↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Large foundation models are expensive to train and deploy in various settings with different resource constraints. Existing methods like training multiple models or post-hoc compression techniques are not ideal, as they either increase training costs or compromise accuracy. This necessitates selecting a model that may not be perfectly suited to the deployment scenario.
MatFormer proposes a novel nested Transformer architecture to address these challenges. By optimizing multiple nested FFN blocks during training, MatFormer allows for the extraction of numerous submodels. A simple heuristic, Mix’n’Match, is used to efficiently select the best submodel for a given compute budget. The effectiveness of MatFormer is demonstrated across several language and vision tasks. It offers significant improvements in inference latency and accuracy while avoiding the additional costs associated with traditional model training and optimization methods.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces a novel approach to efficient deep learning model deployment. MatFormer’s elastic inference capabilities directly address the challenges of deploying large foundation models across diverse resource constraints, offering significant potential for cost reduction and improved performance. The method’s compatibility with various model types and modalities opens exciting new avenues for future research.
Visual Insights#
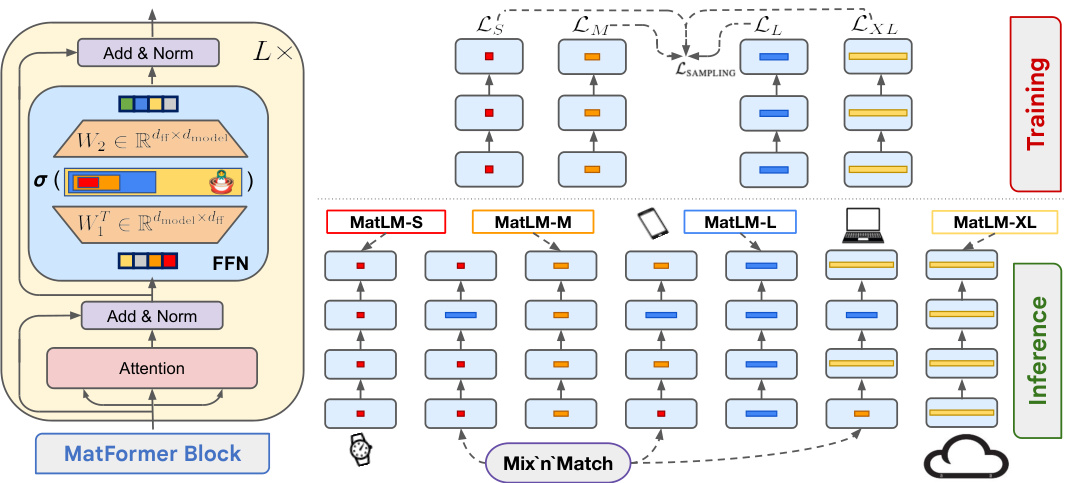
MatFormer modifies the standard Transformer architecture by incorporating a nested Feed Forward Network (FFN) block structure. During training, it optimizes the parameters of multiple nested FFN blocks with varying sizes. This allows for the extraction of many accurate smaller models without incurring additional computational costs. The figure illustrates this nested structure, showing how submodels of different sizes can be extracted from a single, larger model, enabling elastic inference across various deployment environments.

This table compares MatFormer with other methods for obtaining multiple submodels from a single model. It highlights MatFormer’s advantages: requiring optimization of fewer models, producing an exponential number of models at inference time without post-training or Neural Architecture Search (NAS), and its nested subnetwork structure enabling adaptive retrieval and colocation. It also lists the number of models optimized and obtained, whether the subnetworks are nested, the model selection method, if post-training is needed, the architecture type (CNN or Transformer), and if the model is a decoder-only model.
In-depth insights#
Elastic Inference#
Elastic inference, a crucial aspect of deploying large-scale models, addresses the challenge of adapting model resource usage to diverse deployment environments. MatFormer’s approach centers on training a single, universal model which allows extracting multiple smaller submodels, each optimized for different latency and computational constraints. This contrasts with traditional methods which involve training separate models for varying sizes. The key advantage lies in eliminating the substantial cost and time associated with training multiple models, achieving ’elasticity’ at almost no additional cost. This is accomplished through a novel nested FFN block structure and a Mix’n’Match strategy for efficient submodel selection. MatFormer’s elasticity is not just about size; it ensures consistent and accurate submodels, a critical feature for effective speculative decoding and adaptive retrieval tasks. The effectiveness of MatFormer’s approach is validated across language and vision models, demonstrating its broader applicability and potential for significant impact on large-scale model deployment.
Nested Transformer#
The concept of a ‘Nested Transformer’ presents an intriguing approach to enhancing the efficiency and adaptability of Transformer models. By embedding smaller Transformer blocks within larger ones, a hierarchical structure is created. This allows for the extraction of multiple sub-models of varying sizes and capabilities without the need for retraining. The resulting elasticity in model size offers several advantages. First, it enables adaptive inference, enabling deployment across resource-constrained environments (mobile devices) to powerful clusters. Second, it provides cost optimization, as a single large model effectively replaces the need for multiple independently trained models of different sizes. Finally, this nested architecture potentially facilitates improved consistency across submodels, which would be beneficial for techniques that rely on multiple model sizes such as speculative decoding, as seen in the mentioned research.
Mix’n’Match#
The proposed Mix’n’Match strategy represents a significant contribution to the MatFormer architecture, offering a computationally inexpensive method for generating a diverse range of submodels. Instead of computationally expensive neural architecture search (NAS), Mix’n’Match leverages a simple heuristic that selects sub-blocks from the nested structure. By carefully choosing the granularities of the sub-blocks across different layers, Mix’n’Match efficiently creates models optimized for various compute constraints without requiring additional training. The heuristic prioritizes balanced configurations that minimize layer granularity changes, demonstrating superior performance compared to NAS, as shown in the experimental results. This approach greatly enhances MatFormer’s elasticity, providing an effective trade-off between accuracy and computational cost. Its simplicity and effectiveness make Mix’n’Match a practical and valuable addition to the elastic inference capabilities of MatFormer, facilitating practical deployments across a wide spectrum of hardware and latency requirements.
MatLM & MatViT#
The research paper explores MatLM and MatViT, demonstrating elastic inference capabilities in both language and vision domains. MatLM, a decoder-only language model, leverages a nested FFN structure to extract multiple submodels of varying sizes without additional training. This elasticity is particularly valuable for deploying models across diverse computational constraints. MatViT extends this architecture to vision transformers, showing that smaller encoders extracted from a universal model retain metric space structure, enabling efficient adaptive large-scale retrieval. The key innovation lies in the nested sub-structure, allowing for a combinatorial explosion of submodels during inference, exceeding the capabilities of comparable methods while maintaining accuracy.
