↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Current 3D point cloud recognition methods struggle with domain generalization—their performance drops significantly when applied to unseen data or domains. This is largely due to the overfitting of lightweight prompt tuning methods focused solely on improving task-specific performance, ignoring the underlying general knowledge encoded in large pre-trained models. This lack of generalization limits the applicability of these models in real-world applications.
Point-PRC tackles this limitation by introducing a regulation framework that explicitly guides prompt learning. This framework enforces consistency between task-specific predictions and task-agnostic knowledge from the pre-trained model. It achieves this through multiple constraints, promoting mutual agreement between the representations and predictions of both the prompt-tuned and the pre-trained model. The framework is also designed to be plug-and-play, easily integrated into existing large 3D models. Furthermore, to address the lack of systematic evaluation of 3D domain generalization, the paper introduces three new benchmarks: base-to-new, cross-dataset, and few-shot generalization, pushing the field forward. The results demonstrate the effectiveness of the proposed regulation framework, consistently improving both generalization ability and task-specific performance across various benchmarks.
Key Takeaways#
Why does it matter?#
This paper is crucial because it addresses the critical issue of domain generalization in 3D point cloud analysis, a significant challenge in applying deep learning to real-world scenarios. By proposing a novel regulation framework and introducing new benchmarks, it paves the way for more robust and generalizable 3D point cloud models, impacting various applications like autonomous driving and robotics. The new benchmarks are particularly valuable for future research, providing a more rigorous evaluation standard for 3D domain generalization.
