↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
The research focuses on converting energy-intensive transformer-based Artificial Neural Networks (ANNs) into more energy-efficient Spiking Neural Networks (SNNs). A major hurdle is the incompatibility of self-attention mechanisms with the spiking nature of SNNs. Existing approaches either restructure the self-attention or compromise on fully spike-based computation. This limits their energy efficiency gains and may reduce accuracy.
This paper introduces a novel method, named SpikedAttention, that directly converts a pre-trained transformer to a fully spike-based SNN without any retraining. This is achieved through two key innovations: a trace-driven matrix multiplication technique to reduce the timesteps needed for spike-based computation and a winner-oriented spike shift mechanism for approximating the softmax operation. SpikedAttention achieves state-of-the-art accuracy on ImageNet with a 42% energy reduction. Furthermore, it successfully converts a BERT model to an SNN with only a 0.3% accuracy loss and a 58% energy reduction. This demonstrates the potential of SpikedAttention for creating efficient and accurate SNNs for diverse applications.
Key Takeaways#
Why does it matter?#
This paper is significant because it presents SpikedAttention, a novel training-free method for converting large transformer models into energy-efficient spiking neural networks (SNNs). This addresses a critical challenge in AI, enabling deployment of powerful models on resource-constrained devices and reducing energy consumption, which is highly relevant to current trends in energy-efficient AI and neuromorphic computing. It opens avenues for further research in efficient transformer-to-SNN conversion techniques, exploration of various spike coding schemes, and development of specialized hardware architectures optimized for SpikedAttention.
Visual Insights#

Figure 1(a) compares the performance of SpikedAttention against other spike-based SNNs on ImageNet classification in terms of accuracy, energy consumption, and parameter size. It shows that SpikedAttention achieves state-of-the-art accuracy with significantly lower energy consumption. Figure 1(b) illustrates the architecture of the fully spike-based attention module proposed in the paper, which is a key component of SpikedAttention.

This table compares the performance of SpikedAttention with other state-of-the-art spike-based transformer models on the ImageNet dataset. The comparison is based on four key metrics: the number of parameters (Param (M)), energy consumption (Energy (mJ)), required timestep (Timestep), and accuracy (Acc (%)). The table shows that SpikedAttention achieves state-of-the-art accuracy with significantly lower energy consumption compared to existing methods. Two versions of SpikedAttention are shown: one without ReLU activation function and another with it.
In-depth insights#
SNN-Transformer#
SNN-Transformers represent a significant advancement in neural network design, aiming to combine the strengths of spiking neural networks (SNNs) and transformer architectures. SNNs offer superior energy efficiency due to their event-driven nature, while transformers excel at capturing long-range dependencies through self-attention mechanisms. However, directly integrating these two paradigms presents challenges. The inherent differences in data representation (continuous vs. discrete) and computational methods (multiply-accumulate vs. accumulate) necessitate novel approaches for conversion or direct training. Research in this area focuses on developing efficient spike-based self-attention mechanisms, exploring various spike coding schemes to represent transformer inputs and outputs, and devising effective softmax approximations to maintain accuracy. Success in this field would pave the way for highly energy-efficient AI models, particularly important for resource-constrained applications like mobile and edge devices.
Spike-based Softmax#
The concept of a “Spike-based Softmax” within the context of spiking neural networks (SNNs) presents a significant challenge due to the inherent incompatibility of the softmax function’s exponential nature with the discrete, binary signaling of spikes. Approximating the softmax function is crucial for many SNN applications, particularly those involving classification tasks where probabilities are needed. Existing approaches often rely on non-spike computation, which undermines the energy efficiency advantages of SNNs. Therefore, a true spike-based softmax needs to operate entirely within the spiking domain, leveraging spike timing or rate coding to represent probabilities. Winner-Oriented Spike Shift (WOSS) is one potential solution, employing a spike-based mechanism to approximate the softmax output by manipulating spike timings to reflect probability. This approach would require innovative hardware or algorithmic techniques to ensure accuracy and efficiency. Trace-driven approaches, which track spike history, could be integrated to improve the efficiency of the underlying matrix multiplication needed for the softmax calculation. Such a “Spike-based Softmax” would constitute a significant advancement in SNN research, potentially enabling more complex and accurate SNN-based systems for various applications.
