↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Current multi-person pose estimation methods often struggle with identifying specific individuals and providing comprehensive representations (pose and mask). This is particularly challenging in unconstrained environments, where there is significant clutter and occlusion. Existing approaches typically rely on two-stage paradigms or heuristic grouping, leading to suboptimal performance and high computational costs. Moreover, these methods lack the ability to directly predict results based on user-friendly prompts such as text or scribbles.
To address these challenges, the paper introduces Referring Human Pose and Mask Estimation (R-HPM). They introduce a novel dataset, RefHuman, which extends the MS COCO dataset with text and positional prompt annotations. Further, a novel end-to-end promptable approach, UniPHD, is proposed. UniPHD uses a multimodal encoder to extract representations from the image and prompts and utilizes a pose-centric hierarchical decoder to generate identity-aware pose and mask predictions specifically for the target individual specified by the prompt. Extensive experiments demonstrate that UniPHD significantly outperforms state-of-the-art approaches on their proposed task and achieves top-tier performance on established benchmarks.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces a novel task of referring human pose and mask estimation, addresses limitations of existing pose estimation methods, and proposes a new benchmark dataset and a promptable model for this task. It opens new avenues for research in human-centric AI applications such as assistive robotics and sports analysis, and its findings will be of great interest to researchers in computer vision and related fields.
Visual Insights#

