TL;DR#
Current methods for aligning large language models often involve a two-step process: supervised fine-tuning (SFT) followed by reinforcement learning from AI feedback (LAIF). While LAIF has shown promise, this paper challenges the necessity of this complex two-step approach. The authors found that the improvements attributed to the second step (LAIF) are mainly due to using weaker models for SFT data collection than for feedback generation. This raises concerns regarding the value of the added complexity of LAIF in many situations.
This research systematically compared simple SFT using state-of-the-art models to existing LAIF pipelines. They demonstrated that using the same strong model for both SFT data generation and feedback generation resulted in SFT matching or even exceeding the performance of the more complex LAIF approaches. This suggests a potential simplification of existing AI alignment techniques, offering increased efficiency and potentially reducing computational costs.
Key Takeaways#
Why does it matter?#
This paper is crucial because it challenges the prevailing wisdom in AI alignment, questioning the necessity of complex reinforcement learning in learning from AI feedback (LAIF). Its findings offer a more efficient approach to aligning language models and provide valuable insights for researchers working on improving instruction-following capabilities. This is vital for the rapid advancement of safe and reliable large language models.
Visual Insights#
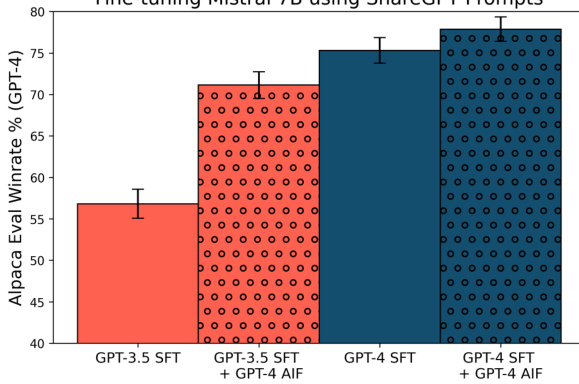
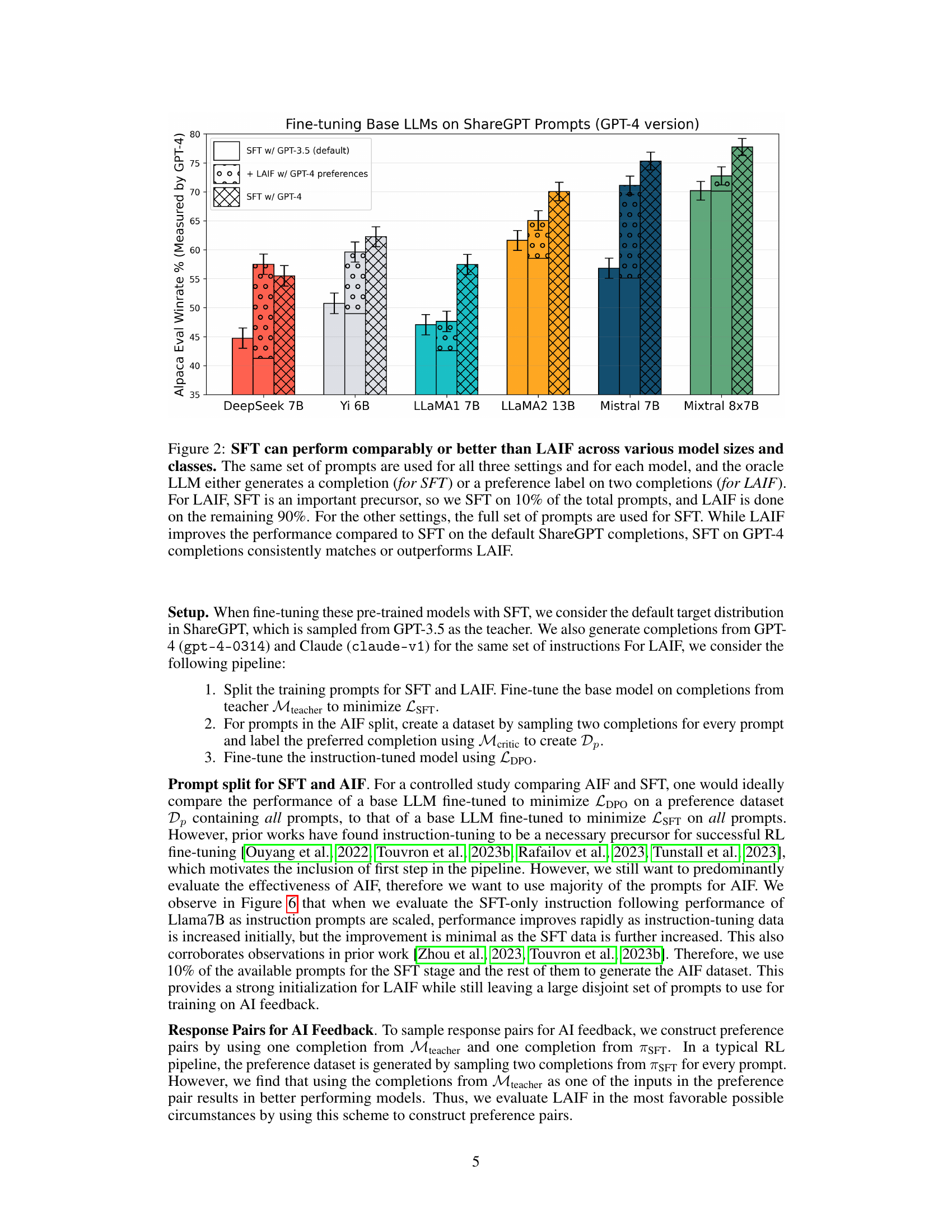
🔼 This figure compares the performance of different model fine-tuning methods using the ShareGPT dataset. It shows that using a stronger teacher model for supervised fine-tuning (SFT) can yield results comparable to or even better than the more complex learning from AI feedback (LAIF) approach. The improvement seen in LAIF using GPT-4 as a critic seems to be largely due to the weaker GPT-3.5 teacher model used in the original SFT dataset. Using GPT-4 as both teacher and critic in LAIF doesn’t provide significantly better results than SFT with GPT-4 alone.
