↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Current large multimodal models (LMMs) process visual data sequentially, leading to high computational costs, especially for high-resolution images. This limits the scalability and efficiency of LMMs for various applications. Many prior works try to solve the problem using token compression or other trade-off solutions, but the fundamental issues of sequentially processing remain unsolved.
DeepStack offers a novel solution by vertically stacking visual tokens and feeding them into different transformer layers, a bottom-up approach in contrast to the existing left-to-right structure. This allows processing multiple times more visual tokens than conventional methods with the same context length, significantly improving performance across multiple benchmarks. The simple yet effective DeepStack architecture demonstrates significant improvements with minimal additional cost, making it a promising direction for future multimodal model development.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces a novel and efficient approach to handling visual data in large multimodal models. It addresses a key limitation in current LMMs by significantly improving the ability to process high-resolution images without increasing computational costs. This opens up new avenues for research into more efficient and powerful multimodal models, particularly relevant given the increasing prevalence of high-resolution visual data.
Visual Insights#
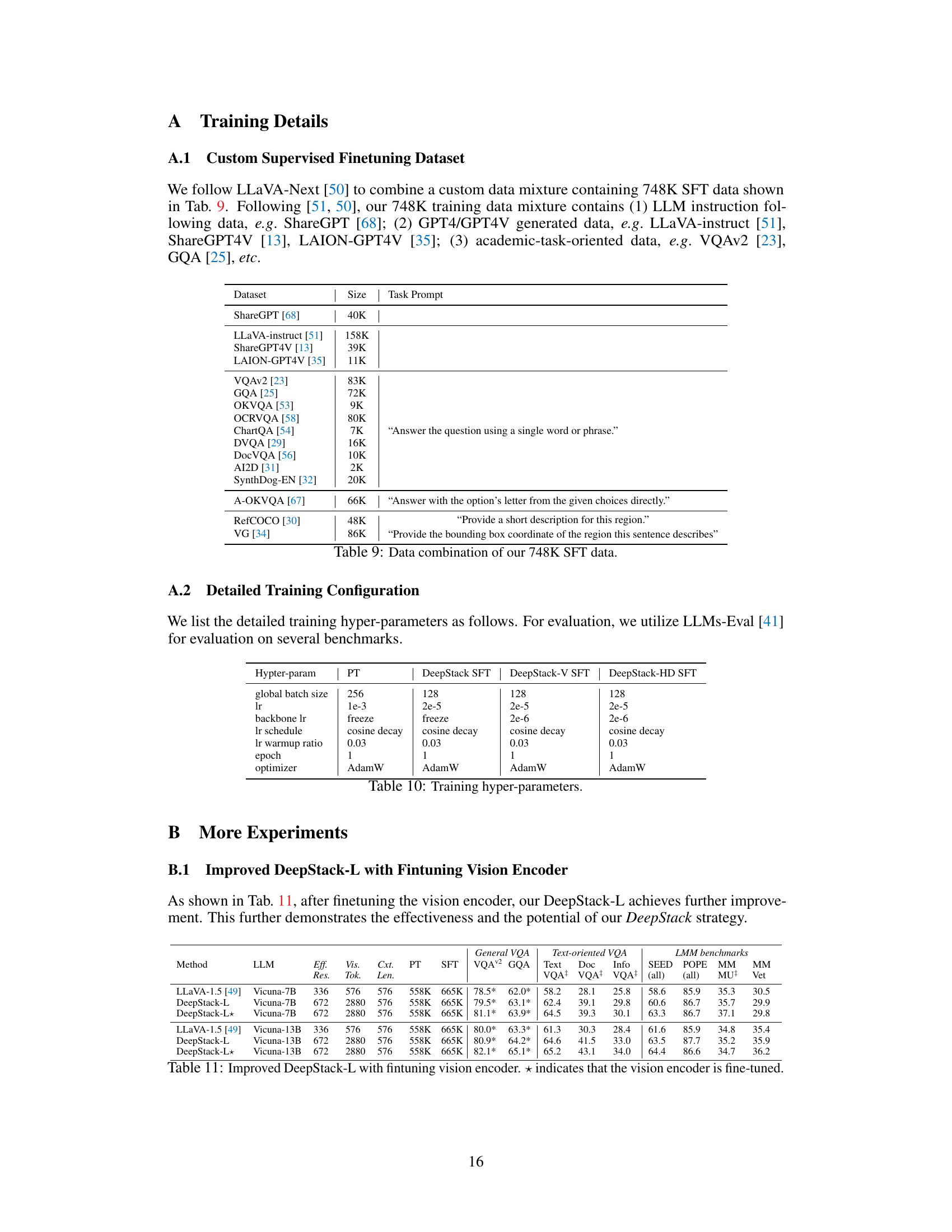
This figure compares three different approaches for handling visual tokens in large multimodal models (LMMs). The left panel shows the conventional method, where visual tokens are linearly concatenated into a sequence and fed into the LLM. The middle panel illustrates the DeepStack approach, which stacks visual tokens in a grid-like structure and feeds them into different transformer layers of the LLM using residual connections. The right panel presents the performance comparison of DeepStack with the conventional method, showing significant improvements. DeepStack uses fewer visual tokens and context length to surpass the sequential LMM and match the one using much longer contexts.
