↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Pedestrian trajectory prediction is challenging due to the complexity of pedestrian movement influenced by various factors including scene, nearby people and individual intentions. Existing methods often struggle with generalization across different scenarios, leading to suboptimal performance. They typically model feature spaces of future trajectories based on high-dimensional historical trajectories, often ignoring the intrinsic similarity between past and future movements.
TrajCLIP tackles these limitations by employing contrastive learning and idempotent networks. By pairing historical and future trajectories and applying contrastive learning, the method enforces consistency in the encoded feature space. Idempotent loss and tightness loss manage complex feature distributions, preventing over-expansion in the latent space. The use of trajectory interpolation and synthetic data further enhances model capacity and generalization. Evaluation across multiple datasets reveals that TrajCLIP surpasses existing methods in accuracy and demonstrates strong adaptability to new scenarios.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on pedestrian trajectory prediction due to its state-of-the-art performance and novel approach. It addresses the limitations of existing methods by focusing on feature space consistency, leading to improved generalization and adaptability. The introduction of contrastive learning and idempotent networks opens new avenues for research in this field and inspires future work on various similar problems.
Visual Insights#

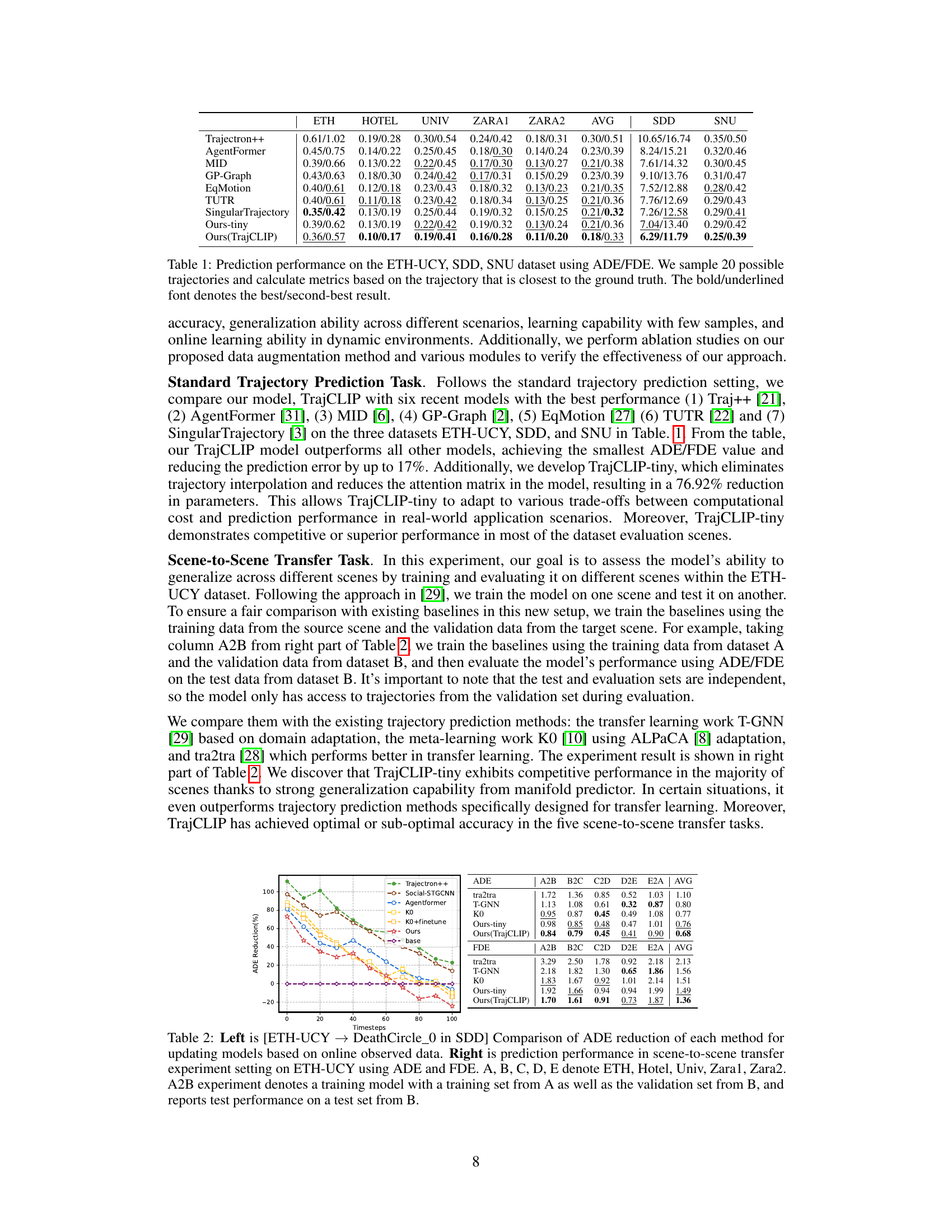
This figure illustrates the difference between existing trajectory prediction methods and the proposed TrajCLIP method. Existing methods encode historical and future trajectories into separate feature spaces, leading to inconsistencies and inaccuracies in predictions. TrajCLIP, on the other hand, maintains consistency between these feature spaces by using affine transformations, resulting in smoother and more realistic trajectory predictions.
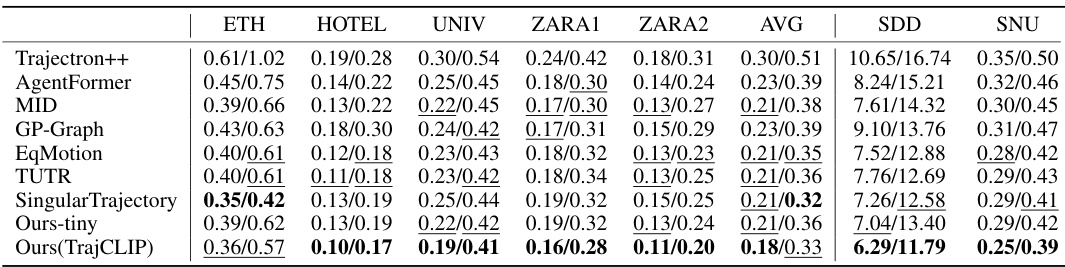
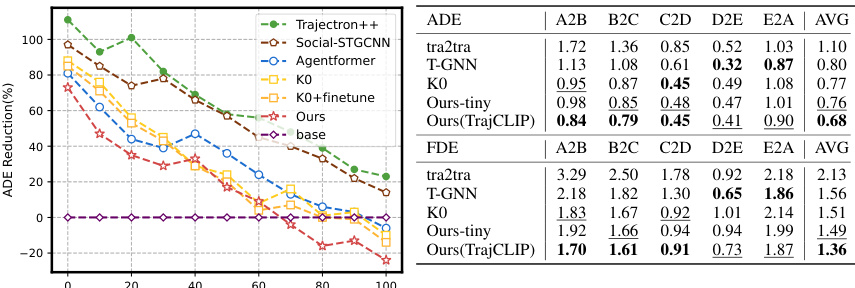
This table presents the performance comparison of different trajectory prediction methods (Trajectron++, AgentFormer, MID, GP-Graph, EqMotion, TUTR, SingularTrajectory, Ours-tiny, and Ours(TrajCLIP)) on three benchmark datasets: ETH-UCY, SDD, and SNU. The metrics used are Average Displacement Error (ADE) and Final Displacement Error (FDE). For each method, the ADE and FDE values are reported for each dataset, along with an average across all datasets. The best and second-best results are highlighted.
In-depth insights#
Contrastive Learning#
