TL;DR#
Federated learning faces challenges with non-identical and independently distributed (non-IID) data across multiple nodes, leading to inconsistent model updates and reduced accuracy. Existing methods struggle to handle severe data heterogeneity effectively.
The proposed CRFed framework tackles this by introducing a diffusion-based data harmonization mechanism involving data augmentation, noise injection, and iterative denoising. It also employs a confusion-resistant strategy with an indicator function to dynamically adjust sample weights and learning rates. Extensive experiments demonstrate CRFed’s superiority over existing methods in terms of accuracy, convergence, and robustness across various non-IID settings.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in federated learning due to its novel approach to handling non-IID data, a persistent challenge in the field. It introduces a new framework that significantly improves accuracy and robustness, opening avenues for more resilient and efficient federated learning systems. The diffusion-based data harmonization technique and confusion-resistant strategies offer valuable insights for future research and development in addressing data heterogeneity issues in distributed learning environments.
Visual Insights#

🔼 This figure illustrates the challenges of federated learning with non-IID data. Panel (a) shows the FedAvg approach, where inconsistent local model updates from clients (due to heterogeneous data distributions) lead to a poorly performing global model. Panel (b) demonstrates the CRFed approach, which utilizes a data harmonization mechanism and a confusion-resistant strategy. This harmonizes local data distributions and leads to more consistent model updates across clients. The resulting global model in CRFed shows improved performance.
read the caption
Figure 1: Problem illustration of federated learning on Non-i.i.d data.
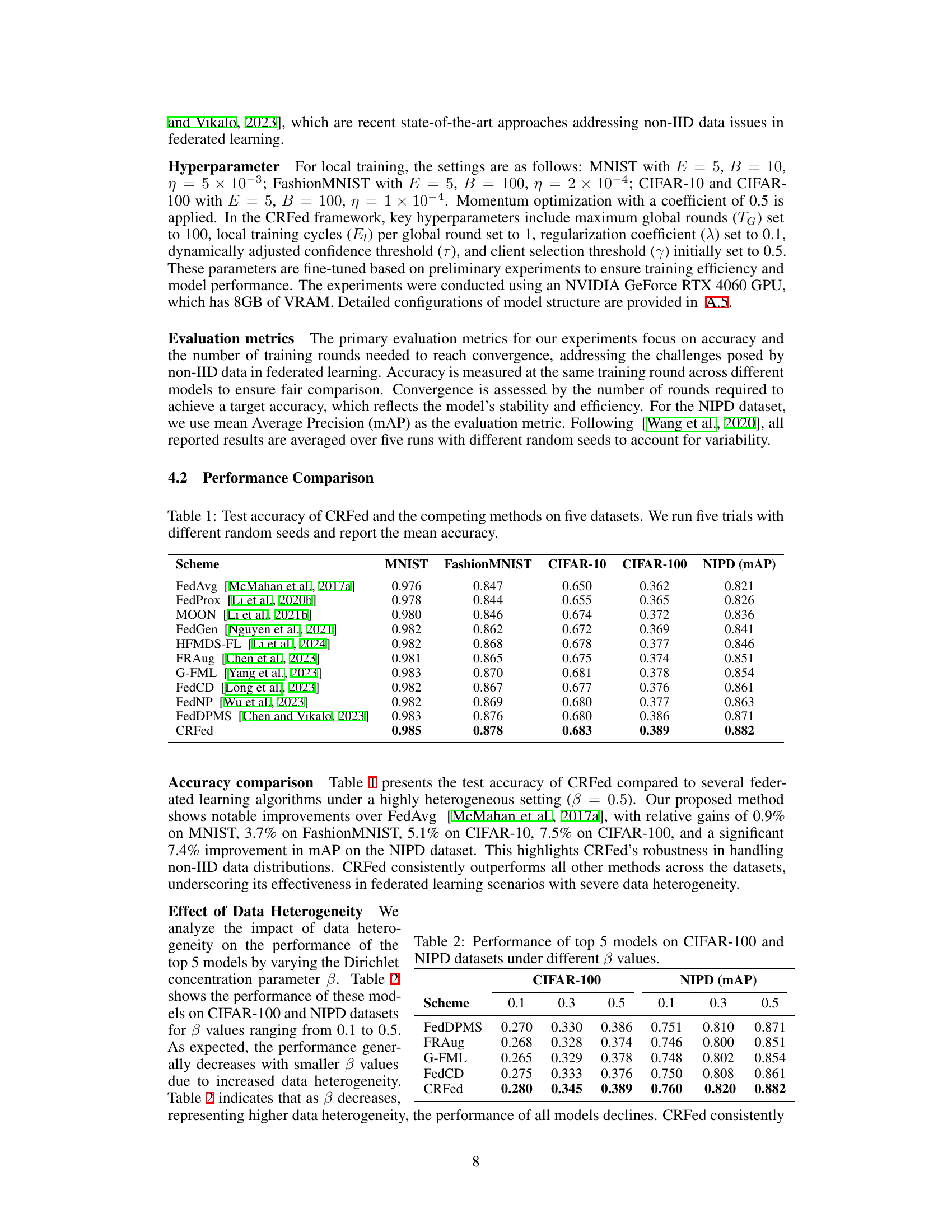
🔼 This table presents the mean test accuracy achieved by CRFed and several other federated learning algorithms across five benchmark datasets (MNIST, FashionMNIST, CIFAR-10, CIFAR-100, and NIPD). The results are averages over five independent trials with different random seeds to account for variability and provide a reliable comparison. It demonstrates CRFed’s performance in comparison to existing methods, highlighting its accuracy and robustness across diverse datasets.