Visual Insights#

This figure illustrates the Point-PRC framework, a prompt learning based regulation framework for generalizable point cloud analysis. It shows how the framework integrates three core components: Mutual Agreement Constraint (MAC), Text Diversity Constraint (TDC), and Model Ensemble Constraint (MEC). The framework utilizes a large pre-trained multi-modal 3D model (with a point cloud branch and text branch), interacting with learnable prompts inserted into the encoder layers of both branches. MAC aligns the features and predicted distributions between the prompts and the pre-trained model. TDC leverages diverse textual descriptions (generated by LLMs or manual templates) for enhanced generalization. MEC synthesizes predictions across different training epochs to avoid overfitting. The figure visually represents the data flow and interactions between the components and how these constraints aim to regulate the prompt learning process for improved generalization performance.
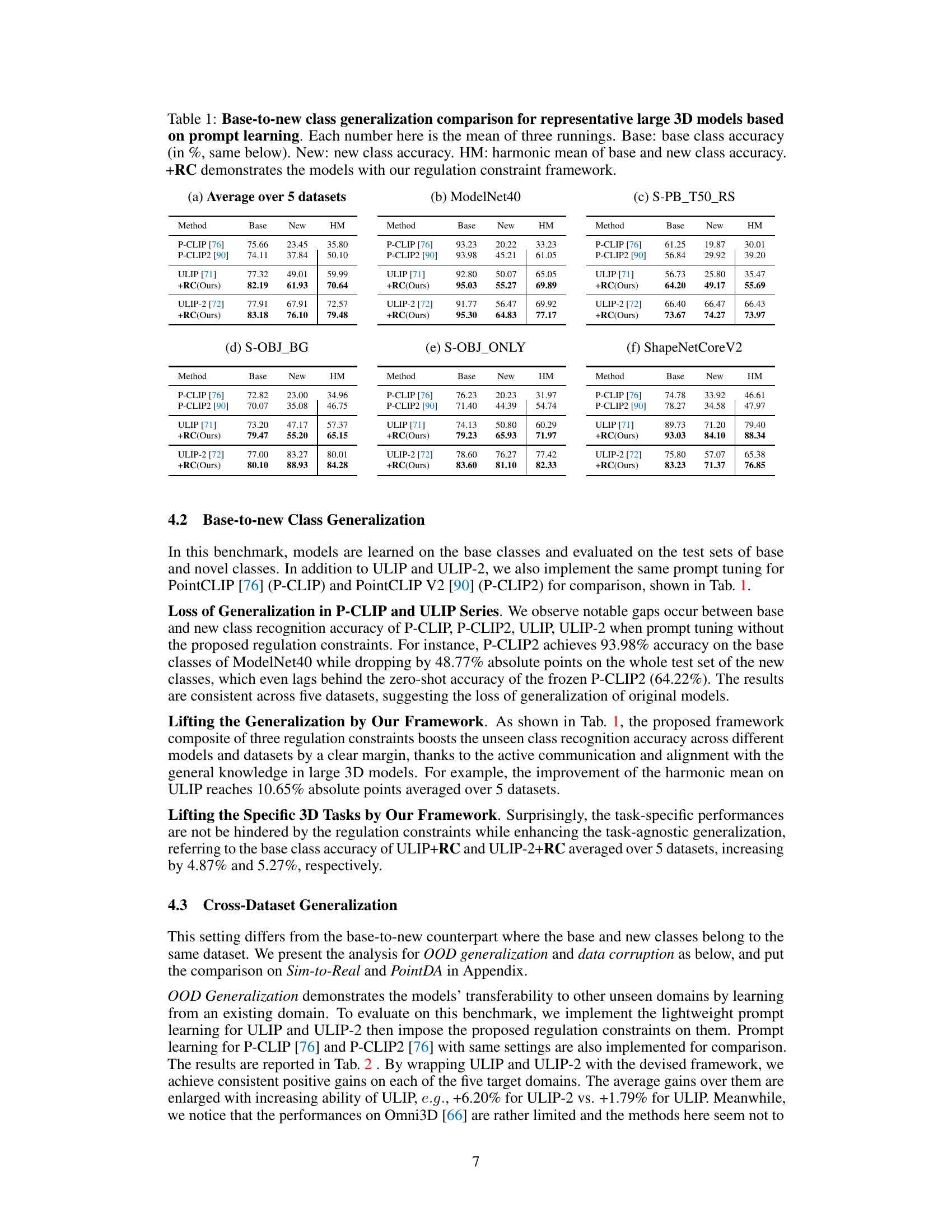
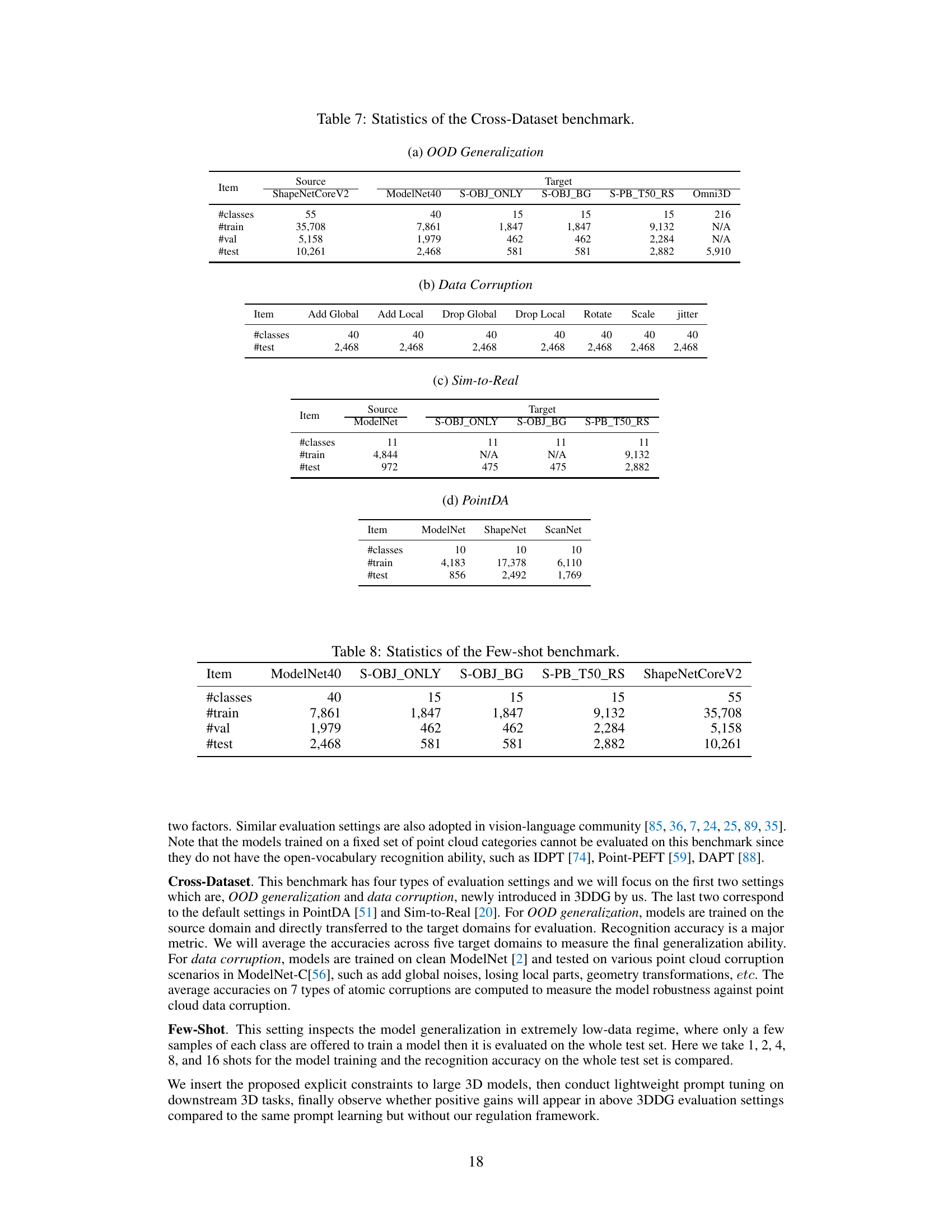
This table compares the base-to-new class generalization performance of several large 3D models using prompt learning, both with and without the proposed regulation constraint framework. The results are averaged across five datasets (ModelNet40, S-PB_T50_RS, S-OBJ_BG, S-OBJ_ONLY, ShapeNetCoreV2), showing base class accuracy, new class accuracy, and the harmonic mean of both, providing a comprehensive assessment of generalization capabilities.
