TL;DR#
Deploying large language models (LLMs) efficiently across different platforms is challenging due to varying resource constraints and application-specific requirements. Existing solutions often focus on a single dimension of compression or require costly, platform-specific fine-tuning, limiting scalability and efficiency.
AmoebaLLM tackles these issues by introducing a novel framework for instantly creating LLM subnets of any shape. It uses a knowledge-preserving subnet selection strategy to identify optimal subnets, a shape-aware mixture of LoRAs (SMOL) to manage gradient conflicts during fine-tuning, and an in-place distillation scheme with loss-magnitude balancing. The results demonstrate AmoebaLLM’s ability to achieve state-of-the-art accuracy-efficiency trade-offs for various LLMs across different devices and deployment flows.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces a novel framework, AmoebaLLM, that allows for the creation of adaptable large language models (LLMs). This addresses a critical challenge in deploying LLMs across diverse platforms with varying resource constraints. The ability to quickly derive optimally sized subnets from a single, fine-tuned model will significantly advance LLM deployment and accessibility, impacting various real-world applications. This work also paves the way for new research avenues focusing on efficient LLM adaptation and compression techniques.
Visual Insights#
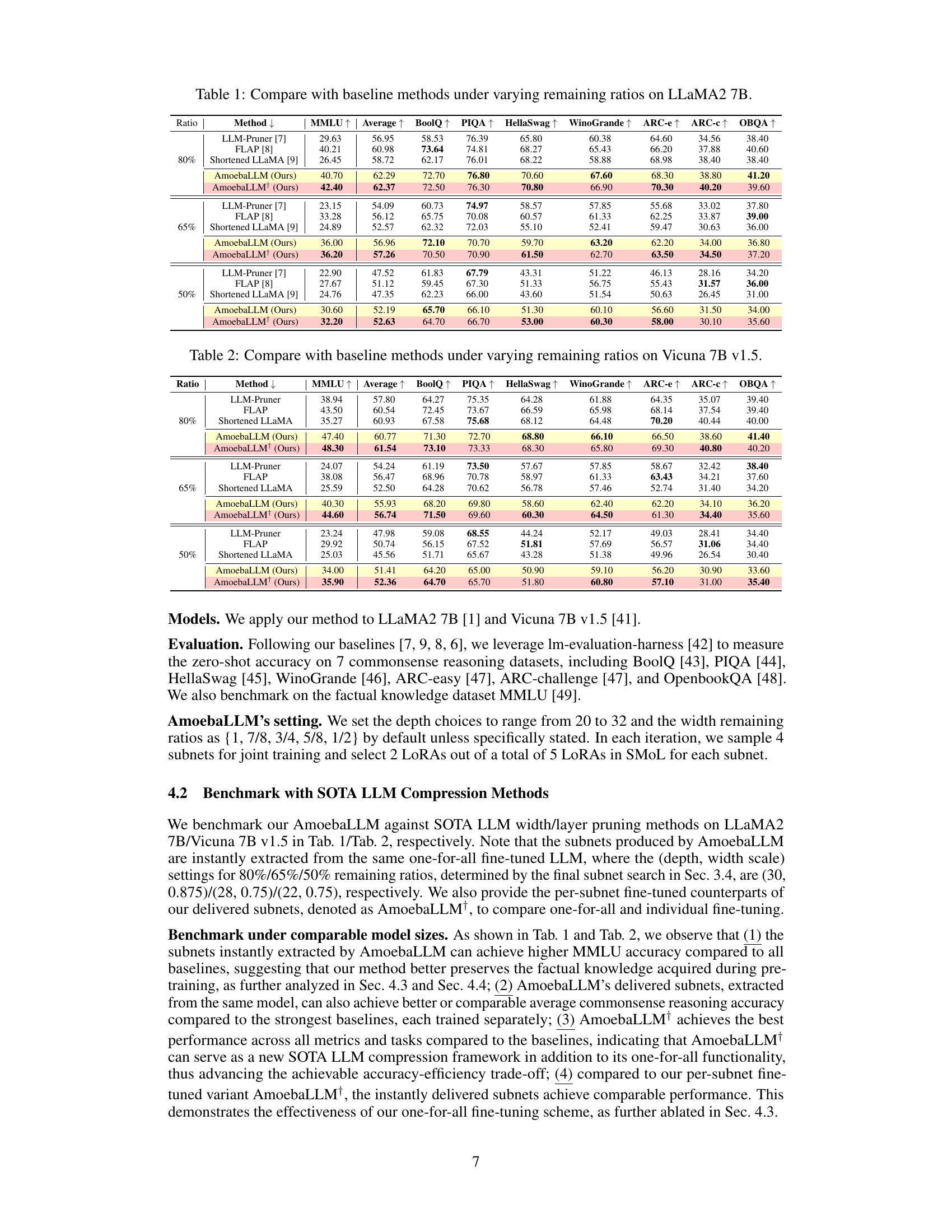
🔼 This figure shows the results of a profiling study on the efficiency of different LLM shapes (depth and width) across various devices (NVIDIA A5000 and NVIDIA Jetson Orin NX) and deployment flows (TensorRT-LLM, MLC-LLM, and vanilla PyTorch). The depth is defined as the number of self-attention blocks, while the width represents the hidden dimensions. The study reveals significant latency variations across different hardware and software combinations, highlighting the need for adaptable LLM structures to optimize efficiency across diverse real-world deployment scenarios.
