↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Image inpainting, the task of filling in missing parts of images, is crucial in computer vision. Traditional methods have limitations in producing visually pleasing results, particularly when subjective human preferences come into play. Deep learning, especially diffusion models, have made progress, but the generated images often lack alignment with human aesthetic standards, leading to unnatural and discordant reconstructions.
PrefPaint addresses this issue by using reinforcement learning to align a pre-trained diffusion model with human aesthetic preferences. The core method involves training a reward model on a large dataset of human-annotated images and then using reinforcement learning to fine-tune the diffusion model toward generating higher-reward (more aesthetically pleasing) images. The paper provides a theoretical analysis of the reward model’s accuracy and demonstrates significant improvements in various inpainting tasks, including image extension and 3D reconstruction. The publicly available code and dataset further enhance the impact and reproducibility of this work.
Key Takeaways#
Why does it matter?#
This paper is significant because it presents a novel framework for aligning image inpainting models with human preferences, a crucial step in bridging the gap between technical performance and user satisfaction. It introduces a reinforcement learning approach and a theoretical analysis of reward model accuracy, offering a robust and efficient method for improving the visual appeal of AI-generated images. This work has broad implications for the design of visually driven AI applications across computer vision and beyond. This work also provides a publicly available dataset and code, accelerating further research.
Visual Insights#