Scaling & Consistency#
The scaling and consistency analysis of the MatFormer architecture reveals crucial insights into its effectiveness. MatFormer demonstrates reliable scaling, achieving comparable performance to traditional Transformer models across different sizes, which is verified through validation loss and downstream evaluation. The consistent behavior of submodels extracted from MatFormer is a key advantage for elastic inference, enabling significant reductions in inference latency and facilitating adaptable deployments. This consistency is not just about accuracy, but also about preserving the underlying metric space, crucial for applications like large-scale retrieval. The Mix’n’Match approach further enhances the model’s elasticity, allowing extraction of numerous accurate submodels beyond explicitly trained ones, providing a cost-effective alternative to computationally expensive methods. These findings underscore MatFormer’s potential for broader adoption in resource-constrained settings and large-scale deployments.
More visual insights#
More on figures
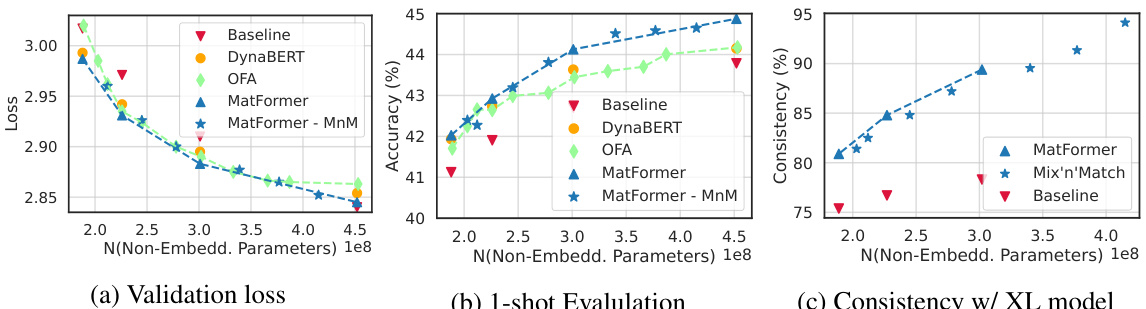
This figure presents the results comparing MatLM (MatFormer Language Model) and baseline models. It shows validation loss, one-shot evaluation scores, and consistency with the largest model (XL) across different model sizes. The key takeaway is that MatLM, especially when using the Mix’n’Match technique, outperforms baselines and produces models with better accuracy and consistency.
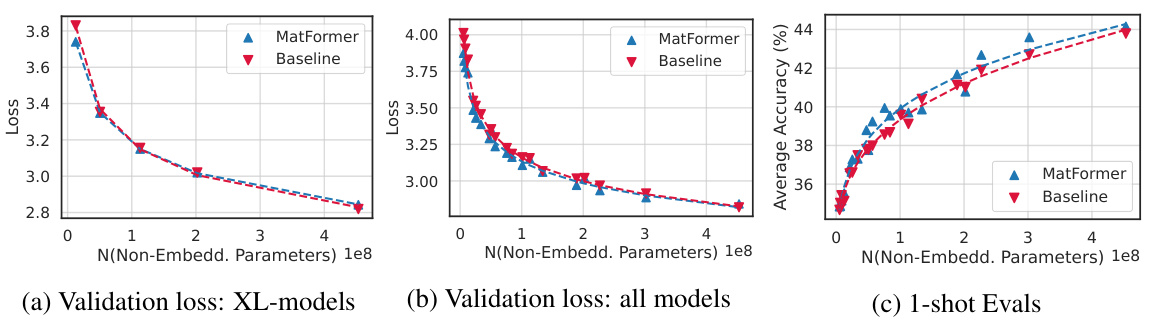
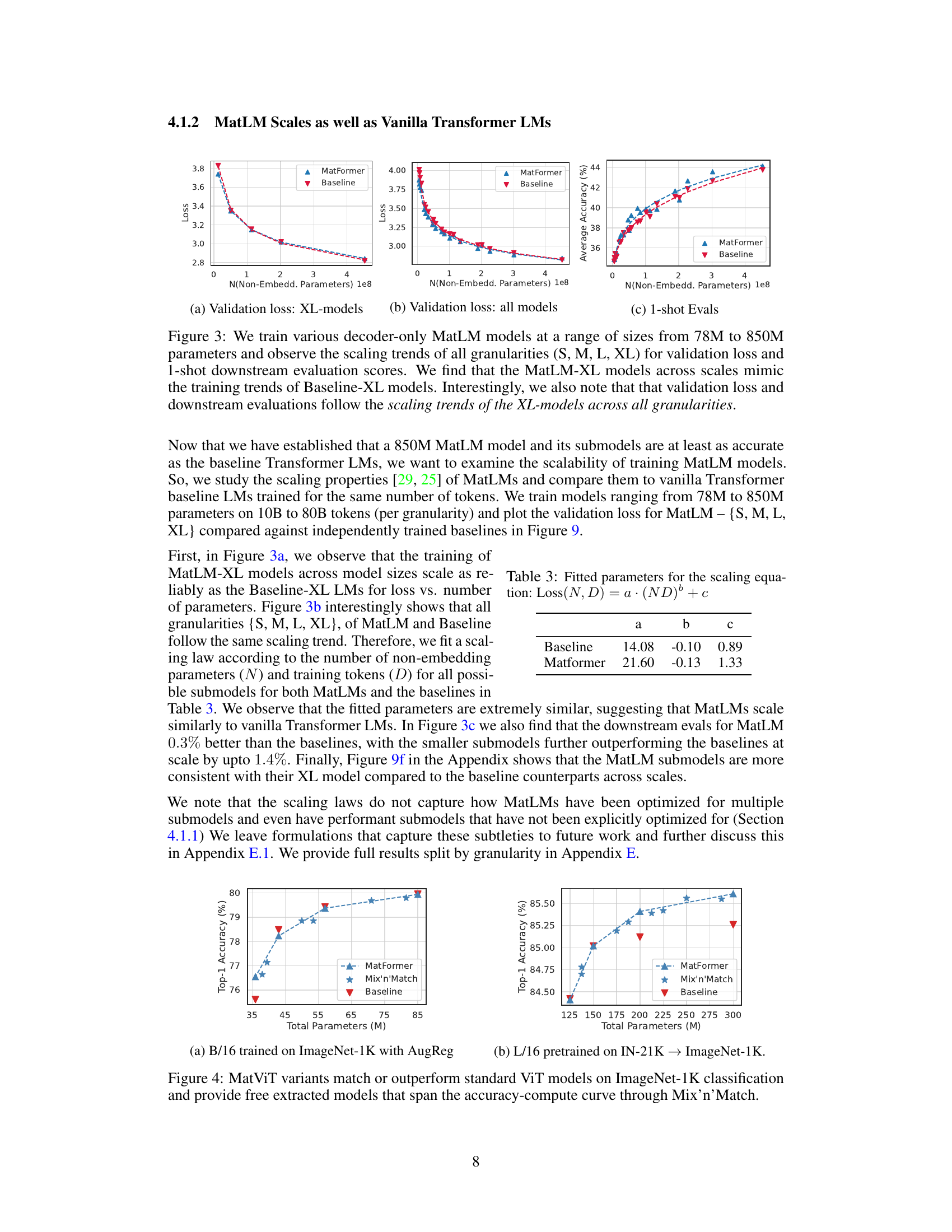
This figure shows the scaling behavior of MatLM models of different sizes (78M to 850M parameters) compared to baseline Transformer Language Models. It demonstrates that the MatLM-XL models (largest models) across different sizes follow the same scaling trend as the baseline XL models, indicating good scalability. The validation loss and 1-shot downstream evaluation scores also show similar scaling trends across all granularities (S, M, L, XL), highlighting the efficacy and consistency of the MatFormer approach across various model sizes.

