TL;DR#
Large pre-trained models excel in various downstream tasks, but their computational requirements hinder widespread adoption. Knowledge Distillation (KD) trains compact student models to mimic larger teacher models, but often results in suboptimal performance due to the limited capacity of student models. This paper addresses this challenge by focusing on efficient model compression and transfer learning.
The proposed Over-Parameterization Distillation Framework (OPDF) tackles these issues by over-parameterizing student models during training. It uses matrix product operators (MPO) for efficient tensor decomposition, scaling up parameters without increasing inference latency. A tensor constraint loss ensures efficient information transfer from teacher to student models. Experiments across computer vision and natural language processing tasks demonstrate OPDF’s effectiveness in improving KD performance.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces a novel approach to knowledge distillation, improving the performance of smaller student models without increasing inference latency. It leverages tensor decomposition to efficiently over-parameterize student models during training, thus bridging the performance gap between large teacher models and smaller student models. This has significant implications for deploying large models in resource-constrained environments and opens up new avenues for research in model compression and efficient training techniques.
Visual Insights#

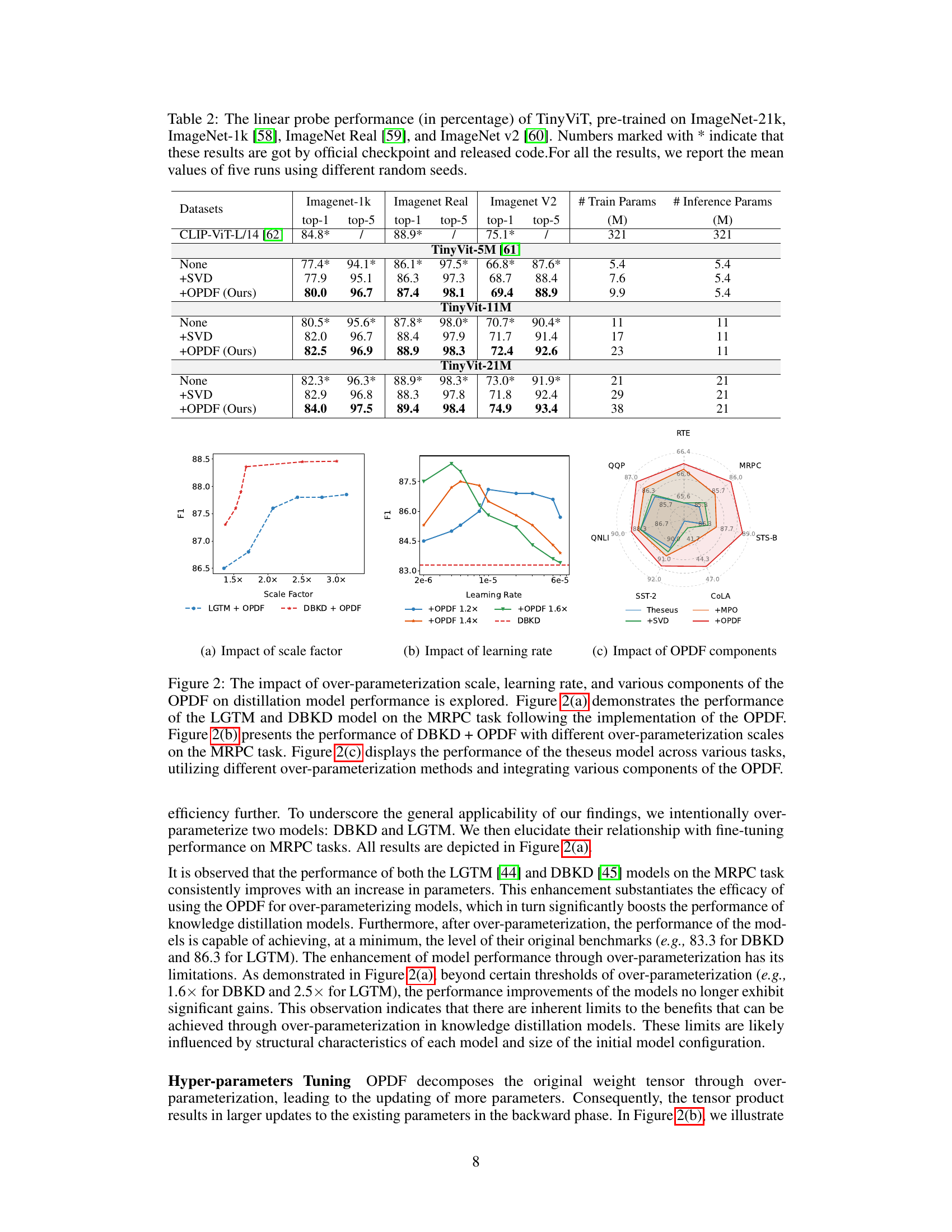
🔼 This figure provides a high-level overview of the Over-parameterization Distillation Framework (OPDF) proposed in the paper. Panel (a) shows the overall workflow: a pre-trained teacher model and a student model are input into the OPDF, which uses Matrix Product Operators (MPO) to over-parameterize the student model. The over-parameterized student model is then trained on a target task, with a tensor alignment loss (LAux) used to ensure consistency between the student and teacher models. Panel (b) details the MPO decomposition process, illustrating how a parameter matrix is decomposed into a central tensor and auxiliary tensors. The central tensor and auxiliary tensors are then optimized and re-combined to generate an enhanced student model.
