TL;DR#
Current gloss-free sign language translation (SLT) systems lag behind gloss-based ones. This paper identifies a major reason: representation density, where different sign gestures are packed tightly in the feature space, making it hard for the model to distinguish between them. This leads to a significant performance drop.
To solve this, the authors propose SignCL, a contrastive learning method. SignCL helps the model learn more distinct features by pulling similar signs closer and pushing different ones further apart. Experiments show that SignCL greatly improves the performance of existing SLT models (e.g., improving BLEU score by 39% and 46% on the CSL-Daily dataset). SignCL also outperforms a state-of-the-art method with only 35% of its parameters, demonstrating its efficiency and effectiveness.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in sign language translation because it identifies a critical bottleneck in gloss-free approaches—representation density—and proposes an effective solution (SignCL). This directly addresses a major challenge in the field, opening new avenues for improving the performance of gloss-free SLT systems and advancing research in self-supervised learning techniques for visual data.
Visual Insights#

🔼 This figure illustrates the representation density problem in sign language translation. It shows a t-SNE visualization of feature vectors representing different sign gestures. Notice that the vectors for ‘RECIPROCATE’ and ‘REVENGE’, which have opposite meanings, are clustered very closely together in the feature space. This proximity makes it difficult for a model to distinguish between them, highlighting the challenge posed by representation density in gloss-free sign language translation.
read the caption
Figure 1: An example of the representation density problem in sign language translation. The two images show the sign gestures for “RECIPROCATE” (blue dot) and “REVENGE” (orange dot). Although the two have opposite meanings, their visual representations are densely clustered together, as shown in the t-SNE visualization. The various colors in the visualization indicate sign gestures with different meanings.
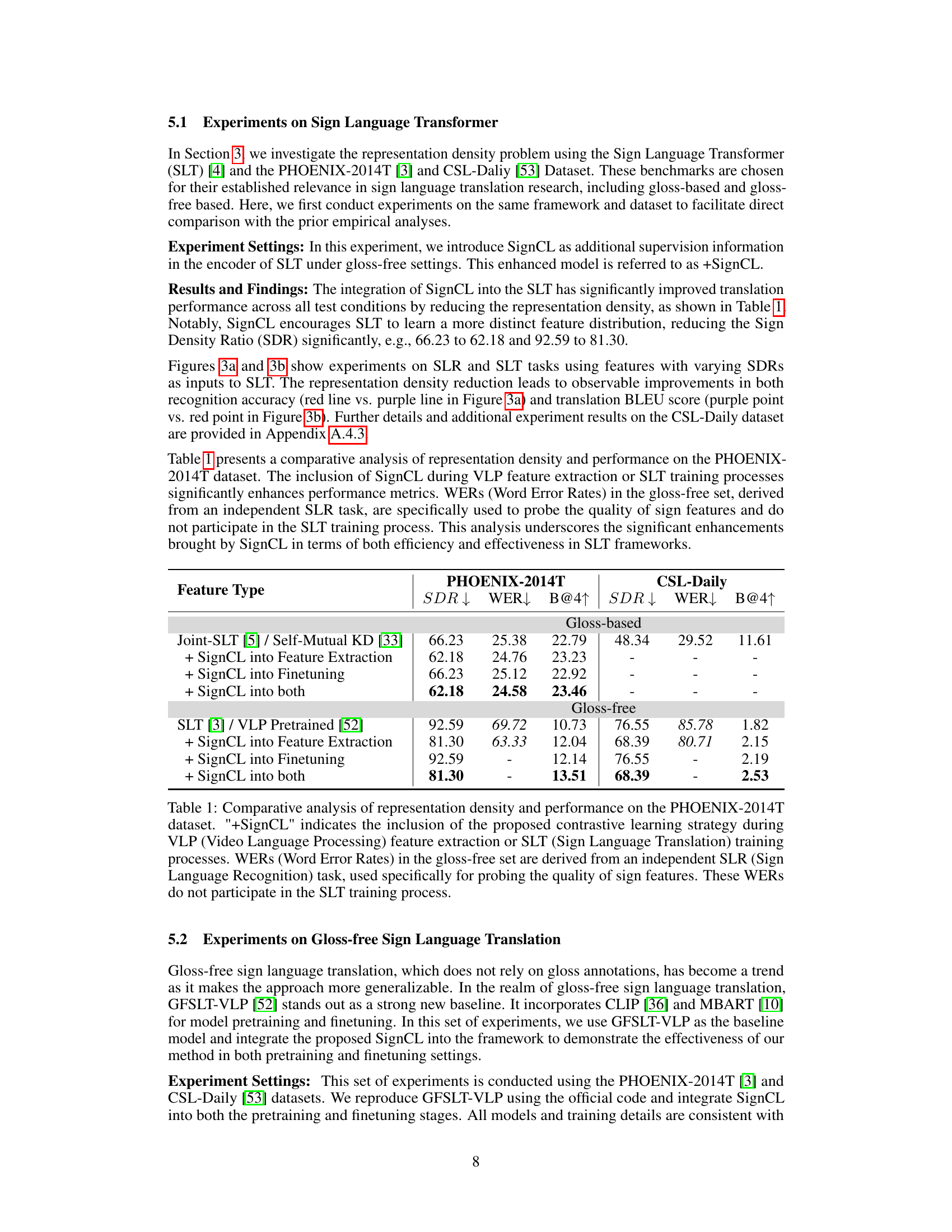
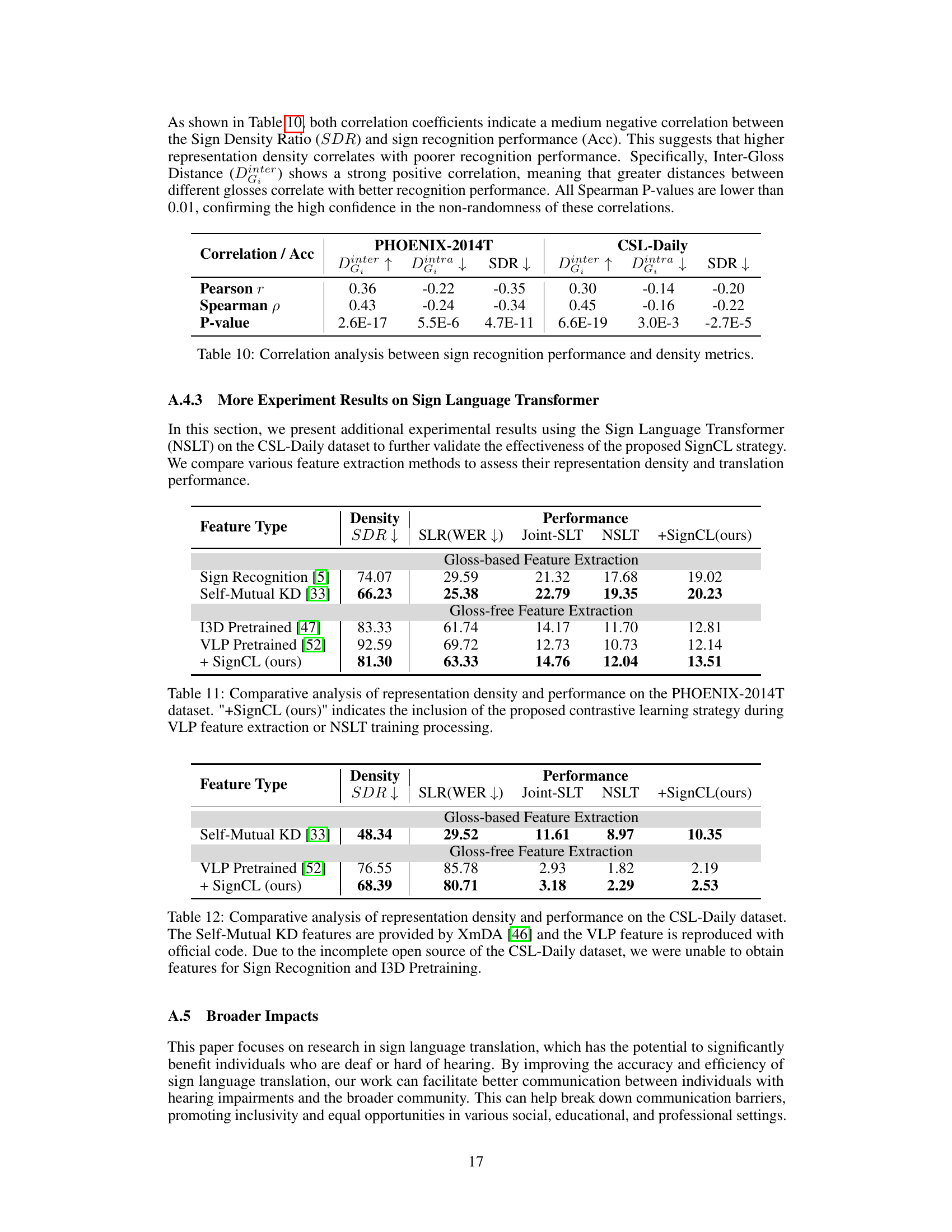
🔼 This table presents a comparative analysis of representation density and performance on the PHOENIX-2014T dataset. It shows the impact of integrating the SignCL method on both gloss-based and gloss-free feature extraction techniques, using different metrics like SDR (Sign Density Ratio), WER (Word Error Rate), and BLEU-4 score (B@4). The results highlight the improvement in performance achieved by SignCL in reducing representation density and enhancing the accuracy of sign language recognition and translation.