In-depth insights#
Prompt Tuning 3D#
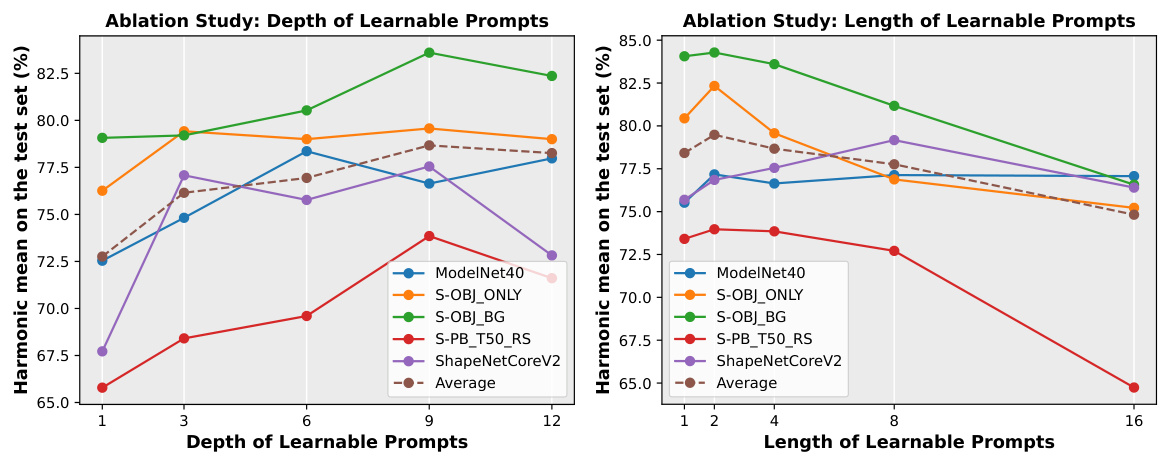
Prompt tuning in 3D point cloud analysis offers a parameter-efficient way to adapt large pre-trained models to specific downstream tasks. By inserting learnable prompts into the input or within the model architecture, it avoids the computational cost of full model fine-tuning. However, a key challenge is maintaining good generalization across different domains and tasks, as prompt tuning can lead to overfitting. Regulation techniques are crucial to balance task-specific performance gains with robust generalization. This involves explicit constraints on the prompt learning trajectory, such as maximizing mutual agreement between task-specific and task-agnostic knowledge within the model. Furthermore, incorporating diverse text descriptions can significantly improve generalization. Benchmarking progress in 3D prompt tuning requires novel evaluation metrics beyond simple accuracy, including measures of generalization across unseen domains, datasets, and few-shot learning scenarios. This field promises to accelerate the adoption of large-scale 3D models across various applications while addressing the critical issue of generalization.
3D Domain Generalization#
3D domain generalization (3DDG) tackles the challenge of building 3D models that generalize well across diverse, unseen domains. Unlike traditional approaches focused on single-domain performance, 3DDG aims for robustness and transferability. Existing methods often rely on small models and datasets, limiting their effectiveness. Parameter-efficient techniques, such as prompt tuning, offer a promising avenue, however, they can suffer from overfitting to specific tasks, hindering generalization. The lack of comprehensive benchmarks further complicates progress. Addressing these limitations requires methods that explicitly encourage interaction between task-specific learning and general knowledge within large, pre-trained models. Furthermore, new evaluation benchmarks are essential, encompassing various scenarios like few-shot learning, cross-dataset generalization, and base-to-new class generalization, to better assess true generalizability. Ultimately, 3DDG is pivotal for deploying 3D models reliably in real-world applications where the variety of domains and data characteristics are unpredictable.
Regulation Framework#
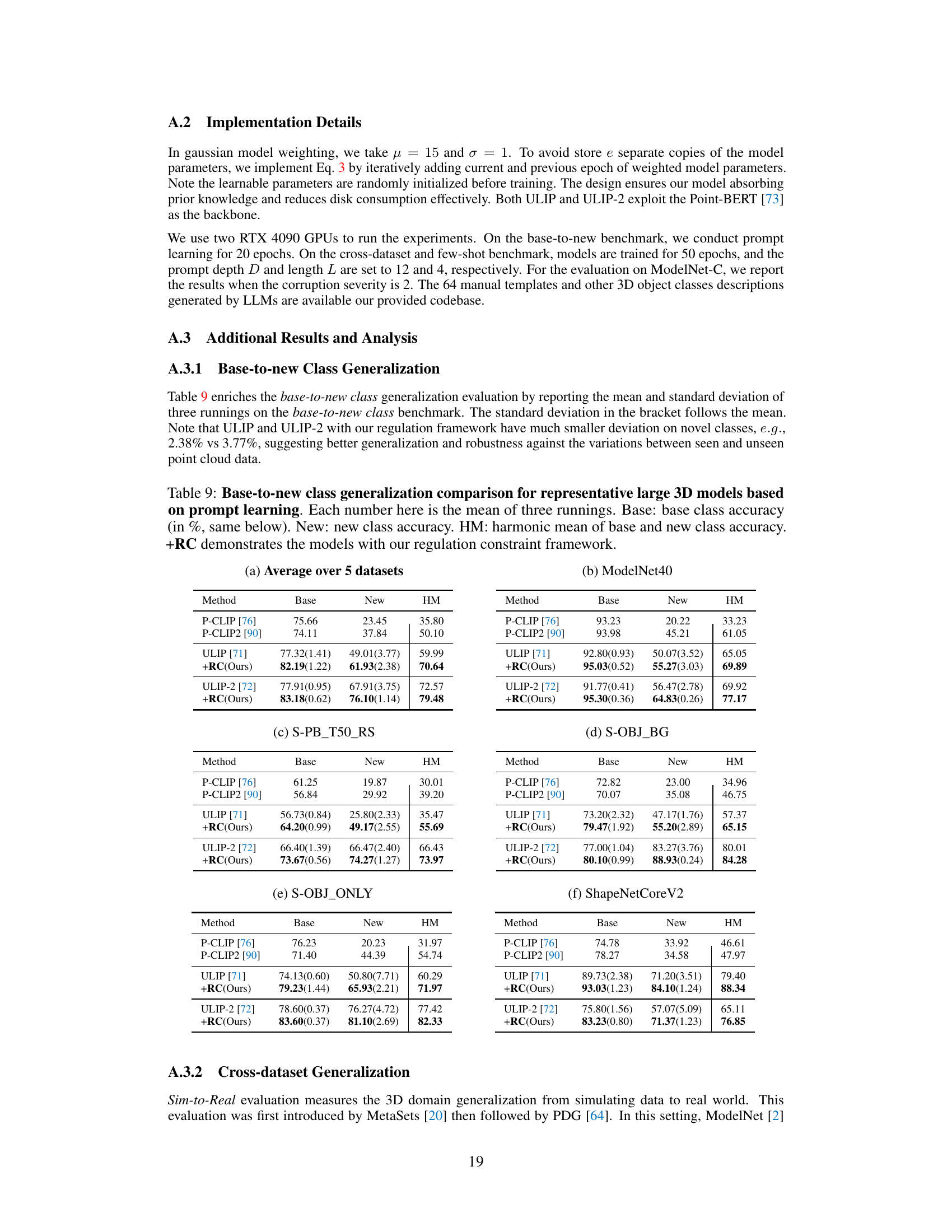
The core of this research paper centers around a novel “Regulation Framework” designed to enhance the generalizability of large 3D models in point cloud analysis. The framework directly addresses the critical issue of prompt learning’s tendency to overfit specific tasks at the expense of broader domain generalization. By imposing multiple constraints (mutual agreement, text diversity, and model ensemble), the framework guides prompt learning to maintain harmony between task-specific performance and retention of the pre-trained model’s general knowledge. This is a significant contribution as it pushes the boundaries of parameter-efficient tuning methods, avoiding the limitations of simply optimizing small modules without considering the impact on the underlying model’s broader understanding. The plug-and-play nature of this framework allows for seamless integration into existing large 3D models, highlighting its potential for widespread adoption and practical application. Furthermore, the development of new benchmarks is crucial for advancing the field of 3D domain generalization. The comprehensive evaluation demonstrates the effectiveness of the framework in improving generalization across various scenarios, a clear advancement in addressing a significant challenge for real-world applications of 3D point cloud analysis.
