↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Current audio deepfake detection models struggle with generalization to new attack methods and lack interpretability. This limits their real-world applications where explanations are needed. This paper introduces SLIM, a novel model that tackles both issues. Existing models primarily rely on black-box methods, hindering understanding of their decision-making process.
SLIM, on the other hand, explicitly uses the Style-Linguistics Mismatch (SLIM) in fake speech. It first uses self-supervised pre-training on real speech to learn style-linguistic dependencies, then combines these learned features with standard acoustic features to classify real and fake audio. This approach leads to improved generalization, competitive performance, and provides insight into model predictions via quantifiable style-linguistic mismatch. These features enable explaining why certain audio is classified as real or fake.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in audio deepfake detection due to its novel approach using style-linguistics mismatch. It addresses the critical issue of generalization to unseen attacks and offers an explainable model, advancing the field significantly. The findings open avenues for research in self-supervised learning, explainable AI, and robust feature extraction for multimedia forensics. This work is particularly relevant given the rise of sophisticated audio deepfakes.
Visual Insights#
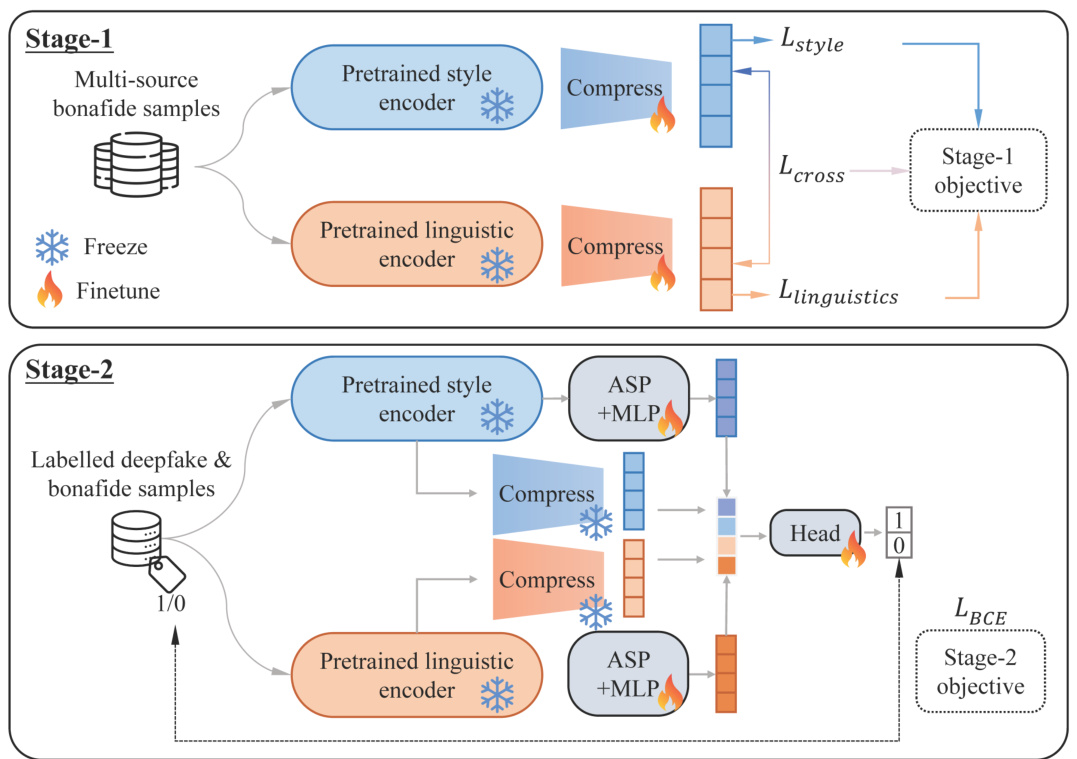
This figure illustrates the SLIM (Style-Linguistics Mismatch) model’s two-stage training process. Stage 1 uses self-supervised learning on real speech data to learn style-linguistic dependencies, compressing these features to minimize redundancy and distance between representations. Stage 2 leverages these compressed features, along with original features, for supervised classification of real and fake speech samples.

