↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Tiny Machine Learning (TinyML) faces challenges in deploying complex Convolutional Neural Networks (CNNs) on resource-constrained tiny AI accelerators due to limited memory. This often forces downsampling of input images, leading to accuracy loss. The existing hardware optimizations in these accelerators, while improving performance, also cause underutilization of processors and memory, especially in the initial layers.
The paper introduces Data Channel Extension (DEX), a novel approach addressing these issues. DEX leverages underutilized processors and memory to extend the input channels by incorporating additional spatial information. DEX utilizes a two-step process: patch-wise even sampling to capture diverse pixel information from the original image and channel-wise stacking to extend this information across channels. Experimental results on multiple models and datasets demonstrate that DEX improves average accuracy by 3.5 percentage points without increasing latency, showcasing its efficiency and practicality.
Key Takeaways#
Why does it matter?#
This paper is important because it addresses a critical limitation of tiny AI accelerators—their limited memory—which hinders the performance of CNNs. The proposed DEX method significantly improves accuracy without increasing latency, opening new avenues for efficient on-device AI applications and advancing the TinyML field. The practical approach and readily available source code enhance the accessibility and impact of this research for a broad range of researchers.
Visual Insights#

This figure shows a simplified architecture of the MAX78000 tiny AI accelerator. It highlights key components such as the pooling engine, caching, convolutional engine, and the 64 parallel processors. The dedicated data and weight memories for each processor are also shown. This architecture enables parallel processing of convolutional operations across multiple channels, which leads to significant performance gains compared to traditional MCUs.
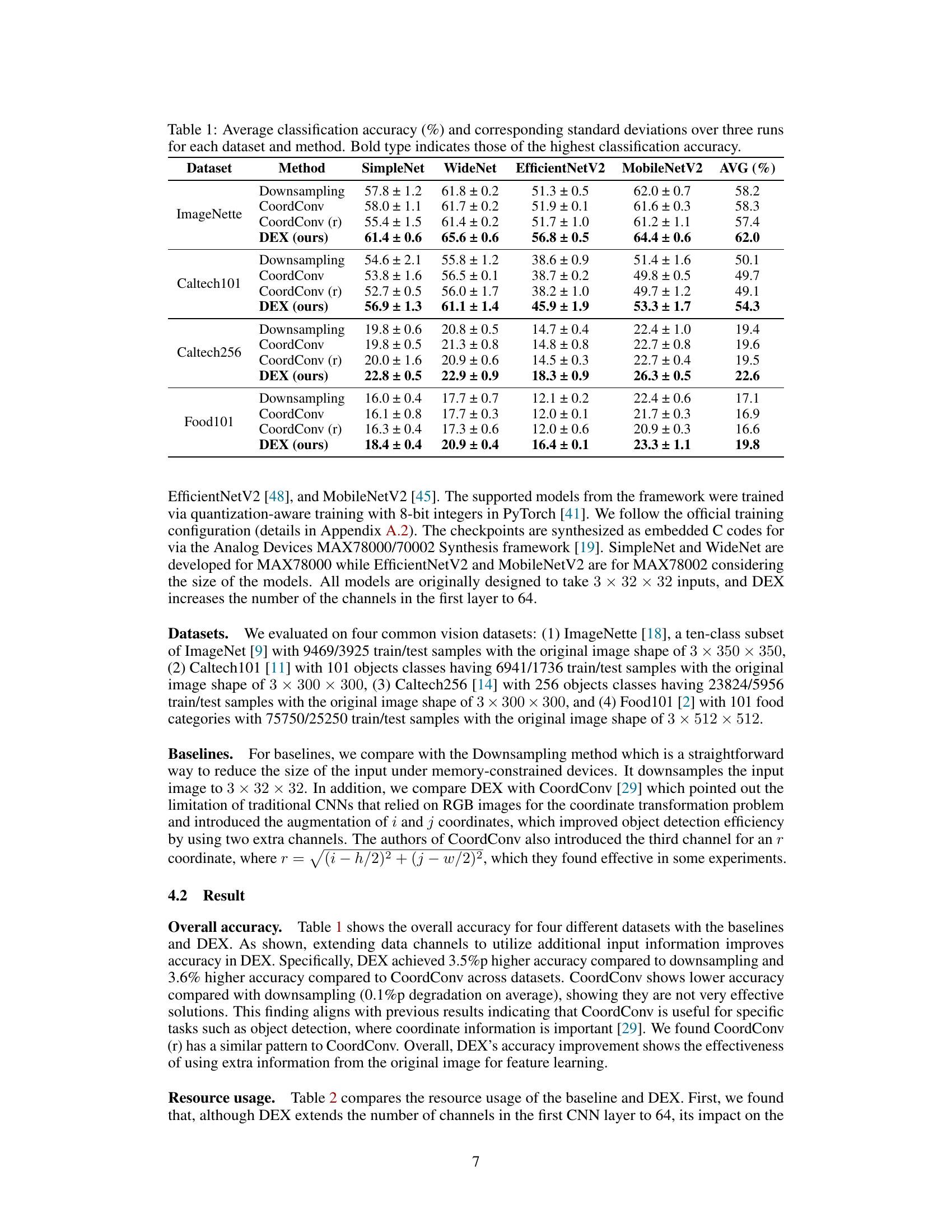
This table presents the average classification accuracy and standard deviations obtained from three independent runs for four different vision datasets (ImageNette, Caltech101, Caltech256, Food101) and four Convolutional Neural Networks (SimpleNet, WideNet, EfficientNetV2, MobileNetV2). Three methods are compared: downsampling, CoordConv, and the proposed DEX method. The bold values highlight the highest accuracy achieved for each dataset. The table summarizes the performance of different approaches in handling limited memory on tiny AI accelerators.
In-depth insights#
TinyML Acceleration#
TinyML, aiming to deploy machine learning on resource-constrained devices, significantly benefits from acceleration techniques. Hardware advancements, such as specialized AI accelerators, have dramatically improved processing power, enabling faster inference and reduced latency. However, limitations such as limited data memory often necessitate downsampling, leading to accuracy degradation. Software optimization strategies, like model compression and efficient algorithms, play a crucial role in maximizing performance within these memory constraints. The interplay between these hardware and software improvements is vital for achieving truly efficient TinyML systems. Further research should explore novel methods for effectively balancing memory usage and computational efficiency to unlock the full potential of TinyML acceleration.