New 3DDG Benchmarks#
The creation of new 3D domain generalization (3DDG) benchmarks is a crucial contribution, addressing the limitations of existing datasets like PointDA and Sim-to-Real, which lack the scope to fully evaluate the generalization capabilities of large 3D models. The paper introduces three novel benchmarks: base-to-new class generalization, testing the ability to recognize unseen classes after training on a subset; cross-dataset generalization, assessing performance across different datasets with varying characteristics, including out-of-distribution (OOD) data and corrupted data; and few-shot generalization, evaluating generalization with limited training data. This multifaceted approach allows for a more comprehensive understanding of 3D model generalization. The inclusion of new benchmarks is particularly important because it enables a more rigorous evaluation and pushes future research to develop more robust and generalizable 3D models.
Future of 3DDG#
The future of 3D domain generalization (3DDG) research is ripe with exciting possibilities. Addressing the limitations of current approaches, such as their reliance on limited datasets and the overfitting to specific tasks, is crucial. Future work should focus on developing more robust methods that leverage larger, more diverse datasets and incorporate techniques that enhance model generalization. This could involve exploring new architectural designs for 3D models, developing novel training paradigms that explicitly promote generalization, or integrating advanced techniques like meta-learning and transfer learning more effectively. Furthermore, exploring different types of 3D data, beyond point clouds, and developing more comprehensive evaluation benchmarks that assess generalization across a wider range of unseen domains and challenging conditions are vital. Finally, integrating techniques from other fields, such as causal inference and domain adaptation, holds significant promise for improving the robustness and reliability of 3DDG approaches. These advancements will pave the way for more reliable and practical applications of 3D point cloud analysis across various real-world scenarios.
More visual insights#
More on figures

This figure shows the overall architecture of Point-PRC, a point cloud analysis framework that uses prompt learning with regulation constraints. It highlights three core components: the Mutual Agreement Constraint (MAC), the Text Diversity Constraint (TDC), and the Model Ensemble Constraint (MEC). MAC ensures that the learnable prompts align with the pre-trained knowledge of large 3D models, TDC leverages diverse text descriptions to enhance generalization, and MEC combines predictions from different training epochs to prevent overfitting. The figure visually represents how these components interact within the framework to improve both task-specific performance and generalization ability.
This figure shows the architecture of Point-PRC, a framework for generalizable point cloud analysis using prompt learning. It highlights three core components: Mutual Agreement Constraint (MAC), Text Diversity Constraint (TDC), and Model Ensemble Constraint (MEC). MAC ensures that the learnable prompts align with the pre-trained knowledge in large 3D models. TDC uses diverse text descriptions to improve generalization. MEC combines predictions from different model training epochs to enhance stability and avoid overfitting. The figure visually represents the interaction between these components and the overall workflow, indicating how the learnable prompts (Lp, Lt) and the distribution prediction (LD) are regulated.
More on tables

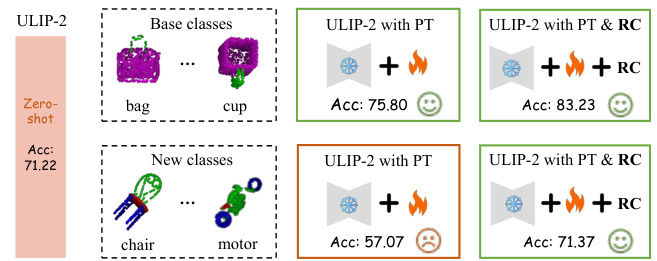
This table compares the base-to-new class generalization performance of four different large 3D models (PointCLIP, PointCLIP2, ULIP, ULIP-2) with and without the proposed regulation constraint framework (+RC). The results are averaged over five datasets (ModelNet40, S-PB_T50_RS, S-OBJ_BG, S-OBJ_ONLY, ShapeNetCoreV2). For each model and dataset, the table shows the base class accuracy, the new class accuracy, and the harmonic mean (HM) of the two. The harmonic mean provides a balanced measure of performance across both seen and unseen classes.