Trace-driven Product#
The concept of a ‘Trace-driven Product’ in the context of spiking neural networks (SNNs) suggests a paradigm shift in how matrix multiplication is handled. Traditional methods in SNNs often struggle with the inherent sparsity of spike data, leading to inefficient computations. A trace-driven approach, however, cleverly leverages the temporal information embedded within spike trains. Instead of performing direct multiplication at each timestep, it maintains a ’trace’ that accumulates weighted contributions over time. This trace effectively summarizes the history of spike interactions, enabling more efficient computation. This is particularly beneficial for the attention mechanism in transformers, where dynamic matrix multiplications are prevalent. By tracking the trace, the computation is streamlined and avoids the costly recalculation at each timestep, leading to significant energy savings and a more biologically plausible implementation. The use of a trace-driven product is thus a crucial innovation for bridging the gap between the theoretical elegance of SNNs and practical implementations of energy-efficient, high-performance AI systems.
Energy Efficiency#
The research paper emphasizes energy efficiency as a primary advantage of Spiking Neural Networks (SNNs) over traditional Artificial Neural Networks (ANNs). It highlights the significantly lower energy consumption of SNNs due to their event-driven nature, involving weight accumulation instead of power-hungry multiply-accumulate (MAC) operations. The paper presents SpikedAttention, a novel transformer-to-SNN conversion method that achieves state-of-the-art accuracy with substantial energy savings (42% on ImageNet and 58% on GLUE benchmark). This efficiency gain is attributed to several key contributions: a fully spike-based transformer architecture, trace-driven matrix multiplication reducing computational timesteps, and a winner-oriented spike shift for efficient softmax approximation. The method’s success in achieving significant energy reduction with minimal accuracy loss demonstrates its potential for low-power AI applications. The thorough analysis of energy consumption, considering factors such as weight accumulation, neuron potential updates, and on-chip data movement, is a strength of the work. The work emphasizes the impact on real-world deployment of energy efficient AI.
Future Works#
The paper’s exploration of SpikedAttention opens exciting avenues for future research. Extending SpikedAttention to handle more complex language models that utilize architectures beyond the transformer or incorporate mechanisms like GeLU and LayerNorm is crucial. This would significantly broaden its applicability. Another important area is improving the energy efficiency of the model further by exploring alternative spike coding schemes and optimizing the hardware implementation to minimize power consumption. Reducing the timestep (T) while maintaining accuracy is another key objective. This could involve learning per-layer bases for one-spike phase coding or developing more sophisticated trace-driven matrix multiplication techniques. Finally, a thorough investigation into the robustness of SpikedAttention across different datasets and tasks is needed to assess its generalizability and practical applicability. This could lead to improvements in the model’s design and training procedures to address potential limitations.
More visual insights#
More on figures

This figure illustrates the computation of attention in previous SNN-based transformers. It highlights two approaches: one with softmax and one without. Both approaches use non-spike computations during the attention mechanism. The figure simplifies the representation by using a timestep T of 1 for the spike tensor. The red box indicates non-spike computation parts.
