TL;DR#
Federated learning (FL) enables collaborative model training while preserving data privacy. However, existing FL methods for semantic segmentation often involve sharing model weights or gradients, making them vulnerable to privacy attacks. This paper introduces BlackFed, a novel black-box FL framework that overcomes this limitation. BlackFed achieves this by formulating the FL problem using split neural networks and employing zero-order optimization for clients and first-order optimization for the server, thus enabling better privacy preservation without gradient or model information exchange.
BlackFed effectively addresses the issues of privacy vulnerabilities in traditional federated learning for semantic segmentation. By employing a black-box approach and avoiding gradient or model information sharing, it enhances privacy protection. The use of zero-order and first-order optimization for updating client and server models, respectively, allows efficient model training without compromising privacy. The evaluation across computer vision and medical imaging datasets demonstrate BlackFed’s effectiveness and robustness.
Key Takeaways#
Why does it matter?#
This paper is important because it proposes BlackFed, a novel federated learning framework for semantic segmentation that significantly improves privacy compared to existing methods by avoiding the transfer of model weights or gradients. This addresses a critical challenge in federated learning and opens new avenues for privacy-preserving collaborative model training in computer vision and medical imaging. The black-box approach makes it robust to existing data reconstruction attacks and offers strong privacy preservation.
Visual Insights#
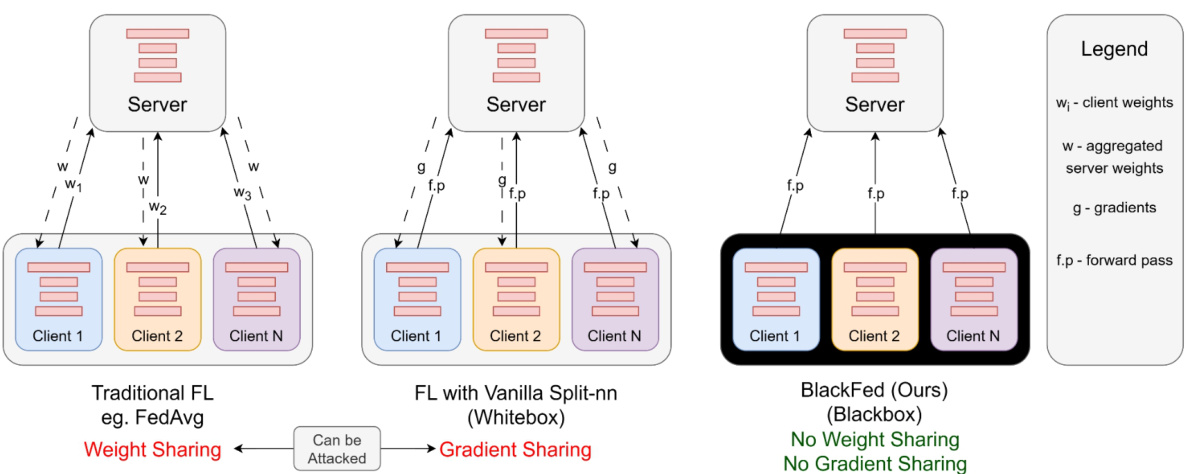
🔼 This figure compares three different federated learning (FL) approaches: traditional FL (e.g., FedAvg), FL with vanilla split-nn (white-box), and the proposed BlackFed (black-box). Traditional FL methods share either model weights or gradients between clients and the server, making them vulnerable to privacy attacks. In contrast, the proposed BlackFed method uses only forward passes to update the client model, avoiding the sharing of weights or gradients and enhancing privacy.
read the caption
Figure 1: Comparison of our method against traditional FL methods. Existing FL methods are primarily 'white-box' as they involve transfer of model weights [34], or gradients[20]. In contrast, our method only utilizes forward passes to update the client and does not require sharing weights or gradients, making it a 'black-box' model.