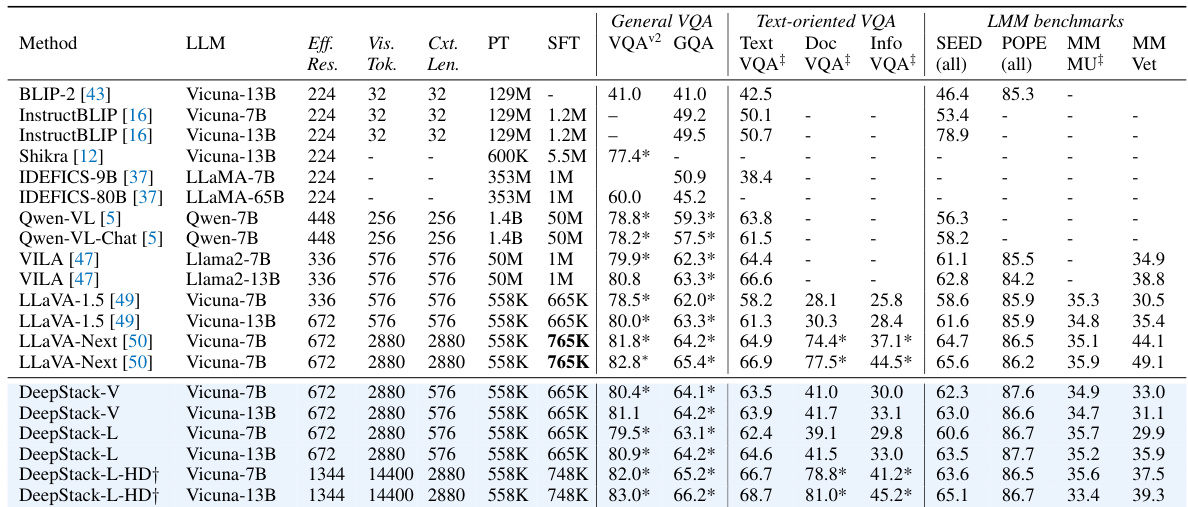
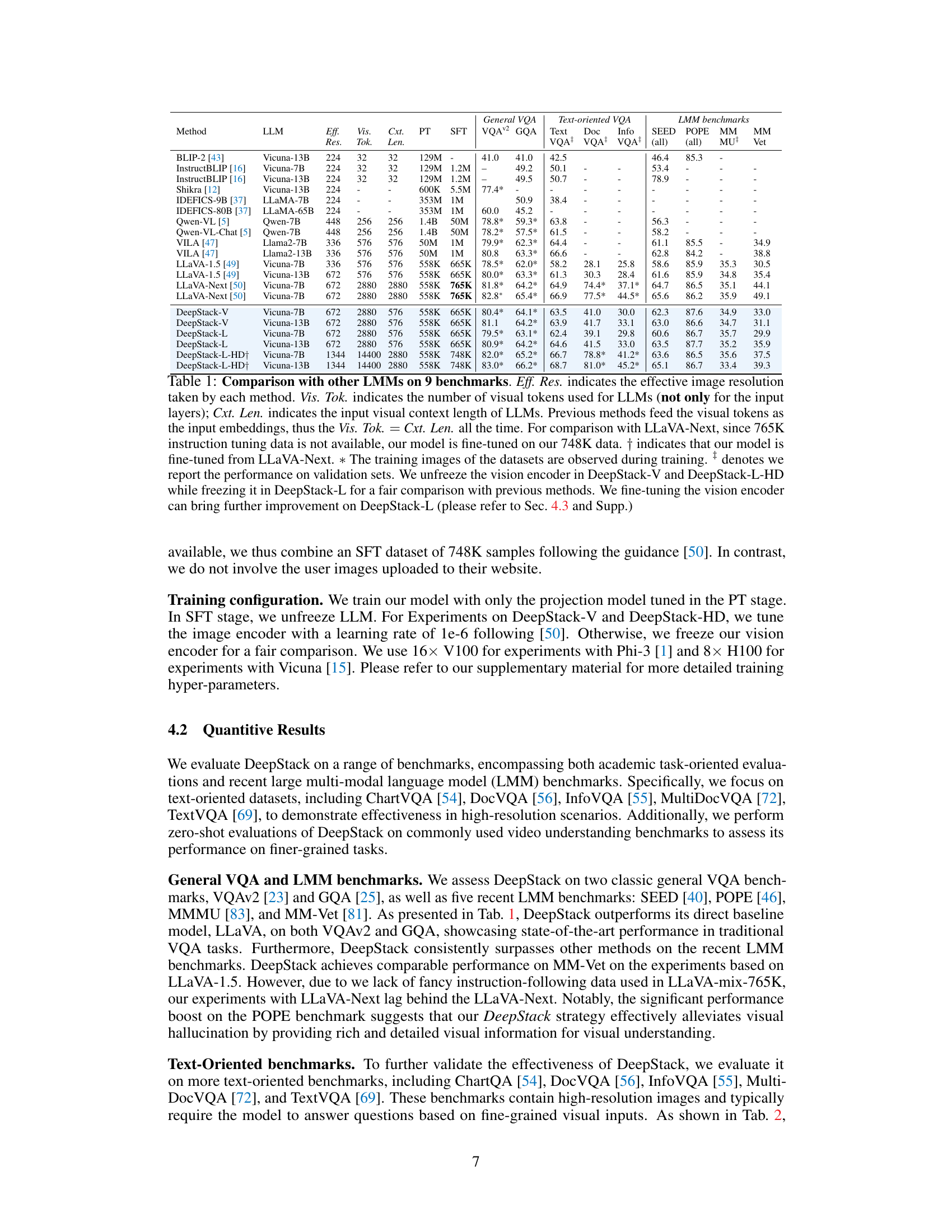
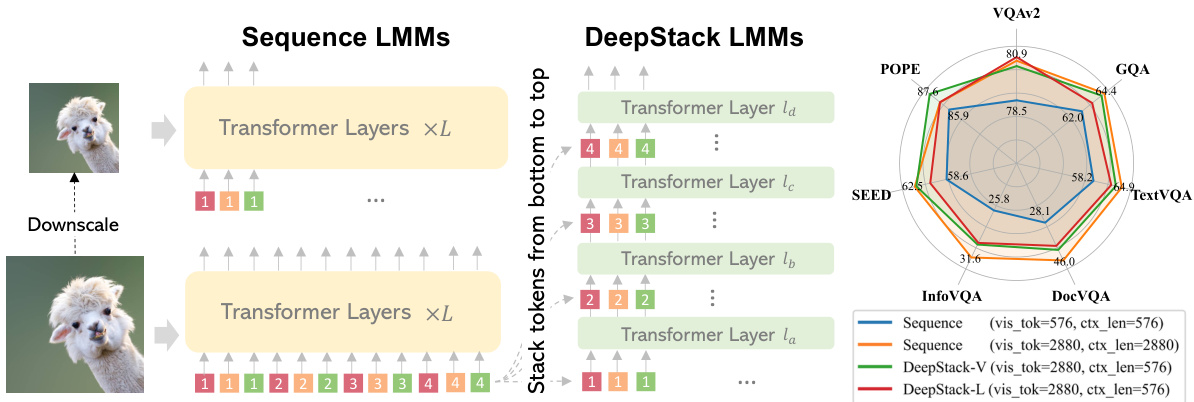
This table compares the performance of DeepStack with other Large Multimodal Models (LMMs) on nine benchmark datasets. It shows the effective resolution, number of visual tokens, context length, and performance metrics (VQAv2, GQA, TextVQA, DocVQA, InfoVQA, SEED, POPE, MM-MU, MM-Vet) for various models. Noteworthy is the comparison of DeepStack with different configurations (DeepStack-V, DeepStack-L, DeepStack-L-HD) and the impact of finetuning the vision encoder.
In-depth insights#
DeepStack’s Design#
DeepStack’s design ingeniously tackles the computational burden of processing numerous visual tokens in large multimodal models (LMMs). Instead of the conventional sequential approach, where visual tokens are strung together as a linear sequence, DeepStack adopts a layered stacking strategy. This involves grouping visual tokens into sets and feeding each set into a corresponding transformer layer within the LLM, proceeding from bottom to top. This approach is surprisingly effective because it leverages the inherent hierarchical structure of LLMs, distributing the processing of visual information across multiple layers. By intelligently stacking high and low resolution visual tokens, DeepStack enhances both local and global context understanding, resulting in significant performance gains, especially on tasks involving high-resolution images. This design is particularly noteworthy for its simplicity and efficiency. It requires minimal architectural changes to existing LLMs and yet achieves impressive results, making DeepStack a promising and practical approach for improving LMM performance.
Improved Tokenization#
Improved tokenization in large language models (LLMs) is crucial for effectively processing visual information. This involves efficiently encoding images into numerical representations that LLMs can understand. Traditional methods often suffer from limitations in capturing fine-grained details or handling high-resolution images, leading to reduced accuracy and increased computational costs. DeepStack, however, addresses this by proposing a hierarchical stacking of visual tokens, which are infused into the LLM at various layers. This method allows the model to process significantly more visual tokens than traditional sequential approaches without dramatically increasing context length. The improved tokenization strategy enables the LLM to effectively model complex visual interactions and relationships across layers, leading to substantial performance improvements on a range of benchmarks. Key to this success is the inherent hierarchical structure of the LLM itself, which DeepStack leverages rather than attempting to flatten visual inputs into a 1D sequence. Furthermore, DeepStack shows how strategically sampling high-resolution features and integrating them into deeper layers significantly boosts performance, demonstrating the importance of understanding not just the quantity but also the quality and placement of visual tokens within the LLM architecture.