This table presents the Pearson correlation coefficients (r) and standard deviations calculated between style and linguistic embeddings for real and synthetic speech samples. The data includes results for five unseen speakers and various TTS/VC systems. The significance of the difference between real and generated speech is evaluated using Welch’s t-test, demonstrating a statistically significant difference.
In-depth insights#
SLIM Model Intro#
The SLIM (Style-Linguistics Mismatch) model is introduced as a novel approach to generalized audio deepfake detection. It addresses the limitations of existing methods that struggle with generalization to unseen attacks and lack interpretability. SLIM leverages the inherent mismatch between stylistic and linguistic features in fake speech, learned through a two-stage process. The first stage uses self-supervised learning on real speech to establish style-linguistic dependencies. The second stage trains a classifier on both real and fake audio using these learned features, along with standard acoustic features, enabling the model to discriminate between genuine and fabricated audio. This framework achieves better generalization to unseen attacks and enables quantification of the style-linguistic mismatch, providing an explanation mechanism crucial for trust and real-world applications. The model’s explainability is a significant advantage, offering insights into its decision-making process.
Style-Linguistics Mismatch#
The concept of “Style-Linguistics Mismatch” offers a novel perspective on audio deepfake detection. It posits that authentic speech exhibits a natural correlation between linguistic content (what is said) and vocal style (how it’s said), whereas deepfakes artificially combine these aspects, creating a mismatch. This mismatch isn’t just a subtle difference; it’s a key characteristic that distinguishes real speech from synthetically generated audio. The research explores this concept by using self-supervised learning on real speech to model the natural style-linguistic relationship, thus creating a baseline for comparison. Deepfakes, with their artificial synthesis, deviate significantly from this baseline, revealing the magnitude of the mismatch. This approach not only improves detection accuracy but also enhances interpretability. By quantifying the mismatch, the model offers insights into why a particular audio sample is classified as fake, thereby increasing trust and understanding of the system’s decisions. The ability to identify and quantify this mismatch is crucial for building robust and explainable audio deepfake detection systems, moving beyond black-box models to more transparent and trustworthy solutions.
Two-Stage Training#
A two-stage training approach is employed to effectively leverage the Style-Linguistics Mismatch (SLIM) in audio deepfakes. Stage 1 focuses solely on real audio samples, employing self-supervised contrastive learning to establish style and linguistic dependencies. This stage is crucial for learning the inherent relationships within real speech, forming the foundation for distinguishing it from synthetic audio. By contrasting style and linguistic subspaces, the model learns a representation capturing their dependency. Stage 2 leverages the features learned in Stage 1, combining them with original style and linguistic representations to train a classifier for real/fake audio classification. This two-stage approach allows the model to learn the inherent structure of real speech before using that knowledge to discriminate it from forged samples, thus improving generalization to unseen deepfake attacks and increasing model interpretability.
Generalization & XAI#
The heading ‘Generalization & XAI’ highlights a crucial problem in audio deepfake detection: current models struggle with generalization to unseen attacks and lack explainability (XAI). The core issue is that existing models often overfit to specific deepfake generation methods, leading to poor performance when encountering new, unseen techniques. This lack of robustness undermines trust and real-world applicability. Simultaneously, the black-box nature of many deep learning models impedes understanding of their decision-making processes. This is especially critical in high-stakes applications requiring transparency and accountability, such as legal proceedings. Therefore, research in this area should prioritize models that not only achieve high accuracy but also generalize well to diverse deepfakes and offer interpretable outputs. This would enhance the reliability of audio deepfake detection systems and build greater confidence in their use.
Future Works#
Future work could explore extending SLIM’s capabilities to multilingual deepfakes, a significant challenge given data scarcity. Addressing the limitations of current style-linguistics disentanglement methods is crucial, as a more precise separation could enhance accuracy and interpretability. Investigating the impact of different generative models and audio processing techniques on SLIM’s performance is warranted. Research on the robustness of SLIM to unseen attacks and varying levels of noise is needed to ensure its real-world applicability. Finally, exploring the use of SLIM in conjunction with other deepfake detection modalities, such as visual analysis, could lead to a more holistic and reliable system. Incorporating explainable AI (XAI) techniques into SLIM is a priority to improve user trust and confidence in its predictions.
