↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Large Multimodal Models (LMMs) show promise in visual understanding and response generation but suffer from “hallucinations”, producing factually incorrect responses. Current methods often involve complex training or modifications to the model architecture. Existing approaches to reduce hallucination in LMMs often involve retraining or complex model architecture changes, which is time-consuming and resource-intensive.
The paper introduces CODE, a novel contrastive decoding method. CODE utilizes self-generated descriptions as contrasting references during decoding. This dynamically adjusts information flow and improves response alignment with actual visual content. Experiments show CODE significantly reduces hallucinations and improves consistency in various benchmarks across multiple LMMs without needing extra training. This provides a simple and effective solution for enhancing existing LMMs.
Key Takeaways#
Why does it matter?#
This paper is crucial because hallucination in large multimodal models (LMMs) hinders real-world applications. The proposed CODE method offers a simple yet effective solution by leveraging self-generated descriptions, improving response accuracy and consistency without additional training. This opens avenues for enhancing existing LMMs and inspires further research on hallucination mitigation techniques.
Visual Insights#
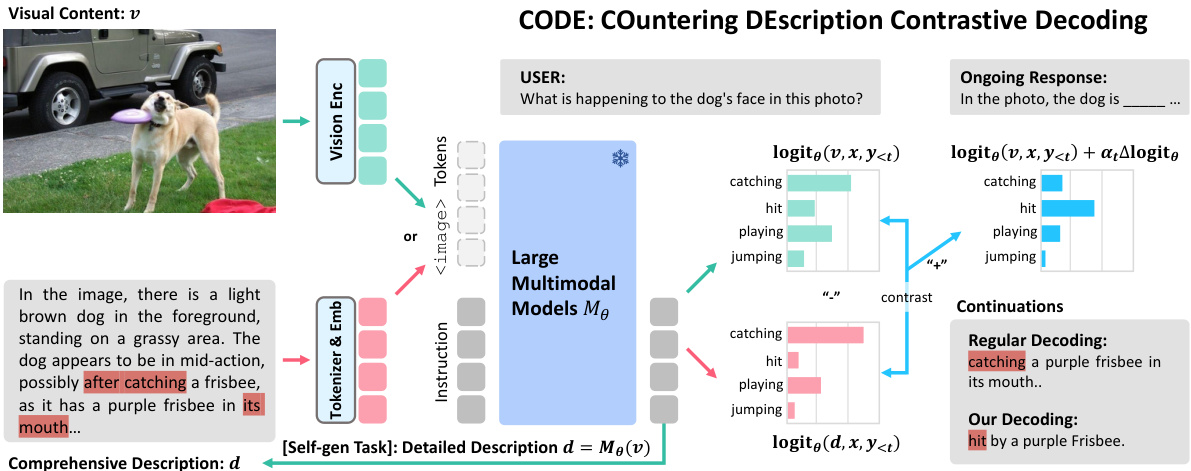
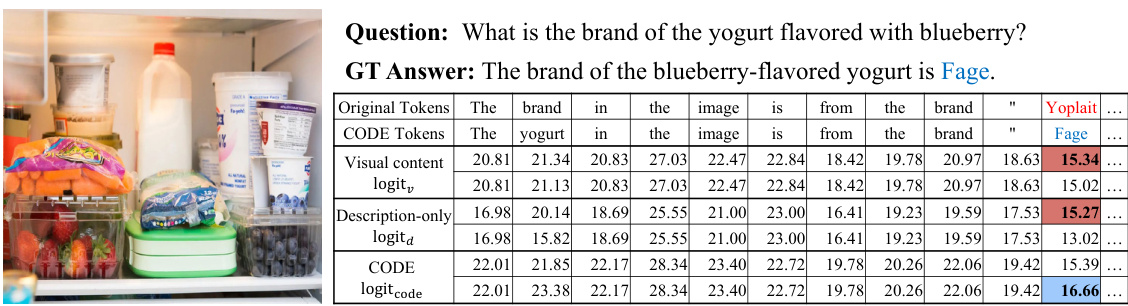
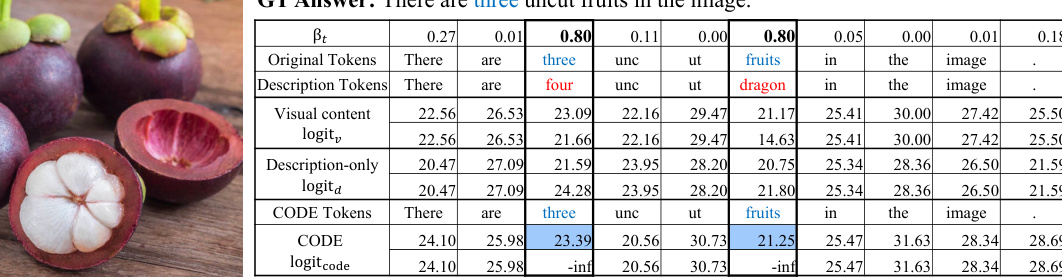
This figure illustrates the CODE (COuntering DEscription Contrastive Decoding) method. The process starts with visual content (an image of a dog catching a frisbee) which is processed by a Large Multimodal Model (LMM). The LMM generates a comprehensive description of the image. Then, during the decoding phase, the LMM generates an ongoing response to a user question. The CODE method contrasts the logit information from the visual content and the generated comprehensive description. This contrasting helps the model to generate more contextually appropriate and correct responses, reducing hallucinations by suppressing inconsistent words in the generated text (e.g., replacing ‘catching’ with ‘hit’ in this example).

