TL;DR#
The effectiveness of adversarial attacks hinges on the transferability of adversarial examples—their ability to fool models beyond those they were designed against. A prevailing belief held that flatter examples are more transferable. This paper investigates the theoretical link between flatness and transferability, using a novel theoretical bound. Existing methods, focused on flatness, lack theoretical justification for their effectiveness.
This study challenges the prevailing belief by demonstrating that increased flatness does not guarantee improved transferability. To address the issue, the authors introduce TPA, an attack that optimizes a surrogate for the theoretical bound. Extensive experiments show TPA produces more transferable adversarial examples than existing methods across standard datasets and real-world applications. This contributes to a more nuanced understanding of adversarial transferability and provides a new benchmark for future research.
Key Takeaways#
Why does it matter?#
This paper is crucial because it challenges a long-held belief in adversarial machine learning, that flatter adversarial examples are more transferable. This recalibration of understanding enables more effective adversarial attack and defense strategies, paving the way for more robust AI systems. The proposed TPA attack demonstrates superior transferability, pushing the boundaries of current techniques and prompting further exploration of this fundamental relationship.
Visual Insights#

🔼 This figure visualizes the first-order gradient (y1), second-order gradient (y2), and their sum (y3) for the function y = sin(x²). It demonstrates that minimizing the first-order gradient (a common approach in flatness-based optimization) doesn’t guarantee minimization of the combined gradient (y3), which is relevant to the overall transferability of adversarial examples. The black stars highlight the points where y1 and y3 achieve their minimum values, showing the discrepancy between optimizing for flatness alone versus optimizing for overall transferability.
read the caption
Figure 1: The visualization of the first-order gradient, the second-order gradient of y = sin x². The black stars symbolize the location where the minimum values of y1 and y3 are achieved.
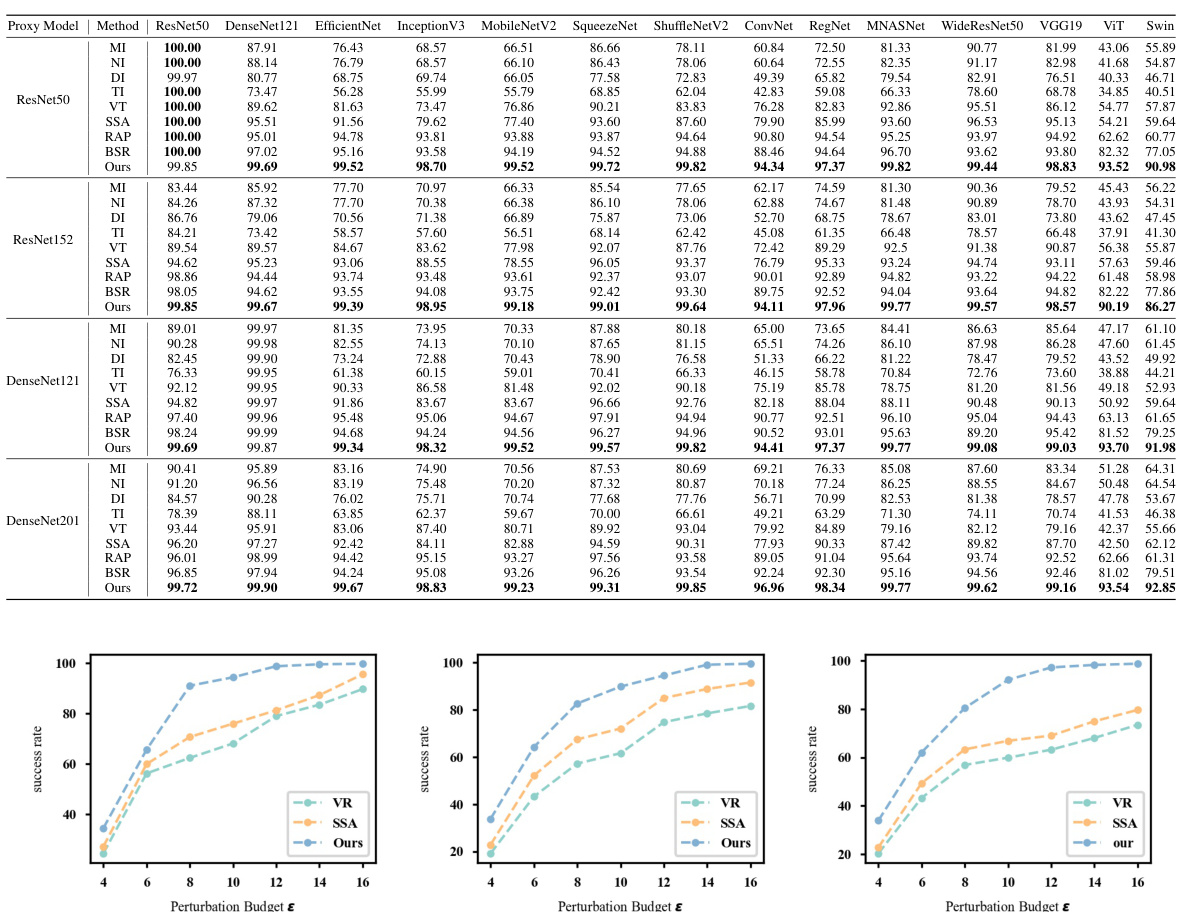
🔼 This table presents the attack success rates achieved by different attack methods against various normal models (ResNet50, DenseNet121, EfficientNet, Inception V3, MobileNetV2, SqueezeNet, ShuffleNetV2, ConvNet, RegNet, MNASNet, WideResNet50, VGG19, ViT, and Swin). The results show the percentage of successful attacks for each method against each model. The best-performing method for each model is highlighted in bold.
read the caption
Table 1: The attack success rates (%) of different attacks on normal models. Best results are in bold.
In-depth insights#
Transferability Bound#