read the caption
Figure 1: The overview of over-parameter distillation framework (OPDF) for knowledge ditillation. a, We use MPO decomposition to realize the over-parameter procedure for the student model. The auxiliary tensors of the student model are trained to imitate the auxiliary tensors of the teacher model closely. b, We present an illustrative example of MPO decomposition. A parameter matrix WIxJ is decomposed into central tensor and auxiliary tensors.

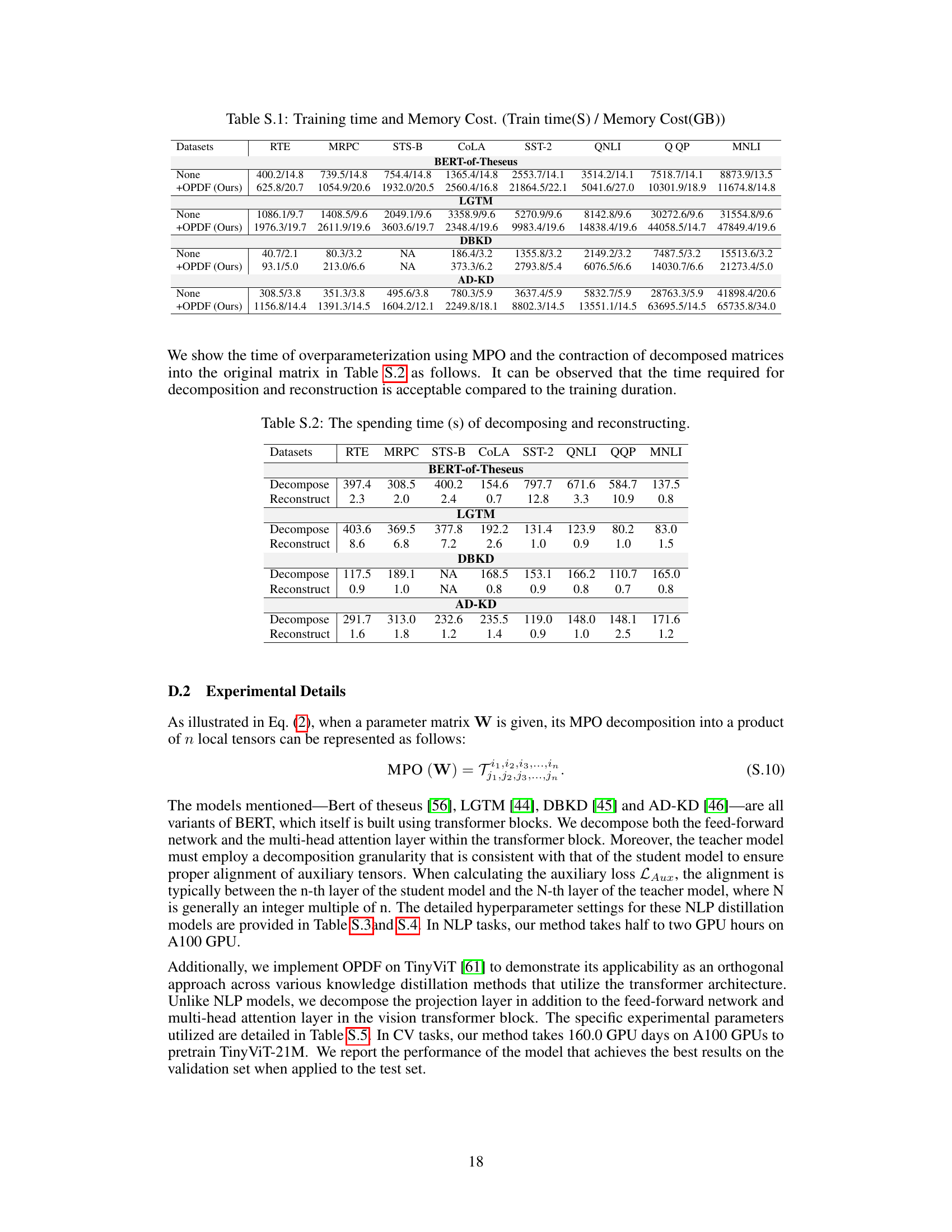
🔼 This table compares the performance of different knowledge distillation (KD) models on the GLUE benchmark. It shows the results for several baseline KD methods (BERT-of-Theseus, LGTM, DBKD, AD-KD) and how their performance changes when the student model is over-parameterized using either Singular Value Decomposition (SVD) or the proposed Matrix Product Operator (MPO) method. The table highlights the average performance across all GLUE tasks and also provides a breakdown of the performance on each individual task. The number of trainable parameters and inference parameters for each model is also included.
read the caption
Table 1: Comparison of performance on the GLUE benchmark (in percent). The terms '+SVD' and '+OPDF' represent the use of different over-parameterization methods in a KD model. '# Train Params' and '# Inference Params' refer to the total number of parameters during training and inference, respectively. Numbers marked with * indicate tasks not tested in the original studies; results here are reproduced from the published code. The best result for each task is highlight in bold. For all the results, we report the mean values of five runs using different random seeds.
In-depth insights#
Overparameterization via MPO#
The heading ‘Overparameterization via MPO’ suggests a method to enhance the performance of student models in knowledge distillation by increasing their parameter count using Matrix Product Operators (MPO). MPO’s ability to efficiently decompose large matrices into a product of smaller tensors allows for a significant increase in the effective number of parameters without a corresponding increase in computational cost during inference. This overparameterization technique is crucial because it allows the student model to better approximate the teacher model’s behavior during training and improve generalization. The use of MPO is particularly interesting as it enables a nearly lossless decomposition, preserving the important information contained in the original matrix, thereby mitigating potential issues of information loss often associated with traditional tensor decomposition methods. This approach is further enhanced by incorporating high-order tensor alignment losses to ensure the consistency between student and teacher model parameters. Overall, this strategy represents a significant advancement in knowledge distillation as it leverages overparameterization to improve the student model’s performance without sacrificing efficiency or increasing inference latency.
