↗ arXiv ↗ Hugging Face ↗ Hugging Face ↗ Chat
TL;DR#
Large language models (LLMs) often struggle with the “lost-in-the-middle” problem: difficulty identifying relevant information embedded within long sequences. This is partly due to the limitations of rotary positional embedding (RoPE), commonly used in LLMs, which introduces a long-term decay effect, causing the model to prioritize recent information.
This paper introduces Multi-scale Positional Encoding (Ms-PoE) to address this issue. Ms-PoE is a simple plug-and-play technique that enhances LLMs’ ability to handle long sequences. It achieves this by strategically rescaling position indices to improve long-term decay and assigning distinct scaling ratios to different attention heads to preserve valuable knowledge from the pre-training stage. Experiments demonstrate that Ms-PoE significantly boosts the accuracy of various LLMs on long-context tasks without any fine-tuning.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working with large language models (LLMs) because it addresses the significant challenge of LLMs struggling to process information in the middle of long sequences. The proposed solution, Ms-PoE, is a simple, plug-and-play method that significantly improves LLM performance without requiring extensive retraining. This opens new avenues for research into more efficient and effective LLM architectures, especially those dealing with extensive contexts.
Visual Insights#

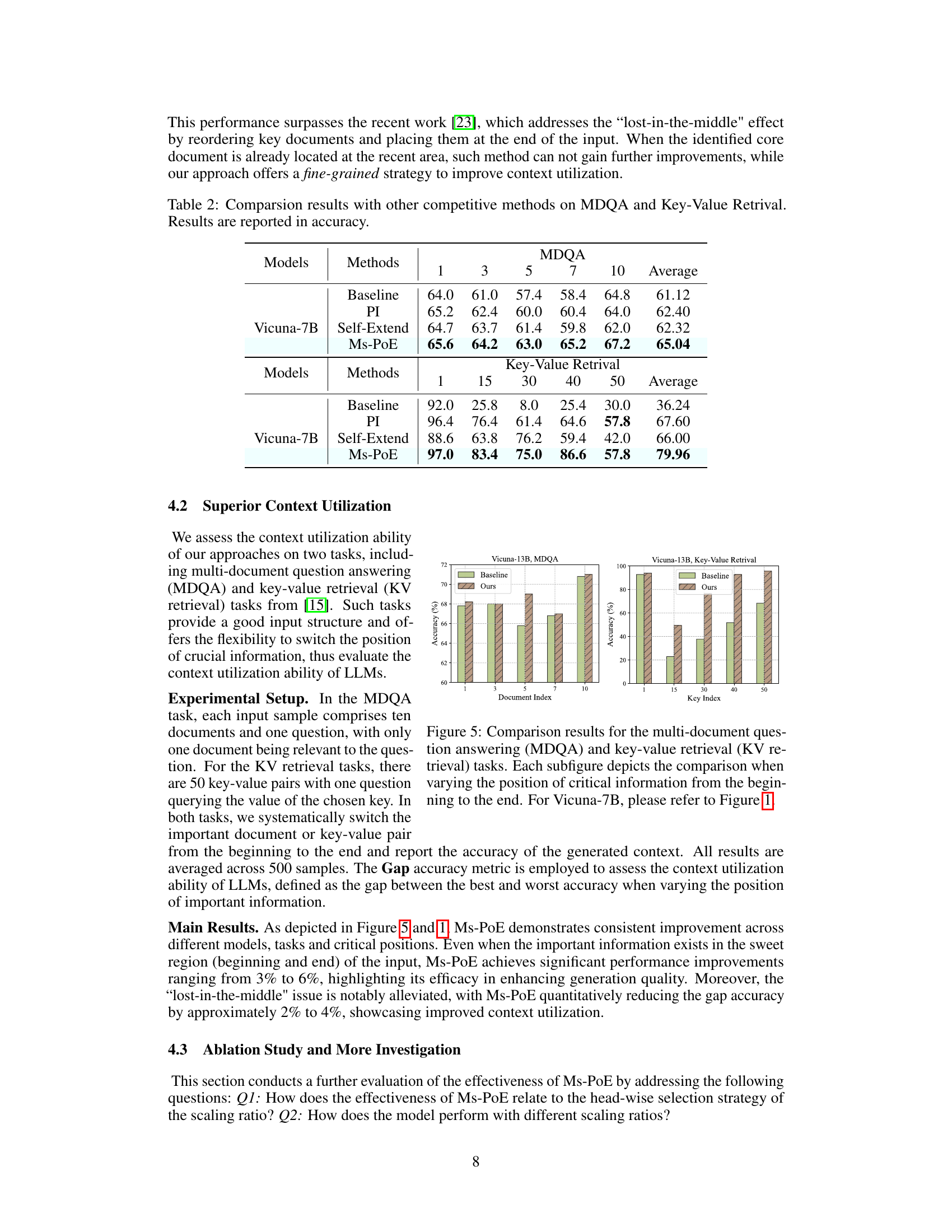
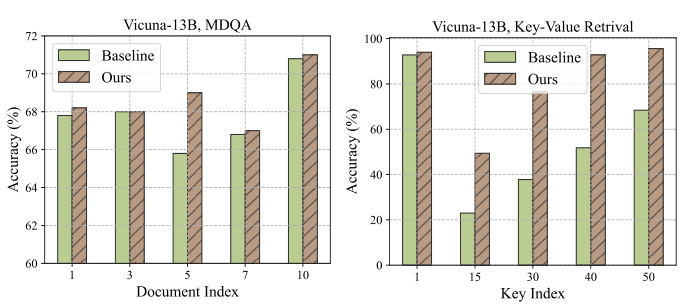