read the caption
Table 1: Comparative analysis of representation density and performance on the PHOENIX-2014T dataset. '+SignCL' indicates the inclusion of the proposed contrastive learning strategy during VLP (Video Language Processing) feature extraction or SLT (Sign Language Translation) training processes. WERs (Word Error Rates) in the gloss-free set are derived from an independent SLR (Sign Language Recognition) task, used specifically for probing the quality of sign features. These WERs do not participate in the SLT training process.
In-depth insights#
Representation Density#
The concept of “Representation Density” in the context of sign language translation (SLT) is a crucial observation. It highlights that semantically distinct sign gestures are often clustered closely together in the feature space learned by SLT models, particularly those without gloss annotations. This density hinders the ability of the model to accurately distinguish between similar-looking gestures with different meanings. The paper proposes a contrastive learning strategy (SignCL) to directly address this, improving performance by making the representations of similar signs more distinct and dissimilar signs more separate. The success of SignCL demonstrates the significant impact of representation density on SLT performance. By reducing this density, SignCL improves translation accuracy across various SLT frameworks significantly, achieving better results even when compared to larger models. Therefore, understanding and mitigating representation density is essential for advancing the field of gloss-free SLT.
SignCL Approach#
The SignCL approach tackles the representation density problem in gloss-free sign language translation. It leverages a contrastive learning strategy to improve the discriminative power of sign gesture representations. SignCL works by pulling together representations of semantically similar signs while pushing apart those with different meanings. This is achieved through a carefully designed sampling strategy which considers both spatial and temporal proximity of frames within sign videos to define positive and negative pairs. The method’s simplicity and effectiveness are highlighted by its significant performance gains, without increasing model parameters, across various translation frameworks. Its integration into both pretraining and finetuning stages further enhances its impact, leading to improved accuracy and a clear demonstration of its ability to address the limitations of existing gloss-free methods. The results strongly suggest that SignCL is a promising technique for advancing the field of gloss-free sign language translation.