read the caption
Figure 1: Supervised fine-tuning (SFT) on strong teachers can accounts for improvements from learning from AI feedback (LAIF). LAIF from strong models such as GPT-4 can result in substantially better instruction-following LLMs than supervised SFT alone on popular datasets such as ShareGPT [Chiang et al., 2023] constructed using GPT-3.5 completions (GPT-3.5 SFT + GPT-4 AIF). However, simply performing SFT on completions from GPT-4 can result in a better model (GPT-4 SFT), suggesting that improvement in performance from LAIF is partly because the default ShareGPT completions are from a weak teacher (GPT-3.5). Furthermore, LAIF (GPT-4 SFT + GPT-4 AIF) does not result in a significantly better model compared to GPT-4 SFT alone.

🔼 This table presents the results of an experiment designed to investigate the impact of preference data source on the performance of LLMs fine-tuned with learning from AI feedback (LAIF). Two base LLMs, Llama 7B and Mistral 7B, were fine-tuned using LAIF with preference data generated by either Llama 7B or Mistral 7B. The results show that the performance after fine-tuning is strongly influenced by the base LLM, rather than the source of preference data. Mistral 7B achieves similar performance when trained on Llama 7B preferences, while Llama 7B does not improve significantly when trained on Mistral 7B preferences.
read the caption
Table 1: LAIF with preference data responses sampled from a different model than the base model being fine-tuned. We find that the final performance after fine-tuning is affected more by the choice of the base LLM, as Mistral 7B reaches a similar performance when fine-tuning on preferences over Llama 7B responses, whereas Llama7B does not improve significantly when trained on preferences over responses generated by Mistral 7B.
In-depth insights#
LAIF’s Limitations#
The paper reveals crucial limitations of Learning from AI Feedback (LAIF), a prominent method for aligning large language models. LAIF’s effectiveness hinges heavily on the disparity between the teacher and critic models’ capabilities. When a strong model is used for both SFT and AI feedback, the incremental gains from LAIF diminish significantly, with supervised fine-tuning (SFT) alone often performing comparably or even better. This highlights LAIF’s reliance on a weak teacher model to create a substantial performance gap, which the critic model then rectifies, rather than representing a truly superior training paradigm. Moreover, the study reveals substantial variability in LAIF’s success across different base models, evaluation protocols, and critic models. This inconsistent performance underscores the need for a more nuanced understanding of LAIF’s strengths and limitations before widely adopting it as the primary alignment technique.
SFT vs. LAIF#
The core of the paper revolves around a comparative analysis of Supervised Fine-Tuning (SFT) and Learning from AI Feedback (LAIF), two prominent techniques for aligning Large Language Models (LLMs). The authors challenge the prevailing notion that LAIF, involving complex reinforcement learning steps, consistently outperforms SFT. Their findings suggest that improvements from LAIF are often largely attributable to a capability mismatch between the weaker teacher model used in SFT and the stronger critic model employed in LAIF. In scenarios where both SFT and LAIF leverage strong models, SFT often demonstrates comparable or even superior performance. This highlights the significance of data quality and model capability in determining the effectiveness of each approach, suggesting that a focus on high-quality training data may be more crucial than the complexity of the alignment method itself. The paper also emphasizes the importance of considering base model capabilities and evaluation protocols when assessing the benefits of LAIF, urging further investigation into maximizing the practical utility of both SFT and LAIF.
Teacher Model Impact#
The effectiveness of AI Feedback (LAIF) for aligning LLMs is significantly impacted by the choice of teacher model used during supervised fine-tuning (SFT). A weaker teacher model (like GPT-3.5) combined with a stronger critic model (like GPT-4) in the LAIF pipeline leads to substantial performance gains, primarily because the RL step compensates for the inferior SFT data. This suggests that the complexity of the RL stage in LAIF may be largely an artifact of using suboptimal teacher models. Conversely, using a strong teacher model (e.g., GPT-4) for SFT often yields comparable or superior performance to the complete LAIF process, highlighting the crucial role of high-quality teacher data in optimizing LLMs. This finding underscores the importance of carefully selecting the teacher model based on the specific task and available resources, as utilizing a strong teacher model for SFT can obviate the need for the resource-intensive RL step in LAIF, leading to potentially more efficient and effective alignment strategies.