This figure displays a visual comparison of image inpainting results between the Runway model and the PrefPaint model proposed in the paper. Multiple image examples are shown, each with a prompt (the incomplete image) and the results produced by both models. The purpose is to highlight the visual improvements achieved by aligning the diffusion model with human preferences using the reinforcement learning approach presented in the paper. The PrefPaint model demonstrates significantly improved visual quality and more natural-looking inpainting results compared to Runway.
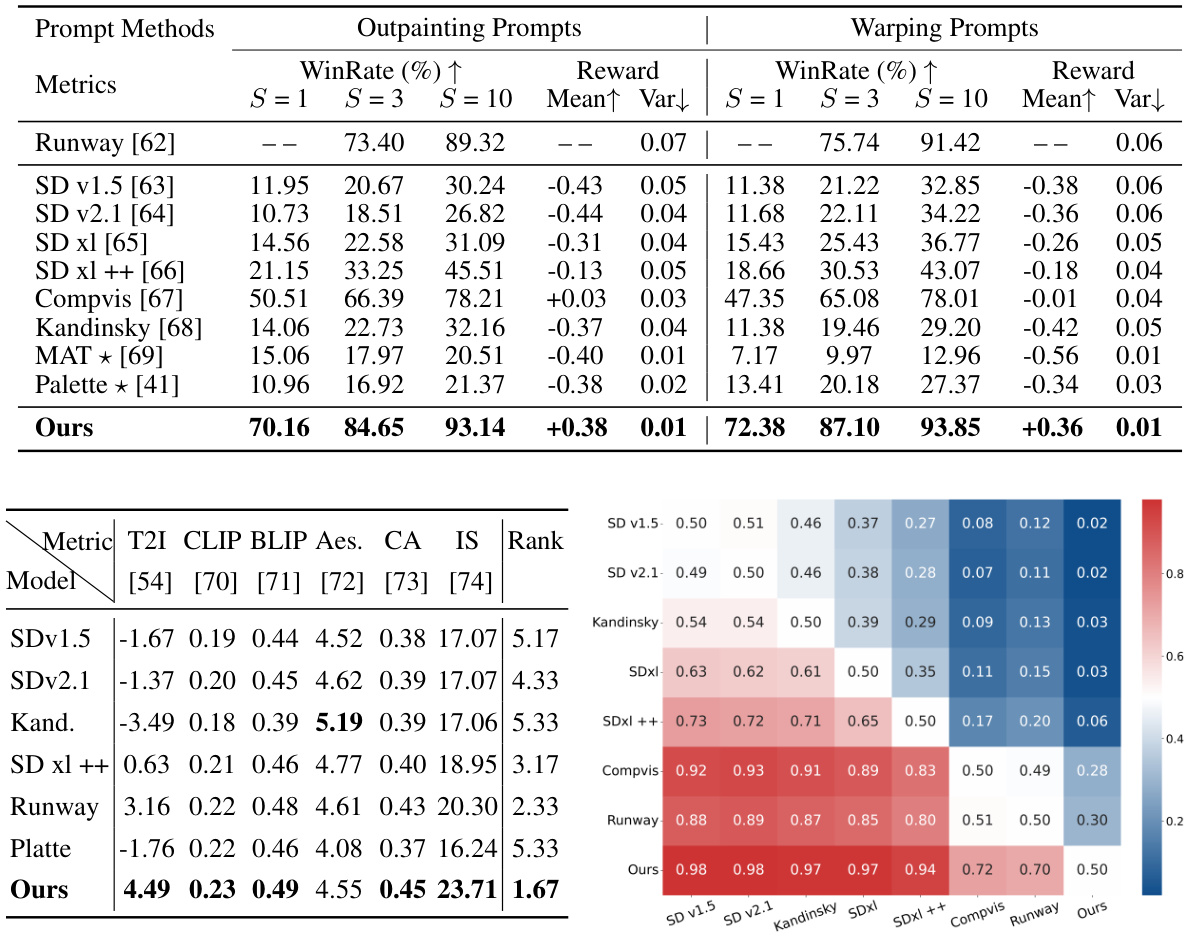
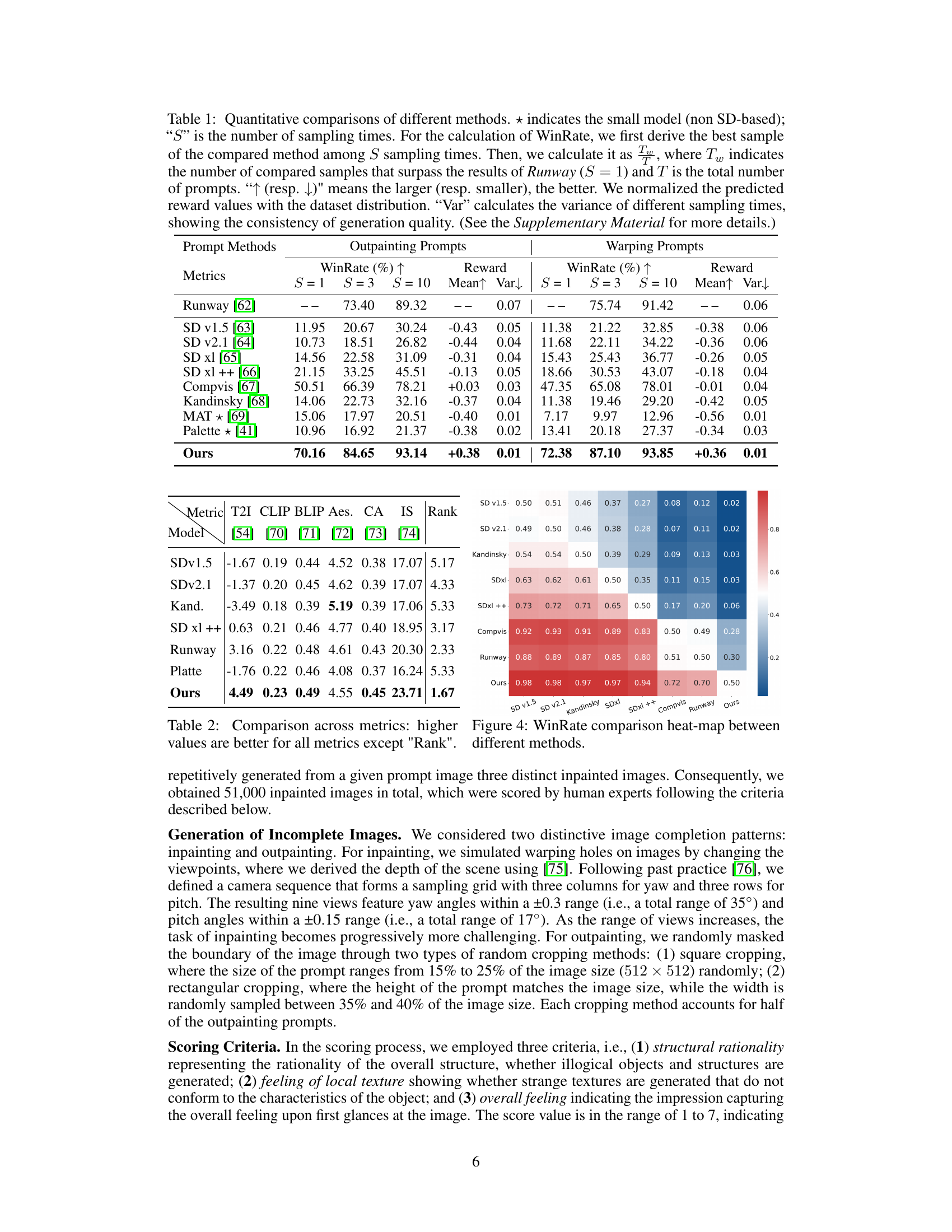
This table presents a quantitative comparison of different image inpainting methods, including the proposed PrefPaint model. It evaluates performance across several metrics: WinRate (percentage of samples surpassing Runway’s baseline), reward scores (normalized), mean reward, and variance of reward across multiple samples (S=1, S=3, S=10). The table highlights PrefPaint’s superior performance in terms of WinRate, mean reward, and consistency of results.
In-depth insights#
Human Preference Align#
Aligning AI models with human preferences is crucial for creating beneficial and trustworthy systems. The concept of “Human Preference Align” focuses on bridging the gap between AI-generated outputs and what humans find desirable or aesthetically pleasing. This involves developing methods to incorporate human feedback into the AI’s learning process, enabling it to learn and adapt to subjective preferences. Techniques like reinforcement learning can be employed, where a reward system guides the AI towards generating outputs that better match human expectations. However, challenges remain in accurately capturing and representing human preferences, which can be complex, diverse, and often implicit. Dataset bias, the difficulty of quantifying subjective measures, and the potential for overfitting to specific preferences are significant hurdles. Addressing these challenges is vital for creating AI systems that are not only technically proficient but also align with human values and societal needs.
RL Framework for IP#
An RL framework for image inpainting (IP) leverages reinforcement learning to enhance the quality and visual appeal of inpainted images. Instead of relying solely on direct pixel-wise comparisons, which often struggle with nuanced aesthetic judgments, this framework learns a reward model from a large dataset of human-annotated images. The model is then used to guide the training of a pre-trained diffusion model, iteratively refining its inpainting results toward higher reward values. This approach is particularly powerful because it allows the inpainting model to learn complex, subjective aspects of human aesthetic preferences, potentially exceeding the capabilities of methods that rely on objective metrics alone. Theoretical analysis of the reward model’s accuracy is crucial, providing confidence in the alignment process. Furthermore, the dataset of human-rated inpaintings is essential for training the reward model effectively. Ultimately, the RL framework offers a novel way to bridge the gap between objective image quality metrics and subjective human perception, leading to more visually pleasing and realistic inpainting results.
Reward Model Accuracy#
In reinforcement learning for aligning image inpainting models with human preferences, reward model accuracy is paramount. An inaccurate reward model will misguide the training process, leading to suboptimal results. Therefore, techniques to bound the error of the reward model are crucial; this allows for a better understanding of the confidence in reward estimations, improving the efficiency and accuracy of the reinforcement alignment. Furthermore, strategies such as reward trustiness-aware alignment can mitigate the impact of less reliable reward predictions by adjusting the regularization strength. Careful design and validation of the reward model, including its architecture, training data, and evaluation metrics, are vital for ensuring its accuracy. Ultimately, a high-fidelity reward model is critical for success in human preference-aligned generative modeling. The theoretical upper bound on the reward model error, as deduced in the paper, provides a confidence metric during the reinforcement learning process. This ensures that the alignment process is not overly influenced by erroneous reward signals, enabling a more robust and efficient learning process that closely reflects human aesthetic standards. The paper presents empirical validation of these theoretical bounds, demonstrating their practical implications.
Inpainting Diffusion#
Inpainting diffusion models represent a significant advancement in image inpainting, leveraging the power of diffusion probabilistic models. These models excel at generating realistic and coherent inpainted regions by gradually removing noise from a corrupted image, guided by the surrounding context. A key advantage is their ability to handle complex scenarios with large missing areas or irregular mask shapes, unlike older methods that often struggle with such conditions. The process involves progressively denoising an initial noisy image, learning to fill in missing parts while maintaining consistency with the existing texture and structure. Reinforcement learning techniques are often employed to further enhance performance by aligning model outputs with human aesthetic preferences, improving visual appeal and plausibility. However, challenges remain regarding computational cost and the subjective nature of aesthetic judgment. Future research should explore more efficient training methods and better ways to incorporate diverse user preferences for a more personalized and satisfying inpainting experience.
Future Directions#
Future research could explore several promising avenues. Improving the reward model’s robustness and accuracy is crucial, perhaps through incorporating more diverse human preferences and developing more sophisticated evaluation metrics. Enhancing the efficiency of the reinforcement learning process is also key, potentially through the development of more efficient algorithms or by leveraging transfer learning techniques. Extending the model’s capabilities to handle more complex inpainting tasks such as those involving large missing regions or significant image degradation, presents another significant challenge. Finally, investigating the theoretical guarantees of the proposed method and addressing limitations such as the computational cost and the potential for overfitting would strengthen its theoretical foundation and improve its generalizability. Ultimately, these efforts could significantly advance the capabilities of image inpainting models and their alignment with human aesthetic preferences.
More visual insights#
More on figures

