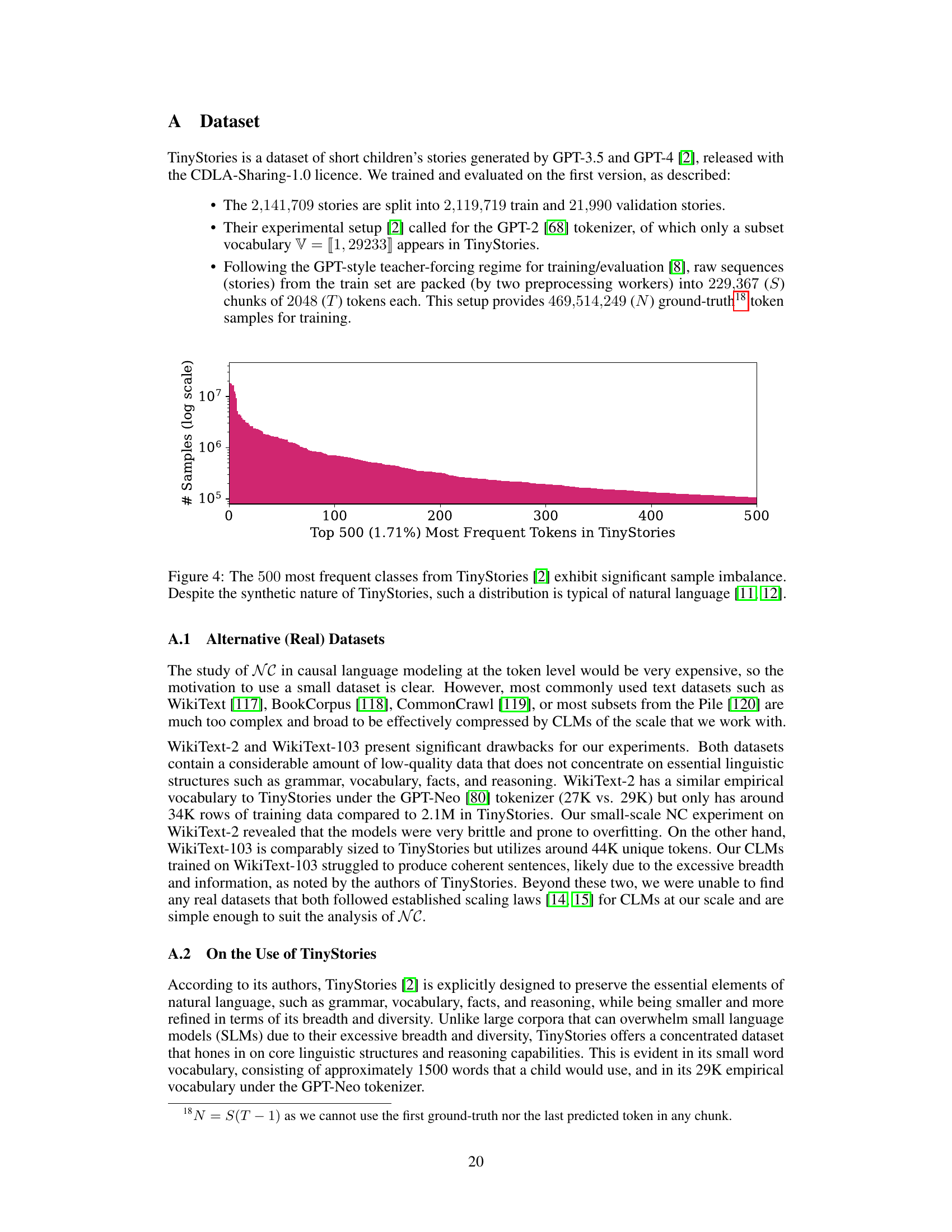
TL;DR#
Large Language Models (LLMs), while not traditionally considered classifiers, perform a classification task during pre-training by predicting the next token. This raises questions about the presence and impact of neural collapse (NC), a phenomenon observed in classification tasks where model representations converge to specific geometries. Existing research primarily focuses on NC in other domains, and often under idealized conditions rarely found in LLMs (balanced classes, few classes, noise-free data, sufficient training). This limits its applicability and understanding in the context of LLMs.
This paper empirically investigates NC in causal language models (CLMs) by systematically scaling model size and training duration. The researchers find that NC properties, particularly hyperspherical uniformity, emerge with increased scale and training, correlating with improved generalization performance. Crucially, these correlations persist even when controlling for model size and training parameters, suggesting a fundamental relationship between NC and LLM generalization. These findings challenge the traditional assumptions associated with NC and provide a novel perspective on LLM behavior and training optimization.
Key Takeaways#
Why does it matter?#
This paper is crucial because it extends the Neural Collapse (NC) framework to large language models (LLMs), a previously unexplored area. It reveals connections between NC properties, model scaling, and generalization ability, opening avenues for improving LLM design and understanding their inherent properties. This has significant implications for advancing LLM research and enhancing their performance and robustness.
Visual Insights#
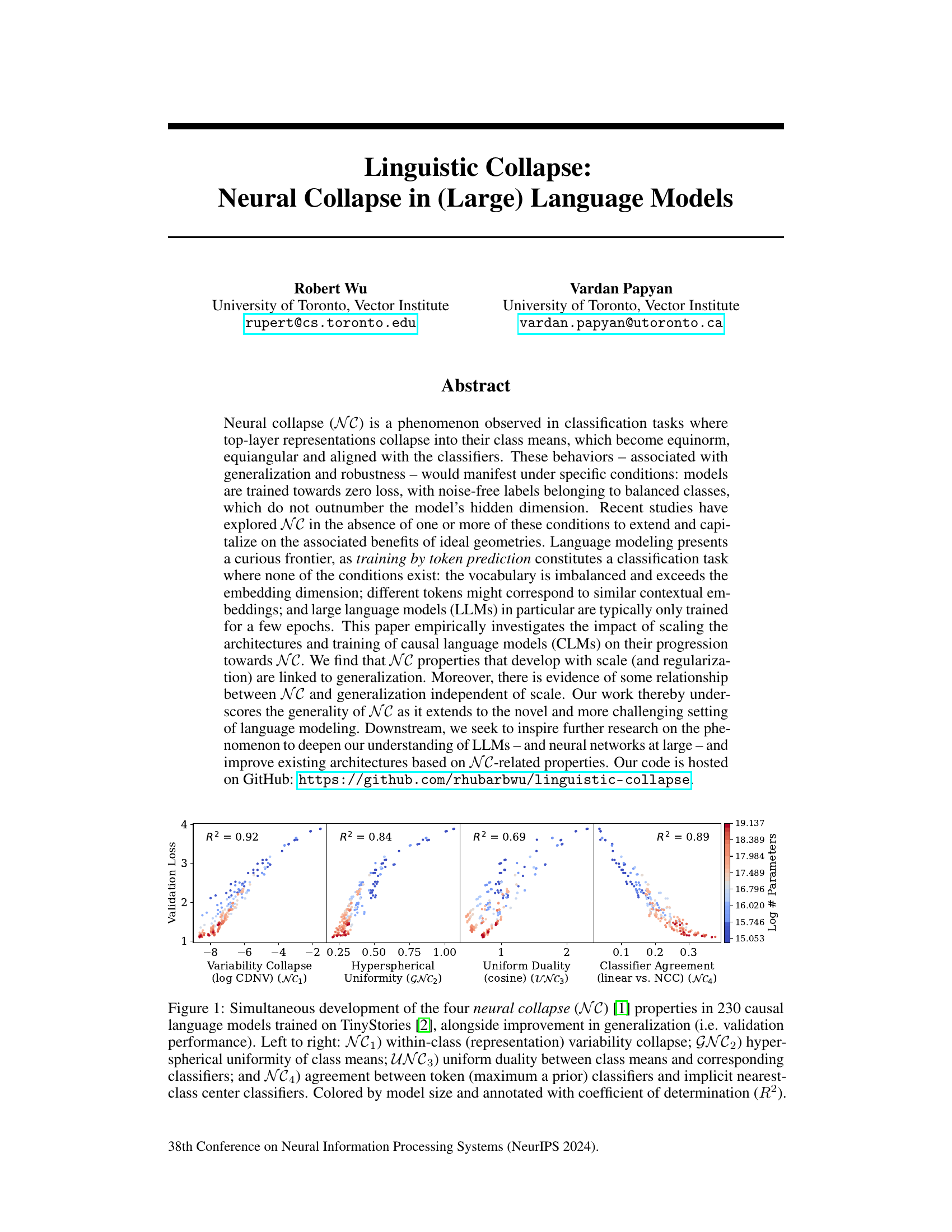
🔼 This figure displays the results of training 230 causal language models on the TinyStories dataset. It shows the simultaneous development of four key neural collapse (NC) properties as model size increases, alongside improvements in generalization performance (measured by validation loss). Each point represents a different model, colored according to its size. The x-axes show the degree to which each NC property is present, and the y-axis shows validation loss. Strong correlations between each NC property and improved generalization are observed.
read the caption
Figure 1: Simultaneous development of the four neural collapse (NC) [1] properties in 230 causal language models trained on TinyStories [2], alongside improvement in generalization (i.e. validation performance). Left to right: NC1) within-class (representation) variability collapse; GNC2) hyperspherical uniformity of class means; UNC3) uniform duality between class means and corresponding classifiers; and NC4) agreement between token (maximum a prior) classifiers and implicit nearest-class center classifiers. Colored by model size and annotated with coefficient of determination (R2).