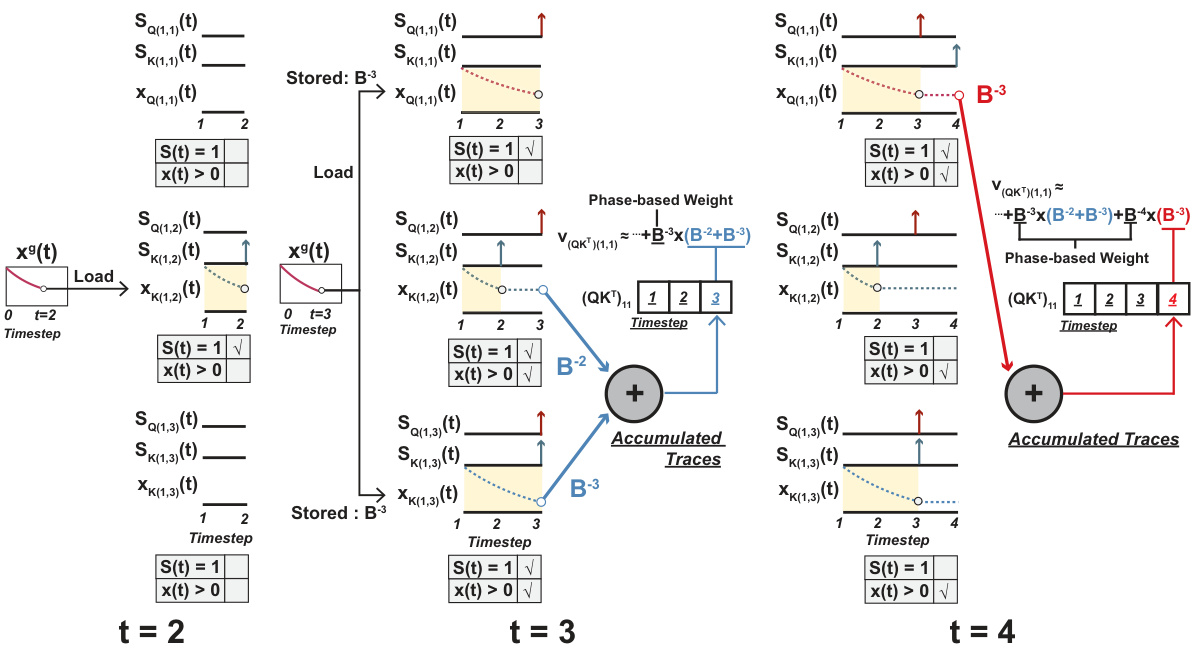
This figure illustrates the trace-driven matrix multiplication method proposed in the paper. It shows how a global trace, decaying with each timestep by a factor of B (the base of the phase coding), is used to accumulate the values associated with each spike. This method is designed to efficiently perform spike-based matrix multiplication, reducing the need for long timesteps. The global trace is transferred to each neuron’s local memory when its first spike is encountered. This results in an efficient computation of dot products using only spikes and local memory operations.

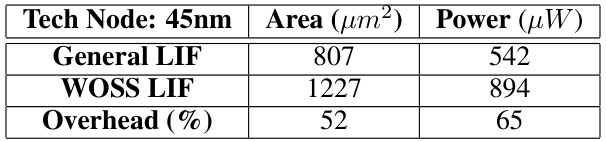
This figure illustrates the Winner-Oriented Spike Shift (WOSS) mechanism used in SpikedAttention to approximate the softmax function. It shows how the potential of neurons is updated based on incoming spikes and a global inhibitory