DEX Methodology#
The core of the DEX methodology centers on augmenting input image data to improve CNN performance on tiny AI accelerators. It cleverly addresses the limitations of these accelerators, specifically their limited memory and underutilized processors, without increasing inference latency. This is achieved through a two-step process: patch-wise even sampling of the original image, and channel-wise stacking of these samples. Patch-wise sampling strategically selects pixels, maintaining spatial relationships. Channel-wise stacking then arranges these sampled pixels across multiple input channels, effectively extending the data available to the network. This approach allows the network to leverage additional spatial information from the original image and makes full use of the accelerator’s parallel processing capabilities and memory instances, leading to improved accuracy. The simplicity and efficiency of DEX are particularly noteworthy, as it achieves performance gains without requiring significant model modifications or increasing computational overhead. The method is demonstrated on several architectures and datasets, showcasing its generalizability and effectiveness in enhancing CNN inference on resource-constrained devices.
Channel Extension#
The concept of ‘Channel Extension’ presents a novel approach to enhance the efficiency and accuracy of Convolutional Neural Networks (CNNs) within the constraints of resource-limited Tiny AI accelerators. The core idea revolves around leveraging underutilized processing power and memory by extending the input data channels. Instead of relying on downsampling, which leads to information loss and reduced accuracy, channel extension strategically incorporates additional spatial information from the original image into input channels, thus enriching the network’s input representation. This is achieved through a combination of patch-wise even sampling and channel-wise stacking, where image patches are sampled and these samples are stacked across multiple channels. This method enables improved accuracy and minimizes latency because of efficient parallel processing and memory utilization, which the authors demonstrate using benchmark experiments and testing on several model architectures.
Accuracy Gains#
