↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Object tracking, crucial in computer vision, faces challenges in handling diverse object representations and maintaining temporal consistency across video frames. Existing methods often rely on specific representations or lack efficient temporal modeling. This research tackles these issues by proposing DINTR, a novel tracking framework.
DINTR leverages the power of diffusion models for visual generation but avoids their limitations by employing a more efficient and stable interpolation mechanism. This mechanism allows seamless transitions between video frames, enabling accurate temporal modeling. The results demonstrate DINTR’s superior performance across seven benchmarks with five different types of object indications, showcasing its versatility and effectiveness.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces a novel approach to object tracking using diffusion models, addressing limitations of existing methods. It achieves superior performance on multiple benchmarks and opens new avenues for research in visual tracking, particularly in unified frameworks across various indication types. This work has significance for researchers interested in generative models, computer vision, and object tracking.
Visual Insights#
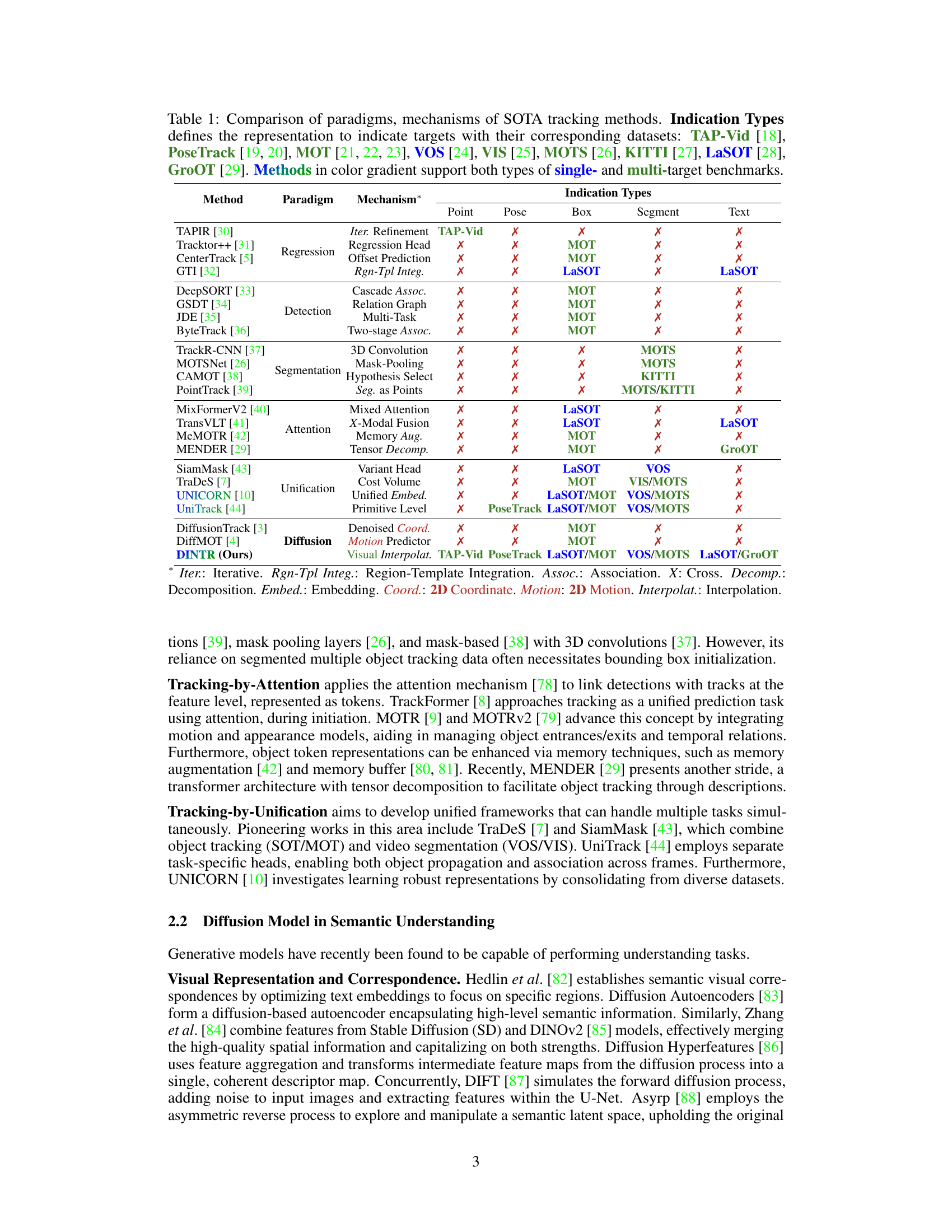
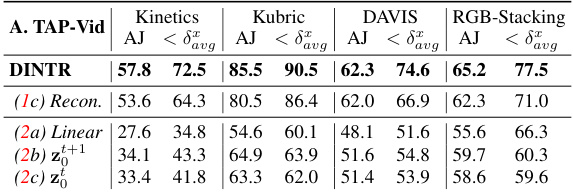
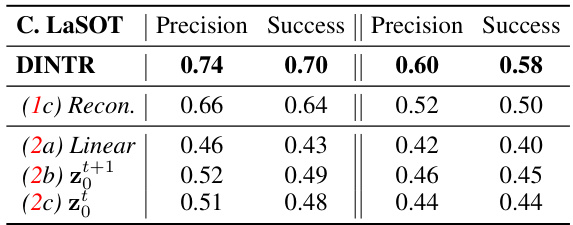
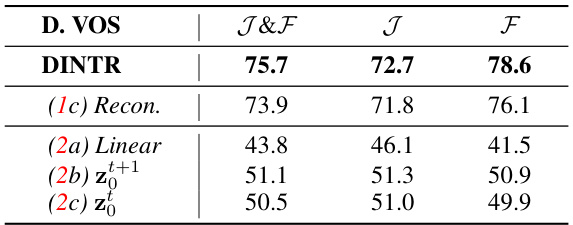
This figure illustrates different diffusion-based processes used in object tracking. (a) shows a standard probabilistic diffusion process. (b) demonstrates a diffusion process operating in 2D coordinate space, commonly used in existing tracking methods. (c) depicts a visual diffusion approach