This figure compares multi-person pose estimation with the proposed referring human pose and mask estimation (R-HPM). (a) shows the traditional approach where a model outputs multiple pose estimations, and a selection strategy (like non-maximum suppression or NMS) is needed to choose the best result. This can lead to missed detections or incorrect selections. (b) illustrates R-HPM, a unified model that directly predicts the pose and mask of the target person specified by the user using either a text, point, or scribble prompt, eliminating the need for post-processing selection steps and leading to more accurate and comprehensive results.
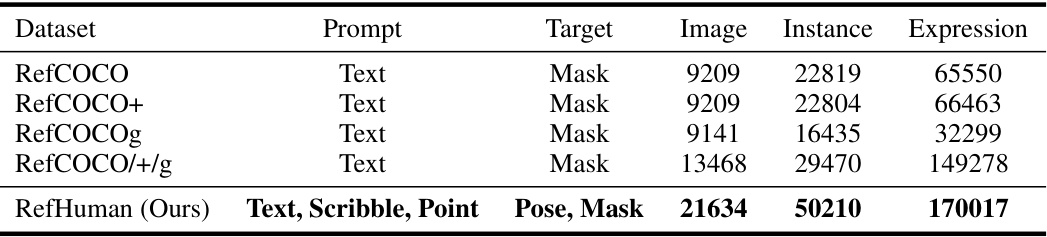
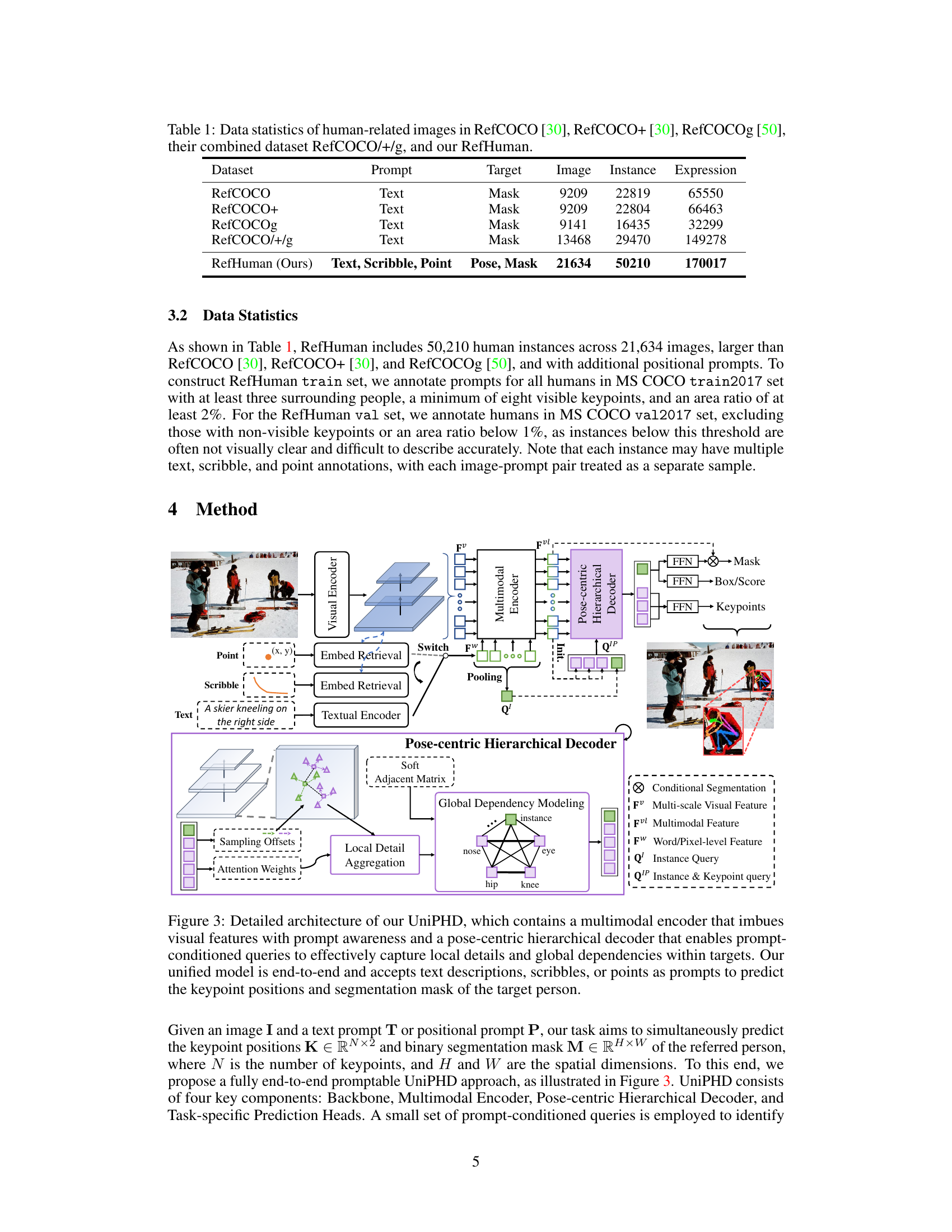
This table presents a comparison of the statistics of human-related images across several datasets, including RefCOCO, RefCOCO+, RefCOCOg, the combined RefCOCO/+/g dataset, and the new RefHuman dataset introduced in this paper. For each dataset, it shows the number of images, instances (individual humans), and expressions (text, scribble, or point annotations). The table highlights that RefHuman is significantly larger than the existing datasets, offering a much more extensive resource for research on human pose and mask estimation.
In-depth insights#
RefHuman Dataset#
The RefHuman dataset, a crucial contribution, significantly expands existing resources like MS COCO by incorporating over 50,000 human instances with detailed annotations. Its novelty lies in the inclusion of multimodal prompts, such as text, scribbles, and points, enabling research on referring human pose and mask estimation. This makes it uniquely suited for advancing human-AI interaction and related applications. The dataset’s large scale and diverse range of scenarios (captured ‘in the wild’) address limitations of existing datasets, making it more realistic and challenging for model development. The annotation process, though costly, leverages a human-in-the-loop approach with large language models to enhance efficiency and consistency. The careful design and annotation process, including the automation of scribble generation, ensures high-quality data essential for reliable evaluation and benchmarking. The dataset’s potential impact extends beyond immediate applications, paving the way for future advancements in human-centric vision tasks reliant on multimodal understanding.