🔼 This figure shows the results of the baseline and the proposed method (Ms-PoE) on two tasks: Multi-Document Question Answering (MDQA) and Key-Value Retrieval. The x-axis represents the position of the essential information within the context (from the beginning to the end). The green bars represent the baseline accuracy, which shows a significant drop in accuracy when the essential information is located in the middle of the context. The brown bars represent the accuracy of the proposed method, showing a significant improvement over the baseline, especially when the essential information is in the middle of the context.
read the caption
Figure 1: The x-axis illustrates the placement of essential information within the prompt, ranging from start to end. The green bar serves as a standard baseline, illustrating the “lost-in-the-middle
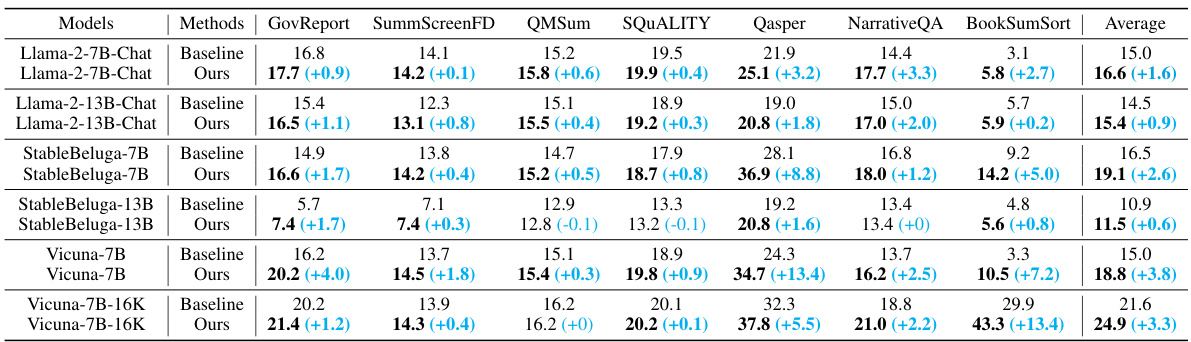
🔼 This table presents a comparison of the performance of several Large Language Models (LLMs) on various tasks from the ZeroSCROLLS benchmark. The models are tested both with and without the proposed Ms-PoE method. Different evaluation metrics are used depending on the specific task, including ROUGE scores, F1 score, and concordance index. The results show the accuracy for each model on each task, with the improvement provided by Ms-PoE shown in parentheses.
read the caption
Table 1: Comparsion results on ZeroSCROLLS [34] benchmarks. The evaluation metrics for various tasks are tailored as follows: GovReport, SummScreenFD, QMSum, and SQUALITY utilize the geometric mean of Rouge-1/2/L scores. Qasper and NarrativeQA are assessed through the F1 score, while BookSumSort employs the concordance index.
