↗ arXiv ↗ Hugging Face ↗ Hugging Face ↗ Chat
TL;DR#
Current multimodal models struggle with simultaneously generating images and texts, often leading to performance degradation. Existing methods typically use modality-specific data, requiring separate models. This inconsistency between modalities is a major hurdle in achieving high-quality visual text generation and comprehension.
To overcome this, the researchers propose TextHarmony, which uses a novel method called Slide-LoRA to dynamically combine modality-specific and modality-agnostic components. This approach allows for a more unified generative process within a single model. They also introduce a new high-quality image caption dataset to further improve performance. TextHarmony shows comparable results to modality-specific methods while using fewer parameters and demonstrates significant improvements in both visual text comprehension and generation tasks.
Key Takeaways#
Why does it matter?#
This paper is important because it presents TextHarmony, a novel approach to multimodal generation that harmonizes visual text comprehension and generation. This addresses a critical challenge in current multimodal models by significantly improving performance across various benchmarks with minimal parameter increase. This work opens up new avenues for research in unified multimodal models and improved visual text generation, relevant to the growing field of MLLMs and their applications.
Visual Insights#

🔼 This figure showcases three different types of image-text generation models and their capabilities. Figure 1(a) compares TextMonkey (text comprehension only), TextDiffusor (image generation only), and TextHarmony (both text and image generation). Figure 1(b) demonstrates TextHarmony’s versatility across various text-centric tasks, including comprehension, perception, generation, and editing of visual text.
read the caption
Figure 1: Figure (a) illustrates the different types of image-text generation models: visual text comprehension models can only generate text, visual text generation models can only generate images, and TextHarmony can generate both text and images. Figure (b) illustrates the versatility of TextHarmony in generating different modalities for various text-centric tasks.
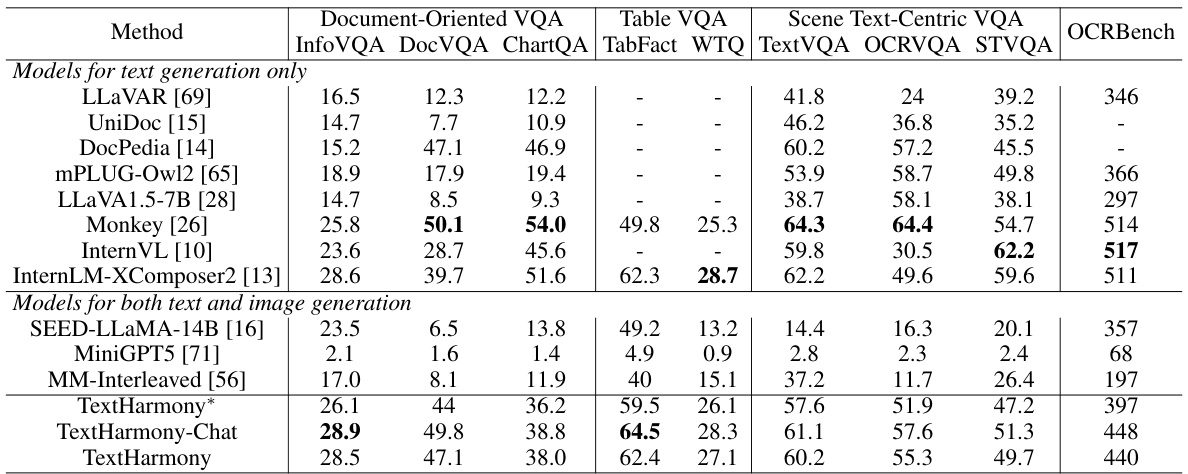
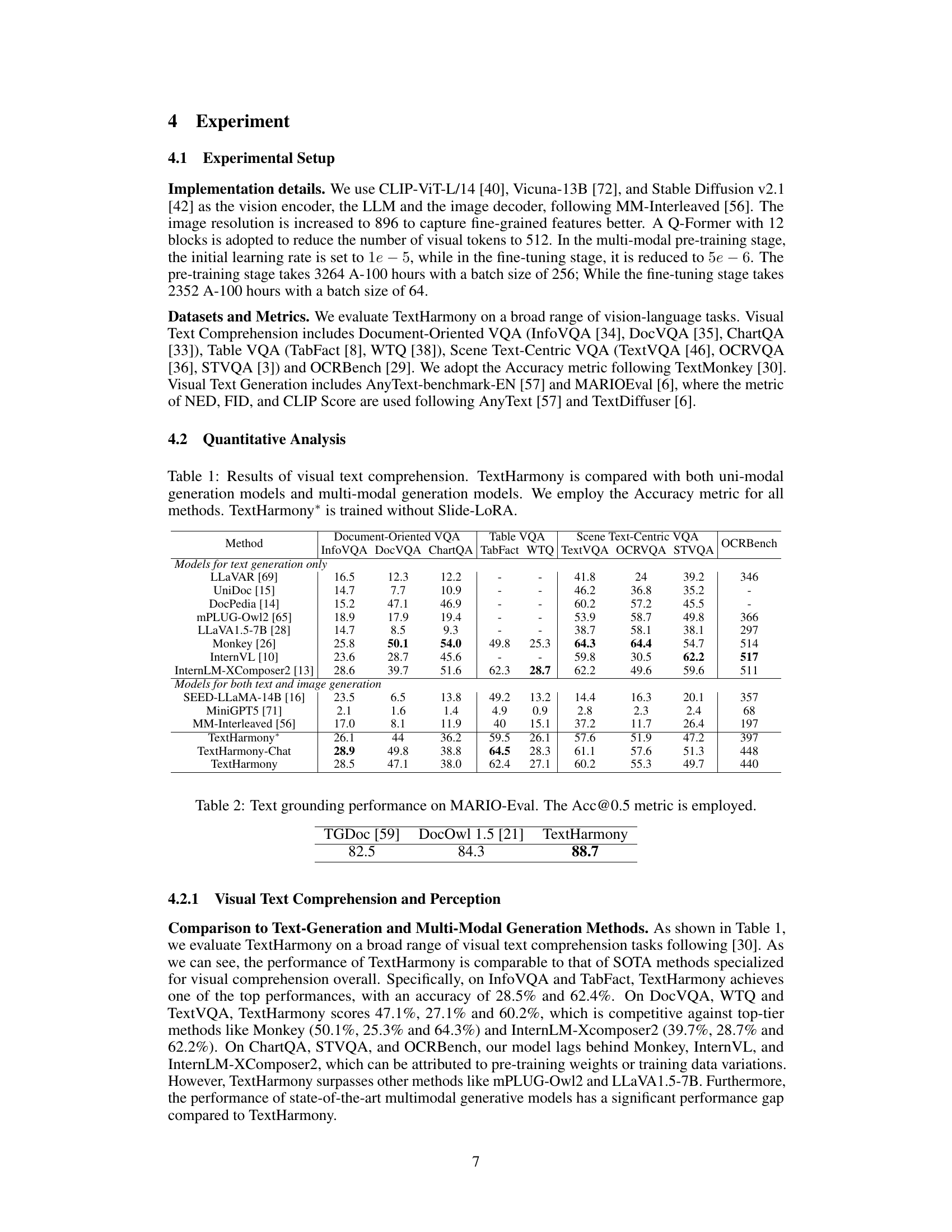
🔼 This table presents a quantitative comparison of TextHarmony’s performance on visual text comprehension tasks against other uni-modal and multi-modal generation models. It evaluates various models across multiple benchmarks including Document-Oriented VQA, Table VQA, and Scene Text-Centric VQA. The ‘Accuracy’ metric is used for comparison. A version of TextHarmony trained without the Slide-LoRA module (TextHarmony*) is also included as a baseline.
read the caption
Table 1: Results of visual text comprehension. TextHarmony is compared with both uni-modal generation models and multi-modal generation models. We employ the Accuracy metric for all methods. TextHarmony* is trained without Slide-LoRA.
