↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Current image super-resolution (SR) methods suffer from data distribution imbalances (easy-to-reconstruct smooth areas outweighing difficult textured areas) and model optimization imbalances (equal weight given to all areas despite varying reconstruction difficulty). These imbalances limit performance and efficiency.
The paper introduces Weight-Balancing SR (WBSR) to address these limitations. WBSR uses Hierarchical Equalization Sampling (HES) to balance training data representation, prioritizing challenging texture areas. It also employs a Balanced Diversity Loss (BDLoss) to focus optimization on these areas and reduce redundant computations. Finally, a gradient projection dynamic inference strategy enables accurate and efficient reconstruction during inference.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in image super-resolution as it addresses efficiency limitations of existing methods by tackling data and model optimization imbalances. The proposed WBSR framework improves SR performance with a 34% reduction in computational cost, opening new avenues for efficient model design and deployment. This is highly relevant given the growing demand for real-time SR applications.
Visual Insights#
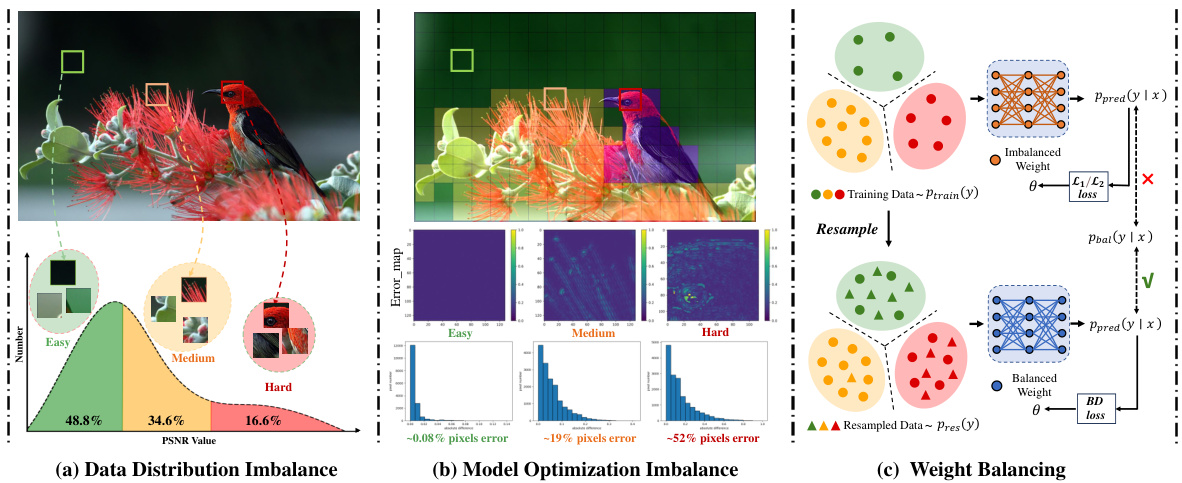
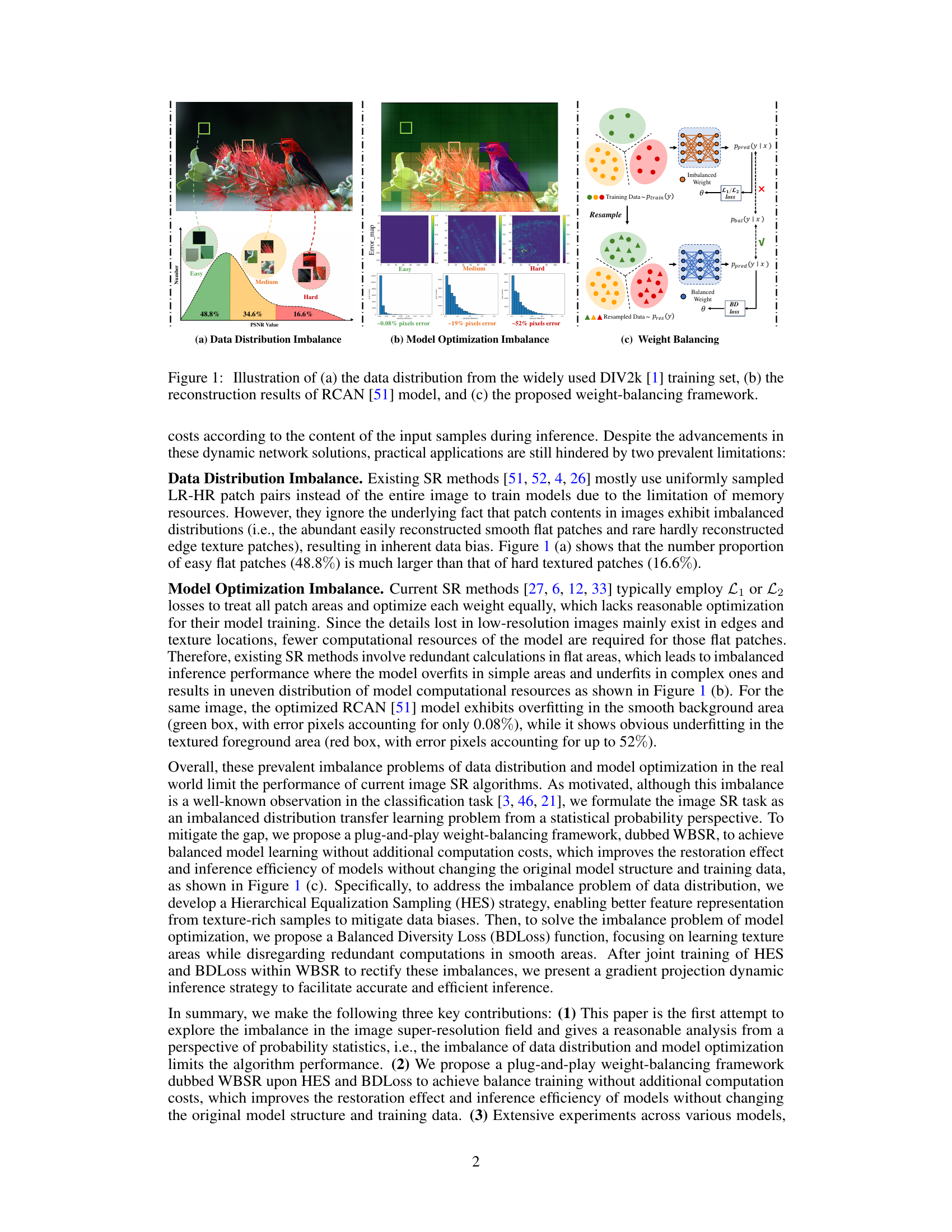
This figure illustrates three key aspects of the paper’s approach to addressing imbalance in image super-resolution. (a) Shows the imbalanced distribution of the DIV2k dataset, highlighting the disproportionate number of easy and hard patches. (b) Presents reconstruction results of a state-of-the-art model (RCAN) revealing that the model overfits easy patches (smooth areas) and underfits hard patches (texture-rich areas). (c) Outlines the proposed Weight-Balancing framework (WBSR), which aims to address data and model optimization imbalances by balancing the learning process. The framework uses Hierarchical Equalization Sampling (HES) for data balancing and Balanced Diversity Loss (BDLoss) for model optimization. This ultimately leads to more efficient and accurate super-resolution.
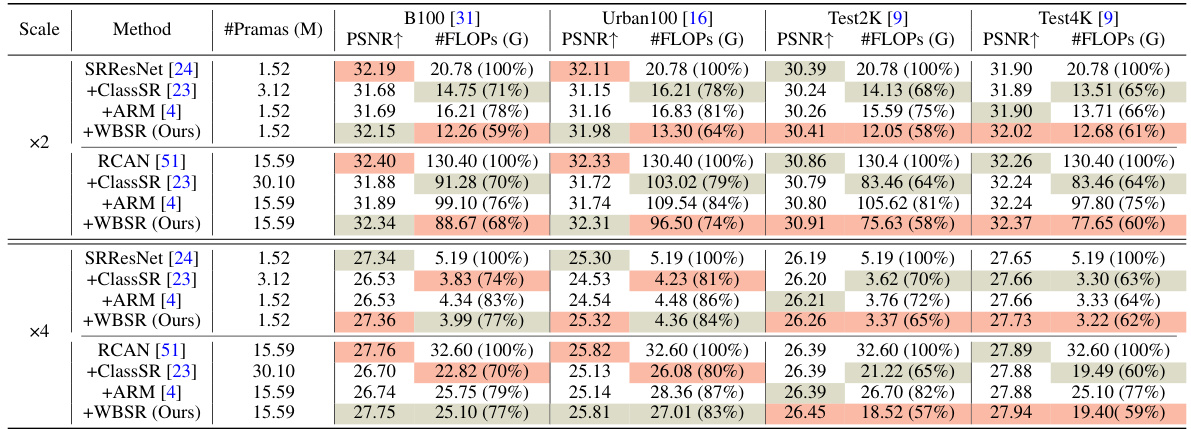
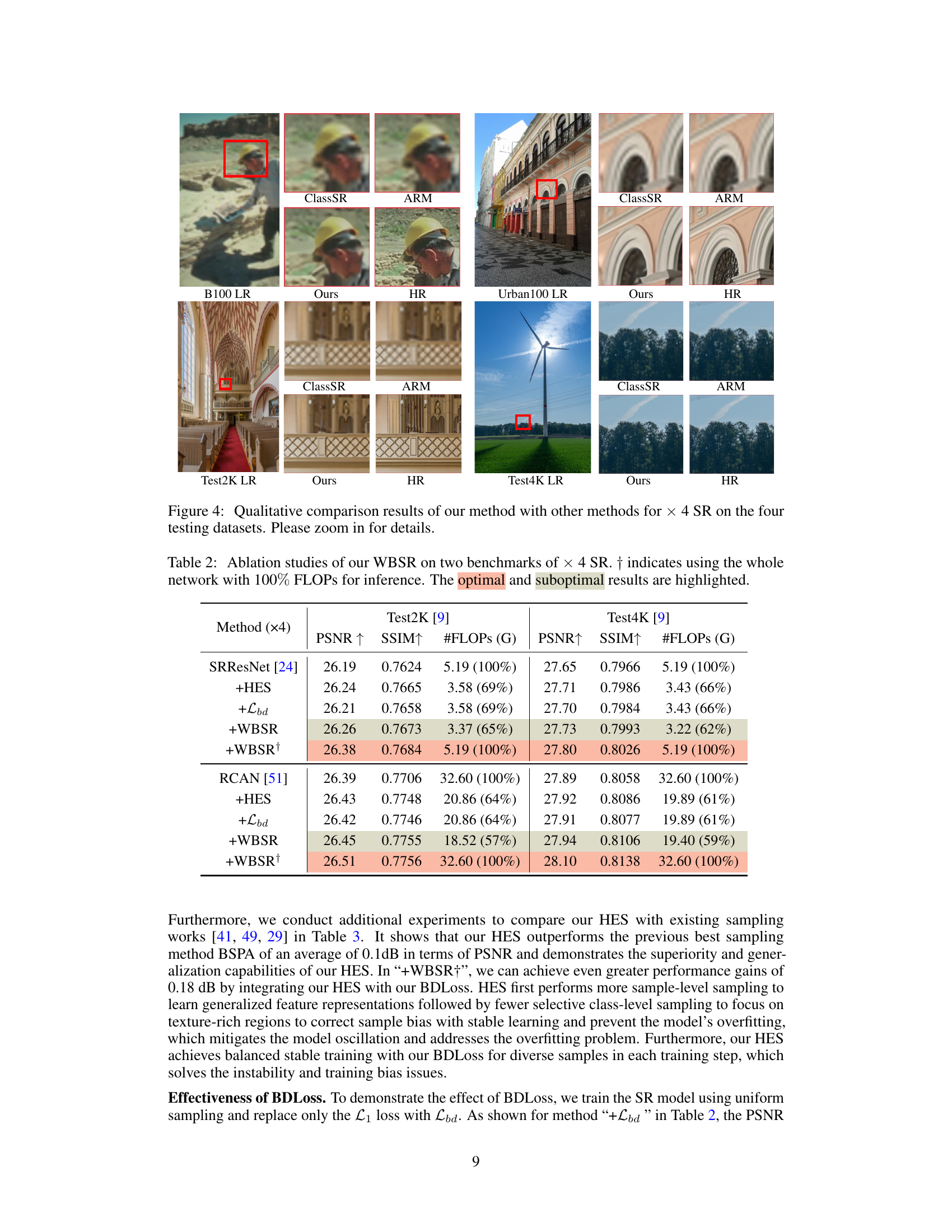
This table presents a quantitative comparison of the proposed Weight-Balancing framework (WBSR) against other state-of-the-art (SOTA) methods for image super-resolution (SR). The comparison is done across four different datasets (GoPro, B100, Urban100, and Test2K) and two scaling factors (x2 and x4). Metrics include PSNR, FLOPs (floating point operations), and the number of model parameters. The best and second-best results for each metric are highlighted to clearly show WBSR’s performance gains and efficiency improvements.