More visual insights#
More on figures
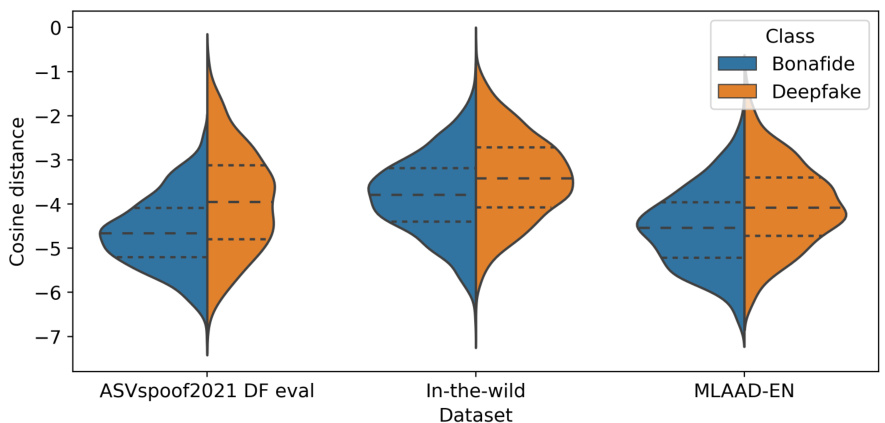
This violin plot shows the distribution of cosine distances between style and linguistic dependency features for real and fake speech samples across three datasets: ASVspoof2021 DF eval, In-the-wild, and MLAAD-EN. The y-axis represents the cosine distance (log scale), indicating the similarity between the two feature sets. A smaller distance suggests a stronger correlation, while a larger distance indicates a greater mismatch. The plot visually compares the distributions for bonafide (real) and deepfake audio samples within each dataset, highlighting the differences in style-linguistic dependency between real and fake speech. Whiskers represent the 75th, median, and 25th percentiles of the distributions.

This figure visualizes the style and linguistic features learned by SLIM using t-SNE for dimensionality reduction. It shows how well the model separates real and fake speech samples from different datasets (ASVspoof2021, In-the-wild, MLAAD-EN). The top row shows the embeddings from the original subspaces (style and linguistic), while the bottom row displays the dependency features learned in Stage 1 of the SLIM model, which aim to capture the style-linguistics mismatch in deepfakes. The visualization helps to understand the effectiveness of the learned features in discriminating between real and fake speech, particularly across different datasets.
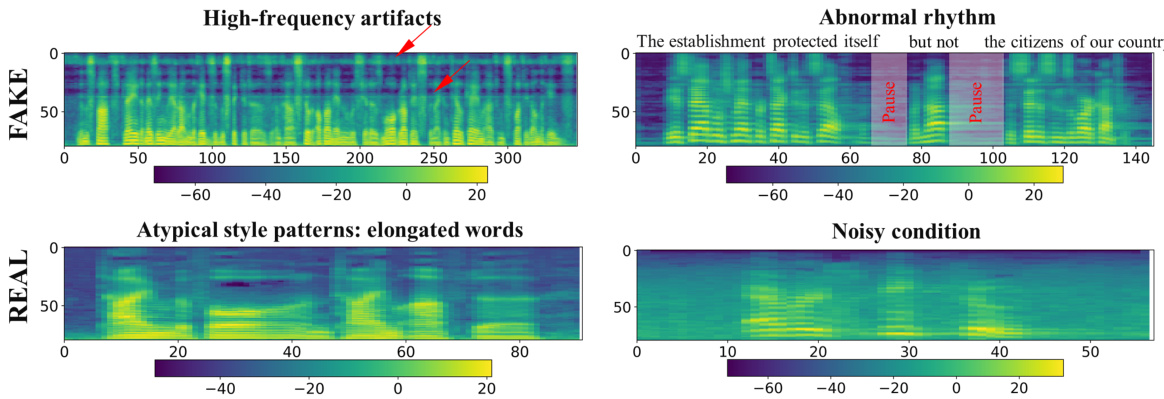
This figure shows four mel-spectrograms from the In-the-wild dataset, illustrating different characteristics of both real and fake speech samples. The top two examples highlight common issues with fake audios: high-frequency artifacts and unnatural pauses. The bottom two showcase examples of real speech: one with atypical style (elongated words) and another with a noisy recording. The caption highlights SLIM’s ability to correctly identify all four samples, and indicates that the model uses features from different subspaces (style and linguistics) in a complementary way. The different subspaces capture diverse artifacts and anomalies, therefore improving the overall detection performance.