In-depth insights#
Slide-LoRA’s Promise#
Slide-LoRA presents a compelling approach to address the inherent challenges in multimodal generation by partially decoupling the parameter space. Its promise lies in harmonizing visual and textual outputs within a unified model, avoiding the performance degradation often seen when training separate modality-specific models. By dynamically aggregating modality-specific and modality-agnostic LoRA experts, Slide-LoRA facilitates a more fluid generative process. This dynamic aggregation, implemented with a gating network, allows for the model to selectively leverage the most relevant expert knowledge, optimizing both visual and textual outputs simultaneously. The advantage is particularly notable in scenarios involving visual text tasks, offering the potential to improve efficiency and reduce complexity compared to traditional methods. This efficient use of parameters is crucial for scaling multimodal models. The method offers a pathway for more unified multimodal architectures that surpass the performance of modality-specific models with minimal increase in parameters. However, the effectiveness of Slide-LoRA hinges on the careful design and training of its constituent experts and gating mechanisms. The success of the approach depends on finding the correct balance between the specialized and general-purpose expertise for optimal results.
Multimodal Harmony#
The concept of “Multimodal Harmony” in a research paper likely explores the effective integration and alignment of multiple modalities, such as text and images, within a unified model. A successful approach would likely address the inherent inconsistencies between these modalities, potentially through novel architectures or training strategies that encourage consistent and balanced performance across all input types. This could involve techniques that dynamically adjust model weights or attention mechanisms, ensuring that different modalities contribute appropriately to the final output. Data quality would be crucial, requiring datasets meticulously labeled with both visual and textual information, perhaps even synthesized using advanced tools to ensure consistency and eliminate spurious correlations. The paper likely benchmarks its approach on various tasks, such as image captioning, visual question answering, and visual text generation, demonstrating superior performance and better generalization compared to models handling each modality separately. Furthermore, exploring the limitations and trade-offs of the proposed methods, with a discussion on potential biases or vulnerabilities introduced by multimodal fusion, would be essential for a comprehensive analysis. Ultimately, the success of “Multimodal Harmony” hinges on demonstrating not just improved performance, but also a more robust and holistic understanding of the underlying interactions between different modalities, paving the way for more sophisticated and versatile AI systems.
Dataset: DetailedTextCaps#
The creation of the DetailedTextCaps dataset is a crucial contribution of this research paper. Its purpose is to address the limitation of existing image caption datasets, which often provide brief and simplistic descriptions, insufficient for training robust visual text generation models. DetailedTextCaps aims to provide significantly more detailed and comprehensive captions, focusing especially on accurately describing textual elements within the images. This is achieved through a sophisticated process, employing an advanced, closed-source MLLM (likely a large language model) and prompt engineering techniques to generate rich and accurate captions. The 100K images and detailed captions within DetailedTextCaps improve the training of TextHarmony and significantly boosts the model’s performance on various visual text generation tasks. The use of a high-quality MLLM suggests that the captions are generated to a high standard of accuracy and detail. The evaluation through comparison to existing datasets, and further validation by GPT-4V, strongly supports the value of this new dataset. In summary, DetailedTextCaps is not just a dataset, but a key enabler of high-quality visual-text model development within the field.
Visual Text Editing#
Visual text editing, as a task within the broader field of multimodal generation, presents a unique set of challenges and opportunities. It involves the manipulation of both visual and textual elements within an image, requiring a deep understanding of the interplay between the two modalities. A successful visual text editing system must be able to accurately identify and locate textual regions within an image, understand the context of the text, and generate appropriate edits based on user instructions. This may involve replacing existing text, adding new text, or modifying the appearance of the text itself. The complexities involved in achieving high accuracy in visual text editing necessitate advanced techniques, potentially incorporating object detection, optical character recognition (OCR), and natural language processing (NLP). Furthermore, the generation of realistic and visually coherent edits is crucial, demanding significant capabilities in image synthesis and manipulation. The development of large, high-quality datasets that include diverse types of image-text editing tasks is essential for training robust models. Research in visual text editing can lead to substantial improvements in various applications such as document editing, image annotation, and graphic design, impacting numerous fields. The field holds great promise in improving accessibility, automating tasks, and creating new interactive and creative tools. Future advancements will likely focus on improving the accuracy and efficiency of algorithms, expanding the range of supported edit types, and exploring more intuitive user interfaces.