This figure shows the results of an experiment comparing the performance of MatViT (a nested Transformer architecture) to baseline ViT models for adaptive image retrieval on ImageNet-1K. MatViT’s elastic inference allows extraction of submodels with varying parameter sizes, adapting to compute constraints. The plot demonstrates that MatViT submodels, selected using the Mix’n’Match heuristic, retain high accuracy while significantly reducing compute cost compared to independently trained baseline ViT models of similar size. This highlights the advantage of MatViT’s nested architecture in providing flexibility and efficiency.
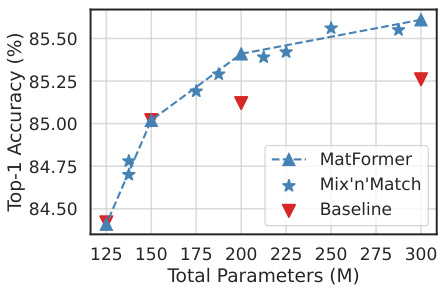
This figure shows the results of image classification experiments on ImageNet-1K using MatViT (MatFormer-based Vision Transformer) models. Two versions of MatViT are presented: B/16 (trained on ImageNet-1K with AugReg) and L/16 (pretrained on ImageNet-21K and finetuned on ImageNet-1K). The figure demonstrates that MatViT models, along with submodels extracted via the Mix’n’Match technique, either match or surpass the performance of standard ViT models. The plots illustrate the accuracy-vs.-parameters trade-off, showing that smaller models extracted from MatViT efficiently cover the performance spectrum.
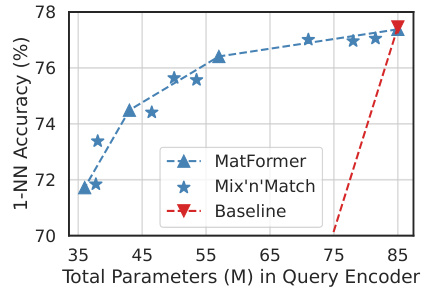
This figure compares the performance of MatViT (MatFormer-based Vision Transformer) and baseline ViT models for adaptive image retrieval on ImageNet-1K. The x-axis represents the total number of parameters (in millions) used in the query encoder, and the y-axis represents the 1-NN (1-Nearest Neighbor) accuracy. The figure shows that MatViT models (both those explicitly trained and those extracted using Mix’n’Match) achieve comparable or better accuracy than baseline ViT models with significantly fewer parameters, demonstrating the effectiveness of MatViT for resource-efficient retrieval tasks.
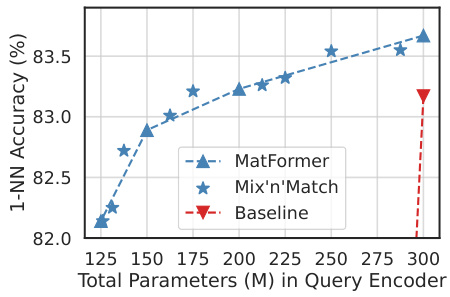
This figure shows the results of using MatViT (MatFormer-based Vision Transformer) for adaptive image retrieval on ImageNet-1K. It compares the 1-nearest neighbor (NN) accuracy of MatViT, Mix’n’Match (a submodel selection heuristic for MatFormer), and baseline ViT models across a range of model sizes (total parameters in millions). The results demonstrate that MatViT and Mix’n’Match models maintain high accuracy even with significantly fewer parameters compared to the baseline, highlighting their efficiency for real-time query-side computation.
