TL;DR#
Current methods for object pose estimation struggle with generalizability, either requiring extensive instance-level training or being limited to predefined categories. This severely restricts their practical applicability in real-world scenarios such as robotic manipulation, where robots frequently encounter unseen objects. The high cost of collecting and labeling real-world data also poses a significant challenge.
The proposed VFM-6D framework tackles these limitations by adopting a two-stage approach, combining object viewpoint and coordinate map estimation using pre-trained vision-language models. This approach is enhanced with novel feature lifting and shape-matching modules, and effectively trained using cost-effective synthetic data. VFM-6D demonstrates significantly improved generalization capability in various real-world scenarios, surpassing existing methods on benchmark datasets. Its effectiveness in both instance-level and category-level scenarios shows its wide applicability.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in robotics and computer vision due to its novel approach to generalizable object pose estimation. It addresses a major limitation of current methods by leveraging existing vision-language models to achieve accurate pose estimation for unseen object categories. This opens new avenues for research in open-world robotic manipulation and interaction, pushing the boundaries of AI systems’ ability to handle unfamiliar objects. The use of cost-effective synthetic data for training offers a practical and scalable solution that is particularly relevant to the resource constraints faced by many research groups. The proposed method also shows promising results in both instance-level and category-level scenarios, making it highly versatile and widely applicable.
Visual Insights#