This figure shows the experimental results related to the theoretical analysis of the reward model’s error. The x-axis represents the norm of the reward embedding vector (||z||v−1), while the y-axis shows the error in predicting the reward. The plot demonstrates that the reward prediction error has a positive correlation with the norm of the reward embedding vector, and that a dashed line acts as an upper bound of the error. This supports the theoretical findings presented in the paper, which establishes an upper bound on the reward model’s error.

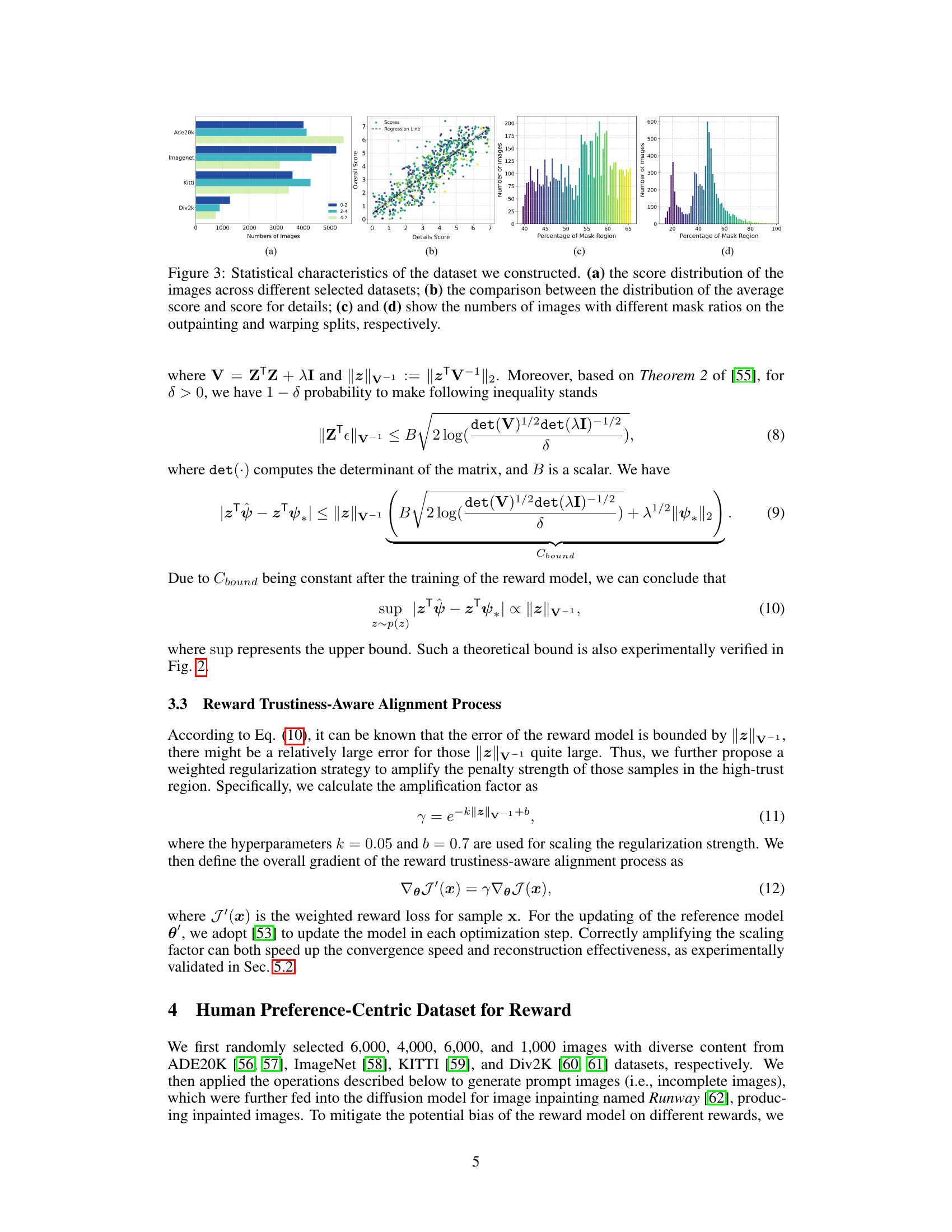
This figure presents the statistical characteristics of the dataset used in the PrefPaint model. Subfigure (a) shows the distribution of overall scores across four different datasets (ADE20k, ImageNet, KITTI, and DIV2k). Subfigure (b) displays a scatter plot comparing the overall score and the detail score for each image, showing their correlation. Subfigures (c) and (d) present histograms illustrating the distribution of the percentage of masked regions in the outpainting and warping image sets, respectively. These visualizations provide insights into the composition and characteristics of the dataset used for training and evaluating the PrefPaint model.