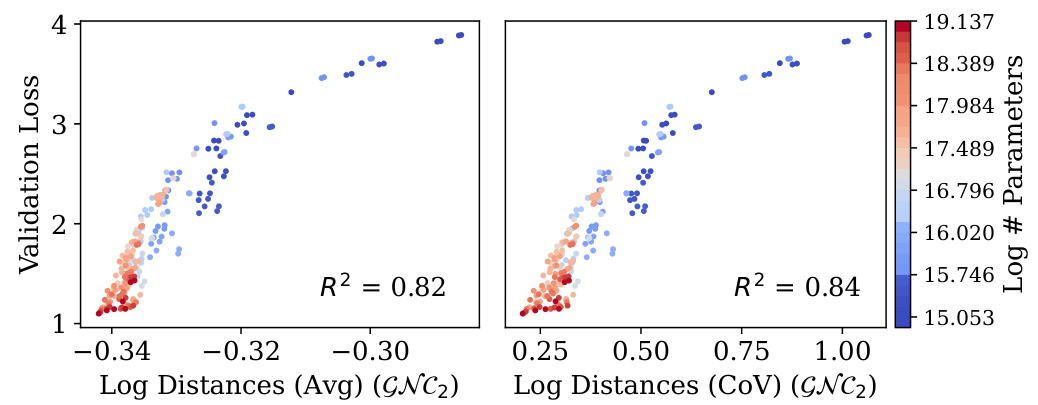
🔼 This table presents the results of a permutation test performed to assess the statistical significance of the correlation between neural collapse (NC) properties and generalization performance (validation loss). Twenty-one identical models were trained with different random data shuffles, and a permutation test was run with 104 trials to control for the effects of random data shuffling. The table shows the R-squared value of the correlation, the correlation coefficient, and the p-value for each NC property, indicating which correlations are statistically significant (p < 0.05).
read the caption
Table 1: Permutation test of NC measurements with respect to validation loss. Twenty-one (21) identical two-layer 768-wide models were trained with different data shuffling seeds and permuted with 104 trials. The p-values below 0.05 (bolded) show those properties to be statistically significant.
In-depth insights#
Linguistic Collapse#
The concept of “Linguistic Collapse” in the context of large language models (LLMs) presents a fascinating extension of the neural collapse (NC) phenomenon. It investigates whether the inherent classification task of token prediction in LLMs exhibits NC properties, despite violating typical NC conditions such as balanced classes and sufficient training. The study reveals a surprising emergence of NC-like behaviors with increasing model scale and training, particularly in hyperspherical uniformity of class embeddings. This suggests NC’s generality extends beyond image classification to the complexities of language modeling. Furthermore, a correlation is observed between the development of NC properties and improved generalization, even when controlling for model size and training, implying a fundamental link between the geometrical properties of the model’s representation and its performance. However, the study acknowledges that traditional NC metrics may not fully capture the subtleties of linguistic data, highlighting potential future research avenues in developing more appropriate metrics and theoretical frameworks to better understand and utilize NC in LLMs.
NC in LLMs#
The study explores Neural Collapse (NC), a phenomenon observed in classification tasks, within the context of Large Language Models (LLMs). It challenges the traditional understanding of NC, which typically requires balanced classes, few classes, and noise-free labels. LLMs violate these conditions; they deal with imbalanced, numerous classes (vocabulary) and inherently ambiguous contexts. The research investigates how scaling LLM architecture and training epochs affects the emergence of NC properties. It finds a correlation between the development of NC properties (specifically hyperspherical uniformity) with improved model generalization, even when controlling for scale, suggesting NC’s broader relevance in LLMs beyond simple classification tasks. This challenges the existing assumptions about NC, broadening our comprehension of LLMs and suggesting potential avenues for architecture improvement and better generalization by leveraging NC-related properties.
Scaling & Generalization#
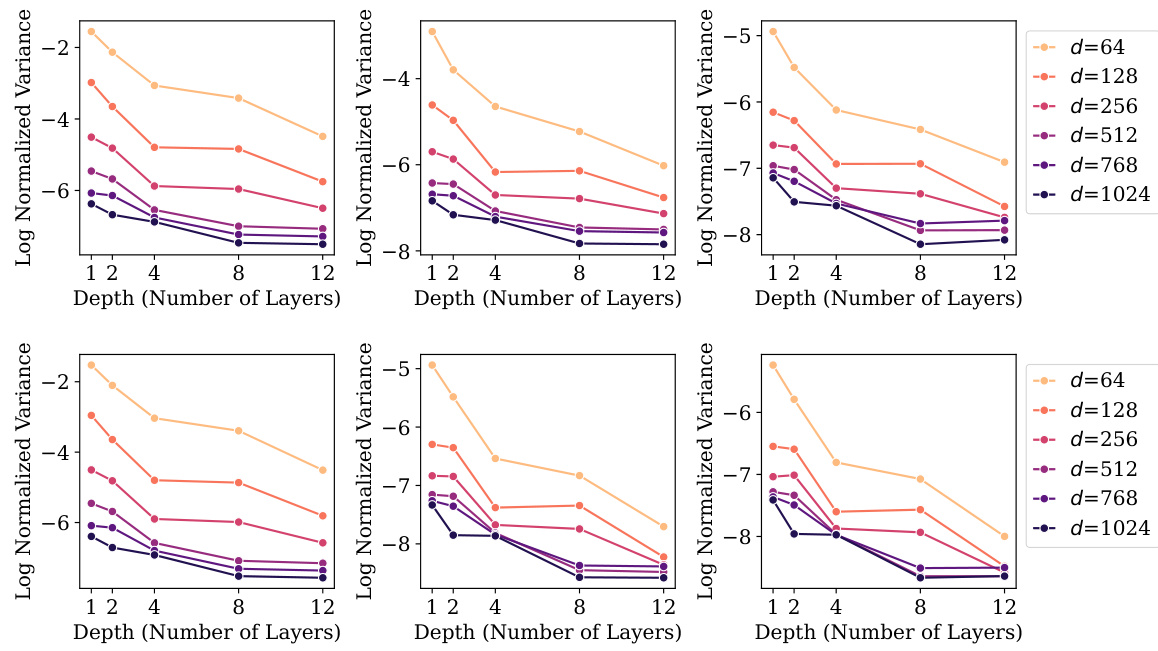
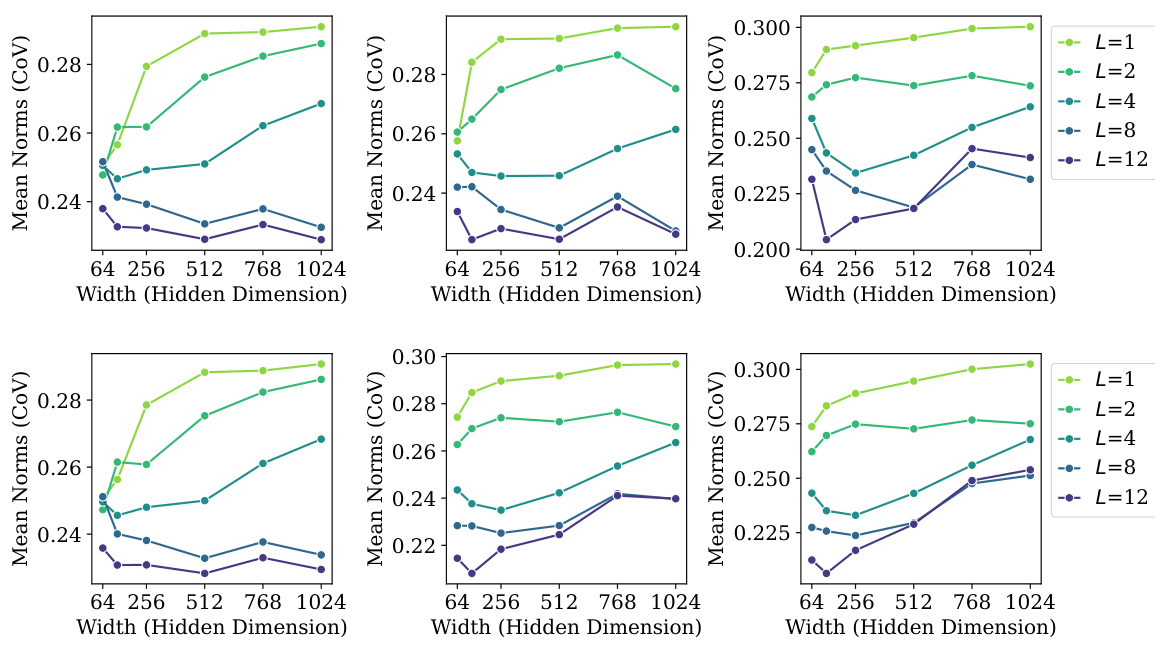
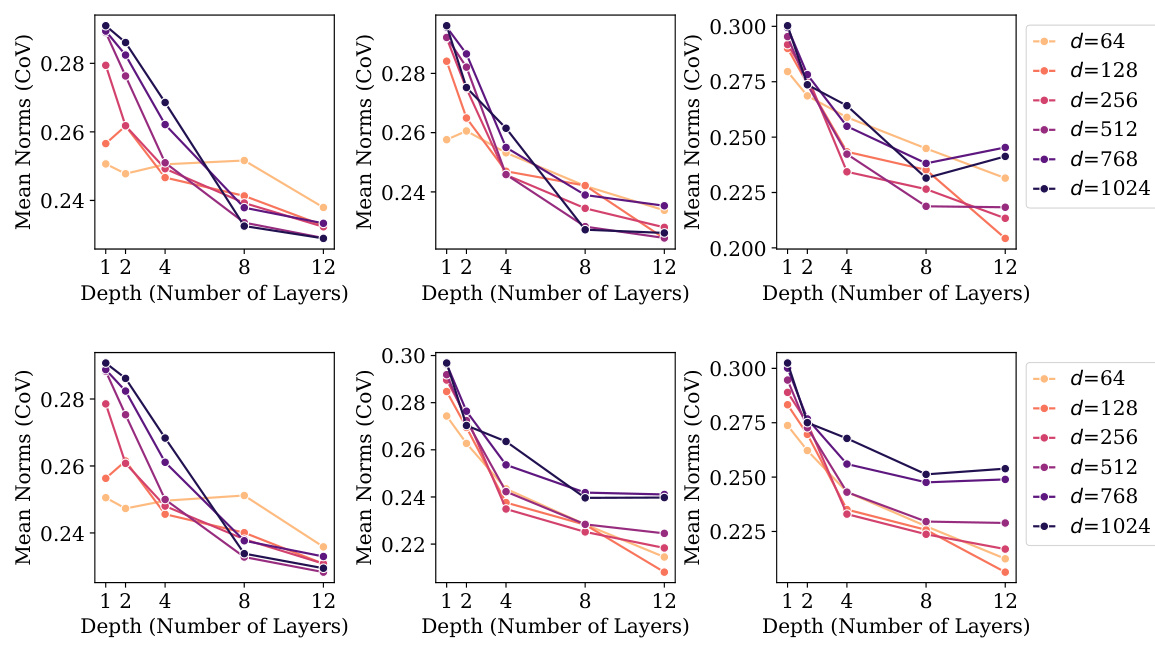
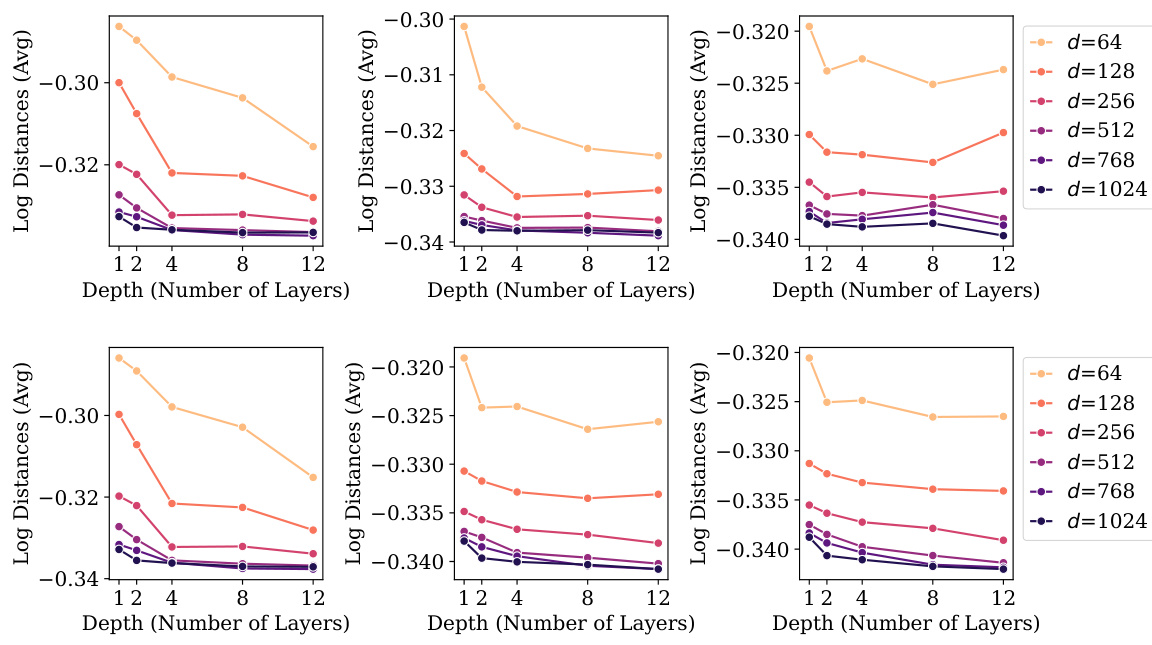
The research explores the intricate relationship between model scaling and generalization performance in large language models (LLMs). Increasing model size (width and depth) generally improves generalization, evidenced by a reduction in validation loss. However, this improvement is not solely attributed to scale; intrinsic properties related to Neural Collapse (NC), such as within-class variability collapse and hyperspherical uniformity, also demonstrate a strong correlation with enhanced generalization. Larger models exhibit a greater tendency toward NC properties, suggesting that these geometric features contribute significantly to improved generalization. Interestingly, even without significant scaling, certain NC characteristics still show a substantial correlation with improved generalization. This implies that fostering NC-related properties could be a key strategy in designing future LLMs, even independent of simply increasing model size. The study highlights the importance of understanding the interplay between these factors for designing highly effective LLMs.