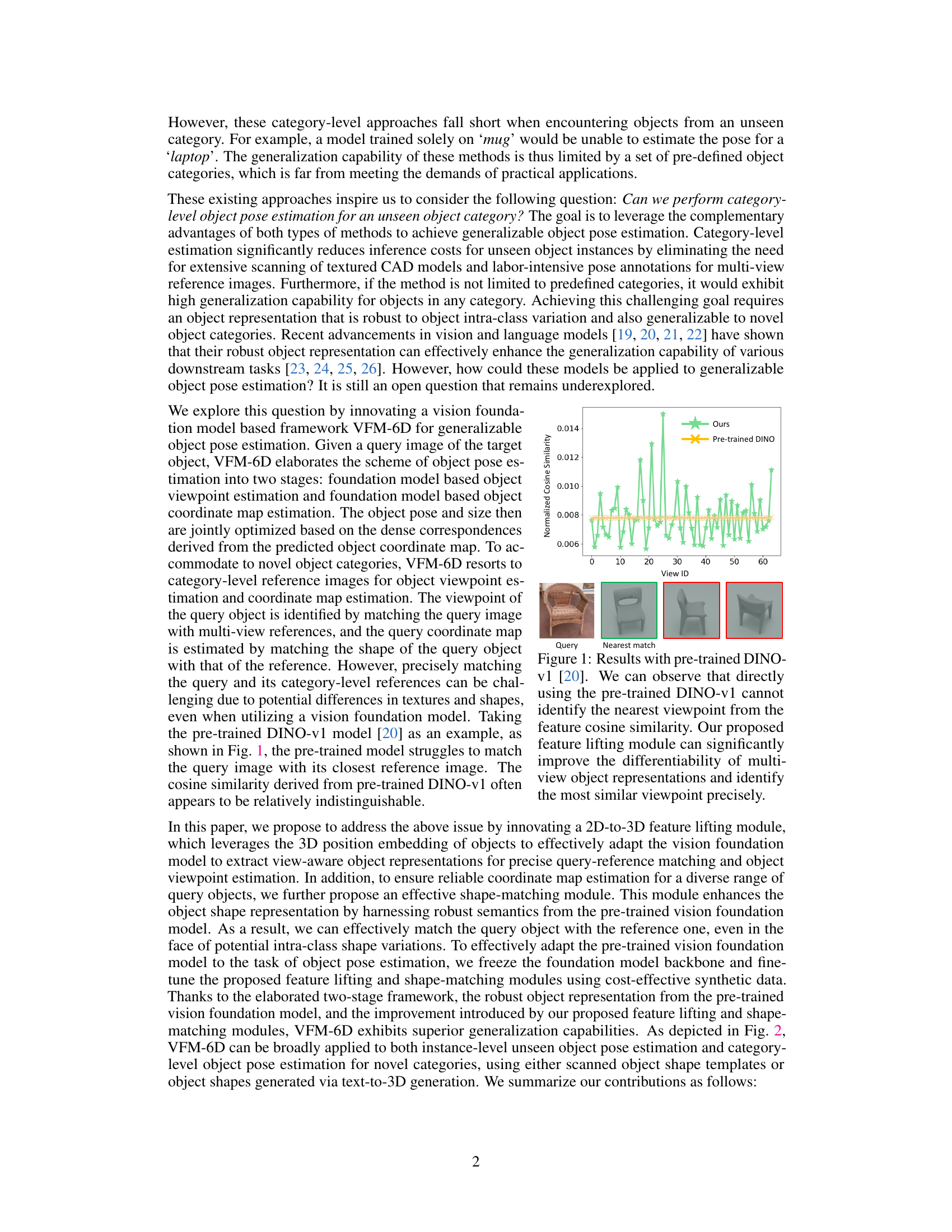
🔼 The figure shows a graph comparing the cosine similarity scores obtained using the pre-trained DINO-v1 model and the proposed method (VFM-6D) for identifying the nearest viewpoint among multiple views of an object. The graph illustrates that the pre-trained DINO-v1 model has difficulty distinguishing between viewpoints, while the proposed method significantly improves the differentiability, enabling accurate viewpoint identification.
read the caption
Figure 1: Results with pre-trained DINO-v1 [20]. We can observe that directly using the pre-trained DINO-v1 cannot identify the nearest viewpoint from the feature cosine similarity. Our proposed feature lifting module can significantly improve the differentiability of multi-view object representations and identify the most similar viewpoint precisely.
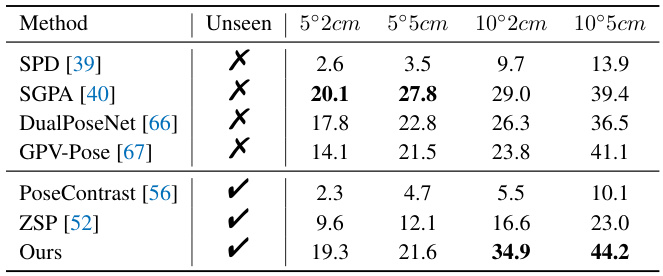
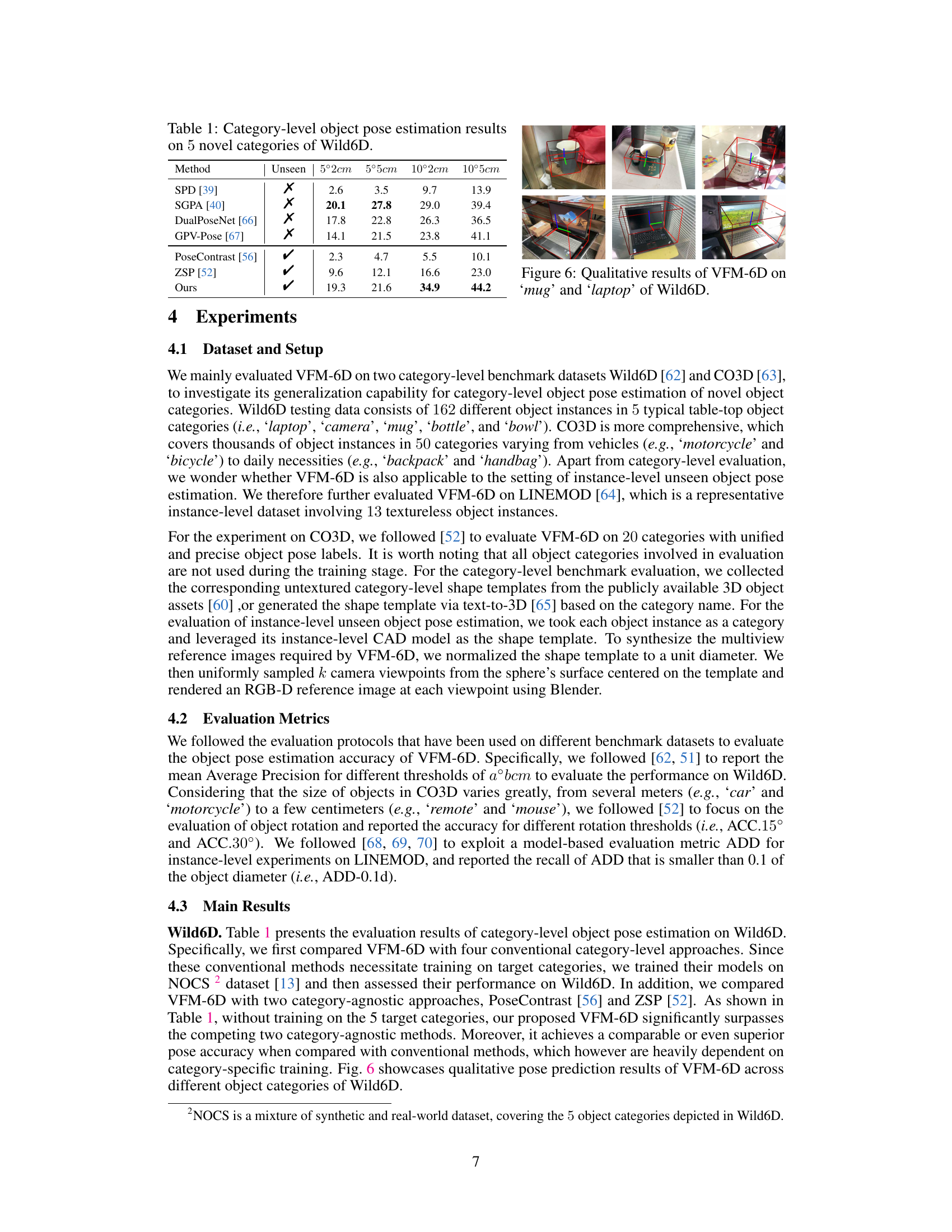
🔼 This table presents the results of category-level object pose estimation on 5 unseen object categories from the Wild6D dataset. It compares the proposed VFM-6D method with several existing methods (SPD, SGPA, DualPoseNet, GPV-Pose, PoseContrast, and ZSP), showing the average precision (AP) for different pose error thresholds (2cm, 5cm). The ‘Unseen’ column indicates whether the method was specifically trained on these categories or not.
read the caption
Table 1: Category-level object pose estimation results on 5 novel categories of Wild6D.
In-depth insights#
VFM-6D Framework#
The VFM-6D framework is a two-stage approach for generalizable object pose estimation, addressing the limitations of existing methods that rely on instance-level training or are confined to predefined categories. The first stage focuses on category-level object viewpoint estimation, leveraging pre-trained vision foundation models to improve object representation and matching accuracy. A novel 2D-to-3D feature lifting module enhances view-aware object representations, enabling precise query-reference matching. The second stage estimates the object coordinate map, utilizing a shape-matching module that leverages robust semantics from the vision foundation model to ensure reliable estimation even with intra-class shape variations. The framework is trained on cost-effective synthetic data, demonstrating superior generalization capabilities for both instance-level unseen and category-level novel object pose estimation. This two-stage design, coupled with the innovative modules, allows VFM-6D to handle various real-world scenarios effectively, making it a significant contribution to the field. Its ability to leverage pre-trained models is particularly valuable, significantly reducing the need for extensive instance-level training data.
Foundation Models#
Foundation models represent a paradigm shift in AI, enabling significant advancements across various downstream tasks by leveraging pre-trained, large-scale models. Their robust object representation capabilities prove particularly valuable in applications like object pose estimation. However, directly employing these models often presents challenges due to their inherent design focusing on broader semantic understanding, rather than the specific nuances of geometric tasks. Therefore, effective integration requires innovative adaptation strategies. For instance, techniques like feature lifting and shape-matching modules can enhance the discriminative power of foundation model features to address the limitations of standard image-based matching techniques. This is crucial for handling real-world complexities like shape variations and occlusion, demonstrating the power of combining foundation models with task-specific modules to achieve robust generalization.
Synthetic Data#