Future Research#
Future research directions stemming from this work on harmonizing visual text comprehension and generation could explore several promising avenues. Improving the handling of complex layouts and dense text within images remains a key challenge, necessitating advancements in visual perception and understanding to enhance robustness. Investigating more sophisticated methods for harmonizing multiple modalities during generation, beyond the proposed Slide-LoRA approach, is crucial for improving the quality and coherence of multimodal outputs. This could involve exploring alternative architectures or training strategies. Enhancing the model’s efficiency and scalability is essential for wider deployment, potentially through model compression or quantization techniques. Finally, developing more comprehensive and diverse benchmarks for evaluating multimodal generation models is needed to ensure fair comparisons and drive future innovations. In-depth analysis of specific failure cases and biases within the model, paired with targeted data augmentation strategies, should be pursued. The creation of larger, higher-quality datasets, such as significantly expanding DetailedTextCaps-100K, would substantially improve the model’s performance and generalization capabilities. Moreover, research exploring the application of TextHarmony to new and emerging visual text-related tasks, including advanced visual editing and creative multimodal content generation, promises exciting opportunities.
More visual insights#
More on figures

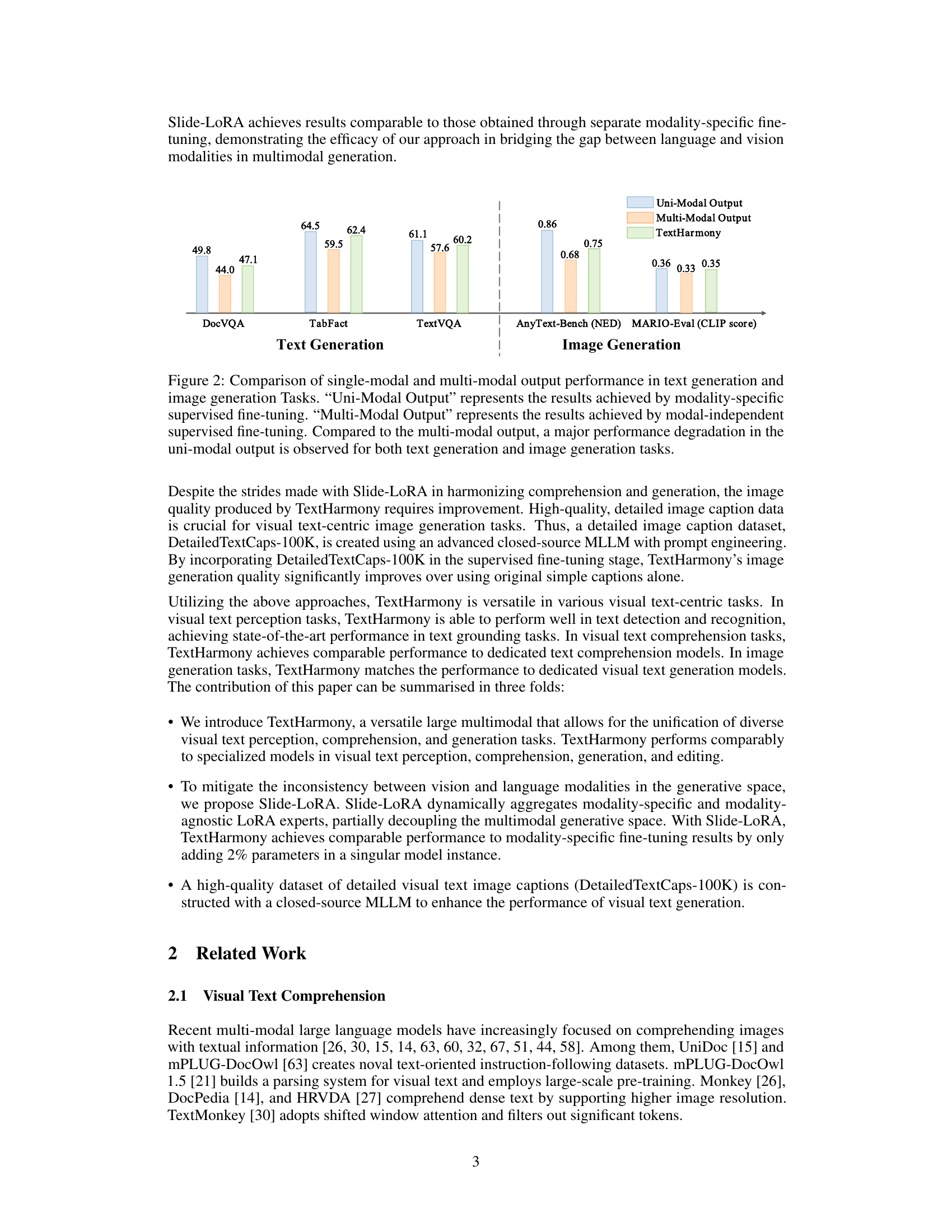
🔼 This figure compares the performance of single-modal and multi-modal outputs in text and image generation tasks. The single-modal output uses modality-specific fine-tuning, while the multi-modal output uses modality-independent fine-tuning. The results show that the multi-modal output outperforms the single-modal output in both text and image generation tasks, indicating that a unified model is more effective than separate models for multimodal generation.