Benchmark Results#
A dedicated ‘Benchmark Results’ section would ideally present a comprehensive evaluation of the proposed DeepStack model against state-of-the-art Large Multimodal Models (LMMs). Quantitative results, presented in tables and charts, should clearly show performance across various benchmarks, including general image understanding tasks (like VQA) and specialized ones (e.g., document analysis, video understanding). The choice of benchmarks should be justified, demonstrating their relevance to the model’s capabilities. Crucially, clear comparisons with baseline models and other LMMs are needed, highlighting DeepStack’s advantages. The discussion should not merely list numbers, but interpret the findings thoughtfully. For instance, it should analyze whether DeepStack’s gains are consistent across different image types or task complexities, and explain the potential reasons for its success or limitations. Statistical significance should be rigorously addressed. Finally, the inclusion of qualitative results or analysis could further strengthen the section, providing concrete examples of the model’s performance and its limitations in specific scenarios.
Ablation Studies#
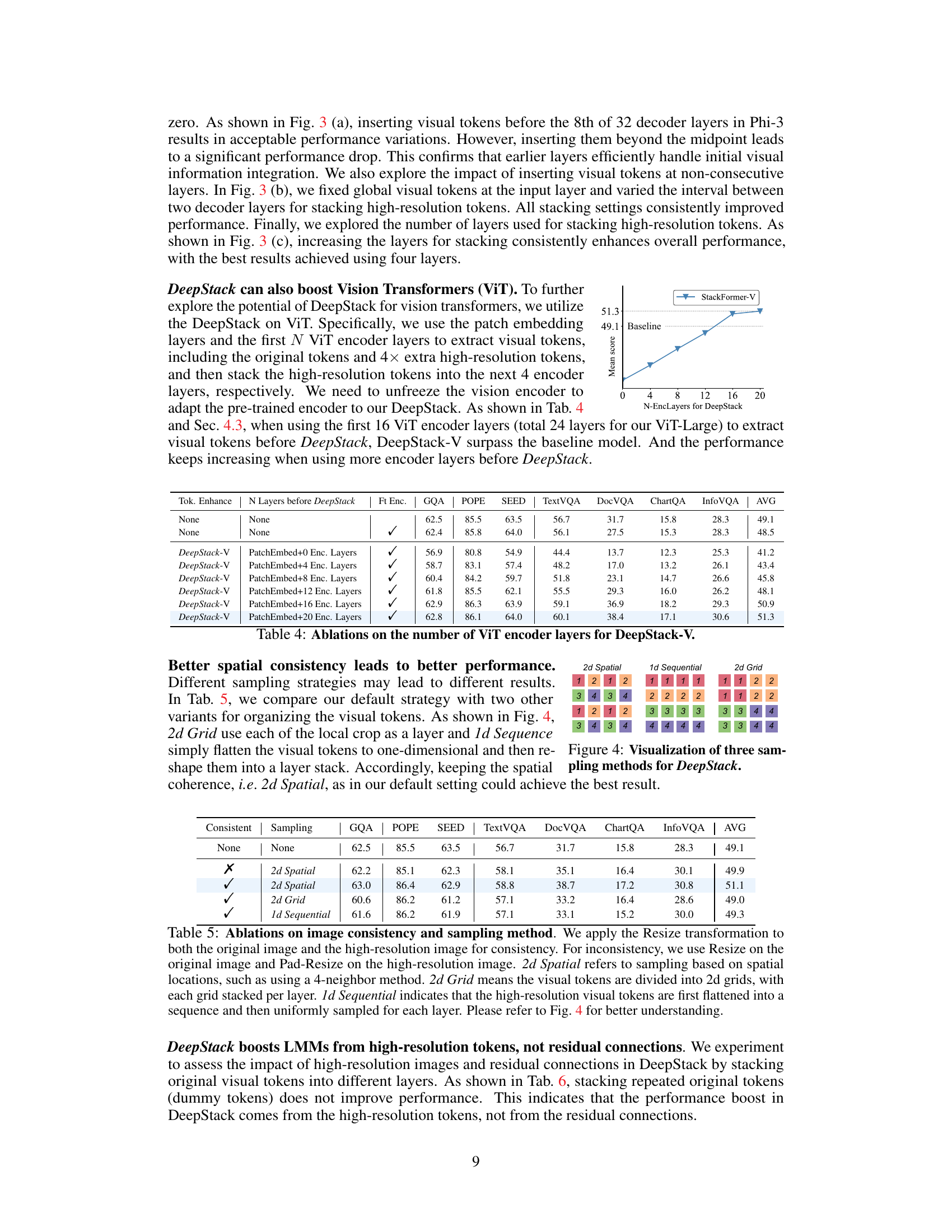
Ablation studies systematically remove components of a model to understand their individual contributions. In the context of a research paper on a novel multimodal model, such studies would be crucial. For example, removing the high-resolution visual token stream might reveal whether this is essential for the model’s performance improvements. Similarly, one could analyze the effect of removing the DeepStack strategy altogether. A comparison between the full model, the model without the high-resolution stream, and the model without DeepStack would highlight the impact of each component. Ideally, the paper would quantify the impact of these ablations using metrics relevant to the task(s) the model is designed for. The results of these ablation studies will determine the importance and effectiveness of each component, revealing the core contributions of the proposed model, and helping to validate design decisions. Furthermore, ablation studies can reveal potential redundancies or areas for future improvements, directing research towards more efficient or robust architectures.