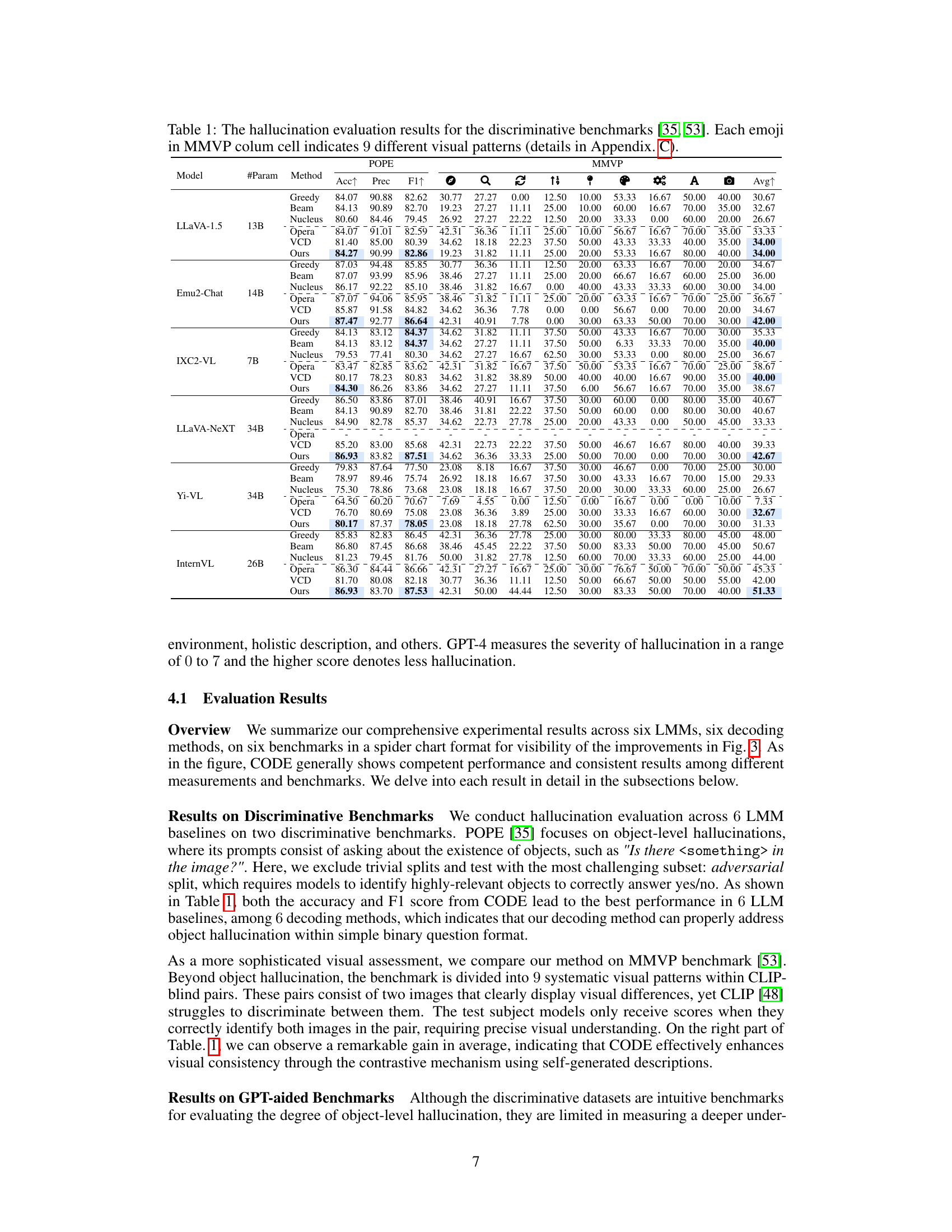
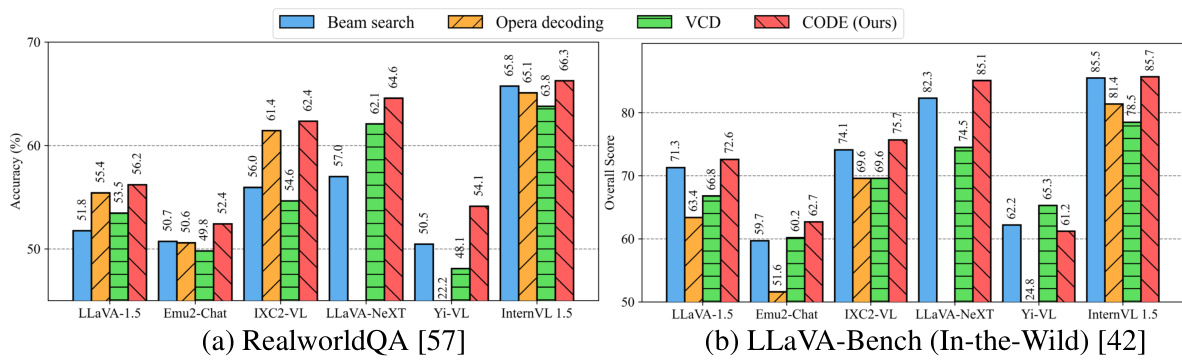
This table presents the results of hallucination evaluation on discriminative benchmarks using six different large multimodal models (LMMs) and six decoding methods. The discriminative benchmarks, POPE and MMVP, assess hallucination by focusing on the correctness of model predictions on object-level and subtle visual detail questions respectively. The table shows precision, F1-score, and accuracy for the POPE benchmark, and accuracy for individual visual pattern categories within the MMVP benchmark. The results are broken down by model, parameter count, and decoding method, showing how CODE compares to other state-of-the-art methods.
In-depth insights#
Hallucination in LMMs#
Large multimodal models (LMMs) demonstrate impressive abilities in visual context understanding and response generation. However, a significant challenge arises from the phenomenon of hallucination, where LMMs generate responses unrelated to the visual content. This issue stems from inconsistencies in cross-modal alignment during training, exacerbated by the limited instruction-following data used for fine-tuning. Several approaches attempt to address this, including reactive methods that intervene during decoding. The core problem involves the gap between the model’s visual understanding and its linguistic capabilities. Effective solutions require careful consideration of information flow during response generation, potentially through contrastive decoding methods that leverage self-generated descriptions to improve the consistency of outputs and reduce hallucination. Addressing this challenge requires not only improved training paradigms but also advanced decoding strategies capable of effectively grounding responses in true visual evidence.
CODE: Contrastive Decoding#
Contrastive decoding methods, exemplified by “CODE: Contrastive Decoding,” aim to enhance the quality of Large Multimodal Models (LMMs) outputs by leveraging the inherent strengths of contrastive learning. CODE likely uses a self-generated description of the input image as a contrastive reference. This approach capitalizes on the model’s own understanding to identify and correct inconsistencies between the generated response and the actual visual content. By contrasting the model’s predictions against its own detailed description, CODE can effectively reduce hallucinations and improve the accuracy of generated responses. The method’s innovation likely lies in the dynamic adjustment of information flow during the decoding process. This adaptive mechanism allows CODE to refine its predictions, ensuring a more contextually relevant and coherent response. While training-free, CODE’s effectiveness hinges on the quality of the self-generated description, making it crucial to manage this component of the framework effectively. Furthermore, CODE’s success depends on the ability of the self-generated descriptions to capture the salient aspects of the visual data while avoiding biases and hallucinations inherent to the model itself.
Visual Counterpart Use#