SLT Performance Boost#
This research paper focuses on improving gloss-free Sign Language Translation (SLT) by addressing the representation density problem. The core idea is that semantically distinct sign gestures are often clustered closely together in the feature space, hindering accurate translation. The SLT performance boost is achieved through a novel contrastive learning strategy called SignCL. SignCL improves the model’s ability to distinguish between similar-looking but different signs by encouraging discriminative feature representation. The results show significant improvements in BLEU scores across various SLT frameworks (e.g., 39% and 46% increases on the CSL-Daily dataset). Importantly, this enhancement is achieved without increasing the number of model parameters. SignCL’s success highlights the crucial role of representation density in gloss-free SLT and offers a simple yet effective solution for its improvement. The approach contrasts with large-scale pre-trained models, achieving comparable or better results with far fewer parameters. This points to the effectiveness of SignCL as a practical and efficient solution for the representation density problem.
Future Work#
Future research directions stemming from this work on gloss-free sign language translation could explore several promising avenues. Improving the contrastive learning strategy (SignCL) by incorporating more nuanced semantic information could lead to even more discriminative feature representations. This might involve using contextual information from surrounding signs or leveraging linguistic models to capture semantic relationships. Investigating alternative data augmentation techniques specifically designed for sign language data could significantly boost model robustness and generalization. Exploring different contrastive loss functions that are better suited to the unique characteristics of sign language data might also prove beneficial. Furthermore, extending the approach to other sign languages and datasets is crucial for verifying generalizability and establishing the technique’s broad applicability. Finally, in-depth analysis of the representation density problem across different sign language modalities (e.g., facial expressions, body movements) could reveal further insights, potentially leading to the development of a more comprehensive and robust representation learning framework. These combined efforts would enhance the accuracy and efficiency of gloss-free SLT systems and bring about a significant impact on the accessibility and inclusion of deaf and hard-of-hearing individuals in a more technological world.
Study Limitations#
The research, while promising, acknowledges several key limitations. Boundary cases, where the assumption of adjacent frames representing the same sign gesture might not always hold, are noted. The model’s performance could be affected by these edge cases. Semantic similarity presents a challenge, as the model doesn’t explicitly account for subtle semantic relationships between visually similar signs. This could lead to misinterpretations. Additionally, the study’s focus on specific datasets and frameworks means the generalizability of findings needs further investigation. The reliance on pre-trained models also limits the complete analysis of the representation density problem’s influence on performance. Addressing these limitations in future work is crucial to advancing the robustness and widespread applicability of the proposed methods.
More visual insights#
More on figures

🔼 This figure visualizes the feature distributions of different sign gesture extraction methods using t-SNE. It shows how densely clustered the representations are for different methods, with gloss-free methods (VLP, I3D) exhibiting higher density than gloss-based methods (SRP, SMKD). The addition of SignCL to the VLP method significantly reduces the density, illustrating the effectiveness of the proposed contrastive learning approach.
read the caption
Figure 2: The t-SNE visualization of sign features across existing extraction techniques. SRP, SMKD, and I3D are downloaded from their official websites, while VLP is reproduced with official code. The addition of +SignCL denotes our proposed method that integrates a contrastive learning strategy into the VLP method (see Section 4). Different colors represent sign gestures with distinct semantics. Points in gray represent other sign categories not listed. Better viewed by zooming in.

🔼 This figure shows a comparative analysis of how representation density affects sign language recognition (SLR) and translation (SLT) performance. The left panel (a) displays the relationship between representation density and SLR accuracy for different feature types and sign gesture groups. The groups are ranked by their density. The right panel (b) shows how different SLT models’ performance decreases as representation density increases. It compares models using gloss-based and gloss-free features and highlights that those using gloss-free features consistently suffer performance drops due to representation density.
read the caption
Figure 3: Comparative analysis of representation density and its impact on sign language recognition (SLR) and translation (SLT). The left panel (a) shows the correlation between representation density and SLR accuracy across different sign feature types and sign gesture groups. Binning in this context is based on sorting by gloss density within a group, where higher bins indicate higher density. The right panel (b) illustrates the performance drops in SLT caused by the representation density problem. This figure assesses both the recognition and translation accuracies, reflecting how denser representations impact these metrics.

🔼 This figure illustrates how the Sign contrastive learning (SignCL) strategy is integrated into a gloss-free sign language translation framework. Panel (a) shows the contrastive learning sampling strategy, where adjacent frames are considered positive samples and distant frames are negative samples. Panel (b) demonstrates how SignCL is incorporated during the model’s pretraining phase, enhancing visual-text alignment. Finally, panel (c) shows the integration of SignCL into the fine-tuning phase, improving the translation performance. The overall goal is to reduce the representation density problem by learning more discriminative feature representations.
read the caption
Figure 4: Overview of the SignCL in gloss-free sign language translation: (a) Sign contrastive learning sampling strategy, (b) Showcases the integration of SignCL in the pretraining stage, and (c)) Displays the application of SignCL during the finetuning stage.

🔼 This figure shows a qualitative comparison of translation results obtained using GFSLT-VLP and GFSLT-VLP with SignCL on the CSL-Daily dataset. The left side presents the results of GFSLT-VLP which misinterprets the sign for ‘piano’ as ’laptop’. The t-SNE visualization shows the close proximity of the two signs in the feature space leading to this error. The right side demonstrates the results of GFSLT-VLP with SignCL which correctly translates ‘piano’. The t-SNE visualization now shows that the signs are more separated in the feature space. The improved separation reflects the effectiveness of SignCL in mitigating representation density issues.
read the caption
Figure 5: Qualitative comparison of translation results on CSL-Daily test set. The red background denotes model misinterpretations about the sign gestures, while green one means accurate recognition. Content in (...) is English translation for non-Chinese readers.