NC Properties & Scale#
The interplay between neural collapse (NC) properties and model scale is a crucial theme. Larger models generally exhibit stronger NC characteristics, such as reduced within-class variability and increased hyperspherical uniformity of class means. This scaling effect suggests that NC is not merely a byproduct of training dynamics, but rather a phenomenon influenced by architectural choices and data characteristics. The observed correlation between enhanced NC properties and improved generalization performance in larger models supports the hypothesis that NC contributes to a model’s ability to generalize well. However, the relationship is complex. Not all NC properties scale equally; for instance, while some show clear improvements with scale, others may plateau or even exhibit a decline. This highlights the necessity of a more nuanced understanding of the individual NC properties and their respective relationships with model size and generalization capabilities. Further research is needed to fully elucidate these relationships and to determine whether specific NC properties are more critical than others in enhancing generalization. This investigation into the interaction of NC and model scale offers valuable insights into the fundamental mechanisms driving the success of deep learning models.
Future Directions#
Future research could explore extending neural collapse (NC) principles to more complex language modeling tasks, such as those involving multi-modal inputs or instruction-following. Investigating the relationship between different NC properties and downstream performance metrics beyond simple validation loss is crucial. This could involve analyzing NC’s impact on fairness and interpretability in various language models. A deeper theoretical understanding of NC in the context of imbalanced datasets and the impact of various training methodologies, including weight decay, on NC’s emergence would enhance the understanding of large language models. Finally, empirical studies comparing NC’s manifestations across diverse language models (LLMs) and architectures are needed to determine the generality of NC’s influence on model performance and its potential as an evaluation criterion.
More visual insights#
More on figures
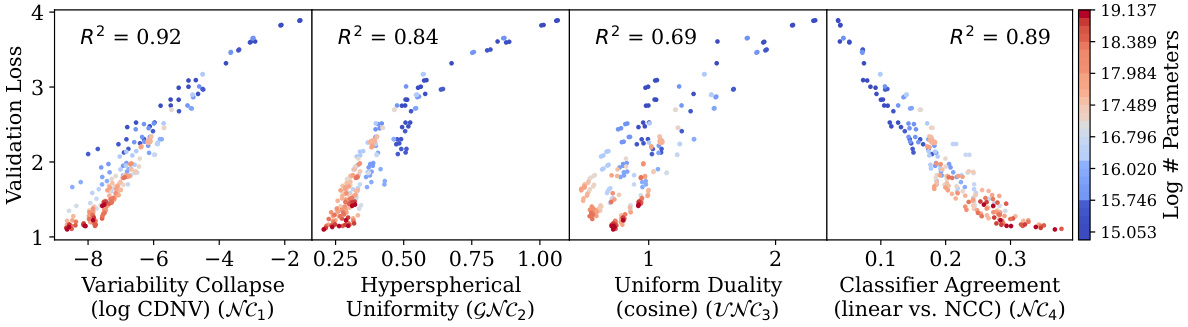
🔼 This figure shows the simultaneous development of four neural collapse (NC) properties in 230 causal language models trained on the TinyStories dataset. The four NC properties are: within-class variability collapse (NC1), hyperspherical uniformity of class means (GNC2), uniform duality between class means and classifiers (UNC3), and agreement between token classifiers and nearest-class center classifiers (NC4). The figure also shows that the development of these properties is correlated with improved generalization performance (measured by validation performance). The models are colored by size, and the coefficient of determination (R2) is annotated for each property.
read the caption
Figure 1: Simultaneous development of the four neural collapse (NC) [1] properties in 230 causal language models trained on TinyStories [2], alongside improvement in generalization (i.e. validation performance). Left to right: NC1) within-class (representation) variability collapse; GNC2) hyperspherical uniformity of class means; UNC3) uniform duality between class means and corresponding classifiers; and NC4) agreement between token (maximum a prior) classifiers and implicit nearest-class center classifiers. Colored by model size and annotated with coefficient of determination (R2).

