↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Large Language Models (LLMs) are computationally expensive, largely due to the Multi-Head Attention (MHA) mechanism. Existing optimization methods often sacrifice performance or require extensive retraining. This research addresses these limitations. The paper focuses on the redundancy within MHA’s heads.
The researchers propose Decoupled-Head Attention (DHA), a novel method that adaptively configures group sharing for key and value heads across different layers. They achieve this by transforming existing MHA checkpoints into the DHA model, leveraging the parametric knowledge of the original model via linear fusion. Experimental results show that DHA requires significantly less pre-training than existing approaches while achieving high performance, resulting in substantial savings in both computational resources and training time.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on large language models (LLMs) due to its significant efficiency improvements. It offers a novel approach to reduce the computational and memory costs associated with LLMs’ attention mechanisms, which is a major bottleneck in their deployment and scalability. By offering practical solutions for resource reduction and providing a path for future research, this study can accelerate LLM development and broaden access to AI technologies.
Visual Insights#
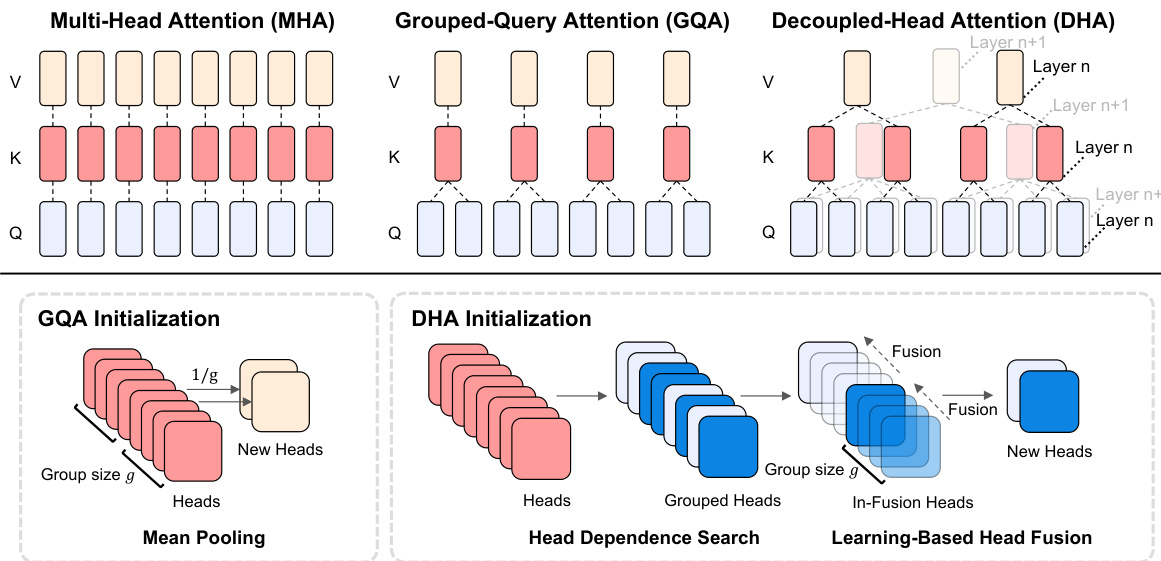
This figure illustrates the difference between three attention mechanisms: Multi-Head Attention (MHA), Grouped-Query Attention (GQA), and Decoupled-Head Attention (DHA). The upper part shows the architectural differences, highlighting how query, key, and value heads are arranged and shared in each method. MHA has independent heads, GQA groups query heads and shares key/value heads within each group, and DHA allows for different key/value head sharing patterns across different layers. The lower part explains the initialization process for GQA and DHA. GQA uses simple mean pooling for initialization, whereas DHA employs a more sophisticated approach that searches for groups of similar heads and progressively fuses them to preserve functionality.