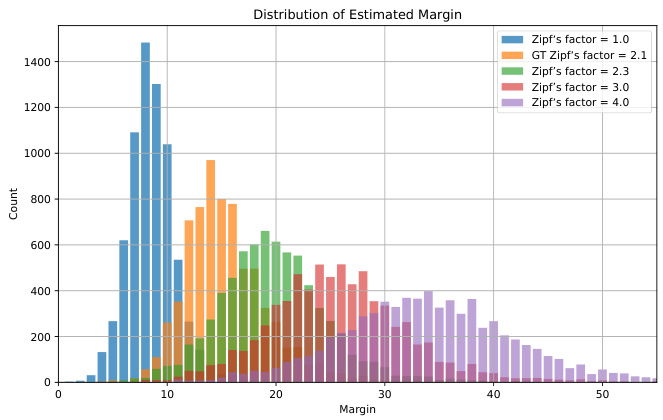
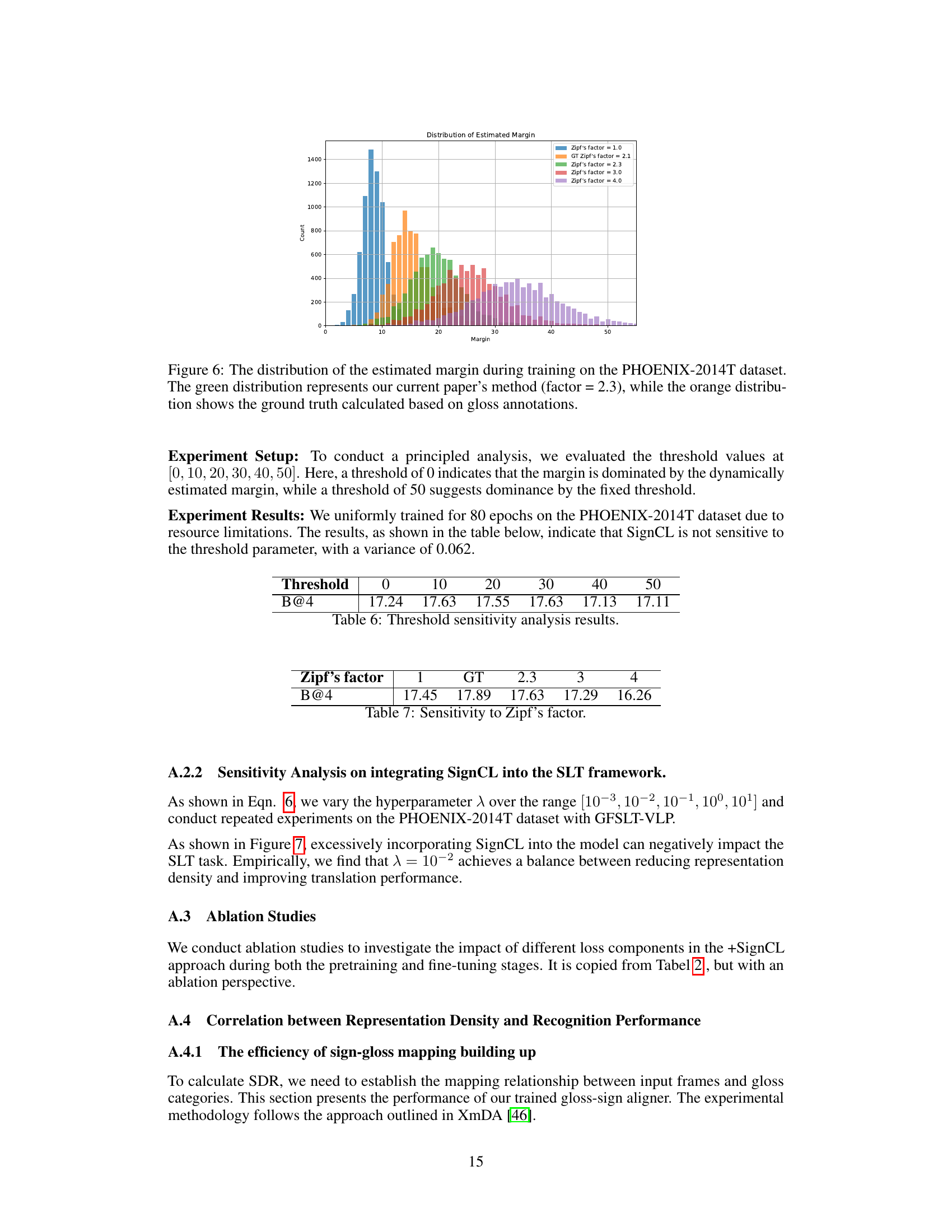
🔼 This figure shows the distribution of dynamically estimated margins used in the SignCL method during training on the PHOENIX-2014T dataset. The margin is a key parameter in contrastive learning, determining how far apart positive and negative samples should be in the feature space. The green bars represent the distribution of margins calculated using the proposed method, which uses a Zipf’s factor of 2.3 to estimate the average duration of sign gestures. The orange bars show the ground truth distribution, calculated using gloss annotations, providing a comparison point to assess the accuracy of the proposed method’s margin estimation.
read the caption
Figure 6: The distribution of the estimated margin during training on the PHOENIX-2014T dataset. The green distribution represents our current paper's method (factor = 2.3), while the orange distribution shows the ground truth calculated based on gloss annotations.