The utilization of synthetic data is a crucial aspect of this research, offering several key advantages. It addresses the limitations of real-world data acquisition, which can be costly, time-consuming, and difficult to obtain in sufficient quantities, particularly for complex scenarios like object pose estimation. Synthetic datasets provide greater control and flexibility, allowing researchers to generate data with specific characteristics and under controlled conditions, thus ensuring data variety and avoiding biases. This approach also mitigates the problem of data scarcity, which is particularly relevant for niche object categories. The use of synthetic data for training allows researchers to leverage powerful foundation models while reducing the reliance on extensive and expensive real-world data collection. However, a critical consideration is the extent to which the synthetic data accurately represents the real world. If there is a significant difference, the model’s generalization to real-world scenarios could be hindered. Therefore, ensuring the fidelity and realism of the synthetic data is vital for the success of this method. The paper’s approach to utilizing cost-effective synthetic data represents a significant contribution in addressing the challenges associated with generalizable object pose estimation.
Generalization#
The concept of generalization in machine learning is crucial for creating robust and reliable models that can adapt to unseen data. Generalization ability refers to a model’s capacity to perform well on data it has not encountered during training. In the context of a research paper, a discussion of generalization would delve into the techniques used to enhance this capacity. This might involve analyzing the model’s architecture, the training data used, and the methods employed for evaluating performance on unseen data. A key aspect would be identifying and mitigating factors that hinder generalization, such as overfitting (where the model performs well on training data but poorly on new data) or underfitting (where the model is too simple to capture the underlying patterns in the data). Regularization techniques, such as dropout or weight decay, might be examined for their effectiveness in improving generalization. Furthermore, the paper likely explores the trade-off between model complexity and generalization performance; more complex models might be more prone to overfitting, while simpler models might struggle to capture nuanced patterns. Ultimately, a thorough analysis of generalization would aim to provide insights into developing models that are not only accurate but also robust and widely applicable.
Future Work#
The ‘Future Work’ section of a research paper on generalizable object pose estimation using vision foundation models would naturally focus on extending the model’s capabilities to handle more challenging scenarios. This could involve improving robustness to occlusion, a prevalent issue in real-world settings. Further research could explore more efficient training methods, perhaps leveraging self-supervised learning or transfer learning techniques to reduce reliance on large synthetic datasets. Integration with other AI modalities such as language models or tactile sensors is also a key area for future work, allowing for richer object understanding and more nuanced robot manipulation. Finally, evaluating performance on a broader range of real-world datasets and tasks is crucial for demonstrating the true generalizability and practical applicability of the proposed approach. Addressing the limitations of relying solely on synthetic data is essential, as real-world conditions are far more complex and varied. The research could explore techniques for incorporating real-world data more effectively, potentially through domain adaptation or semi-supervised learning strategies.
More visual insights#
More on figures
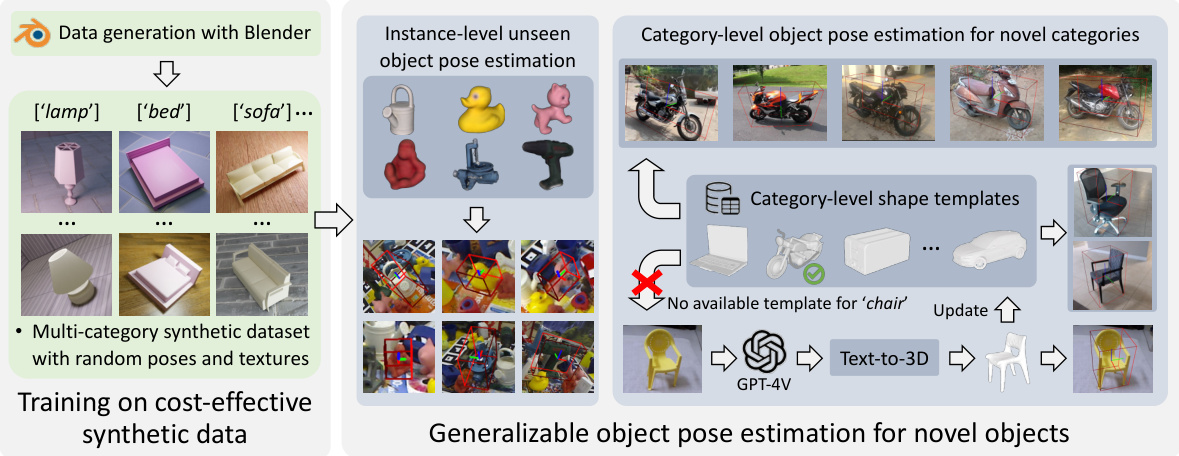
🔼 This figure illustrates the generalizability of the proposed VFM-6D model. It shows that after training on synthetic data, the model can successfully perform both instance-level unseen object pose estimation (estimating the pose of objects not seen during training) and category-level object pose estimation for novel categories (estimating the pose of objects belonging to categories not seen during training). The left side demonstrates the process of generating cost-effective synthetic training data with Blender, showing examples of objects and their varied poses and textures. The right side depicts the application of the trained model to both instance-level and category-level tasks, highlighting its ability to handle unseen objects and categories, including situations where text-to-3D generation is needed to supplement the training dataset.
read the caption
Figure 2: Our proposed VFM-6D is highly generalizable. After training on cost-effective synthetic data, it can be widely applied to instance-level unseen object pose estimation and category-level object pose estimation for novel categories.