read the caption
Table 1: Test accuracy of CRFed and the competing methods on five datasets. We run five trials with different random seeds and report the mean accuracy.
In-depth insights#
Non-IID FL Challenges#
Non-IID (non-identically and independently distributed) data poses significant challenges to federated learning (FL). Data heterogeneity, where data distributions vary across participating clients, leads to inconsistent model updates and reduced overall model accuracy. Communication efficiency becomes a major bottleneck as diverse models require more communication rounds to converge. Privacy concerns are amplified because data heterogeneity requires more sophisticated privacy-preserving techniques. Statistical efficiency suffers because the model might not generalize well to unseen data, particularly when dealing with small datasets. Addressing these challenges requires robust techniques to harmonize data distributions, enhance model consistency, improve communication efficiency, and maintain strong privacy guarantees. Novel approaches focusing on data augmentation, model aggregation techniques, and client selection strategies are being developed to address these issues and improve the robustness and scalability of FL systems.
Diffusion-Based Harmony#
The concept of “Diffusion-Based Harmony” in a federated learning context suggests a novel approach to address the challenges posed by Non-IID data. The core idea revolves around using diffusion models to harmonize the data distributions across various clients before model aggregation. This likely involves adding noise to the data iteratively, thereby mitigating distribution discrepancies and enhancing model consistency. The diffusion process aims to subtly shift data distributions towards a common, more uniform space, reducing the divergence among locally-trained models. This methodology presents a significant departure from other techniques that directly address Non-IID data by adjusting model parameters or sampling strategies. Diffusion-Based Harmony provides a data-centric approach, ensuring that model updates are more aligned across clients before they reach the server for aggregation. This potentially leads to improved model accuracy, faster convergence, and enhanced robustness in federated learning systems significantly affected by data heterogeneity. The key lies in the iterative denoising processes that align the data before performing global model updates, reducing the impact of inconsistent local models.
CRFed Framework#
The CRFed framework, central to the research paper, presents a novel approach to confusion-resistant federated learning. It tackles the challenges of non-IID data in federated learning by introducing a diffusion-based data harmonization mechanism. This mechanism uses iterative noise injection and denoising to align local data distributions, improving model consistency and robustness. A key component is the indicator function, which dynamically adjusts sample weights based on loss values and uncertainties, prioritizing more difficult samples. This self-paced learning approach, combined with a strategic client selection method, ensures that model updates are robust and aligned across different nodes. The framework’s effectiveness is showcased through extensive experiments on benchmark datasets demonstrating improved accuracy, convergence speed, and overall robustness in handling severe data heterogeneity. The combination of diffusion-based harmonization, intelligent client selection and adaptive learning rate adjustment allows CRFed to address inconsistencies inherent in standard FedAvg approaches to federated learning.
Robustness & Speed#
A robust and fast federated learning system is a crucial goal. This paper’s approach focuses on enhancing both robustness and speed, tackling the challenge of non-IID data which often leads to performance degradation and slow convergence in federated learning. The proposed framework, CRFed, employs a diffusion-based data harmonization method to address data heterogeneity across clients. This technique improves model consistency by reducing data distribution disparities. A confusion-resistant strategy complements this, mitigating the adverse effects of heterogeneity and model inconsistency via a dynamic sample weighting mechanism and adaptive learning rate adjustment. Experimental results demonstrate that CRFed significantly outperforms existing methods in terms of accuracy and convergence speed, showcasing its effectiveness in handling diverse and challenging non-IID scenarios. The key to CRFed’s success lies in its ability to adapt and self-pace; dynamically adjusting to data difficulties to promote efficient and reliable convergence.