Analyzing potential accuracy gains in a research paper requires a deeper dive into methodologies and results. Significant improvements often hinge on novel approaches that address existing limitations, such as the data channel extension (DEX) proposed in this hypothetical paper. The effectiveness of DEX likely rests on its ability to leverage underutilized processing power and memory in tiny AI accelerators by incorporating additional spatial information from the original image. This approach combats accuracy degradation typically associated with downsampling, a common necessity due to memory constraints on these devices. Quantifiable results, demonstrating average accuracy improvements (e.g., 3.5 percentage points) are crucial to evaluate the impact. Crucially, assessing if these improvements come at the cost of increased latency or resource consumption is essential. Maintaining comparable latency while improving accuracy highlights the efficiency of the proposed method. The robustness of accuracy gains across various models and datasets further supports its generalizability and practical significance. Examining specific details regarding the datasets used, and the statistical significance of the observed gains, helps in verifying the credibility of these results.
Future of DEX#
The “Future of DEX” holds exciting possibilities for enhancing CNN inference on tiny AI accelerators. Extending DEX to other CNN layers beyond the initial layer could significantly boost accuracy by integrating additional spatial information throughout the network. Exploring different sampling strategies within DEX, beyond the even sampling currently used, could further optimize performance. Integrating DEX with other model compression techniques, such as pruning or quantization, could lead to even more efficient and accurate models. Adapting DEX for various hardware architectures beyond the MAX78000 family would broaden its applicability. Finally, investigating the use of DEX for tasks beyond image classification, such as object detection and segmentation, would unlock new opportunities for on-device AI applications. Research in these directions will determine DEX’s overall impact and utility within the TinyML field.
More visual insights#
More on figures
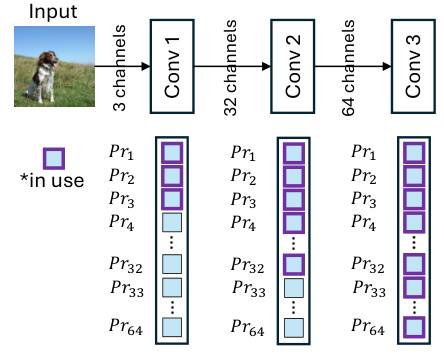
This figure illustrates how the processors of a tiny AI accelerator are utilized when processing CNN inputs with different numbers of channels. With only three input channels (e.g., RGB), only three processors are utilized, while the remaining 61 processors remain idle. This highlights the underutilization of resources in existing methods which is addressed by the proposed DEX method.
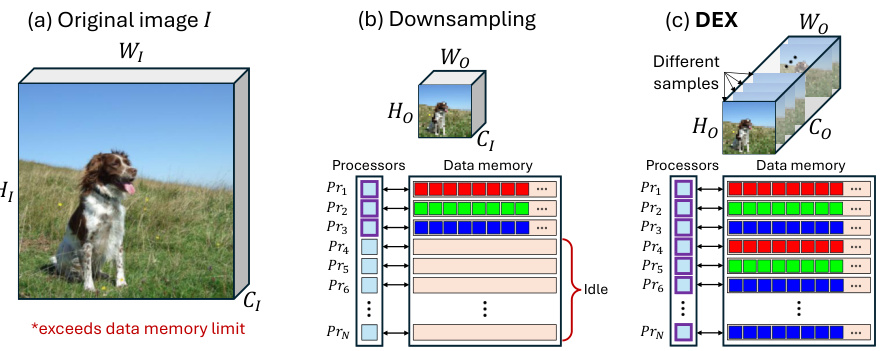
This figure compares three different ways of handling input images for tiny AI accelerators: (a) shows an original image that’s too large for the accelerator’s memory, (b) shows a downsampled image which fits into memory but underutilizes the parallel processors, and (c) shows the DEX method, which extends the image across channels to make full use of the available resources.
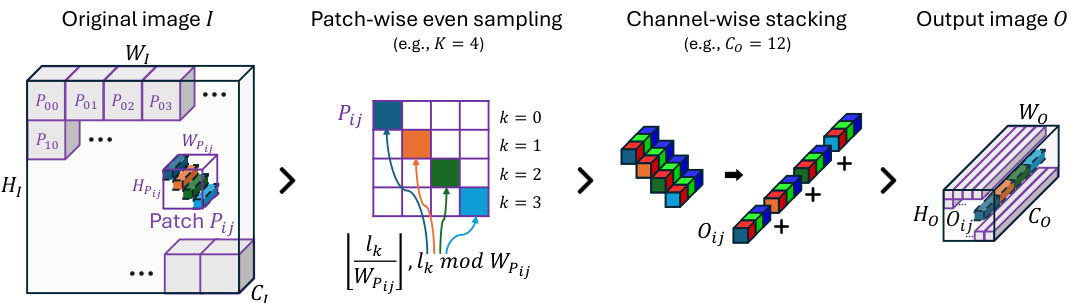
This figure illustrates the DEX process. The original image is divided into patches. DEX then uses patch-wise even sampling to select pixels evenly spaced across the original image while maintaining spatial relationships. These samples are then stacked channel-wise, creating an output image with extended channels (Co). This process adds more information from the original image to the input without increasing the spatial dimensions (Ho, Wo).