for video frame prediction. (d) introduces the authors’ proposed DINTR method, which performs interpolation between consecutive frames for improved temporal understanding and object tracking. (e) shows various object representations (points, bounding boxes, segments, and text) that DINTR can handle for object tracking.
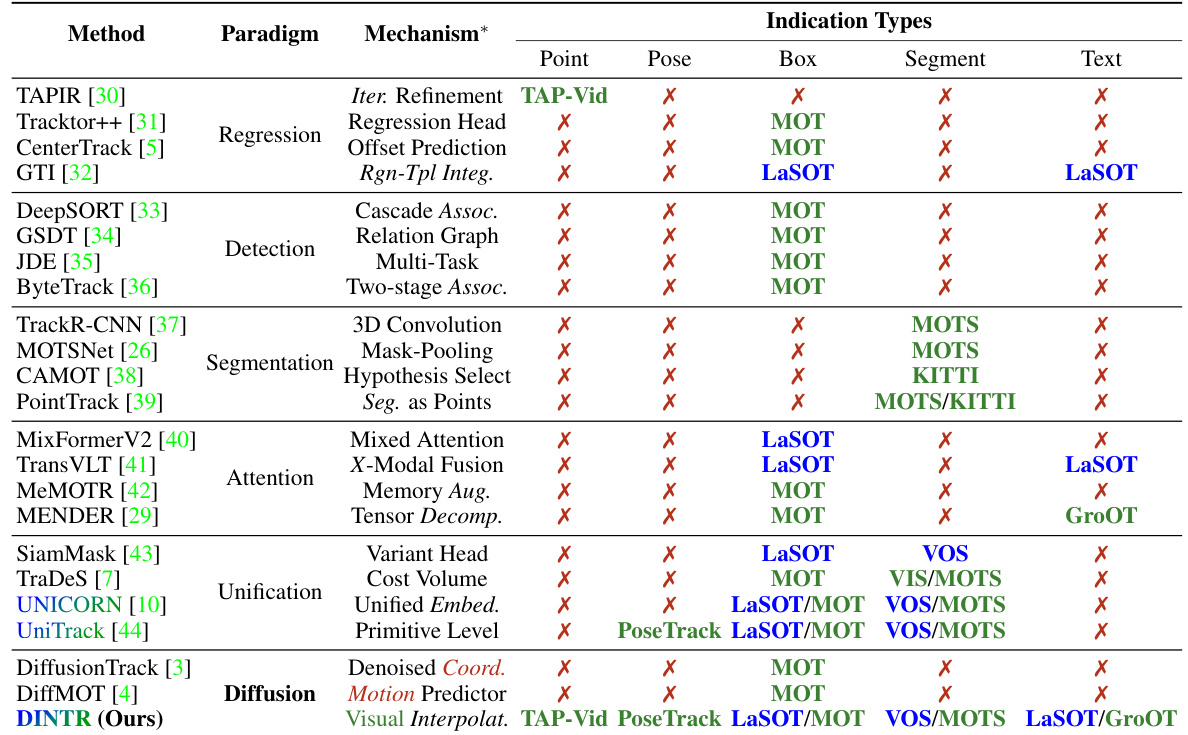
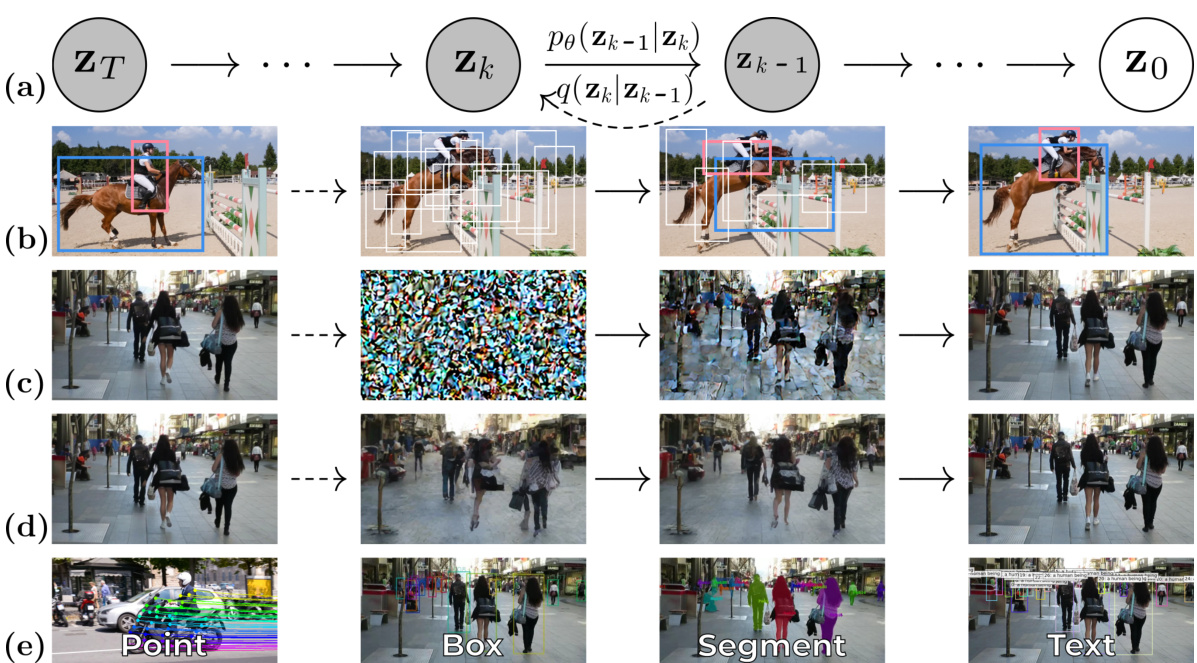
This table compares state-of-the-art (SOTA) object tracking methods across different paradigms (e.g., tracking-by-regression, tracking-by-detection, etc.). For each method, it lists the mechanism used, and whether it supports different indication types (point, pose, box, segment, text) for representing the target object. The table also indicates which benchmark datasets each method was evaluated on. Methods supporting both single and multi-target tracking are highlighted.