In-depth insights#
Long Context Issue#
The “Long Context Issue” in large language models (LLMs) centers on their struggle with effectively utilizing information situated within lengthy input sequences. While recent advancements enable LLMs to process millions of tokens, a persistent challenge remains: accurately identifying and leveraging relevant data located in the middle of the input. This “lost-in-the-middle” phenomenon is significantly problematic for numerous applications that require long-range reasoning. The core difficulties often stem from architectural limitations, particularly within the attention mechanism. Existing positional encodings, such as Rotary Positional Embeddings (RoPE), introduce a decay effect, causing the model to prioritize more recent information. Furthermore, the softmax function’s inherent behavior can disproportionately allocate attention to initial tokens, regardless of their actual relevance. Addressing this necessitates innovative approaches focusing on improving context utilization and mitigating these architectural biases, which are crucial for unlocking the full potential of LLMs in real-world, long-context applications.
Ms-PoE Approach#
The Multi-scale Positional Encoding (Ms-PoE) approach tackles the “lost-in-the-middle” problem in large language models (LLMs). Ms-PoE enhances LLMs’ ability to utilize information situated within lengthy contexts without requiring fine-tuning or adding computational overhead. It achieves this by strategically re-scaling positional indices, a technique that modifies how the model weighs positional information. Crucially, Ms-PoE employs a multi-scale strategy, assigning different scaling ratios to various attention heads. This is based on the observation that some heads are inherently more “position-aware” than others. By carefully adjusting these ratios, Ms-PoE alleviates the long-term decay effect of relative positional embeddings like RoPE, allowing the model to better capture relevant information regardless of its position within the sequence. The plug-and-play nature of Ms-PoE makes it a particularly attractive solution for improving long-context performance in existing LLMs.
Position-Aware Heads#
The concept of “Position-Aware Heads” in the context of large language models (LLMs) centers on the observation that different attention heads exhibit varying sensitivities to token position within a long sequence. Some heads consistently attend to relevant information regardless of its location, demonstrating a position-invariant behavior crucial for long-context understanding. Others, however, show a strong bias toward tokens at the beginning or end of the sequence, neglecting information in the middle. This heterogeneity in positional sensitivity among attention heads suggests an opportunity to leverage the strengths of each. A multi-scale approach, such as assigning distinct scaling ratios to different heads based on their positional awareness, can enhance context utilization. This involves carefully modifying positional encodings to help mitigate the ’lost-in-the-middle’ phenomenon and improve overall long-range reasoning capabilities of the LLMs. Identifying and exploiting the differential positional awareness of various attention heads is key to improving long-context understanding in LLMs. The research focuses on leveraging the inherent diversity in attention mechanisms to overcome limitations in current positional encodings and improve long sequence processing.
Multi-Scale Encoding#
Multi-scale encoding, in the context of large language models (LLMs), addresses the challenge of information loss within long sequences. Standard positional encodings often suffer from a decay effect, where information in the middle of a sequence gets de-emphasized. A multi-scale approach combats this by employing different positional encoding schemes or modifications across different layers or attention heads. This allows the model to process information at multiple levels of granularity, effectively capturing both short-range and long-range dependencies. By combining fine-grained and coarse-grained positional information, the LLM can better handle long-range context and avoid the “lost-in-the-middle” problem. This is achieved by assigning different scaling factors or applying diverse kernel sizes to the positional information, allowing different attention mechanisms to focus on various contextual scopes. The effectiveness of such methods heavily relies on meticulous design and tuning of the scaling ratios to preserve essential knowledge learned during pre-training while enhancing long-range context understanding. The resulting improvements in accuracy highlight the importance of accounting for the diverse nature of contextual information within long sequences.