Mechanistic Insights#
The mechanistic insights section of this research paper would ideally delve into the why behind the observed phenomena. Specifically, it should offer explanations for why supervised fine-tuning (SFT) with a strong language model often outperforms the more complex learning from AI feedback (LAIF) pipeline. This could involve exploring the limitations of LAIF, perhaps due to suboptimal exploration within the reinforcement learning framework, or issues related to reward model inaccuracies. A key focus would be explaining how capability mismatches between the teacher and critic models in LAIF lead to seemingly beneficial results, rather than true improvements. Addressing the limitations of current evaluation metrics, such as AlpacaEval, would also be a crucial aspect of this section. Finally, the section should provide a theoretical understanding, possibly through a simplified model like a bandit problem, that formally supports the empirical findings and clarifies when SFT alone is sufficient and when the added complexity of LAIF might be truly beneficial.
Future Directions#
Future research should prioritize developing more robust and reliable methods for evaluating AI feedback’s effectiveness. Current evaluation metrics may not fully capture the nuanced improvements or limitations of AI feedback-based fine-tuning. Investigating the interplay between the quality of the teacher model, the critic model, and the base model’s architecture is crucial for understanding the factors that influence AI feedback’s efficacy. Furthermore, exploration of alternative training paradigms beyond supervised fine-tuning and reinforcement learning, such as direct preference optimization, warrants further investigation. Finally, addressing the potential for bias and safety concerns arising from the use of AI feedback in model alignment is essential. Thorough analysis of the distributions used for training and evaluation, along with rigorous testing across diverse datasets and evaluation scenarios, are imperative for ensuring that AI feedback methods consistently improve model behavior in a safe and equitable manner. The long-term goal should be creating techniques to produce more aligned LLMs with human values and reducing the reliance on large-scale, potentially biased, human feedback data.
More visual insights#
More on figures

🔼 This figure compares the performance of Supervised Fine-Tuning (SFT) and Learning from AI Feedback (LAIF) across different language models of varying sizes. It demonstrates that while LAIF sometimes improves upon the default SFT (using GPT-3.5 generated completions), simply using SFT with higher-quality completions from GPT-4 consistently matches or surpasses LAIF’s performance. This highlights that LAIF’s apparent gains may stem from compensating for weaker initial SFT data rather than inherent superiority.
read the caption