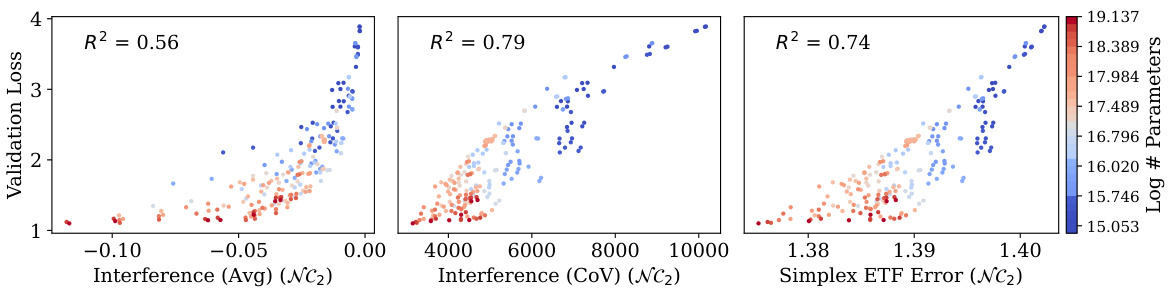
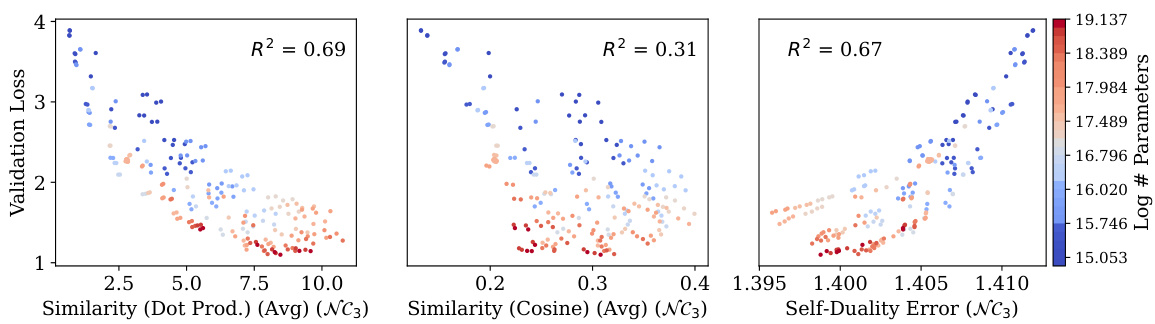
🔼 This figure shows the relationship between validation loss and two metrics related to Neural Collapse: self-duality (NC3) and uniform duality (UNC3). The left panel shows a weak correlation between validation loss and the average cosine similarity between class means and classifiers (NC3). The right panel, however, shows a strong correlation between validation loss and the coefficient of variation of cosine similarity between class means and classifiers (UNC3). This indicates that uniform duality (UNC3) is a better indicator of generalization in the context of language modeling compared to self-duality (NC3).
read the caption
Figure 3: Validation loss shows a negligible relationship with self-duality (NC3, left) and some correlation with uniform duality (UNC3, right). In other words, UNC3 develops with scale and correlates with generalization much better than NC3.
🔼 This figure shows the simultaneous development of four neural collapse (NC) properties in 230 causal language models trained on TinyStories dataset. The properties are: within-class variability collapse (NC1), hyperspherical uniformity of class means (GNC2), uniform duality between class means and classifiers (UNC3), and agreement between token classifiers and nearest-class center classifiers (NC4). The figure also shows how these properties correlate with improvements in generalization performance (validation performance). Each point represents a different model, colored by its size, with the coefficient of determination (R-squared) also shown.
read the caption
Figure 1: Simultaneous development of the four neural collapse (NC) [1] properties in 230 causal language models trained on TinyStories [2], alongside improvement in generalization (i.e. validation performance). Left to right: NC1) within-class (representation) variability collapse; GNC2) hyperspherical uniformity of class means; UNC3) uniform duality between class means and corresponding classifiers; and NC4) agreement between token (maximum a prior) classifiers and implicit nearest-class center classifiers. Colored by model size and annotated with coefficient of determination (R2).

🔼 This figure shows the simultaneous development of four neural collapse (NC) properties in 230 causal language models as model size and training increase. The four properties are: within-class variability collapse (NC1), hyperspherical uniformity of class means (GNC2), uniform duality between class means and classifiers (UNC3), and agreement between token classifiers and nearest-class center classifiers (NC4). The figure also demonstrates a correlation between these NC properties and improved generalization (validation performance). Model size is represented by color, and the coefficient of determination (R-squared) is shown for each property’s correlation with validation performance.
read the caption
Figure 1: Simultaneous development of the four neural collapse (NC) [1] properties in 230 causal language models trained on TinyStories [2], alongside improvement in generalization (i.e. validation performance). Left to right: NC1) within-class (representation) variability collapse; GNC2) hyperspherical uniformity of class means; UNC3) uniform duality between class means and corresponding classifiers; and NC4) agreement between token (maximum a prior) classifiers and implicit nearest-class center classifiers. Colored by model size and annotated with coefficient of determination (R2).

🔼 This figure visualizes the simultaneous emergence of four neural collapse properties (NC1, GNC2, UNC3, NC4) in 230 causal language models as model size increases, alongside an improvement in the model’s generalization performance. Each property is plotted against a measure of classifier agreement, showing a clear correlation between the development of these NC properties and improved generalization. The models were trained on the TinyStories dataset. The color of each point represents the model size, and the R-squared value indicates the strength of the correlation.
read the caption
Figure 1: Simultaneous development of the four neural collapse (NC) [1] properties in 230 causal language models trained on TinyStories [2], alongside improvement in generalization (i.e. validation performance). Left to right: NC1) within-class (representation) variability collapse; GNC2) hyperspherical uniformity of class means; UNC3) uniform duality between class means and corresponding classifiers; and NC4) agreement between token (maximum a prior) classifiers and implicit nearest-class center classifiers. Colored by model size and annotated with coefficient of determination (R2).
🔼 This figure shows the simultaneous development of four neural collapse properties (NC1, GNC2, UNC3, NC4) in 230 causal language models as model size increases. It also demonstrates the correlation between these properties and improved generalization performance (lower validation loss). Each property is visualized in a separate subplot, colored by the model’s size, and annotated with the coefficient of determination (R2) illustrating the strength of the correlation between the metric and validation performance.
read the caption
Figure 1: Simultaneous development of the four neural collapse (NC) [1] properties in 230 causal language models trained on TinyStories [2], alongside improvement in generalization (i.e. validation performance). Left to right: NC1) within-class (representation) variability collapse; GNC2) hyperspherical uniformity of class means; UNC3) uniform duality between class means and corresponding classifiers; and NC4) agreement between token (maximum a prior) classifiers and implicit nearest-class center classifiers. Colored by model size and annotated with coefficient of determination (R2).
🔼 This figure shows the simultaneous development of four neural collapse (NC) properties in 230 causal language models trained on the TinyStories dataset. The four properties are: within-class variability collapse (NC1), hyperspherical uniformity of class means (GNC2), uniform duality between class means and classifiers (UNC3), and agreement between token classifiers and implicit nearest-class center classifiers (NC4). The figure also demonstrates the correlation between these NC properties and improved generalization performance (validation performance) as measured by the R-squared value.
read the caption
Figure 1: Simultaneous development of the four neural collapse (NC) [1] properties in 230 causal language models trained on TinyStories [2], alongside improvement in generalization (i.e. validation performance). Left to right: NC1) within-class (representation) variability collapse; GNC2) hyperspherical uniformity of class means; UNC3) uniform duality between class means and corresponding classifiers; and NC4) agreement between token (maximum a prior) classifiers and implicit nearest-class center classifiers. Colored by model size and annotated with coefficient of determination (R2).
🔼 This figure visualizes the simultaneous emergence of four neural collapse properties (NC1-NC4) in 230 causal language models, trained using the TinyStories dataset. The properties are: within-class variability collapse, hyperspherical uniformity of class means, uniform duality between class means and classifiers, and agreement between token classifiers and implicit nearest-class center classifiers. The figure demonstrates the correlation between the development of these properties and the improvement of the model’s generalization performance, measured by validation performance. Model size is represented by color, and the coefficient of determination (R-squared) is also shown for each property’s correlation with validation performance.
read the caption
Figure 1: Simultaneous development of the four neural collapse (NC) [1] properties in 230 causal language models trained on TinyStories [2], alongside improvement in generalization (i.e. validation performance). Left to right: NC1) within-class (representation) variability collapse; GNC2) hyperspherical uniformity of class means; UNC3) uniform duality between class means and corresponding classifiers; and NC4) agreement between token (maximum a prior) classifiers and implicit nearest-class center classifiers. Colored by model size and annotated with coefficient of determination (R2).
🔼 This figure shows the simultaneous development of four neural collapse properties (NC1, GNC2, UNC3, NC4) in 230 causal language models trained on TinyStories, alongside an improvement in generalization (validation performance). Each panel displays the correlation between one of the four NC properties and the validation performance. The NC properties are: (NC1) within-class variability collapse, (GNC2) hyperspherical uniformity of class means, (UNC3) uniform duality, and (NC4) classifier agreement. Model size is represented by color.
read the caption
Figure 1: Simultaneous development of the four neural collapse (NC) [1] properties in 230 causal language models trained on TinyStories [2], alongside improvement in generalization (i.e. validation performance). Left to right: NC1) within-class (representation) variability collapse; GNC2) hyperspherical uniformity of class means; UNC3) uniform duality between class means and corresponding classifiers; and NC4) agreement between token (maximum a prior) classifiers and implicit nearest-class center classifiers. Colored by model size and annotated with coefficient of determination (R2).