The effective utilization of visual counterparts is crucial for enhancing the performance of large multimodal models (LMMs). A key challenge lies in selecting a suitable visual counterpart that effectively balances factual accuracy with the potential for hallucination. The paper explores the use of self-generated descriptions as visual counterparts. This approach offers a unique advantage: self-generated descriptions provide a comprehensive overview of the model’s interpretation of the visual input, incorporating both accurate information and potential biases or inaccuracies. By contrasting these self-generated descriptions with the actual visual information, the model can refine its response and reduce inconsistencies. This method is particularly useful because it leverages the model’s own understanding of the visual content, making it a training-free strategy for mitigating hallucination. The success of using self-generated descriptions as visual counterparts heavily relies on the quality and completeness of the initial description. Further research is needed to investigate how to further optimize the generation process and address limitations, specifically for complex or ambiguous images. The dynamic adjustment of information flow and the introduction of an adaptive constraint are key improvements, ensuring that the model’s understanding of the visual content drives response generation more effectively.
Adaptive Info Control#
Adaptive information control in the context of large multimodal models (LMMs) aims to dynamically adjust the flow of information during the decoding process. This is crucial because LMMs often generate hallucinatory outputs, which are factually incorrect or inconsistent with the input visual data. The core idea is to selectively gate or amplify information from different sources, such as the visual input and self-generated descriptions, to improve the coherence and accuracy of the generated response. This selective gating might involve techniques like contrasting logits derived from multiple sources, or employing a dynamic weighting scheme based on the relative confidence or relevance of information. A key challenge lies in determining the appropriate level of control: too much restriction might suppress relevant information, while insufficient control may allow hallucinations to persist. Effective adaptive mechanisms must carefully balance these competing needs, ideally learning to differentiate between genuine visual evidence and spurious model-generated content. Successful implementation would lead to a significant reduction in hallucinations, enhanced cross-modal consistency, and more reliable LMM outputs. This would be especially valuable in real-world applications relying on reliable and truthful information from these powerful models.
Future Work#
The authors suggest several avenues for future research. Improving the robustness of self-generated descriptions is crucial, as these descriptions serve as the foundation for CODE’s contrastive mechanism. Hallucinations in these descriptions propagate errors, so enhancing their accuracy, perhaps through more sophisticated prompting techniques or model architectures, would significantly boost CODE’s effectiveness. Integrating external knowledge sources is another key area; CODE’s reliance on the model’s internal knowledge limits its ability to correct factual inaccuracies. External resources could provide more reliable contextual information for comparison. Finally, developing more sophisticated bias detection mechanisms is important. While CODE helps mitigate hallucination, biases within the model can still affect its output. More robust detection and correction of these biases could greatly enhance the overall reliability of the system.
More visual insights#
More on figures