Figure 2: SFT can perform comparably or better than LAIF across various model sizes and classes. The same set of prompts are used for all three settings and for each model, and the oracle LLM either generates a completion (for SFT) or a preference label on two completions (for LAIF). For LAIF, SFT is an important precursor, so we SFT on 10% of the total prompts, and LAIF is done on the remaining 90%. For the other settings, the full set of prompts are used for SFT. While LAIF improves the performance compared to SFT on the default ShareGPT completions, SFT on GPT-4 completions consistently matches or outperforms LAIF.
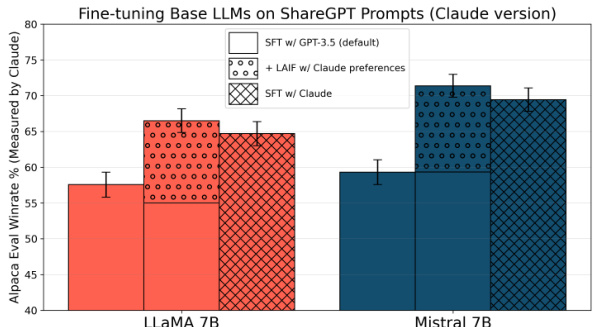
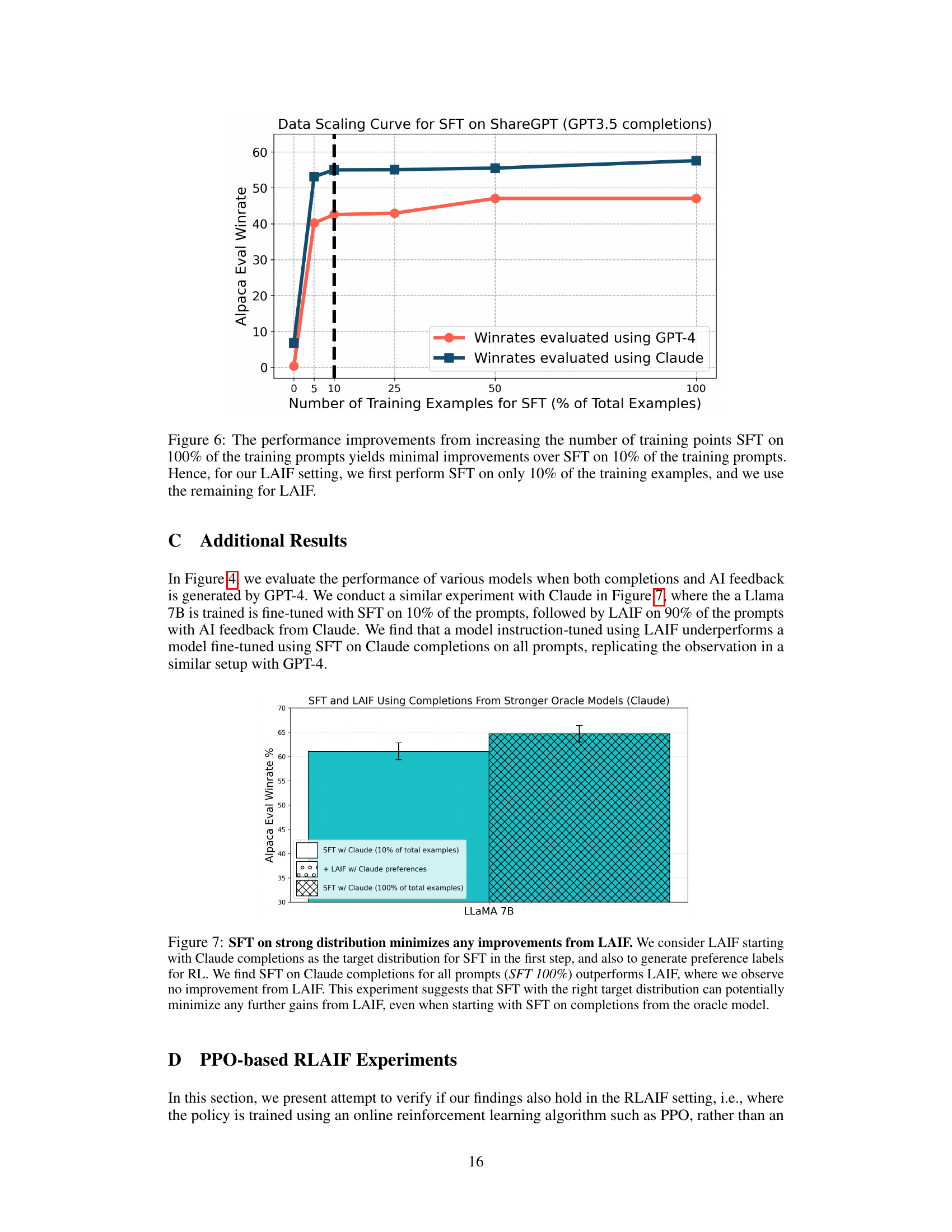
🔼 This figure compares the performance of supervised fine-tuning (SFT) and learning from AI feedback (LAIF) using different strong language models (Claude and GPT-4) as critics. It shows that when using Claude as the critic, SFT using Claude as the teacher model performs comparably to or better than LAIF. This suggests that the performance gains from LAIF in previous experiments were largely due to using a weaker teacher (GPT-3.5) during the SFT stage. The results imply that the benefits of the complex LAIF pipeline may be overestimated, and that simply using SFT with high-quality teacher completions can be just as effective, or even better.
read the caption
Figure 3: We make a similar observation that SFT performs comparably to LAIF when Claude as is used as an oracle. LAIF with AI feedback from does not significantly outperform SFT on Claude completions, and the performance improvement from LAIF is explained by the use of a weaker SFT target distribution (GPT-3.5). The results for effectiveness of SFT may apply more generally to strong LLMs beyond GPT-4.
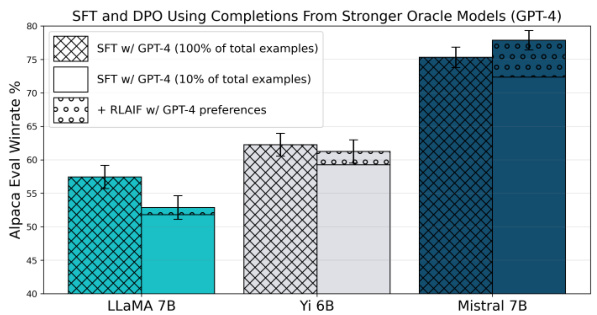
🔼 This figure compares the performance of supervised fine-tuning (SFT) and learning from AI feedback (LAIF) on various language models. It shows that using a stronger teacher model for SFT can lead to performance comparable to or even better than LAIF, especially when using GPT-4 as the teacher model. The improvement from LAIF is mainly due to using a weaker teacher model (GPT-3.5) for SFT in the default ShareGPT dataset. The figure demonstrates that aligning models via SFT using strong teacher model completions can achieve similar or even superior performance compared to LAIF.
read the caption
Figure 2: SFT can perform comparably or better than LAIF across various model sizes and classes. The same set of prompts are used for all three settings and for each model, and the oracle LLM either generates a completion (for SFT) or a preference label on two completions (for LAIF). For LAIF, SFT is an important precursor, so we SFT on 10% of the total prompts, and LAIF is done on the remaining 90%. For the other settings, the full set of prompts are used for SFT. While LAIF improves the performance compared to SFT on the default ShareGPT completions, SFT on GPT-4 completions consistently matches or outperforms LAIF.