In-depth insights#
Imbalanced SR#
The concept of “Imbalanced SR” highlights a critical limitation in traditional super-resolution (SR) methods. These methods often fail to account for the inherent imbalance present in real-world image datasets, where some image patches (e.g., smooth regions) are far more abundant than others (e.g., detailed textures). This imbalance leads to suboptimal model training, where models may overfit to easily reconstructed patches while underfitting those with complex details. Addressing this imbalance is crucial for improved SR performance, particularly in generating high-quality results for all image regions. This requires new methodologies that effectively handle data and model optimization imbalances. Approaches to solve this problem might involve data resampling techniques to balance the dataset, novel loss functions that weigh differently easy and difficult patches, or dynamic inference mechanisms that adaptively allocate computational resources based on the difficulty of each patch. By addressing the issue of imbalanced data and optimization, significant advancements can be achieved in both the quality and efficiency of SR algorithms.
WBSR Framework#
The Weight-Balancing Super-Resolution (WBSR) framework tackles the core issue of imbalance in image super-resolution. It cleverly addresses both data distribution imbalance (e.g., abundance of easy samples versus scarcity of complex textures) and model optimization imbalance (uneven weight updates across model parameters). The framework achieves this using a two-pronged approach: Hierarchical Equalization Sampling (HES) for better representation of texture-rich samples and a Balanced Diversity Loss (BDLoss) to prioritize learning from texture areas while mitigating redundant computations in smooth regions. The framework is plug-and-play, meaning it adapts seamlessly to various existing SR models without structural modification. This results in a more efficient and accurate SR model, achieving comparable or superior performance with significantly reduced computational costs. Gradient projection dynamic inference further enhances efficiency by adaptively allocating resources during testing. The comprehensive design of WBSR provides a crucial advancement in SR model training and inference.
HES & BDLoss#
The proposed framework, integrating Hierarchical Equalization Sampling (HES) and Balanced Diversity Loss (BDLoss), presents a novel approach to address data and model optimization imbalances in image super-resolution. HES tackles data imbalance by strategically sampling image patches, prioritizing texture-rich areas often underrepresented in uniform sampling methods. This leads to improved feature representation, especially for challenging details. BDLoss, addressing model optimization imbalance, refocuses learning on these texture regions, reducing redundant computations on smooth areas. By jointly training with HES, BDLoss helps to learn more balanced model weights, improving overall performance. This combined approach is particularly significant because it enhances accuracy without increasing model complexity or computational cost during training, making it a practical and effective solution for efficient and accurate image super-resolution.
Dynamic Inference#
Dynamic inference, in the context of image super-resolution, aims to optimize computational efficiency without sacrificing accuracy. It involves adaptively allocating resources based on the complexity of the input image. This is achieved by employing multiple subnetworks, each designed for a specific level of detail or complexity. The choice of which subnetwork to use for a given patch is often determined dynamically through an evaluation of the input patch’s features, such as gradient magnitude, effectively reducing computation on simple regions while maintaining high accuracy on complex ones. This approach enables significant cost reduction, making real-time or resource-constrained applications feasible. However, designing an effective dynamic inference mechanism requires careful consideration of factors such as subnet complexity, selection criteria, and overall architecture design. The effectiveness hinges on striking a balance between the reduction in computational overhead and the preservation of reconstruction quality. Furthermore, the scalability and generalization ability of the dynamic inference method across diverse datasets and image types also need to be carefully evaluated.
Future Works#
The ‘Future Works’ section of this research paper could explore several promising avenues. Extending the Weight-Balancing framework (WBSR) to other image processing tasks, such as image denoising or deblurring, would demonstrate its generalizability and impact. Investigating the effectiveness of WBSR with various network architectures beyond the tested SRResNet and RCAN, including transformers or efficient convolutional networks, could reveal further performance gains or potential limitations. A deeper analysis of the Hierarchical Equalization Sampling (HES) strategy, particularly concerning its sensitivity to different data distributions and potential improvements via adaptive sampling techniques, would be beneficial. Finally, exploring the potential for hardware acceleration of the gradient projection dynamic inference would be crucial for practical applications, potentially through specialized hardware or optimized algorithms.