This figure compares the performance of models using self-generated descriptions as visual input replacements versus the original models using actual visual content. The comparison is performed on two benchmarks: MMVP (multiple choice) and LLaVA-Bench (description-level). The bar chart displays the results, with plain bars representing models using self-generated descriptions and dotted bars representing original models. This visualization helps to illustrate the impact of using self-generated descriptions as a source of visual information.

This figure illustrates the CODE (COuntering DEscription Contrastive Decoding) method. CODE leverages self-generated descriptions to improve the accuracy of LMMs’ responses. The model generates a detailed description of the input image (d). During decoding, it contrasts this description with the visual content (v) to produce logits. By contrasting the likelihoods from both visual and textual information, the model generates more accurate and contextually appropriate responses, reducing hallucinations. An example is shown where the inconsistent word ‘catching’ is corrected to ‘hit’ based on the contrastive decoding.
This figure illustrates the CODE (COuntering DEscription Contrastive Decoding) method. CODE uses a large multimodal model (LMM) to generate a detailed description of an image. This description is then used as a contrasting reference during the decoding phase. The LMM recursively outputs logits based on both the original visual content and the self-generated description. By comparing these logits, CODE adjusts the information flow and improves response alignment with the actual visual content, reducing hallucinations.

This figure illustrates the CODE (COuntering Description Contrastive Decoding) method. The process starts with a Large Multimodal Model (LMM) receiving visual content (v) and a user’s instruction. The LMM first generates a detailed description of the visual content (d) independently. Then, during the decoding phase of generating a response, CODE contrasts the logit information from both the visual content and the self-generated description. By dynamically adjusting the information flow based on this comparison, CODE aims to improve response accuracy and consistency with the visual content, mitigating hallucination issues. The example shows how the model shifts from an incorrect prediction (‘catching’) to a correct one (‘hit’) by leveraging the contrastive information.

This figure illustrates the CODE (COuntering Description Contrastive Decoding) method. It shows how a large multimodal model (LMM) generates a detailed description of an image (v). This description (d) acts as a contrastive reference during decoding. The LMM then recursively generates logits based on both the image (v) and its self-generated description (d). By contrasting these logits, CODE aims to produce more accurate responses aligned with the actual visual content, correcting inconsistencies like replacing ‘catching’ with ‘hit’ in a response regarding an image of a dog.