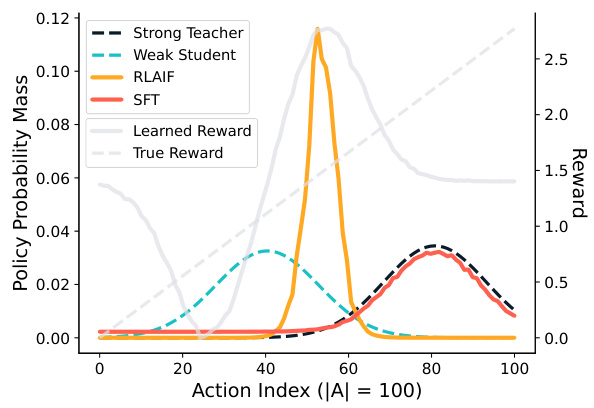
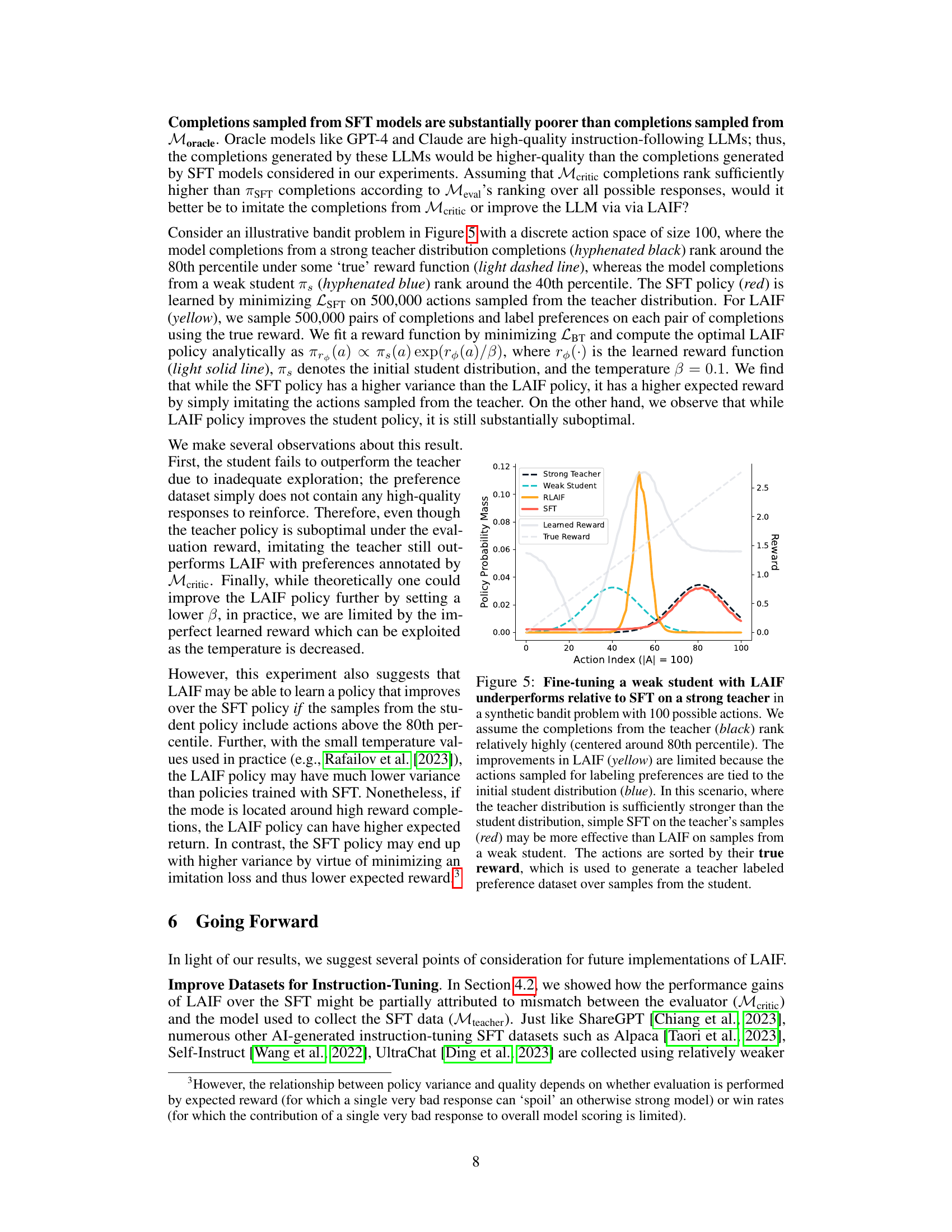
🔼 This figure illustrates a simplified bandit problem comparing supervised fine-tuning (SFT) and reinforcement learning from AI feedback (RLAIF). It demonstrates that when the teacher model provides high-quality data, SFT can outperform RLAIF. The limitations of RLAIF stem from using a weak student model for data generation, which constrains exploration and improvement.
read the caption
Figure 5: Fine-tuning a weak student with LAIF underperforms relative to SFT on a strong teacher in a synthetic bandit problem with 100 possible actions. We assume the completions from the teacher (black) rank relatively highly (centered around 80th percentile). The improvements in LAIF (yellow) are limited because the actions sampled for labeling preferences are tied to the initial student distribution (blue). In this scenario, where the teacher distribution is sufficiently stronger than the student distribution, simple SFT on the teacher's samples (red) may be more effective than LAIF on samples from a weak student. The actions are sorted by their true reward, which is used to generate a teacher labeled preference dataset over samples from the student.