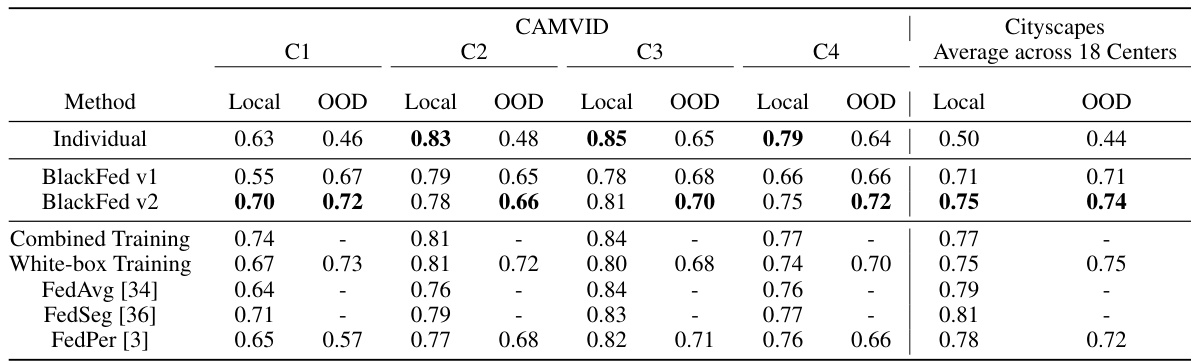
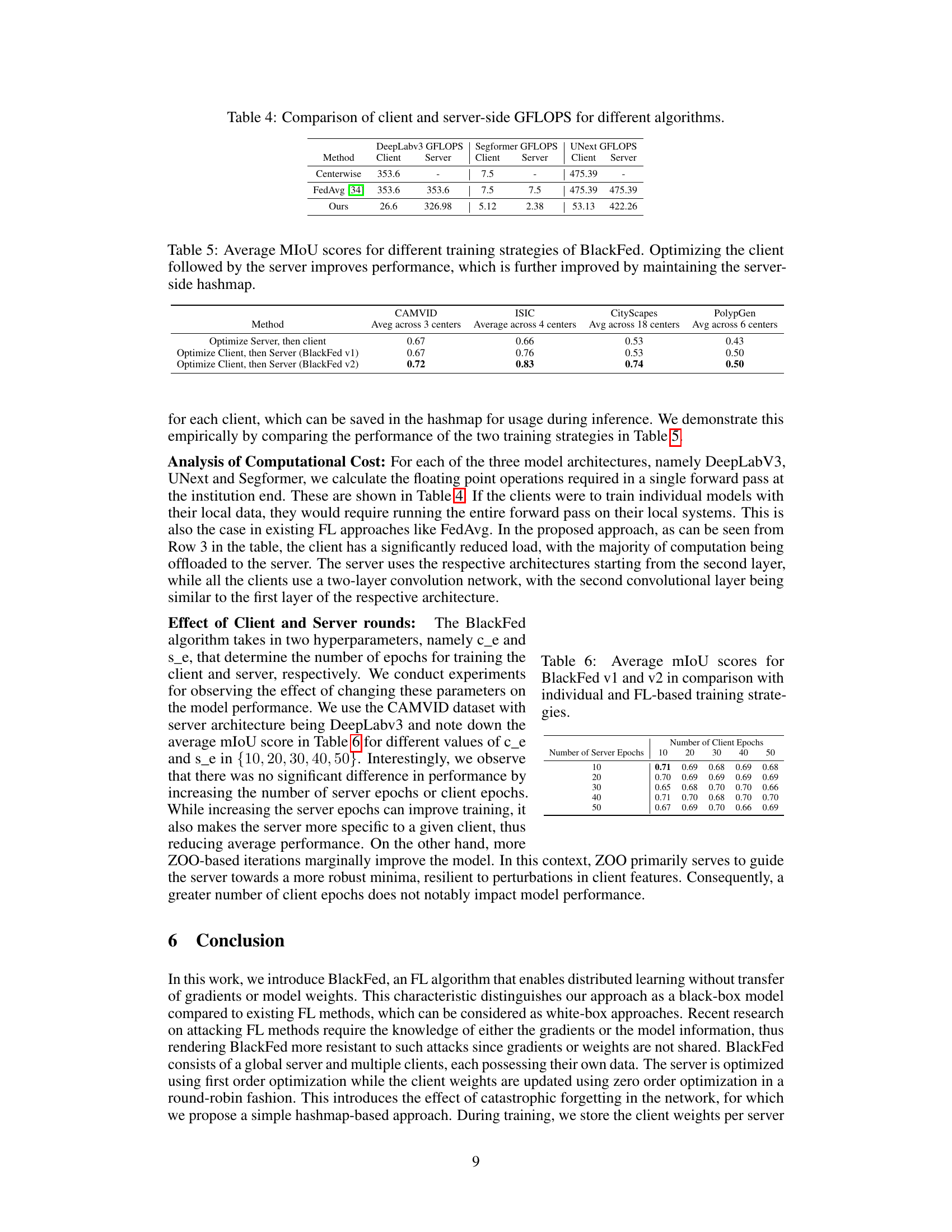
🔼 This table compares the performance of BlackFed v1 and v2 against individual training and other federated learning methods on two datasets (CAMVID and Cityscapes). It shows the mean Intersection over Union (mIoU) scores for both ‘Local’ (performance on the same center’s test data) and ‘Out-of-Distribution’ (OOD, average performance across test data from other centers) settings. The results highlight BlackFed’s ability to improve OOD performance while maintaining strong local performance.
read the caption
Table 1: mIoU scores for BlackFed v1 and v2 in comparison with individual and FL-based training strategies for natural datasets. 'Local' represents test data from the center. 'OOD' represents mean mIoU on test data from rest of the centers. For FedAvg and Combined Training, just one model is trained. Hence, its performance is noted only in each of the local test datasets. For Cityscapes, we only present the average local and OOD performance across centers for brevity. The supplementary contains an expanded version for Cityscapes.
In-depth insights#
Black-box FL#
Black-box Federated Learning (FL) presents a compelling approach to address privacy concerns in distributed machine learning. Unlike traditional FL methods that rely on sharing model weights or gradients, black-box FL aims to train a global model without exposing the architecture or internal parameters of individual client models. This enhances privacy by preventing reconstruction attacks that could infer sensitive information from gradient or weight exchanges. The core challenge lies in designing effective optimization strategies for the global model without direct access to client model information. Zero-order optimization methods offer a potential solution, enabling parameter updates based on function evaluations rather than gradient calculations. However, zero-order methods generally exhibit slower convergence compared to first-order techniques, presenting a trade-off between privacy and efficiency. Research in this area is actively exploring techniques to improve the efficiency of zero-order optimization in FL settings, such as incorporating variance reduction methods and adaptive step-size strategies. Furthermore, ensuring the robustness and security of black-box FL against potential adversarial attacks is a crucial ongoing research direction. The potential for increased privacy protection makes black-box FL a promising paradigm for future collaborative machine learning applications.