🔼 This figure shows the simultaneous development of four neural collapse (NC) properties in 230 causal language models trained on TinyStories dataset. It demonstrates the relationship between these properties (within-class variability collapse, hyperspherical uniformity of class means, uniform duality, and classifier agreement) and the improvement in generalization performance (validation performance). Each point represents a model, colored by its size and annotated with the coefficient of determination (R-squared) showing the correlation with validation performance.
read the caption
Figure 1: Simultaneous development of the four neural collapse (NC) [1] properties in 230 causal language models trained on TinyStories [2], alongside improvement in generalization (i.e. validation performance). Left to right: NC1) within-class (representation) variability collapse; GNC2) hyperspherical uniformity of class means; UNC3) uniform duality between class means and corresponding classifiers; and NC4) agreement between token (maximum a prior) classifiers and implicit nearest-class center classifiers. Colored by model size and annotated with coefficient of determination (R2).

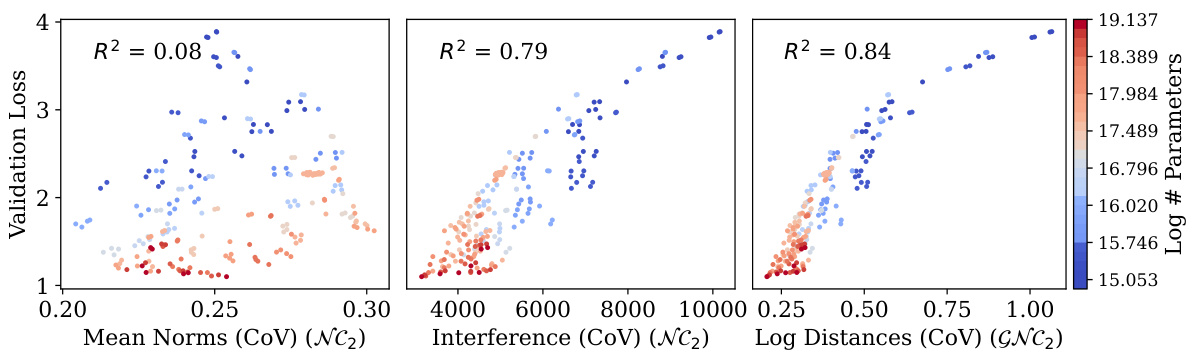
🔼 This figure displays the correlation between validation loss and three different neural collapse properties: equinormness, equiangularity, and hyperspherical uniformity. The x-axis represents each property and the y-axis represents validation loss. The left plot shows a weak negative correlation between validation loss and equinormness. The center plot indicates a weak correlation between validation loss and equiangularity. The right plot shows a strong negative correlation between validation loss and hyperspherical uniformity. The overall finding is that hyperspherical uniformity (GNC2) exhibits the strongest correlation with generalization performance, which is much better than those of equinormness and equiangularity.
read the caption
Figure 2: Validation loss shows negligible correlation with equinormness (NC2, left), some relationship with equiangularity (NC2, centre), and a stronger one with hyperspherical uniformity (GNC2, right). So, GNC2 develops with scale and correlates well with generalization, better than NC2.

🔼 This figure shows the correlation between four neural collapse properties and the generalization performance of 230 causal language models trained on TinyStories dataset. The four properties are: within-class variability collapse (NC1), hyperspherical uniformity of class means (GNC2), uniform duality between class means and classifiers (UNC3), and agreement between token classifiers and implicit nearest-class center classifiers (NC4). The figure demonstrates the simultaneous development of these four NC properties with the improvement in generalization performance as measured by the validation performance. Each point in the plots represents a specific language model. The color of the points indicates the model size, and the R-squared value indicates the strength of the correlation between NC properties and generalization performance.
read the caption
Figure 1: Simultaneous development of the four neural collapse (NC) [1] properties in 230 causal language models trained on TinyStories [2], alongside improvement in generalization (i.e. validation performance). Left to right: NC1) within-class (representation) variability collapse; GNC2) hyperspherical uniformity of class means; UNC3) uniform duality between class means and corresponding classifiers; and NC4) agreement between token (maximum a prior) classifiers and implicit nearest-class center classifiers. Colored by model size and annotated with coefficient of determination (R2).

🔼 This figure displays the results of training 230 causal language models on the TinyStories dataset. It shows the simultaneous development of four neural collapse (NC) properties (within-class variability collapse, hyperspherical uniformity of class means, uniform duality, and classifier agreement) alongside improved generalization performance (measured by validation performance). Each point represents a different model, colored by its size. The R-squared values quantify the correlation between each NC property and generalization performance.
read the caption
Figure 1: Simultaneous development of the four neural collapse (NC) [1] properties in 230 causal language models trained on TinyStories [2], alongside improvement in generalization (i.e. validation performance). Left to right: NC1) within-class (representation) variability collapse; GNC2) hyperspherical uniformity of class means; UNC3) uniform duality between class means and corresponding classifiers; and NC4) agreement between token (maximum a prior) classifiers and implicit nearest-class center classifiers. Colored by model size and annotated with coefficient of determination (R2).
🔼 This figure shows the simultaneous development of four neural collapse (NC) properties in 230 causal language models, along with improvements in generalization performance. The four NC properties are: within-class variability collapse, hyperspherical uniformity of class means, uniform duality between class means and classifiers, and agreement between token classifiers and nearest-class center classifiers. The figure is colored by model size and shows the coefficient of determination (R-squared) for each relationship.
read the caption
Figure 1: Simultaneous development of the four neural collapse (NC) [1] properties in 230 causal language models trained on TinyStories [2], alongside improvement in generalization (i.e. validation performance). Left to right: NC1) within-class (representation) variability collapse; GNC2) hyperspherical uniformity of class means; UNC3) uniform duality between class means and corresponding classifiers; and NC4) agreement between token (maximum a prior) classifiers and implicit nearest-class center classifiers. Colored by model size and annotated with coefficient of determination (R2).

🔼 This figure shows the simultaneous development of four neural collapse properties (NC1, GNC2, UNC3, NC4) in 230 causal language models trained on the TinyStories dataset, alongside an improvement in generalization performance. Each property is displayed in a separate scatter plot. The plots show a strong correlation between these NC properties and improved generalization performance, suggesting a link between NC and generalization in the context of language modeling. The models are colored by their size, and each plot includes an R-squared value indicating the strength of the correlation.
read the caption
Figure 1: Simultaneous development of the four neural collapse (NC) [1] properties in 230 causal language models trained on TinyStories [2], alongside improvement in generalization (i.e. validation performance). Left to right: NC1) within-class (representation) variability collapse; GNC2) hyperspherical uniformity of class means; UNC3) uniform duality between class means and corresponding classifiers; and NC4) agreement between token (maximum a prior) classifiers and implicit nearest-class center classifiers. Colored by model size and annotated with coefficient of determination (R2).
🔼 This figure shows the simultaneous development of four neural collapse (NC) properties in 230 causal language models trained on the TinyStories dataset, alongside the improvement in generalization performance. The four NC properties are: within-class variability collapse (NC1), hyperspherical uniformity of class means (GNC2), uniform duality between class means and corresponding classifiers (UNC3), and agreement between token classifiers and implicit nearest-class center classifiers (NC4). The models are colored according to their size, and the coefficient of determination (R2) is annotated. This visualization demonstrates the correlation between NC properties and generalization in language models.
read the caption
Figure 1: Simultaneous development of the four neural collapse (NC) [1] properties in 230 causal language models trained on TinyStories [2], alongside improvement in generalization (i.e. validation performance). Left to right: NC1) within-class (representation) variability collapse; GNC2) hyperspherical uniformity of class means; UNC3) uniform duality between class means and corresponding classifiers; and NC4) agreement between token (maximum a prior) classifiers and implicit nearest-class center classifiers. Colored by model size and annotated with coefficient of determination (R2).