🔼 This figure provides a detailed overview of the VFM-6D framework’s two-stage approach to object pose estimation. The first stage focuses on object viewpoint estimation using a pre-trained vision foundation model, 2D image features, 3D position embedding, and a 2D-to-3D feature lifting module. The second stage involves object coordinate map estimation using object shape focalization, foundation feature-based object shape representation, and query-reference object shape matching. Both stages ultimately contribute to pose and size optimization, leveraging both RGB-D query and reference images and point clouds for comprehensive analysis.
read the caption
Figure 3: An overview of the proposed VFM-6D framework for generalizable object pose estimation.

🔼 This figure illustrates the 2D-to-3D feature lifting module used in the VFM-6D framework for object viewpoint estimation. It enhances the discriminative capacity of the vision foundation model by lifting the object representation from 2D image features to 3D, using 3D positional information from object point clouds. The process involves encoding the 3D object position with an MLP, then integrating that embedding with the pre-trained 2D image features via a Transformer encoder block, resulting in a lifted feature representation that’s more sensitive to viewpoint changes.
read the caption
Figure 4: 2D-to-3D foundation feature lifting for view-aware object representation.

🔼 This figure illustrates the foundation feature-based object shape representation module used in VFM-6D. It shows how the pre-trained vision foundation model’s features are combined with point cloud information to create a robust object shape representation, which is used for shape matching and NOCS coordinate map estimation. The process involves focalizing the point clouds to a canonical coordinate space, using a point cloud transformer to extract shape features, integrating these features with pre-trained image features via a transformer encoder block, and finally generating the enhanced object shape representation.
read the caption
Figure 5: Foundation feature-based object shape representation.

🔼 This figure shows qualitative results of the proposed VFM-6D model on the Wild6D dataset for the object categories ‘mug’ and ’laptop’. The images depict successful object pose estimation, with the estimated 3D bounding boxes accurately aligned with the corresponding objects in the images. This illustrates the model’s ability to accurately estimate the pose of objects in real-world scenarios.
read the caption
Figure 6: Qualitative results of VFM-6D on 'mug' and 'laptop' of Wild6D.