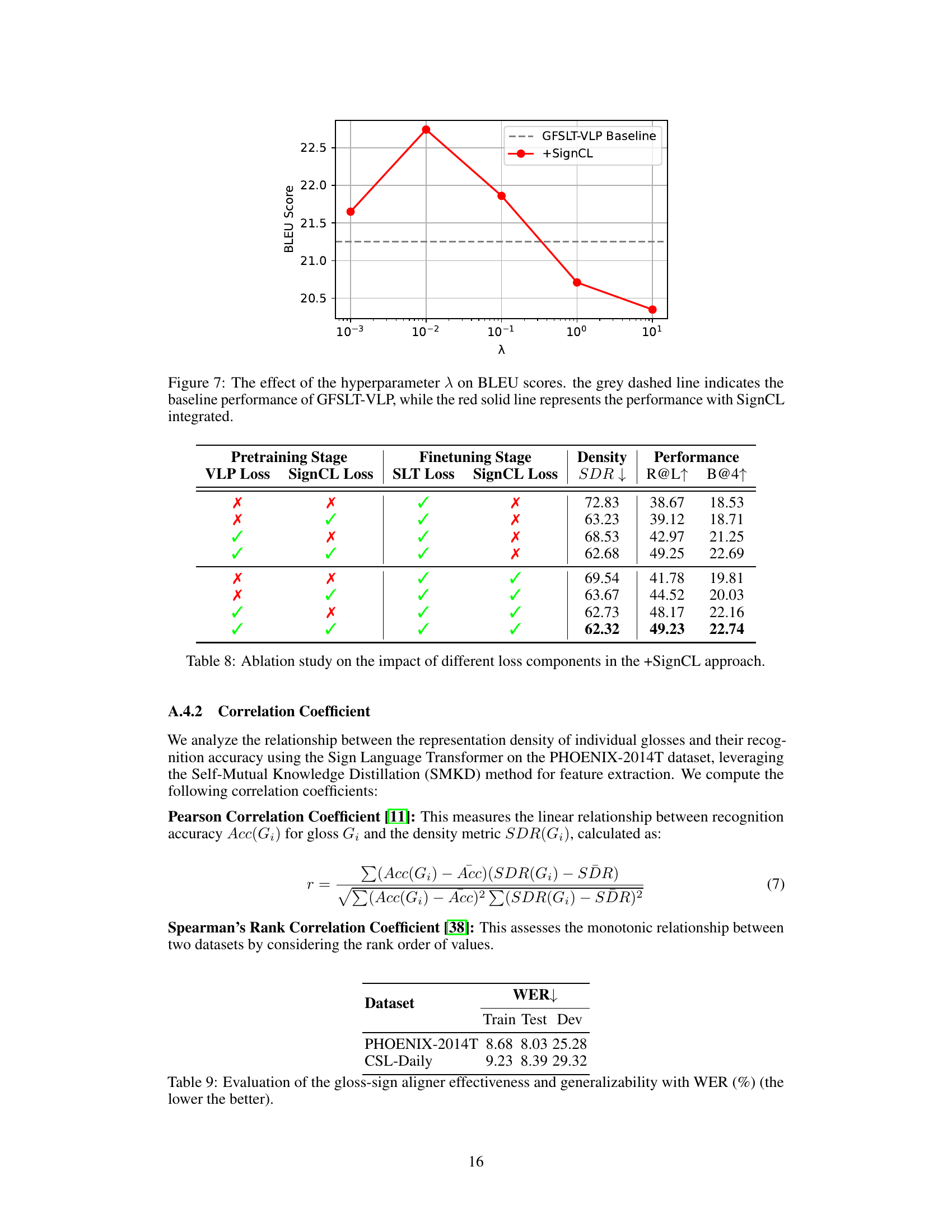
🔼 This figure shows the impact of the hyperparameter lambda (λ) on the BLEU scores of a sign language translation model. The x-axis represents different values of λ, and the y-axis shows the corresponding BLEU scores. The grey dashed line represents the baseline performance of the GFSLT-VLP model without SignCL. The red solid line shows the performance of the model when SignCL (the proposed contrastive learning strategy) is integrated. It demonstrates that a specific range of λ values achieves the best balance between reducing representation density and improving translation performance. Selecting an inappropriate λ value can negatively affect the model’s performance.
read the caption
Figure 7: The effect of the hyperparameter λ on BLEU scores. the grey dashed line indicates the baseline performance of GFSLT-VLP, while the red solid line represents the performance with SignCL integrated.