read the caption
Figure 1: The latency of LLaMA2 7B with scaled depth/width on various devices/deployment flows.
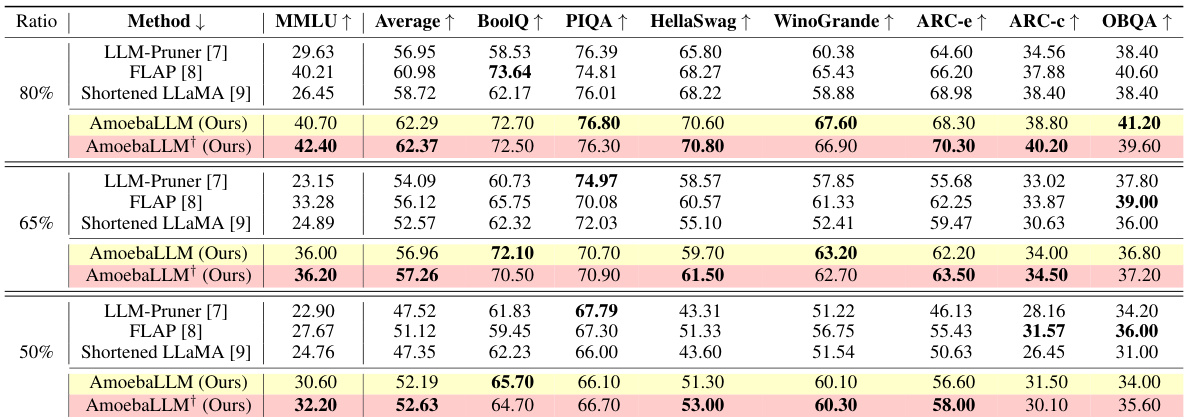
🔼 This table compares the performance of AmoebaLLM against several baseline methods (LLM-Pruner, FLAP, Shortened LLaMA) on the LLaMA2 7B model. The comparison is done across multiple evaluation metrics (MMLU, Average, BoolQ, PIQA, HellaSwag, WinoGrande, ARC-e, ARC-c, OBQA) and varying remaining ratios (80%, 65%, 50%) representing different levels of model compression. AmoebaLLM shows improvement on most metrics when compared to baselines at all compression ratios. The table also includes AmoebaLLM+ which represents individually fine-tuned versions of the subnets for comparison.
read the caption
Table 1: Compare with baseline methods under varying remaining ratios on LLaMA2 7B.
In-depth insights#
AmoebaLLM Overview#
AmoebaLLM is presented as a novel framework for generating adaptable Large Language Models (LLMs). Its core innovation lies in the ability to instantly create LLM subnets of arbitrary shapes, optimizing accuracy and efficiency across diverse platforms. This is achieved through a one-time fine-tuning process, eliminating the need for individual model adaptations for each target deployment environment. The framework integrates three key components: a knowledge-preserving subnet selection strategy ensuring crucial information is retained during compression, a shape-aware mixture of LoRAs to mitigate gradient conflicts during training, and an in-place distillation scheme with loss-magnitude balancing for improved accuracy. AmoebaLLM’s key strength is its adaptability, delivering state-of-the-art accuracy-efficiency trade-offs without the usual time-consuming and computationally expensive fine-tuning process required by other LLM compression methods. This adaptability makes it highly suitable for deployment across various platforms and applications with diverse resource constraints.