signal, resulting in a spike-based approximation of softmax without using exponential functions. The winner neuron fires early, and others fire later, reflecting the softmax probability distribution.

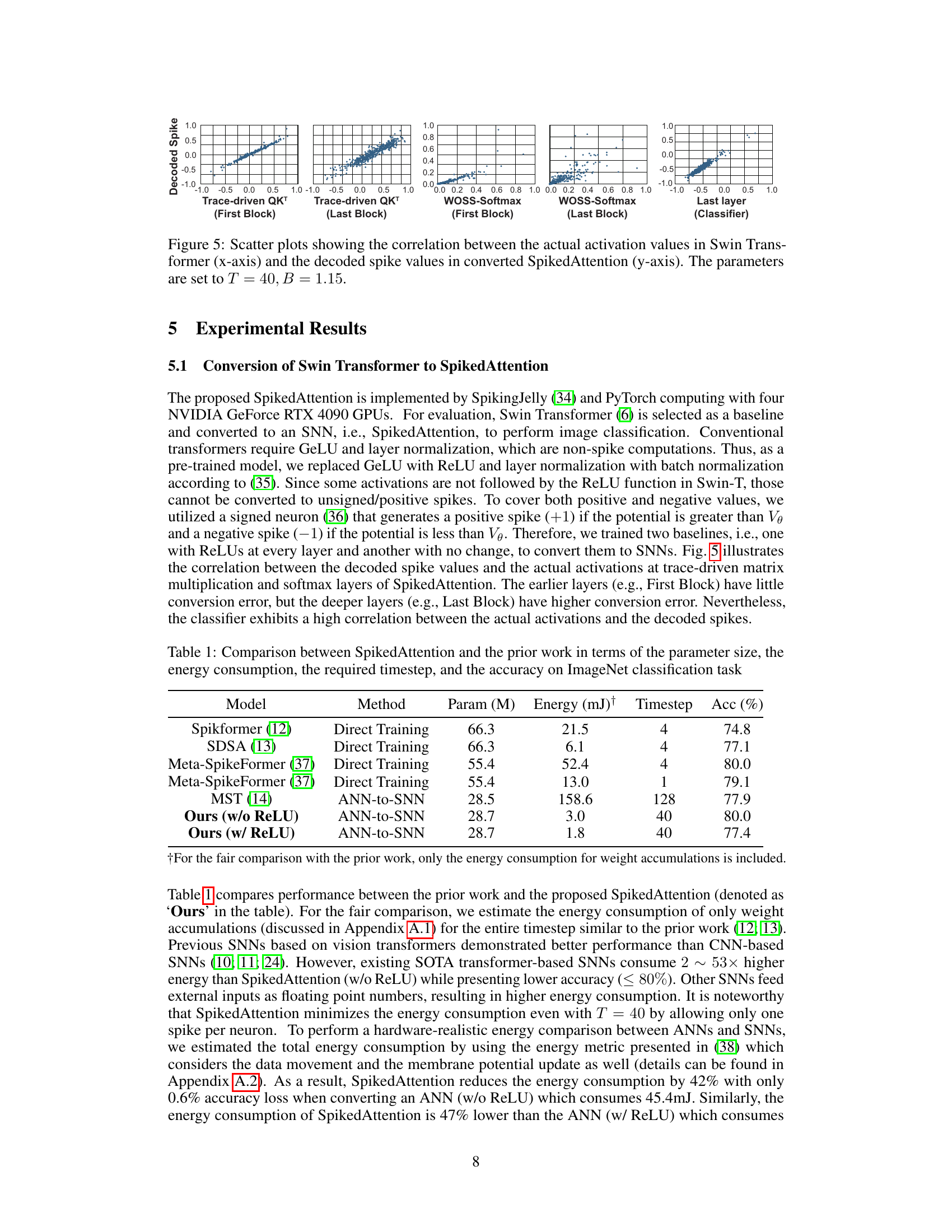
This figure shows scatter plots illustrating the correlation between the real activation values from the original Swin Transformer model and the corresponding decoded spike values after conversion to SpikedAttention. The plots are separated by different stages of the SpikedAttention model, including trace-driven QK’ computations (both first and last blocks), WOSS-Softmax operations (first and last blocks), and the final classification layer. The parameters used for the conversion are T=40 and B=1.15. The strong positive correlations demonstrate that the spike-based representation accurately captures the information present in the original model’s activations.