This figure presents a visual comparison of image inpainting results between the proposed method (PrefPaint) and several state-of-the-art (SOTA) methods. The comparison is done on various images with missing regions created through two different methods: warping and boundary cropping. Each row shows the same prompt image (the incomplete image with a missing part) followed by results from different inpainting models (Kandinsky, SD v1.5, SD v2.1, Palette, SD xl++, Compvis, Runway, and the proposed method PrefPaint). The use of the same random seeds ensures that differences are due solely to the models and not random variations in the generation process. The visual results demonstrate PrefPaint’s ability to generate inpainted images that are more aligned with human preferences.

This figure presents a visual comparison of image inpainting results between the Runway model and the PrefPaint model (the proposed method). Multiple examples are shown across various image categories (e.g., buildings, animals, cars), each demonstrating the improvement in visual appeal and quality achieved by aligning the diffusion model with human preferences using reinforcement learning. The differences highlight how PrefPaint generates more natural and contextually appropriate inpainted regions compared to the original Runway model, which sometimes produces less visually pleasing or unrealistic results.

This figure shows eight examples of novel view synthesis on the KITTI dataset using the proposed method. Each example consists of three images: (1) the prompt image which provides the input context for the inpainting task, (2) the given view which shows the original viewpoint before warping, and (3) the result which depicts the generated novel view after inpainting. The results demonstrate that the proposed method effectively fills missing or damaged parts of the images, providing plausible and consistent results.

This figure shows several examples of image inpainting results generated by the model, along with their associated reward scores. The purpose is to visually demonstrate the model’s ability to assess the quality of inpainting reconstructions based on human preferences. Each row presents a series of inpainting results for the same input, highlighting the variations in quality and the corresponding reward scores.

This figure shows the distribution of reward errors from the proposed reward model. The x-axis represents the reward errors, and the y-axis shows the number of samples with those errors. A visual representation shows that the majority of errors are clustered around zero, indicating a high level of accuracy in reward estimation.

This figure presents a visual comparison of image inpainting results between the ‘Runway’ model and the proposed PrefPaint model. It shows several examples of images with missing parts, along with the inpainting results produced by each method. The goal is to highlight the improved visual quality and aesthetic appeal of the inpainting generated by PrefPaint compared to the baseline Runway model, demonstrating the effectiveness of aligning the diffusion model with human preferences.

This figure showcases visual comparisons between the results obtained using the ‘Runway’ diffusion-based image inpainting model and the model aligned using the method proposed in the paper. It demonstrates the improvement in image quality and visual appeal achieved by aligning the model with human aesthetic preferences. The comparison is shown for several different images, illustrating that the proposed method consistently produces better results across various scenarios.

This figure shows a visual comparison of image inpainting results between the Runway model and the PrefPaint model proposed in the paper. The figure consists of several sets of images; in each set, the first image is the original prompt image (incomplete image with missing regions). The second image is the inpainting result generated by the Runway model and the third image is the inpainting result generated by the PrefPaint model. The comparison aims to highlight the improvements in visual appeal and quality achieved by aligning the diffusion model with human preferences using the proposed reinforcement learning approach.

This figure presents a visual comparison of image inpainting results between the Runway model and the PrefPaint model (the authors’ proposed method). The figure showcases several examples across various image categories, each showing the original image with a masked region, the Runway inpainting result, and the PrefPaint inpainting result. The purpose is to visually demonstrate the improved quality and visual appeal of the inpainting results achieved by aligning the diffusion model with human preferences, as proposed by the PrefPaint method.

This figure presents a visual comparison of image inpainting results between the Runway model and the proposed PrefPaint model. The figure shows several examples of images with missing parts, followed by the inpainting results produced by each model. The purpose is to illustrate the improvement in visual quality and alignment with human aesthetic standards achieved by PrefPaint compared to the baseline Runway model. Each row displays a different image scenario with the prompt (input), and then the results of the Runway model followed by the PrefPaint model. This visual comparison showcases the superiority of the proposed model in generating visually pleasing and coherent inpainted images.

This figure shows the results of applying the proposed image FOV enlargement method on two different scenes. The left side of each pair displays the input prompt image (the given image), while the right side showcases the enlarged output image produced by the method. The white dashed lines in the output images highlight the boundary of the original input prompt.