This figure illustrates the CODE (Countering Description Contrastive Decoding) method. CODE uses a large multimodal model (LMM) to generate a detailed description of an image. This description acts as a ‘visual counterpart’ during the decoding process. The LMM then recursively outputs logits based on both the original visual input and the self-generated description. By contrasting these logits, CODE aims to improve response accuracy and coherence by suppressing inconsistent words and ensuring that the generated response aligns with the actual visual content. The example shows how the word ‘catching’ is corrected to ‘hit’ because the self-generated description provides a more accurate contextual understanding of the image.
This figure illustrates the CODE (COuntering DEscription Contrastive Decoding) method. CODE leverages self-generated descriptions as contrasting references during the decoding phase of Large Multimodal Models (LMMs) to reduce hallucinations. The model generates a detailed description of the input image (d), which is then used alongside the original image content (v) to generate the final response. By comparing the log probabilities from both sources, CODE refines the output, prioritizing responses that align with the actual visual content and suppressing hallucinatory words.
This figure illustrates the CODE (COuntering DEscription Contrastive Decoding) method. CODE uses a large multimodal model (LMM) to generate a detailed description of an image. This description is then used as a contrastive reference during the decoding phase, where the model compares logits from the original image (v) and the self-generated description (d). This contrastive process helps to correct and improve the response alignment with the actual visual content, reducing hallucinations by suppressing inconsistent words. The example shown highlights how the word ‘catching’ is corrected to ‘hit’, based on the contrastive information.

This figure illustrates the overall decoding procedure of the CODE method. It shows how a Large Multimodal Model (LMM) generates a detailed description of an image (visual content). This description is then used as a contrasting reference during the decoding process. The LMM recursively outputs logits (probabilities) for each token based on both the original visual content and the self-generated description. By contrasting these logits, CODE aims to produce more accurate and contextually relevant responses that align with the image content, correcting any inconsistencies or hallucinations.

This figure illustrates the CODE (Countering DEscription Contrastive Decoding) method. It shows how a Large Multimodal Model (LMM) generates a detailed description of an image (d). This description is then used contrastively during the decoding phase, where the model’s next-token predictions are adjusted based on comparing logits from the actual visual content (v) and the self-generated description (d). This process helps to correct inconsistencies and improve the alignment of the model’s response with the actual visual content, reducing hallucinations. The example highlights how the word ‘catching’ is replaced with ‘hit’ because the self-generated description provides a contrasting view.

This figure illustrates the CODE (Countering DEscription Contrastive Decoding) method. CODE uses a large multimodal model (LMM) to generate a detailed description of an image. This description acts as a contrasting reference during the decoding process for a user’s question about the image. The LMM produces logits (probabilities) for the next word based on both the original visual input and the self-generated description. By contrasting these logits, CODE aims to improve the accuracy and coherence of the LMM’s response by suppressing inaccurate or hallucinated words.

This figure illustrates the CODE (Countering Description Contrastive Decoding) method. It shows how a large multimodal model (LMM) generates a detailed description of an image. This description is then used as a contrasting reference during the decoding process. The model recursively outputs logits (probabilities) for each word based on both the visual content and self-generated description. By comparing these probabilities, CODE aims to select words that are consistent with both the image and the model’s understanding, reducing hallucinations.

This figure illustrates the CODE (Countering DEscription Contrastive Decoding) method. The process begins with a Large Multimodal Model (LMM) generating a comprehensive description of the input image. This description serves as a contrast to the image itself during the decoding process. The LMM recursively outputs logits (predicted probabilities) for the next token based on both the image and its self-generated description. By comparing the likelihoods, the model refines its response to align better with the actual visual content. The example shown highlights how contrasting the log-likelihoods corrects an inconsistent word from ‘catching’ to ‘hit’, improving accuracy.

This figure illustrates the CODE (Countering DEscription Contrastive Decoding) method. CODE uses a large multimodal model (LMM) to generate a detailed description of an image. This description acts as a contrastive reference during the decoding process. The model generates logits (probabilities) for the next word based on both the original image and its self-generated description. By comparing these probabilities, CODE refines the model’s response to be more accurate and consistent with the actual image content, reducing hallucinations.