Future Research#
Future research directions stemming from this work could explore several promising avenues. Extending Ms-PoE’s applicability to other positional encodings beyond RoPE would broaden its impact and establish its versatility as a general technique for improving long-context understanding. Investigating the interplay between Ms-PoE and other long-context techniques, such as sparse attention mechanisms or memory augmentation methods, could lead to synergistic improvements. A deeper understanding of the inherent limitations of attention mechanisms in handling long sequences is crucial and deserves focused investigation. This may involve developing novel attention mechanisms that are less susceptible to the ’lost-in-the-middle’ phenomenon. Developing a theoretical framework to explain why Ms-PoE works so effectively could provide valuable insights and pave the way for designing even more efficient and robust long-context models. Finally, extensive experimentation on a wider range of downstream tasks and LLMs is essential to validate the generality and robustness of this approach. This would solidify Ms-PoE’s position as a valuable tool in the LLM community and spur further development in long-context reasoning.
More visual insights#
More on figures
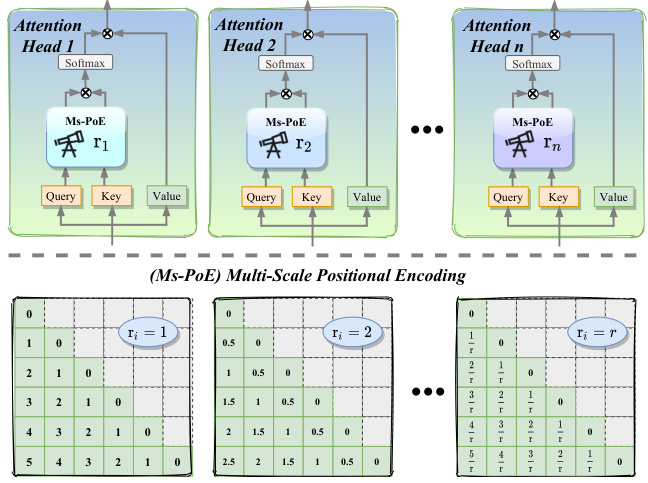
🔼 This figure illustrates the Multi-scale Positional Encoding (Ms-PoE) framework. The top part shows how Ms-PoE is implemented within different attention heads of a Transformer model. Each attention head uses a different scaling ratio (ri) for positional encoding. The bottom part visually represents the positional encoding matrices for different scaling ratios. When r_i = 1, it represents the original ROPE positional encoding. As r_i increases, the positional indices are compressed into a smaller range. This compression helps alleviate the long-term decay effect of RoPE and improves the model’s ability to handle information in the middle of long sequences.
read the caption
Figure 2: Illustration of our Multi-scale Positional Encoding (Ms-PoE) framework. The top figure demonstrates the implementation of Ms-PoE with various scaling ratios in different attention heads, marked with different colors. The bottom figure shows the position details of each head, in which the first matrix (ri = 1) represents the original ROPE.

🔼 This figure shows the impact of positional re-scaling on the accuracy of LLMs in handling long contexts, specifically focusing on the ’lost-in-the-middle’ problem. The top graph displays the average accuracy across different positions of a key document within the input sequence, while the bottom graph shows the difference (gap) between the best and worst accuracy across those positions, representing context utilization ability. It illustrates how changing the scaling ratio affects both the average accuracy and the gap, showing how the approach helps mitigate the ’lost-in-the-middle’ issue by improving overall accuracy and reducing the performance variance across different positions of the key document.
read the caption
Figure 3: Results of the relationship between positional re-scaling and context utilization. The upper curve illustrates the average accuracy when placing the key document in various positions. The bottom curve indicates the gap between the best and worst accuracy.