Tensor Alignment Loss#
A tensor alignment loss function is crucial for effective knowledge distillation when employing tensor decomposition techniques like the Matrix Product Operator (MPO). The core idea is to minimize the discrepancies between corresponding high-dimensional tensors in the teacher and student models. This ensures that the over-parameterized student model, decomposed into multiple tensors, accurately captures the intricate relationships learned by the teacher model. By aligning the auxiliary tensors, the loss function not only facilitates effective knowledge transfer but also preserves the student model’s ability to learn independently. Standard distillation methods often fall short due to the capacity gap; the alignment loss directly addresses this by promoting consistency between teacher and student representations at a more granular, tensor level. This leads to significantly improved performance, even surpassing the teacher model in some cases, and promotes better generalization. The selection of the appropriate loss function (e.g., Mean Squared Error) and the careful design of the alignment strategy are critical for optimal performance. Moreover, minimizing information loss during the decomposition process is essential, thereby enhancing the accuracy and efficiency of the knowledge transfer.
OPDF: KD Framework#
The OPDF framework, a novel knowledge distillation (KD) approach, is designed to enhance KD’s effectiveness by over-parameterizing student models during training. This is achieved via matrix product operator (MPO) decomposition, which efficiently factorizes parameter matrices into higher-dimensional tensors, effectively increasing parameters without impacting inference latency. MPO’s near-lossless decomposition minimizes information loss during the process. Further enhancing performance, the framework introduces a tensor constraint loss, aligning high-dimensional tensors between student and teacher models to improve knowledge transfer. This results in significant performance gains across diverse KD tasks in both computer vision and natural language processing, enabling student models to achieve performance comparable to, or even exceeding, their larger teacher counterparts. The framework’s modular design allows seamless integration with various existing KD methods, showcasing its broad applicability and generalizability.