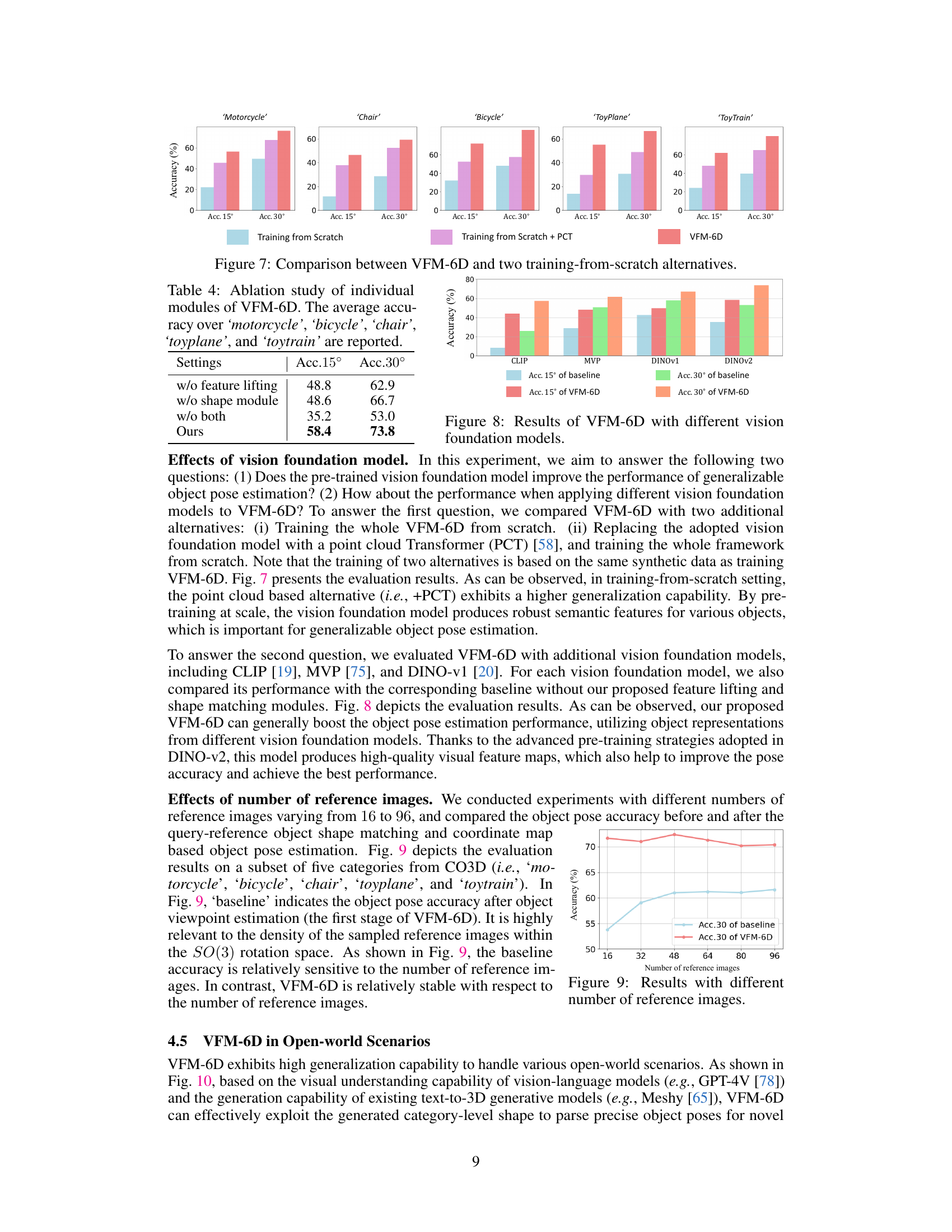
🔼 This figure compares the performance of VFM-6D against two training-from-scratch baselines on five object categories from the CO3D dataset. The first baseline trains the entire VFM-6D model from scratch. The second baseline uses a point cloud transformer (PCT) for the first stage, again training from scratch. The bar chart displays the accuracy (Acc. 15° and Acc. 30°) for each approach, highlighting the superior performance of the pre-trained VFM-6D model.
read the caption
Figure 7: Comparison between VFM-6D and two training-from-scratch alternatives.

🔼 This figure compares the performance of VFM-6D when using different vision foundation models (CLIP, MVP, DINO-v1, and DINO-v2). It shows the accuracy (Acc. 15° and Acc. 30°) for both the baseline approach (without the proposed feature lifting and shape matching modules) and VFM-6D. The results demonstrate that VFM-6D consistently improves the accuracy regardless of the underlying vision foundation model, highlighting its effectiveness.
read the caption
Figure 8: Results of VFM-6D with different vision foundation models.

🔼 The figure shows the impact of the number of reference images on the accuracy of object pose estimation. The blue line represents the baseline accuracy (Acc.30), while the red line represents the accuracy achieved by VFM-6D (Acc.30). The baseline’s accuracy is heavily affected by the number of reference images, showing higher accuracy with a greater number of reference images, while VFM-6D is more robust to variations in the number of images. This indicates that the shape matching module in VFM-6D effectively improves the accuracy and reliability of pose estimation, even when the density of the reference images is not extremely high.
read the caption
Figure 9: Results with different number of reference images.
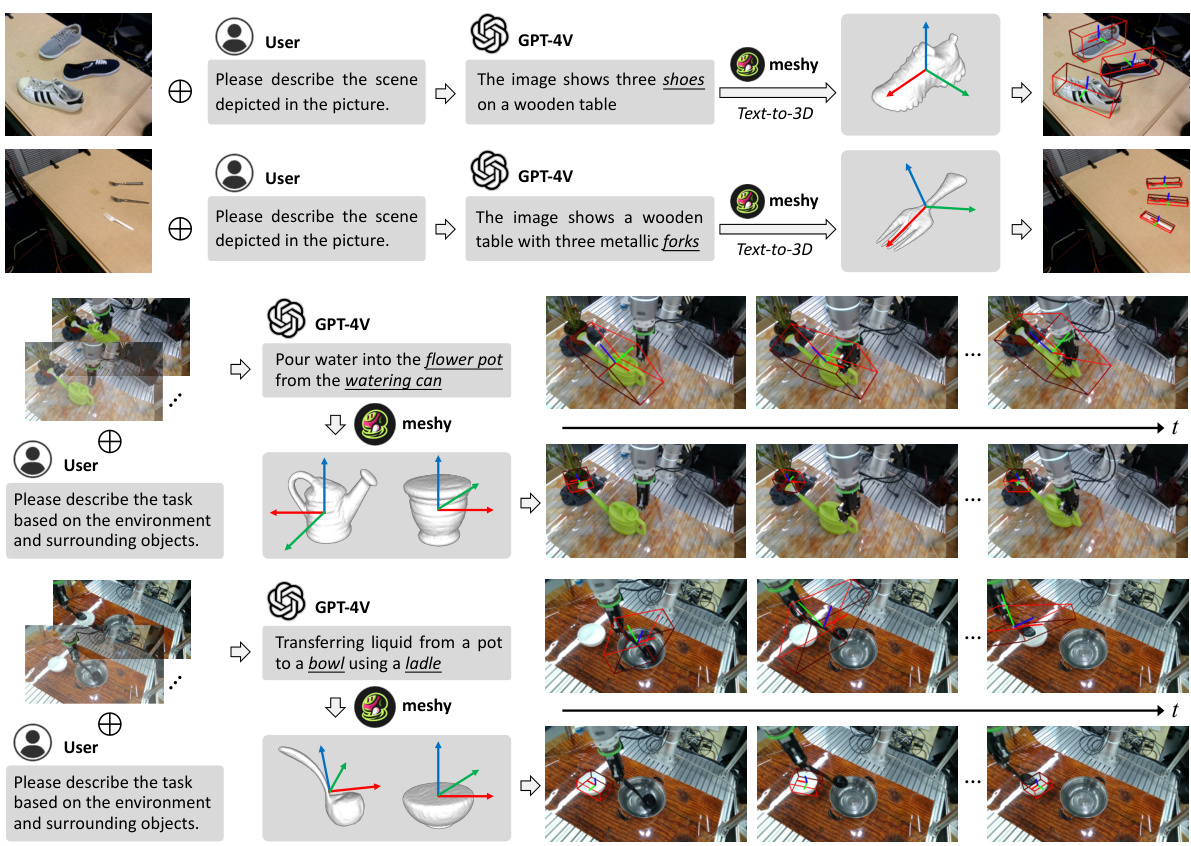
🔼 This figure demonstrates the generalizability of the proposed VFM-6D framework by showing its application in two different real-world scenarios: D³Fields and RH20T. In D³Fields, VFM-6D successfully predicts the poses of various objects, including shoes and forks, based on natural language descriptions. In RH20T, VFM-6D handles sequential poses from a robotic manipulation video, showcasing its applicability to dynamic situations and demonstrating its ability to predict object poses in complex and variable conditions. This highlights the versatility and robustness of VFM-6D in handling diverse real-world scenarios.
read the caption
Figure 10: VFM-6D application in scenarios from D³Fields (top) [76] and RH20T (bottom) [77].

