TL;DR#
Large Vision Language Models (LVLMs) struggle with the high cost and effort of acquiring large, high-quality training data. Current self-training approaches aren’t effective due to the unique visual perception and reasoning needed by LVLMs.
This paper introduces Self-Training on Image Comprehension (STIC) to solve this. STIC uses unlabeled images to create a preference dataset for image descriptions, focusing on both preferred and dispreferred responses. Then, a small portion of existing instruction-tuning data is used alongside the self-generated data to fine-tune the model, further improving its reasoning. Results show significant performance gains across several benchmarks while using far less labeled data.
Key Takeaways#
Why does it matter?#
This paper is important because it presents STIC, a novel self-training approach that significantly improves the performance of large vision language models (LVLMs) by using unlabeled image data. This addresses the crucial challenge of acquiring high-quality vision-language data, which is expensive and time-consuming. The effectiveness of STIC across various benchmarks demonstrates its potential for advancing the field of LVLMs, opening new avenues for research focusing on cost-effective self-training methods for multimodal models.
Visual Insights#

🔼 The figure on the left shows a bar chart comparing the accuracy improvement achieved by the proposed STIC method against the baseline LLaVA-v1.6 model across seven different vision-language benchmarks. The figure on the right provides example queries and responses from both the baseline LLaVA-v1.6 and the STIC-enhanced LLaVA-v1.6 model, highlighting the improved image comprehension and reasoning capabilities of the STIC method. The example demonstrates that STIC produces a more accurate answer to a question about the price and quantity of gasoline, as seen on a gas station sign.
read the caption
Figure 1: Left: Accuracy improvement of our method, STIC, compared to the original LLaVA-v1.6 (Liu et al., 2024) on seven benchmarks. Right: Response examples from the original LLaVA-v1.6 and STIC (LLaVA-v1.6), which enhances image comprehension and subsequent reasoning capabilities.
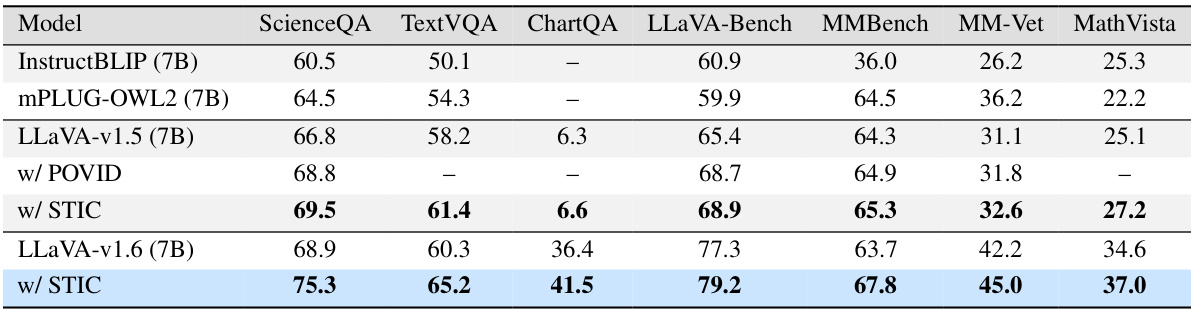
🔼 This table presents the performance comparison between the original Large Vision Language Model (LLVM) and the same model enhanced with Self-Training on Image Comprehension (STIC) across seven different vision-language reasoning benchmarks. The benchmarks cover diverse tasks such as scientific question answering, mathematical reasoning, optical character recognition, and various visual question answering scenarios. The table includes results for different LLVM versions (7B and 13B parameters) and compares STIC’s performance against baselines (InstructBLIP, mPLUG-OWL2, and POVID). The ‘-’ symbol indicates that the baseline study did not report that specific metric.
read the caption
Table 1: Performance of STIC compared with the original LVLM model across vision-language reasoning tasks. For LLaVA-v1.5 (Vicuna 7B), we directly report the values in the paper of POVID, and '-' indicates an unreported value.
In-depth insights#
STIC Framework#
The STIC framework introduces a novel self-training approach for Large Vision Language Models (LVLMs). It’s a two-stage process: Stage 1 focuses on building a preference dataset for image descriptions using unlabeled images and strategically designed prompts, including ‘good’ and ‘bad’ prompts that generate preferred and dispreferred responses. Stage 2 refines the LVLMs by incorporating these self-generated descriptions alongside existing instruction-tuning data, enabling a description-infused fine-tuning stage. This approach cleverly leverages unlabeled data, reducing reliance on expensive human-labeled datasets. The design is especially notable for its focus on improving image comprehension, a crucial aspect of LVLMs that other self-training methods often overlook. By directly tackling image understanding alongside reasoning, the STIC framework shows significant promise for making LVLMs more robust and effective while substantially decreasing training costs.
Ablation Studies#
Ablation studies systematically remove components of a model to assess their individual contributions. In this context, understanding which aspects of the self-training process are essential is crucial. The authors likely investigated variations of the model, such as removing the negative sample generation, the step-by-step prompting, or the description-infused fine-tuning. Results from these experiments would reveal the relative importance of each element. Performance drops upon removing a component highlight its significance, while minimal change indicates redundancy. The overall goal is to isolate the key drivers of the method’s success, thus justifying design choices and potentially simplifying the approach. Insights into the most crucial components would improve understanding and allow for future model optimization.