read the caption
Figure 2: Comparison of single-modal and multi-modal output performance in text generation and image generation Tasks. “Uni-Modal Output” represents the results achieved by modality-specific supervised fine-tuning. “Multi-Modal Output' represents the results achieved by modal-independent supervised fine-tuning. Compared to the multi-modal output, a major performance degradation in the uni-modal output is observed for both text generation and image generation tasks.

🔼 This figure illustrates the architecture of TextHarmony, a multimodal generation model. It shows how a vision encoder, a large language model (LLM), and an image decoder are integrated to generate both text and images. The key innovation, Slide-LoRA, is highlighted as a method to address the common issue of inconsistency between vision and language modalities in multimodal generation, achieving this by partially separating the parameter space during training.
read the caption
Figure 3: Pipeline of TextHarmony. TextHarmony generates both textual and visual content by concatenating a vision encoder, an LLM, and an image decoder. The proposed Slide-LoRA module mitigates the problem of inconsistency in multi-modal generation by partially separating the parameter space.

🔼 This figure shows two sets of image captions for the same two images. The first set of captions comes from the MARIO-LAION dataset, which provides relatively short and general descriptions. The second set comes from the newly created DetailedTextCaps-100K dataset. These captions are significantly more detailed and accurately reflect the textual elements present within the images. This comparison demonstrates the superior quality of the DetailedTextCaps-100K dataset for visual text generation tasks.
read the caption
Figure 4: Captions from DetailedTextCaps-100K and MARIO-LAION for the same image. DetailedTextCaps-100K can better depict the textual elements in the image.