This table presents a comprehensive evaluation of the DHA and GQA models’ performance across various downstream tasks, including commonsense reasoning, reading comprehension, and language modeling. It compares models of different sizes (LLaMA2-7B, Sheared-LLaMA-2.7B, Sheared-LLaMA-1.3B) with varying head budget ratios (50% and 25%). The results highlight DHA’s ability to achieve competitive performance while utilizing significantly fewer training resources compared to the original MHA models and the GQA baseline. The table shows scores for multiple tasks, which allows for a thorough comparison across different model architectures and resource budgets.
In-depth insights#
Adaptive Head Fusion#
The concept of “Adaptive Head Fusion” in the context of large language models (LLMs) presents a novel approach to optimize the efficiency of multi-head attention mechanisms. It intelligently leverages the inherent redundancy within the attention heads by adaptively grouping and fusing similar heads across different layers. This isn’t a blanket approach; the fusion process is data-driven, analyzing head parameter similarity to determine which heads can be safely combined without substantial performance degradation. This adaptive nature is crucial, as it avoids the pitfalls of static head pruning or parameter sharing, which often necessitate costly retraining to restore performance. The method cleverly uses a learned fusion operator, making it possible to transform an existing multi-head attention model into a more efficient decoupled-head architecture with minimal retraining. By allowing for variable head allocation across layers, it achieves a superior balance between efficiency and accuracy. The effectiveness of the adaptive fusion is demonstrated experimentally, showcasing significant reductions in computational cost and KV cache memory usage with minimal accuracy loss compared to traditional methods. The use of this approach is particularly appealing because it allows for rapid adaptation of existing LLMs and potentially improves the overall performance.
Linear Head Fusion#
Linear Head Fusion, as a core concept, aims to improve efficiency in transformer models by merging similar attention heads. This approach leverages the observation that certain attention heads exhibit redundant functionality. By linearly combining the weights of these similar heads, the model’s size is reduced without significantly compromising performance. The fusion process needs to carefully balance performance and efficiency, aiming to retain crucial information while eliminating redundancy. Adaptive methods are often employed to determine which heads to fuse and how to combine them effectively, often relying on similarity metrics to identify functionally close heads. The success of this technique depends greatly on the ability to effectively identify and fuse similar heads, avoiding information loss that can lead to performance degradation. Successful implementation requires careful analysis of head parameter characteristics and the development of robust fusion algorithms that maintain the original model’s capabilities. This method presents a powerful way to optimize transformer models, reducing computational costs and memory footprint.
DHA Model Training#
Training the Decoupled-Head Attention (DHA) model involves a multi-stage process leveraging pre-trained Multi-Head Attention (MHA) checkpoints. First, a head dependence search identifies similar head clusters within the MHA, revealing redundancy and opportunities for fusion. Then, an adaptive head fusion algorithm progressively transforms the MHA parameters into a DHA model via linear combinations, guided by an augmented Lagrangian approach to balance model performance and compression. This fusion aims to minimize information loss while efficiently reducing the parameter count. Finally, a continued pre-training phase refines the DHA model, leveraging a small portion of the original MHA’s training budget to further optimize performance and recover from information loss during fusion. The whole training process demonstrates significant efficiency gains over typical approaches, requiring substantially less compute than training from scratch while maintaining performance levels close to the original MHA model.
Ablation Study Results#
An ablation study for a large language model (LLM) focusing on efficiency improvements would systematically remove components to assess their individual contributions. Removing the linear heads fusion module would likely result in a significant performance drop, highlighting its crucial role in knowledge preservation during model compression. Similarly, removing the adaptive transformation module would likely reduce the model’s ability to allocate resources effectively across layers based on varying redundancy levels. The results would quantitatively show the impact of each component on various downstream tasks. A key finding could be that both components are essential for achieving high performance with minimal training budget and reduced KV cache usage. Training speedup could be another quantitative metric analyzed, showing the benefit of these components. This would validate the design choices in the model’s architecture by demonstrating the effectiveness of the proposed methods in enhancing efficiency and maintaining model accuracy.
Future Research#
Future research directions stemming from this Decoupled-Head Attention (DHA) work could explore several promising avenues. Extending DHA’s applicability beyond LLMs to other transformer-based architectures is crucial. Investigating the effects of different fusion functions beyond linear combinations, such as non-linear transformations or more sophisticated attention mechanisms, could significantly boost performance. A deeper investigation into the interplay between head clustering, head redundancy, and model performance is warranted. This includes examining the impact of different head-clustering algorithms and the relationship between head similarity and the effectiveness of the fusion process. Combining DHA with other model compression techniques, such as pruning or quantization, could lead to even more efficient models while maintaining accuracy. Finally, exploring the use of DHA in scenarios requiring extremely long sequences and adapting the adaptive head fusion process to handle such contexts is a significant challenge worth pursuing. These avenues of research would strengthen the theoretical underpinnings of DHA and demonstrate its wider applicability.
More visual insights#
More on figures
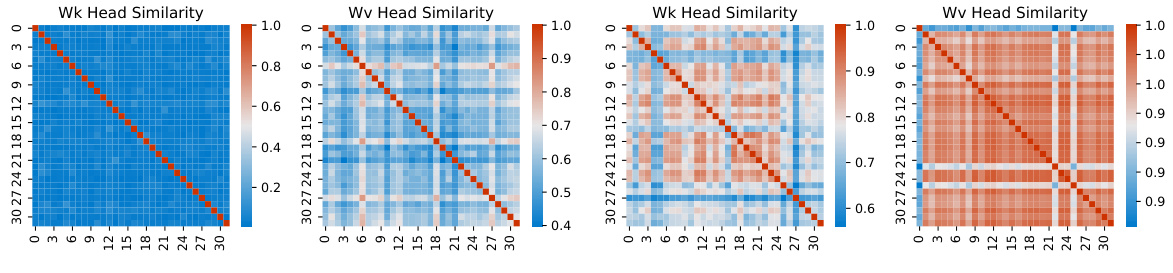
This figure visualizes the similarity between heads in the Multi-Head Attention (MHA) mechanism of the LLaMA2-7B model. Two heatmaps are shown, one for layer 0 and another for layer 21. Each heatmap represents the pairwise similarity between different heads, with warmer colors indicating higher similarity. The figure highlights that the distribution of similar head clusters (groups of highly similar heads) is different across layers and between key heads and value heads, showing a decoupled distribution. This observation motivates the design of the Decoupled-Head Attention (DHA) mechanism which allocates different numbers of key heads and value heads at different layers.