Subnet Selection#
Effective subnet selection is crucial for achieving accuracy-efficiency trade-offs in large language models. Knowledge preservation is paramount; methods should prioritize retaining informative layers and neurons, avoiding the loss of crucial knowledge encoded during pre-training. Dynamic programming offers a principled approach for depth reduction, systematically evaluating layer combinations to optimize performance. Importance-driven width shrinking complements this, identifying and retaining the most essential neurons, further enhancing efficiency without significant accuracy loss. The selection strategy should be adaptable, allowing for the creation of diverse subnet shapes tailored to various resource constraints and platform specifications. A well-designed selection process is key to the success of any efficient LLM deployment strategy.
SMOL Adapters#
The concept of “SMOL Adapters” presented in the paper is a novel approach to address the challenges of fine-tuning large language models (LLMs) for diverse applications and hardware platforms. The core idea revolves around using a shape-aware mixture of Low-Rank Adaptation (LoRA) modules as trainable adapters. This is a significant improvement over traditional methods that rely on either single LoRA modules or separate modules for each subnet configuration. The shape-awareness enables the selective activation and combination of multiple sparse LoRA sets using a gating function, effectively mitigating gradient conflicts during the one-for-all fine-tuning process. This adaptability to varying subnet shapes allows for immediate adaptation to diverse resource constraints without the need for individual fine-tuning for each platform or task. The integration of SMOL adapters with the knowledge-preserving subnet selection strategy and the loss-magnitude balancing scheme is crucial to AmoebaLLM’s overall success, demonstrating a significant advancement in efficient and flexible LLM deployment strategies.
Fine-tuning Objective#
The fine-tuning objective in AmoebaLLM is crucial for achieving its goal of creating adaptable LLMs. It enhances in-place distillation, a technique where smaller subnets learn from a larger, already trained subnet, by introducing loss-magnitude balancing. This addresses the issue of unbalanced losses among different sized subnets during training, which could lead to some subnets performing significantly better than others. The approach of normalizing loss magnitudes helps to prevent bias towards larger subnets and ensures more balanced learning and performance across the entire range of LLM sizes that AmoebaLLM aims to produce. This balanced fine-tuning is essential to AmoebaLLM’s success, because it enables the creation of high-quality, instantly deployable subnets, irrespective of their size or structure, ready to achieve state-of-the-art accuracy-efficiency tradeoffs.
Future Work#
The AmoebaLLM paper’s ‘Future Work’ section suggests several promising avenues. Addressing the limitations of parameter-efficient fine-tuning is crucial, acknowledging that while mitigating gradient conflicts on smaller datasets, it limits the accuracy-efficiency trade-off achievable with larger datasets. Exploring more extensive fine-tuning data and enhanced gradient conflict mitigation techniques are key to pushing the boundaries of this trade-off. Investigating more sophisticated subnet search strategies, such as evolutionary algorithms, beyond the hierarchical search presented in the paper, is another important direction. Finally, the authors highlight the need for further analysis of the knowledge preservation and the efficacy of the approaches used, particularly regarding the effects of different calibration datasets and the selection of target metrics. These combined improvements would potentially lead to more aggressive accuracy and efficiency gains.
More visual insights#
More on figures

🔼 This figure illustrates the two-stage process of AmoebaLLM. Stage 1 focuses on the knowledge-preserving subnet selection using dynamic programming for depth shrinking and an importance-driven method for width shrinking. The output is a subnet selection strategy. Stage 2 performs one-for-all fine-tuning using a shape-aware mixture of LoRAs (SMOL) and in-place distillation with loss-magnitude balancing. The result is a set of subnets with diverse shapes.
read the caption
Figure 2: An overview of our AmoebaLLM framework: (a) Stage 1: Generate the subnet selection strategy; (b) Stage 2: One-for-all fine-tuning. Zoom in for a better view.