Image Diversity#
Image diversity is a crucial factor influencing the performance and generalizability of large vision-language models (LVLMs). A diverse image dataset ensures the model is exposed to a wide range of visual styles, objects, and contexts, reducing the risk of overfitting to specific characteristics present in a limited dataset. This leads to improved robustness in handling unseen images, crucial for real-world applications where image variability is high. A lack of diversity, however, can result in biased or inaccurate model predictions, as the model may fail to generalize to images significantly different from those encountered during training. Therefore, careful consideration of image diversity during dataset creation and model training is paramount to building reliable and fair LVLMs. Strategies to enhance image diversity include expanding the range of sources, utilizing diverse image augmentation techniques, and employing methods that explicitly quantify and monitor image diversity. The ultimate goal is to create models that can effectively understand and interact with visual information from diverse real-world settings.
STIC Scalability#
The scalability of STIC, a self-training approach for enhancing Large Vision Language Models (LVLMs), is a crucial aspect determining its real-world applicability. Experiments demonstrate that increasing the size of the self-generated preference dataset significantly improves the model’s performance, suggesting a positive scaling relationship. This is particularly valuable given the abundance of readily available unlabeled image data that can be leveraged. However, future research should investigate the upper limits of this scaling behavior to determine if diminishing returns exist at some point. Understanding this scaling behavior is key to optimizing STIC for various scenarios and resource constraints. The ability to scale efficiently with limited computational resources and extensive datasets is paramount for widespread adoption and impact. Moreover, the scalability of STIC in conjunction with different LVLMs of varying sizes needs to be explored to assess its generalizability and effectiveness. This will ensure that the performance gains are consistent and robust across a range of model architectures and capacities, further highlighting the potential for broader adoption.
Future Work#
The authors suggest several promising avenues for future research. Extending STIC to encompass more diverse image datasets beyond MSCOCO is crucial to enhance its generalizability and effectiveness across various visual domains. They also mention investigating more sophisticated strategies for constructing preference data, possibly involving more nuanced comparisons and human-in-the-loop methods, to further improve the model’s learning. Integrating the two stages of STIC into a single end-to-end training process is another avenue, potentially leading to greater synergies and performance gains. Finally, a more thorough exploration of the scaling law of STIC, examining the effects of using vastly larger quantities of unlabeled images for self-training, is needed to understand its ultimate limits and potential for even greater improvements.
More visual insights#
More on figures

🔼 This figure illustrates the two-stage self-training process of STIC. Stage 1 focuses on building a preference dataset for image descriptions by using a base large vision language model (LVLM) to generate preferred and dispreferred responses. Preferred responses are generated using detailed step-by-step prompts, while dispreferred responses come from either bad prompts or corrupted images. Stage 2 then leverages the created dataset, plus a small portion of existing instruction-tuning data combined with the self-generated descriptions to further fine-tune the LVLM and improve its reasoning capabilities.
read the caption
Figure 2: Framework overview of STIC, a two-stage self-training algorithm focusing on the image comprehension capability of the LVLMs. In Stage 1, the base LVLM self-constructs its preference dataset for image description using well-designed prompts, poorly-designed prompts, and distorted images. In Stage 2, a small portion of the previously used SFT data is recycled and infused with model-generated image descriptions to further fine-tune the base LVLM.