Performance Enhancements#
Analyzing performance enhancements in a research paper requires a multifaceted approach. We need to understand the baseline performance, against which improvements are measured. The paper should clearly define metrics to quantify these enhancements, perhaps using established benchmarks or creating novel metrics. The magnitude of the improvement needs to be contextualized within the specific task or domain. Statistical significance is crucial; are enhancements reliably reproduced across multiple runs, or are they due to chance? Any limitations impacting generalizability or robustness should be explicitly addressed. A detailed analysis may explore factors influencing the enhancements, such as the algorithm itself, its hyperparameters, or the data used. Finally, the practical implications of the reported enhancements should be discussed in relation to the broader research field. Are the improvements substantial enough to justify further investigation or real-world applications?
Future Work & Limits#
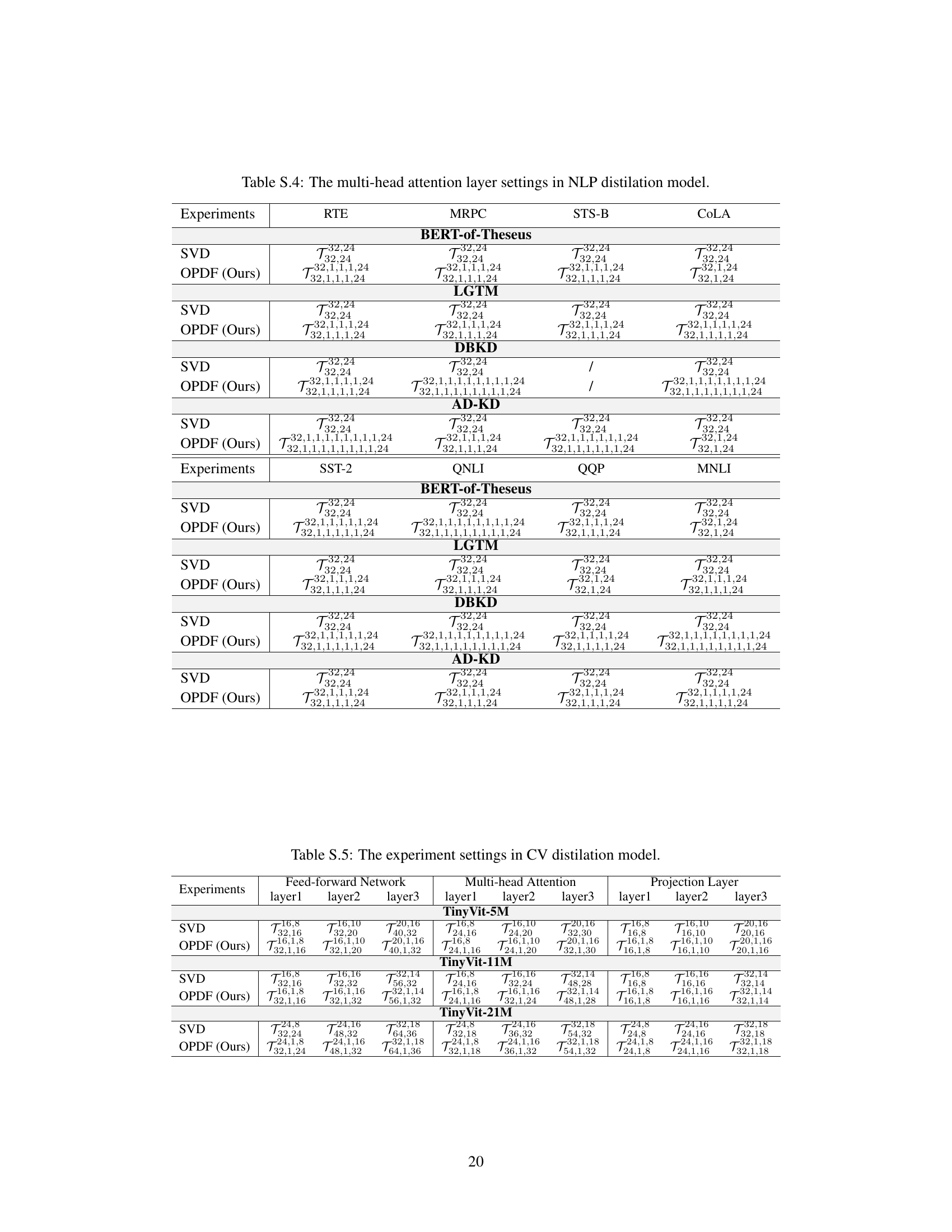
Future research directions could explore applying the over-parameterization distillation framework (OPDF) to other important backbones like multimodal learning models and investigating more efficient tensor decomposition methods. A key limitation is the sensitivity of the approach to learning rate, especially as the parameter scale increases. Further research is needed to understand and mitigate this sensitivity, perhaps by developing adaptive learning rate schemes or alternative optimization strategies. The current work focuses on specific distillation methods; future work could assess OPDF’s compatibility and effectiveness across a broader range of distillation techniques and model architectures. Finally, a thorough analysis of the computational cost trade-offs of OPDF across diverse hardware and model scales is necessary to establish its practical utility.