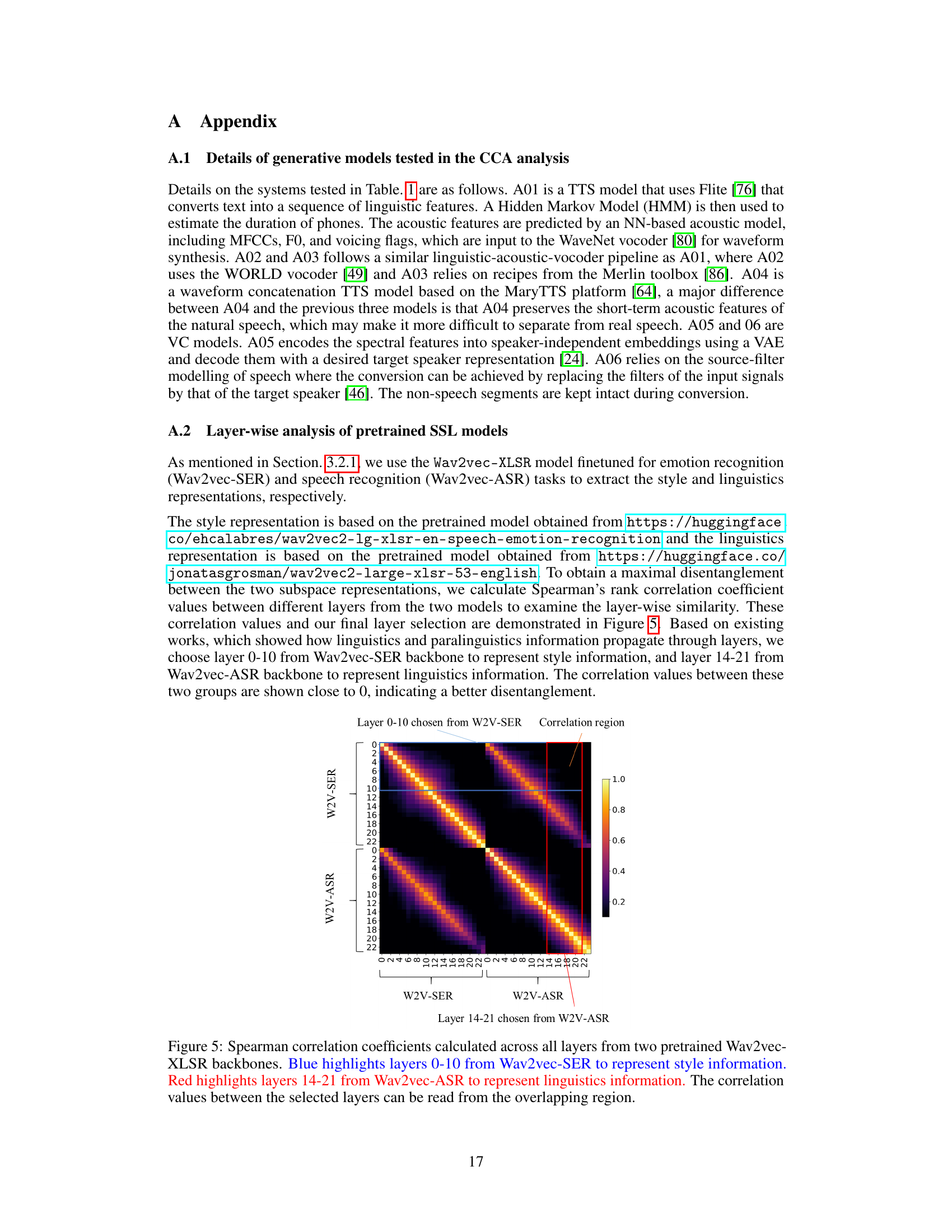
This figure shows a heatmap representing the Spearman correlation coefficients between different layers of two pretrained Wav2vec-XLSR models: one fine-tuned for speech emotion recognition (Wav2vec-SER) and another for speech recognition (Wav2vec-ASR). The x and y axes represent layers from Wav2vec-SER and Wav2vec-ASR respectively. The color intensity represents the correlation strength, with warmer colors indicating higher correlation. The blue and red rectangles highlight the chosen layers (0-10 and 14-21) from Wav2vec-SER and Wav2vec-ASR respectively, indicating the style and linguistic features used in the SLIM model. The near-zero correlation between these selected layers suggests a good disentanglement between style and linguistic information.