Contrastive learning, in the context of pedestrian trajectory prediction, is a powerful technique for learning robust representations. By comparing similar and dissimilar trajectory pairs, the model learns to capture subtle differences that might otherwise be missed. This approach helps to disentangle the complex interactions between pedestrians and their environments, improving the generalization capability of the predictive model. Instead of relying solely on high-dimensional feature spaces, which can be noisy and less informative, contrastive learning focuses on learning a more structured representation of these interactions. The success of this technique hinges on defining an effective similarity metric for trajectory pairs, a crucial step for guiding the model towards learning meaningful relationships. The use of contrastive learning often leads to more accurate and reliable trajectory predictions, particularly in diverse and complex scenarios. Therefore, this method improves the model’s ability to generalize to unseen data and perform well in real-world applications.
Idempotent Networks#
Idempotent networks, in the context of trajectory prediction, offer a compelling approach to managing complex data distributions. The core concept revolves around creating a feature transformation that, when applied repeatedly, produces the same output. This idempotency ensures stability and prevents over-expansion of the latent space, a common problem in generative models. By constraining the feature space mapping to be idempotent, the model avoids generating unrealistic or unstable predictions. This method enhances generalization by enabling the model to learn consistent and stable relationships between historical and future trajectories, regardless of the specific input distribution. The use of idempotent networks is particularly beneficial when handling multimodal data and aims to improve the accuracy and robustness of the prediction model.
Trajectory Encoding#
Effective trajectory encoding is crucial for pedestrian trajectory prediction. A robust encoding must capture both spatiotemporal dynamics and inter-agent interactions. Simple methods might use a sequence of coordinates, but this lacks the richness needed for accurate prediction. Advanced techniques could incorporate features like velocity, acceleration, and relative positions to other pedestrians. Fourier transforms can reveal underlying frequencies in movement patterns, offering insight into periodic behaviors and enabling efficient dimensionality reduction. Furthermore, attention mechanisms can selectively focus on relevant parts of the trajectory and the surrounding environment, especially critical in complex scenes. The choice of encoding significantly impacts the model’s ability to learn meaningful representations and generalize to unseen situations. Multimodal encoding, addressing the inherent uncertainty in human motion, is another important aspect, where different possibilities are represented.
