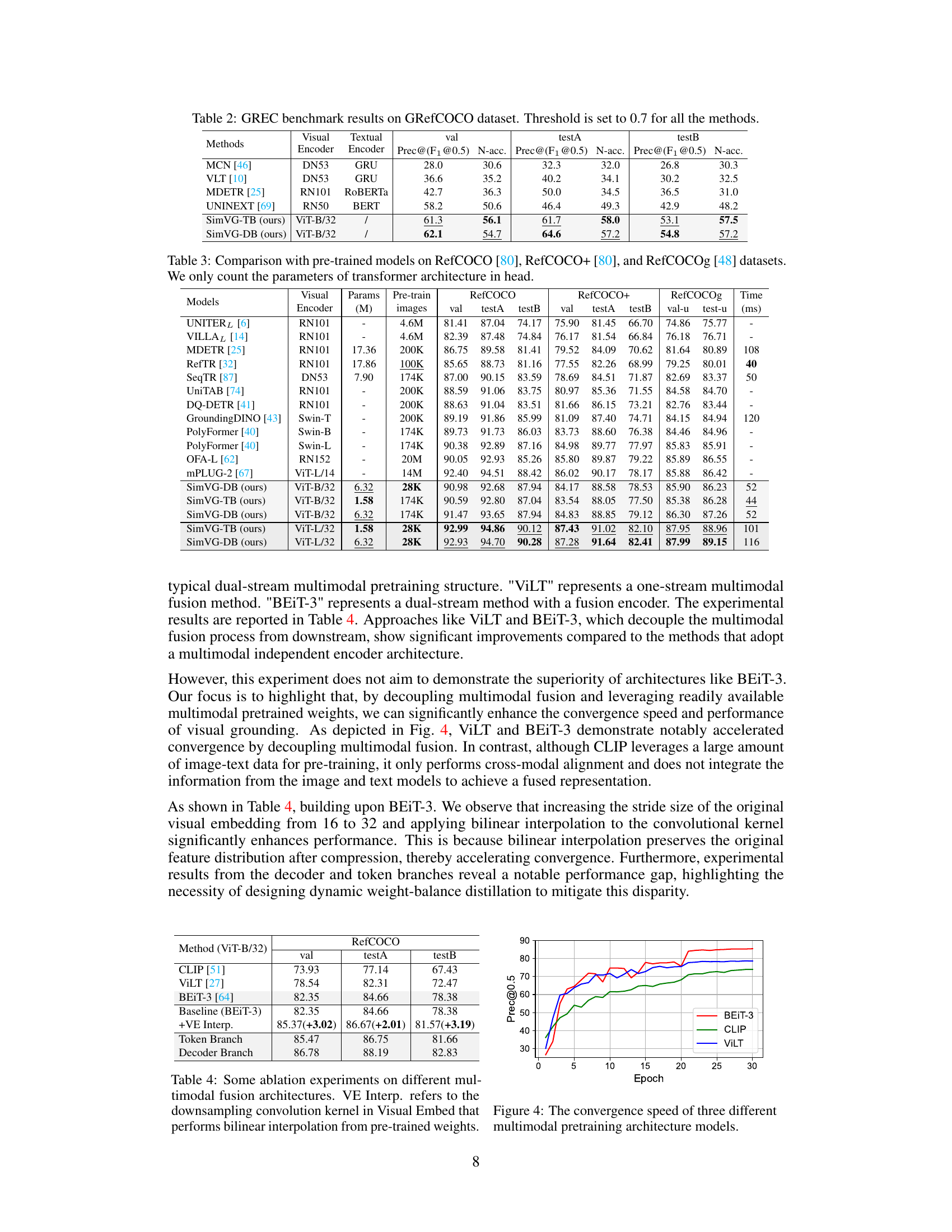
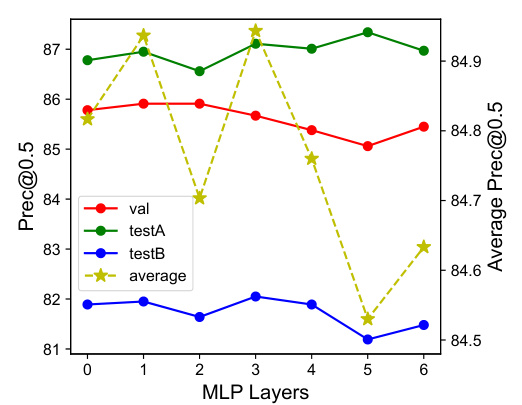
This table presents a comparison of different methods’ performance on the GRefCOCO dataset for the GREC (general referring expression comprehension) task. The performance is measured using Precision@(F1@0.5) and N-acc (no-target accuracy), with an IoU threshold of 0.7. The table shows the visual and textual encoders used by each method along with its performance on the validation set and test sets (testA and testB). SimVG-TB and SimVG-DB represent different variations of the proposed SimVG model.