🔼 This figure shows 20 object categories used to create synthetic data for training the VFM-6D model. Each category has example images of different instances of the object, showcasing variations in pose and texture. This variety in the synthetic data helps the model generalize better to real-world scenarios.
read the caption
Figure 11: 20 object categories used for generating the synthetic data and their example images.

🔼 This figure compares the object viewpoint estimation results of three different approaches: the proposed VFM-6D, VFM-6D without the feature lifting module, and a model trained from scratch with a Point Cloud Transformer. Each row shows a query image and its two nearest matching reference images, highlighting how the different methods perform in identifying the correct viewpoint.
read the caption
Figure 12: Comparative results for object viewpoint estimation. We present the top-2 reference images found by different approaches.(a) results w/o the proposed foundation feature lifting module. (b) results of training from scratch + PCT. (c) results of proposed VFM-6D.

🔼 This figure shows qualitative results of the VFM-6D model combined with Depth-Anything on the CO3D dataset. Each pair of images shows the predicted depth map (left) and the visualized predicted object pose (right) for various object categories in the dataset.
read the caption
Figure 15: Qualitative results of VFM-6D + Depth-anything model on the CO3D dataset. For each pair of results, the left image depicts the predicted depth map and the right image visualizes the predicted object pose.

🔼 This figure shows qualitative results of the VFM-6D model on the LINEMOD dataset. Each pair of images shows a reference image (left) that VFM-6D matched with a query image (right). The 3D bounding boxes overlaid on the query images illustrate the estimated object poses and orientations determined by VFM-6D.
read the caption
Figure 14: Qualitative results of VFM-6D on LINEMOD. For each object instance, the left image is the reference image found by VFM-6D. The right image is the corresponding query image, on which the object pose estimation results are overlayed.

🔼 This figure shows qualitative results on the CO3D dataset using VFM-6D with depth prediction from Depth Anything. Each pair of images shows the predicted depth map (left) and the visualized pose (right) for different object categories.
read the caption
Figure 15: Qualitative results of VFM-6D + Depth-anything model on the CO3D dataset. For each pair of results, the left image depicts the predicted depth map and the right image visualizes the predicted object pose.
More on tables