UniPHD Approach#
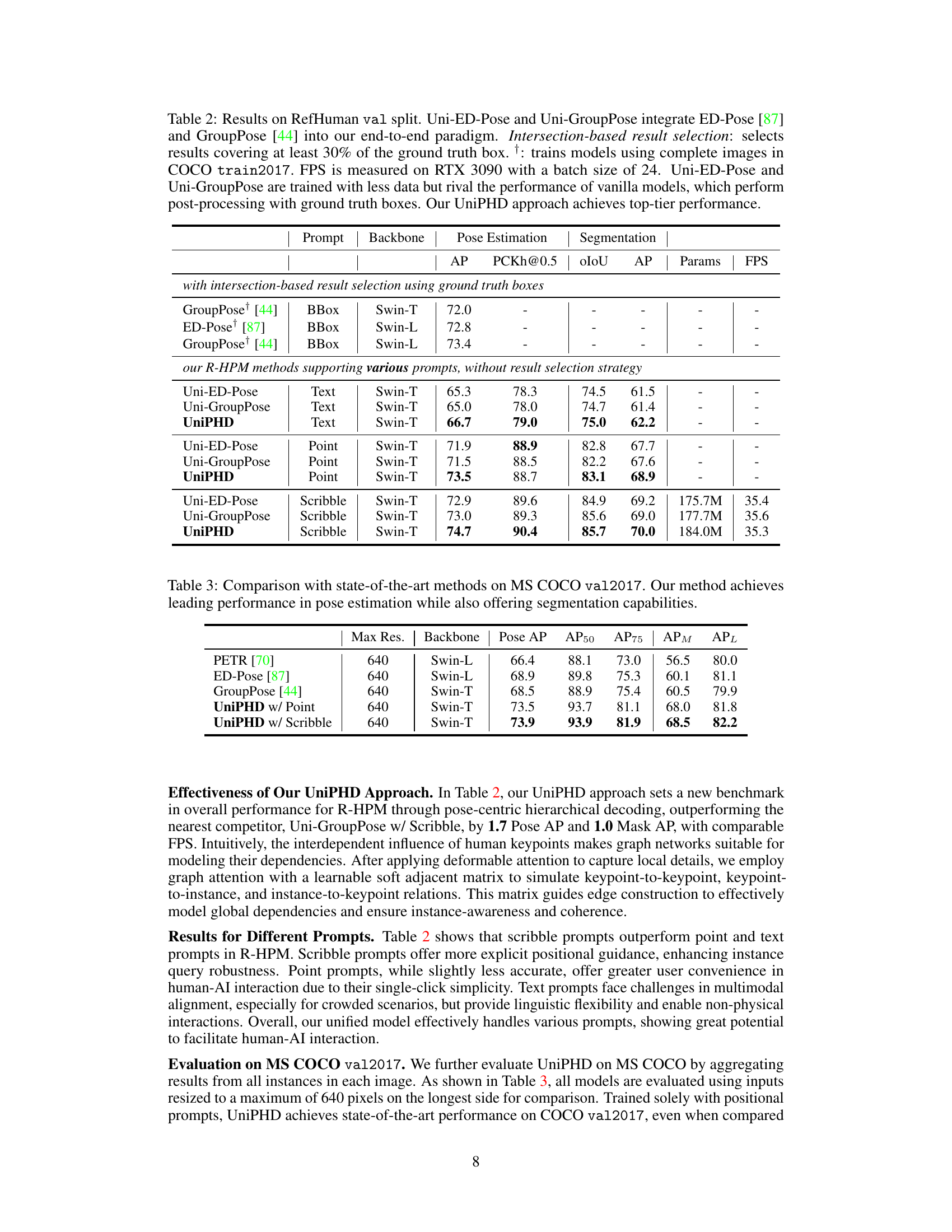
The UniPHD approach, a novel end-to-end promptable method for Referring Human Pose and Mask Estimation (R-HPM), is presented as a significant advancement. Its core innovation lies in the pose-centric hierarchical decoder (PHD), which processes both instance and keypoint queries simultaneously, resulting in identity-aware predictions. This hierarchical structure effectively handles both local details and global dependencies, a key feature that differentiates it from previous two-stage approaches. The multimodal encoder expertly fuses visual and prompt features (text or positional) enabling the network to efficiently understand and respond to various prompt types. UniPHD’s promptable nature is highlighted as a major advantage, enabling user-friendly interaction and avoiding cumbersome post-processing steps. The system’s capacity to simultaneously predict human pose and masks provides a more comprehensive understanding compared to traditional pose estimation alone. Its end-to-end design and integration with existing transformer-based architectures make it highly adaptable and efficient. The top-tier performance demonstrated on benchmark datasets strongly validates the effectiveness of the UniPHD architecture and overall approach.