This table presents the base-to-new class generalization performance comparison of several prominent large 3D models using prompt learning, with and without the proposed regulation constraint framework (+RC). The results are averaged across five different datasets (ModelNet40, S-PB_T50_RS, S-OBJ_BG, S-OBJ_ONLY, ShapeNetCoreV2). For each model and dataset, the table shows the base class accuracy, new class accuracy, and the harmonic mean of these two accuracies. The harmonic mean (HM) provides a balanced measure of performance across both seen and unseen classes.
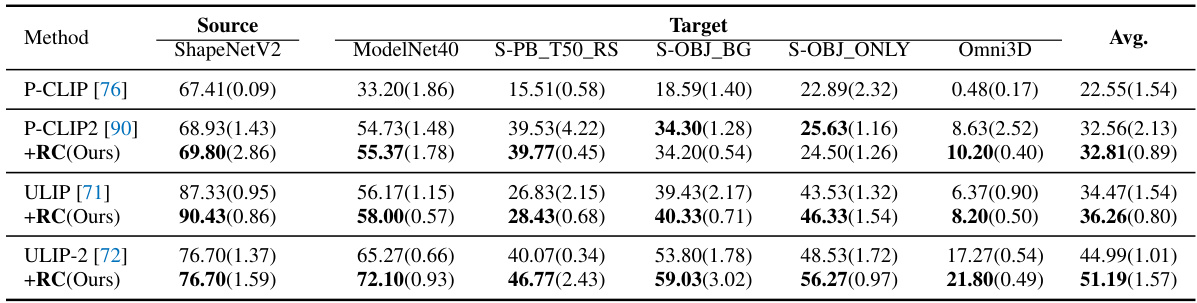
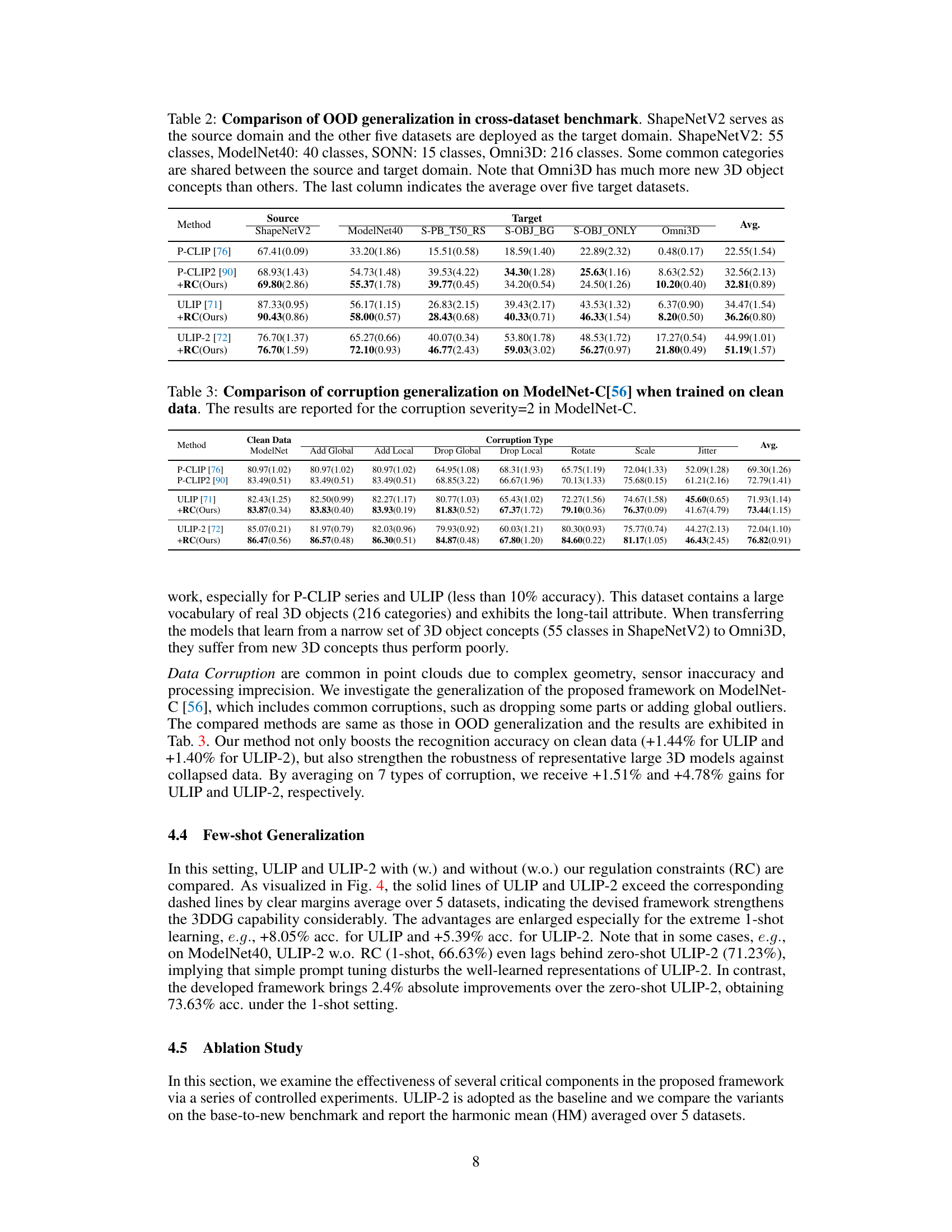
This table presents the results of the out-of-distribution (OOD) generalization experiment. The source domain is ShapeNetV2, and the target domains are ModelNet40, three variants of ScanObjectNN, and Omni3D. The table shows the performance of different methods (P-CLIP, P-CLIP2, ULIP, ULIP-2, and the proposed +RC method) on each target dataset, highlighting the impact of the proposed regulation framework on OOD generalization performance. The average performance across all target domains is also provided.