Zero-Order Opt.#
Zero-order optimization (ZOO) methods are particularly valuable in scenarios where gradient information is unavailable or computationally expensive to obtain. BlackFed’s use of ZOO for client updates directly addresses the privacy concerns inherent in traditional federated learning by avoiding the transmission of gradient information, which could be exploited to reconstruct sensitive training data. The choice of ZOO highlights the algorithm’s commitment to a truly black-box approach. However, ZOO’s slower convergence rate compared to first-order methods is a trade-off. This likely necessitates more iterations to achieve comparable accuracy, potentially impacting training time and resource efficiency. The paper’s success despite this limitation speaks to the efficacy of the chosen optimization strategy in balancing privacy and performance within this novel federated learning framework for semantic segmentation.
Catastrophic Forget.#
Catastrophic forgetting, a significant challenge in continual learning, is especially relevant in federated learning (FL) settings. In FL, the global model is updated iteratively with data from different clients, potentially causing it to ‘forget’ previously learned patterns from earlier clients. This phenomenon can severely hinder performance, as the model’s ability to generalize across diverse data distributions diminishes. The paper acknowledges catastrophic forgetting as a potential issue in their BlackFed approach, particularly when the number of clients is large or when data distributions vary significantly. To mitigate this, they propose a strategy that stores client-specific checkpoints of the global model’s weights. This allows the server to revert to a prior state when processing a particular client’s data, enhancing performance and generalization. The effectiveness of this approach is evidenced by their experimental results, highlighting the necessity of addressing catastrophic forgetting for successful FL applications. The choice of utilizing a hashmap for maintaining these checkpoints provides an efficient way to manage the potentially large number of client-specific weights, without incurring excessive storage or computational overhead. Further research could investigate more sophisticated approaches to continual learning in FL, such as employing more advanced regularization techniques or memory mechanisms.
Multi-dataset Eval.#
A multi-dataset evaluation in a research paper rigorously assesses the generalizability and robustness of a proposed model or method. It moves beyond the limitations of single-dataset evaluations, which can be susceptible to overfitting or dataset-specific biases. A strong multi-dataset evaluation strategically selects diverse datasets that vary in size, data distribution, image quality, and annotation style. This diversity helps reveal the model’s strengths and weaknesses across different scenarios, providing a more holistic understanding of its performance. The evaluation should clearly define the