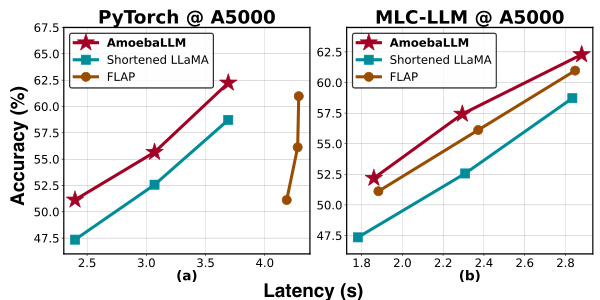
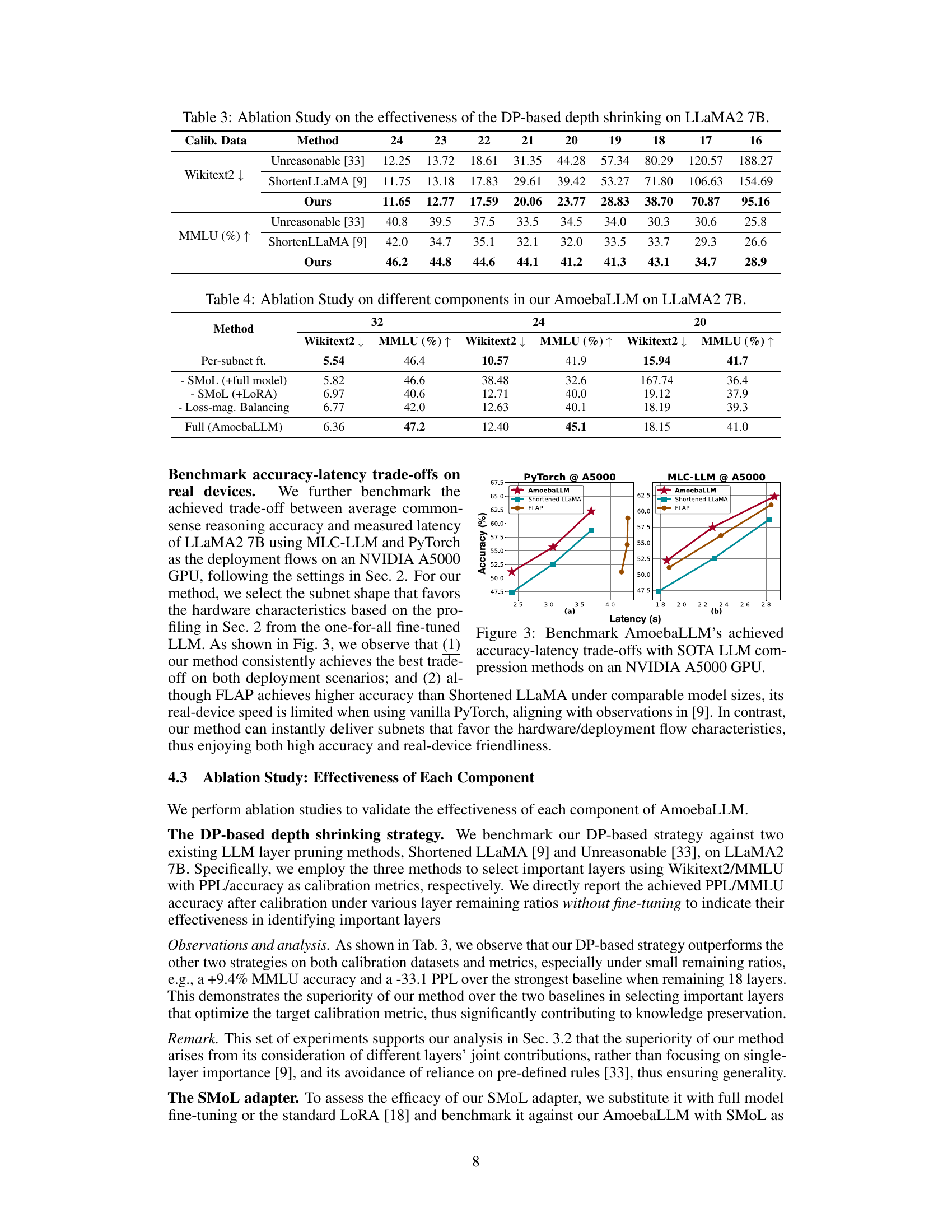
🔼 This figure presents a comparison of AmoebaLLM’s performance against state-of-the-art (SOTA) LLM compression methods on an NVIDIA A5000 GPU. The comparison focuses on the trade-off between accuracy and latency. Two subfigures show the results for two different deployment flows: PyTorch and MLC-LLM. Each subfigure shows how accuracy varies as a function of latency for AmoebaLLM, Shortened LLaMA, and FLAP, illustrating the relative performance and efficiency of each method.
read the caption
Figure 3: Benchmark AmoebaLLM's achieved accuracy-latency trade-offs with SOTA LLM compression methods on an NVIDIA A5000 GPU.