This figure illustrates the CODE (Countering DEscription Contrastive Decoding) method. The process begins with a Large Multimodal Model (LMM) receiving visual content (v). The LMM generates a comprehensive self-description (d) of the visual content. The model then uses both the visual content (v) and its self-description (d) to predict the next token in the response generation process. By contrasting the likelihoods from both v and d, the model improves the response accuracy and consistency, reducing hallucinations and making it more aligned with the actual image content. An example is provided showing how inconsistent words, such as ‘catching’ being corrected to ‘hit’ based on the visual context.
More on tables
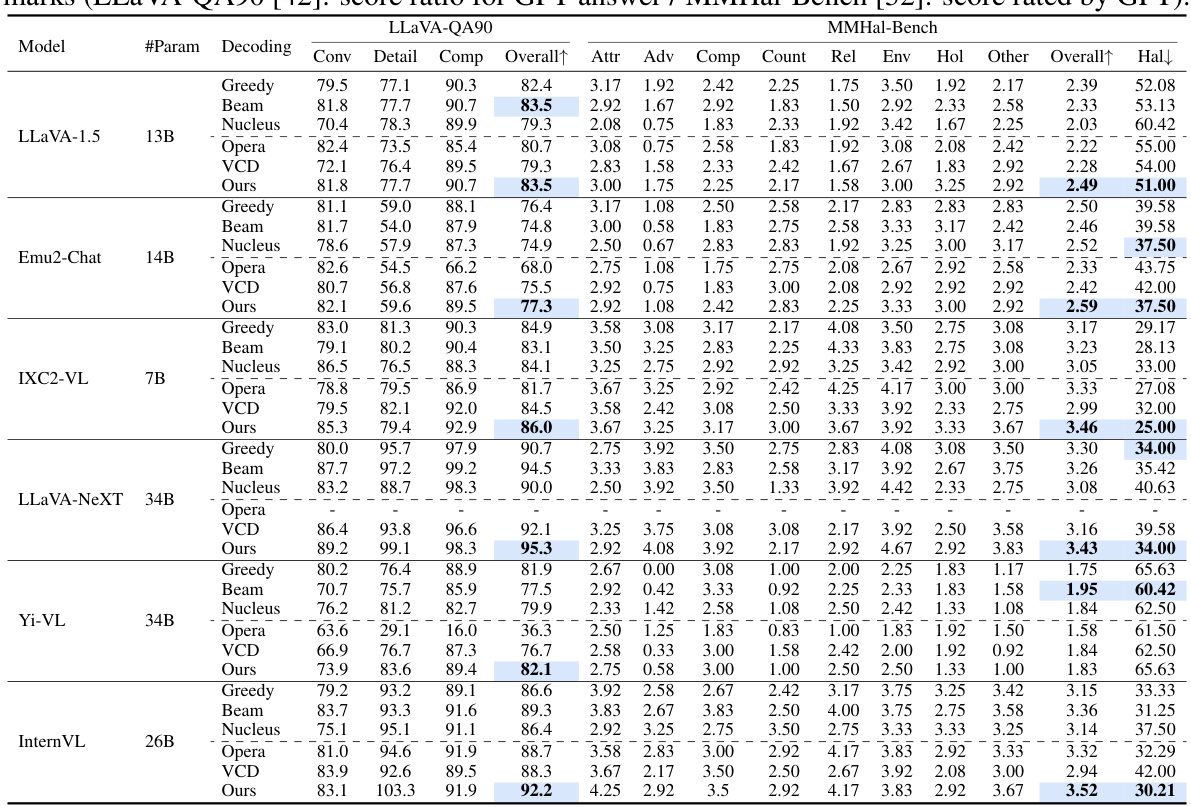
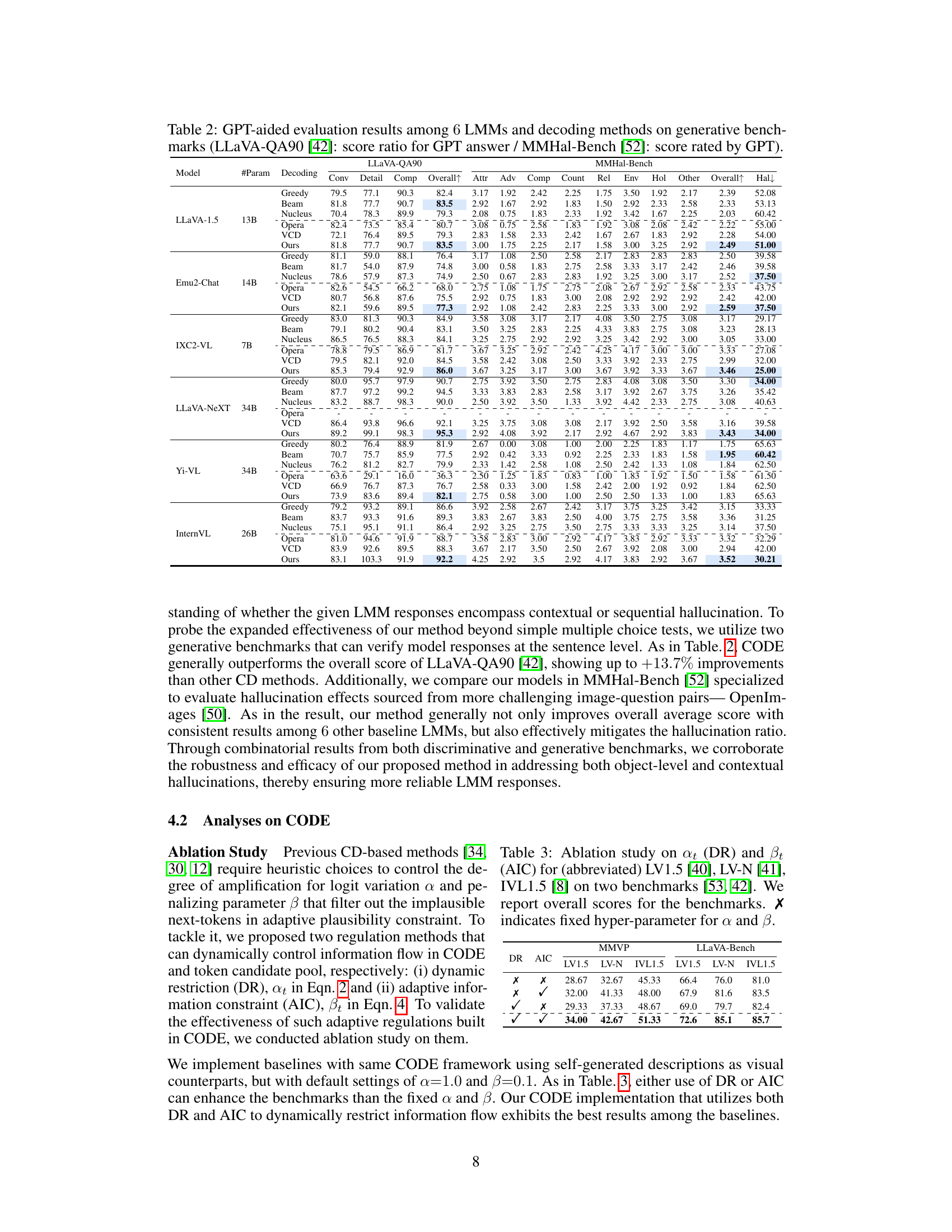
This table presents the results of GPT-aided evaluations of six different Large Multimodal Models (LMMs) using six different decoding methods on two generative benchmarks: LLaVA-QA90 and MMHal-Bench. LLaVA-QA90 uses a score ratio based on GPT-4 ratings of model responses compared to ground truth, covering conversation, detailed description, and complex reasoning question types. MMHal-Bench provides a GPT-4 hallucination score (0-7, higher is better) across eight question types assessing various aspects of visual understanding.