Prompt Encoding#
Prompt encoding is a crucial step in any system processing natural language instructions, especially in the context of multimodal tasks like referring human pose and mask estimation. A well-designed prompt encoder is essential for effectively capturing the semantic meaning of the user’s input, whether it is textual, scribble, or point-based. The choice of encoder architecture significantly impacts the system’s ability to understand the intent and correctly identify the target person. For textual prompts, pre-trained language models like RoBERTa offer powerful capabilities for extracting semantic features. However, these models need to be carefully adapted to fit the specific task and dataset. For positional prompts (scribbles or points), it’s important to effectively convert spatial information into meaningful features for downstream processing. Techniques like retrieving embeddings directly from visual features based on spatial locations or using Bézier curves to represent scribbles offer viable approaches. The challenge lies in seamlessly integrating textual and positional features to create a unified multimodal representation. This often requires attention mechanisms or other sophisticated fusion techniques to capture the interdependencies between modalities. Ultimately, the quality of the prompt encoding directly influences the accuracy and robustness of the overall system, determining its capability to accurately predict human pose and mask based on diverse and often ambiguous user inputs.
Ablation Studies#
Ablation studies systematically remove components of a model to assess their individual contributions. Thoughtful design is crucial, isolating variables to understand impact. In a pose estimation model, for example, this could involve removing specific attention mechanisms, decoder layers, or loss functions. By observing the effects on performance metrics (like accuracy and speed), researchers gain insights into architectural choices and the effectiveness of different components. Results reveal which parts are essential and identify areas for improvement or simplification. Well-executed ablation studies strengthen a paper’s claims by providing empirical evidence supporting the model’s design choices, demonstrating the importance of each component, and justifying its complexity or relative simplicity.
Future Work#
Future research directions stemming from this work could explore several promising avenues. Extending the RefHuman dataset with even more diverse scenarios and prompt types would significantly improve model robustness and generalization. Improving the efficiency of the UniPHD model is crucial; exploring architectural optimizations and model compression techniques could reduce computational costs without sacrificing performance. A key area for investigation is enhancing the model’s handling of complex scenes with significant occlusion or ambiguous identities. Investigating alternative query mechanisms and refining the pose-centric hierarchical decoder could improve this aspect. Finally, the application of R-HPM to real-world assistive robotics scenarios warrants further investigation. Developing reliable and robust interaction methods between the system and users would pave the way for practical applications in healthcare and other fields.