🔼 This figure shows three examples of image descriptions generated by the model. The first example is a preferred response generated using a well-crafted, step-by-step prompt that guides the model to provide a detailed and accurate description of the image. The second and third examples show dispreferred responses generated using either a bad prompt (that encourages the model to imagine objects not present in the image) or an image corrupted with color jitter or lower resolution. These examples highlight the different qualities of data used to train the model in STIC, which helps the model learn to distinguish between preferred and dispreferred responses. The variation in description quality helps the model learn better image comprehension and reasoning.
read the caption
Figure 3: Examples of the self-constructed preference data in STIC.

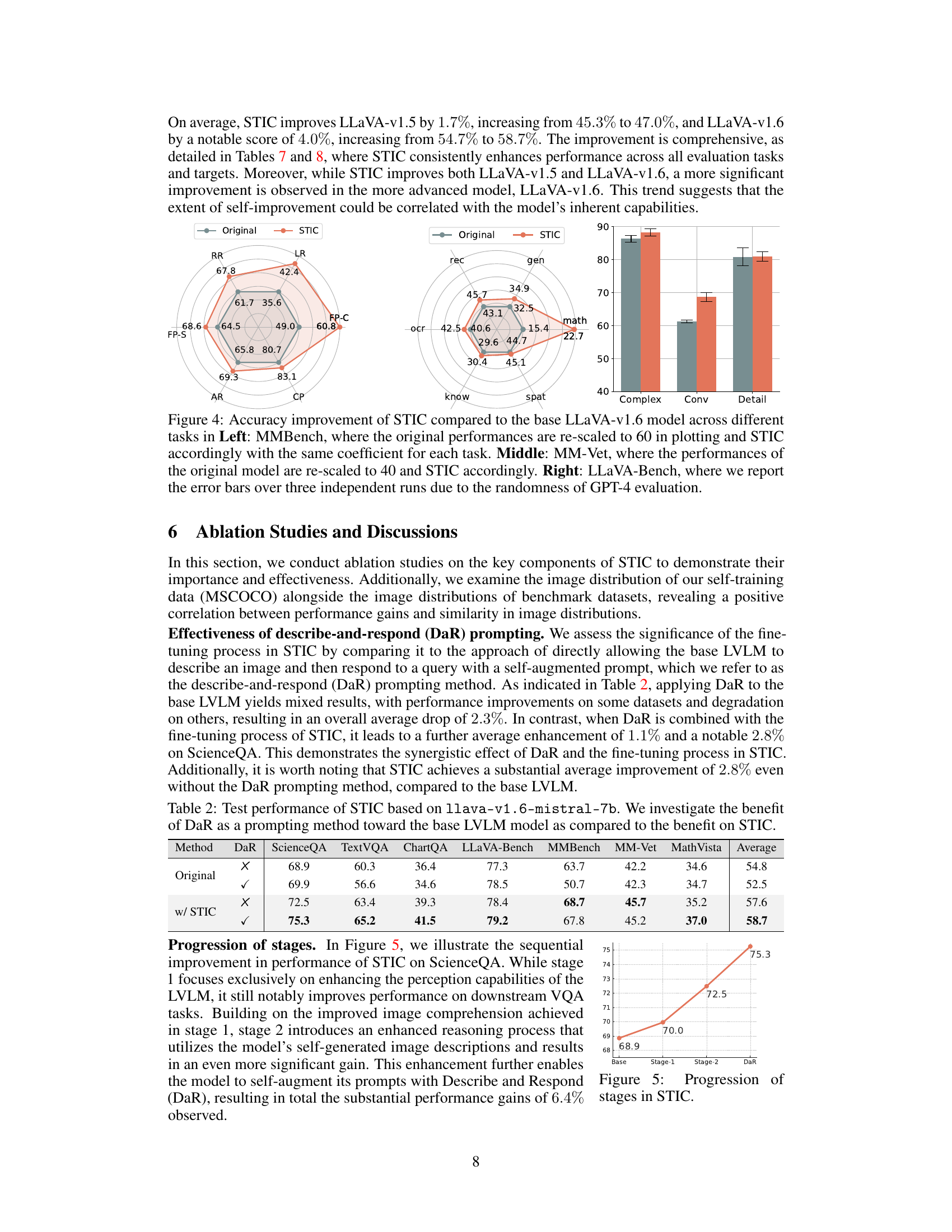
🔼 This figure presents a comparison of the performance improvements achieved by the Self-Training on Image Comprehension (STIC) method compared to the original LLaVA-v1.6 model across three different vision-language reasoning benchmarks: MMBench, MM-Vet, and LLaVA-Bench. The left panel (MMBench) and middle panel (MM-Vet) show radar charts illustrating performance gains for various sub-tasks within each benchmark. The right panel (LLaVA-Bench) presents a bar chart summarizing the average performance improvement across multiple tasks, with error bars reflecting the variability introduced by the use of GPT-4 for evaluation.
read the caption
Figure 4: Accuracy improvement of STIC compared to the base LLaVA-v1.6 model across different tasks in Left: MMBench, where the original performances are re-scaled to 60 in plotting and STIC accordingly with the same coefficient for each task. Middle: MM-Vet, where the performances of the original model are re-scaled to 40 and STIC accordingly. Right: LLaVA-Bench, where we report the error bars over three independent runs due to the randomness of GPT-4 evaluation.