The figure shows two subfigures. Subfigure (a) presents a line graph illustrating the relationship between loss and head ratios during a 4-head fusion process, demonstrating the impact of fusing similar parameters on model performance. Subfigure (b) displays a bar chart that depicts the redundancy of query, key, and value head parameters across 32 layers of a large language model, revealing variability in redundancy across layers and between key/value pairs. These findings highlight the potential for model compression by selectively fusing similar heads across different layers and parameter types.

This figure illustrates the three stages of the Decoupled-Head Attention (DHA) model transformation from Multi-Head Attention (MHA) checkpoints. The first stage, Dependence Search, identifies groups of similar heads using multi-step optimization. The second stage, In-Group Head Fusion, initializes and optimizes fusion operators to linearly combine heads within each group, aiming to minimize the difference in functionality between the original heads and the fused head. The final stage, Post-Process, fuses the heads within groups and performs continued pre-training of the DHA model. The figure also shows the fusion loss calculation, which measures the difference between the original MHA heads and the fused DHA heads.
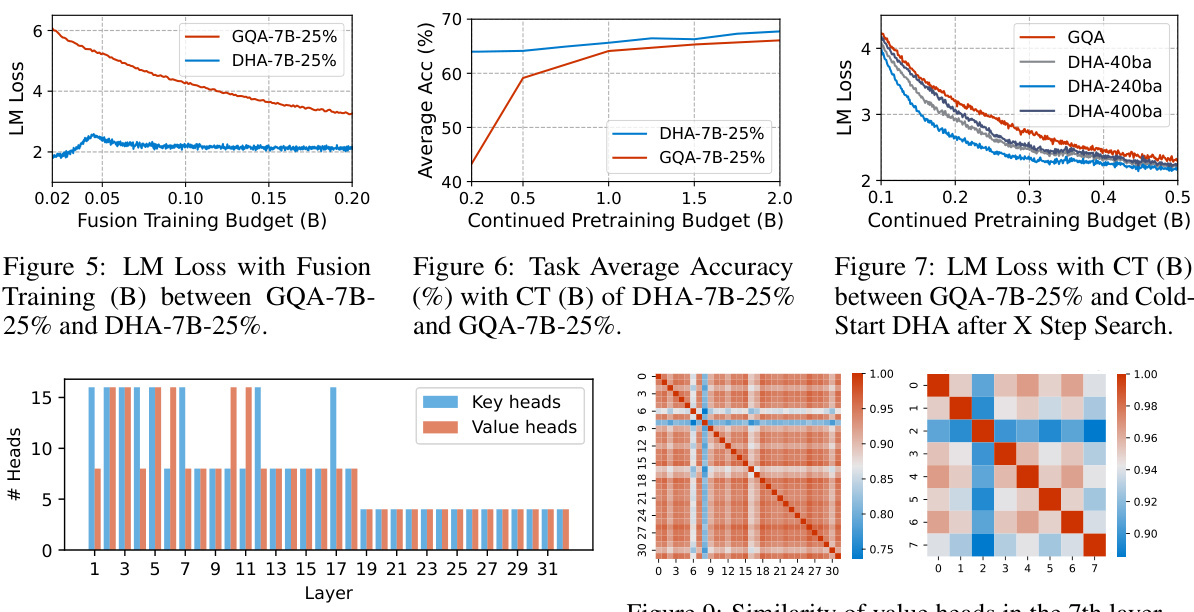
This figure shows a comparison of key and value head budget allocation in a 32-layer LLaMA2-7B model using the Multi-Head Attention (MHA) mechanism (left) versus the Decoupled-Head Attention (DHA) mechanism with a 25% head budget (right). The DHA model was obtained after 240 steps of the search process. The bar chart on the left illustrates the original even distribution of key and value heads across all layers in the MHA model. In contrast, the bar chart on the right shows the adaptive allocation of heads in the DHA model, where layers are assigned a different number of key and value heads based on the fusion loss calculation in the search stage. This adaptive allocation reflects the varying degree of redundancy found across different layers within the MHA model’s parameters.