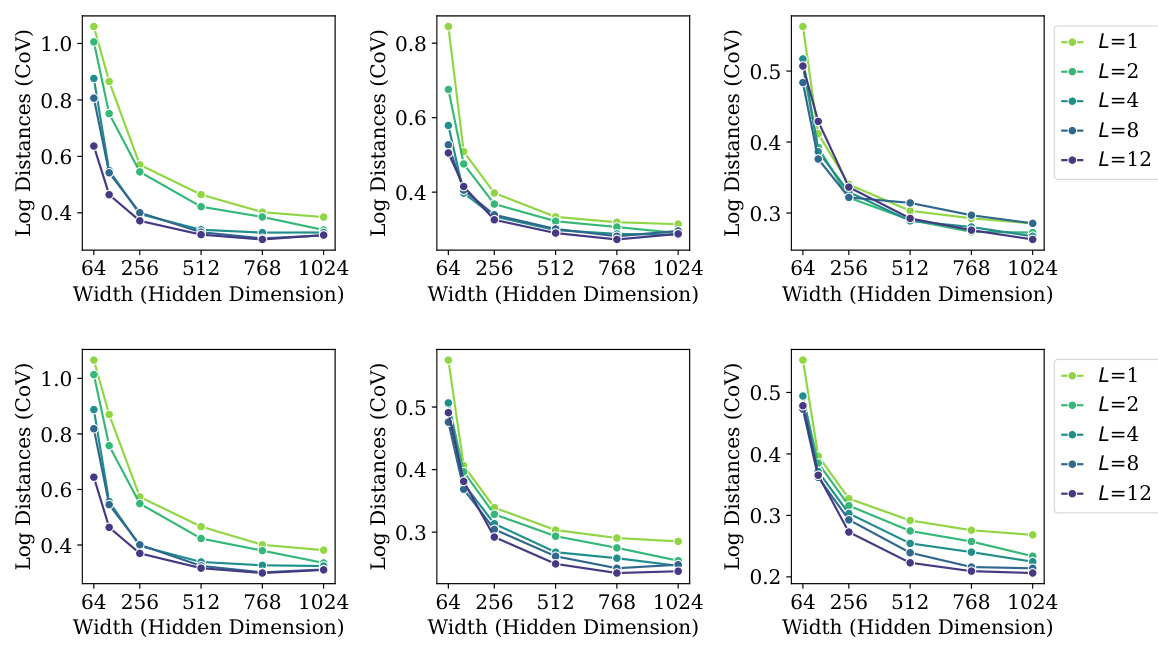
🔼 This figure displays the correlation between four neural collapse properties and generalization performance across 230 causal language models. The four properties (NC1-NC4) are visualized as scatter plots, where the color of each point corresponds to the model size. The plots show that as model size increases, the NC properties become more pronounced, which correlates with improved generalization. This visualization provides strong empirical support for the generality of neural collapse and its implications for the performance of LLMs.
read the caption
Figure 1: Simultaneous development of the four neural collapse (NC) [1] properties in 230 causal language models trained on TinyStories [2], alongside improvement in generalization (i.e. validation performance). Left to right: NC1) within-class (representation) variability collapse; GNC2) hyperspherical uniformity of class means; UNC3) uniform duality between class means and corresponding classifiers; and NC4) agreement between token (maximum a prior) classifiers and implicit nearest-class center classifiers. Colored by model size and annotated with coefficient of determination (R2).

🔼 This figure shows the simultaneous development of four neural collapse (NC) properties in 230 causal language models (CLMs) trained on the TinyStories dataset, alongside their generalization performance. The four NC properties are: 1. Within-class variability collapse (NC1): The variability of the representations within each class decreases. 2. Hyperspherical uniformity of class means (GNC2): The class means become uniformly distributed on a hypersphere. 3. Uniform duality (UNC3): The angle between the class means and their corresponding classifiers becomes uniform. 4. Agreement between token classifiers (NC4): The agreement between maximum a posteriori (MAP) token classifiers and implicit nearest class center classifiers increases. The figure demonstrates that as model size increases and training progresses, the four NC properties emerge, which are correlated with improved generalization (as measured by validation performance).
read the caption
Figure 1: Simultaneous development of the four neural collapse (NC) [1] properties in 230 causal language models trained on TinyStories [2], alongside improvement in generalization (i.e. validation performance). Left to right: NC1) within-class (representation) variability collapse; GNC2) hyperspherical uniformity of class means; UNC3) uniform duality between class means and corresponding classifiers; and NC4) agreement between token (maximum a prior) classifiers and implicit nearest-class center classifiers. Colored by model size and annotated with coefficient of determination (R2).

🔼 This figure displays the simultaneous development of four neural collapse (NC) properties in 230 causal language models (CLMs) trained on the TinyStories dataset. The four properties are: within-class variability collapse (NC1), hyperspherical uniformity of class means (GNC2), uniform duality between class means and classifiers (UNC3), and agreement between token classifiers and implicit nearest-class center classifiers (NC4). The figure shows how these four NC properties emerge and strengthen as the model size increases alongside an improvement in the model’s generalization performance (as measured by validation performance). The models are color-coded by size and the coefficient of determination (R-squared) is shown for each property.
read the caption
Figure 1: Simultaneous development of the four neural collapse (NC) [1] properties in 230 causal language models trained on TinyStories [2], alongside improvement in generalization (i.e. validation performance). Left to right: NC1) within-class (representation) variability collapse; GNC2) hyperspherical uniformity of class means; UNC3) uniform duality between class means and corresponding classifiers; and NC4) agreement between token (maximum a prior) classifiers and implicit nearest-class center classifiers. Colored by model size and annotated with coefficient of determination (R2).
🔼 This figure displays the simultaneous development of four neural collapse (NC) properties in 230 causal language models trained on the TinyStories dataset. The properties shown are within-class variability collapse (NC1), hyperspherical uniformity of class means (GNC2), uniform duality between class means and classifiers (UNC3), and agreement between token classifiers and nearest-class-center classifiers (NC4). The figure demonstrates a correlation between the development of these NC properties and improved generalization performance (as measured by validation performance), indicated by the R-squared values. Model size is represented by color.
read the caption
Figure 1: Simultaneous development of the four neural collapse (NC) [1] properties in 230 causal language models trained on TinyStories [2], alongside improvement in generalization (i.e. validation performance). Left to right: NC1) within-class (representation) variability collapse; GNC2) hyperspherical uniformity of class means; UNC3) uniform duality between class means and corresponding classifiers; and NC4) agreement between token (maximum a prior) classifiers and implicit nearest-class center classifiers. Colored by model size and annotated with coefficient of determination (R2).
🔼 This figure displays the simultaneous development of four neural collapse (NC) properties in 230 causal language models (CLMs) trained on the TinyStories dataset. The properties are: within-class variability collapse (NC1), hyperspherical uniformity of class means (GNC2), uniform duality between class means and classifiers (UNC3), and agreement between token classifiers and nearest-class center classifiers (NC4). The figure shows how these NC properties develop together with improvements in the CLMs’ generalization performance (measured by validation performance). Each point represents a CLM, colored by model size, with R-squared values indicating the correlation between each NC property and generalization.
read the caption
Figure 1: Simultaneous development of the four neural collapse (NC) [1] properties in 230 causal language models trained on TinyStories [2], alongside improvement in generalization (i.e. validation performance). Left to right: NC1) within-class (representation) variability collapse; GNC2) hyperspherical uniformity of class means; UNC3) uniform duality between class means and corresponding classifiers; and NC4) agreement between token (maximum a prior) classifiers and implicit nearest-class center classifiers. Colored by model size and annotated with coefficient of determination (R2).
🔼 This figure shows the simultaneous development of four neural collapse (NC) properties in 230 causal language models trained on the TinyStories dataset. The four properties are: within-class variability collapse (NC1), hyperspherical uniformity of class means (GNC2), uniform duality between class means and classifiers (UNC3), and agreement between token classifiers and nearest-class center classifiers (NC4). The figure also demonstrates the correlation between these NC properties and the improvement in generalization performance (validation performance) as measured by R-squared. Model size is represented by color.
read the caption
Figure 1: Simultaneous development of the four neural collapse (NC) [1] properties in 230 causal language models trained on TinyStories [2], alongside improvement in generalization (i.e. validation performance). Left to right: NC1) within-class (representation) variability collapse; GNC2) hyperspherical uniformity of class means; UNC3) uniform duality between class means and corresponding classifiers; and NC4) agreement between token (maximum a prior) classifiers and implicit nearest-class center classifiers. Colored by model size and annotated with coefficient of determination (R2).
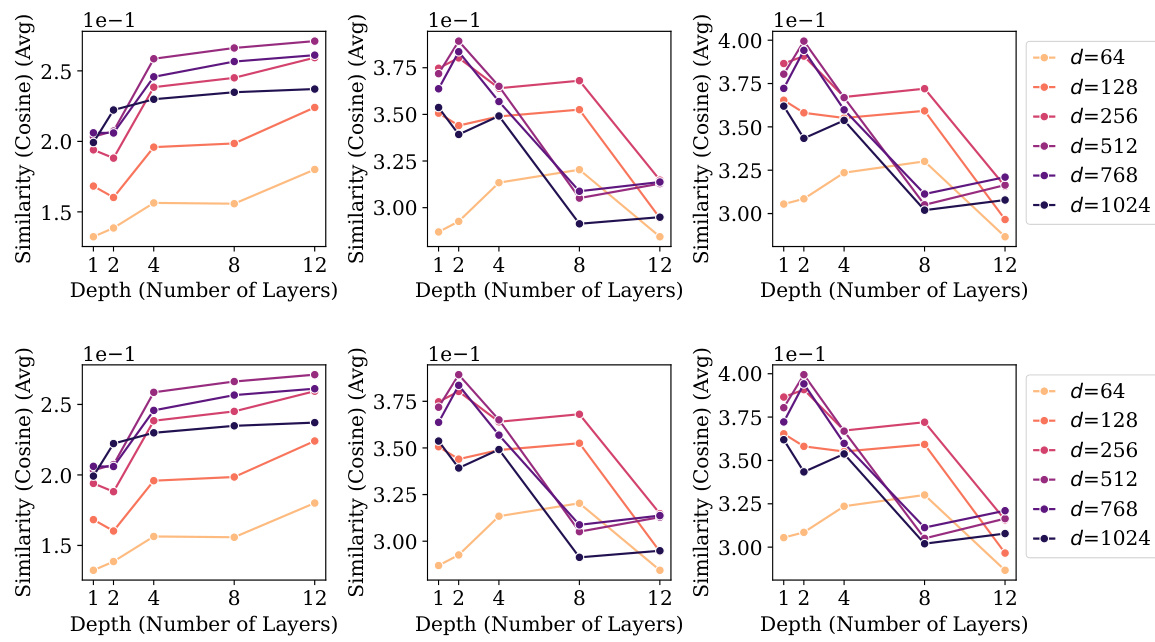
🔼 This figure visualizes the correlation between four neural collapse properties (within-class variability collapse, hyperspherical uniformity, uniform duality, and classifier agreement) and model generalization performance in 230 causal language models. Each point represents a model, colored by its size, and the x-axis represents the level of classifier agreement. The R-squared values indicate the strength of the correlations between these properties and generalization.
read the caption
Figure 1: Simultaneous development of the four neural collapse (NC) [1] properties in 230 causal language models trained on TinyStories [2], alongside improvement in generalization (i.e. validation performance). Left to right: NC1) within-class (representation) variability collapse; GNC2) hyperspherical uniformity of class means; UNC3) uniform duality between class means and corresponding classifiers; and NC4) agreement between token (maximum a prior) classifiers and implicit nearest-class center classifiers. Colored by model size and annotated with coefficient of determination (R2).