More on tables
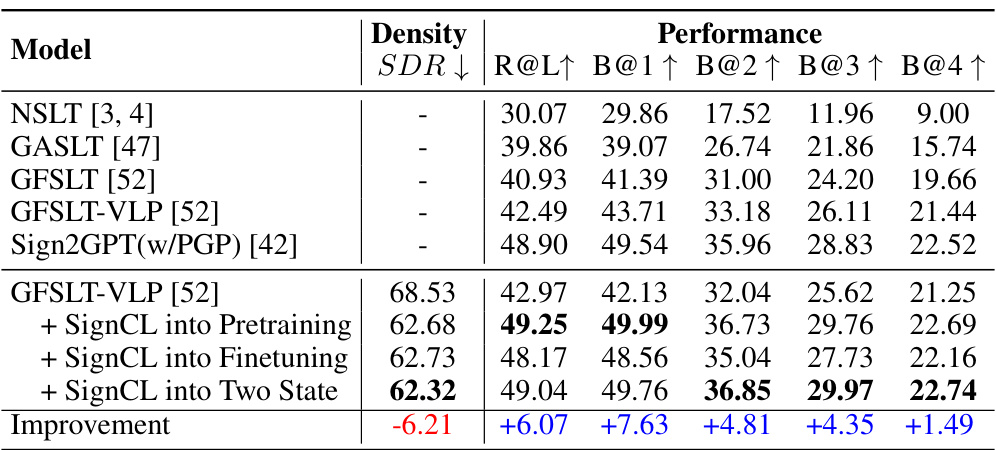
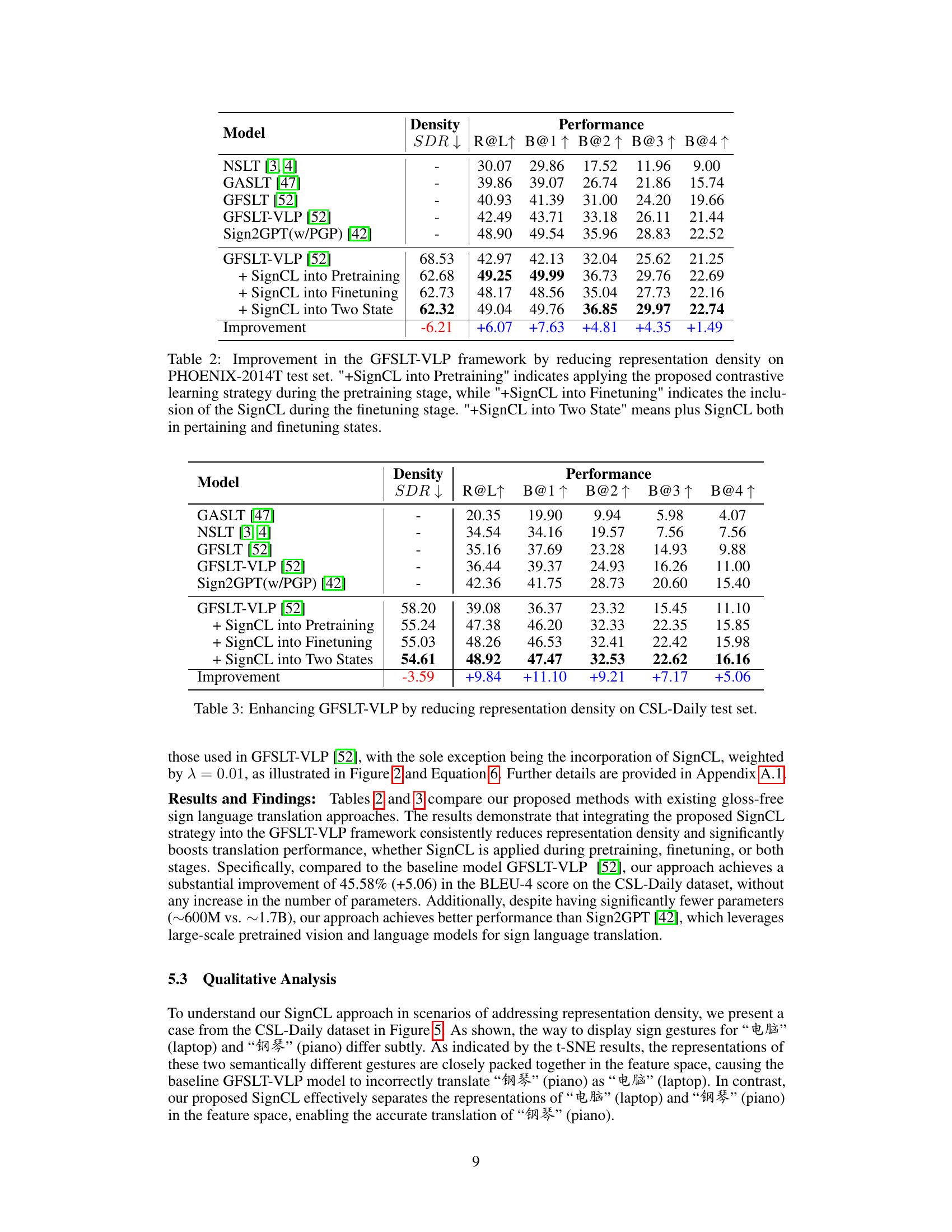
🔼 This table shows the performance improvement of GFSLT-VLP model by applying SignCL in different training stages (pretraining, finetuning, or both). The results are evaluated on the PHOENIX-2014T test set, using metrics such as Recall@1 (R@1), BLEU scores at different levels (B@1, B@2, B@3, B@4), and Sign Density Ratio (SDR). The table demonstrates that incorporating SignCL leads to significant improvements in translation performance, especially when applied during both pretraining and finetuning.
read the caption
Table 2: Improvement in the GFSLT-VLP framework by reducing representation density on PHOENIX-2014T test set. '+SignCL into Pretraining' indicates applying the proposed contrastive learning strategy during the pretraining stage, while '+SignCL into Finetuning' indicates the inclusion of the SignCL during the finetuning stage. '+SignCL into Two State' means plus SignCL both in pertaining and finetuning states.