More visual insights#
More on tables
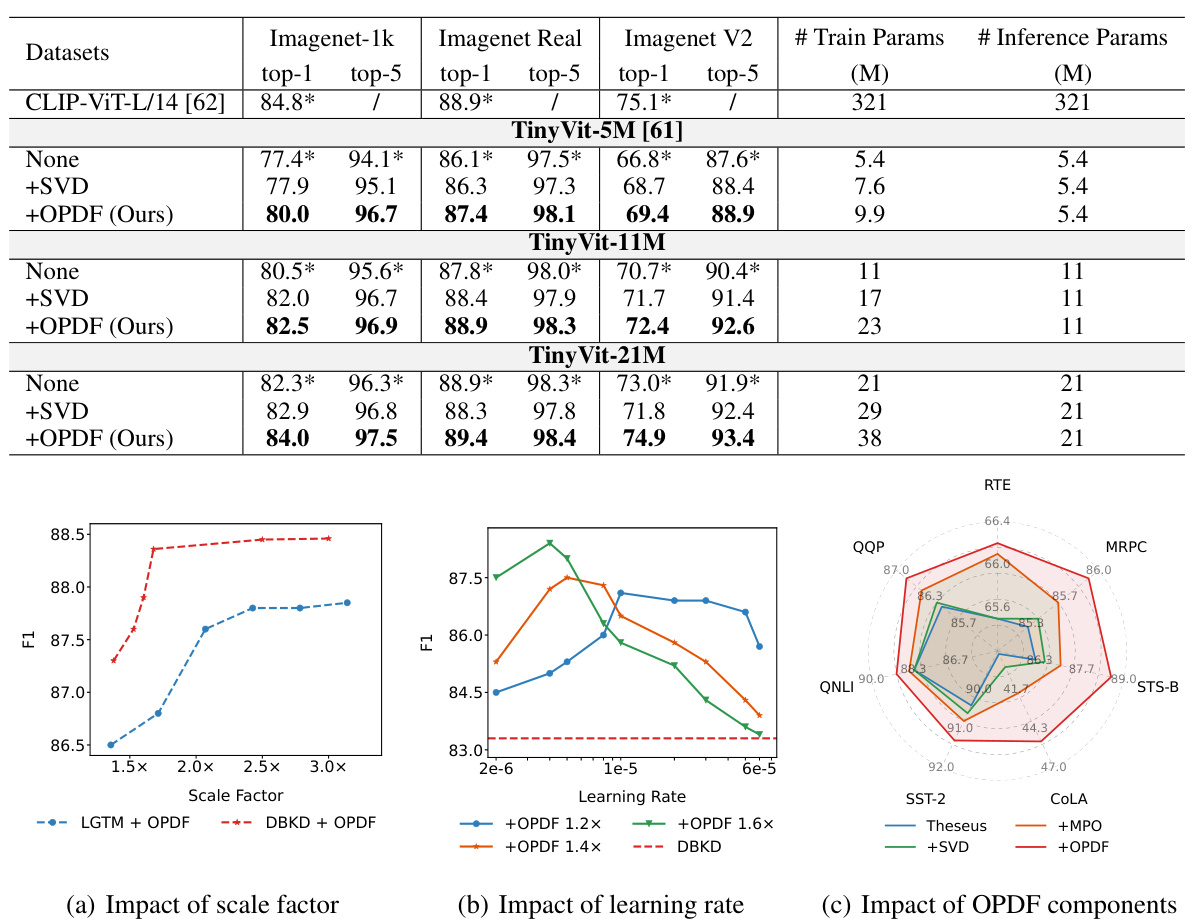
🔼 This table compares the performance of different knowledge distillation (KD) methods on the GLUE benchmark. It shows the impact of adding Singular Value Decomposition (SVD) and the proposed Over-Parameterized Distillation Framework (OPDF) to several baseline KD methods. The table presents accuracy and F1 scores for various tasks, along with the number of parameters used during training and inference. The best performing method for each task is highlighted.