This figure presents a visual comparison of image inpainting results between the Runway model and the PrefPaint model (the authors’ proposed method). It shows several examples of images with missing parts, and for each example it displays side-by-side the inpainting results produced by both the Runway model and the PrefPaint model. The goal is to demonstrate the improvement in the quality and visual appeal of the inpainted images achieved by aligning the diffusion model with human preference using the proposed reinforcement learning framework. The image categories represented are diverse, and the results clearly show that the PrefPaint model produces visually more plausible and aesthetically pleasing results than the Runway model.

This figure shows a visual comparison of image inpainting results between the Runway model and the PrefPaint model (the authors’ proposed method). For several different images and prompts (different scenes and missing sections), the figure shows three columns: the original incomplete image, the inpainting result from the Runway model, and the inpainting result from the PrefPaint model. The goal is to demonstrate the improved visual quality and aesthetic appeal achieved by aligning the diffusion model with human preferences using the PrefPaint approach.

This figure shows a visual comparison of image inpainting results between the Runway model and the PrefPaint model proposed in the paper. Multiple image examples across different categories (e.g., buildings, animals, cars) are shown. For each category, the left column displays the results obtained by the Runway model, and the right column shows the results generated by the PrefPaint model. The goal of the figure is to visually demonstrate the improved quality and visual appeal of the inpainted images produced by PrefPaint, which aligns the inpainting results more closely with human aesthetic preferences.

This figure shows a visual comparison of image inpainting results between the Runway model and the PrefPaint model (the model proposed in the paper). For several different images and prompts (e.g., a building, an animal, and cars), the figure displays three inpainted versions side by side: the original Runway result, a result from a baseline model (Runway), and a result from the PrefPaint model. The visual difference shows how the PrefPaint model, guided by human preferences, improves upon the quality and visual appeal of the inpainted images compared to the baseline method.

This figure in the Appendix of the paper shows examples of image inpainting results with their corresponding scores and explanations, illustrating the assessment criteria related to the ‘Feeling of Local Texture’. The scores range from 0 to 7, with higher scores indicating better quality and consistency with objective facts. Each example highlights a specific aspect of texture quality, such as the presence of unrealistic textures, partially incomplete objects, or overall consistency of texture with surrounding elements.

This figure presents a visual comparison of image inpainting results between the Runway model and the PrefPaint model proposed in the paper. The figure displays several examples, each showing the same incomplete image (prompt) followed by the inpainting generated using the Runway model and then the PrefPaint model. The comparison aims to demonstrate the improvement in visual appeal and quality achieved by aligning the diffusion model with human preferences, as implemented in the PrefPaint method.

This figure displays a visual comparison of image inpainting results between the Runway model and the PrefPaint model (the authors’ proposed method). It shows several examples of images with masked regions, and the results of inpainting those regions using both models. The purpose is to visually demonstrate the improvement in visual quality and realism achieved by the PrefPaint method, which aligns the image inpainting diffusion model with human aesthetic preferences. Each row represents a different image, with the ‘Runway’ results shown first, and then the improved results produced by the PrefPaint model.

This figure shows several examples of image inpainting results generated by the model, along with the associated reward scores. The reward scores are based on human preferences, and the figure illustrates the model’s ability to evaluate the quality of the inpainting results based on these preferences.

This figure shows the labeling platform used in the paper. Each group of images consists of three different inpainting results (reconstructions 1, 2, and 3) and the original prompt image (the incomplete image). The platform allows annotators to provide scores based on three criteria: structural rationality, feeling of local texture, and overall feeling. These scores are used in the training of the reward model.

This figure shows a visual comparison of image inpainting results between the Runway model and the model developed by the authors using their proposed method. The figure is structured in rows, each row representing a different image with missing sections, and within each row, there are multiple columns showing the results from both methods. The goal is to demonstrate how the authors’ approach improves the quality and visual appeal of inpainted images. The improvements are visible across various scenarios, suggesting a generally superior performance for image inpainting.

This figure shows a visual comparison of image inpainting results between the Runway model and the proposed PrefPaint model. For several different images with missing sections, it displays side-by-side comparisons of the results from both models. The goal is to highlight the improved visual quality and aesthetic appeal of the inpainting achieved by the PrefPaint model, which aligns with human preferences.

This figure shows a visual comparison of image inpainting results between the Runway model and the proposed PrefPaint model. For several different image prompts (different scenes and objects), it displays the original incomplete image, the inpainting result from the Runway model, and the inpainting result from the PrefPaint model. The goal is to highlight the improvement in visual quality and aesthetic appeal achieved by aligning the diffusion model with human preferences using the reinforcement learning approach described in the paper.

This figure demonstrates the effectiveness of the proposed method for image field-of-view (FOV) enlargement. Nine different scenes are shown, each with its corresponding prompt image (cropped to the center) and the enlarged result generated using the method. The results demonstrate that the proposed method can consistently produce meaningful and visually pleasing enlargements across diverse image styles, including paintings, nature photography, and even Chinese paintings.

This figure shows eight examples of novel view synthesis on the KITTI dataset. Each example includes three images: the prompt (input), the warped given view, and the reconstructed result from the PrefPaint model. The warped given view shows the missing regions that the model is tasked with inpainting. The results demonstrate the model’s ability to generate realistic and coherent novel views from incomplete inputs.