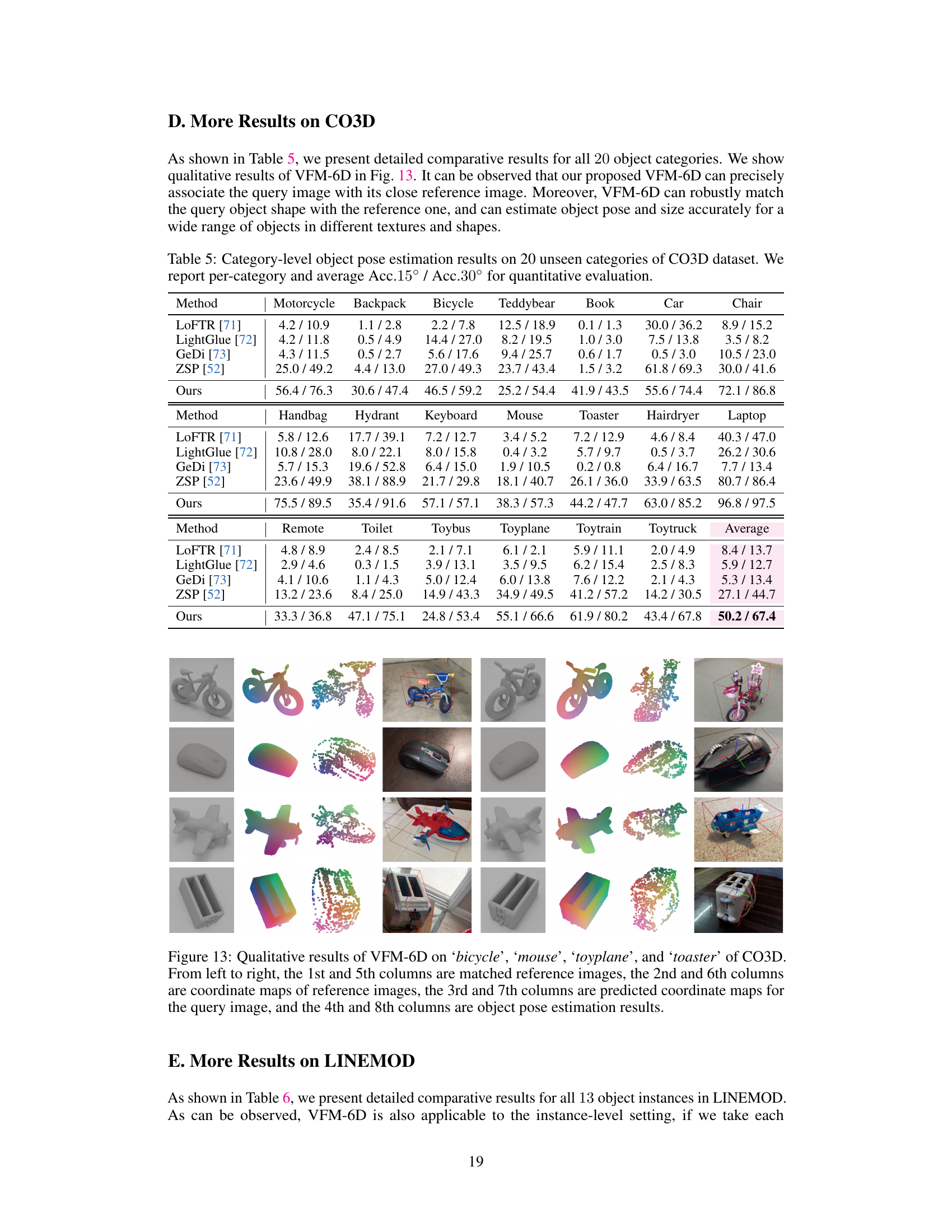
🔼 This table presents a comparison of category-level object pose estimation results on 20 unseen categories from the CO3D dataset. The methods compared include LOFTR, LightGlue, GeDi, ZSP, and the proposed VFM-6D method. The results are presented as the average accuracy for rotation thresholds of 15 and 30 degrees across all categories, with results for a subset of illustrative categories also provided. A more complete breakdown of per-category results is available in the appendix.
read the caption
Table 2: Category-level object pose estimation results on 20 unseen categories of CO3D dataset. We report Acc.15° / Acc.30° averaged across all 20 categories. We also report results for an illustrative subset of categories. Please refer to the appendix for full per-category results.

🔼 This table presents the results of instance-level object pose estimation using the ADD-0.1d metric on the LINEMOD dataset. The ADD-0.1d metric measures the average distance between the estimated and ground truth object poses, with a threshold of 0.1 times the object diameter. The table shows the average performance across all object instances in the dataset and also provides individual results for a selection of instances to illustrate the performance variability.
read the caption
Table 3: Instance-level object pose estimation results measured by ADD-0.1d on LINEMOD dataset. We report average score over all instances and per-instance score for an illustrative subset of instances. Please refer to the appendix for full per-instance results.
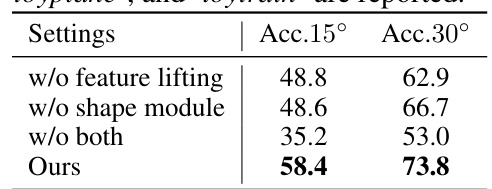
🔼 This table presents the ablation study results of individual modules within the VFM-6D framework. It shows the impact of removing either the feature lifting module, the shape module, or both on the overall accuracy (measured by Acc.15° and Acc.30°) for object pose estimation. The results demonstrate the significant contribution of both modules to the model’s performance.
read the caption
Table 4: Ablation study of individual modules of VFM-6D. The average accuracy over 'motorcycle', 'bicycle', 'chair', 'toyplane', and ‘toytrain' are reported.