metrics used, ensuring they are appropriate for the specific task and datasets. Careful consideration of the datasets’ characteristics allows for insightful comparisons and identification of potential limitations. The findings should be presented transparently, including any discrepancies in performance across datasets, which might suggest areas for future improvement or indicate dataset-specific limitations of the model. Ultimately, a comprehensive multi-dataset evaluation significantly enhances the credibility and impact of the research by providing a more reliable and realistic assessment of the model’s capabilities.
Future Works#
Future research directions stemming from this federated black-box semantic segmentation work could explore alternative optimization strategies beyond SPSA-GC and Adam-W, potentially investigating more sophisticated zeroth-order or first-order methods better suited to the unique challenges of this setting. A deeper investigation into mitigating catastrophic forgetting is warranted, exploring advanced techniques such as regularization or memory-based approaches. Addressing non-independent and identically distributed (non-IID) data concerns remains crucial; further research could examine more robust methods for handling data heterogeneity across clients. Evaluating the robustness and security of BlackFed against sophisticated adversarial attacks and data poisoning is also a vital area of future work. Finally, extending the framework to other computer vision tasks besides segmentation, and broadening its applicability to diverse real-world scenarios are compelling avenues of future research.
More visual insights#
More on figures
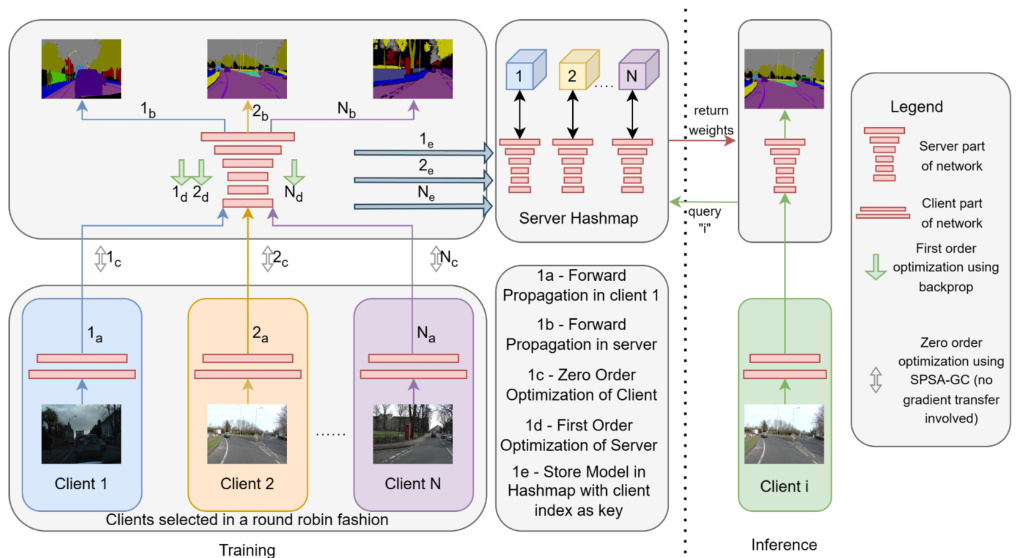
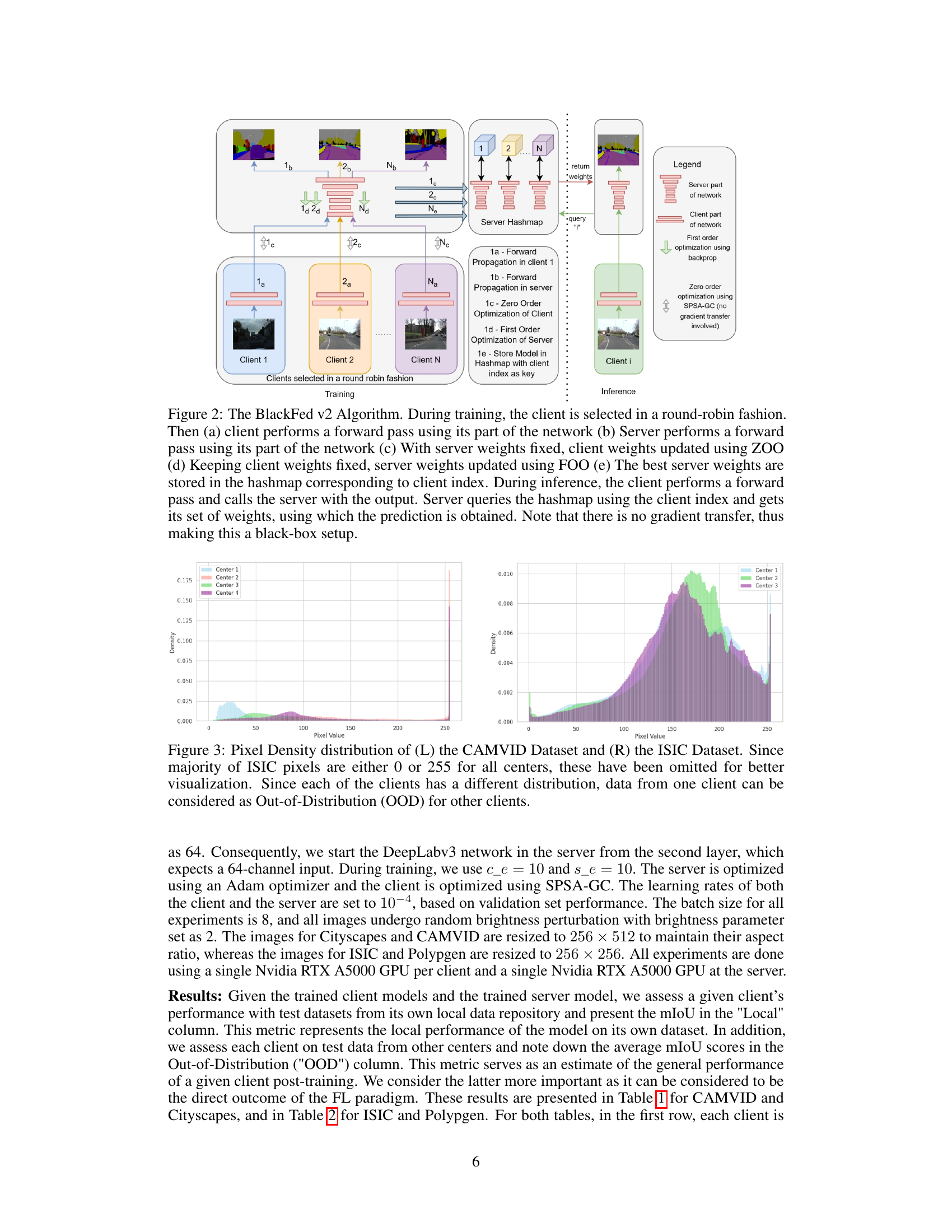
🔼 This figure illustrates the BlackFed v2 algorithm, a black-box federated learning approach for semantic segmentation. It details the training and inference phases, highlighting the round-robin client selection, the use of zero-order optimization (ZOO) for client updates, first-order optimization (FOO) for server updates, and the crucial role of a server-side hashmap to mitigate catastrophic forgetting. The diagram emphasizes the absence of gradient transfer, reinforcing the black-box nature of the method.
read the caption
Figure 2: The BlackFed v2 Algorithm. During training, the client is selected in a round-robin fashion. Then (a) client performs a forward pass using its part of the network (b) Server performs a forward pass using its part of the network (c) With server weights fixed, client weights updated using ZOO (d) Keeping client weights fixed, server weights updated using FOO (e) The best server weights are stored in the hashmap corresponding to client index. During inference, the client performs a forward pass and calls the server with the output. Server queries the hashmap using the client index and gets its set of weights, using which the prediction is obtained. Note that there is no gradient transfer, thus making this a black-box setup.