Future Directions#
Future research could explore several promising avenues. DeepStack’s effectiveness on various LLM architectures beyond those tested (e.g., applying it to decoder-only or encoder-decoder models) warrants investigation. Further exploration of optimal visual token sampling and stacking strategies is crucial for maximizing performance and efficiency. This includes investigating different sampling methods and the impact of varying the number of stacked layers. Combining DeepStack with other LMM improvements such as advanced token compression techniques, multi-modal pre-training methods, or improved vision encoders could yield significant performance gains. Additionally, exploring DeepStack’s applications in diverse multimodal tasks beyond those examined is essential to establish its broad applicability. Finally, in-depth analysis on the theoretical underpinnings of DeepStack and a more comprehensive understanding of why this simple method is surprisingly effective would contribute valuable insight to future LMM design.
More visual insights#
More on figures
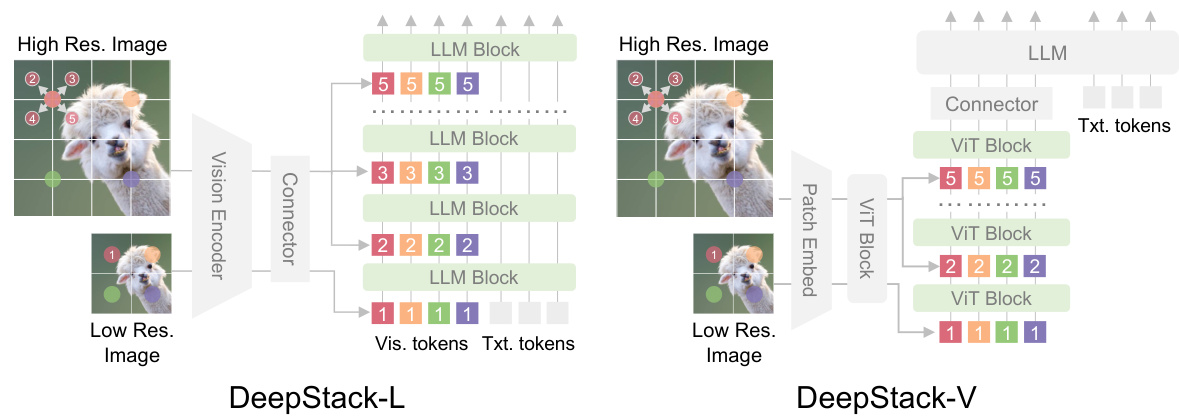
This figure illustrates the DeepStack architecture applied to both LLMs and Vision Transformers (ViTs). For LLMs, a low-resolution image is processed, and its tokens are fed to the input layer. High-resolution tokens are extracted from the same image, organized into a stack, and infused into subsequent LLM layers via residual connections. The ViT version uses a similar strategy, feeding the visual tokens into various ViT layers instead of LLM layers. This demonstrates how DeepStack integrates multi-resolution visual information across multiple layers for improved multimodal understanding.

This figure illustrates the DeepStack architecture. It shows how visual tokens are processed in two different ways: one for Large Language Models (LLMs) and one for Vision Transformers (ViTs). In both cases, DeepStack enhances the input visual tokens by dividing image feature extraction into two streams: a global-view stream and a high-resolution stream. The global-view stream provides an overview of the image, while the high-resolution stream adds fine-grained details by stacking dilated high-resolution image features across different layers. This dual-stream approach increases the efficiency and improves understanding of fine-grained details.

This figure illustrates the DeepStack architecture for both LLMs and Vision Transformers (ViTs). For LLMs, it shows how low-resolution image tokens are fed into the initial layer, while high-resolution tokens, organized in a layered structure (DeepStack), are infused into subsequent layers via residual connections. The ViT version shows a similar approach, but with visual tokens fed into various ViT encoder layers. The figure highlights the core concept of DeepStack: integrating high-resolution visual details throughout the model without increasing the context length.