read the caption
Table 1: Comparison of performance on the GLUE benchmark (in percent). The terms '+SVD' and '+OPDF' represent the use of different over-parameterization methods in a KD model. '# Train Params' and '# Inference Params' refer to the total number of parameters during training and inference, respectively. Numbers marked with * indicate tasks not tested in the original studies; results here are reproduced from the published code. The best result for each task is highlight in bold. For all the results, we report the mean values of five runs using different random seeds.
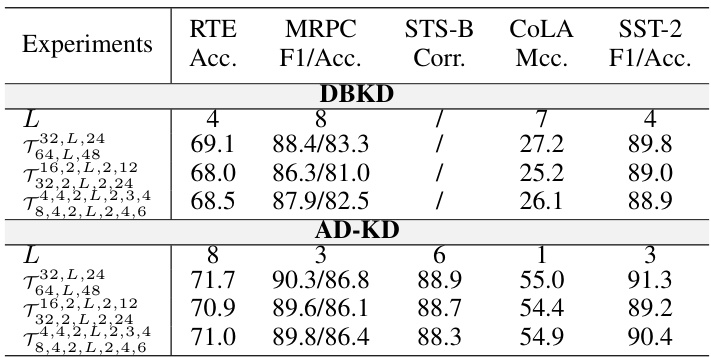
🔼 This table presents a comparison of the performance of different knowledge distillation (KD) methods on the GLUE benchmark. It shows the results for baseline KD methods (BERT-of-Theseus, LGTM, DBKD, and AD-KD), as well as those same methods enhanced by the addition of SVD and OPDF over-parameterization techniques. The table reports the accuracy, F1-score, or correlation coefficient for each task in the GLUE benchmark, and also notes the number of training and inference parameters for each model. The best result for each task is highlighted in bold.
read the caption
Table 1: Comparison of performance on the GLUE benchmark (in percent). The terms '+SVD' and '+OPDF' represent the use of different over-parameterization methods in a KD model. '# Train Params' and '# Inference Params' refer to the total number of parameters during training and inference, respectively. Numbers marked with * indicate tasks not tested in the original studies; results here are reproduced from the published code. For all the results, we report the mean values of five runs using different random seeds.

🔼 This table presents a comparison of the performance of different knowledge distillation (KD) models on the GLUE benchmark. It compares baseline KD methods (BERT-of-Theseus, LGTM, DBKD, AD-KD) against versions of these methods that incorporate either SVD or the proposed OPDF (Over-Parameterization Distillation Framework) over-parameterization technique. The table shows accuracy, F1 scores, and correlation coefficients for various sub-tasks within GLUE, along with the number of parameters used during training and inference for each model. The results highlight the performance improvements achieved by integrating the OPDF method with existing KD techniques.
read the caption
Table 1: Comparison of performance on the GLUE benchmark (in percent). The terms '+SVD' and '+OPDF' represent the use of different over-parameterization methods in a KD model. '# Train Params' and '# Inference Params' refer to the total number of parameters during training and inference, respectively. Numbers marked with * indicate tasks not tested in the original studies; results here are reproduced from the published code. The best result for each task is highlight in bold. For all the results, we report the mean values of five runs using different random seeds.

🔼 This table compares the performance of different knowledge distillation (KD) methods on the GLUE benchmark. It shows the impact of two over-parameterization techniques (+SVD and +OPDF) on various baseline KD models (BERT-of-Theseus, LGTM, DBKD, and AD-KD). The table presents accuracy, F1 scores, and correlation coefficients for multiple downstream tasks (RTE, MRPC, STS-B, COLA, SST-2, QNLI, QQP, and MNLI). The number of trainable parameters and inference parameters for each model are also included, highlighting the efficiency of the proposed OPDF method.
read the caption
Table 1: Comparison of performance on the GLUE benchmark (in percent). The terms '+SVD' and '+OPDF' represent the use of different over-parameterization methods in a KD model. '# Train Params' and '# Inference Params' refer to the total number of parameters during training and inference, respectively. Numbers marked with * indicate tasks not tested in the original studies; results here are reproduced from the published code. For all the results, we report the mean values of five runs using different random seeds.