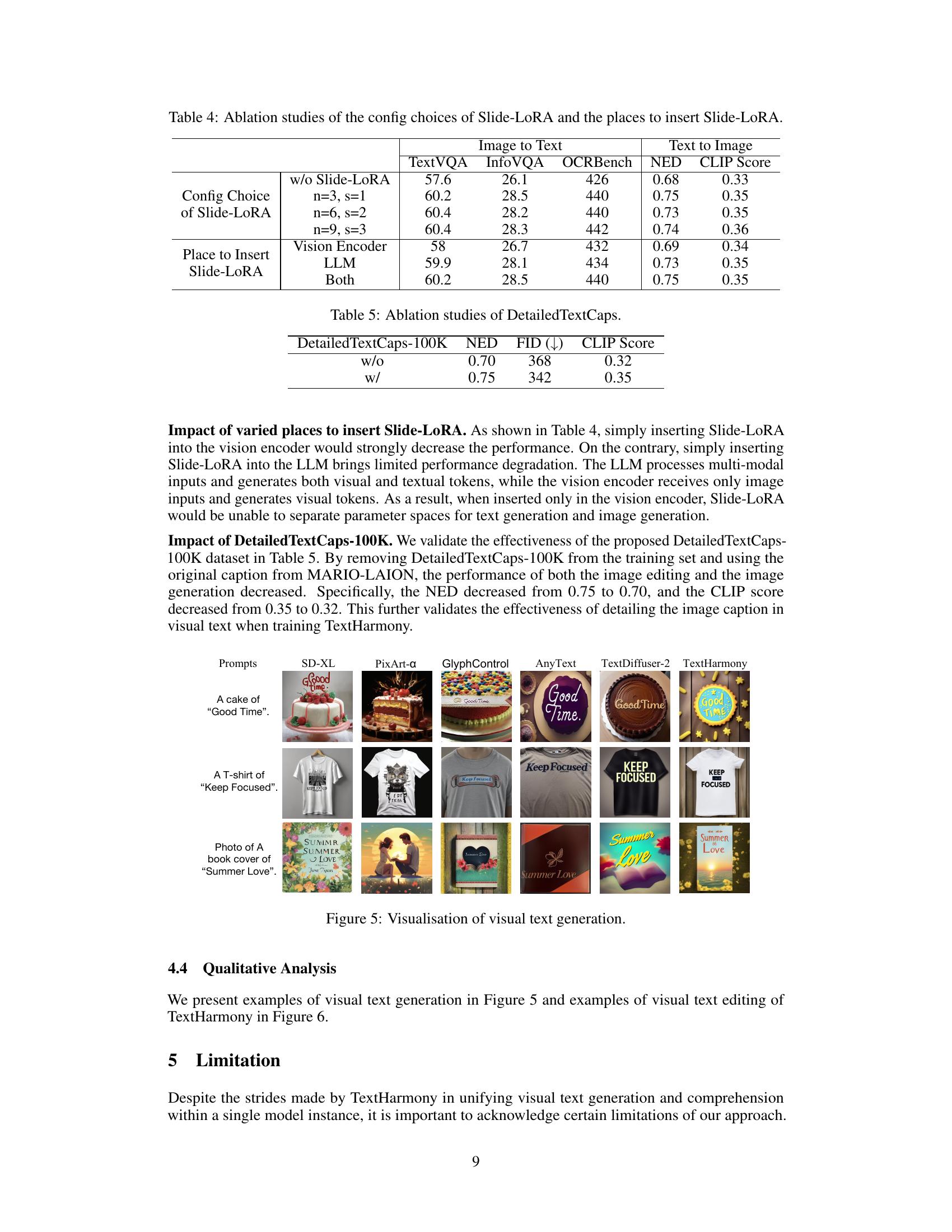
🔼 This figure shows examples of visual text generation results from different models including SD-XL, PixArt-a, GlyphControl, AnyText, TextDiffuser-2, and TextHarmony. For each model, there are three examples with the prompts: ‘A cake of 'Good Time'’, ‘A T-shirt of 'Keep Focused'’, and ‘Photo of A book cover of 'Summer Love'’. The images generated show the variety in style and quality of text rendering achieved by each model.
read the caption
Figure 5: Visualisation of visual text generation.

🔼 This figure shows a comparison of visual text editing results between the original image and those generated by AnyText, TextDiffuer-2, and TextHarmony. The three example images demonstrate the models’ abilities to edit text within images, preserving the overall image quality. Differences in text clarity, accuracy, and overall aesthetic are readily apparent across different models. The figure highlights TextHarmony’s capacity to perform visual text editing effectively.
read the caption
Figure 6: Visualisation of visual text editing.

🔼 This figure shows four examples of image captions generated using two different methods: MARIO-LAION and DetailedTextCaps-100K. Each example shows the same image and its caption from both methods. The captions from DetailedTextCaps-100K are longer and more detailed, and they better capture the text contained within each image than those from MARIO-LAION.
read the caption
Figure 4: Captions from DetailedTextCaps-100K and MARIO-LAION for the same image. DetailedTextCaps-100K can better depict the textual elements in the image.