The concept of a ‘Transferability Bound’ in adversarial machine learning is crucial. It seeks to quantify the limits of how well an adversarial example, crafted for one model, will also fool other, unseen models. A tighter bound indicates more predictable transferability, making attacks easier to generalize and defenses harder to create. Research into this area often involves deriving theoretical bounds based on factors like model similarity and the flatness of the loss landscape around adversarial examples. However, existing research suggests that the relationship between flatness and transferability isn’t straightforward, challenging initial intuitions. A key area of ongoing investigation focuses on identifying practical, measurable factors that reliably predict the transferability of adversarial examples, allowing for the development of more robust attacks and defenses.
TPA Attack#
The TPA attack, as described in the research paper, is a novel approach to crafting adversarial examples. Its core innovation lies in theoretically grounding the attack’s design by deriving a transferability bound. Unlike previous methods that relied on heuristics or empirical observations, TPA uses this bound as a direct optimization target. Although directly optimizing the bound is computationally expensive, TPA cleverly introduces a surrogate function that only needs first-order gradients, making it practical. Experiments show TPA generates significantly more transferable adversarial examples compared to state-of-the-art baselines, across various datasets and real-world applications. TPA’s theoretical foundation and superior empirical performance challenge the commonly held belief that flatness is the sole key to high transferability, potentially reshaping the landscape of adversarial attack research and defense mechanisms.
Flatness Myth#
The prevailing belief that flatter adversarial examples exhibit better transferability, often termed the “Flatness Myth,” is challenged by this research. The study demonstrates a theoretical bound on transferability, revealing that flatness alone is insufficient to guarantee improved transferability. While flatness contributes, other factors such as the inherent difference between models and the higher-order gradients significantly impact transferability. This theoretical analysis thus debunks the overreliance on flatness as the sole metric for enhancing adversarial example transferability. The study proposes a Theoretically Provable Attack (TPA) which leverages a surrogate of the derived bound, optimizing a more principled and practically efficient method. Extensive experiments confirm TPA’s superiority over existing state-of-the-art methods, suggesting a need to re-evaluate the community’s existing preconceived notions about the relationship between flatness and transferability, advocating for more theoretically grounded approaches.