This figure illustrates how the initial convolutional layer of a CNN operates when using the DEX method. The input to the layer is an image enhanced using DEX, which extends the number of channels from C1 to Co. This extended input is then processed by the convolutional layer, which uses kernels of size Lkernel_size. The operation of the layer is shown for three different channels, representing the original channels (C1) and the added channels using DEX (Co-C1). The summation symbol (Σ) shows that the outputs from the individual channels are added to create the final output of the first convolutional layer (Lc_out). The added channels via DEX provide extra information for better feature extraction by the model, leading to improved accuracy without affecting the inference speed.
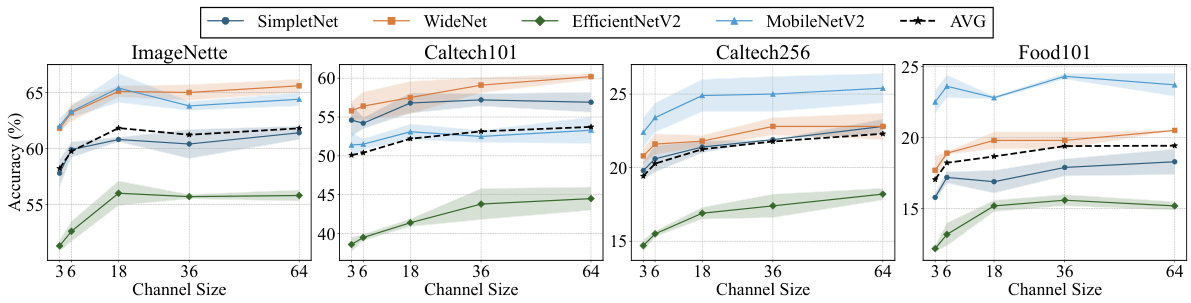
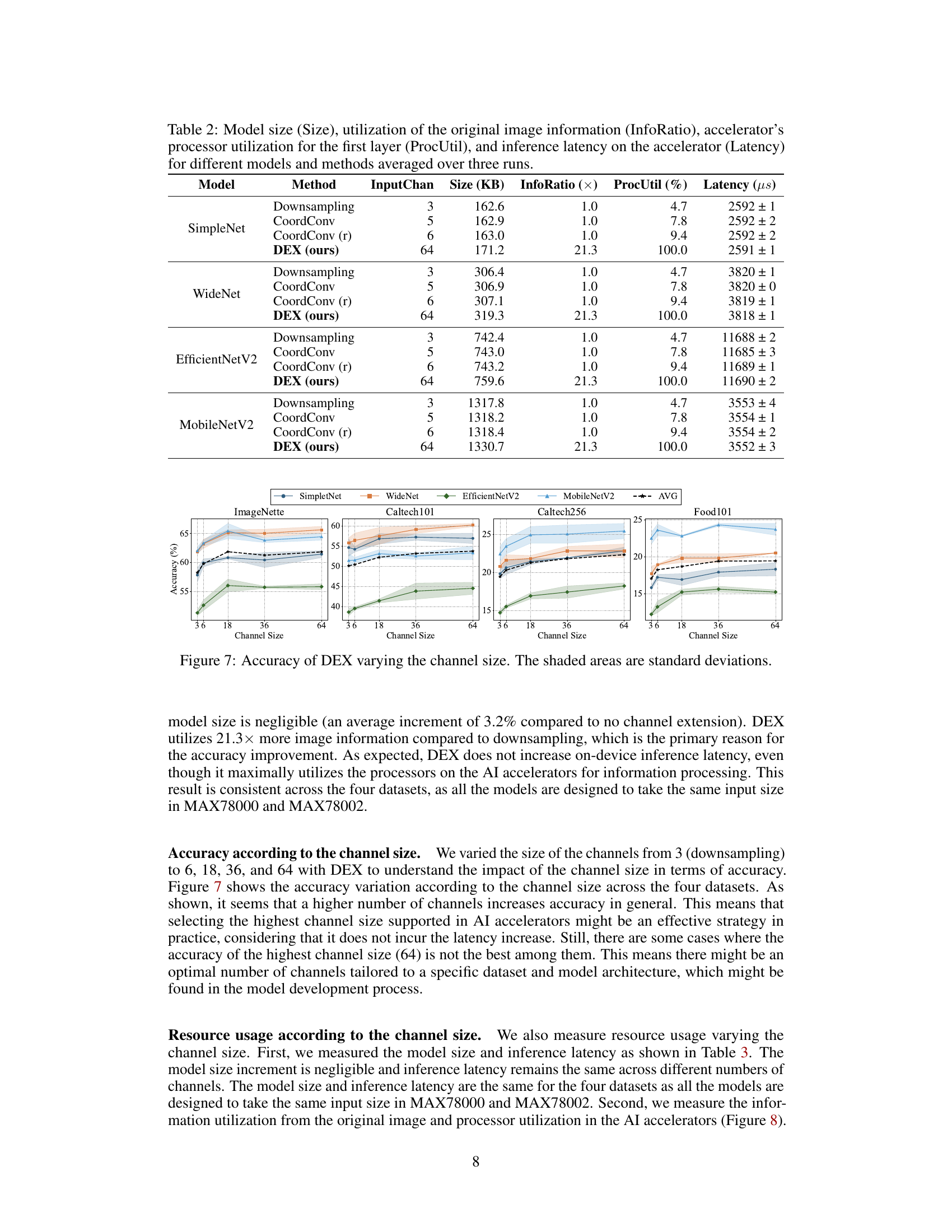
This figure shows the impact of varying the number of channels (3, 6, 18, 36, and 64) used in DEX on the accuracy of four different CNN models (SimpleNet, WideNet, EfficientNetV2, and MobileNetV2) across four different datasets (ImageNette, Caltech101, Caltech256, and Food101). The shaded regions represent standard deviations, illustrating the variability in accuracy across multiple experimental runs. The results demonstrate that increasing the channel size generally leads to improved accuracy, although there might be some exceptions depending on the specific model and dataset.