This figure shows eight examples of novel view synthesis using the PrefPaint model on the KITTI dataset. Each example displays three images: the original prompt image (a warped image with missing parts), the original ‘given’ view from which the prompt was created, and the inpainting result produced by PrefPaint. The figure demonstrates the model’s ability to generate plausible and coherent novel viewpoints, especially in challenging scenes with irregular and large missing areas.
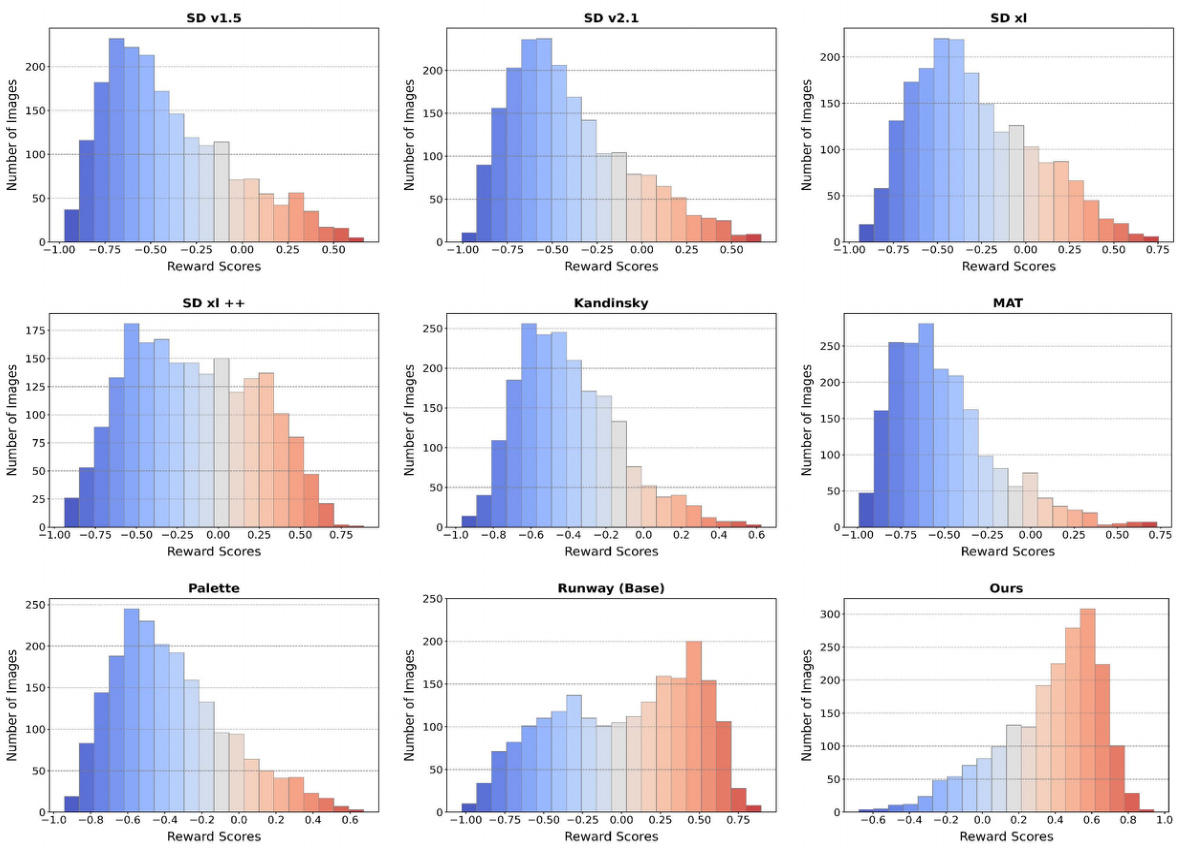
This figure shows the detailed score statistics of the proposed dataset, broken down by different datasets (ADE20K, KITTI, ImageNet, and Div2k) and inpainting types (Warping and Outpainting). Each subfigure is a histogram representing the distribution of reward scores for a specific dataset and inpainting type. The histograms visualize the frequency of different score ranges, providing insights into the overall quality distribution of the inpainted images and the balance of various scores within the dataset. This analysis helps in understanding the characteristics of the dataset used to train the reward model and assessing the reliability of the reward model’s predictions.

This figure provides a visual comparison of the image inpainting results generated by the proposed method and several state-of-the-art (SOTA) methods. The results are shown for both outpainting (boundary cropping) and inpainting (warping) scenarios. Each row represents a different prompt image, and the columns show the results from different methods, including the proposed PrefPaint, alongside methods like Kandinsky, SD v1.5, Palette, SD xl++, Compvis, and Runway. The use of the same random seeds for all methods helps to isolate the impact of the different algorithms on the quality of the generated images. The figure is intended to showcase the visual improvements achieved by the proposed PrefPaint model compared to other established models.