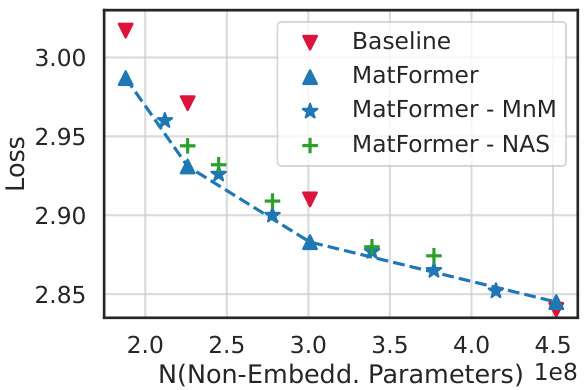
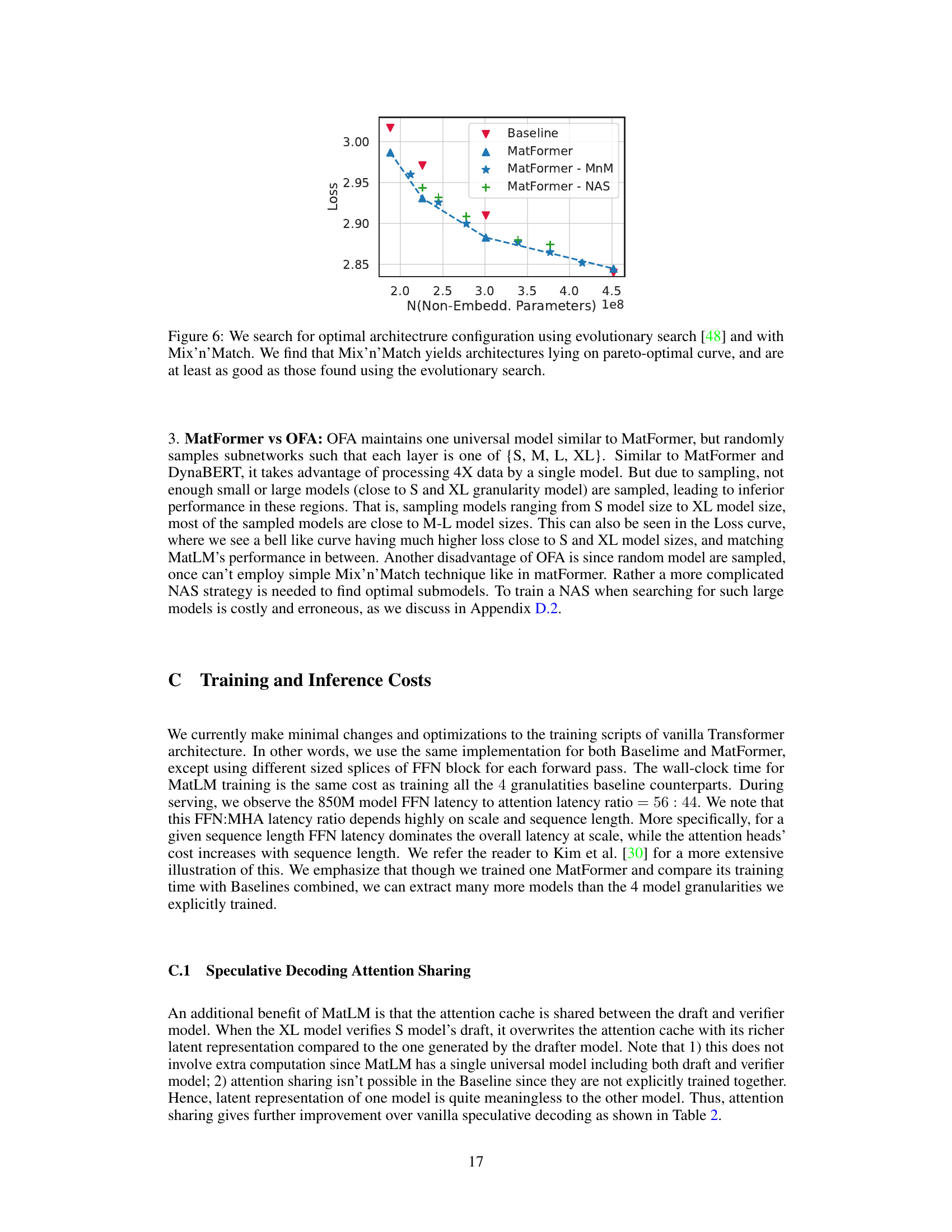
This figure compares the performance of Mix’n’Match against Neural Architecture Search (NAS) for finding optimal submodels within a given parameter budget. It shows that Mix’n’Match achieves comparable results to the more computationally expensive NAS approach, while also offering a simpler heuristic.

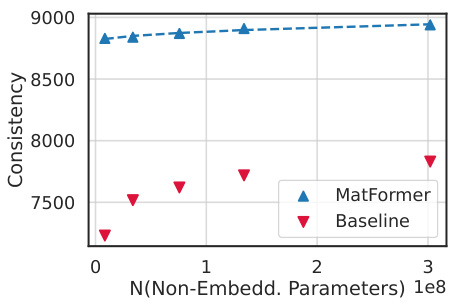
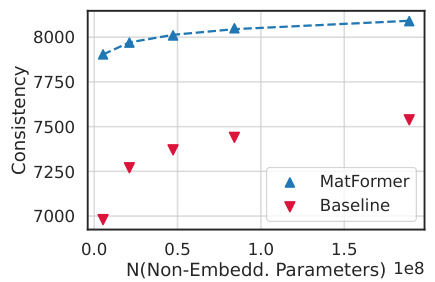
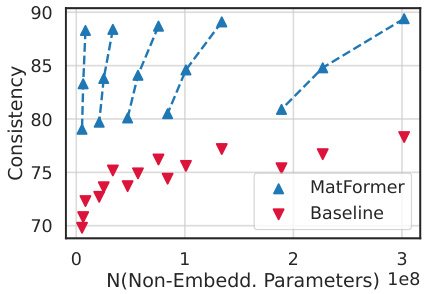
The figure shows the KL divergence between smaller models (S, M, L) and the largest model (XL) for different model sizes. The KL divergence is a measure of the difference in probability distributions between two models. Lower KL divergence indicates higher consistency between models. The figure shows that MatFormer and Mix’n’Match consistently have smaller KL divergences compared to baselines, suggesting that MatFormer and Mix’n’Match produce smaller models that are more consistent with the largest model.
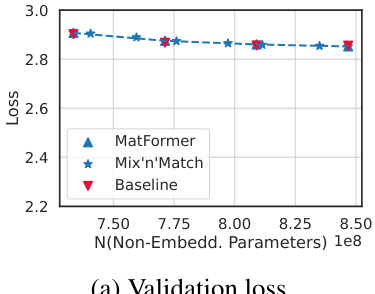
This figure shows the validation loss and one-shot downstream evaluation scores for an 850M parameter MatLM (Matryoshka Transformer Language Model) and its baseline models. The results demonstrate that MatLM’s submodels, obtained through a technique called Mix’n’Match, achieve better validation loss and one-shot downstream evaluation performance than independently trained baseline models. Additionally, it highlights the consistency of the Mix’n’Match submodels compared to the full model, indicating they fall on the accuracy-parameter tradeoff curve.
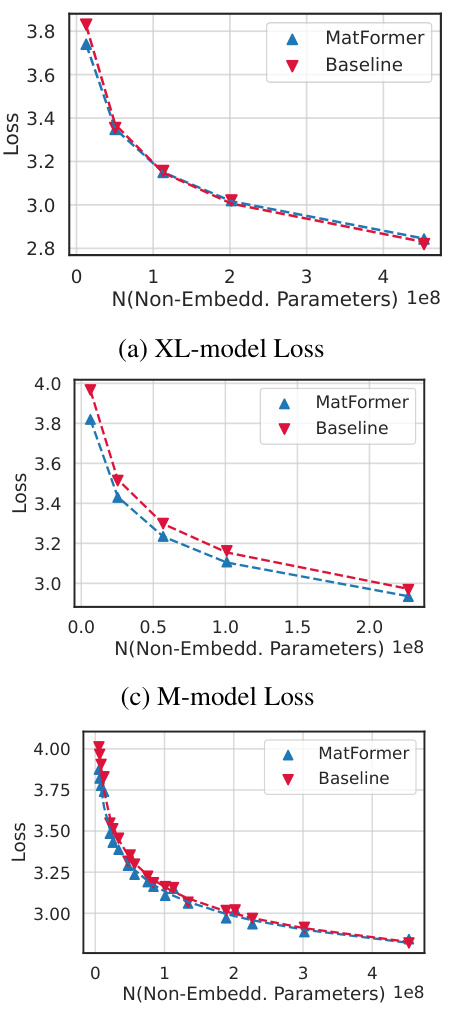
This figure shows the scaling behavior of MatLM models of various sizes (78M to 850M parameters) and granularities (S, M, L, XL). It plots validation loss against the number of non-embedding parameters. The key observation is that the performance difference between MatLM and baseline models remains relatively constant across all granularities and model sizes. The figure also highlights the consistency of submodels (smaller models extracted from the largest MatLM model) in validation loss which is consistent with the findings of the paper.