This figure illustrates the architecture of three different attention mechanisms: Multi-Head Attention (MHA), Grouped-Query Attention (GQA), and Decoupled-Head Attention (DHA). The top part shows the general structure of each method, highlighting the different ways that query (Q), key (K), and value (V) heads are used. MHA has independent heads for Q, K, and V. GQA shares K and V heads across groups of Q heads. DHA shares K and V heads across different groups of Q heads, with the grouping potentially varying between layers. The bottom part displays how model initialization differs between GQA and DHA. GQA uses simple mean pooling to initialize its parameters while DHA employs a more sophisticated approach involving head grouping and progressive fusion to retain parametric knowledge from the original MHA checkpoint.
This figure illustrates the architecture of three attention mechanisms: Multi-Head Attention (MHA), Grouped-Query Attention (GQA), and Decoupled-Head Attention (DHA). The upper part shows a comparison of how query, key, and value heads are structured and shared in each mechanism. MHA has independent heads for each of these, GQA shares key and value heads within groups of query heads, and DHA dynamically shares key and value heads across different layers and groups of query heads. The lower part shows how each model is initialized. GQA uses mean pooling, while DHA searches for similar heads and fuses them to maintain functionality.

This figure illustrates the architecture of three different attention mechanisms: Multi-Head Attention (MHA), Grouped-Query Attention (GQA), and Decoupled-Head Attention (DHA). The upper part shows a comparison of how query, key, and value heads are structured and shared across the three methods. MHA has independent heads for query, key, and value. GQA shares key and value heads across multiple query heads. DHA is more flexible and shares key and value heads differently across layers. The lower part shows the initialization process for GQA and DHA. GQA uses a mean pooling method to create a single head from a group of heads, while DHA uses a more sophisticated process to progressively search for and fuse similar heads.

This figure illustrates the differences between three attention mechanisms: Multi-Head Attention (MHA), Grouped-Query Attention (GQA), and Decoupled-Head Attention (DHA). The top part shows the architectural differences, highlighting how MHA uses separate key, query, and value heads for each attention head, GQA shares key and value heads for a group of query heads, and DHA shares them adaptively for different groups of query heads across layers. The bottom part shows the initialization process for GQA (mean pooling) and DHA (progressive head fusion).
More on tables
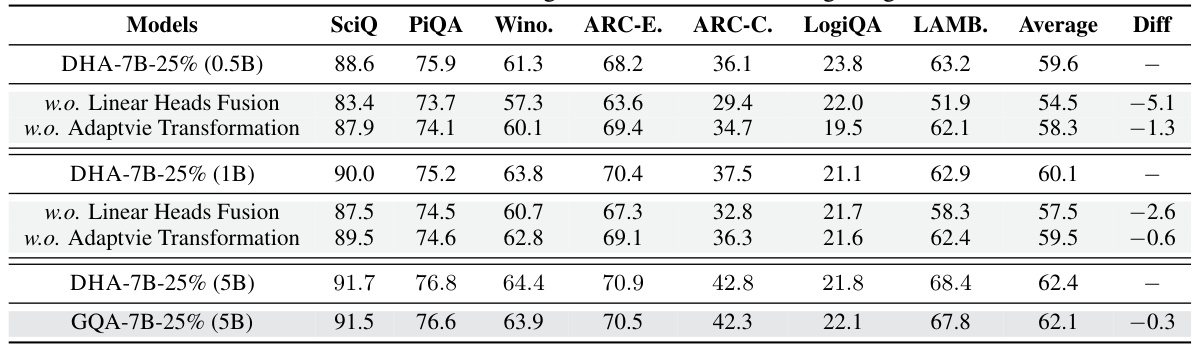
This table presents the ablation study results for the Decoupled-Head Attention (DHA) model. It shows the impact of removing the linear heads fusion and adaptive transformation components on the model’s performance. The experiments were conducted using the LLaMA2-7B model with a 25% head budget, and the results are evaluated using 0-shot evaluation on several downstream tasks. The table compares the performance of the full DHA model to versions without linear heads fusion and without adaptive transformation, revealing the contribution of each component to the overall model performance.
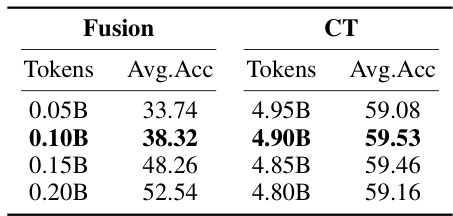
This table presents the results of an experiment investigating the impact of different budget allocations between the fusion and continued pre-training phases on the performance of a DHA-1.3B model. The model’s performance is measured using 0-shot task average accuracy. The table shows that increasing the fusion budget (while maintaining a fixed total budget of 2 billion tokens) leads to improved performance at the initialization point, indicating the importance of the fusion phase for knowledge retention. The continued pre-training phase, however, sees only minor performance changes despite the varying budget allocated.