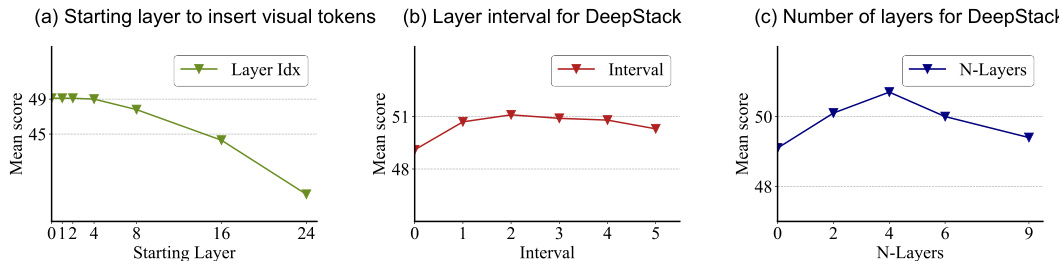
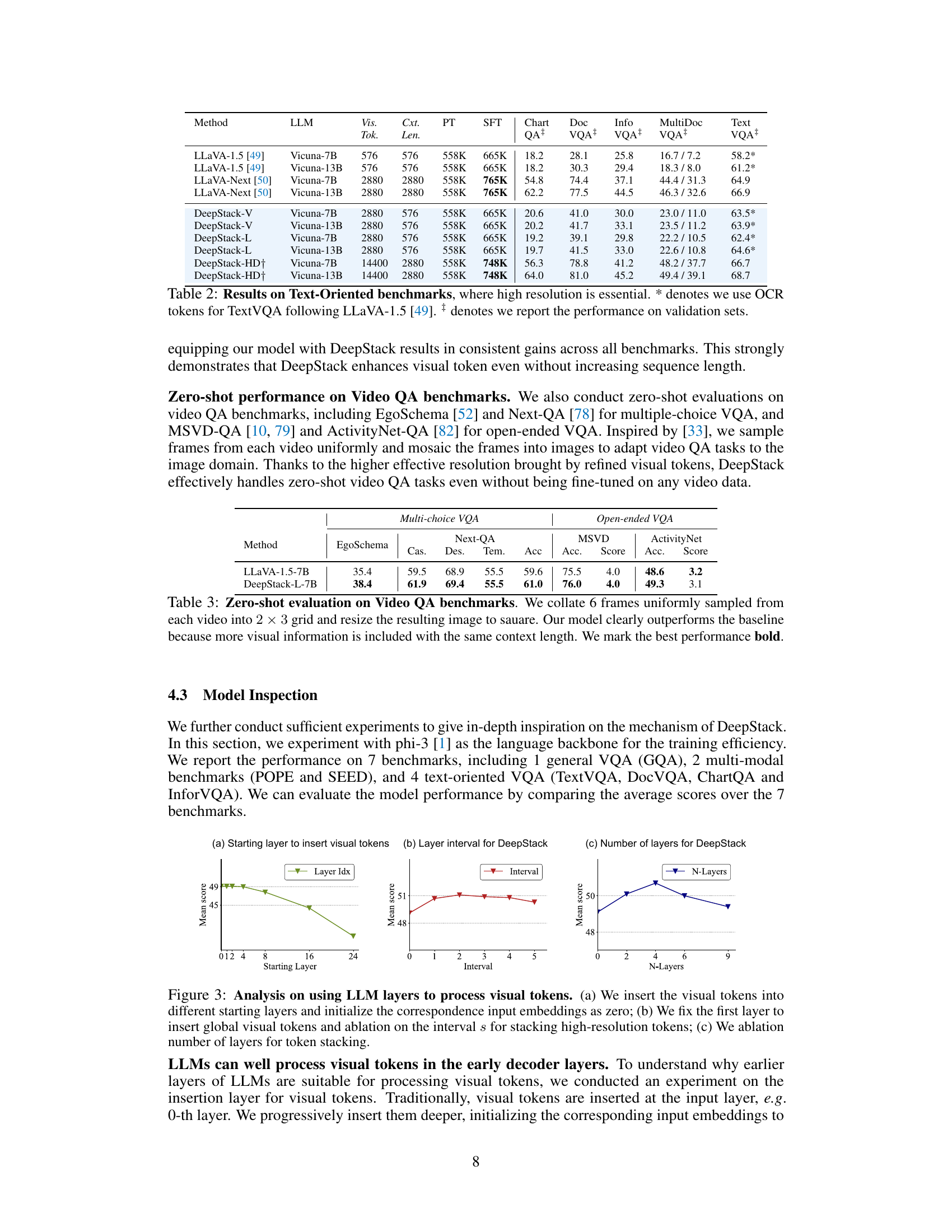
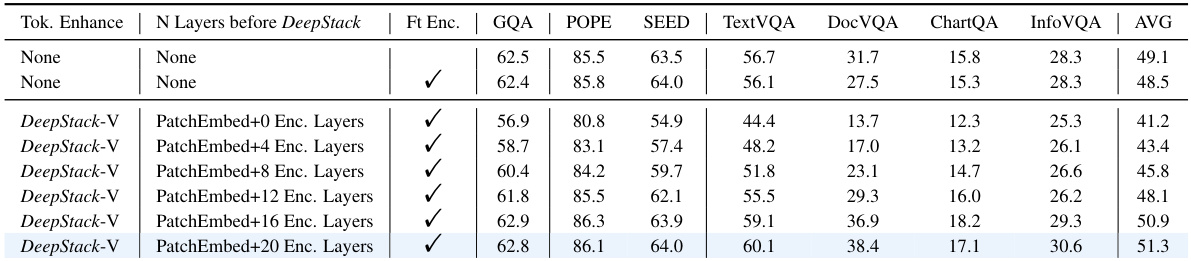
The figure shows the ablation studies on different aspects of DeepStack. Specifically, it investigates the impact of (a) inserting visual tokens into different starting layers of LLMs, (b) varying the interval between layers for stacking high-resolution tokens, and (c) changing the number of layers used for stacking. The results demonstrate the effect of these variations on the model’s overall performance.