🔼 This figure demonstrates TextHarmony’s ability to perform visual text comprehension and perception tasks. The left side shows an example image with a book cover. The right side illustrates how the model answers questions about the image, demonstrating its capacity to extract and locate text within images and answer questions based on their contents.
read the caption
Figure 8: Visualisation of TextHarmony's visual text comprehension and perception capabilities.
More on tables

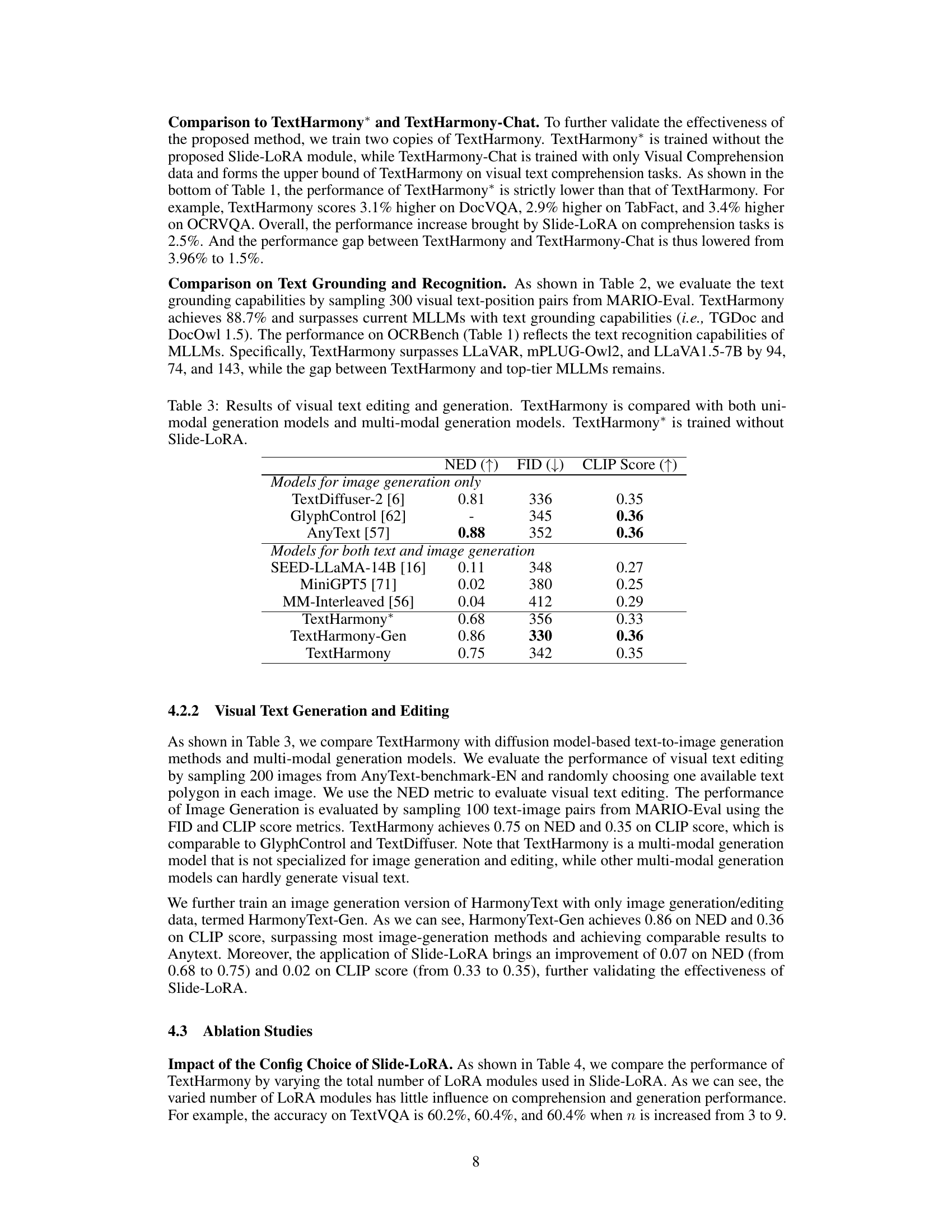
🔼 This table presents the results of the TextHarmony model on the MARIO-Eval benchmark for text grounding. The Acc@0.5 metric, which measures the accuracy of text grounding at a 0.5 IoU threshold, is used to evaluate the model’s performance. The table compares TextHarmony’s performance to two other state-of-the-art models, TGDoc and DocOwl 1.5, demonstrating that TextHarmony achieves superior performance on this task.