Future of CRFed#
The Confusion-Resistant Federated Learning via Consistent Diffusion (CRFed) framework shows significant promise. Future development should focus on enhancing its scalability and efficiency, particularly for extremely large-scale federated learning scenarios with many heterogeneous clients. Addressing the computational overhead of the diffusion process is crucial. Exploring alternative diffusion models or approximation techniques could significantly improve performance. Another promising area is improving the robustness of the indicator function and meta-model by making them more adaptive to highly skewed and noisy data distributions. Investigating the impact of different noise injection strategies and denoising processes could lead to better harmonization and convergence. Finally, rigorous theoretical analysis of CRFed’s convergence properties and generalization capabilities under diverse non-IID settings would further establish its credibility and guide future enhancements. Specifically, formal bounds on convergence rates and generalization error would strengthen the theoretical foundation.
More visual insights#
More on figures
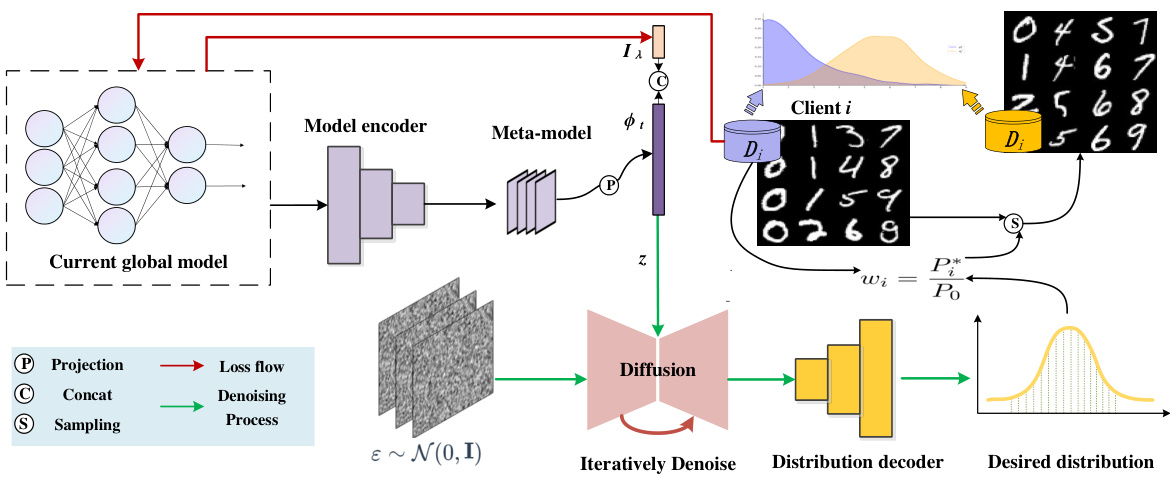
🔼 The figure illustrates the CRFed framework, outlining the workflow of model encoding, meta-model generation, data harmonization via diffusion, and client data sampling based on importance weights. It shows how the global model is processed, combined with indicator function, and used to guide the sampling process that leads to enhanced model performance.
read the caption
Figure 2: CRFed Framework. The process begins with the current global model, which is downloaded by clients. The model encoder processes the global model, and the meta-model is obtained. This meta-model is then projected into a higher-dimensional space and concatenated with the indicator function, forming the combined representation zi. The diffusion-based data harmonization mechanism adds noise to this representation and iteratively denoises it to achieve the desired distribution. The distribution decoder then aligns the denoised data distribution. Client i's data is sampled based on importance sampling weights wi, calculated as the ratio of the optimal sampling probability P* to the original data distribution Po. This ensures that the sampled data aligns with the desired distribution, following a curriculum learning approach that progresses from easy to difficult samples, thus enhancing overall model performance.