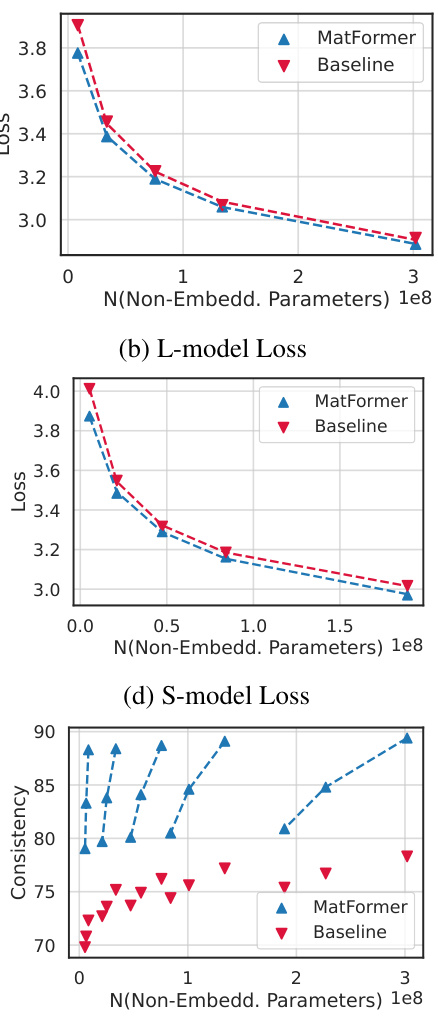
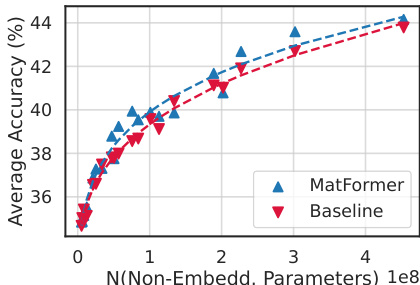
This figure shows the results of experiments comparing MatLM (MatFormer Language Model) with baseline Transformer Language Models. The plots illustrate validation loss, one-shot downstream evaluation scores, and consistency with the largest model (XL). It demonstrates that MatLM outperforms baselines and that a simple heuristic called Mix’n’Match can create many accurate submodels.
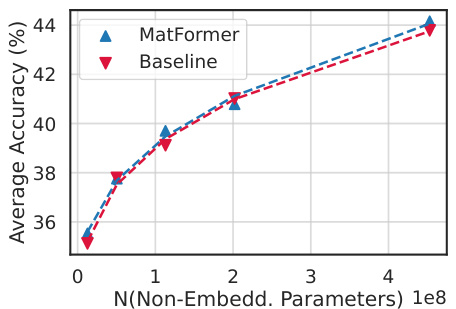
This figure displays three sub-figures showing the validation loss, the one-shot downstream evaluation scores, and the consistency with the XL model for the 850M MatLM and its baseline models. The results demonstrate that MatFormer (and Mix’n’Match) outperforms the baselines in terms of validation loss and downstream performance while maintaining consistency with the largest model.
This figure presents a comparison of validation loss and one-shot downstream evaluation scores for an 850M parameter MatLM (Matryoshka Transformer Language Model) and its baseline counterparts. It demonstrates that MatLM, particularly when combined with the Mix’n’Match submodel selection technique, achieves better performance than independently trained models across various sizes. The results show that the Mix’n’Match approach generates models that follow the accuracy-versus-parameter trade-off curve established by the explicitly trained submodels, indicating a cost-effective way to obtain accurate models for diverse compute budgets.

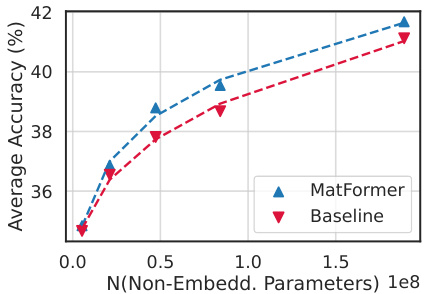
This figure shows the comparison of validation loss and downstream evaluation scores between 850M parameter MatLM and its baseline models with different sizes. It demonstrates that MatLM outperforms baselines across all granularities. The Mix’n’Match technique, which enables the extraction of additional submodels, helps in generating accurate and consistent models, demonstrating the efficacy of MatFormer in creating models that span the performance versus compute trade-off curve.
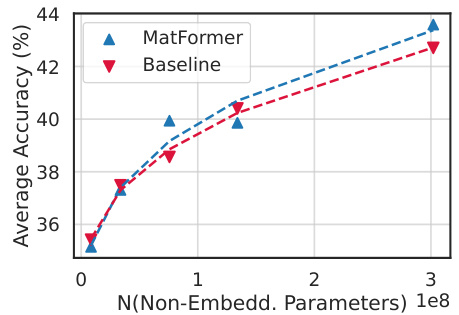
This figure shows the validation loss and one-shot downstream evaluation results for an 850M parameter MatLM model and its baseline counterparts. It demonstrates that MatLM outperforms the baselines across different model sizes (S,M,L,XL), and that the Mix’n’Match approach used for MatLM yields models that are both accurate and highly consistent with the full model. The consistency of smaller models created using Mix’n’Match is particularly highlighted in a separate graph.
This figure presents the validation loss and one-shot downstream evaluation scores for an 850M parameter MatLM (Matryoshka Transformer Language Model) and its corresponding baseline models. It demonstrates that MatFormer’s Mix’n’Match technique produces smaller, more consistent submodels that maintain high accuracy across different computational budgets. The submodels are shown to fall on the curve defined by the explicitly trained models, highlighting the efficacy of the MatFormer approach.
MatFormer introduces a nested structure into the feed-forward network (FFN) block of the Transformer. During training, MatFormer optimizes multiple nested FFN blocks of varying sizes. This allows for the extraction of numerous accurate, smaller models without incurring additional computational costs. The figure illustrates this nested structure, highlighting how the submodels can be mixed and matched during inference to achieve elastic inference across various deployment constraints.