read the caption
Table 2: Text grounding performance on MARIO-Eval. The Acc@0.5 metric is employed.
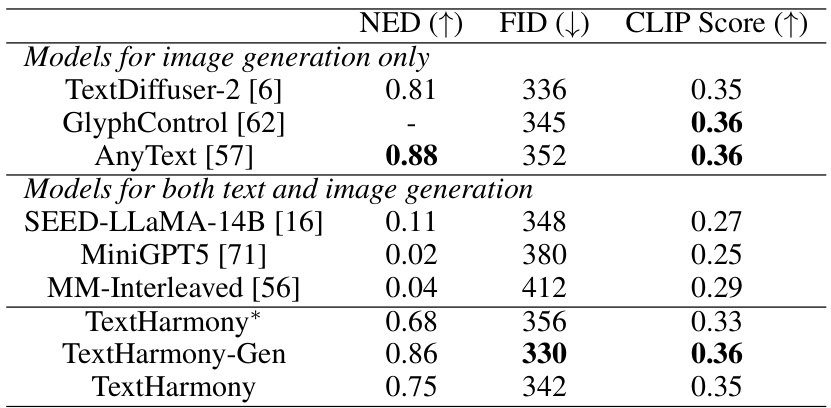
🔼 This table presents the results of visual text editing and generation tasks. It compares the performance of TextHarmony against both unimodal (models specializing in either image or text generation) and multimodal (models generating both) generation models. A version of TextHarmony trained without the Slide-LoRA module (TextHarmony*) is included as a baseline for comparison. The metrics used for evaluation are NED (higher is better), FID (lower is better), and CLIP Score (higher is better).
read the caption
Table 3: Results of visual text editing and generation. TextHarmony is compared with both uni-modal generation models and multi-modal generation models. TextHarmony* is trained without Slide-LoRA.

🔼 This table presents the ablation study results for different configurations of Slide-LoRA, a module in TextHarmony responsible for harmonizing visual text comprehension and generation. It shows how changes in the number of LoRA modules (n) and scaling factor (s) impact the performance metrics on various tasks. It also compares the impact of placing Slide-LoRA in different locations within the model architecture (Vision Encoder, LLM, or both). The performance metrics include the accuracy (TextVQA, InfoVQA, OCRBench) and image generation metrics (NED, CLIP Score).
read the caption
Table 4: Ablation studies of the config choices of Slide-LoRA and the places to insert Slide-LoRA.

🔼 This table presents the results of an ablation study evaluating the impact of using the DetailedTextCaps-100K dataset on the performance of TextHarmony in visual text generation and editing tasks. The table compares the performance metrics (NED, FID, and CLIP score) when using the DetailedTextCaps-100K dataset (‘w/’) against the performance when not using it (‘w/o’). The results show that including DetailedTextCaps-100K improves the performance across all three metrics.
read the caption
Table 5: Ablation studies of DetailedTextCaps.

🔼 This table presents a comparison of TextHarmony’s performance on visual text comprehension tasks against various unimodal and multimodal generation models. It shows accuracy scores across several datasets categorized by task type (Document-Oriented VQA, Table VQA, Scene Text-Centric VQA, and OCRBench). The table highlights TextHarmony’s competitive performance, especially when compared to models that only generate text or images, demonstrating the effectiveness of the integrated approach.
read the caption
Table 1: Results of visual text comprehension. TextHarmony is compared with both uni-modal generation models and multi-modal generation models. We employ the Accuracy metric for all methods. TextHarmony* is trained without Slide-LoRA.
Full paper#