🔼 This figure illustrates the BlackFed v2 algorithm, a black-box federated learning approach. The algorithm uses a split neural network architecture where the client and server train separately without gradient transfer. Clients are selected sequentially (round-robin). The client performs a forward pass, then the server. Client weights are updated using zero-order optimization (ZOO), server weights with first-order optimization (FOO). The best server weights are stored in a hashmap (indexed by client). During inference, the server retrieves the appropriate weights from the hashmap, ensuring no gradient transfer.
read the caption
Figure 2: The BlackFed v2 Algorithm. During training, the client is selected in a round-robin fashion. Then (a) client performs a forward pass using its part of the network (b) Server performs a forward pass using its part of the network (c) With server weights fixed, client weights updated using ZOO (d) Keeping client weights fixed, server weights updated using FOO (e) The best server weights are stored in the hashmap corresponding to client index. During inference, the client performs a forward pass and calls the server with the output. Server queries the hashmap using the client index and gets its set of weights, using which the prediction is obtained. Note that there is no gradient transfer, thus making this a black-box setup.
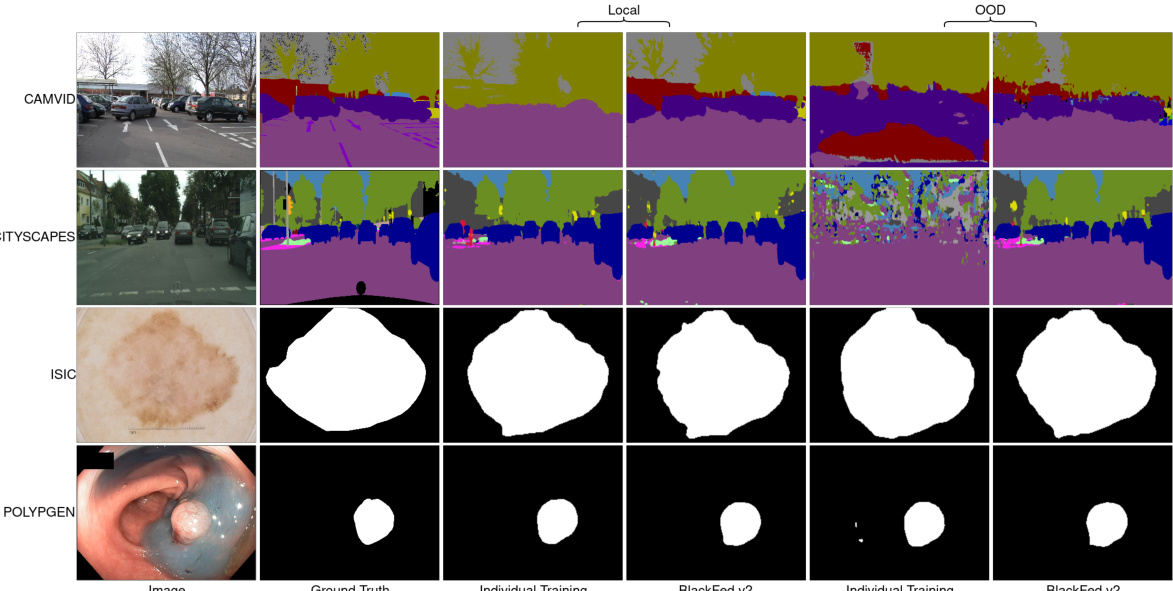
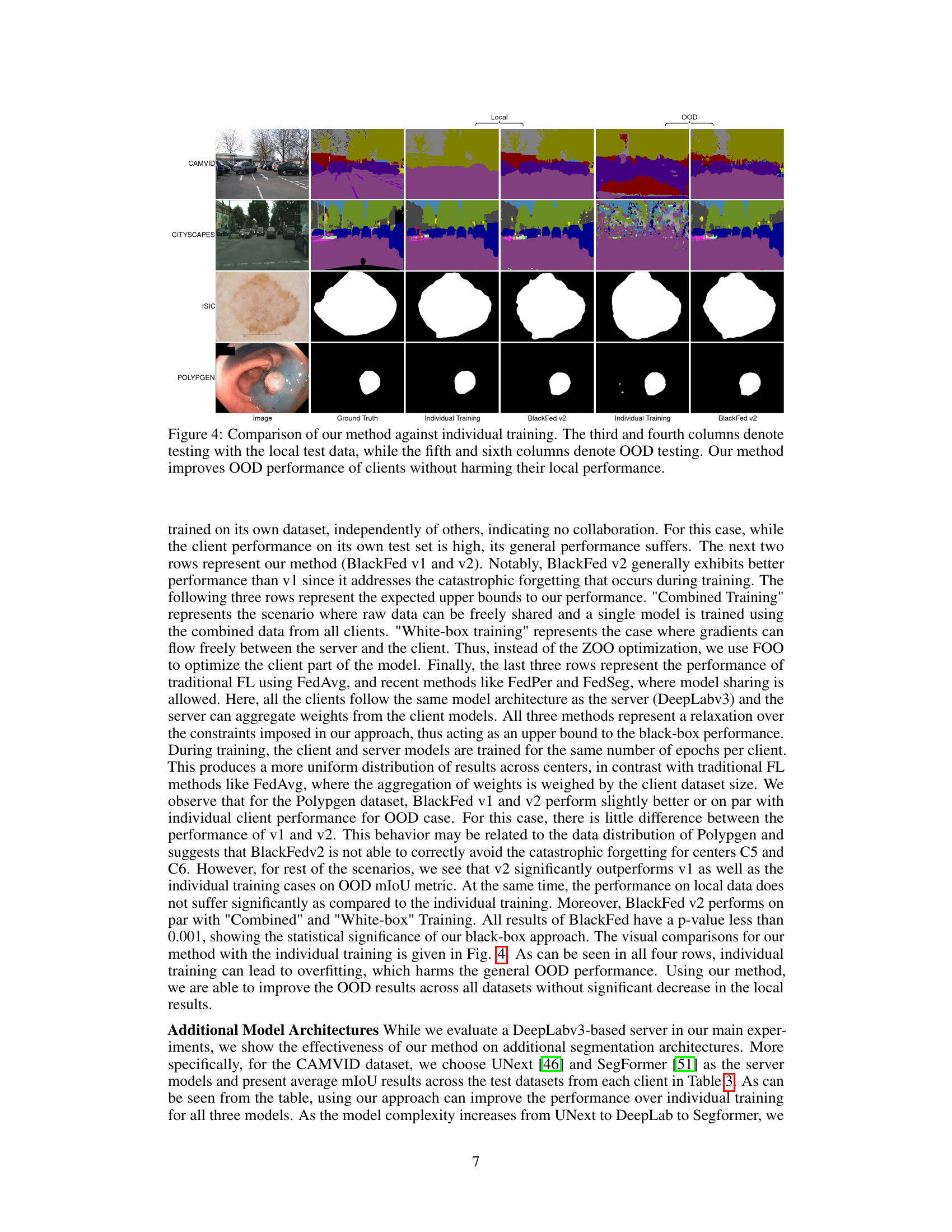
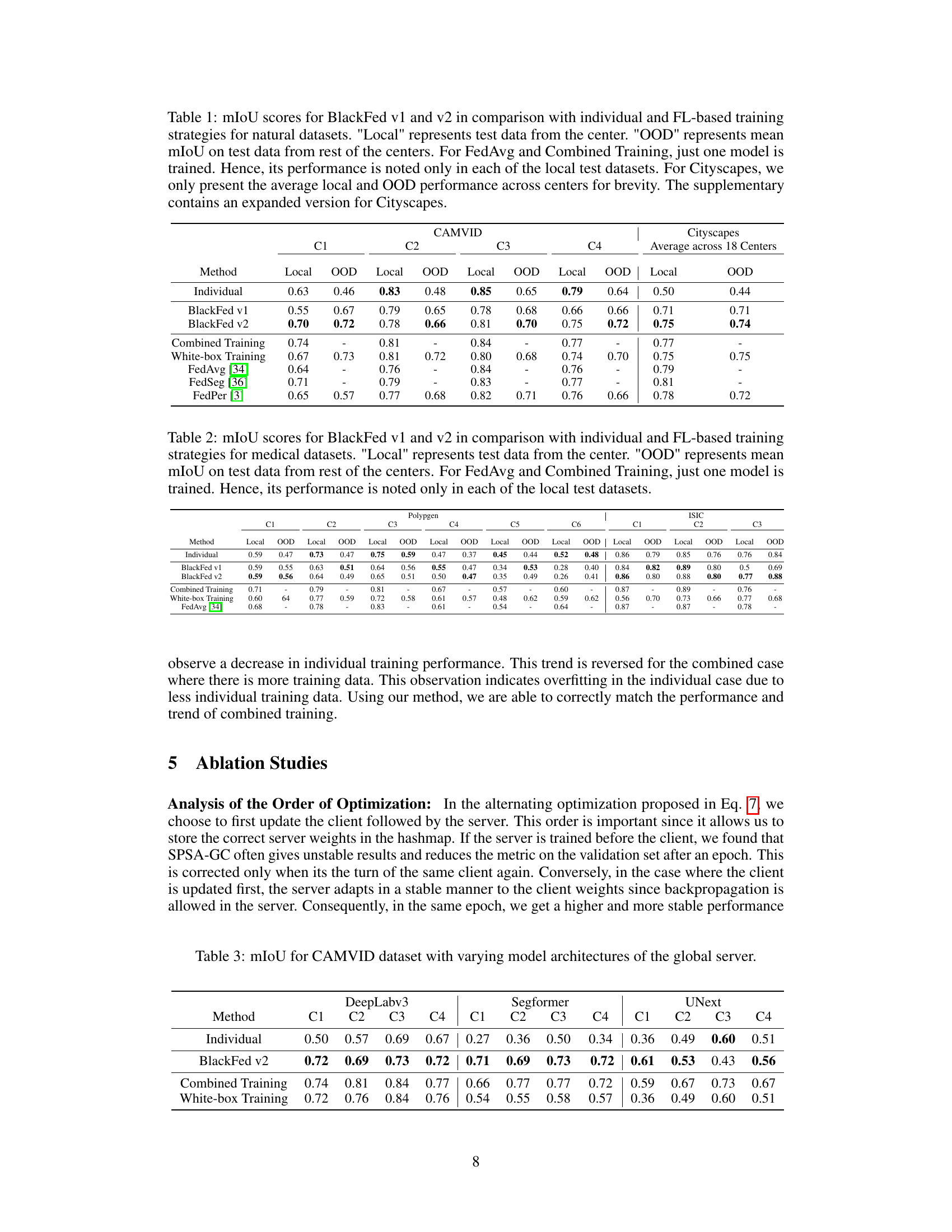
🔼 This figure compares the performance of the proposed BlackFed method against individual training. The left half shows the results when testing is done using data from the same client (Local) and the right half shows the results of using data from different clients (OOD). The ground truth is shown for comparison. The figure demonstrates that the BlackFed method significantly improves the out-of-distribution performance (OOD) without hurting the local performance.
read the caption
Figure 4: Comparison of our method against individual training. The third and fourth columns denote testing with the local test data, while the fifth and sixth columns denote OOD testing. Our method improves OOD performance of clients without harming their local performance.