More on tables
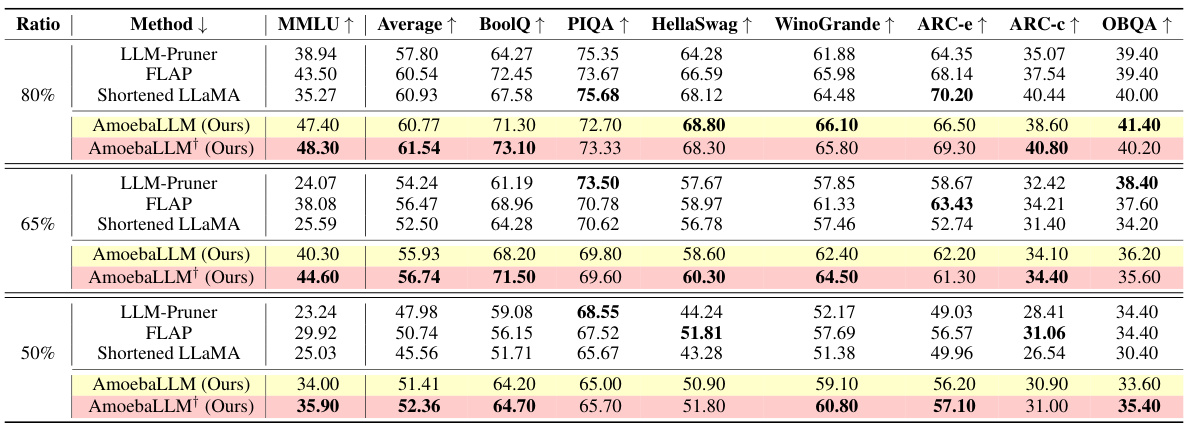
🔼 This table compares the performance of AmoebaLLM with three baseline methods (LLM-Pruner, FLAP, Shortened LLaMA) on the Vicuna 7B v1.5 model across various downstream tasks. The comparison is done under different remaining ratios (80%, 65%, and 50%), representing different model sizes. The performance metrics include MMLU (Massive Multitask Language Understanding), Average (average score across all tasks), BoolQ (boolean question answering), PIQA (physical interaction question answering), HellaSwag (commonsense reasoning), Winogrande (commonsense reasoning), ARC-e (AI2 reasoning challenge - easy), ARC-c (AI2 reasoning challenge - challenge), and OBQA (openbook question answering). AmoebaLLM is shown to outperform the baselines in various scenarios. The AmoebaLLM† rows show the results after individual fine-tuning for each subnet configuration, highlighting the effectiveness of the one-for-all approach.