This figure shows the accuracy of the proposed DEX method (Data Channel Extension) as the number of channels in the input image is varied. The accuracy is tested across four different datasets (ImageNette, Caltech101, Caltech256, and Food101) and four different CNN models. It demonstrates how the accuracy improves with increasing channel size, indicating the effectiveness of the DEX method in utilizing more information from the original input image.

This figure shows two different development platforms used for evaluating DEX: the MAX78000 Feather Board and the MAX78002 Evaluation Kit. The image highlights the small size of the AI accelerators themselves (8mm x 8mm for the MAX78000 and 12mm x 12mm for the MAX78002) in contrast to the larger development boards. The caption emphasizes that all data storage and model inference take place solely within the AI accelerator.

This figure visualizes four alternative data extension methods compared to DEX in the paper. (a) Repetition: repeats the same downsampled image across channels. (b) Rotation: generates slightly different images through rotation. (c) Tile: divides the original image into multiple tiles and stacks them across channels. (d) Patch-wise sequential sampling: samples pixels sequentially within a patch. (e) Patch-wise random sampling: samples pixels randomly within a patch. These methods are compared against DEX to highlight the effectiveness of DEX’s approach of patch-wise even sampling and channel-wise stacking.

This figure shows example images generated by DEX from an original ImageNette image (350x350 pixels). The original image is compared to downsampled versions (32x32 pixels) created using DEX with different sampling parameters (k=0 to k=6). Each downsampled image has different pixel information, which contributes to improved feature learning within CNNs by providing a more comprehensive representation of the original image.

This figure shows example images generated by DEX from an original high-resolution image (350x350 pixels). It demonstrates how DEX extends the number of channels by incorporating additional pixel information from the original image through patch-wise even sampling and channel-wise stacking. Each of the downsampled images (k=0 to k=6) represents a different set of sampled pixels, providing additional spatial context for the CNN.

This figure shows example images generated using DEX, demonstrating how it extends the input image channels by incorporating additional pixel information. The original ImageNet image is shown alongside several downsampled versions, highlighting the diverse pixel information incorporated by the DEX method.
More on tables