This figure presents a visual comparison of the image inpainting results produced by the proposed method and several state-of-the-art (SOTA) methods. The top row shows the original prompt images, with subsequent rows displaying the inpainting results from different methods, including the proposed method. The figure highlights the differences in image quality and visual appeal. The different inpainting methods are compared side by side for the same prompt, allowing for direct visual comparison and illustrating the relative strengths of each technique. Half of the prompts were generated by warping and the other half by boundary cropping, showing that our method works for both.
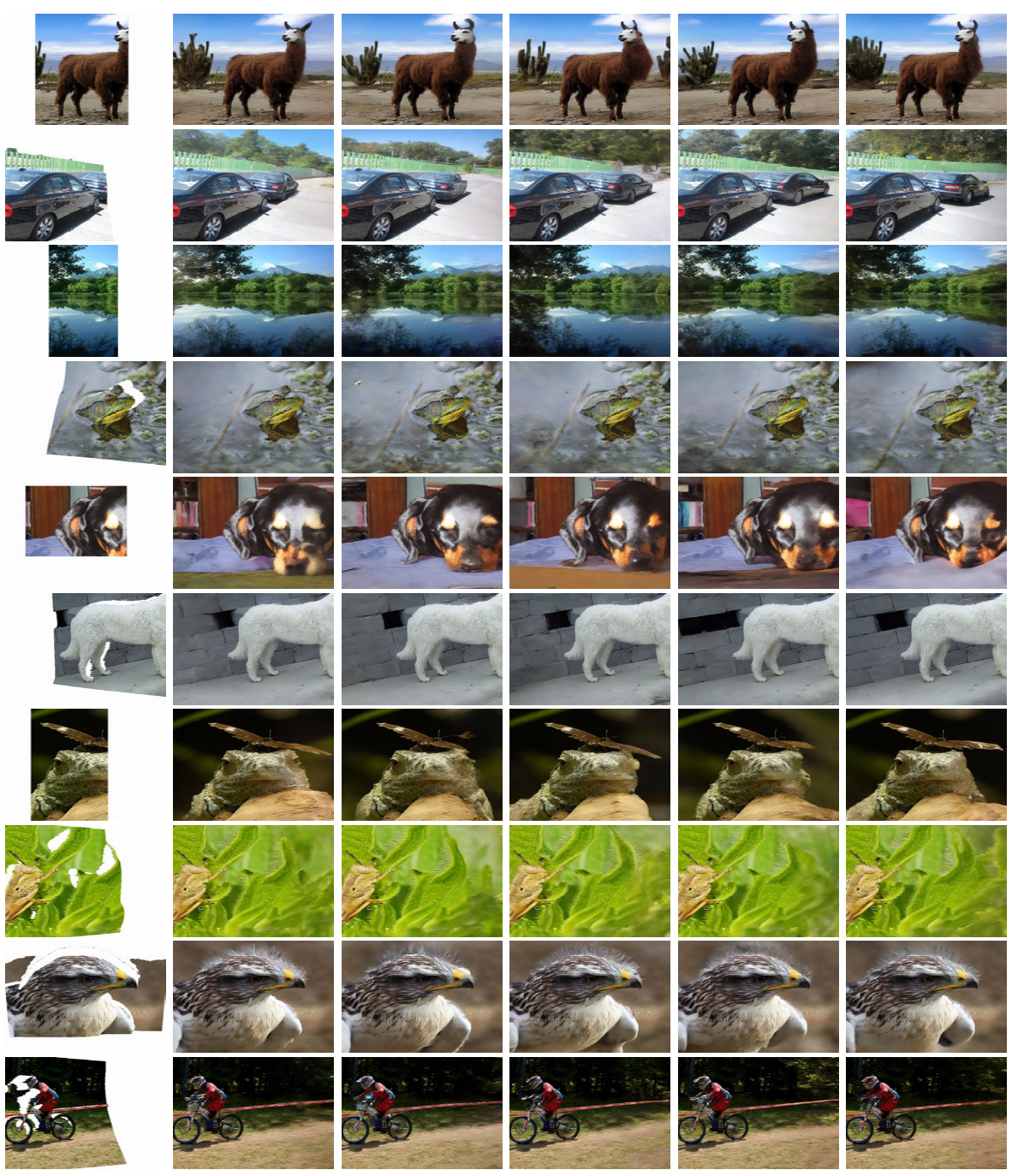
This figure shows the results of running the proposed image inpainting method 5 times with different random seeds. Each row represents a different prompt image, and each column represents one of the five runs. The consistency of the results across the different runs demonstrates the robustness and stability of the proposed method.

This figure shows the training curves for four different experimental setups: BaseLine, 1.4BaseLine, 1.4Boundary, and Ours. The x-axis represents the number of training steps, and the y-axis represents the mean rewards. The curves show that the 1.4Boundary (Ours) approach converges faster than the other approaches, reaching a mean reward of around 0.35 earlier than the others. This indicates that the proposed method is more efficient in terms of training time.
More on tables
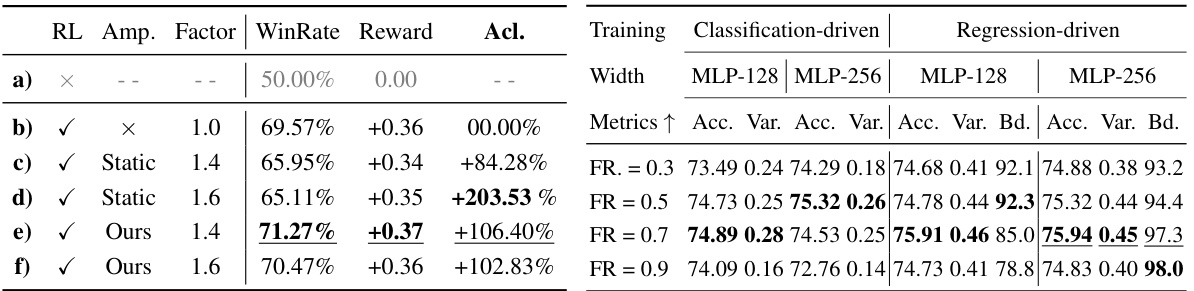
This table presents a quantitative comparison of different image inpainting methods, including the proposed PrefPaint model. Metrics such as WinRate (percentage of times a method outperforms Runway), reward scores (mean and variance), and other quantitative measures (S=1, S=3, S=10) are compared across various methods for both outpainting and warping prompts. The table also provides context for interpreting WinRate and details on the normalization and variance calculations.
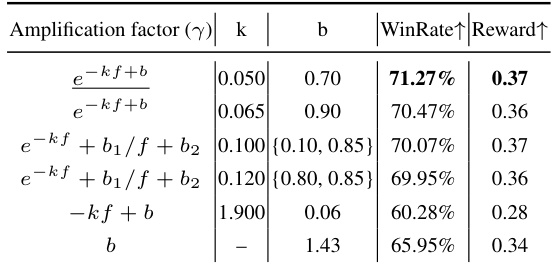
This table presents a quantitative comparison of different image inpainting methods, including the proposed PrefPaint model. The comparison uses several metrics across two types of prompts (outpainting and warping). Key metrics include WinRate (percentage of samples where the method outperforms Runway), mean reward score (normalized), and variance of reward scores (reflecting consistency). The table allows for a direct comparison of the performance and consistency of various methods.