read the caption
Table 2: Compare with baseline methods under varying remaining ratios on Vicuna 7B v1.5.
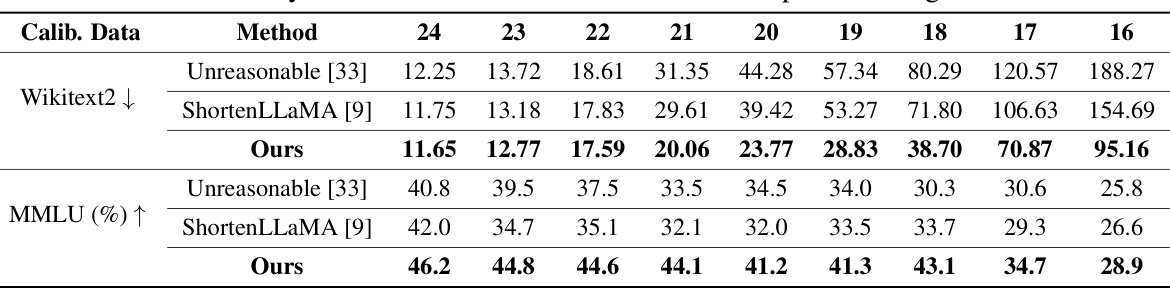
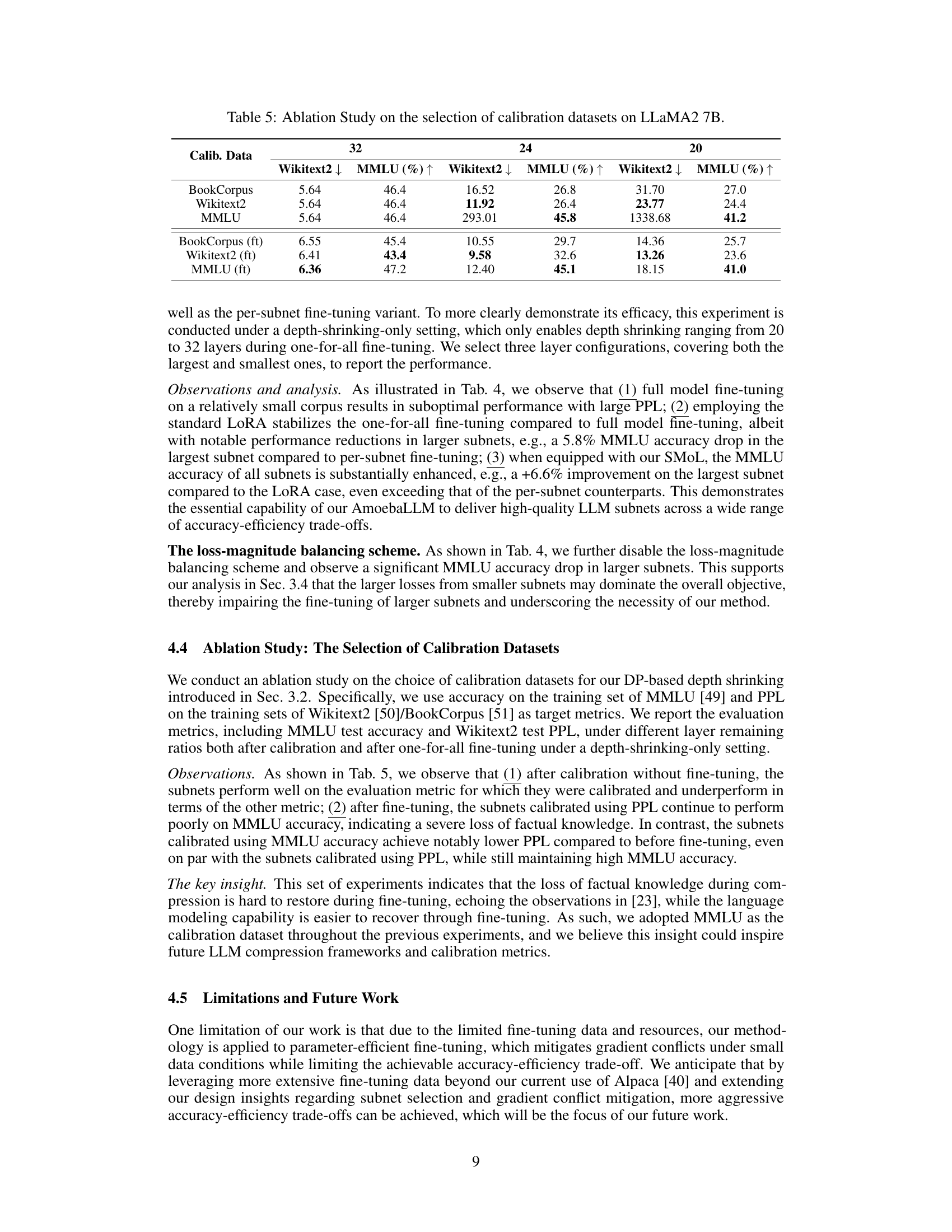
🔼 This table presents an ablation study on the effectiveness of the dynamic programming (DP)-based depth shrinking method used in AmoebaLLM. It compares the performance of AmoebaLLM’s DP-based approach against two other methods: Unreasonable [33] and ShortenLLaMA [9]. The results are shown for different numbers of remaining layers (from 24 to 16) and are measured using two metrics: perplexity (PPL) on the Wikitext2 dataset and accuracy on the MMLU dataset. This comparison aims to demonstrate the advantage of AmoebaLLM’s knowledge-preserving subnet selection strategy in maintaining model performance while reducing the depth.
read the caption
Table 3: Ablation Study on the effectiveness of the DP-based depth shrinking on LLaMA2 7B.