Cross-Scene Transfer#
Cross-scene transfer in pedestrian trajectory prediction focuses on a model’s ability to generalize knowledge gained from one environment to unseen environments. Success hinges on the model’s capacity to disentangle scene-specific factors from underlying pedestrian movement patterns. A model excelling at cross-scene transfer would demonstrate consistent accuracy across diverse scenarios (e.g., busy intersections versus sparse walkways), showcasing robustness beyond memorization of training data distributions. Effective approaches often involve learning scene-invariant features, such as pedestrian interactions and movement dynamics, while mitigating the impact of scene-specific visual details. This requires careful consideration of the feature representation and learning methods employed. Evaluation often involves training on one scene and testing on others, measuring performance differences to quantify transferability. A model with high cross-scene transfer capabilities is highly desirable for real-world applications, such as autonomous driving, where diverse and unpredictable scenarios are the norm.
Future Directions#
Future research could explore enhancing TrajCLIP’s robustness by incorporating more diverse datasets representing varied pedestrian behaviors and environmental conditions. Improving the model’s efficiency and scalability is crucial for real-world applications, potentially through model compression techniques or optimized architectures. Investigating the model’s interpretability is also important to build trust and understand its decision-making process, which could involve visualizing attention mechanisms or using explainable AI methods. Furthermore, exploring the integration of multimodal data, such as images or sensor readings, would enhance prediction accuracy and context awareness. Finally, developing methods for online adaptation and continuous learning is crucial to handle dynamic and changing environments. Addressing these points will solidify TrajCLIP’s position as a robust and reliable pedestrian trajectory prediction model for real-world applications.
More visual insights#
More on figures
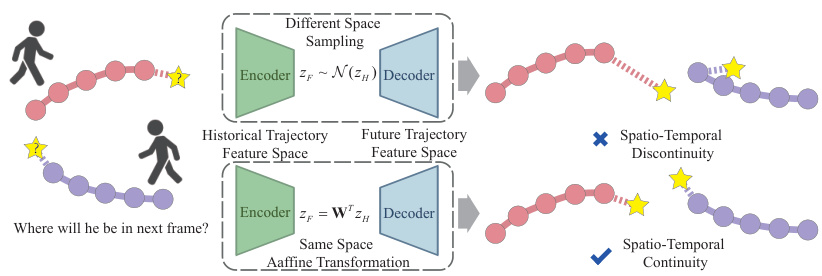
This figure illustrates the difference between existing trajectory prediction methods and the proposed TrajCLIP method. Existing methods map historical and future trajectories into different feature spaces, leading to discontinuities in predicted trajectories. In contrast, TrajCLIP maps them into the same feature space, ensuring spatio-temporal continuity and smoother trajectory predictions.