🔼 This figure shows the results of baseline and proposed Ms-PoE methods on two tasks: MDQA and Key-Value Retrieval. The x-axis represents the position of the essential information within the input. The green bars represent the baseline accuracy, highlighting the ’lost-in-the-middle’ phenomenon where models struggle to identify relevant information in the middle of long contexts. The brown bars show the improved accuracy achieved by using the proposed Ms-PoE method.
read the caption
Figure 1: The x-axis illustrates the placement of essential information within the prompt, ranging from start to end. The green bar serves as a standard baseline, illustrating the “lost-in-the-middle
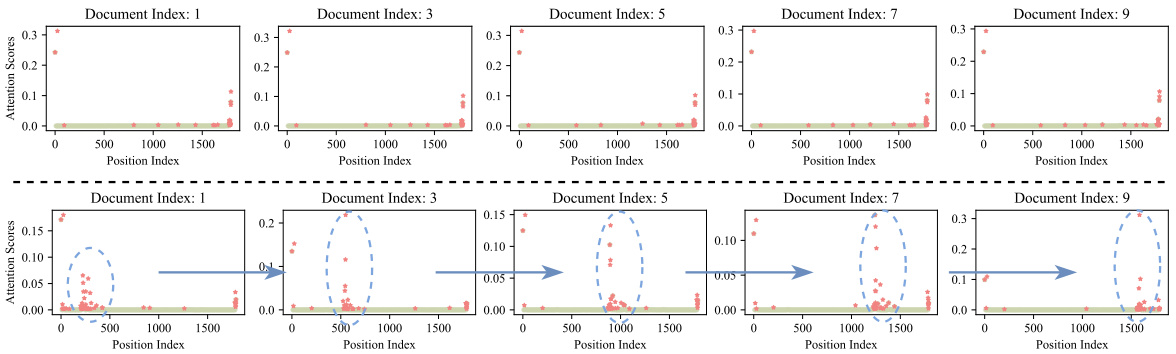
🔼 This figure compares the accuracy of baseline LLMs and LLMs enhanced with Ms-PoE on two tasks: Multi-Document Question Answering (MDQA) and Key-Value Retrieval. In MDQA, the x-axis represents the index of the document containing the answer, showing that Ms-PoE significantly improves accuracy when the relevant document is located in the middle of the sequence. In Key-Value Retrieval, the x-axis shows the index of the relevant key, similarly demonstrating improved accuracy with Ms-PoE, especially when the key is not at the beginning or end of the sequence.
read the caption
Figure 1: The x-axis illustrates the placement of essential information within the prompt, ranging from start to end. The green bar serves as a standard baseline, illustrating the “lost-in-the-middle

🔼 This figure shows the results of an experiment comparing the baseline performance of LLMs (green bars) with the improved performance after applying Multi-scale Positional Encoding (Ms-PoE, brown bars). The x-axis represents the location of crucial information within the input text (from the beginning to the end), and the y-axis shows the accuracy of the LLMs’ performance on different tasks. The figure demonstrates that Ms-PoE significantly improves the ability of LLMs to identify relevant information located in the middle of long contexts, addressing the ’lost-in-the-middle’ challenge.