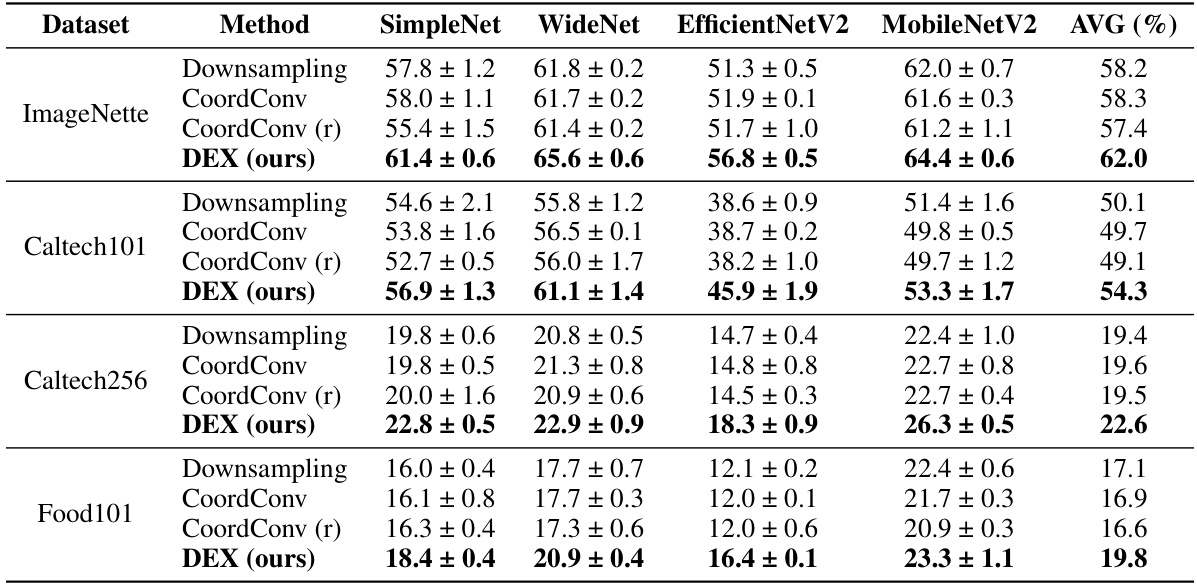
This table presents a quantitative comparison of different methods (Downsampling, CoordConv, CoordConv (r), and DEX) applied to four different CNN models (SimpleNet, WideNet, EfficientNetV2, and MobileNetV2). It shows the model size in kilobytes, the ratio of original image information utilized, the percentage of the accelerator’s processors utilized in the first layer, and the inference latency in microseconds. The results are averages across three runs.
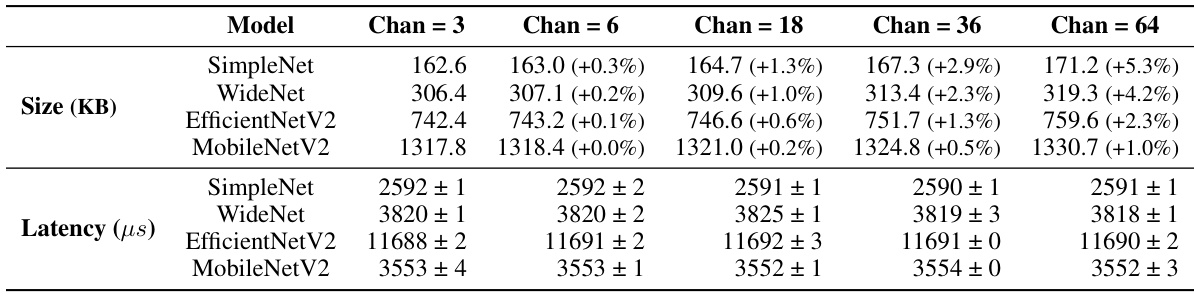
This table presents a quantitative comparison of different model architectures (SimpleNet, WideNet, EfficientNetV2, MobileNetV2) and methods (Downsampling, CoordConv, DEX) across four key metrics: model size (KB), the ratio of utilized original image information to the downsampled version, the percentage of utilized processors in the first layer of the CNN, and the inference latency in microseconds. The results are averaged over three runs and show the impact of DEX in terms of resource utilization and performance.

This table compares the performance of DEX with four alternative data extension strategies: repeating the same downsampled image across channels (Repetition), generating slightly different images through rotation (Rotation), dividing the original image into multiple tiles and stacking those tiles across channels (Tile), patch-wise sequential sampling, and patch-wise random sampling. The table shows that DEX’s approach of patch-wise even sampling is superior.

This table compares the specifications of two tiny AI accelerator platforms: MAX78000 and MAX78002. It details the MCU processor, flash memory, SRAM, CNN processor, data memory, weight memory, and bias memory for each platform, highlighting the differences in their hardware resources.

This table shows the power consumption results measured using a Monsoon Power Monitor for different models (SimpleNet and WideNet) with varying channel sizes (Chan = 3, 6, 18, 36, 64). The data demonstrates the increase in power consumption as the number of channels increases, due to higher processor utilization in the AI accelerator.
Full paper#