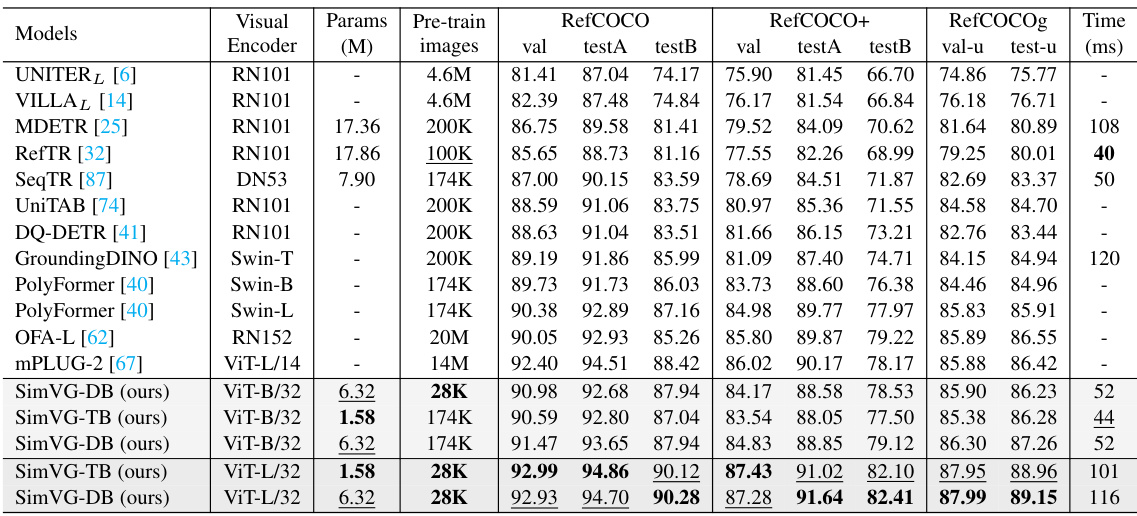
This table compares the performance of SimVG with other state-of-the-art (SOTA) visual grounding models on several benchmark datasets (RefCOCO, RefCOCO+, RefCOCOg, ReferIt, Flickr30K). It shows the results for different model architectures (two-stage, one-stage, transformer-based), visual encoders (ResNet, DarkNet, ViT), and measures performance using various metrics (val, testA, testB, etc.). The table also indicates the inference time and the GPU used for testing, clarifying differences in computational efficiency.

This table compares the performance of SimVG with other state-of-the-art (SOTA) visual grounding methods across several benchmark datasets (RefCOCO, RefCOCO+, RefCOCOg, ReferIt, Flickr30K). It shows the performance (val, testA, testB) for each method, specifying the backbone used (ResNet, DarkNet, ViT), and the inference time. The table also highlights the improvements achieved by using only the token branch (SimVG-TB) or decoder branch (SimVG-DB) of the SimVG model.