🔼 This figure shows the performance improvement of STIC on ScienceQA across its different stages. The baseline performance is shown first, followed by the performance after Stage 1 (image comprehension self-training), Stage 2 (description-infused fine-tuning), and finally the combined effect with the describe-and-respond (DaR) prompting method. The graph clearly illustrates the incremental improvement achieved by each stage, demonstrating the synergistic effects of the different components of the STIC approach.
read the caption
Figure 5: Progression of stages in STIC.
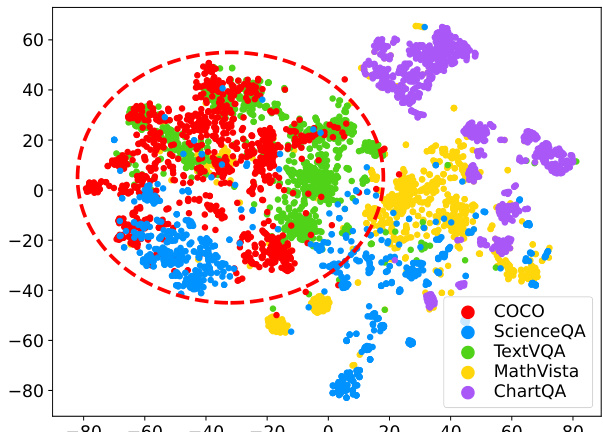
🔼 This figure visualizes the similarity of image distributions between MSCOCO (the dataset used for self-training in STIC) and four different benchmarks: ScienceQA, TextVQA, MathVista, and ChartQA. Each point represents an image, and the proximity of points indicates similarity in visual features. The figure aims to show the correlation between the image distribution overlap and the performance gains observed by STIC on each benchmark. A larger overlap suggests a stronger positive impact from STIC’s self-training.
read the caption
Figure 7: t-SNE visualization of images from MSCOCO and four benchmarks, each sampling 1k.
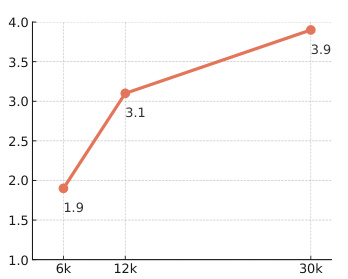
🔼 This figure shows the scaling law of the STIC method. The x-axis represents the amount of preference data used in Stage 1 of the STIC algorithm (6k, 12k, and 30k images from MSCOCO). The y-axis represents the accuracy improvement (%) achieved by STIC on the LLaVA-Bench benchmark. The graph shows that increasing the amount of preference data leads to a consistent and significant increase in performance improvement, demonstrating that STIC can effectively leverage large quantities of unlabeled data.
read the caption
Figure 6: Scaling law in STIC.