More visual insights#
More on figures

This figure illustrates the WBSR framework. The training stage (a) shows how hierarchical equalization sampling addresses data imbalance by sampling patches, leading to balanced weight updates using the Balanced Diversity Loss. The testing stage (b) details the dynamic inference, where input is chopped into patches, gradients are calculated and projected onto a map to route patches to appropriate subnets for processing, followed by combining results to produce the final high-resolution image. The framework aims to efficiently address data and model optimization imbalances for efficient inference.

This figure visualizes the process of gradient projection dynamic inference. (a) shows edge detection results, highlighting the boundaries of image regions. (b) displays the gradient magnitude, indicating the complexity of each region; higher magnitudes represent more complex areas. (c) demonstrates subnet selection based on gradient magnitude. Patches with low gradients (smooth areas) are assigned to small subnets, while patches with high gradients (texture-rich regions) are assigned to larger subnets. The color-coding helps visualize this dynamic allocation of resources during inference, illustrating how the model adapts its computational resources to the input image.

This figure illustrates the WBSR framework. The training stage uses Hierarchical Equalization Sampling (HES) and Balanced Diversity Loss (BDLoss) to train a supernet model. The testing stage uses gradient projection dynamic inference for efficiency. It shows how imbalanced LR patches are processed through HES to create balanced weights, then processed through the supernet and BDLoss to create a balanced and efficient model for inference.
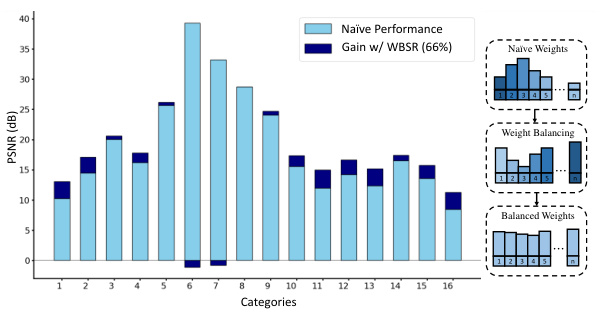
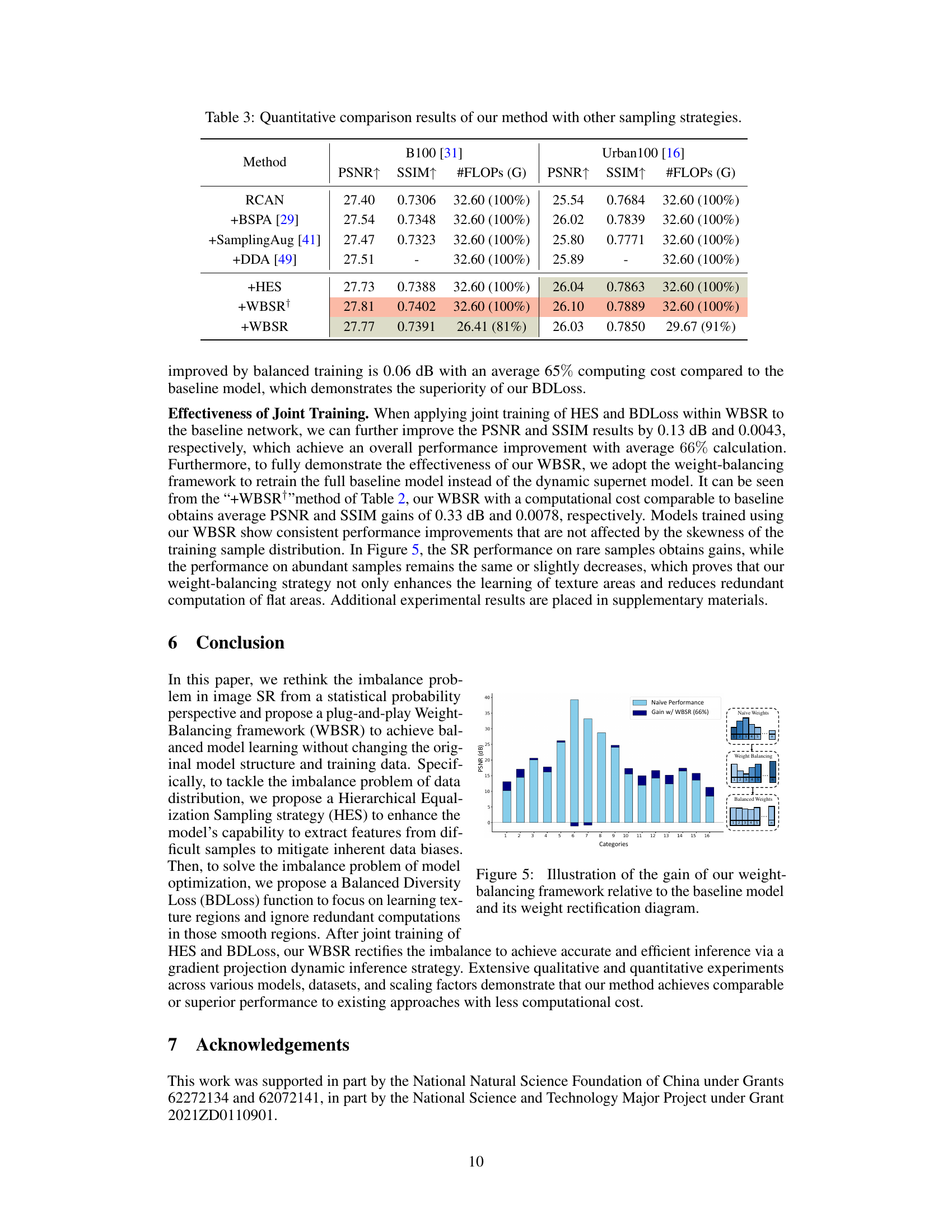