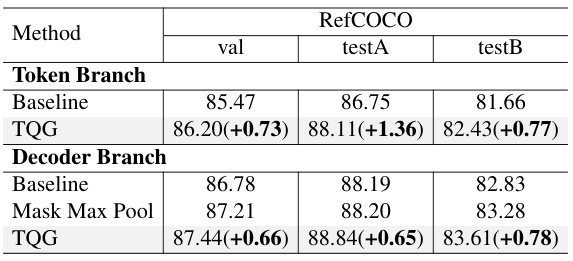
This table presents the ablation study results focusing on the Text-guided Query Generation (TQG) module. It compares the performance of the token branch and decoder branch with and without the TQG module, and with different variations of the TQG module (Baseline, TQG, Mask Max Pool, TQG) to show how the performance improves by incorporating textual information into queries.
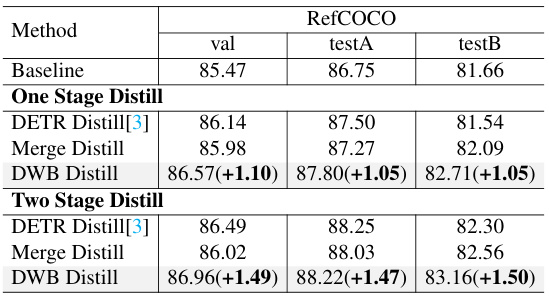
This table presents the ablation study results focusing on the Dynamic Weight-Balance Distillation (DWBD) module. It compares different distillation methods, including one-stage and two-stage approaches. The methods are compared based on their performance on the RefCOCO validation set, testA and testB splits. The numbers in parentheses indicate the absolute improvement over the baseline.

This table compares the performance of SimVG with other state-of-the-art (SOTA) visual grounding models on four benchmark datasets: RefCOCO, RefCOCO+, RefCOCOg, and ReferIt. The table shows the performance (in terms of validation and test accuracy) of each model, categorized by whether it is a two-stage, one-stage, or transformer-based approach. It also lists the backbone network used for the visual encoder (e.g., RN101, DN53, VGG16, ViT-B/16, ViT-B/32), the inference time in milliseconds, and whether the model was tested on a NVIDIA RTX 3090 GPU or a GTX 1080Ti GPU. The SimVG-TB and SimVG-DB columns show the performance of SimVG using only the token branch and only the decoder branch, respectively.
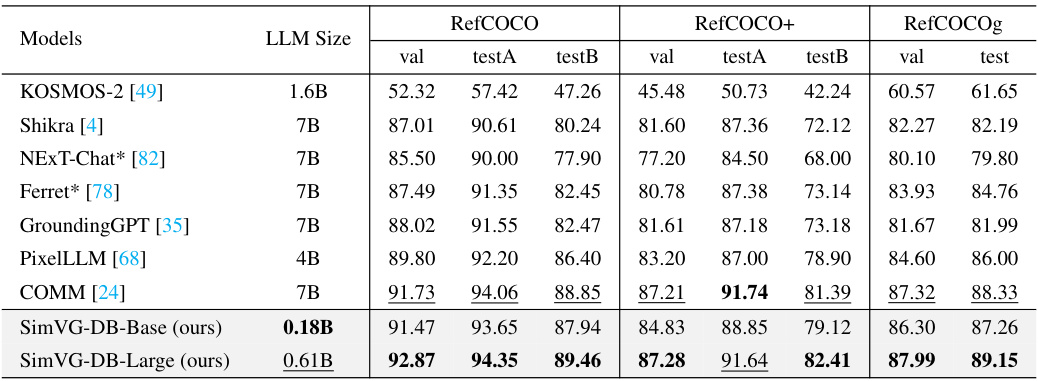
This table compares the performance of SimVG with other state-of-the-art (SOTA) visual grounding methods on several benchmark datasets (RefCOCO, RefCOCO+, RefCOCOg, ReferIt, Flickr30k). It shows precision scores (val, testA, testB) for different models, along with the type of visual encoder used (RN101, DN53, ViT-B/16, ViT-B/32, ViT-L/32) and the inference time. The table highlights SimVG’s improved performance and efficiency compared to two-stage, one-stage, and transformer-based methods. SimVG-TB and SimVG-DB results show the performance of using either the token or decoder branch independently. The GPU used for testing is also indicated.
Full paper#