🔼 This table presents a comparison of category-level object pose estimation results on 20 unseen object categories from the CO3D dataset using different methods. The accuracy is measured using two metrics (Acc.15° and Acc.30°), representing the percentage of poses estimated within 15 and 30 degrees of the ground truth, respectively. Results are shown for the average across all 20 categories and also a subset of illustrative categories. More detailed per-category results can be found in the appendix.
read the caption
Table 2: Category-level object pose estimation results on 20 unseen categories of CO3D dataset. We report Acc.15°/Acc.30° averaged across all 20 categories. We also report results for an illustrative subset of categories. Please refer to the appendix for full per-category results.
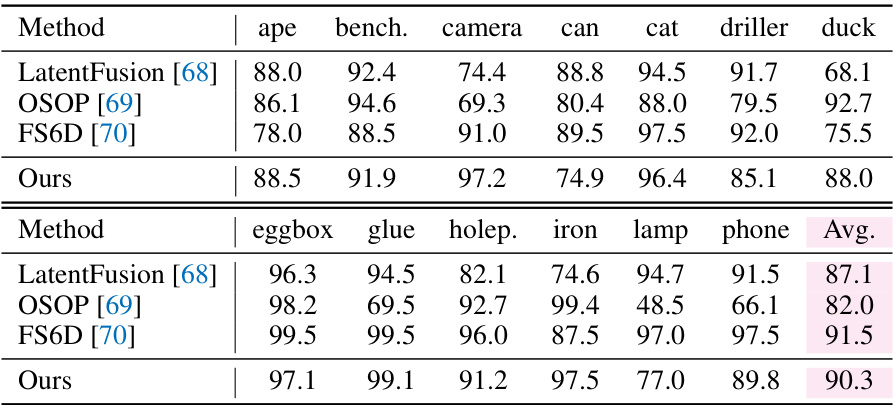
🔼 This table presents the results of instance-level object pose estimation using the ADD-0.1d metric on the LINEMOD dataset. It compares the proposed VFM-6D method against three other methods: LatentFusion, OSOP, and FS6D. The table shows the average ADD-0.1d score across all instances, as well as scores for a selection of individual instances. A more complete set of results is available in the appendix.
read the caption
Table 3: Instance-level object pose estimation results measured by ADD-0.1d on LINEMOD dataset. We report average score over all instances and per-instance score for an illustrative subset of instances. Please refer to the appendix for full per-instance results.

🔼 This table presents the results of object pose estimation experiments conducted on the LINEMOD and LINEMOD-Occlusion datasets. It shows the performance of the method (ADD-0.1d) under varying levels of occlusion: no occlusion, less than 30% occlusion, 30-60% occlusion, and greater than 60% occlusion. The table quantifies the impact of occlusion on the accuracy of the object pose estimation.
read the caption
Table 7: Object pose estimation results on LINEMOD and LINEMOD-Occlusion datasets.
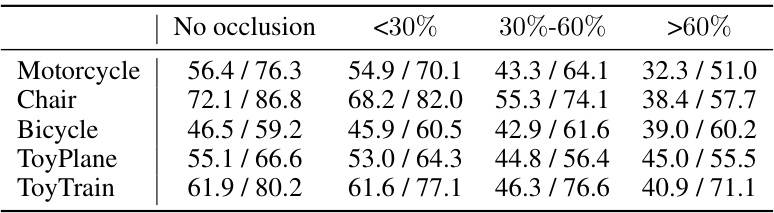
🔼 This table presents the results of object pose estimation on five categories from the CO3D dataset under different levels of occlusion. The results are presented as Accuracy (Acc.15°/Acc.30°), which represents the percentage of poses estimated with less than 15° and 30° angular error, respectively. Each category shows the results for ‘No occlusion’, ‘<30%’, ‘30%-60%’, and ‘>60%’ occlusion, indicating how the performance changes with increasing occlusion levels. This provides insights into the robustness of the proposed method under varying occlusion conditions.
read the caption
Table 8: Object pose estimation results on 5 representative object categories of the CO3D dataset.
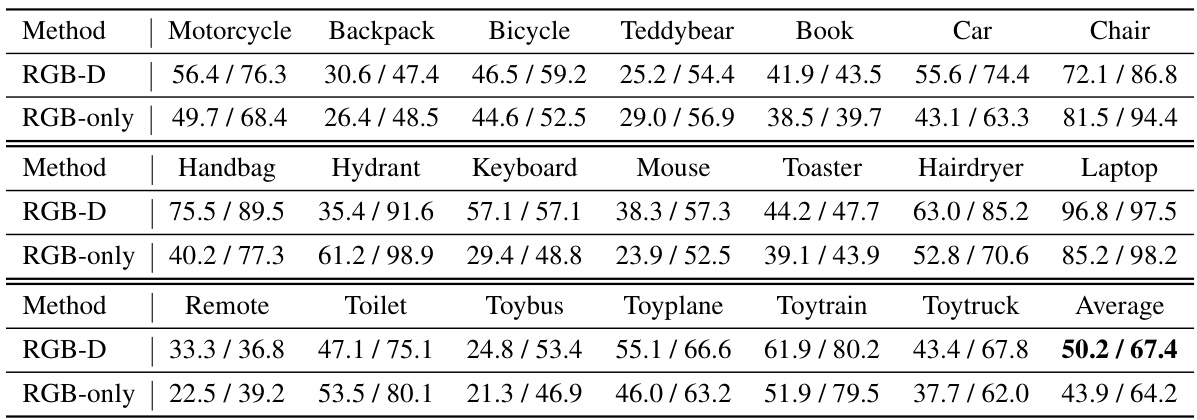
🔼 This table presents the results of category-level object pose estimation on five unseen categories from the Wild6D dataset. It compares the proposed VFM-6D method against several other methods (SPD, SGPA, DualPoseNet, GPV-Pose, PoseContrast, ZSP), showing the accuracy of pose estimation (measured in degrees and centimeters) at different levels of accuracy thresholds (5° and 10° for rotation error, 2cm and 5cm for translation error). The results demonstrate VFM-6D’s superior performance on unseen categories.
read the caption
Table 1: Category-level object pose estimation results on 5 novel categories of Wild6D.
Full paper#