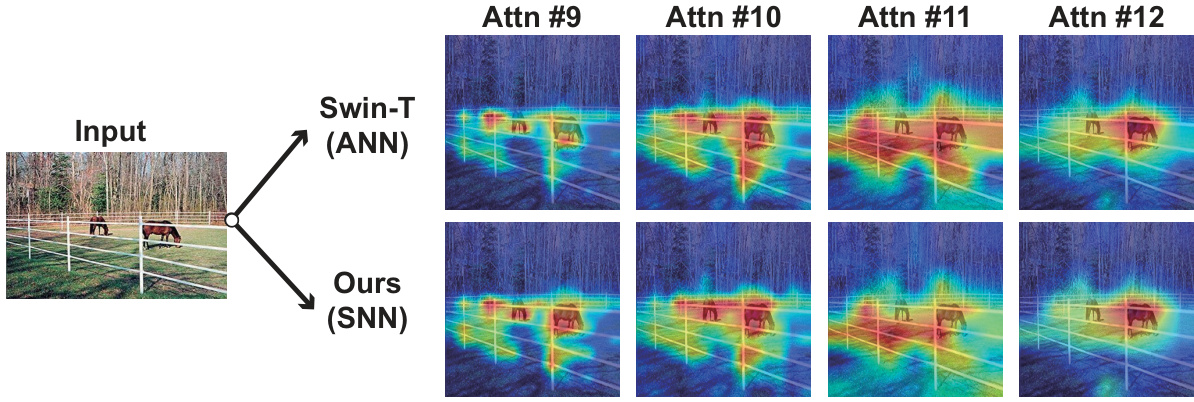
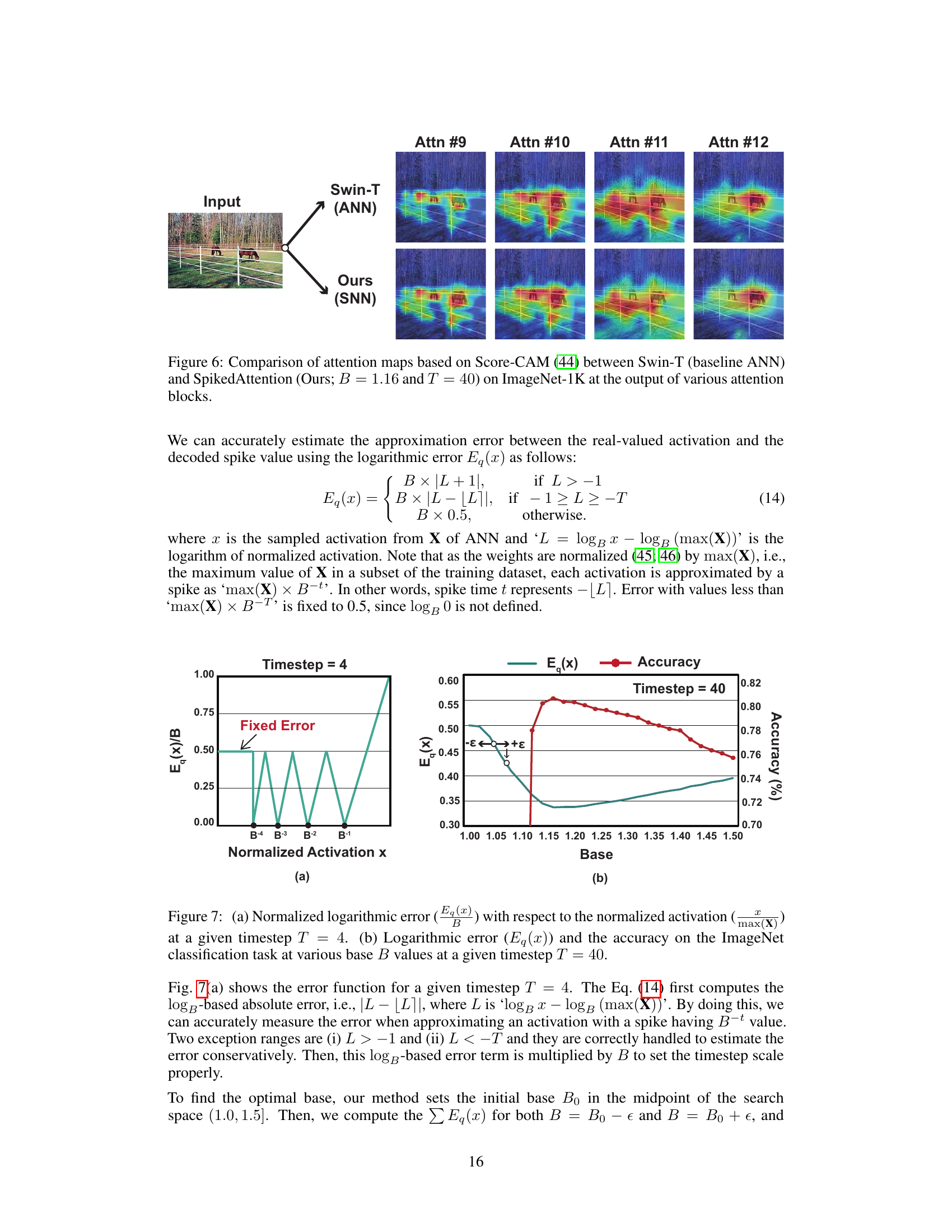
This figure compares attention maps generated by a baseline ANN (Swin-T) and the proposed SpikedAttention SNN model on ImageNet. Score-CAM was used to visualize the attention maps from four different attention blocks (Attn #9 - #12) within the networks. The goal is to show that SpikedAttention successfully converts the attention mechanism into a spike-based representation while maintaining similar attention patterns to the original ANN.