🔼 The left part of the figure shows a bar chart comparing the accuracy improvement achieved by the proposed STIC method against the original LLaVA-v1.6 model across seven different vision-language benchmarks. The right part presents a comparison of the model responses to a sample query, highlighting the improved image comprehension and reasoning capabilities of STIC compared to the original LLaVA-v1.6 model.
read the caption
Figure 1: Left: Accuracy improvement of our method, STIC, compared to the original LLaVA-v1.6 (Liu et al., 2024) on seven benchmarks. Right: Response examples from the original LLaVA-v1.6 and STIC (LLaVA-v1.6), which enhances image comprehension and subsequent reasoning capabilities.

🔼 This figure shows three examples of image descriptions generated by the model. The first is a preferred description, generated using a detailed, step-by-step prompt. The second and third are dispreferred descriptions, generated using either a poorly-worded prompt or a corrupted image. These examples illustrate how the model learns to distinguish between preferred and dispreferred descriptions through self-training.
read the caption
Figure 9: Example of generated preference data, where the dis-preferred response is generated from bad prompting.

🔼 This figure shows examples from the self-constructed preference dataset used in the STIC method. The preferred response is a detailed description of a child blowing out candles on a birthday cake. The dispreferred response describes the same image but with significantly less detail and clarity due to lower image resolution. The comparison highlights how the self-training method uses the differences between preferred and dispreferred responses to improve model performance.
read the caption
Figure 10: Example of generated preference data, where the dis-preferred response is generated from images with lower resolution.

🔼 This figure shows three examples of image descriptions generated by the model using different prompting strategies. The first example uses a detailed, step-by-step prompt to generate a high-quality description. The second and third examples use either a corrupted image or a misleading prompt to generate lower-quality descriptions. These descriptions are used to construct a preference dataset for image descriptions, which is then used to fine-tune the model.
read the caption
Figure 3: Examples of the self-constructed preference data in STIC.

🔼 The figure demonstrates the effectiveness of the proposed STIC method. The left panel shows a bar chart illustrating the accuracy improvements achieved by STIC across seven different vision-language benchmarks compared to the original LLaVA-v1.6 model. The right panel presents example outputs from both the original LLaVA-v1.6 and the STIC-enhanced LLaVA-v1.6, highlighting the improved image comprehension and reasoning capabilities of the latter.
read the caption
Figure 1: Left: Accuracy improvement of our method, STIC, compared to the original LLaVA-v1.6 (Liu et al., 2024) on seven benchmarks. Right: Response examples from the original LLaVA-v1.6 and STIC (LLaVA-v1.6), which enhances image comprehension and subsequent reasoning capabilities.

🔼 The figure on the left shows a bar chart comparing the accuracy improvement achieved by STIC against the original LLaVA-v1.6 model across seven different benchmarks. The figure on the right provides a qualitative comparison, showcasing how STIC enhances the model’s ability to comprehend images and reason effectively, leading to more accurate and contextually relevant responses compared to the original model.
read the caption
Figure 1: Left: Accuracy improvement of our method, STIC, compared to the original LLaVA-v1.6 (Liu et al., 2024) on seven benchmarks. Right: Response examples from the original LLaVA-v1.6 and STIC (LLaVA-v1.6), which enhances image comprehension and subsequent reasoning capabilities.
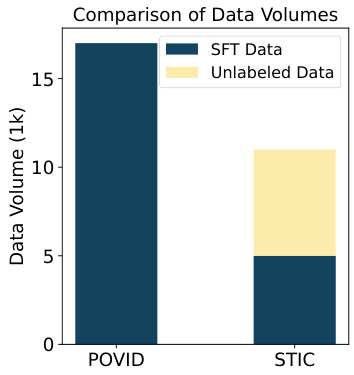
🔼 This figure is a bar chart comparing the amount of supervised fine-tuning (SFT) data and unlabeled data used in the POVID and STIC methods. It shows that POVID used significantly more SFT data and no unlabeled data, whereas STIC used a smaller amount of SFT data and a substantial amount of unlabeled data for self-training. This visualization highlights the data efficiency of the STIC approach.
read the caption
Figure 15: Data comparison.