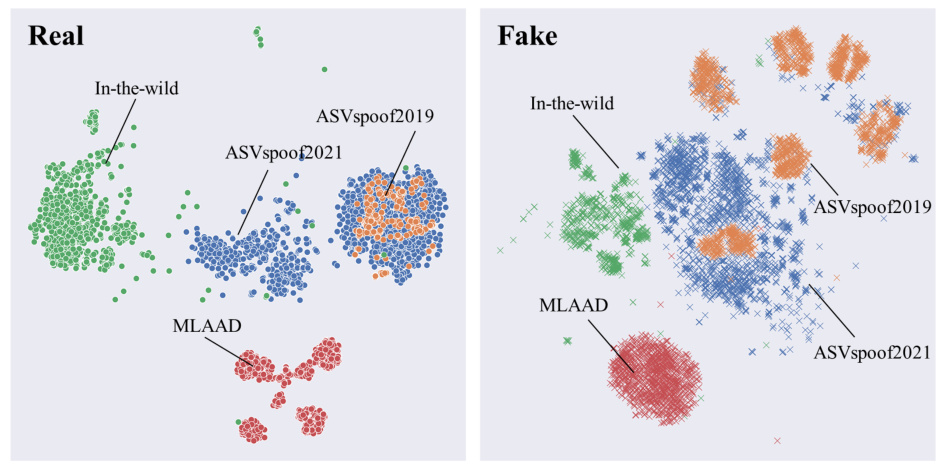
This figure uses t-SNE to visualize the WavLM embeddings of real and fake audio samples from four datasets: ASVspoof2019, ASVspoof2021, In-the-wild, and MLAAD-EN. The visualization shows how well the embeddings separate the real and fake audio samples from each dataset. The left panel shows real samples, while the right panel shows fake samples. The different colors represent the different datasets. The plot helps to illustrate the model’s ability to distinguish between real and fake speech and how this ability varies across datasets.

This figure illustrates the SLIM (Style-Linguistics Mismatch) model’s two-stage training process. Stage 1 focuses on self-supervised learning using only real speech samples to extract style and linguistic features and their dependencies. It involves compressing these features to minimize redundancy and distance between the compressed style and linguistic representations. In Stage 2, these compressed features are combined with the original features and used to train a supervised classifier for audio deepfake detection, using both real and fake speech samples. The frozen SSL encoders from Stage 1 highlight that the improvement in generalization doesn’t come from finetuning, but the novel features learned in Stage 1.