read the caption
Figure 1: The x-axis illustrates the placement of essential information within the prompt, ranging from start to end. The green bar serves as a standard baseline, illustrating the “lost-in-the-middle
More on tables
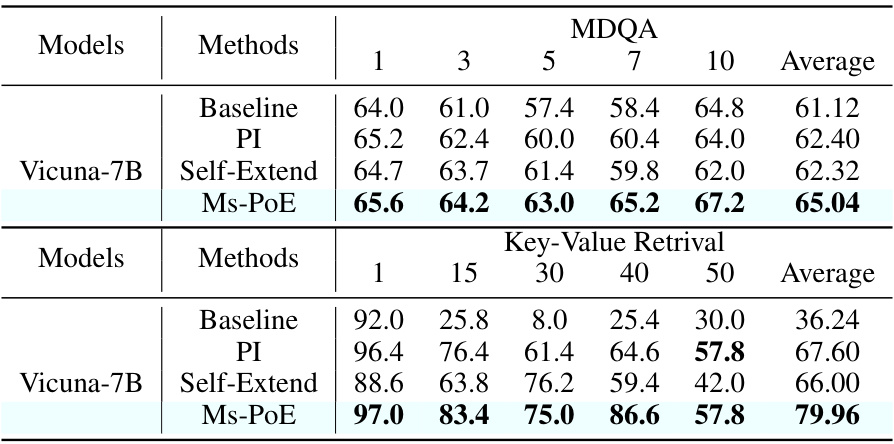
🔼 This table compares the performance of Ms-PoE against baseline methods (PI and Self-Extend) and other competitive methods on two tasks: Multi-Document Question Answering (MDQA) and Key-Value Retrieval. The accuracy is reported for different positions of the key document or key-value pair within the input context (1, 3, 5, 7, 10 for MDQA; 1, 15, 30, 40, 50 for Key-Value Retrieval). The average accuracy across all positions is also provided for each method. The results highlight Ms-PoE’s superior performance in handling long contexts.
read the caption
Table 2: Comparsion results with other competitive methods on MDQA and Key-Value Retrival. Results are reported in accuracy.
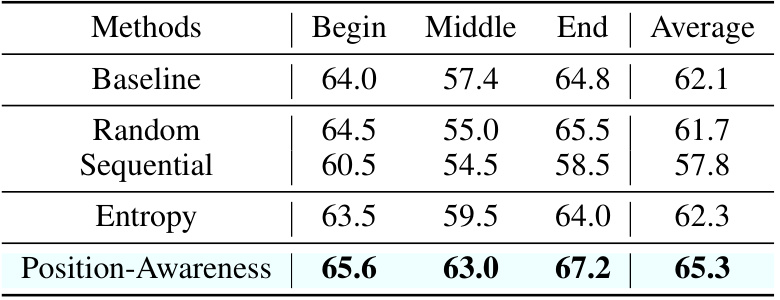
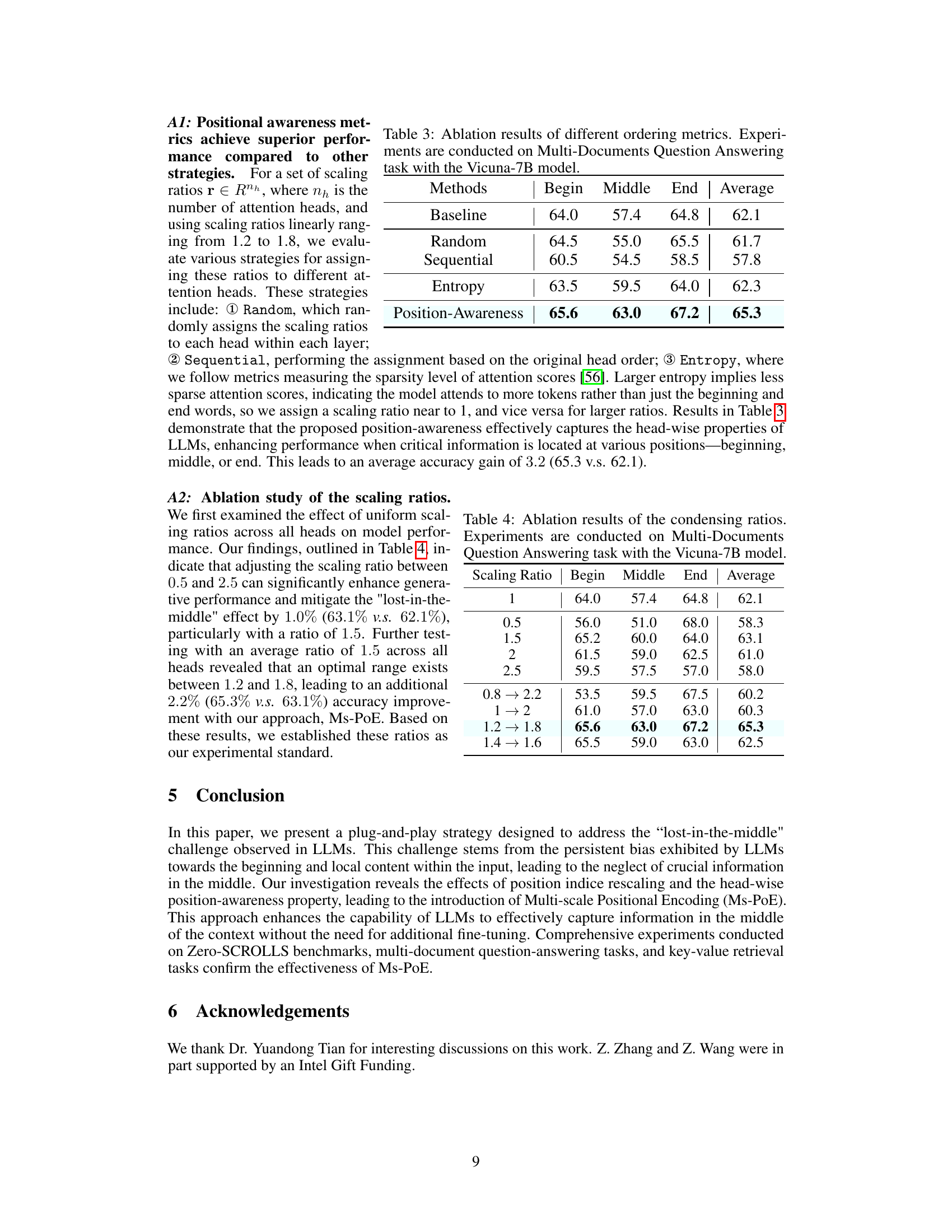
🔼 This table presents the ablation study results on the Multi-Documents Question Answering task using the Vicuna-7B model. It compares the performance of different head ordering strategies for assigning scaling ratios in the Ms-PoE method. The strategies include: Baseline (original method), Random, Sequential, Entropy, and Position-Awareness. The results are shown in terms of accuracy for the beginning, middle, and end positions of the key document, as well as the average accuracy across all positions. The Position-Awareness strategy, which leverages the position-awareness score of each attention head, demonstrates the best performance.
read the caption
Table 3: Ablation results of different ordering metrics. Experiments are conducted on Multi-Documents Question Answering task with the Vicuna-7B model.
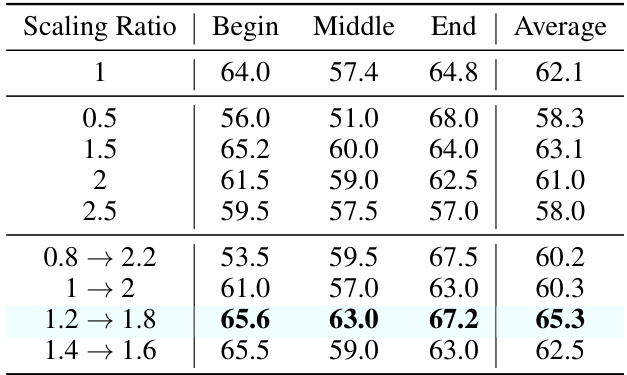
🔼 This table presents the ablation study results focusing on different ordering metrics for assigning scaling ratios to attention heads in the Ms-PoE method. It compares the average accuracy across various strategies (Random, Sequential, Entropy, Position-Awareness) for assigning scaling ratios when the crucial information is located at the beginning, middle, or end of the input text. The results demonstrate the effectiveness of the position-awareness strategy in improving the model’s ability to utilize long-context information.
read the caption
Table 3: Ablation results of different ordering metrics. Experiments are conducted on Multi-Documents Question Answering task with the Vicuna-7B model.
Full paper#