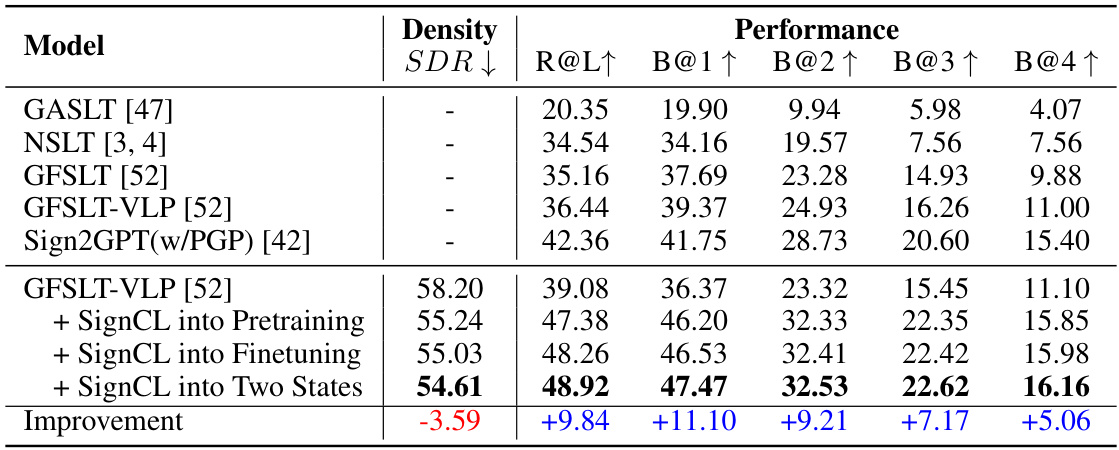
🔼 This table presents a comparative analysis of representation density and performance on the CSL-Daily test set. It shows the results for the baseline GFSLT-VLP model and three variants incorporating the SignCL contrastive learning strategy at different stages (pretraining, finetuning, or both). The metrics include the Sign Density Ratio (SDR), Recall at 1 (R@1), and BLEU scores at different levels (B@1, B@2, B@3, B@4). The improvement achieved by SignCL in each metric is also displayed, highlighting its positive impact on performance.
read the caption
Table 3: Enhancing GFSLT-VLP by reducing representation density on CSL-Daily test set.

🔼 This table lists the hyperparameters used for training the Sign Language Transformer models on the PHOENIX-2014T and CSL-Daily datasets. The hyperparameters control various aspects of the model’s architecture and training process, including the number of encoder and decoder layers, attention heads, hidden size, activation function, learning rate, Adam beta parameters, label smoothing, maximum output length, dropout rate, and batch size. These settings were optimized for each dataset to achieve the best performance.
read the caption
Table 4: Hyperparameters of Sign Language Transformer models.
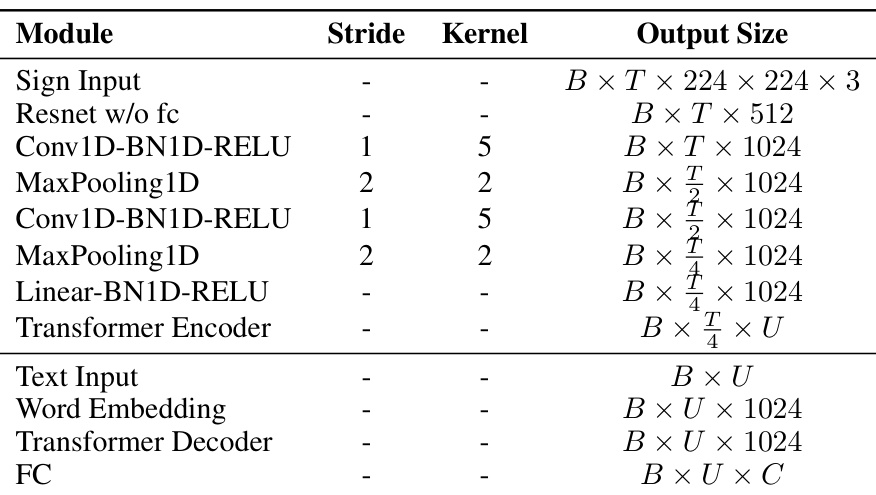
🔼 This table details the architecture of the Gloss-Free Sign Language Translation (GFSLT) model used in the paper. It breaks down the different modules involved, their strides and kernel sizes, and the resulting output sizes at each stage of processing. It shows how the model processes both sign language input (video) and text input, ultimately leading to a final output. The table uses B for batch size, T for the length of the longest video, and U for the length of the longest text input. The values are copied from a previously published work, GFSLT-VLP [52].
read the caption
Table 5: Detailed Gloss-Free SLT (GFSLT) Framework. B represents batch size, T denotes the length of the longest input sign video in the batch, and U is the length of the longest input text in the batch. It is copied from GFSLT-VLP [52].

🔼 This table compares the performance of different sign language translation models on the PHOENIX-2014T dataset. It shows that the proposed SignCL method significantly improves performance by reducing the representation density. The table compares gloss-based and gloss-free methods, with and without SignCL. Performance is evaluated using SDR (Sign Density Ratio), WER (Word Error Rate), and BLEU score (B@4).
read the caption
Table 1: Comparative analysis of representation density and performance on the PHOENIX-2014T dataset. '+SignCL' indicates the inclusion of the proposed contrastive learning strategy during VLP (Video Language Processing) feature extraction or SLT (Sign Language Translation) training processes. WERs (Word Error Rates) in the gloss-free set are derived from an independent SLR (Sign Language Recognition) task, used specifically for probing the quality of sign features. These WERS do not participate in the SLT training process.

🔼 This table presents the results of an ablation study on the sensitivity of the SignCL model to different values of the Zipf’s factor. The Zipf’s factor is used to dynamically estimate the margin for negative sampling in the contrastive learning process. The table shows the BLEU-4 scores obtained using five different Zipf’s factor values (1, GT, 2.3, 3, and 4). The GT (Ground Truth) value represents the actual average margin calculated from the data. The experiment results shows that SignCL model is relatively insensitive to the choice of Zipf’s factor within this range.
read the caption
Table 7: Sensitivity to Zipf's factor.

🔼 This ablation study investigates the individual effects of VLP Loss, SignCL Loss, SLT Loss, and SignCL Loss on the performance of the Sign Language Transformer model. The table shows that the inclusion of both SignCL loss components (during both pre-training and fine-tuning) significantly improves performance, as indicated by lower SDR (Sign Density Ratio) and higher R@L and B@4 metrics. The study highlights the importance of SignCL in enhancing performance.
read the caption
Table 8: Ablation study on the impact of different loss components in the +SignCL approach.