This figure shows the relationship between the base B used in the one-spike phase coding scheme and both the approximation error and accuracy on the ImageNet dataset. The logarithmic error measures how well the spike-based approximation matches the actual activation values. The left subplot (a) shows this error at timestep T=4, while the right subplot (b) shows the error and resulting accuracy at timestep T=40, demonstrating the optimal base B to minimize error and maximize accuracy.

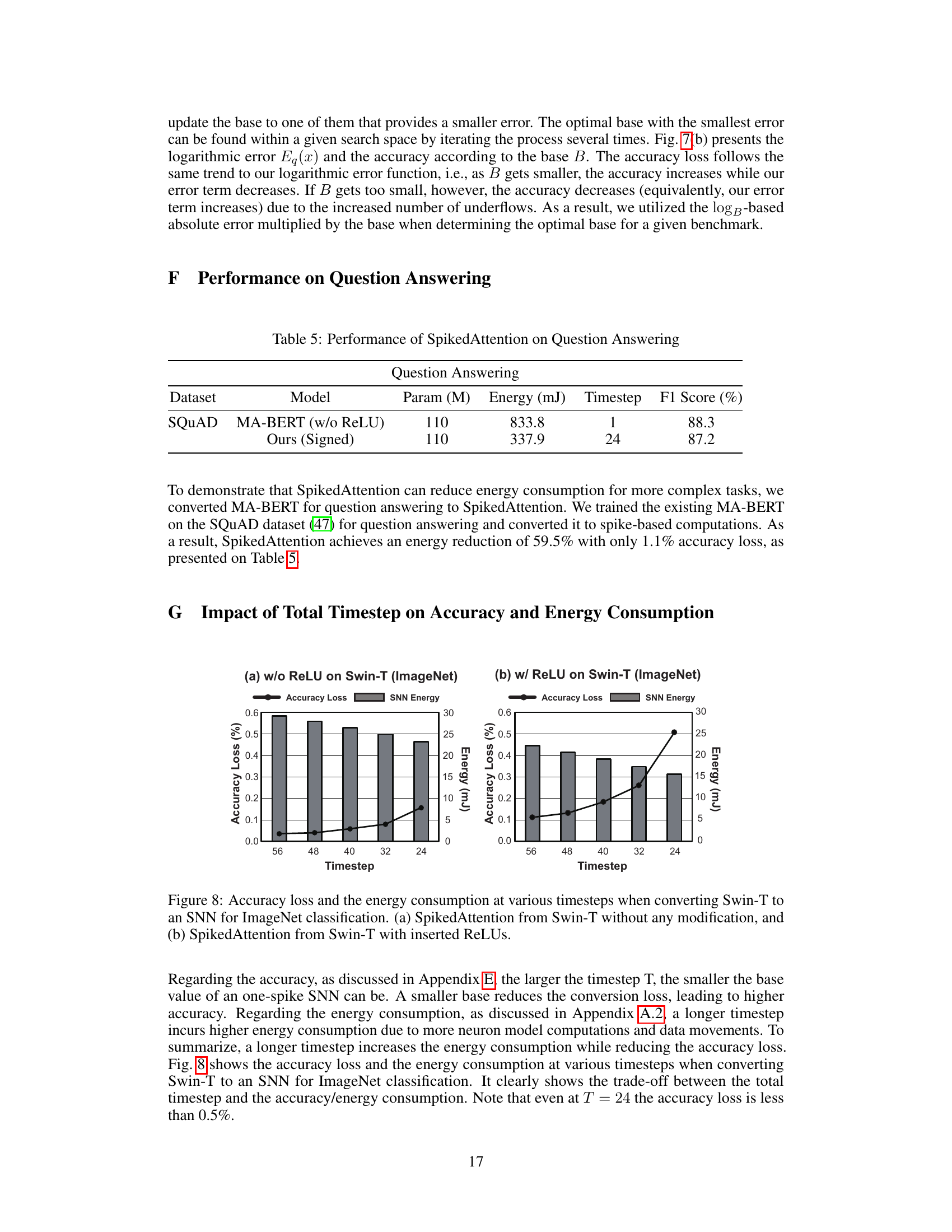
This figure shows the trade-off between accuracy and energy consumption when varying the timestep (T) in the conversion of Swin Transformer to SpikedAttention on the ImageNet dataset. Two scenarios are compared: one without ReLU activation and another with ReLU. As the timestep decreases, accuracy loss increases, but energy consumption decreases significantly. The results indicate that a balance must be struck between accuracy and energy efficiency in choosing a suitable timestep. Using ReLU seems to increase the energy consumption.