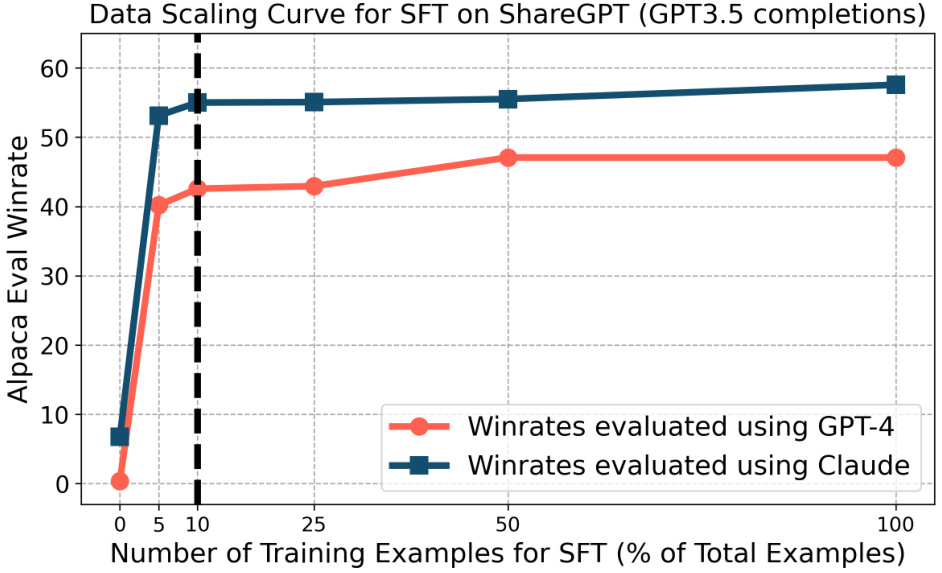
🔼 This figure shows the impact of increasing the number of training examples used for supervised fine-tuning (SFT) on the performance of language models. It demonstrates that using a larger number of training examples doesn’t improve performance significantly once a certain amount of data has been used. This finding supports the strategy used in the paper’s LAIF experiments where only 10% of data was used for SFT, reserving the remaining 90% for AI feedback.
read the caption
Figure 6: The performance improvements from increasing the number of training points SFT on 100% of the training prompts yields minimal improvements over SFT on 10% of the training prompts. Hence, for our LAIF setting, we first perform SFT on only 10% of the training examples, and we use the remaining for LAIF.
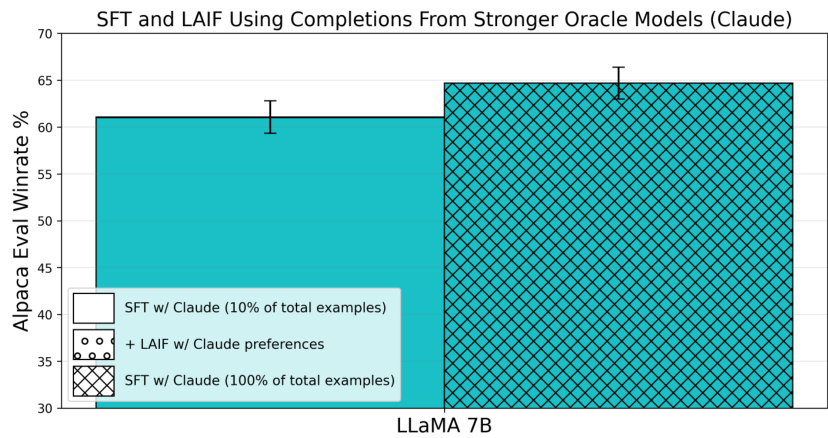
🔼 This figure compares the performance of supervised fine-tuning (SFT) and learning from AI feedback (LAIF) across different language models. It shows that while LAIF often improves upon the baseline SFT using the default ShareGPT dataset (trained on GPT-3.5 completions), simply using SFT with GPT-4 completions consistently performs as well or better than LAIF. This highlights the importance of the quality of the training data (the teacher model) for instruction following in LLMs.
read the caption
Figure 2: SFT can perform comparably or better than LAIF across various model sizes and classes. The same set of prompts are used for all three settings and for each model, and the oracle LLM either generates a completion (for SFT) or a preference label on two completions (for LAIF). For LAIF, SFT is an important precursor, so we SFT on 10% of the total prompts, and LAIF is done on the remaining 90%. For the other settings, the full set of prompts are used for SFT. While LAIF improves the performance compared to SFT on the default ShareGPT completions, SFT on GPT-4 completions consistently matches or outperforms LAIF.