This figure presents the overall architecture of the TrajCLIP model, highlighting its four main components: the Trajectory Encoder, the CLIP Pairing Learning module, the Trajectory Manifold Predictor, and the Trajectory Manifold Decoder. The Trajectory Encoder processes both historical and future trajectories, extracting Spatio-Temporal Interaction Features (STIF) and Scene-Agent Interaction Features (SAIF). The CLIP Pairing Learning module uses contrastive learning to ensure consistency between the feature spaces of historical and future trajectories. The Trajectory Manifold Predictor employs idempotent and tightness loss functions to map historical trajectory features onto a manifold representing the distribution of future trajectories. Finally, the Trajectory Manifold Decoder generates the predicted future trajectory based on this manifold. The figure illustrates the data flow and the interactions between these components, clearly showing how historical and future trajectory features are processed and used to predict future trajectories.

This figure illustrates the architecture of two feature extractors used in the TrajCLIP model: Spatio-Temporal Interaction Feature (STIF) and Scene-Agent Interaction Feature (SAIF). The STIF processes trajectory data in the time domain, incorporating position, velocity, acceleration, and agent sequences. Agent-aware attention mechanisms are used to capture interactions between agents. The SAIF operates in the frequency domain, using Fast Fourier Transforms (FFT) to extract scene-agent interaction information. A Butterworth filter is applied to separate high and low-frequency components before inverse FFT (IFFT) to obtain the final features. Self-attention is used to aggregate agent information. Both feature extractors aim to provide comprehensive representations of trajectory dynamics.
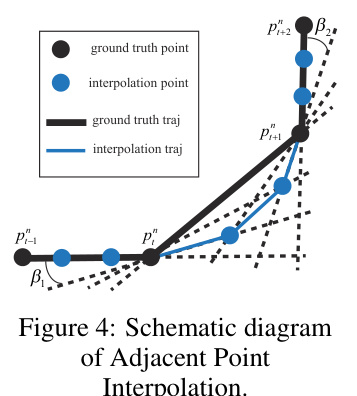
This figure illustrates the adjacent point interpolation algorithm used for data augmentation. It shows how new data points (blue circles) are interpolated between existing trajectory points (black circles) based on the vectors formed by consecutive points. The algorithm considers the relative positions of these vectors to determine the appropriate interpolation method, resulting in a more representative and complex distribution of trajectories for model training.

This figure shows the overall framework of the TrajCLIP model, which consists of four main parts: a trajectory encoder, a CLIP pairing learning module, a trajectory manifold predictor, and a trajectory manifold decoder. The trajectory encoder processes both historical and future trajectories, extracting spatio-temporal and scene-agent interaction features. The CLIP pairing learning module enforces consistency between the feature spaces of historical and future trajectories using contrastive learning. The trajectory manifold predictor maps the historical trajectory features to future trajectory features in the same feature space using an idempotent generative network. Finally, the trajectory manifold decoder generates the predicted future trajectories. Sections 3.2 and 4.2 of the paper provide further details on each component and implementation.
This figure shows the overall framework of the TrajCLIP model, which is composed of four main parts: a trajectory encoder, a CLIP pairing learning module, a trajectory manifold predictor, and a trajectory manifold decoder. The trajectory encoder encodes the historical and future trajectories, the CLIP pairing learning module ensures consistency between the feature spaces of past and future trajectories, the trajectory manifold predictor maps past trajectory features into future trajectory features in the same feature space, and the trajectory manifold decoder generates predicted trajectories. Specific details about each component are available in Sections 3.2 and 4.2 of the paper.

This figure illustrates the architecture of two key components in the TrajCLIP model: the Spatio-Temporal Interaction Feature (STIF) and the Scene-Agent Interaction Feature (SAIF). STIF processes trajectories to extract temporal features (position, velocity, acceleration) using agent-aware attention. SAIF uses Fourier transforms to extract interaction features between agents and the scene, emphasizing shared information and eliminating agent-specific details. The figure visually depicts the data flow and processing steps within each component.

This figure illustrates the difference between existing trajectory prediction methods and the proposed TrajCLIP method. Existing methods project historical and future trajectories into different feature spaces, leading to inconsistencies and difficulties in prediction, especially in terms of spatio-temporal continuity. In contrast, TrajCLIP maintains consistency between the feature spaces, enabling smooth and accurate prediction through affine transformations.
More on tables
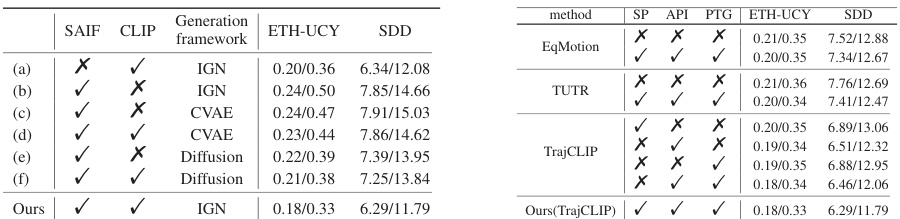
This table presents the results of ablation studies conducted on the TrajCLIP model. The left part shows the impact of different modules (SAIF, CLIP pairing learning, and IGN generation framework) on the model’s performance, while the right part demonstrates the effectiveness of various data augmentation techniques (Small Perturbations, Adjacent Point Interpolation, and Plausible Trajectories Generation). The performance is evaluated using ADE and FDE metrics on the ETH-UCY and SDD datasets. The table helps to understand the contribution of each component and data augmentation strategy to the overall performance of the TrajCLIP model.

This table compares TrajCLIP with other state-of-the-art trajectory prediction methods across three key metrics: model size (in MB), computational complexity (in GFlops), and inference speed (in seconds). Inference speed specifically refers to the time taken to predict the next 12 frames of a trajectory given the preceding 8 frames.
Full paper#