More on tables
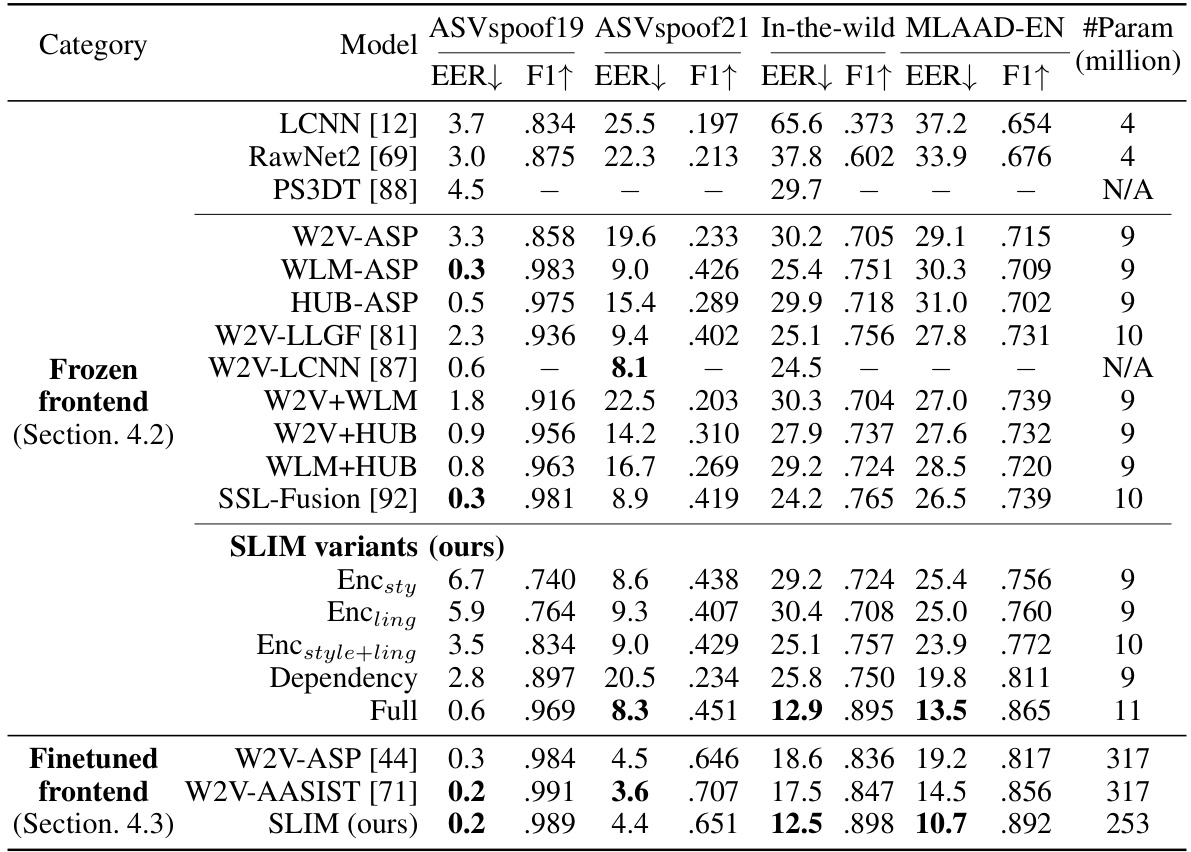
This table compares the performance of SLIM against other state-of-the-art audio deepfake detection models across four different datasets: ASVspoof2019, ASVspoof2021, In-the-wild, and MLAAD-EN. The metrics used for comparison are Equal Error Rate (EER) and F1-score. The table also indicates whether the model’s frontend (feature extraction) was frozen or fine-tuned during training, and the number of trainable parameters for each model. The results highlight SLIM’s superior generalization capabilities, especially to unseen attacks.

This table details the datasets used in both stages of the SLIM model training and evaluation. Stage 1 uses data for self-supervised contrastive learning (only real data) while stage 2 uses labeled data (real and fake) for supervised training. The table lists the dataset name, the split (train, valid, or test), the number of samples, the number of real and fake samples, the number of attacks (types of deepfakes), the type of speech (scripted or spontaneous), and the recording environment (studio or in-the-wild).
This table compares the performance of SLIM and several other state-of-the-art (SOTA) models on four different audio deepfake detection datasets: ASVspoof2019, ASVspoof2021, In-the-wild, and MLAAD-EN. The table shows the Equal Error Rate (EER) and F1 score for each model on each dataset, and also indicates the number of trainable parameters (in millions) for each model. The models are categorized based on whether they fine-tune the feature extraction frontend or keep it frozen during training. The table highlights that SLIM outperforms other models with frozen frontends on out-of-domain datasets, while maintaining competitive performance on in-domain datasets. The results demonstrate SLIM’s superior generalizability to unseen attacks.