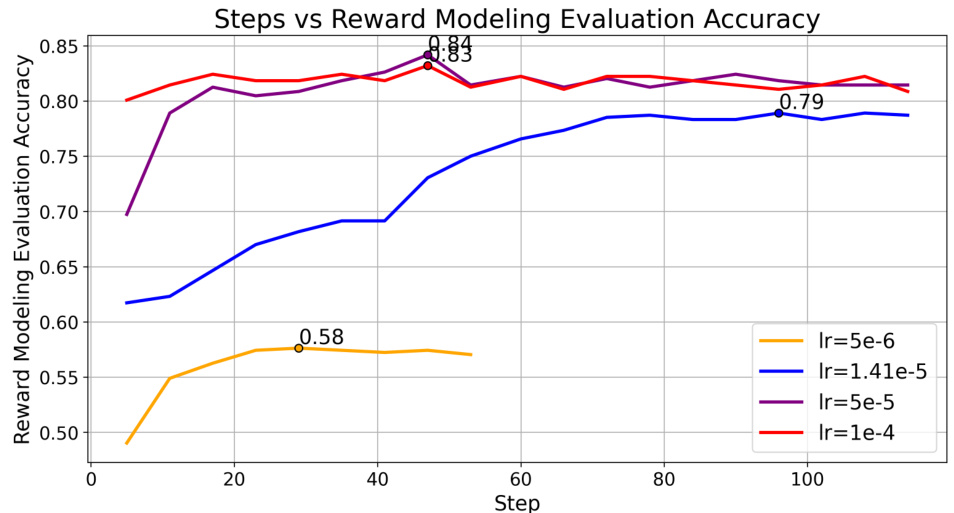
🔼 This figure shows the reward modeling evaluation accuracy across steps for different learning rates during the reward model training in the reinforcement learning from AI feedback (RLAIF) pipeline. The x-axis represents the training step, and the y-axis shows the reward modeling evaluation accuracy. Different colored lines represent different learning rates used in the training process. The figure highlights that the learning rate of 5e-5 achieved the highest reward modeling accuracy (84.18%).
read the caption
Figure 8: The highest point for each LR curve is highlighted. Our best reward model is the model trained with lr=5e-5, which reaches an accuracy of 84.18%.
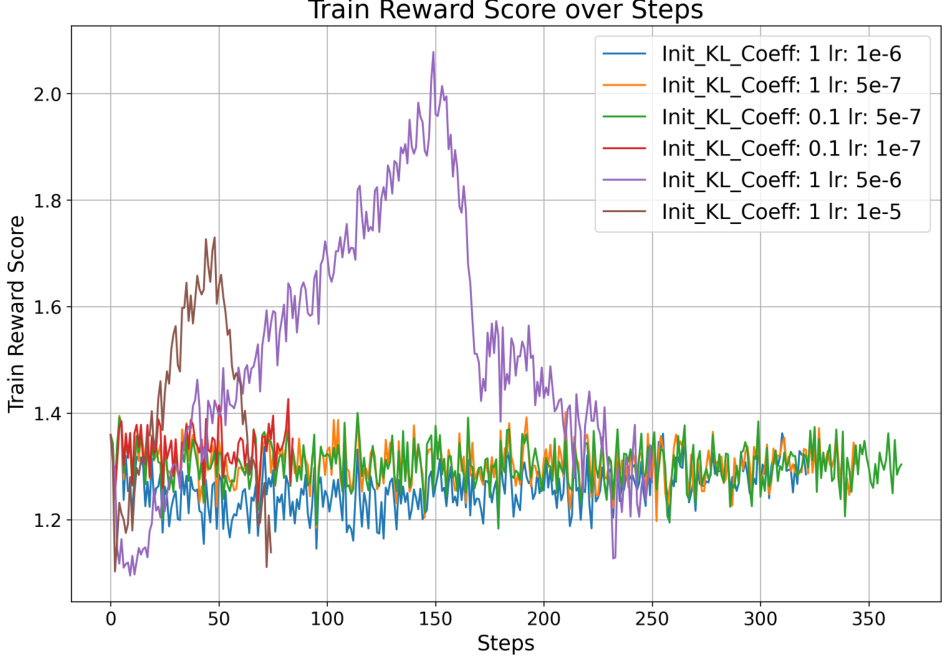
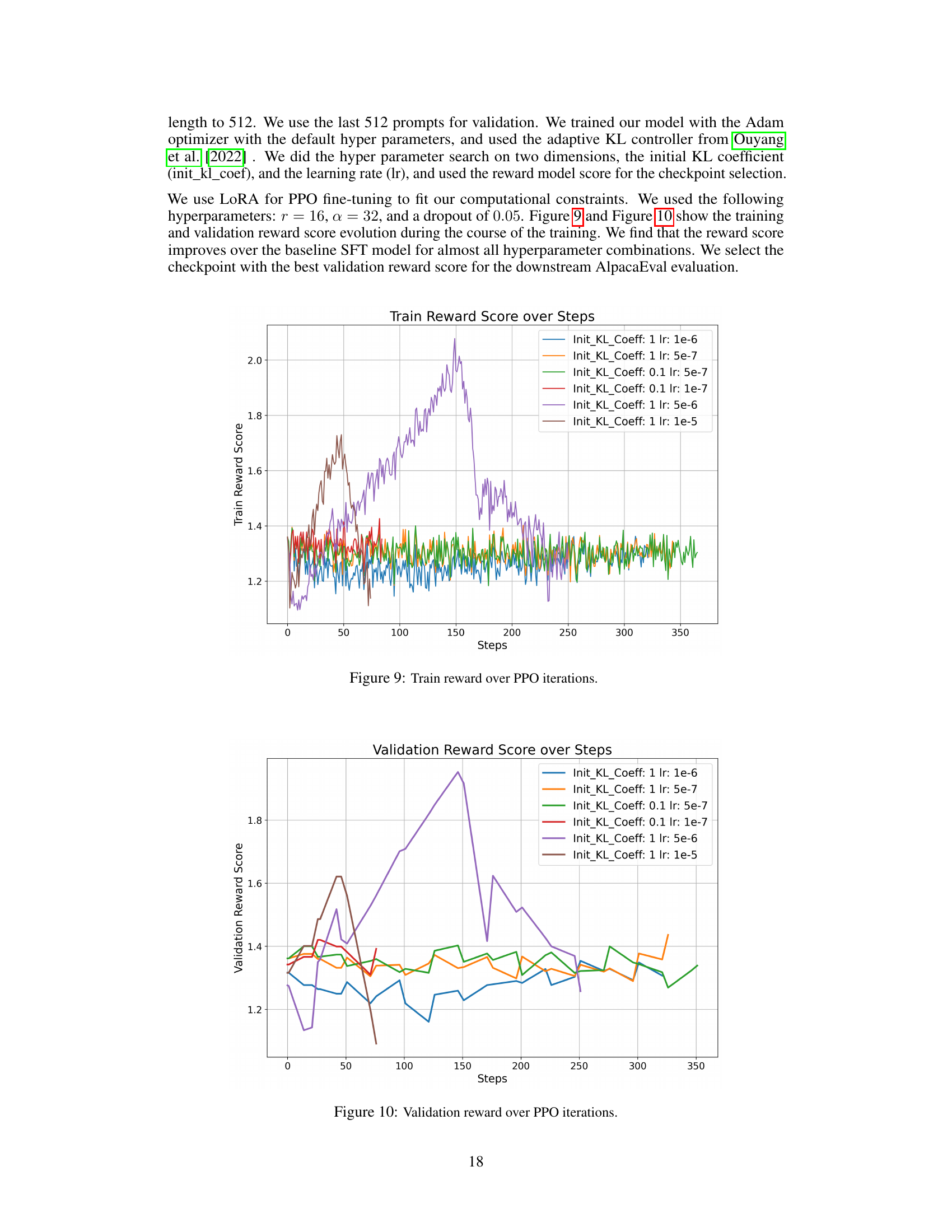