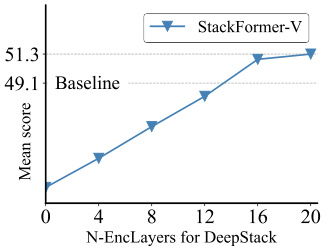
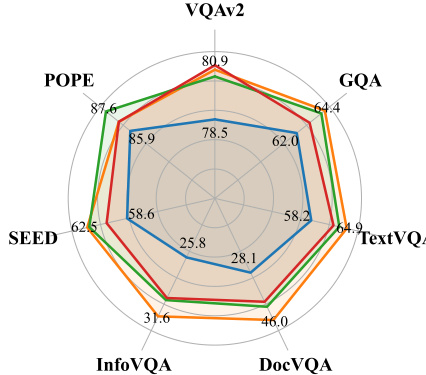
This figure shows a comparison between LLaVA-1.5 and DeepStack on several visual question answering tasks. The top part highlights specific examples where DeepStack outperforms LLaVA-1.5 by correctly identifying details requiring high resolution and fine-grained understanding. The bottom section presents a radar chart summarizing the performance of both models across multiple benchmarks, demonstrating DeepStack’s superior accuracy in detailed visual captioning.
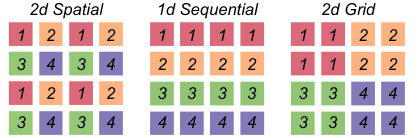
This figure illustrates the DeepStack architecture for both LLMs and Vision Transformers (ViTs). The left side shows how DeepStack integrates low and high-resolution visual tokens into different layers of an LLM. High-resolution tokens are extracted from the image and arranged in a grid structure that is sequentially fed to subsequent transformer layers. The right side demonstrates a similar approach for ViTs, but with visual tokens fed into the ViT layers.

This figure illustrates the core concept of DeepStack. The left panel shows traditional LMMs processing visual tokens as a sequence, while the middle panel introduces DeepStack, which stacks tokens into a grid and feeds them into different transformer layers. The right panel presents a comparison of DeepStack’s performance against conventional LMMs and highlights its ability to handle significantly more visual tokens and achieve superior results.

This figure illustrates the core concept of DeepStack, a novel architecture for Large Multimodal Models (LMMs). The left panel shows the traditional approach of linearly processing visual tokens. The middle panel demonstrates DeepStack’s method of stacking visual tokens into a grid and integrating them into multiple transformer layers. The right panel presents a comparison of DeepStack’s performance against traditional methods, highlighting its ability to handle significantly more visual tokens while maintaining comparable or superior accuracy.
This figure illustrates the core idea of DeepStack, a novel architecture for Large Multimodal Models (LMMs). The left panel shows the traditional approach of processing visual tokens as a sequence, limiting the number of tokens that can be handled. The middle panel demonstrates DeepStack’s method of stacking visual tokens into a grid and injecting them into multiple transformer layers, significantly increasing capacity without modifying the context length. The right panel provides a comparison of DeepStack’s performance against traditional methods on various benchmarks, showing significant improvements.
More on tables

This table compares the performance of DeepStack with other Large Multimodal Models (LMMs) across nine benchmarks. It details the effective image resolution, number of visual tokens, context length, and performance metrics (VQAv2, GQA, SEED, POPE, MM-MU, MM-Vet, TextVQA, DocVQA, InfoVQA) for various models, highlighting the improvements achieved by DeepStack. Key differences in training data and vision encoder fine-tuning are also noted.

This table presents the zero-shot performance of LLaVA-1.5-7B and DeepStack-L-7B on video question answering (VQA) benchmarks. The benchmarks are categorized into multi-choice and open-ended VQA tasks. For each benchmark, the table shows the accuracy (Acc) and score achieved by each model. The results demonstrate that DeepStack-L-7B outperforms LLaVA-1.5-7B on most benchmarks, highlighting its ability to effectively handle video data.
This table compares the performance of DeepStack with other Large Multimodal Models (LMMs) across nine benchmarks. It shows various metrics including effective resolution, number of visual tokens, context length, and performance scores on several tasks (VQAv2, GQA, SEED, POPE, MM-MU, MM-Vet, TextVQA, DocVQA, and InfoVQA). Key differences in training data and model configurations are also noted.

This table compares the performance of DeepStack with other Large Multimodal Models (LMMs) across nine benchmarks. It shows the effective image resolution, number of visual tokens, context length, and performance metrics (e.g., VQAv2, GQA, TextVQA) for each model. The table highlights DeepStack’s ability to handle significantly more visual tokens while maintaining comparable or superior performance to other methods, especially when considering context length.