🔼 The left panel of Figure 1 shows a bar chart comparing the accuracy improvements achieved by STIC against the original LLaVA-v1.6 model across seven different vision-language benchmarks. STIC demonstrates substantial performance gains across all benchmarks, with an average improvement of 4.0%. The right panel provides a qualitative comparison, showcasing example responses from both the original LLaVA-v1.6 and the STIC-enhanced version for a given query. The examples highlight STIC’s improved ability to comprehend image content and perform subsequent reasoning tasks.
read the caption
Figure 1: Left: Accuracy improvement of our method, STIC, compared to the original LLaVA-v1.6 (Liu et al., 2024) on seven benchmarks. Right: Response examples from the original LLaVA-v1.6 and STIC (LLaVA-v1.6), which enhances image comprehension and subsequent reasoning capabilities.
More on tables

🔼 This table presents the performance comparison between the original LLaVA models (versions 1.5 and 1.6, both with 7B parameters) and their corresponding versions fine-tuned using the STIC method across seven different vision-language benchmarks. The benchmarks cover various tasks and domains, including ScienceQA (scientific reasoning), TextVQA (text-based VQA), ChartQA (chart-based reasoning), LLaVA-Bench (general VQA), MMBench (multimodal benchmark), MM-Vet (visual reasoning in veterinary medicine), and MathVista (mathematical reasoning). For LLaVA-v1.5, results from a concurrent work (POVID) are also included for comparison. The table highlights the improvement in accuracy achieved by STIC on each benchmark.
read the caption
Table 1: Performance of STIC compared with the original LVLM model across vision-language reasoning tasks. For LLaVA-v1.5 (Vicuna 7B), we directly report the values in the paper of POVID, and '-' indicates an unreported value.

🔼 This table presents the results of an ablation study on the impact of negative samples within the STIC (Self-Training on Image Comprehension) framework. By comparing the performance of STIC using only positive samples (preferred responses) against the full STIC approach which utilizes both positive and negative samples, the table quantifies the contribution of negative samples to model improvement. The results highlight the importance of negative samples (dispreferred responses) in achieving the performance gains reported by STIC.
read the caption
Table 3: Test performance of STIC if we remove negative examples and use positive ones to perform SFT in Stage 1.

🔼 This table presents the performance comparison between the original LLaVA-v1.6 (7B) model and the model enhanced with the STIC method using two different datasets for training: COCO and VFLAN. The performance is measured across several vision-language reasoning tasks on the LLaVA-Bench, MM-Vet, and MMBench benchmarks. The table shows the accuracy scores for various sub-tasks within each benchmark, providing a comprehensive evaluation of the STIC method’s effectiveness in improving image comprehension and overall model performance.
read the caption
Table 4: Performance of STIC on different stage-1 training images compared with the original LVLM model LLaVA-v.16 (Mistral 7B) across vision-language reasoning benchmarks.