More visual insights#
More on figures
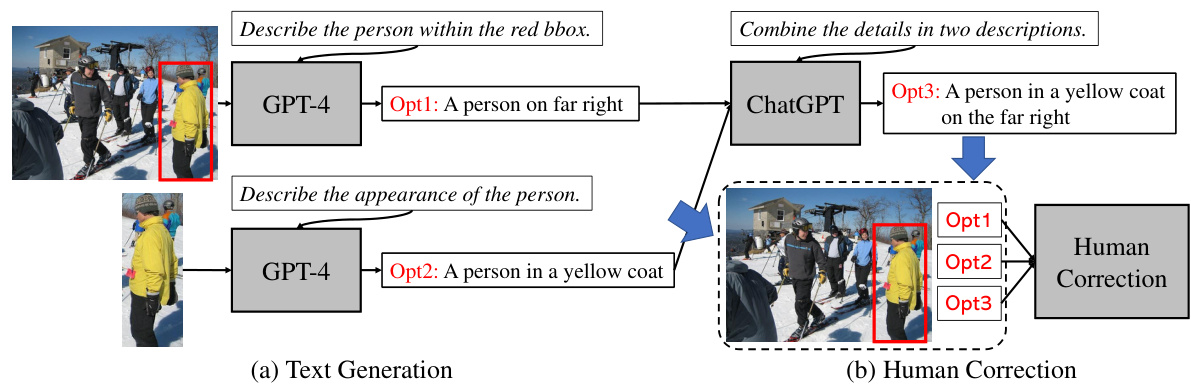
This figure illustrates the process of generating text prompts for the RefHuman dataset using a human-in-the-loop approach with GPT. First, GPT-4 generates a description considering the entire image (Opt1). Then, a cropped version focusing on the target person is fed to GPT-4 for a more detailed description (Opt2). These two descriptions are combined (Opt3), and finally, a human corrects and refines the generated description to ensure accuracy and comprehensiveness. This iterative process ensures high-quality and diverse text prompts for the dataset.

This figure illustrates the architecture of the UniPHD model. The model takes an image and a prompt (text, scribble, or point) as input. A multimodal encoder fuses visual and prompt features. A pose-centric hierarchical decoder, with global dependency modeling and local detail aggregation, uses prompt-conditioned queries to predict keypoint positions and a segmentation mask for the specified person. The decoder uses a soft adjacent matrix to model relationships between keypoints and the instance.

This figure contrasts multi-person pose estimation with the proposed Referring Human Pose and Mask Estimation (R-HPM) task. (a) shows the limitations of traditional multi-person pose estimation, highlighting the need for post-processing steps (like Non-Maximum Suppression) to select the correct pose from multiple predictions. (b) illustrates the R-HPM approach, which uses a single model and a textual or positional prompt to directly identify and extract both pose and mask for the specified person, removing the need for post-processing and providing a more complete representation.