This table presents a comprehensive evaluation of the fundamental capabilities of various LLMs, including DHA models and those using MHA. It compares their performance across multiple common sense and reading comprehension tasks, as well as language modeling (LM) tasks. The key takeaway is that DHA models achieve competitive performance with significantly lower training resource requirements compared to models using the standard MHA method.

This table presents a comprehensive evaluation of the fundamental capabilities of various language models, including those using the Decoupled-Head Attention (DHA) method and the Multi-Head Attention (MHA) method. It compares the performance across several downstream tasks (commonsense reasoning, reading comprehension, and language modeling) for different model sizes (LLaMA2-7B, Sheared-LLaMA-2.7B, and Sheared-LLaMA-1.3B) and under varying head budget and training budget conditions. The table highlights that the DHA models achieve competitive performance using significantly less training data compared to models using the MHA method.

This table presents a comprehensive evaluation of the fundamental capabilities of different model architectures across various sizes and training budgets. It compares the performance of Decoupled-Head Attention (DHA) models with different head budget ratios (50% and 25%) against Grouped-Query Attention (GQA) models and Multi-Head Attention (MHA) baselines (indicated by †) on nine representative downstream tasks, including commonsense reasoning, reading comprehension, and language modeling. The table highlights the competitive performance of DHA models while significantly reducing the training resource requirements compared to MHA and achieving faster training compared to GQA. The results demonstrate DHA’s efficiency in achieving competitive performance with a fraction of the training cost and computational resources.

This table presents a comprehensive evaluation of the DHA and GQA models’ performance across various downstream tasks, including commonsense reasoning, reading comprehension, and language modeling. It compares models of different sizes (LLaMA2-7B, Sheared-LLaMA-2.7B, and Sheared-LLaMA-1.3B) with varying head budget ratios (50% and 25%). The table highlights DHA’s ability to achieve competitive performance with significantly less training data (1B tokens vs. 2T tokens) compared to the baseline MHA models. It also shows the improvement of DHA over GQA under low-resource settings.
This table presents a comprehensive evaluation of the DHA and GQA models’ performance across various downstream tasks, including commonsense reasoning, reading comprehension, and language modeling. It compares the performance of DHA models with different head budget ratios (50% and 25%) against baseline LLaMA models and GQA models. The results are broken down by task and show that DHA consistently achieves comparable or superior performance while using significantly less training data.
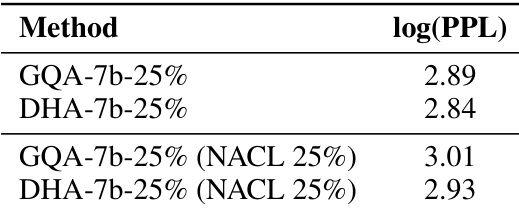
This table compares the log-perplexity (PPL) scores of GQA and DHA models, both with and without the NACL (Neural Cache Alignment) method, at a 25% compression rate. Lower PPL scores indicate better model performance. The comparison demonstrates how DHA maintains or improves performance compared to GQA, even when combined with a KV cache compression technique.

This table compares the average accuracy (Avg ACC) and perplexity (PPL) of three different methods: DHA, GQA, and GQA with CKA-based grouping, all using the LLaMA 7B model with 25% head compression and trained with 5 billion tokens. It shows that DHA achieves better results than both GQA approaches, highlighting its effectiveness in achieving a balance between efficiency and performance.
Full paper#



