More on tables

🔼 This table compares the performance of BlackFed v1 and v2 against individual training and other federated learning methods (FedAvg, FedSeg, and FedPer) on two medical image segmentation datasets (ISIC and Polypgen). The ‘Local’ column shows the performance of each client’s model on its own test set, while the ‘OOD’ (Out-of-Distribution) column indicates the average performance across all other clients’ test datasets. This helps assess the generalization ability of each method. The table demonstrates how BlackFed approaches the performance of methods that allow for full gradient or model sharing while maintaining better privacy.
read the caption
Table 2: mIoU scores for BlackFed v1 and v2 in comparison with individual and FL-based training strategies for medical datasets. 'Local' represents test data from the center. 'OOD' represents mean mIoU on test data from rest of the centers. For FedAvg and Combined Training, just one model is trained. Hence, its performance is noted only in each of the local test datasets.

🔼 This table compares the performance of BlackFed v1 and v2 against other methods (individual training, combined training, white-box training, FedAvg, FedSeg, and FedPer) for four datasets (CAMVID, Cityscapes, ISIC, and Polypgen). It shows the mean Intersection over Union (mIoU) scores for both ‘Local’ (test data from the same center) and ‘Out-of-Distribution’ (OOD, test data from other centers). The OOD performance is crucial for evaluating the generalization capabilities of federated learning approaches.
read the caption
Table 3: mIoU scores for BlackFed v1 and v2 in comparison with individual and FL-based training strategies for natural datasets. 'Local' represents test data from the center. 'OOD' represents mean mIoU on test data from rest of the centers. For FedAvg and Combined Training, just one model is trained. Hence, its performance is noted only in each of the local test datasets. For Cityscapes, we only present the average local and OOD performance across centers for brevity. The supplementary contains an expanded version for Cityscapes.
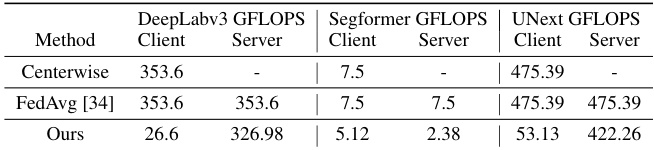
🔼 This table compares the computational cost (GFLOPS) of different algorithms for client and server sides using three different model architectures: DeepLabv3, Segformer, and UNext. It shows that the proposed ‘Ours’ method significantly reduces the computational burden on the client side while shifting more processing to the server.
read the caption
Table 4: Comparison of client and server-side GFLOPS for different algorithms.

🔼 This table presents the average mean Intersection over Union (mIoU) scores achieved by different training strategies within the BlackFed framework, across four different datasets: CAMVID, ISIC, Cityscapes, and Polypgen. It compares three approaches: 1. Optimizing the server, then the client. 2. Optimizing the client, then the server (BlackFed v1). 3. Optimizing the client, then the server, while maintaining a server-side hashmap to mitigate catastrophic forgetting (BlackFed v2). The results show that optimizing the client first, followed by the server, improves performance, and this improvement is enhanced further by employing the server-side hashmap in BlackFed v2.
read the caption
Table 5: Average MIoU scores for different training strategies of BlackFed. Optimizing the client followed by the server improves performance, which is further improved by maintaining the server-side hashmap.
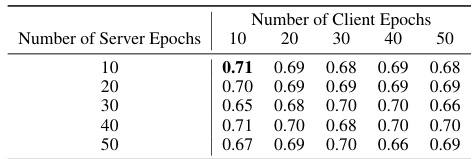
🔼 This table presents the mean Intersection over Union (mIoU) scores achieved by the proposed BlackFed approach (versions 1 and 2), compared against individual training and other federated learning (FL) methods like FedAvg. The results are shown for different numbers of client and server epochs, allowing analysis of the impact of these hyperparameters on model performance. ‘Local’ indicates performance on a client’s own data, while ‘OOD’ represents out-of-distribution performance, showcasing the model’s generalization capabilities.
read the caption
Table 6: Average mIoU scores for BlackFed v1 and v2 in comparison with individual and FL-based training strategies.