This table provides a quantitative comparison of different image inpainting methods, including the proposed PrefPaint method. It uses several metrics to evaluate the performance, such as WinRate (comparing to Runway), reward, and variance across multiple sampling attempts. Higher values generally indicate better performance. The table also provides a breakdown of results for different types of prompts (outpainting and warping).
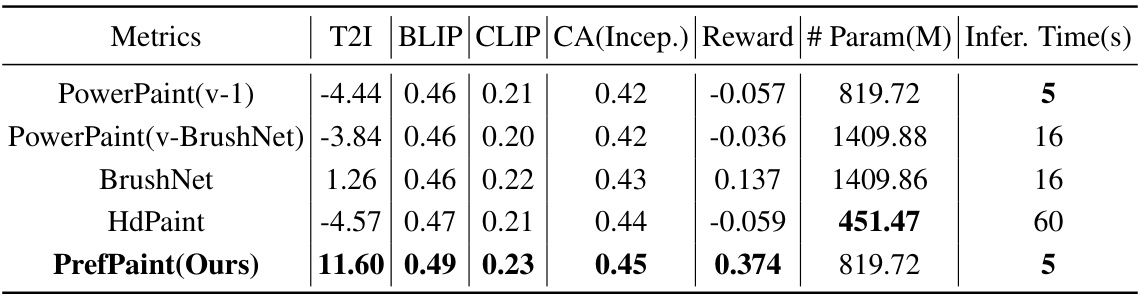
This table presents a quantitative comparison of different image inpainting methods, including the proposed PrefPaint method. It uses several metrics to evaluate performance across different prompt types (outpainting and warping) and varying numbers of sampling times (S). WinRate measures the percentage of samples surpassing the baseline Runway model, while Reward shows the average normalized reward score. The variance (Var) indicates the consistency of generation quality across multiple samples.
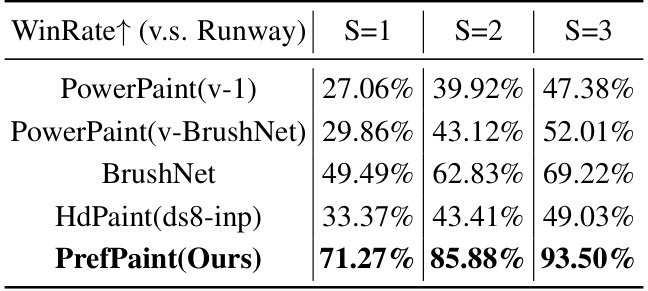
This table quantitatively compares the performance of the proposed PrefPaint method against several state-of-the-art (SOTA) image inpainting methods. Key metrics include WinRate (the percentage of times the method outperforms Runway, a baseline model), reward scores (a measure of aesthetic quality), and the variance of these scores across multiple samplings. The table provides a comprehensive comparison across different prompting scenarios and highlights the proposed method’s improved performance in terms of both quality and consistency.
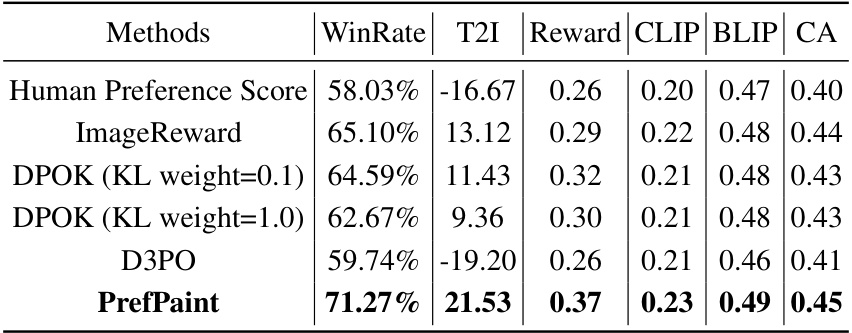
This table presents a quantitative comparison of different image inpainting methods, including the proposed PrefPaint method. It evaluates performance using metrics such as WinRate (percentage of times the method outperforms Runway), reward scores (normalized), and variance of reward scores across multiple sampling attempts. The table highlights PrefPaint’s superior performance, particularly its high WinRate and low variance, indicating its robustness and consistent generation of high-quality images.
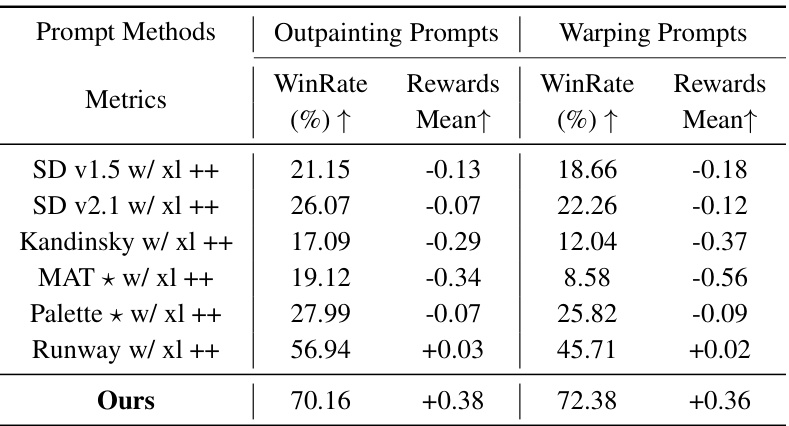
This table presents a quantitative comparison of different image inpainting methods, including the proposed PrefPaint method. The metrics used are WinRate (percentage of times the method outperforms Runway), reward (mean reward score), and variance of reward scores across multiple sampling runs (reflecting consistency). The table shows that PrefPaint significantly outperforms other methods in terms of WinRate and reward, while also demonstrating higher consistency. The * indicates models not based on Stable Diffusion.
Full paper#