This figure shows several qualitative results of the UniPHD model on various challenging scenarios, showcasing its ability to accurately predict human pose and mask using different types of prompts (text, point, scribble). The results demonstrate that the model can effectively handle challenging situations like crowded scenes, occlusions, and variations in lighting conditions.
More on tables

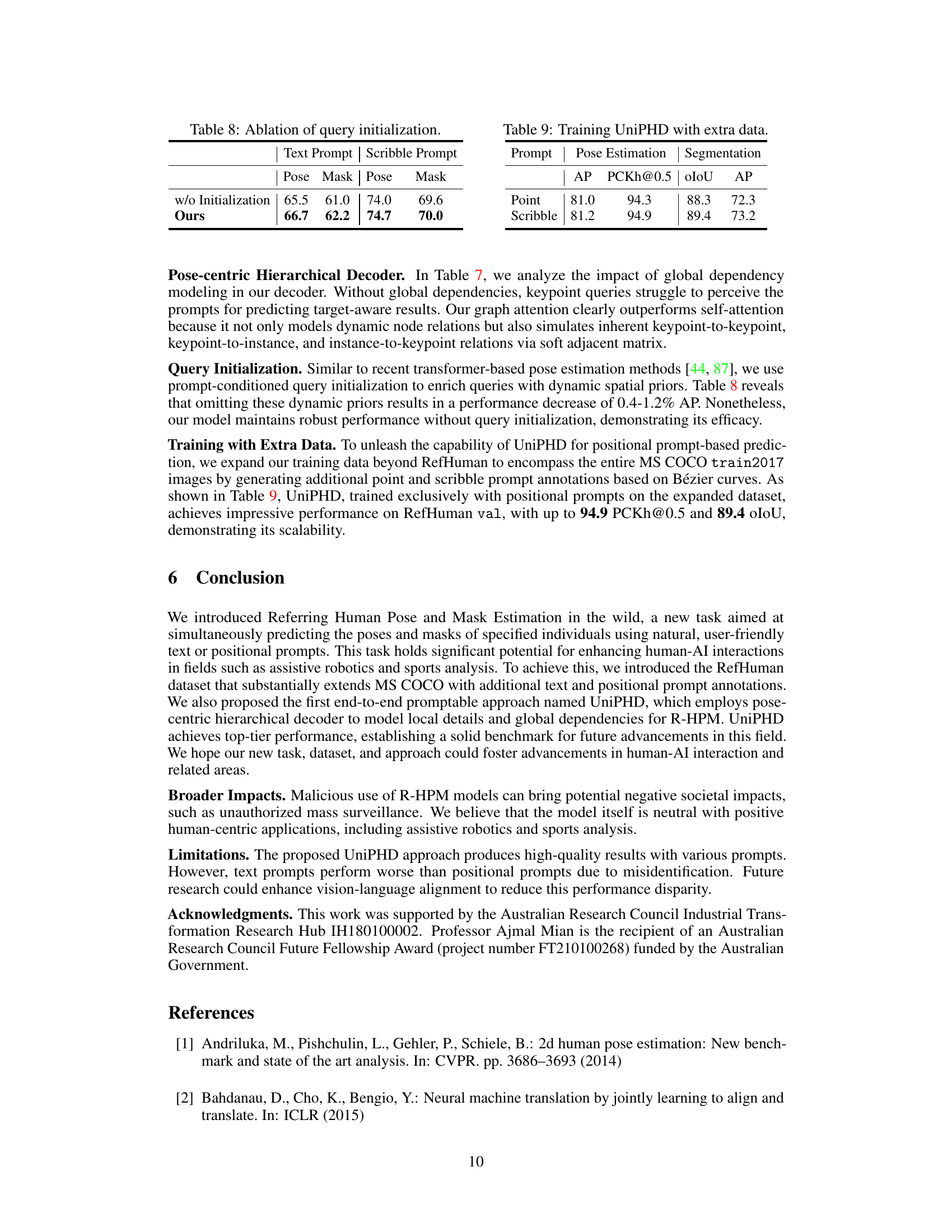
This table presents the results of the proposed UniPHD method and two other methods (Uni-ED-Pose and Uni-GroupPose) on the RefHuman validation set. It compares performance metrics for pose estimation and segmentation using different prompts (text, point, and scribble) while highlighting the advantages of the proposed end-to-end approach over two-stage methods. Key metrics include Average Precision (AP), Percentage of Correct Keypoints (PCKh@0.5), Intersection over Union (IoU), and Frames Per Second (FPS). The table also notes the model parameters and the impact of using different backbone networks (Swin-T and Swin-L).
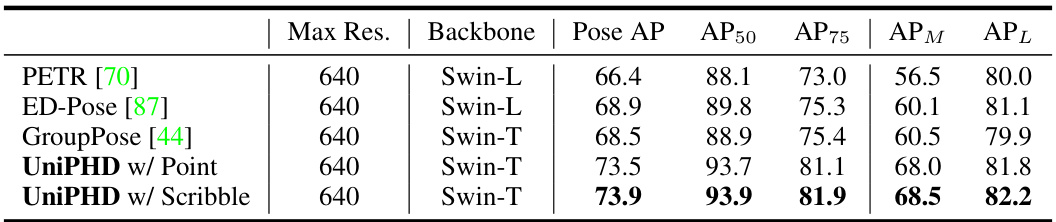
This table compares the performance of the proposed UniPHD model with other state-of-the-art methods on the MS COCO val2017 dataset. The metrics used are Average Precision (AP) for pose estimation and segmentation, along with AP50, AP75, APM, and APL which represent different IoU thresholds for evaluating pose estimation performance. The table shows that UniPHD achieves leading performance in pose estimation while also providing strong results in segmentation.

This table compares the performance of the proposed UniPHD model with other state-of-the-art text-based segmentation methods on the RefHuman dataset. The comparison is based on the IoU metric, using Swin-T as the backbone for all models. The table shows that the proposed UniPHD model outperforms other methods, achieving the highest IoU score of 76.3.