This figure shows the comparison of validation loss and one-shot downstream evaluation scores between the 850M parameter MatLM and its baseline models. The leftmost panel (a) displays validation loss, demonstrating that MatLM outperforms baselines across all granularities (S, M, L, XL). The center panel (b) shows one-shot downstream evaluation scores, where again MatLM surpasses baselines. Importantly, the rightmost panel (c) illustrates the consistency of submodels extracted via Mix’n’Match, highlighting that these models exhibit high consistency with the full MatLM-XL model. This consistency is a key finding, suggesting that smaller, more efficient models can be obtained without sacrificing performance.
This figure shows the results of the experiments comparing MatLM and baseline models, in terms of validation loss, one-shot evaluation scores, and consistency with the largest model. It highlights how MatLM outperforms baseline models, especially in terms of achieving better results with smaller models, and how the Mix’n’Match strategy helps in creating accurate and consistent submodels within a given parameter budget.
This figure shows three graphs comparing the performance of MatLM (MatFormer Language Model) with baseline Transformer models. The first graph displays validation loss against the number of non-embedding parameters. The second graph shows one-shot downstream evaluation scores against the number of non-embedding parameters. The third graph presents the consistency of the smaller MatLM models with the largest MatLM model. The results demonstrate that MatLM, particularly when using the Mix’n’Match technique, produces more accurate and consistent models that perform as well as or better than independently trained counterparts across a range of sizes. These models effectively occupy the optimal accuracy vs. parameters trade-off space.
More on tables

This table presents the inference time speedup achieved by using speculative decoding with the smaller (393M parameters) and larger (850M parameters) submodels extracted from the 850M MatLM model, compared to standard autoregressive decoding of the 850M model. The speedup is shown for two downstream tasks: LAMBADA and TriviaQA. The table also includes a row showing the additional speedup achieved by sharing the attention cache across the smaller and larger models.
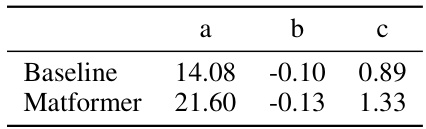
This table presents the fitted parameters (a, b, c) for the scaling law equation Loss(N, D) = a * (ND)^b + c, which describes the relationship between the loss, the number of non-embedding parameters (N), and the number of training tokens (D). The parameters are fitted separately for both Baseline and MatFormer models, offering a comparison of their scaling behavior.

This table provides detailed information about the language models used in the experiments of section 4.1. For each model size (78M, 180M, 310M, 463M, and 850M parameters), it breaks down the total parameter count into the number of non-embedding parameters and FFN (Feed-Forward Network) parameters. It also specifies the model dimension (dmodel) and the number of training tokens used for each model.

This table compares the configurations of submodels generated by the Mix’n’Match heuristic and Neural Architecture Search (NAS) for various parameter budgets on an 850M MatFormer model. The results show that NAS tends to favor balanced granularities (even distribution of different submodel granularities across layers), aligning with the Mix’n’Match heuristic, which prioritizes balanced configurations for optimal performance.
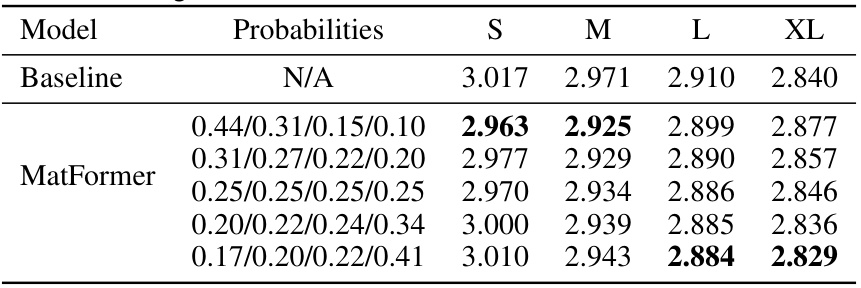
This table presents the results of experiments on an 850M parameter model where different probabilities were used for sampling submodels during training. The goal was to investigate the impact of non-uniform sampling on model performance across different granularities. The results show that strategies which emphasize the largest granularity generally perform well, with only minor negative effects on smaller granularities.
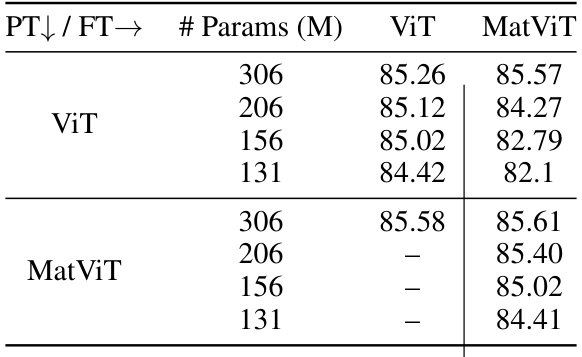
This table presents the top-1 accuracy results of different ViT models trained with and without MatFormer on ImageNet-1K. It shows the impact of using MatFormer during pretraining and finetuning phases on the model’s accuracy, demonstrating its effectiveness in producing more accurate and elastic models. Different model sizes are compared for both ViT and MatViT architectures.
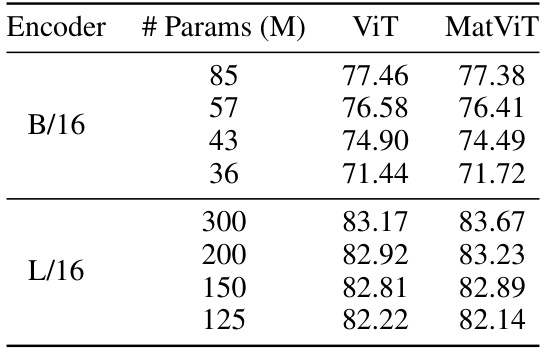
This table presents the 1-nearest neighbor (NN) accuracy results for image retrieval experiments on ImageNet-1K. The query and document encoders used are the same model. The results show that the MatViT models (variants of Vision Transformers with a nested structure) either match or outperform the standard ViT (Vision Transformer) counterparts in terms of accuracy. A key point is that the smaller MatViT models are extracted at no additional cost, while the corresponding baseline ViT models of the same sizes would need to be explicitly trained.