🔼 This table compares the performance of different models on the PHOENIX-2014T dataset, focusing on the impact of representation density. It shows the sign density ratio (SDR), word error rate (WER), and BLEU score (B@4) for various models with and without the proposed SignCL method. The results demonstrate that SignCL significantly reduces the representation density, leading to improved performance in both sign language recognition and translation.
read the caption
Table 1: Comparative analysis of representation density and performance on the PHOENIX-2014T dataset. '+SignCL' indicates the inclusion of the proposed contrastive learning strategy during VLP (Video Language Processing) feature extraction or SLT (Sign Language Translation) training processes. WERs (Word Error Rates) in the gloss-free set are derived from an independent SLR (Sign Language Recognition) task, used specifically for probing the quality of sign features. These WERs do not participate in the SLT training process.

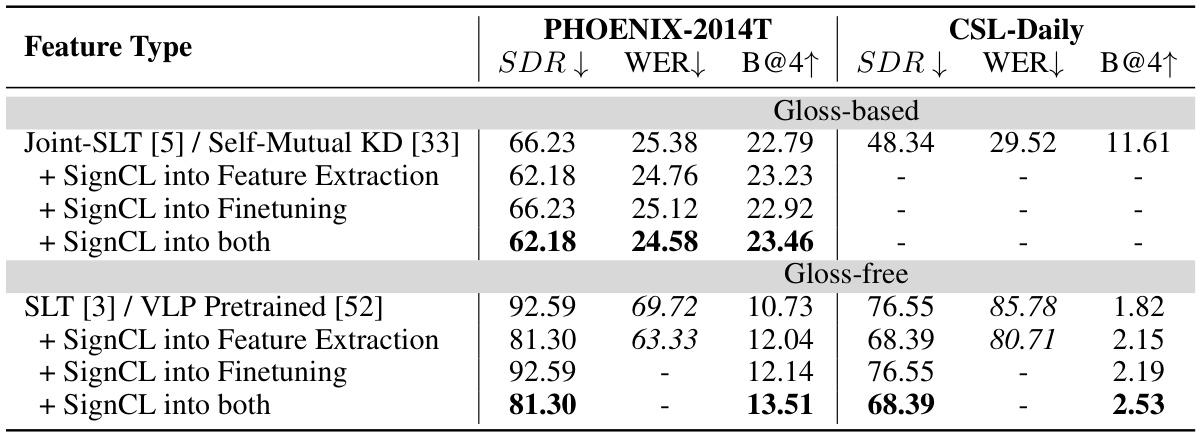
🔼 This table presents the results of a correlation analysis between sign recognition performance (accuracy) and density metrics (Inter-Gloss Distance, Intra-Gloss Distance, and Sign Density Ratio) for both PHOENIX-2014T and CSL-Daily datasets. It shows the Pearson and Spearman correlation coefficients, along with their corresponding p-values, indicating the strength and significance of the relationships. Negative correlation between SDR and accuracy suggests that higher representation density correlates with poorer recognition performance. Conversely, a positive correlation between Inter-Gloss Distance and accuracy shows that greater distances between different glosses correlate with better recognition performance.
read the caption
Table 10: Correlation analysis between sign recognition performance and density metrics.

🔼 This table presents a comparative analysis of representation density and performance on the PHOENIX-2014T dataset for different feature extraction methods: Self-Mutual KD, Sign Recognition, I3D Pretrained, and VLP Pretrained. It shows the Sign Density Ratio (SDR), Word Error Rate (WER) for Sign Language Recognition (SLR), and BLEU scores (B@4) for Sign Language Translation (SLT) using the Joint-SLT and NSLT models. The table also includes results when the proposed contrastive learning strategy, SignCL, is integrated into either feature extraction or the SLT training process.
read the caption
Table 11: Comparative analysis of representation density and performance on the PHOENIX-2014T dataset. '+SignCL (ours)' indicates the inclusion of the proposed contrastive learning strategy during VLP feature extraction or NSLT training processing.
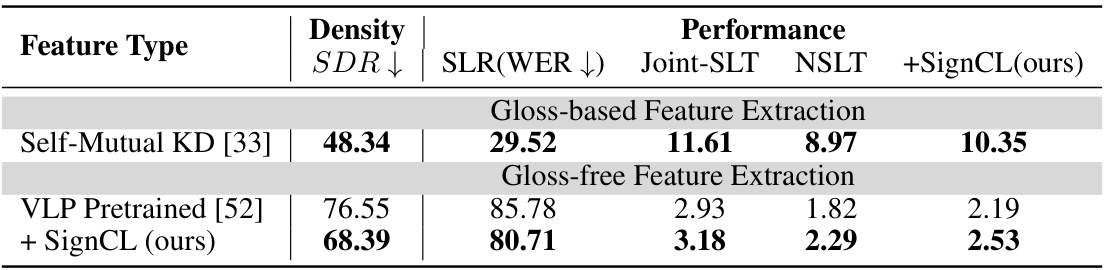
🔼 This table compares different feature extraction methods (gloss-based and gloss-free) for their representation density and performance on the PHOENIX-2014T dataset. The performance metrics are evaluated using Word Error Rate (WER) for Sign Language Recognition (SLR) and BLEU score (B@4) for Sign Language Translation (SLT), using both the standard Sign Language Transformer and a version enhanced with SignCL (the proposed contrastive learning method). It shows that reducing representation density using SignCL leads to improved performance on both SLR and SLT tasks.
read the caption
Table 11: Comparative analysis of representation density and performance on the PHOENIX-2014T dataset. '+SignCL (ours)' indicates the inclusion of the proposed contrastive learning strategy during VLP feature extraction or NSLT training processing.
Full paper#