🔼 This figure shows the training reward score evolution during the course of the PPO training. It displays the train reward score over steps for various hyperparameter combinations: init_kl_coeff and lr. The plot helps visualize how the reward score changes across different iterations of PPO training under different hyperparameter settings.
read the caption
Figure 9: Train reward over PPO iterations.
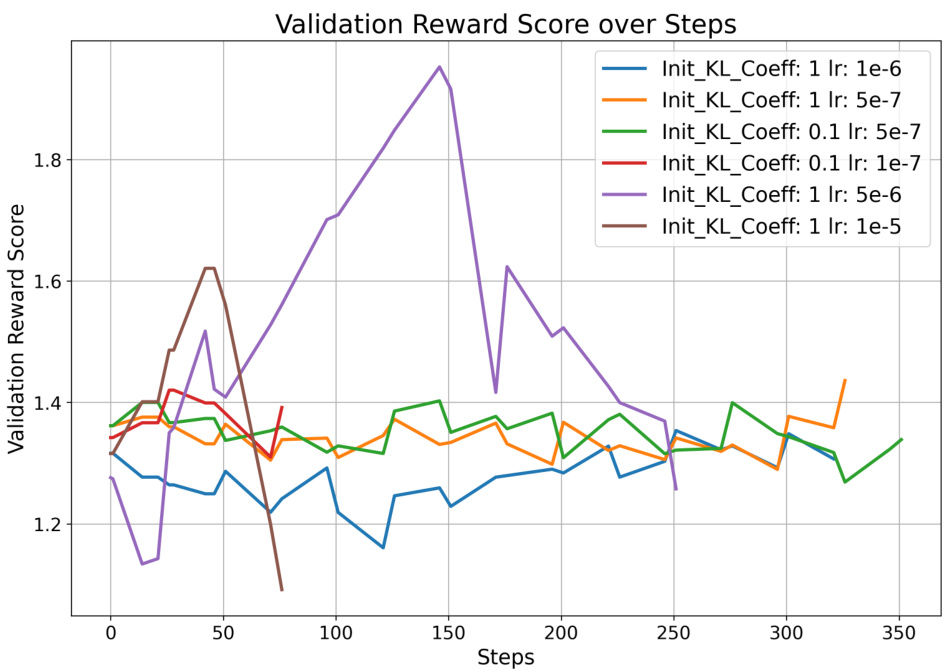
🔼 This figure shows the validation reward score over steps during PPO training in the RLAIF experiments. Different lines represent different hyperparameter combinations for the initial KL coefficient and learning rate. The x-axis represents the number of steps in the PPO training process, and the y-axis represents the validation reward score. The goal is to observe the trend of the validation reward score during training to identify the best hyperparameter settings.
read the caption
Figure 10: Validation reward score over PPO iterations.
Full paper#