This table presents the results of corruption generalization experiments on the ModelNet-C dataset. The experiments evaluate the robustness of different models against various types of data corruptions. The table shows the performance (accuracy) of several methods on clean ModelNet data and corrupted ModelNet-C data with corruption severity level 2. The performance is reported for different corruption types such as adding global noise, adding local noise, dropping global data points, dropping local data points, rotation, scaling, and jittering. The average performance across all corruption types is also reported. This experiment aims to assess how well the models generalize to noisy and corrupted data.
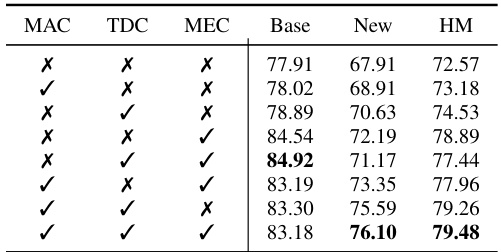
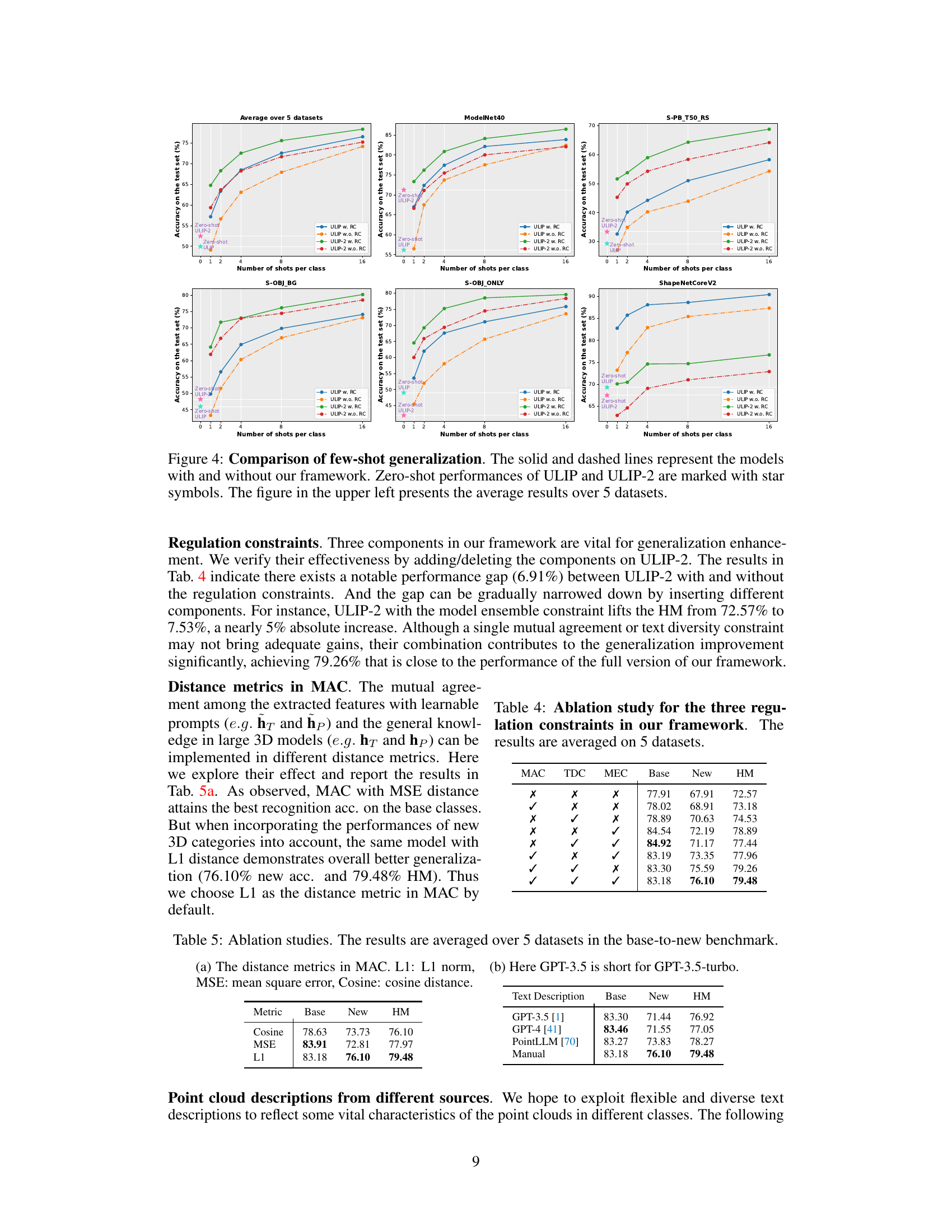
This table presents the ablation study of the three regulation constraints (MAC, TDC, and MEC) proposed in the Point-PRC framework. It shows the impact of each constraint on the model’s performance, measured by base class accuracy, new class accuracy, and their harmonic mean (HM), averaged across five datasets. The results demonstrate the effectiveness of each constraint and their combined effect on improving generalization.
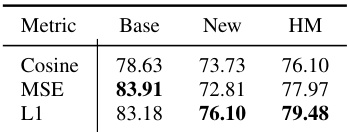
This table presents ablation study results on the proposed framework. Part (a) shows the effect of different distance metrics used in the Mutual Agreement Constraint (MAC) component on the base, new, and harmonic mean (HM) accuracies. Part (b) shows a comparison of using different text description sources (LLMs and manual descriptions) on the same metrics.