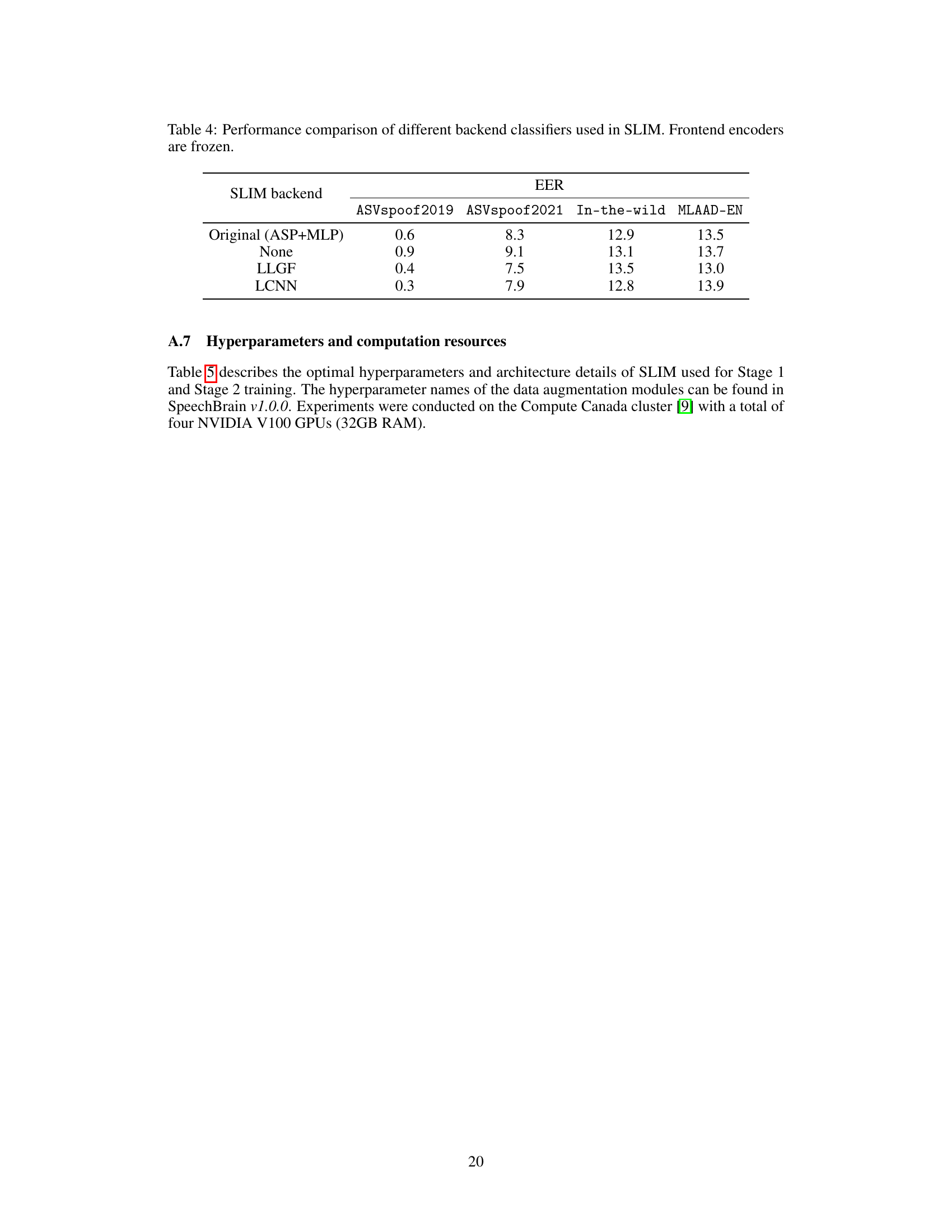
This table presents a comparison of the performance of various deepfake detection models on four different datasets: ASVspoof2019, ASVspoof2021, In-the-wild, and MLAAD-EN. The metrics used for comparison are Equal Error Rate (EER) and F1-score. The table also indicates whether the model’s frontend (feature extraction) was frozen or finetuned during training, and the number of trainable parameters in millions for each model. This allows for analysis of model performance across datasets, the impact of frontend finetuning, and model complexity.
Full paper#