Real-World Tests#
A dedicated ‘Real-World Tests’ section would significantly enhance the paper’s impact by demonstrating the practical applicability of the proposed TPA attack. Concrete examples are crucial; showcasing TPA’s performance against diverse real-world systems (e.g., image recognition APIs, search engines, and large language models) would provide compelling evidence of its transferability and effectiveness beyond benchmark datasets. The results should be presented with appropriate metrics (e.g., success rate, confidence scores, qualitative analysis of misclassifications) and a careful discussion of potential limitations and vulnerabilities in the targeted real-world applications. Comparative analysis against existing state-of-the-art attacks in these real-world scenarios is essential to highlight TPA’s advantages. Finally, a thorough ethical discussion is necessary, acknowledging the potential misuse of such an effective attack and outlining steps taken to mitigate risks and responsibly disclose findings.
Future Work#
Future research directions stemming from this paper could involve developing more sophisticated surrogate functions for the transferability bound, enabling the optimization of higher-order gradients more efficiently. Another avenue would be to explore alternative theoretical frameworks beyond the current analysis, potentially leading to tighter bounds and a deeper understanding of the relationship between flatness and transferability. Investigating the impact of different model architectures and training methods on the transferability bound is also crucial. Finally, further research could focus on developing more robust defense mechanisms against these theoretically-proven attacks, thereby advancing the broader field of adversarial machine learning and cybersecurity.
More visual insights#
More on figures

🔼 The figure visualizes attention maps generated by different attack methods (VT, SSA, and TPA) on target model for targeted attack. It demonstrates how attention is shifted by the different attack methods. The goal is to show how TPA’s adversarial examples more effectively distract the model’s attention away from the true object, leading to better transferability.
read the caption