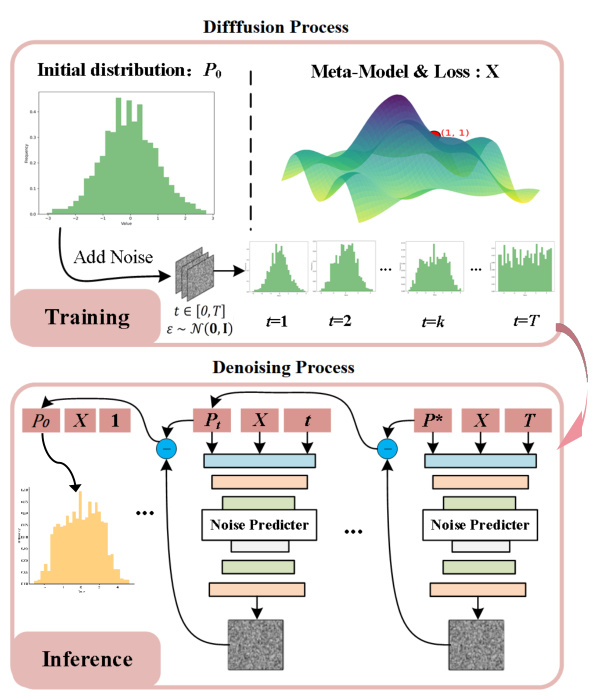
🔼 This figure illustrates the diffusion-based data harmonization mechanism used in the CRFed framework. It’s a two-stage process: 1. Forward Diffusion: Gaussian noise is iteratively added to the initial data distribution (P₀) over a series of timesteps (t = 1…T). This transforms the data into a latent representation. 2. Reverse Denoising: A noise predictor network learns to iteratively remove the added noise, starting from the final noisy representation (at t=T) and working backward to t=1. The goal is to refine the data distribution to a desired target distribution (P*). The process uses the model encoder and meta-model (from Figure 2), along with indicator function, to guide this denoising process.
read the caption
Figure 3: The diffusion-based data harmonization mechanism in CRFed framework. The process involves a forward diffusion process where Gaussian noise is added to the initial data distribution, transforming it into a latent representation. This is followed by a reverse denoising process that iteratively removes the noise, aligning the data distribution with the desired target distribution.

🔼 This figure shows the test accuracy of the top 5 performing models (CRFed, FedDPMS, G-FML, FRAug, FedCD) across federated training rounds for three different datasets: FMNIST, CIFAR-10, and CIFAR-100. It demonstrates the convergence speed and overall accuracy of each model on these datasets, highlighting CRFed’s superior performance and faster convergence.
read the caption
Figure 5: Test accuracy across federated training rounds for top 5 models on FMNIST, CIFAR-10, and CIFAR-100 datasets.
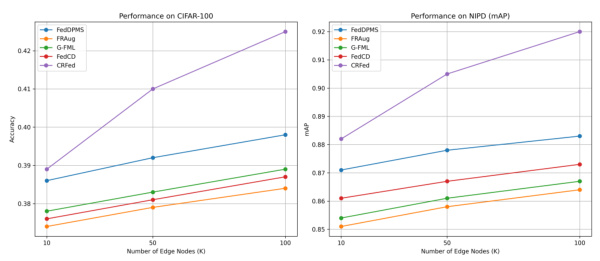
🔼 This figure shows the performance of the top 5 models (CRFed, FedDPMS, FRAug, G-FML, FedCD) on CIFAR-100 and NIPD datasets as the number of edge nodes (K) increases from 10 to 100. It illustrates how model performance changes with a varying number of participating nodes in a federated learning setting. The x-axis represents the number of edge nodes, while the y-axis shows the accuracy for CIFAR-100 and mean Average Precision (mAP) for NIPD. The figure demonstrates the scalability and effectiveness of CRFed compared to other methods, showing its ability to handle a larger number of participating clients.
read the caption
Figure 4: Effect of Increasing Edge Nodes
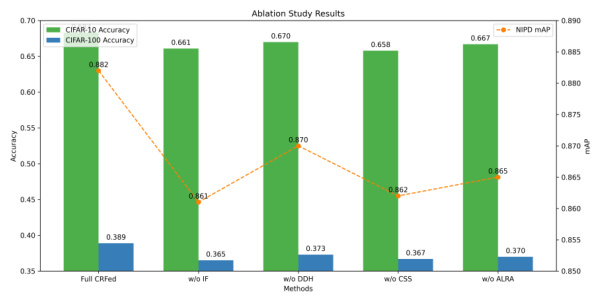
🔼 This ablation study shows the impact of removing or modifying specific components of the CRFed framework. The figure displays the performance (accuracy for CIFAR-10 and CIFAR-100 and mAP for NIPD) when removing the indicator function (w/o IF), diffusion-based data harmonization (w/o DDH), client selection strategy (w/o CSS), and adaptive learning rate adjustment (w/o ALRA). The results demonstrate the importance of each component in achieving the overall strong performance of the CRFed model.
read the caption
Figure 6: Ablation study results on CIFAR-10, CIFAR-100, and NIPD datasets. The bar charts show the accuracy on CIFAR-10 and CIFAR-100 datasets, while the line plot represents the mAP on the NIPD dataset.