🔼 This table compares the performance of various knowledge distillation (KD) methods on the GLUE benchmark. It shows the performance of baseline models (BERT-of-Theseus, LGTM, DBKD, AD-KD) and the improvement achieved when using either SVD or the proposed OPDF method for over-parameterization of the student model. The table reports accuracy and F1 scores for different GLUE tasks, along with the number of trainable and inference parameters for each configuration. The results highlight the improved performance when using OPDF for over-parameterization, particularly exceeding the performance of the teacher model in some cases.
read the caption
Table 1: Comparison of performance on the GLUE benchmark (in percent). The terms '+SVD' and '+OPDF' represent the use of different over-parameterization methods in a KD model. '# Train Params' and '# Inference Params' refer to the total number of parameters during training and inference, respectively. Numbers marked with * indicate tasks not tested in the original studies; results here are reproduced from the published code. For all the results, we report the mean values of five runs using different random seeds.

🔼 This table compares the performance of different knowledge distillation (KD) methods on the GLUE benchmark. It shows the impact of integrating over-parameterization techniques (+SVD and +OPDF) with various baseline KD methods. The table reports accuracy (or F1 score) on different GLUE tasks, the number of parameters used during training and inference, and highlights the best performing method for each task. The results represent the average of five runs.
read the caption
Table 1: Comparison of performance on the GLUE benchmark (in percent). The terms '+SVD' and '+OPDF' represent the use of different over-parameterization methods in a KD model. '# Train Params' and '# Inference Params' refer to the total number of parameters during training and inference, respectively. Numbers marked with * indicate tasks not tested in the original studies; results here are reproduced from the published code. The best result for each task is highlight in bold. For all the results, we report the mean values of five runs using different random seeds.
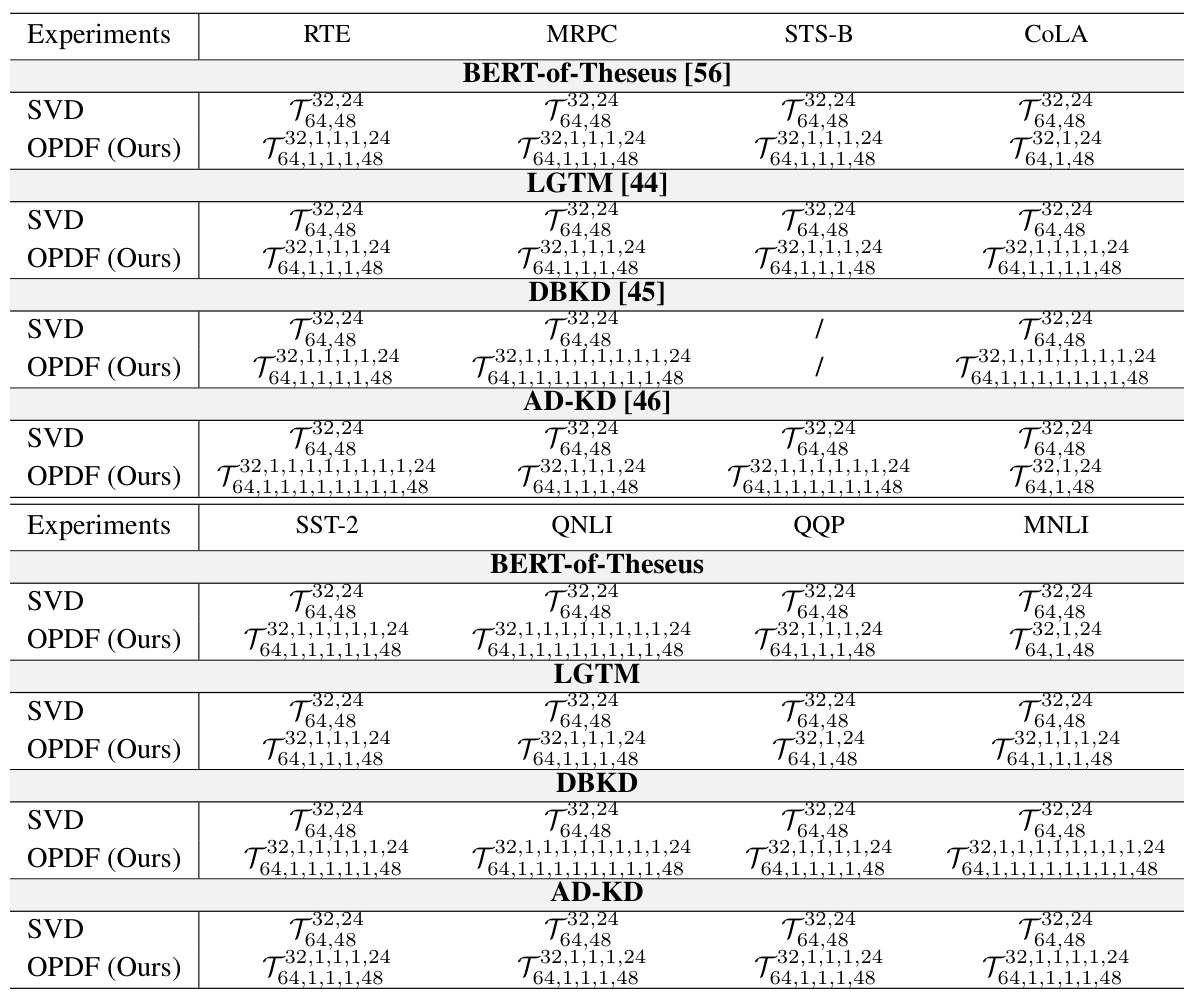
🔼 This table compares the performance of different knowledge distillation (KD) methods on the GLUE benchmark. It shows the impact of adding SVD and OPDF (the proposed over-parameterization method) to various existing KD approaches (BERT-of-Theseus, LGTM, DBKD, AD-KD). The table includes accuracy, F1 score, and Matthews Correlation Coefficient for various tasks, along with the number of parameters during training and inference. The bold values represent the best performance for each task.
read the caption