Figure 4: We conduct targeted attacks and visualize attention maps of the target model to the resultant adversarial images.

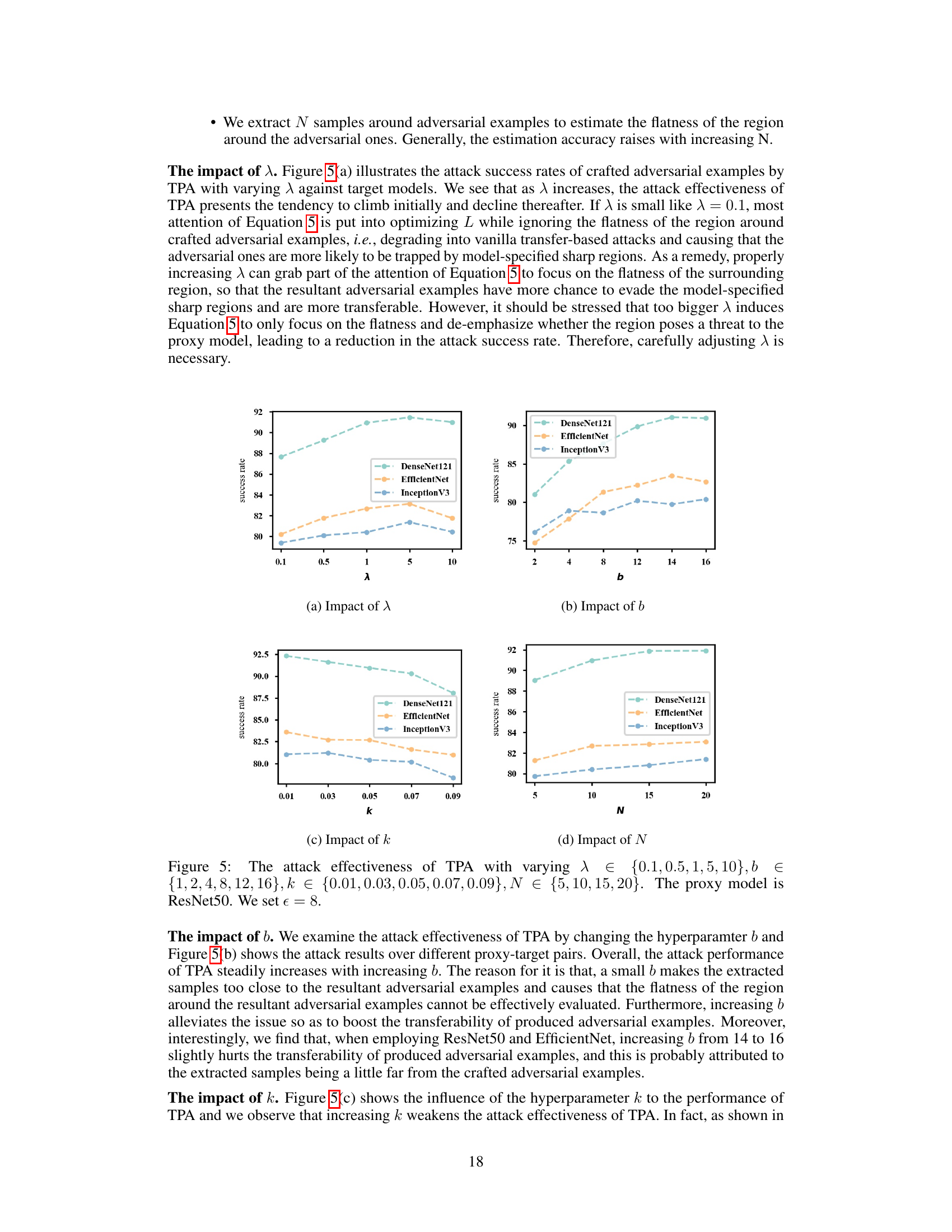
🔼 This figure shows the impact of four hyperparameters (λ, b, k, N) on the attack success rate of TPA. Each subplot shows the attack success rate for different values of a single hyperparameter while keeping the others constant. The results demonstrate how the hyperparameters affect the balance between local effectiveness and transferability, influencing the overall performance of TPA.
read the caption
Figure 5: The attack effectiveness of TPA with varying λ∈ {0.1,0.5,1,5,10},b ∈ {1, 2, 4, 8, 12, 16},k ∈ {0.01,0.03, 0.05, 0.07, 0.09}, 0.07,0.09}, Ν ∈ {5,10,15,20}. The proxy model is ResNet50. We set e = 8.
🔼 This figure visualizes attention maps for targeted attacks using four different methods: original image, VT, SSA, and the proposed TPA method. The attention maps show how the target model focuses its attention on different parts of the image after adversarial examples are added. The goal is to illustrate that TPA more effectively distracts the attention of the target model away from the object of interest.