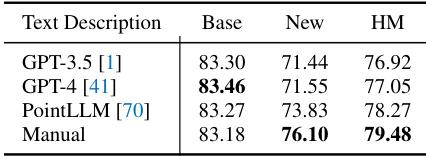
This table presents the ablation study results on two aspects: the distance metrics used in the Mutual Agreement Constraint (MAC) and the source of text descriptions used in the Text Diversity Constraint (TDC). For the MAC ablation, it compares the harmonic mean (HM) of base and new class accuracies using L1 norm, Mean Square Error (MSE), and Cosine distance. For the TDC ablation, it shows the HM using text descriptions generated by GPT-3.5, GPT-4, PointLLM, and manual descriptions. The results highlight the impact of different choices on the model’s performance in terms of base and new class accuracy and the overall HM.

This table presents the base-to-new class generalization results for several large 3D models using prompt learning, both with and without the proposed regulation constraint framework (+RC). It shows the base class accuracy, new class accuracy, and their harmonic mean (HM) across five different datasets (ModelNet40, S-PB_T50_RS, S-OBJ_BG, S-OBJ_ONLY, ShapeNetCoreV2). The results demonstrate the impact of the regulation framework on improving generalization to unseen classes.

This table presents the results of out-of-distribution (OOD) generalization experiments on five different datasets (ModelNet40, S-OBJ_ONLY, S-OBJ_BG, S-PB_T50_RS, Omni3D), using ShapeNetCoreV2 as the source domain. It shows the performance (accuracy) of different methods (P-CLIP, P-CLIP2, ULIP, ULIP-2, and the proposed method (+RC)) on each target dataset. The table highlights the improvement in OOD generalization achieved by the proposed method, particularly on datasets with significantly different characteristics from the source domain.

This table presents the results of corruption generalization experiments using ModelNet-C dataset with corruption severity level 2. It compares the performance of different methods (P-CLIP, P-CLIP2, ULIP, ULIP-2, and their respective versions with the proposed regulation constraint framework) across various corruption types (Add Global, Add Local, Drop Global, Drop Local, Rotate, Scale, Jitter). The table shows the average accuracy for each method across different types of corruptions. This helps in understanding the robustness and generalization capabilities of different models in the face of noisy or corrupted data.
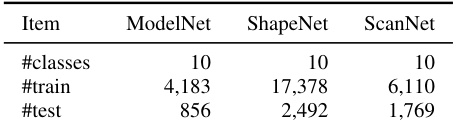
This table compares the cross-dataset generalization performance of different methods on the PointDA benchmark. PointDA consists of six domain adaptation settings, each involving transferring knowledge from a source dataset to a target dataset. The table shows the accuracy of different methods (including the proposed method) across these settings, with ModelNet (M), ShapeNet (S), and ScanNet (S*) as the source and target datasets. The results highlight the relative performance gains achieved by the proposed method compared to prior state-of-the-art methods.
This table presents the results of the out-of-distribution (OOD) generalization experiment. The source domain is ShapeNetV2, and five other datasets are used as target domains. The table shows the performance of several methods (P-CLIP, P-CLIP2, ULIP, ULIP-2, and the proposed method) on each target domain, highlighting the impact of the proposed regulation framework on OOD generalization. The average performance across all target datasets is also provided.

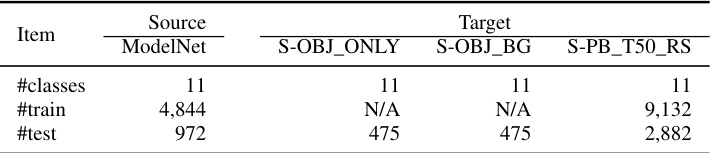