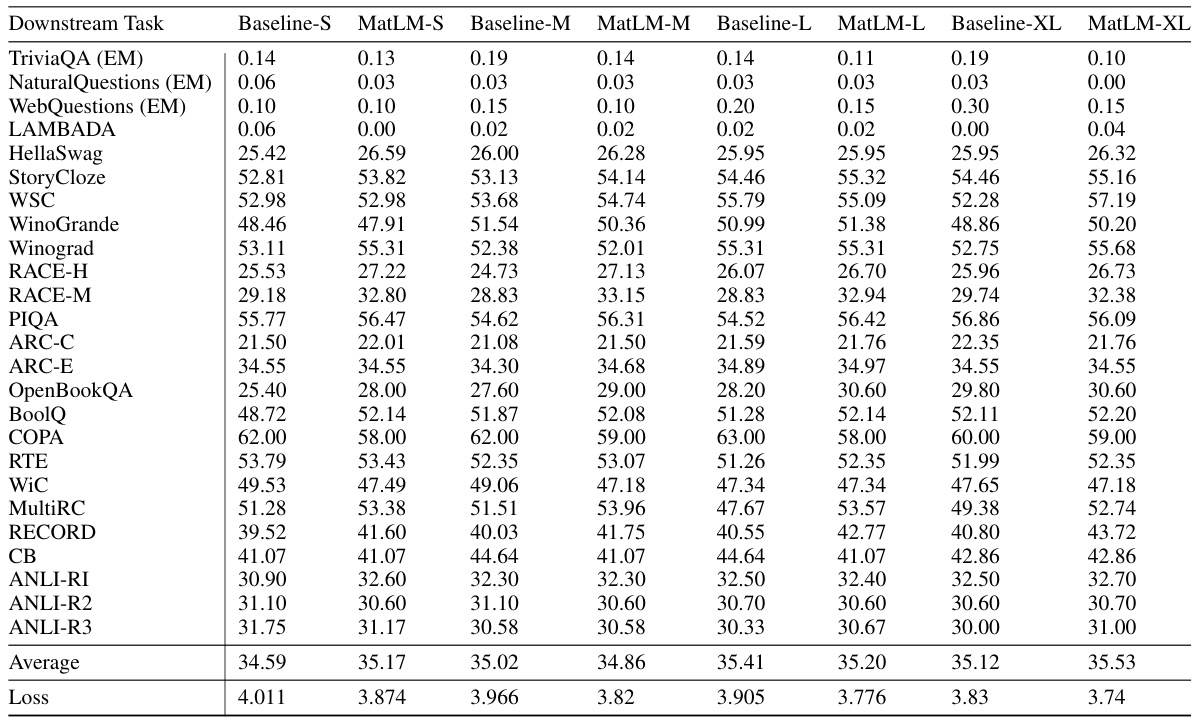
This table presents the performance of different language models on 25 downstream tasks. It compares the performance of baseline Transformer models with MatFormer models across four different granularities (S, M, L, XL) representing different model sizes. The table includes both downstream evaluation metrics and development set log perplexity loss for each model and granularity, allowing for a comprehensive comparison of accuracy and efficiency.

This table presents the results of evaluating the 78M parameter MatLM model and its corresponding baseline models on a variety of downstream tasks. The evaluation metrics include accuracy scores on tasks such as TriviaQA, Natural Questions, and HellaSwag, along with the development set log perplexity loss. The table shows the performance of MatLM compared to the baseline for each model granularity (S, M, L, XL).

This table presents the results of downstream evaluation tasks and development set log perplexity loss for different model sizes (78M) and granularities (S, M, L, XL). It compares the performance of baseline models with MatFormer models across various tasks, offering a detailed breakdown of the model’s performance at different scales.
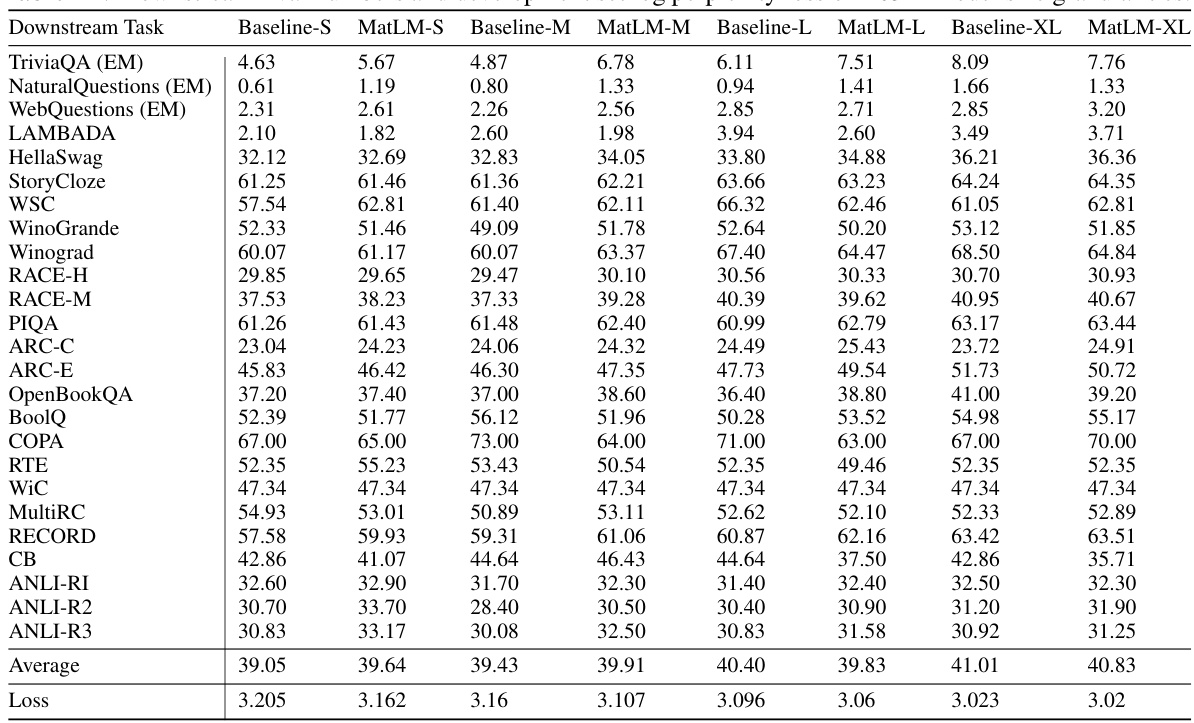
This table presents the results of evaluating various language models on 25 downstream tasks. It compares the performance of baseline transformer models (Baseline-S, Baseline-M, Baseline-L, Baseline-XL) against MatFormer models (MatLM-S, MatLM-M, MatLM-L, MatLM-XL) of four different sizes (granularities) — 78M parameters. The metrics used are accuracy scores for each task and the average log perplexity across all tasks for each model. The table highlights the relative performance differences between baseline and MatFormer models.