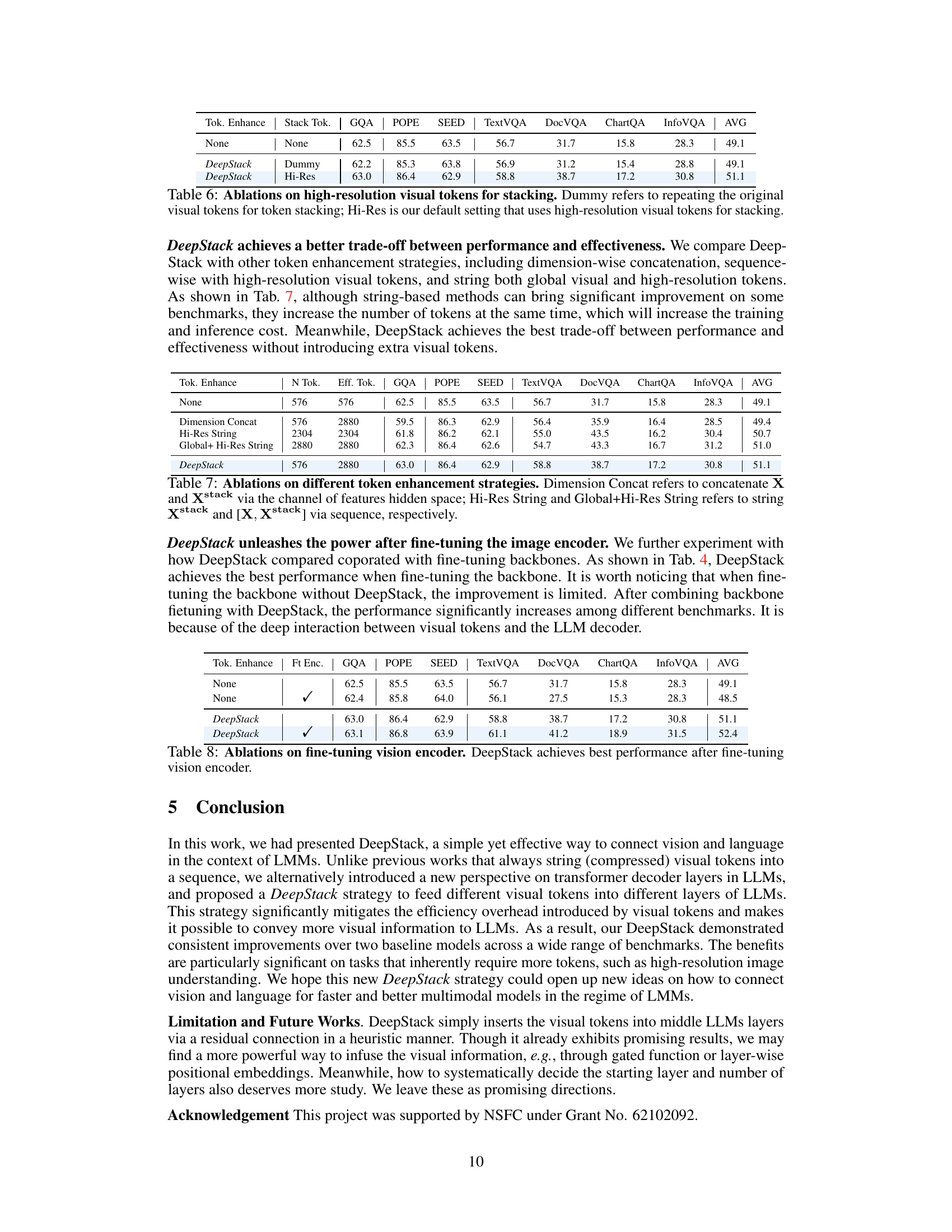
This table presents ablation studies on the impact of using high-resolution visual tokens versus dummy (repeated original) tokens within the DeepStack framework. It compares the performance across various benchmarks (GQA, POPE, SEED, TextVQA, DocVQA, ChartQA, InfoVQA) when using either dummy tokens or high-resolution tokens for stacking in the DeepStack method. The results demonstrate that utilizing high-resolution tokens significantly improves the performance compared to using dummy tokens.

This table compares the performance of DeepStack with other Large Multimodal Models (LMMs) across nine benchmarks. It shows the effective image resolution, the number of visual tokens, context length, and performance metrics (e.g., VQAv2, GQA, TextVQA) for each model. Key differences in training data and vision encoder fine-tuning are also noted. The table highlights DeepStack’s superior performance, especially when using a shorter context length.

This table compares the performance of DeepStack with other Large Multimodal Models (LMMs) across nine benchmark datasets. It shows the effective resolution, number of visual tokens, and context length used by each model. Key performance metrics are presented for each model on each benchmark, highlighting DeepStack’s improvements, particularly when using a shorter context length. The table also notes differences in fine-tuning datasets and vision encoder freezing/unfreezing.

This table compares the performance of DeepStack with other Large Multimodal Models (LMMs) across nine benchmarks. It shows the effective resolution, number of visual tokens, context length, pre-training data size, supervised fine-tuning data size, and performance on various VQA and LMM tasks. The table highlights DeepStack’s improved performance, particularly with fewer visual tokens, showcasing the effectiveness of the proposed approach.
This table compares the performance of DeepStack with other Large Multimodal Models (LMMs) on nine benchmark datasets. It shows the effective resolution, number of visual tokens, context length, pre-training data size, and supervised fine-tuning data size for each model. Key performance metrics across various VQA and LMM benchmarks are presented, highlighting DeepStack’s superior performance, especially when using a shorter context length. Note that some differences in training data and fine-tuning between DeepStack and other methods exist.

This table compares the performance of DeepStack with other Large Multimodal Models (LMMs) across nine benchmark datasets. It shows metrics such as effective image resolution, number of visual tokens, context length, and performance scores on various VQA and LMM tasks. The table highlights DeepStack’s improved performance, especially when considering the context length.
Full paper#