read the caption
Figure 4: We conduct targeted attacks and visualize attention maps of the target model to the resultant adversarial images.
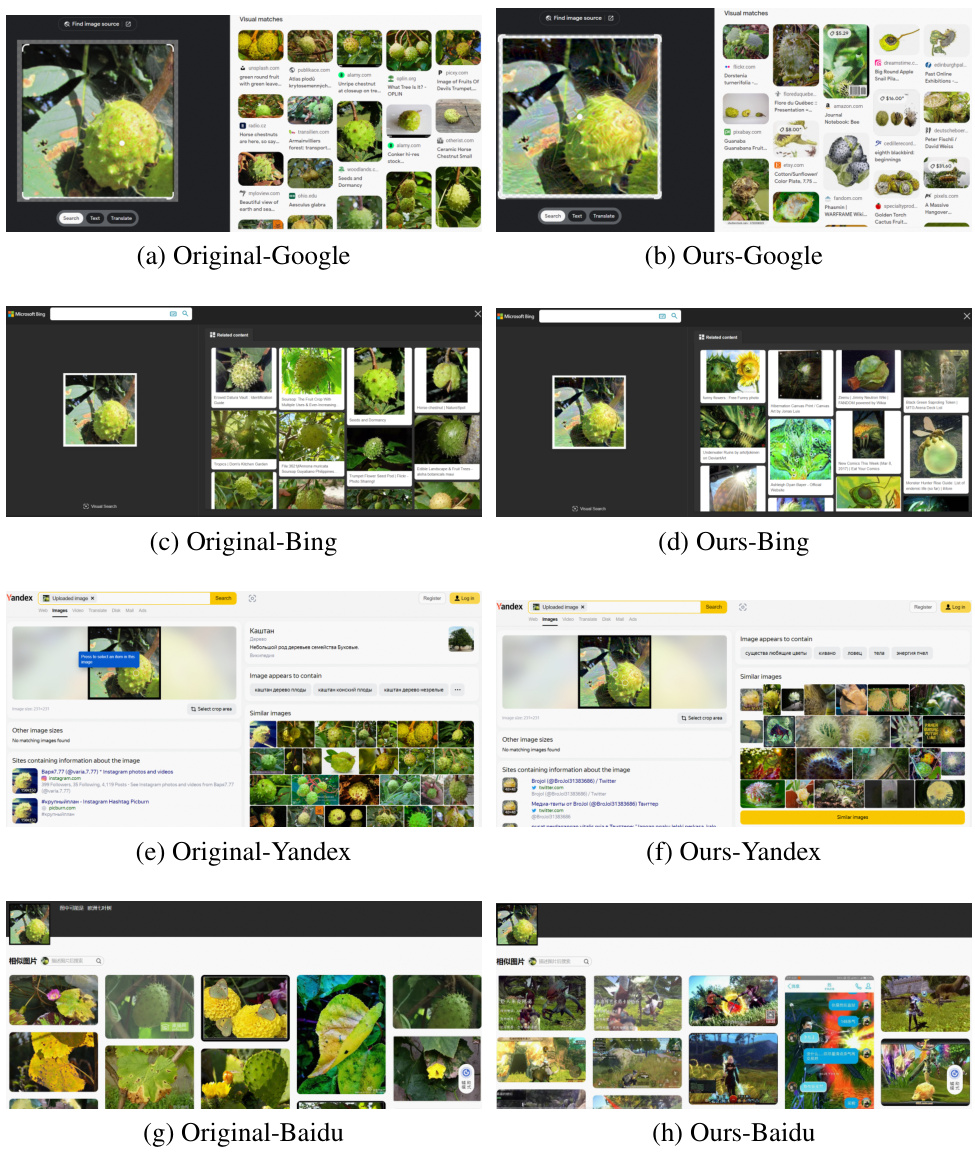
🔼 This figure visualizes an example of TPA against four state-of-the-art search engines. We observe that search engines fetch high-quality and similar images for normal samples. However, when we input the generated adversarial examples, the quality of retrieved images noticeably deteriorates, particularly in the case of Baidu.
read the caption
Figure 7: An example for attacking four state-of-the-art search engines.
More on tables
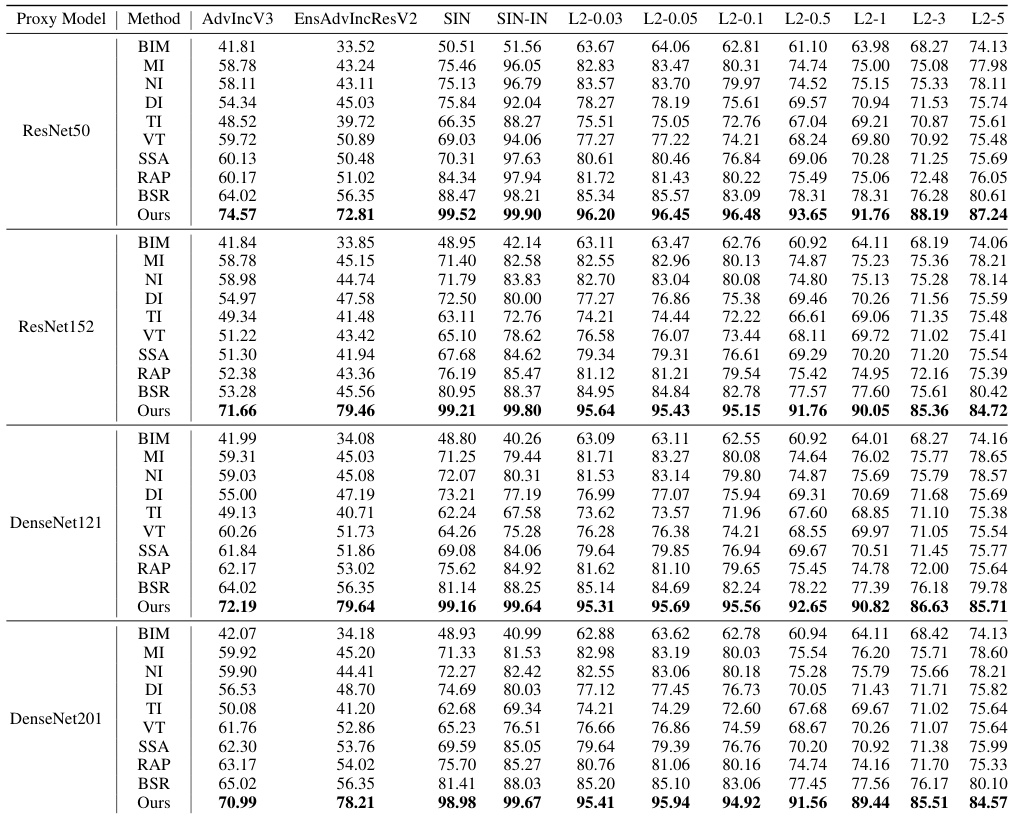
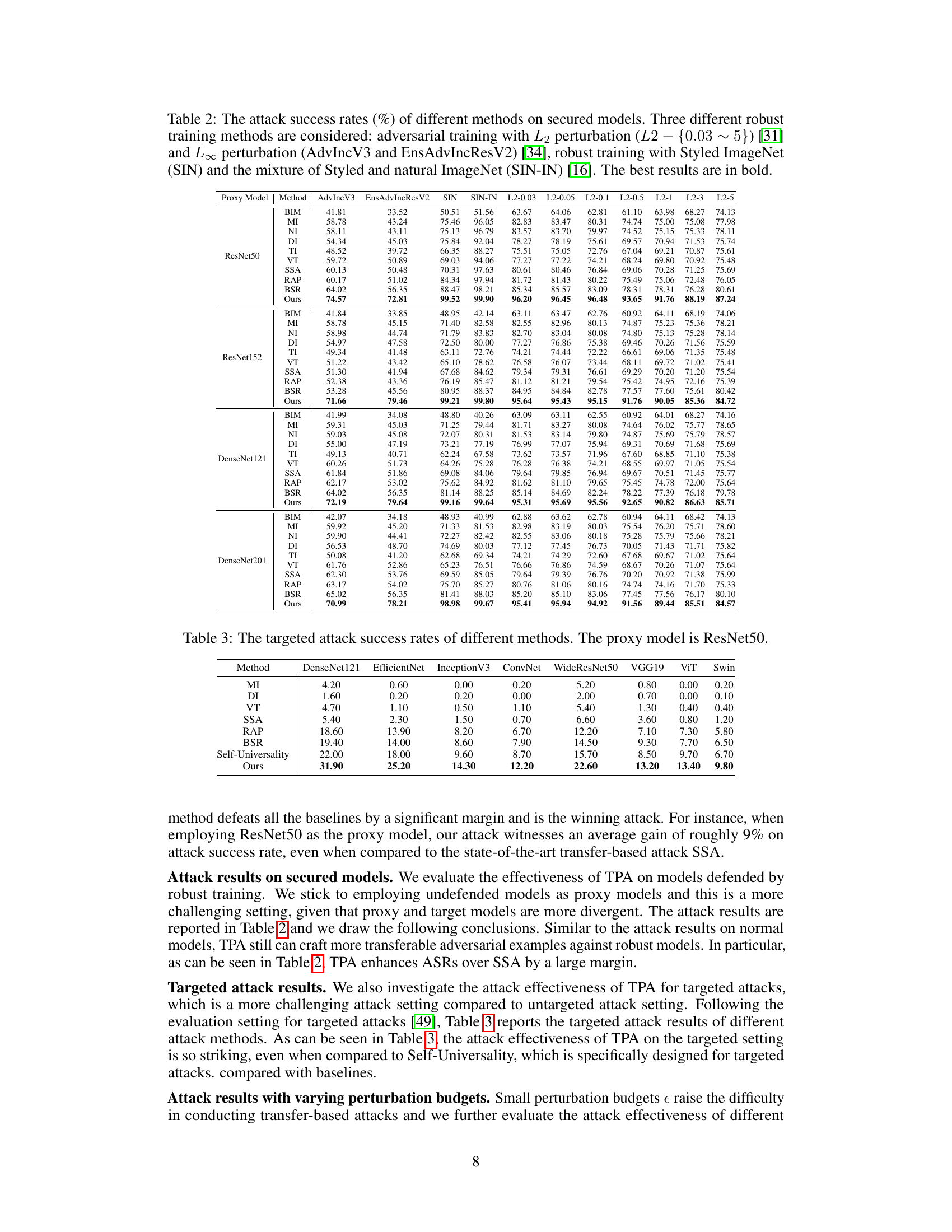
🔼 This table presents the attack success rates of various methods against secured models. It compares the performance of different attack methods on models that have undergone three different types of robust training: adversarial training with L2 and L∞ perturbations, and robust training with Styled ImageNet and a mix of styled and natural ImageNet. The best result for each model/method combination is highlighted in bold.