More on tables
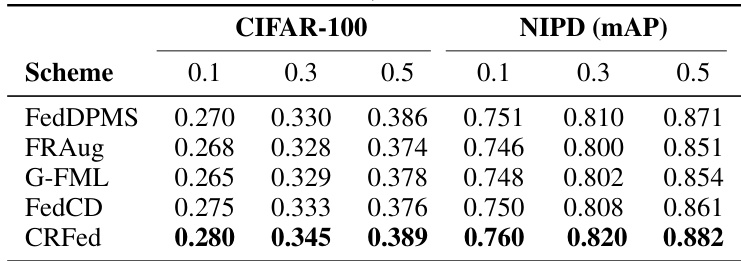
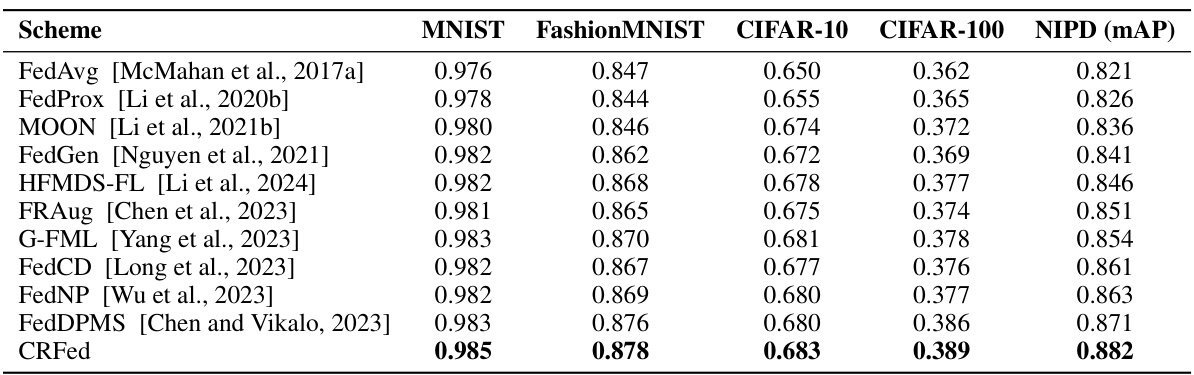
🔼 This table presents the performance comparison of the top 5 models (FedDPMS, FRAug, G-FML, FedCD, and CRFed) on CIFAR-100 and NIPD datasets under different values of the Dirichlet concentration parameter β (0.1, 0.3, and 0.5). The parameter β controls the level of data heterogeneity, with smaller values indicating higher heterogeneity. The table shows the test accuracy for CIFAR-100 and mean Average Precision (mAP) for NIPD. It demonstrates how the performance of each model varies under different levels of data heterogeneity.
read the caption
Table 2: Performance of top 5 models on CIFAR-100 and NIPD datasets under different β values.
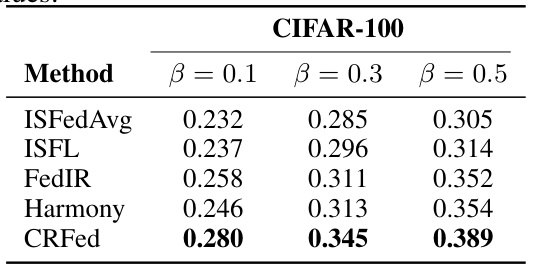
🔼 This table compares the performance of several importance sampling methods (ISFedAvg, ISFL, FedIR, Harmony) and the proposed CRFed method on the CIFAR-100 dataset under different levels of data heterogeneity (β = 0.1, 0.3, 0.5). It demonstrates CRFed’s superior performance compared to existing importance sampling techniques in handling non-IID data in federated learning.
read the caption
Table 3: The performance of different importance sampling methods on CIFAR-100 under various β values.

🔼 This table presents the mean test accuracy of the proposed CRFed model and several other federated learning algorithms across five benchmark datasets (MNIST, FashionMNIST, CIFAR-10, CIFAR-100, and NIPD). The results are averaged over five independent trials with different random seeds to assess the statistical reliability of the performance comparison.
read the caption
Table 1: Test accuracy of CRFed and the competing methods on five datasets. We run five trials with different random seeds and report the mean accuracy.
🔼 This table presents the test accuracy achieved by CRFed and several other federated learning algorithms on five benchmark datasets (MNIST, FashionMNIST, CIFAR-10, CIFAR-100, and NIPD). The results are averaged over five independent trials, each using different random seeds, to showcase the robustness of the models and reduce the impact of randomness on the results. The table highlights CRFed’s superior performance compared to existing state-of-the-art methods, demonstrating its effectiveness in handling the challenges of non-IID data in federated learning scenarios.
read the caption
Table 1: Test accuracy of CRFed and the competing methods on five datasets. We run five trials with different random seeds and report the mean accuracy.
Full paper#