This ablation study investigates the impact of the dynamic restriction (DR) and adaptive information constraint (AIC) components of the CODE model on two benchmarks: MMVP and LLaVA-Bench. It evaluates three different LLM models: LLaVA-1.5, LLaVA-NeXT, and InternVL 1.5. The results show the performance of each model under different combinations of DR and AIC (enabled/disabled), with the final row representing the full CODE model where both techniques are enabled.
This table presents the results of hallucination evaluation on discriminative benchmarks (POPE, MMVP) for six different Large Multimodal Models (LMMs) using six different decoding methods (greedy, beam search, nucleus, OPERA, VCD, and CODE). The performance is measured using precision, F1-score, and accuracy for POPE and average accuracy for MMVP. For MMVP, emojis represent different visual patterns used in the evaluation. The table highlights the performance improvements achieved by the CODE method compared to baselines.
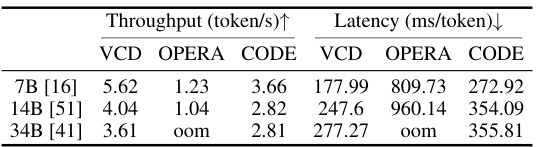
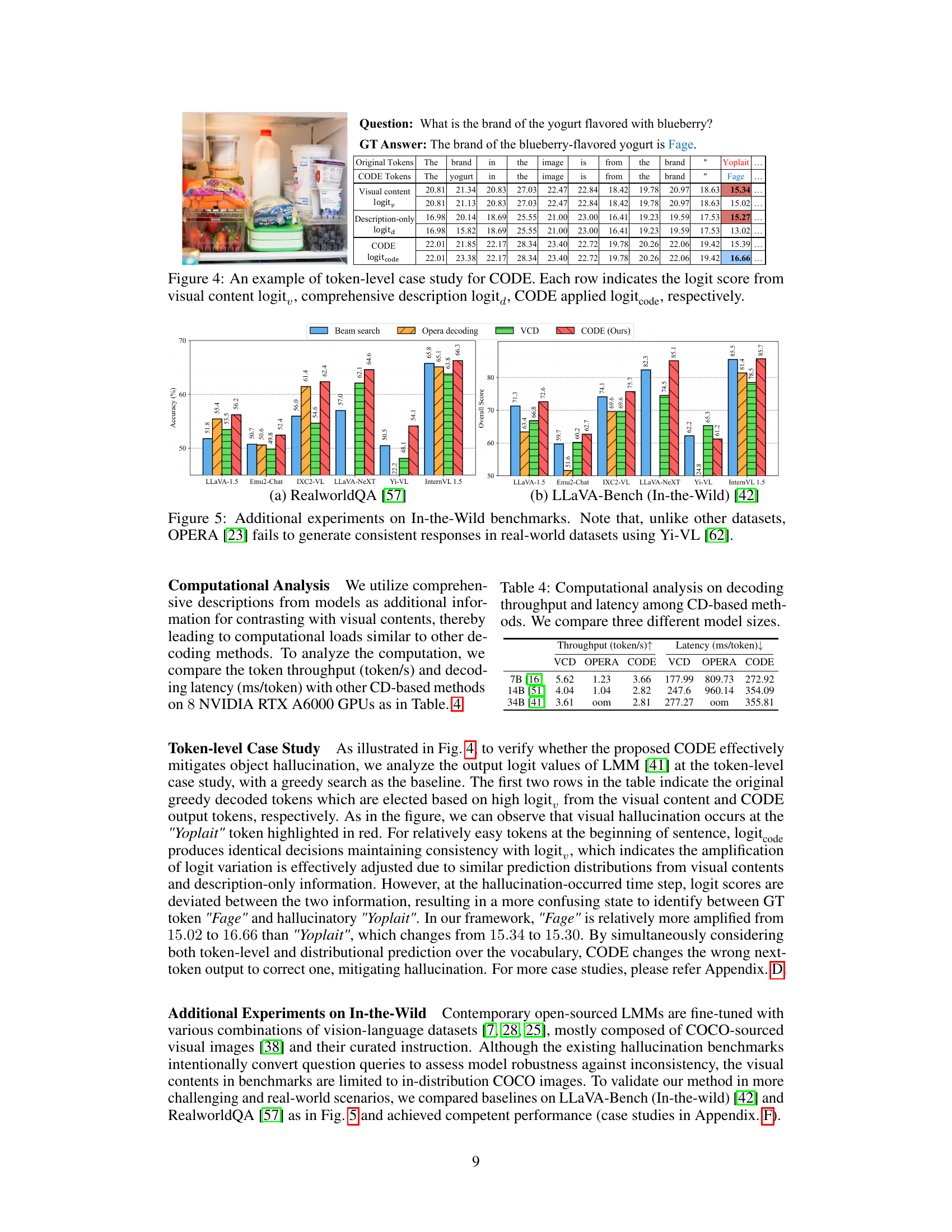
This table presents the results of a computational analysis comparing three different contrastive decoding methods (VCD, OPERA, and CODE) across three different model sizes (7B, 14B, and 34B parameters). For each model size and method, the throughput (tokens processed per second) and latency (milliseconds per token) are reported. The results show the relative efficiency of each method in terms of speed and resource utilization.