🔼 This figure displays the simultaneous development of four neural collapse (NC) properties in 230 causal language models trained on the TinyStories dataset. It shows how these properties (within-class variability collapse, hyperspherical uniformity, uniform duality, and classifier agreement) develop with increasing model size, alongside improvements in generalization performance, as measured by validation performance. Each property is shown separately and the models are color-coded by their size.
read the caption
Figure 1: Simultaneous development of the four neural collapse (NC) [1] properties in 230 causal language models trained on TinyStories [2], alongside improvement in generalization (i.e. validation performance). Left to right: NC1) within-class (representation) variability collapse; GNC2) hyperspherical uniformity of class means; UNC3) uniform duality between class means and corresponding classifiers; and NC4) agreement between token (maximum a prior) classifiers and implicit nearest-class center classifiers. Colored by model size and annotated with coefficient of determination (R2).

🔼 This figure shows the simultaneous development of four neural collapse properties (NC1, GNC2, UNC3, NC4) in 230 causal language models, trained on TinyStories dataset, and their relationship with improved generalization (validation performance). Each property is visualized in a separate plot, showing how the different properties evolve together with model size and training. The plots are colored according to model size and annotated with the coefficient of determination (R-squared), indicating the strength of the relationship between each NC property and validation performance. The visualization suggests that increased model size and training correlate with the emergence of NC properties and improved generalization.
read the caption
Figure 1: Simultaneous development of the four neural collapse (NC) [1] properties in 230 causal language models trained on TinyStories [2], alongside improvement in generalization (i.e. validation performance). Left to right: NC1) within-class (representation) variability collapse; GNC2) hyperspherical uniformity of class means; UNC3) uniform duality between class means and corresponding classifiers; and NC4) agreement between token (maximum a prior) classifiers and implicit nearest-class center classifiers. Colored by model size and annotated with coefficient of determination (R2).
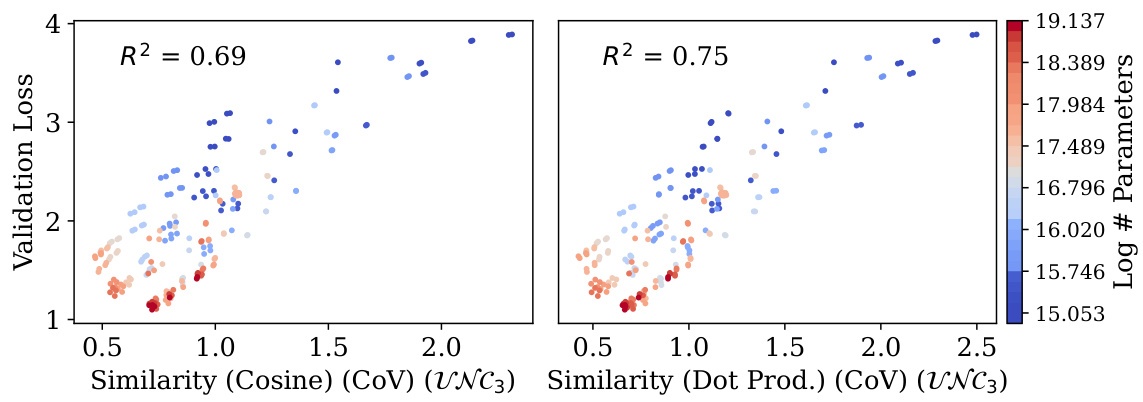
🔼 This figure displays the simultaneous emergence of four neural collapse (NC) properties (within-class variability collapse, hyperspherical uniformity of class means, uniform duality between class means and classifiers, and agreement between token classifiers and implicit nearest-class center classifiers) in 230 causal language models as model size increases. It also demonstrates the correlation between these NC properties and improved generalization performance (as measured by validation performance). The models are trained on the TinyStories dataset. Each point represents a model, colored by its size, and annotated with the R-squared value indicating the strength of correlation between NC properties and generalization.
read the caption
Figure 1: Simultaneous development of the four neural collapse (NC) [1] properties in 230 causal language models trained on TinyStories [2], alongside improvement in generalization (i.e., validation performance). Left to right: NC1) within-class (representation) variability collapse; GNC2) hyperspherical uniformity of class means; UNC3) uniform duality between class means and corresponding classifiers; and NC4) agreement between token (maximum a prior) classifiers and implicit nearest-class center classifiers. Colored by model size and annotated with coefficient of determination (R2).
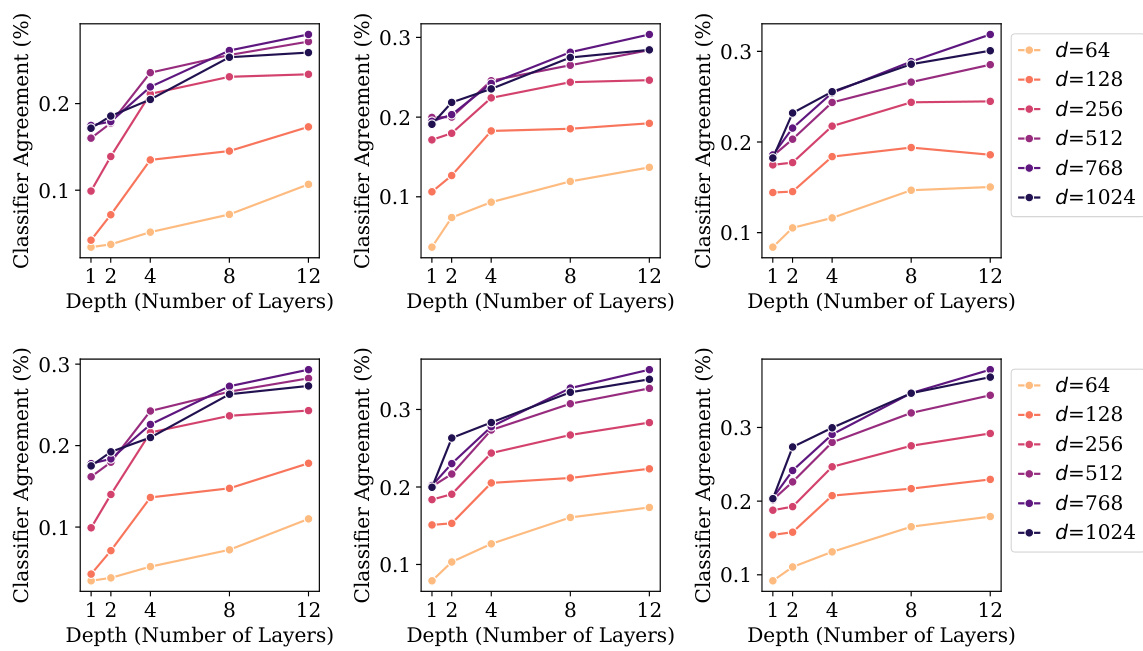
🔼 This figure shows the simultaneous development of four neural collapse properties (NC1-NC4) in 230 causal language models as the model size increases. NC1 represents the collapse of within-class variability, GNC2 shows hyperspherical uniformity of class means, UNC3 illustrates uniform duality between class means and classifiers, and NC4 demonstrates agreement between the token classifiers and nearest class center classifiers. The figure also highlights a correlation between these NC properties and improvements in generalization performance (validation performance). The models are color-coded by size, and R-squared values are provided to quantify the strength of the observed correlations.
read the caption
Figure 1: Simultaneous development of the four neural collapse (NC) [1] properties in 230 causal language models trained on TinyStories [2], alongside improvement in generalization (i.e., validation performance). Left to right: NC1) within-class (representation) variability collapse; GNC2) hyperspherical uniformity of class means; UNC3) uniform duality between class means and corresponding classifiers; and NC4) agreement between token (maximum a prior) classifiers and implicit nearest-class center classifiers. Colored by model size and annotated with coefficient of determination (R2).

🔼 This figure shows the simultaneous development of four neural collapse (NC) properties in 230 causal language models trained on the TinyStories dataset, alongside the improvement in generalization performance. Each panel represents one of the NC properties: within-class variability collapse (NC1), hyperspherical uniformity of class means (GNC2), uniform duality between class means and classifiers (UNC3), and agreement between token classifiers and implicit nearest-class center classifiers (NC4). The models are colored by size, and the R-squared values indicate the strength of the correlation between the NC properties and generalization performance.
read the caption
Figure 1: Simultaneous development of the four neural collapse (NC) [1] properties in 230 causal language models trained on TinyStories [2], alongside improvement in generalization (i.e. validation performance). Left to right: NC1) within-class (representation) variability collapse; GNC2) hyperspherical uniformity of class means; UNC3) uniform duality between class means and corresponding classifiers; and NC4) agreement between token (maximum a prior) classifiers and implicit nearest-class center classifiers. Colored by model size and annotated with coefficient of determination (R2).