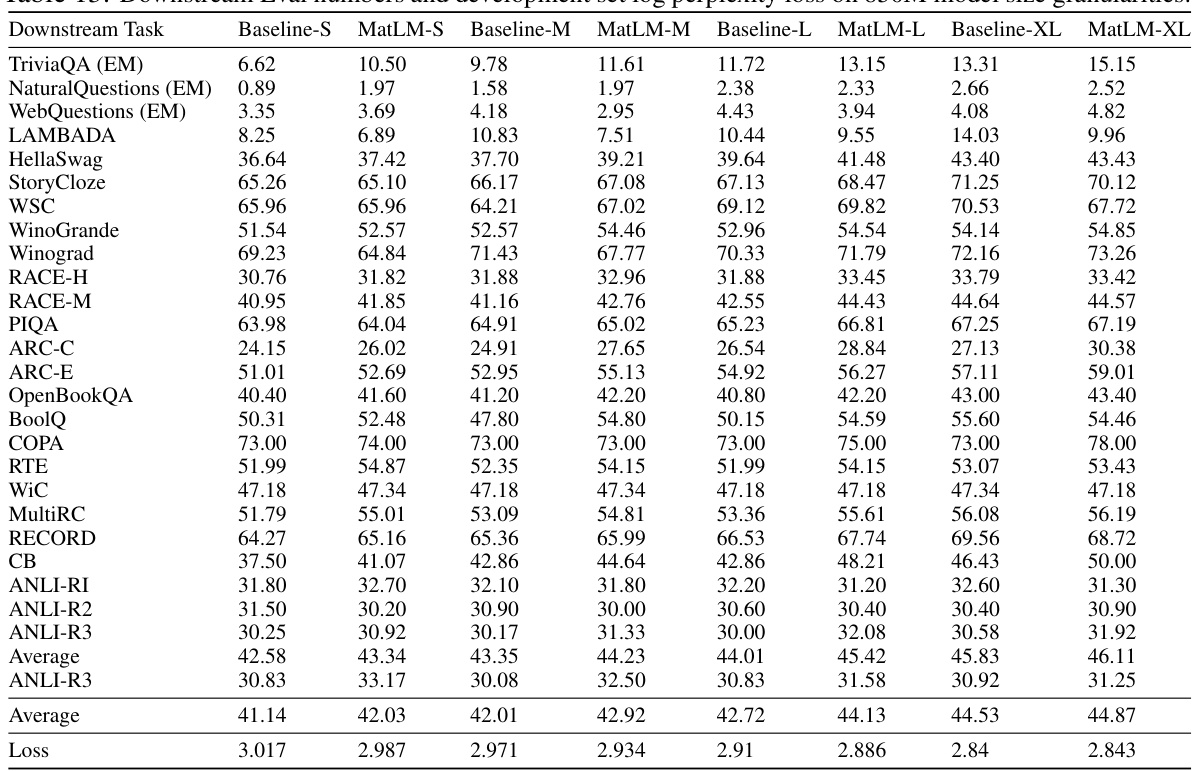
This table presents the performance of different models (Baseline and MatLM with granularities S, M, L, XL) on 25 downstream tasks. It shows the accuracy and log perplexity loss for each model on each task, allowing for a comparison of the different model sizes and architectures. The log perplexity loss is a metric used to evaluate the language model’s performance, where lower values indicate better performance.
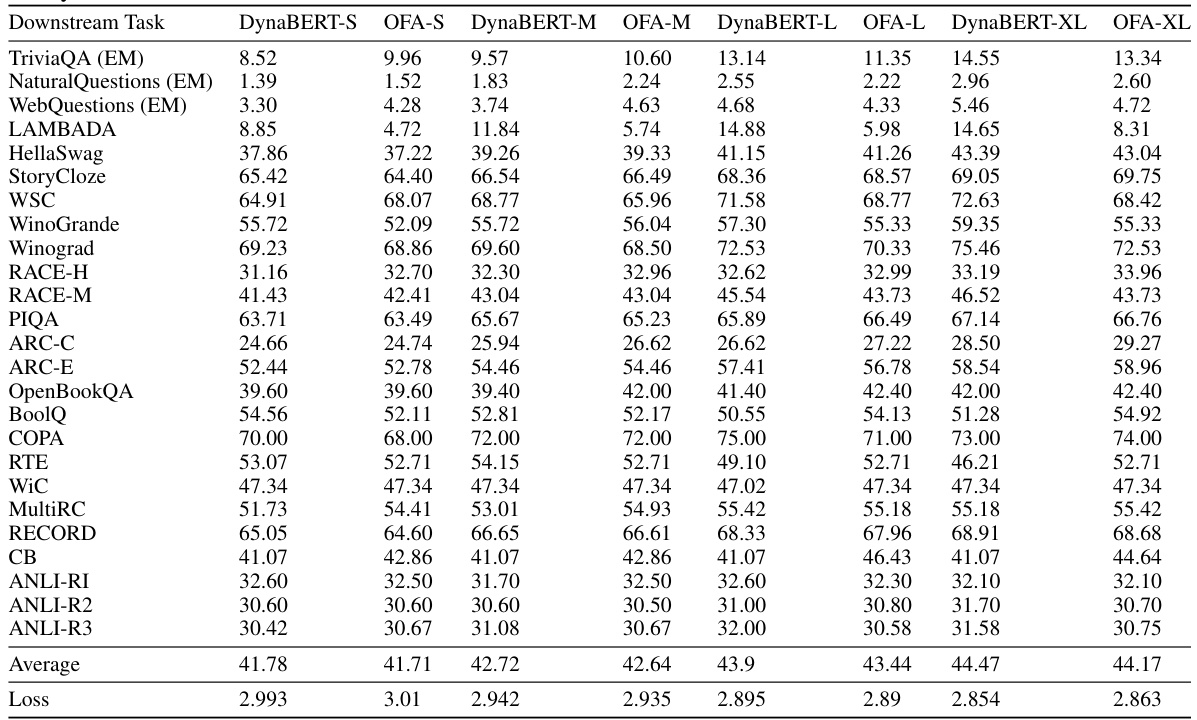
This table presents the performance of different language models on various downstream tasks. It compares the performance of baseline models (Baseline-S, Baseline-M, Baseline-L, Baseline-XL) with MatFormer models (MatLM-S, MatLM-M, MatLM-L, MatLM-XL) at the 78M parameter scale. Each model’s performance is evaluated using various metrics (e.g., Exact Match, Accuracy) for 25 English tasks. The table also includes the development set log perplexity loss for each model, providing a comprehensive evaluation of their performance across diverse language understanding tasks.
Full paper#