This figure illustrates the performance improvement achieved by the proposed Weight-Balancing framework (WBSR) compared to a baseline model. The bar chart shows the PSNR (Peak Signal-to-Noise Ratio) for different categories of image patches. The light blue bars represent the baseline model’s performance, while the dark blue bars show the additional gain achieved using the WBSR. The diagram on the right visually explains how the WBSR method rebalances the weights across different patch categories, leading to improved performance on challenging texture regions. The categories are based on the complexity of the image patches.

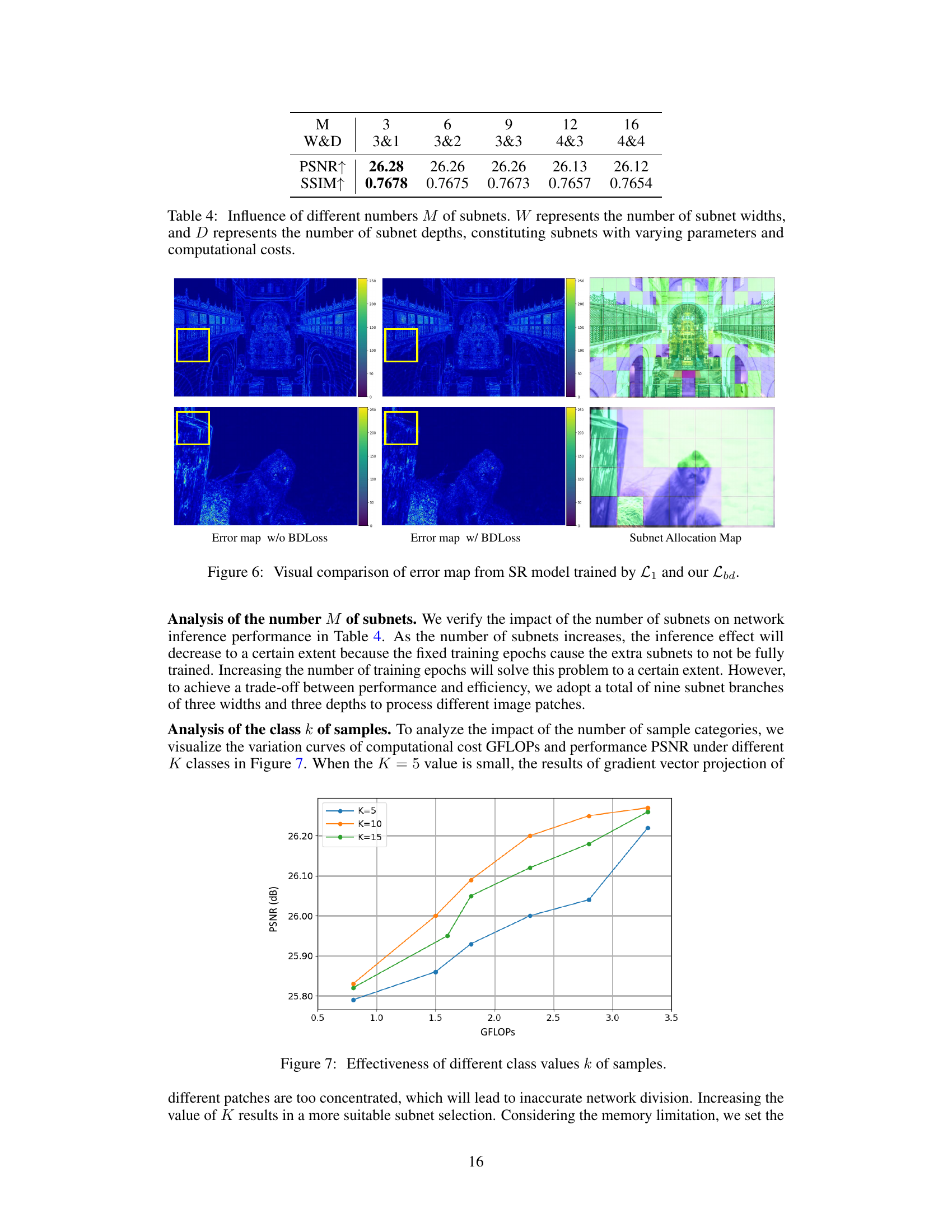
This figure shows a visual comparison of error maps generated using L1 loss and the proposed Balanced Diversity Loss (BDLoss). The error maps are displayed side-by-side for two different images. The rightmost image shows the subnet allocation map, which visualizes how different subnets are assigned to process various parts of the image. The comparison highlights the improved accuracy and efficiency of the BDLoss in handling complex textures and details, as evidenced by the reduced errors in the textured regions.

This figure shows the performance (PSNR) and computational cost (GFLOPs) of the model under different numbers of sample categories (K). The plot indicates that using a small number of categories (K=5) results in less accurate subnet selection due to concentrated gradient vector projections. Increasing the value of K improves the accuracy but also increases the computational cost. The optimal value of K balances the performance gain and computational cost trade-off, which is not explicitly stated in the figure but implied by the plotted trends.