🔼 This figure shows the simultaneous development of four neural collapse (NC) properties in 230 causal language models trained on the TinyStories dataset. The four NC properties are: within-class variability collapse (NC1), hyperspherical uniformity of class means (GNC2), uniform duality between class means and classifiers (UNC3), and agreement between token classifiers and implicit nearest-class center classifiers (NC4). The figure demonstrates how the development of these NC properties correlates with improved generalization performance (as measured by validation performance), indicated by the R-squared values. Model size is represented by color.
read the caption
Figure 1: Simultaneous development of the four neural collapse (NC) [1] properties in 230 causal language models trained on TinyStories [2], alongside improvement in generalization (i.e. validation performance). Left to right: NC1) within-class (representation) variability collapse; GNC2) hyperspherical uniformity of class means; UNC3) uniform duality between class means and corresponding classifiers; and NC4) agreement between token (maximum a prior) classifiers and implicit nearest-class center classifiers. Colored by model size and annotated with coefficient of determination (R2).
More on tables
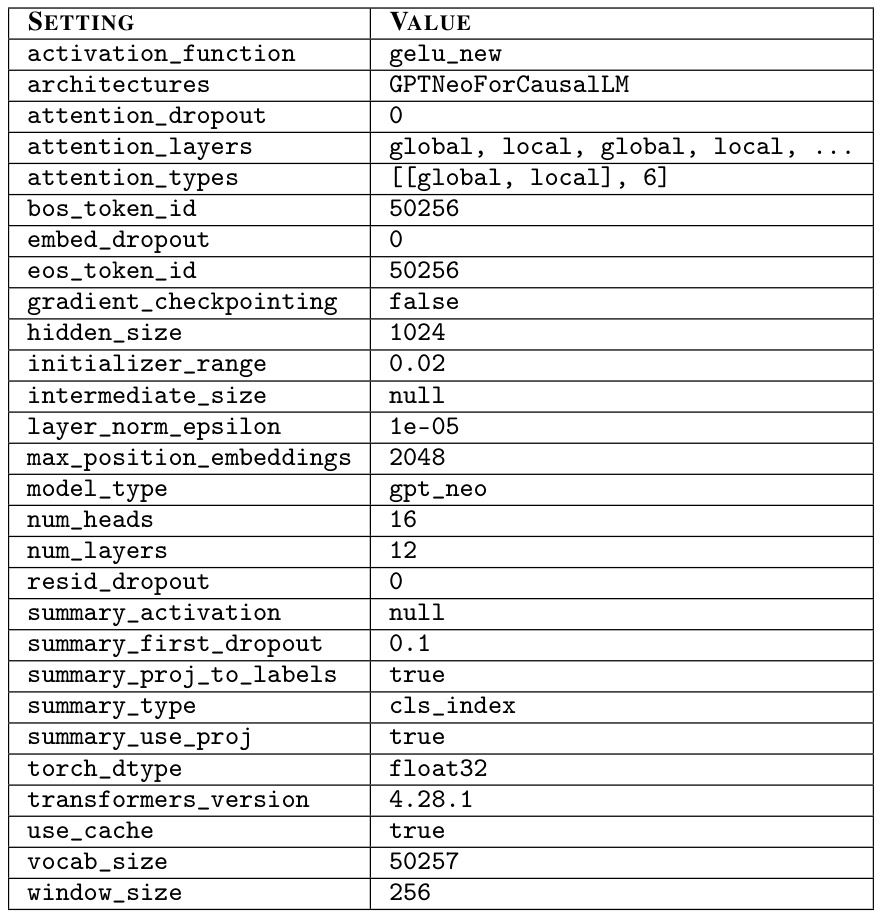
🔼 This table shows the hyperparameters used to train the causal language models in the experiments. The base configuration is for a 12-layer model with a hidden size of 1024. Variations in depth (number of layers) and width (hidden size) are indicated in the caption.
read the caption
Table 2: Sample architectural configuration for a 12-layer 1024-dimensional causal language model (CLM) based on [2] and GPT-Neo [80]. Shallower models have configurations with attention_layers and attention_types truncated. Narrower models adjust hidden_size to their width (d). All other configuration values are the same across models.
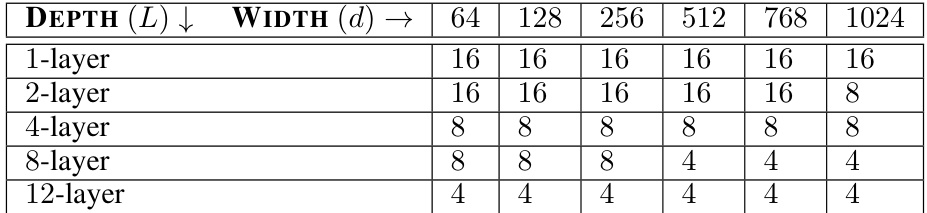
🔼 This table shows the batch sizes used for training the causal language models on a single NVIDIA A100 GPU with 40GB memory. The batch size varied depending on the model’s depth (number of layers) and width (embedding dimension). The table is organized to show how batch size changed across different model configurations.
read the caption
Table 3: Batch sizes used to train models on a single NVIDIA A100 (40GB) GPU. Width (d) and depth (L) correspond to hidden_size and length of attention_layers, respectively, in Table 2.
🔼 This table presents the results of a statistical test investigating the correlation between Neural Collapse (NC) properties and generalization performance (measured by validation loss). Twenty-one identical models were trained with different random initializations (data shuffling seeds), and a permutation test was conducted to determine the statistical significance of any observed correlations. The table shows the R-squared values (measuring the strength of the correlation), and p-values (indicating statistical significance). Bold p-values below 0.05 indicate statistically significant correlations between the specific NC property and generalization performance.
read the caption
Table 1: Permutation test of NC measurements with respect to validation loss. Twenty-one (21) identical two-layer 768-wide models were trained with different data shuffling seeds and permuted with 104 trials. The p-values below 0.05 (bolded) show those properties to be statistically significant.

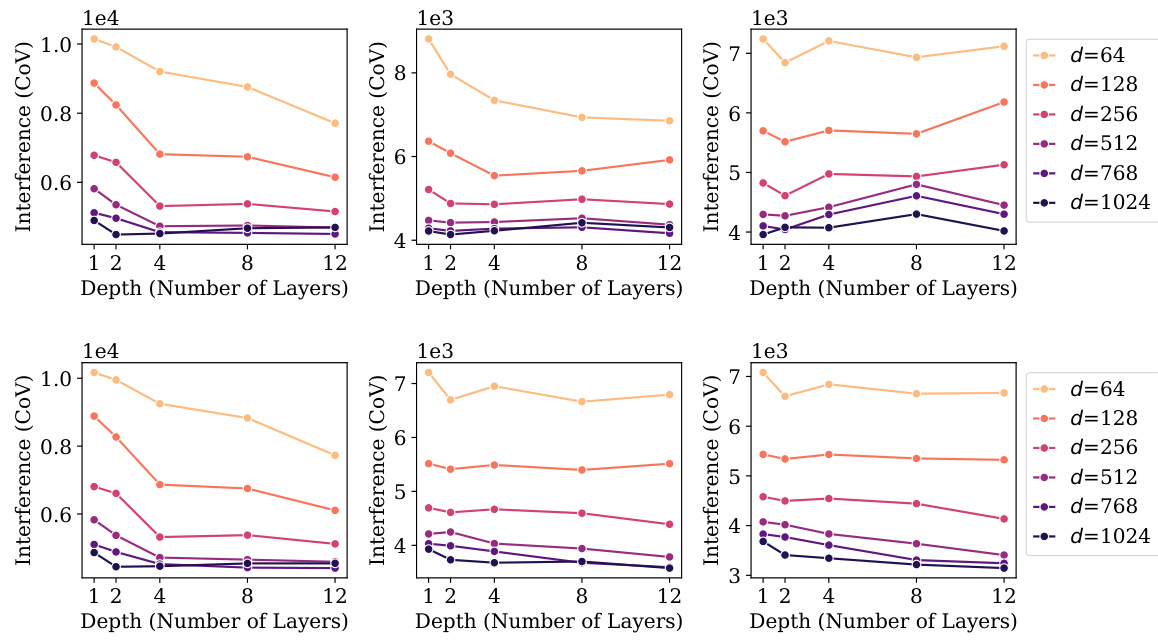
🔼 This table shows the variability (CDNV) and interference of several English first names. It demonstrates that most names have lower variability and interference compared to the average token, which could be due to their distinctness and limited contextual overlap with other words. The exception is the names ‘Anna’ and ‘Tim’, which exhibit variability and interference closer to the average.
read the caption
Table 5: Under TinyStories-12x1024_10L, the variability and interference of some English first names were far below those of the average token. This might be because names are distinct from one another and are not typically used in the same contexts as other words (aside from articles). The only names to have CDNV close to that of the average token are “Anna” and “Tim”. Note that the positive interference of the last row (average token) is not a typo.
Full paper#