This table presents the number of classes, training samples, validation samples, and testing samples for each of the five datasets used in the Base-to-New class generalization benchmark. The datasets are ModelNet40, three variants of ScanObjectNN (S-PB_T50_RS, S-OBJ_BG, S-OBJ_ONLY), and ShapeNetCoreV2. The table provides a detailed breakdown of the data distribution used for evaluating the base-to-new class generalization performance of the models.
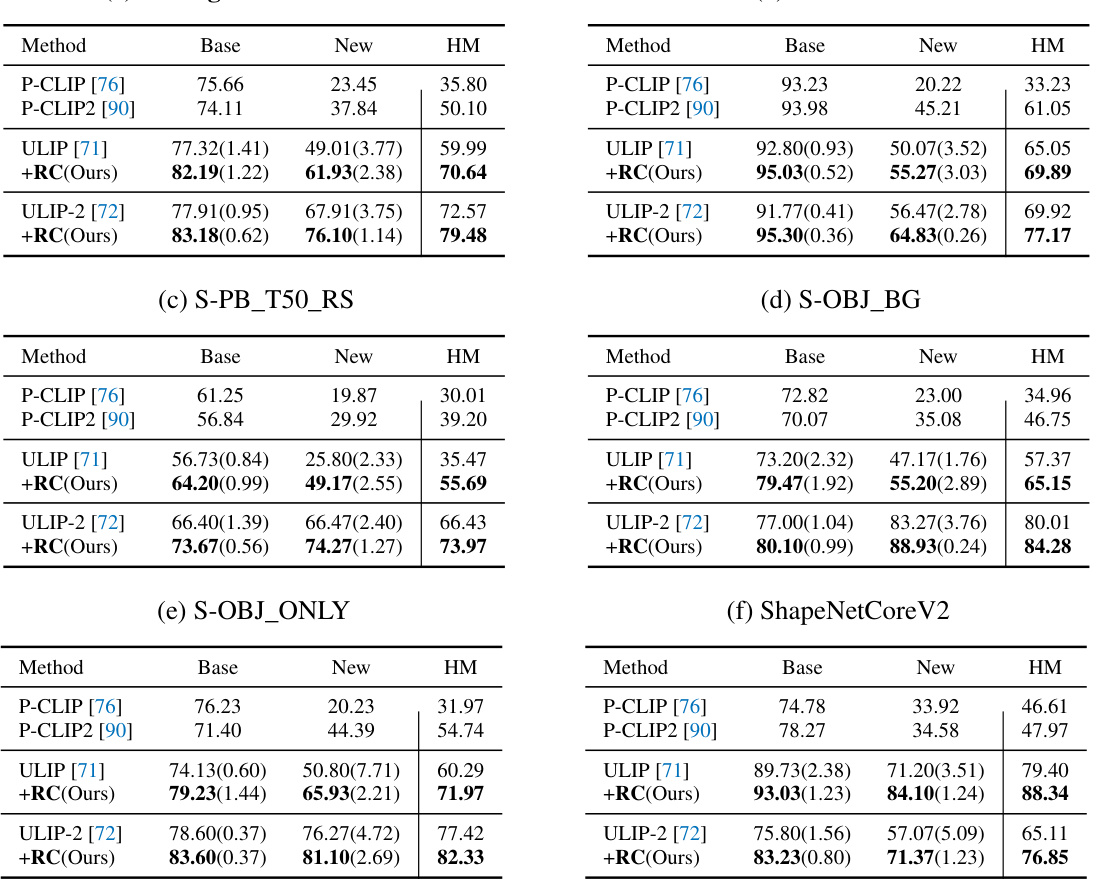
This table presents the results of the base-to-new class generalization experiment. It compares the performance of several large 3D models (PointCLIP, PointCLIP2, ULIP, ULIP-2) with and without the proposed regulation constraint framework (+RC). The table shows the base class accuracy (accuracy on seen classes), new class accuracy (accuracy on unseen classes), and the harmonic mean (HM) of both, which balances performance on seen and unseen classes. The results are averaged over five different datasets (ModelNet40, S-PB_T50_RS, S-OBJ_BG, S-OBJ_ONLY, ShapeNetCoreV2). The numbers represent the average of three runs for each model and dataset.

This table presents a comparison of base-to-new class generalization performance across several prominent large 3D models using prompt learning. It shows the base class accuracy (accuracy on seen classes), new class accuracy (accuracy on unseen classes), and the harmonic mean (HM) of these two accuracies, both with and without the proposed regulation constraint framework (+RC). The results are averaged over five datasets (ModelNet40, S-PB_T50_RS, S-OBJ_BG, S-OBJ_ONLY, ShapeNetCoreV2).
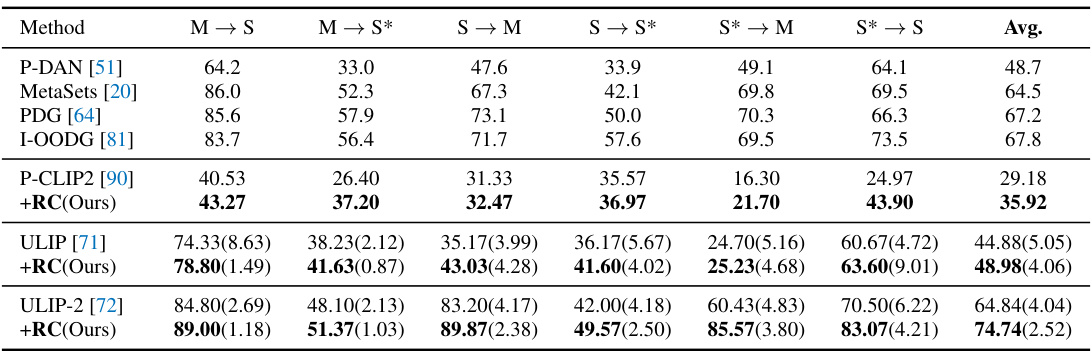
This table presents the results of the cross-dataset generalization experiment. ShapeNetV2 is used as the source domain, and five other datasets (ModelNet40, ScanObjectNN (three variants), and Omni3D) serve as target domains. The table shows the performance (accuracy) of various methods on each target dataset, highlighting the ability of the proposed method to generalize to unseen domains. The table also notes that Omni3D contains significantly more new object categories compared to other datasets.
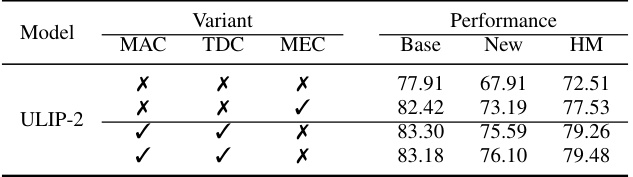
This table presents the ablation study results for the proposed Point-PRC framework. It shows the impact of each of the three regulation constraints (Mutual Agreement Constraint, Text Diversity Constraint, and Model Ensemble Constraint) on the model’s performance. The results are averaged across five datasets and reported as Base class accuracy, New class accuracy, and Harmonic Mean (HM). The table helps determine the contribution of each constraint in improving the overall accuracy and generalization ability.
This table compares the base-to-new class generalization performance of several large 3D models using prompt learning, with and without the proposed regulation constraint framework. It shows the base class accuracy, new class accuracy, and their harmonic mean (HM) across five different datasets (ModelNet40, S-PB_T50_RS, S-OBJ_BG, S-OBJ_ONLY, ShapeNetCoreV2). The results demonstrate the improvement in generalization ability achieved by incorporating the regulation constraint.

This table compares the performance of different large 3D models (PointCLIP, PointCLIP V2, ULIP, ULIP-2) on a base-to-new class generalization benchmark. The models utilize prompt learning, and the table shows base class accuracy, new class accuracy, and their harmonic mean (HM). It also shows the improvement achieved by adding a regulation constraint framework (+RC). The results are averaged across five datasets.
Full paper#