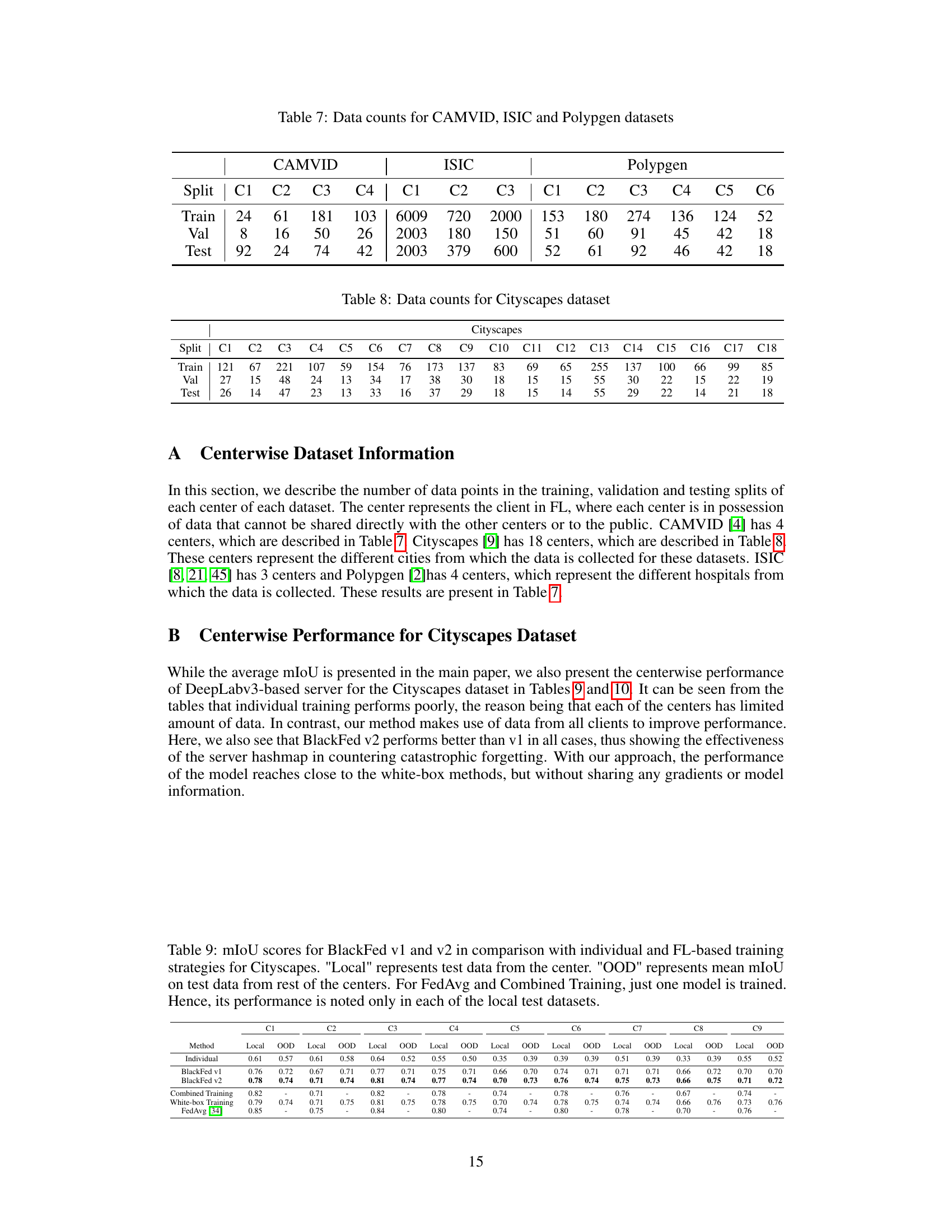
🔼 This table presents the number of data samples available for training, validation, and testing in each of the four datasets used in the paper. The datasets are split across multiple clients, representing different institutions or data sources. For each dataset, the table shows the number of samples in each split for each client (C1, C2, etc.). This illustrates the distribution of data among the clients, which is important in the context of federated learning.
read the caption
Table 7: Data counts for CAMVID, ISIC and Polypgen datasets

🔼 This table shows the number of images in the training, validation, and testing sets for each of the 18 centers (clients) in the Cityscapes dataset used in the federated learning experiments. The data is not publicly available and is split based on the location of the images.
read the caption
Table 8: Data counts for Cityscapes dataset

🔼 This table presents the mean Intersection over Union (mIoU) scores achieved by different federated learning methods on four datasets (CAMVID, Cityscapes, ISIC, and Polypgen). It compares the performance of BlackFed versions 1 and 2 against individual training, combined training (all data together), a white-box approach (with gradient sharing), and other established FL methods like FedAvg and FedSeg. The ‘Local’ column shows performance on data from the same institution, and ‘OOD’ (Out-of-Distribution) represents average performance across data from other institutions, indicating generalization ability. Note that Cityscapes results are averaged across all 18 centers for brevity in the main table.
read the caption
Table 1: mIoU scores for BlackFed v1 and v2 in comparison with individual and FL-based training strategies for natural datasets. 'Local' represents test data from the center. 'OOD' represents mean mIoU on test data from rest of the centers. For FedAvg and Combined Training, just one model is trained. Hence, its performance is noted only in each of the local test datasets. For Cityscapes, we only present the average local and OOD performance across centers for brevity. The supplementary contains an expanded version for Cityscapes.

🔼 This table presents the mean Intersection over Union (mIoU) scores achieved by different federated learning methods on four datasets (CAMVID, Cityscapes, ISIC, and Polypgen). It compares the performance of BlackFed v1 and v2 against individual training, combined training (all data aggregated), white-box federated training (gradients shared), and existing federated methods (FedAvg, FedSeg, and FedPer). The ‘Local’ column shows performance on the test data from the same client used for training, while the ‘OOD’ (Out-of-Distribution) column shows performance on test data from other clients, evaluating generalization ability. The table demonstrates BlackFed’s ability to match or surpass individual and some federated learning approaches, especially in the OOD setting, without sharing gradients or model architectures.
read the caption
Table 1: mIoU scores for BlackFed v1 and v2 in comparison with individual and FL-based training strategies for natural datasets. 'Local' represents test data from the center. 'OOD' represents mean mIoU on test data from rest of the centers. For FedAvg and Combined Training, just one model is trained. Hence, its performance is noted only in each of the local test datasets. For Cityscapes, we only present the average local and OOD performance across centers for brevity. The supplementary contains an expanded version for Cityscapes.
Full paper#