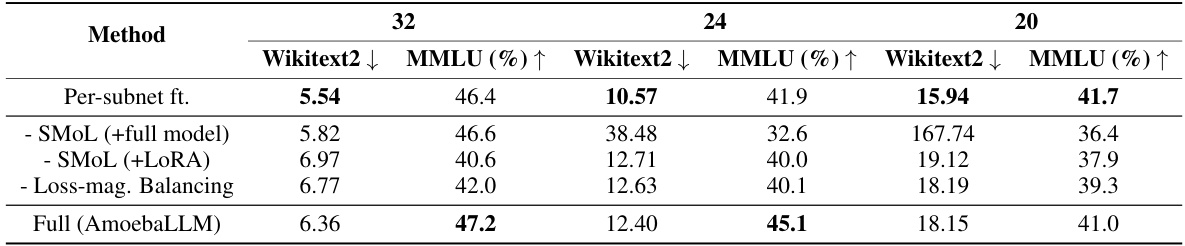
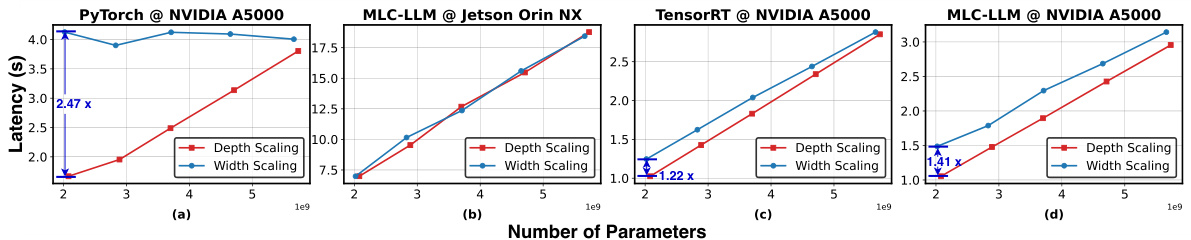
🔼 This table presents the ablation study of different components of AmoebaLLM on LLaMA2 7B. It compares the performance of different configurations of AmoebaLLM against the baseline (per-subnet fine-tuning) across three different depth settings: 32, 24, and 20. The configurations tested include removing SMOL adapter, removing SMOL and replacing with standard LoRA, removing the loss-magnitude balancing scheme. The results (Wikitext2 perplexity and MMLU accuracy) are shown for each configuration and depth, demonstrating the individual contributions of each AmoebaLLM component to the overall performance.
read the caption
Table 4: Ablation Study on different components in our AmoebaLLM on LLaMA2 7B.
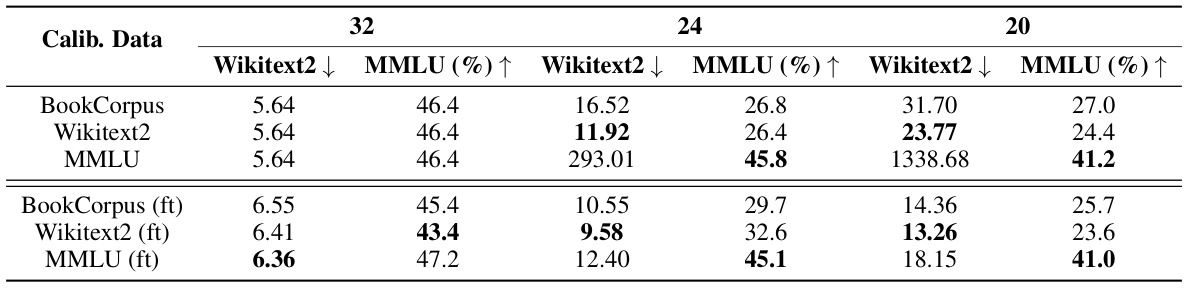
🔼 This table presents an ablation study on the choice of calibration datasets for the DP-based depth shrinking method used in the AmoebaLLM framework. It shows the results of using three different calibration datasets (BookCorpus, Wikitext2, and MMLU) for training LLMs with varying numbers of layers (32, 24, and 20). The results are shown both before fine-tuning and after fine-tuning. The goal is to determine which calibration dataset is most effective for maintaining both accuracy and language modeling capabilities after compressing the LLM.
read the caption
Table 5: Ablation Study on the selection of calibration datasets on LLaMA2 7B.
Full paper#