This table presents the performance of different decoding methods (Greedy, Beam, Nucleus, Opera, VCD, and CODE) on several Large Multimodal Models (LMMs) across two discriminative benchmarks: POPE and MMVP. POPE evaluates object-level hallucinations, while MMVP assesses the models’ ability to discern subtle visual differences in image pairs. The results are shown in terms of precision, F1-score, and accuracy for POPE, and accuracy for each of the nine visual patterns in MMVP, along with an average accuracy across all patterns. The table allows comparison of the proposed CODE method against standard decoding methods on various state-of-the-art LMMs.

This table presents the results of hallucination evaluation on discriminative benchmarks (POPE, MMVP) across six different Large Multi-modal Models (LMMs) and six decoding methods. Each LMM is evaluated using three metrics for POPE and multiple metrics for MMVP. The MMVP results use emojis to represent performance across nine different visual patterns, as detailed in Appendix C of the paper. The table allows for a comparison of the effectiveness of various decoding strategies in mitigating hallucinations in different LMMs.
This table presents the results of hallucination evaluation using discriminative benchmarks (POPE, MMVP) on six different Large Multimodal Models (LMMs) and six decoding methods. For each LMM and decoding method, the precision, F1 score, and accuracy are shown for the POPE benchmark, while the average accuracy across nine visual patterns are provided for the MMVP benchmark. The emoji icons in the MMVP section indicate the nine different visual patterns assessed in that benchmark, allowing for a detailed comparison of hallucination mitigation techniques across various LMM architectures and decoding strategies.
Full paper#