read the caption
Table 2: The attack success rates (%) of different methods on secured models. Three different robust training methods are considered: adversarial training with L2 perturbation (L2 - {0.03 ~ 5}) [31] and L∞ perturbation (AdvIncV3 and EnsAdvIncResV2) [34], robust training with Styled ImageNet (SIN) and the mixture of Styled and natural ImageNet (SIN-IN) [16]. The best results are in bold.
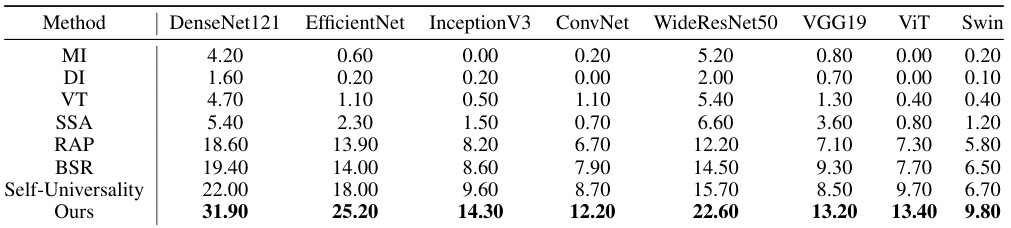
🔼 This table presents the success rates of various targeted attacks against different models. The attacks were designed to force misclassification to a specific target label, making this a more challenging scenario than untargeted attacks. ResNet50 is used as the proxy model for generating adversarial examples, which are then tested on other models. The results showcase the relative effectiveness of different attack methods under these conditions.
read the caption
Table 3: The targeted attack success rates of different methods. The proxy model is ResNet50.

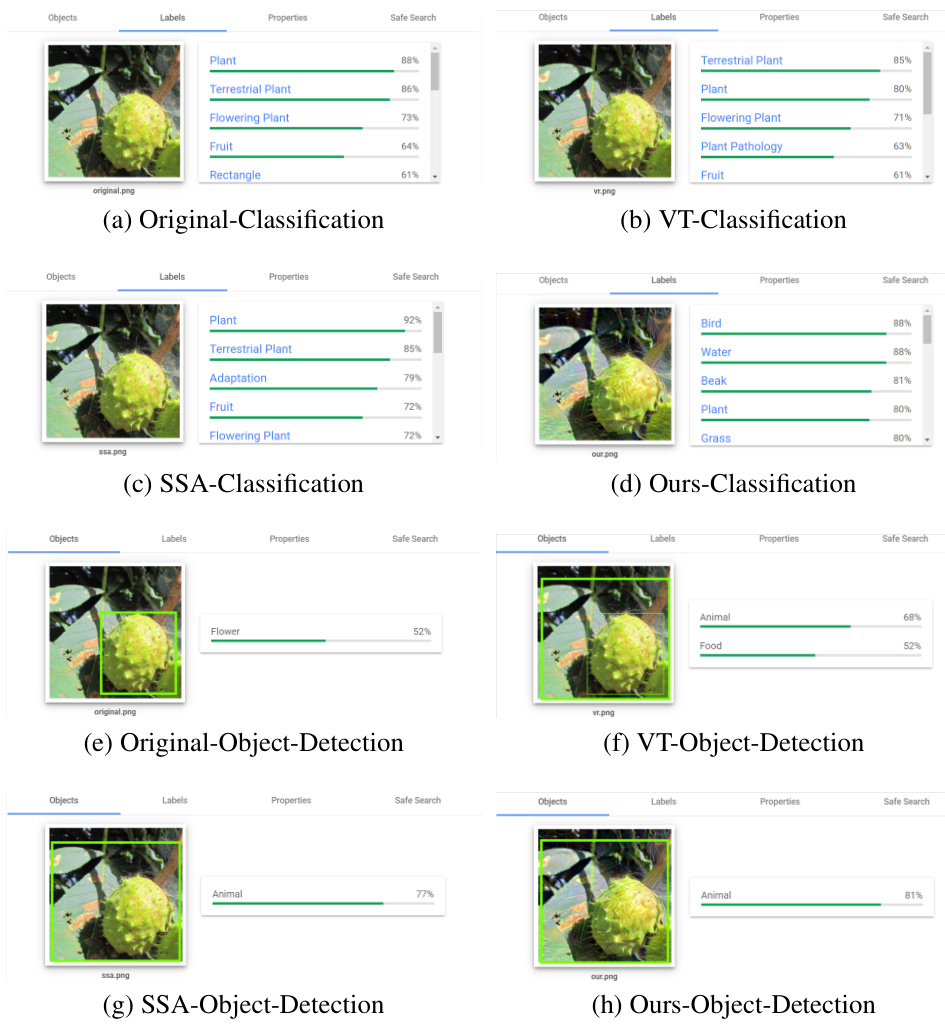
🔼 This table presents the results of evaluating the effectiveness of adversarial examples generated using the TPA method against various real-world applications. A total of 100 samples were randomly chosen from ImageNet, and adversarial examples were created using TPA and ResNet50. A volunteer assessed the consistency between the image content and application predictions, rating them on a scale of 1 (completely incorrect) to 5 (completely correct). Lower scores indicate higher attack effectiveness. The applications evaluated include image classification, object detection, and several search engines (Google, Bing, Yandex, Baidu). The table also shows the performance against large language models (GPT-4 and Claude3).