🔼 This table presents the performance comparison between the original LLaVA-v1.6 model (using Vicuna 13B) and the same model enhanced with the STIC method. It shows the accuracy scores on various vision-language reasoning tasks (LLaVA-Bench, MM-Vet, and MMBench). The improvement from STIC is also provided. Note that the same image data was used for both the 7B and 13B models.
read the caption
Table 5: Performance of STIC compared with the original LVLM model LLaVA-v1.6 (Vicuna 13B) across vision-language reasoning tasks. Image data used for 13B model remain the same as what we used for the 7B model.
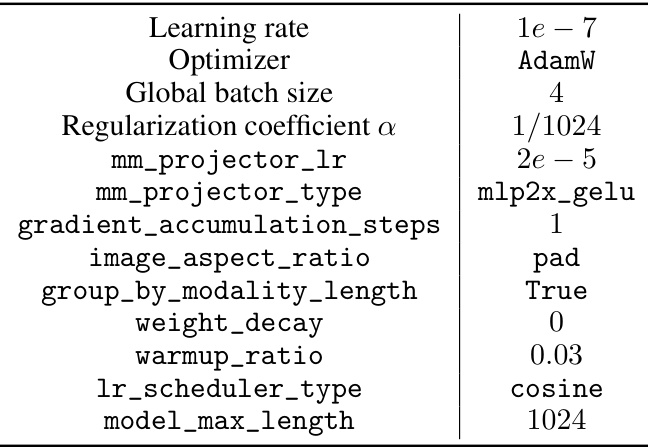
🔼 This table presents a comparison of the performance of the Self-Training on Image Comprehension (STIC) method against the original Large Vision Language Models (LVLMs) across seven different vision-language reasoning tasks. It shows accuracy improvements achieved by STIC on various benchmarks, including ScienceQA, TextVQA, ChartQA, LLaVA-Bench, MMBench, MM-Vet, and MathVista. The table also includes a comparison with a concurrent baseline method, POVID, using LLaVA-v1.5 (Vicuna 7B).
read the caption
Table 1: Performance of STIC compared with the original LVLM model across vision-language reasoning tasks. For LLaVA-v1.5 (Vicuna 7B), we directly report the values in the paper of POVID, and '-' indicates an unreported value.

🔼 This table presents a detailed comparison of the performance of the original Large Vision Language Model (LVLM) and the LVLM enhanced with Self-Training on Image Comprehension (STIC) across six different sub-tasks within the MMBench dev set. It shows the accuracy improvement achieved by STIC for each subtask, highlighting the overall effectiveness of the proposed method.
read the caption
Table 7: Detailed performance of STIC compared with the original VLM model on the MM-Bench dev set.
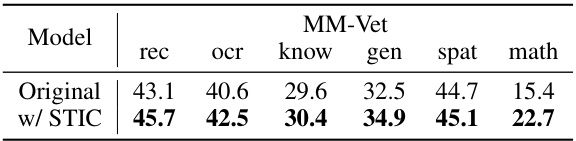
🔼 This table presents a detailed comparison of the performance of the original Vision Language Model (VLM) and the same VLM after applying the Self-Training on Image Comprehension (STIC) method. The comparison is done across six different sub-tasks within the MM-Vet benchmark: recognition, optical character recognition, knowledge, generation, spatial reasoning, and mathematical reasoning. For each subtask, the table shows the accuracy scores achieved by both the original VLM and the STIC-enhanced VLM, demonstrating the improvement gained by applying the STIC method.
read the caption
Table 8: Detailed performance of STIC compared with the original VLM model on the MM-Vet benchmark.

🔼 This table shows the impact of different prompt styles on the performance of the LLaVA-v1.6 (7B) model when using the describe-and-respond (DaR) method. It compares the performance using no DaR prompt, a normal prompt, a hallucination prompt, and two well-curated prompts (one from Llama-3 8B and one from GPT-4) across three benchmarks: LLaVA-Bench, MM-Vet, and MMBench. The numbers in parentheses show the performance difference compared to the baseline (no DaR prompt). The table highlights the significant positive effect of using well-crafted prompts and the detrimental effect of using hallucination prompts.
read the caption
Table 9: Test performance of llava-v1.6-mistral-7b using various prompts with DaR. We evaluate prompt quality using DaR as a prompting method. DaR=None represents the original LVLM model's performance. Normal prompt refers to the simple prompt we used for DaR in our paper. GPT-4's well-curated prompt refers to the prompt we used for preferred response generation, and we include Mistral 7B's curated prompt for additional comparison.
Full paper#