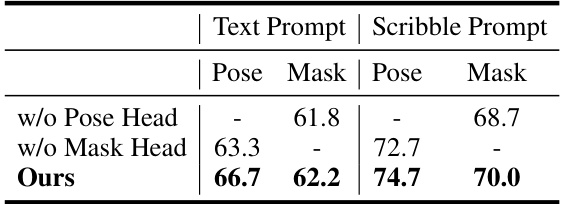
This table presents the ablation study results on the performance of multi-task learning in the proposed UniPHD model. It shows the performance (in terms of Pose AP and Mask AP) when either the pose head or the mask head is removed, and compares it to the full model. The results demonstrate the effectiveness of multi-task learning in improving the overall performance of both pose and mask estimation.
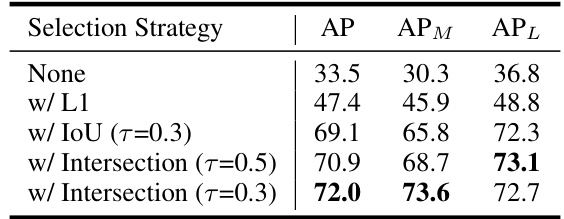
This table presents an ablation study on the result selection strategies used in the GroupPose model with the Swin-T backbone. The study aims to determine the effectiveness of different strategies for selecting the most appropriate prediction results. The strategies compared include using no selection strategy, L1 loss, IoU, and intersection-over-union (IoU) with different thresholds. The results are evaluated in terms of Average Precision (AP), AP for medium-sized objects (APM), and AP for large-sized objects (APL). The table shows that using the intersection-based strategy with a threshold of 0.3 achieves the best performance across all three metrics.

This table presents the ablation study results for the global dependency modeling component of the UniPHD model. It shows the performance (Pose AP and Mask AP) of the model using different methods for global dependency modeling, including without global dependency, self-attention only and the proposed pose-centric hierarchical decoder. The results are shown separately for text and scribble prompts. The purpose is to demonstrate the importance of the pose-centric hierarchical decoder in capturing global relationships between keypoints and instance queries.
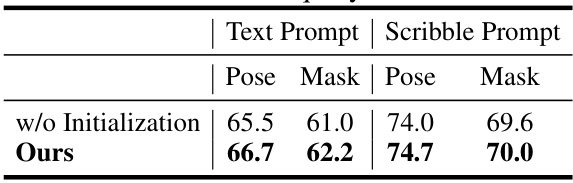
This ablation study analyzes the impact of removing the prompt-conditioned query initialization step in the UniPHD model. It compares the performance with and without query initialization, using both text and scribble prompts, evaluating the pose and mask prediction results (AP). The results show that while the model is robust enough to perform without initialization, including this step improves performance.
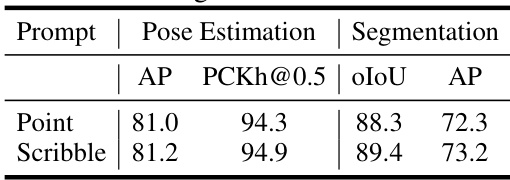
This table presents the performance of the UniPHD model trained with extra data, specifically using point and scribble prompts. The results show the performance metrics (AP, PCKh@0.5, oIoU) for pose estimation and segmentation, demonstrating significant performance improvements achieved by incorporating more data into the training process.

This table shows the ablation study of different numbers of query groups used in the UniPHD model. The results are evaluated using the AP metric for both pose and mask, with text and scribble prompts. The table demonstrates that increasing the number of query groups improves the performance in both pose and mask prediction.

This table presents the ablation study of increasing the model capacity by adding more layers to the multimodal encoder and increasing the feature dimensions. The baseline model is compared to models with more layers and higher dimensions. The results show that the current model settings are already quite effective, as adding more layers or higher dimensions does not significantly improve the performance.
Full paper#