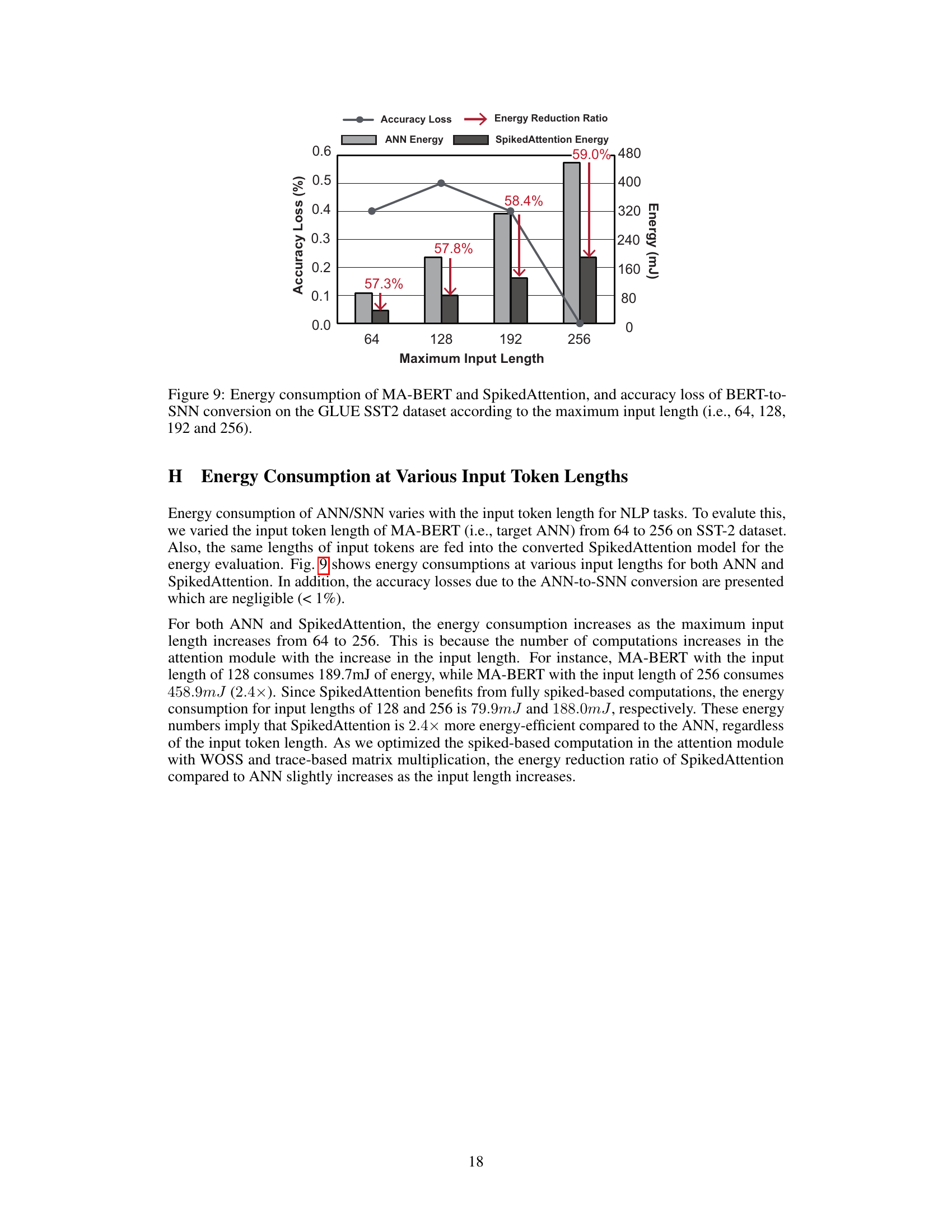
This figure shows the energy consumption and accuracy loss comparison between MA-BERT (ANN) and SpikedAttention (SNN) for different input lengths on the GLUE SST2 dataset. As the maximum input length increases, both models show increased energy consumption. However, SpikedAttention demonstrates significantly lower energy consumption with a small accuracy loss across all tested input lengths, highlighting its efficiency.