Table 1: Comparison of performance on the GLUE benchmark (in percent). The terms '+SVD' and '+OPDF' represent the use of different over-parameterization methods in a KD model. '\# Train Params' and '\# Inference Params' refer to the total number of parameters during training and inference, respectively. Numbers marked with * indicate tasks not tested in the original studies; results here are reproduced from the published code. The best result for each task is highlight in bold. For all the results, we report the mean values of five runs using different random seeds.

🔼 This table compares the performance of different knowledge distillation (KD) models on the GLUE benchmark. It shows the impact of two over-parameterization methods (+SVD and +OPDF) on various baseline KD models (BERT-of-Theseus, LGTM, DBKD, AD-KD). The table includes the accuracy and F1 scores for each task, the number of trainable parameters during training and inference, and highlights the best-performing model for each task. The results are averaged over five runs with different random seeds.
read the caption
Table 1: Comparison of performance on the GLUE benchmark (in percent). The terms '+SVD' and '+OPDF' represent the use of different over-parameterization methods in a KD model. '# Train Params' and '# Inference Params' refer to the total number of parameters during training and inference, respectively. Numbers marked with * indicate tasks not tested in the original studies; results here are reproduced from the published code. The best result for each task is highlight in bold. For all the results, we report the mean values of five runs using different random seeds.

🔼 This table compares the performance of different knowledge distillation (KD) models on the GLUE benchmark. It shows the impact of two over-parameterization methods (+SVD and +OPDF) on the performance of several KD methods (BERT-of-Theseus, LGTM, DBKD, AD-KD). The table includes the accuracy and F1 scores for each task, the number of parameters during training and inference, and highlights the best performance achieved for each task. The results are averaged over five runs with different random seeds.
read the caption
Table 1: Comparison of performance on the GLUE benchmark (in percent). The terms '+SVD' and '+OPDF' represent the use of different over-parameterization methods in a KD model. '# Train Params' and '# Inference Params' refer to the total number of parameters during training and inference, respectively. Numbers marked with * indicate tasks not tested in the original studies; results here are reproduced from the published code. The best result for each task is highlight in bold. For all the results, we report the mean values of five runs using different random seeds.
Full paper#