read the caption
Table 4: The scoring for the effectiveness of adversarial examples against real-world applications. We randomly extract 100 samples from ImageNet and generate adversarial examples for them using TPA and ResNet50. We enlist a volunteer to assess the consistence between the image contents with the predictions made by applications. A lower rating reflects a higher effectiveness of the attack.

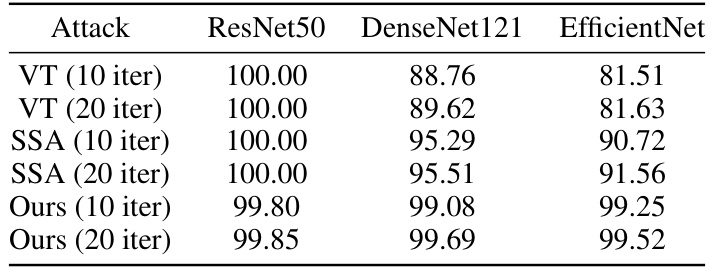
🔼 This table presents the attack success rates of different attack methods against various defense mechanisms. The ResNet50 model is used as the proxy model for all attacks. The table compares the performance of four attacks: VT, SSA, RAP, and the proposed ‘Ours’ attack against six different defenses: R&P, NIPS-R3, FD, ComDefend, RS, and NRP. Higher values indicate better attack performance (higher success rate). The results show that the proposed ‘Ours’ attack consistently outperforms the baselines against all defenses.
read the caption
Table 5: The attack success rates (%) of attacks against various defenses. We use ResNet50 as the proxy model.
🔼 This table shows the attack success rates of different attack methods against various defense mechanisms. The proxy model used is ResNet50. The results show the effectiveness of different attacks in bypassing defenses, such as R&P, NIPS-R3, FD, ComDefend, RS, and NRP.
read the caption
Table 5: The attack success rates (%) of attacks against various defenses. We use ResNet50 as the proxy model.
Full paper#