More on tables

This table compares the performance of SpikedAttention with other state-of-the-art spike-based transformer models on the ImageNet dataset for image classification. It shows the parameter size (in millions), energy consumption (in mJ), required timestep, and accuracy achieved by each model. The energy consumption is specifically for weight accumulations to ensure a fair comparison with other studies. Note that the energy values of SpikedAttention are significantly lower than those of other models and that the accuracy of SpikedAttention is competitive or superior.
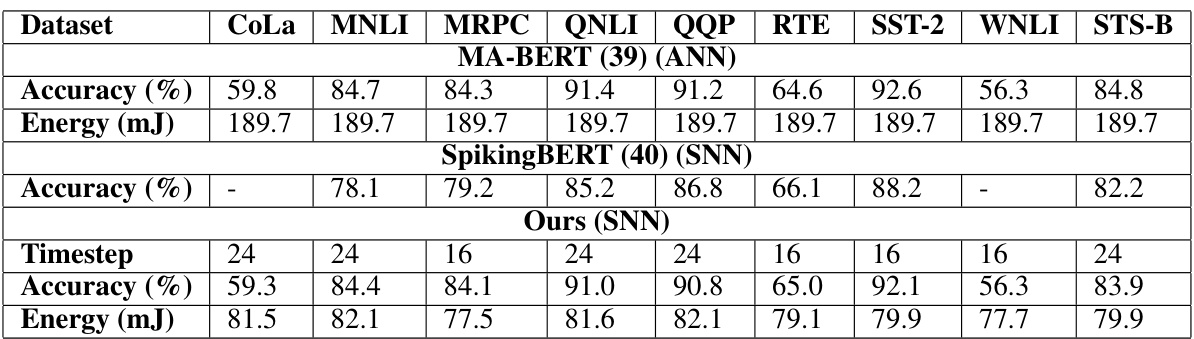
This table compares the performance of SpikedAttention against other BERT models on the GLUE benchmark. It shows the accuracy and energy consumption for each model across various GLUE tasks (CoLA, MNLI, MRPC, QNLI, QQP, RTE, SST-2, WNLI, STS-B). The table highlights SpikedAttention’s ability to achieve comparable accuracy with significantly lower energy consumption compared to traditional ANN-based models.
This table compares the performance of SpikedAttention with other state-of-the-art spike-based transformer models on the ImageNet dataset. It evaluates each model based on its parameter size (in millions), energy consumption (in mJ), required timestep for spike processing, and classification accuracy (in percentage). The comparison highlights SpikedAttention’s superior efficiency and accuracy compared to existing methods.

This table compares the performance of SpikedAttention against several prior state-of-the-art spike-based transformer models on the ImageNet dataset. It shows that SpikedAttention achieves state-of-the-art accuracy while significantly reducing both energy consumption and the required timestep. The comparison highlights the improvements in efficiency and accuracy SpikedAttention offers over existing methods.
Full paper#