This figure displays a qualitative comparison of super-resolution (SR) results from four different methods (ClassSR, ARM, WBSR (Ours), and a high-resolution (HR) ground truth) on four different test datasets (B100, Urban100, Test2K, and Test4K). Each dataset contains images with varying levels of complexity and texture. The results show that the proposed WBSR method generally produces more visually appealing and accurate reconstructions compared to the other three methods, especially in areas with complex textures. The WBSR method preserves more details and finer textures compared to other methods. In regions with simpler details, all four methods produce similar results.

This figure compares the super-resolution results of different methods on the Urban100 dataset. The top row shows the low-resolution (LR) image, followed by the results from ClassSR, ARM, the proposed WBSR method, and finally the high-resolution (HR) ground truth. The red boxes highlight regions of detail. The figure aims to visually demonstrate the superior performance of the WBSR method in recovering fine details and textures compared to existing approaches.

This figure visualizes the process of gradient projection dynamic inference. It shows three stages: edge detection, gradient magnitude calculation, and subnet selection based on gradient magnitude. Each stage highlights how the complexity of image patches is evaluated, ultimately leading to the appropriate subnet selection for efficient inference. Green, yellow, and red boxes represent different subnet choices based on computational cost.

This figure displays visual comparisons of super-resolution (SR) results from four different methods (ClassSR, ARM, the proposed WBSR, and a ground truth HR image) on four different test datasets (B100, Urban100, Test2k, and Test4k). The comparisons showcase the quality of reconstruction at a scale factor of x4, highlighting the improved detail and sharpness achieved with the proposed WBSR approach in comparison to the baseline methods.
More on tables
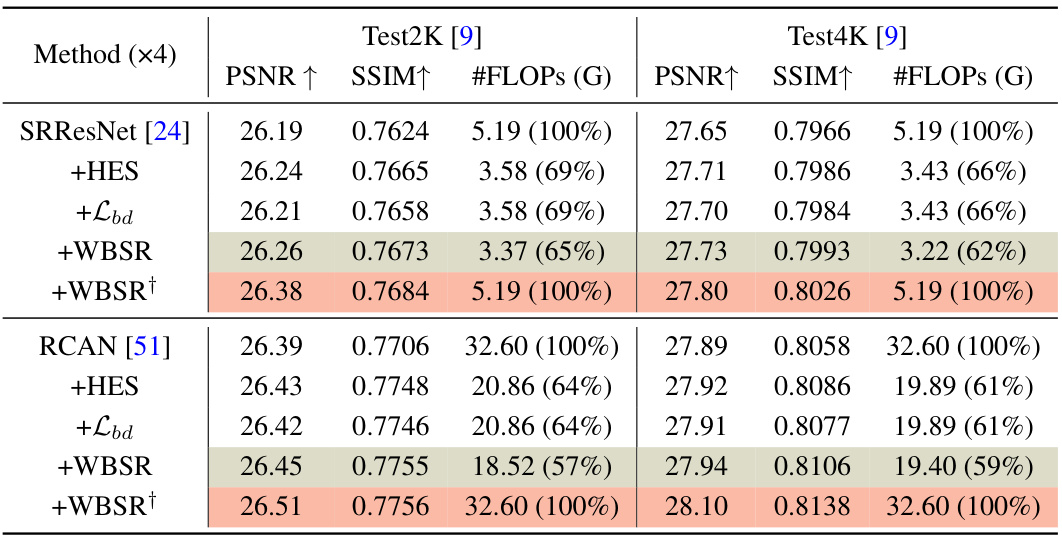
This table presents a quantitative comparison of the proposed WBSR framework against other state-of-the-art (SOTA) methods. The comparison is conducted on two datasets, GoPro and H2D, and across different super-resolution (SR) scaling factors (x2, x4). The metrics used for comparison include Peak Signal-to-Noise Ratio (PSNR), structural similarity index (SSIM), the number of model parameters (#Params), and floating point operations (#FLOPs). The table highlights the optimal and suboptimal results for each method and scale factor to facilitate easy identification of the best-performing approaches. The percentage values in parentheses show the computational cost relative to the baseline method in each row.
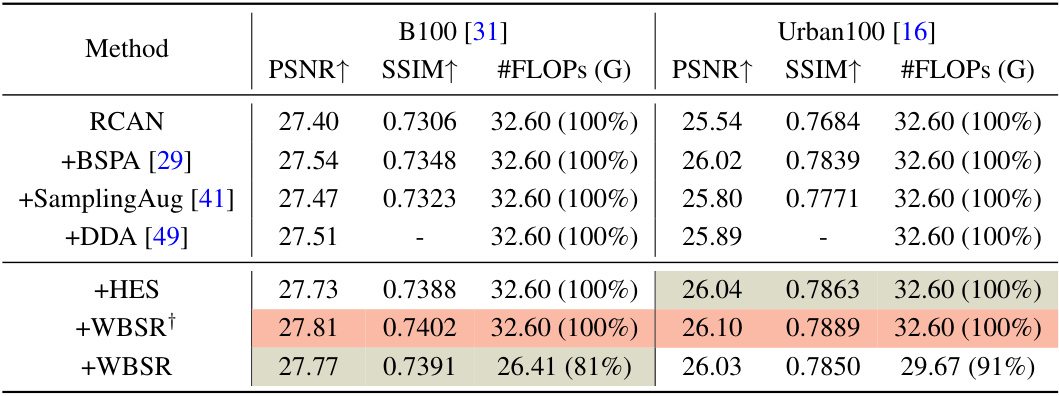
This table presents a quantitative comparison of the proposed method against other sampling strategies on two datasets: B100 and Urban100. The comparison is done using PSNR, SSIM, and #FLOPS (in Giga-FLOPs). It shows the impact of different sampling strategies on the performance and computational cost of image super-resolution. The results are presented as values and percentages relative to the baseline RCAN model, which allows for a clear visualization of the performance gains.

This table shows the impact of varying the number of subnets (M) on the performance of the SR model. Different configurations of subnet widths (W) and depths (D) are tested, resulting in subnets with different numbers of parameters and computational costs. The table presents the PSNR and SSIM scores obtained for each configuration, demonstrating how the number of subnets influences the model’s performance.
Full paper#