In-depth insights#
DiffusionTrack#
DiffusionTrack, as a conceptual framework, leverages diffusion models for object tracking. It presents a novel approach by applying diffusion processes directly to visual data. Instead of relying on intermediate representations like bounding boxes, it aims for direct prediction of object locations in subsequent frames. The core idea is to model the temporal evolution of visual features within the diffusion process, allowing the model to inherently capture temporal relationships and object motion. This method could potentially offer advantages in handling occlusions and complex motion patterns. However, it is important to consider computational costs. Diffusion models are computationally expensive; thus, the efficiency and scalability of a DiffusionTrack approach are crucial. Moreover, the performance of DiffusionTrack critically depends on the underlying diffusion model’s ability to generalize to unseen video sequences and its sensitivity to noise and hyperparameter settings. Further research is needed to explore these aspects and compare this approach to existing state-of-the-art techniques for robustness and efficiency.
Temporal Modeling#
Effective temporal modeling in video analysis is crucial for understanding dynamic scenes and events. The core challenge lies in capturing the relationships between consecutive frames, modeling motion, and predicting future states accurately. Approaches vary widely, from simple motion estimation techniques to sophisticated deep learning architectures. The choice of method often depends on the specific application and the type of data available. Some methods utilize recurrent neural networks (RNNs) which are well-suited for sequential data, but can suffer from vanishing gradients. Others employ convolutional neural networks (CNNs), often incorporating attention mechanisms to focus on relevant spatio-temporal features. Another key aspect is the representation of temporal information. Whether this is achieved via explicit modeling of motion vectors, or implicit representations through learned features is also crucial in defining the performance and efficiency. The success of any temporal modeling approach hinges on the ability to learn meaningful temporal patterns that generalize well to unseen data. Techniques like optical flow, trajectory prediction, and spatiotemporal feature extraction are commonly used to build robust and accurate temporal models. Advancements continue to push the boundaries of what’s achievable, exploring transformer networks and diffusion models to enhance the capabilities of temporal understanding in vision tasks.
Interpolation Approach#
The core idea revolves around replacing the computationally expensive Gaussian noise diffusion process with a more efficient interpolation technique borrowed from classical image processing. This shift allows for a more direct and interpretable way to model temporal correspondences in video frames. The approach is particularly well-suited for object tracking, enabling a seamless transition of visual information between frames. The key advantage is speed and stability, offering a faster and more robust approach compared to traditional diffusion methods. The authors cleverly leverage the strengths of diffusion models for conditional generation while mitigating their inherent limitations. By directly interpolating between latent representations of consecutive frames, they achieve a faster and more interpretable solution tailored for object tracking, leading to improved performance and efficiency.
Benchmark Results#
A thorough analysis of benchmark results should delve into the specific metrics employed, the datasets used, and a comparison with state-of-the-art methods. Performance gains should be clearly quantified and contextualized, noting whether improvements are consistent across different datasets or metrics. It’s crucial to discuss any limitations or weaknesses of the benchmarks themselves, acknowledging potential biases or limitations that might affect the overall interpretation of the results. Understanding the variability of the results, considering factors like random initialization or hyperparameter settings, is also key to establishing the reliability of the claims. Finally, a thoughtful discussion should connect the benchmark performance to the core contributions of the research, demonstrating the significance of the improvements within the larger context of the field.
Future Directions#
The ‘Future Directions’ section of a research paper on object tracking using diffusion models could explore several promising avenues. Extending the approach to 3D object tracking is a natural next step, requiring adaptation of the diffusion process to handle volumetric data. Another key area is improving robustness to occlusion and challenging conditions, such as low light or heavy rain, possibly through incorporating more sophisticated motion models or data augmentation techniques. Incorporating more diverse forms of object representation, beyond points, bounding boxes, and segmentation masks, such as articulated pose or detailed semantic descriptions, is another exciting direction. This could also involve exploring different data modalities and multi-modal fusion. Finally, the scalability and real-time performance of the method are crucial considerations, requiring optimizations and potential hardware acceleration to make it practical for broader deployment in applications like autonomous driving or robotics. The integration of these advancements could significantly improve the accuracy, reliability, and applicability of the approach for varied real-world scenarios.
More visual insights#
More on figures
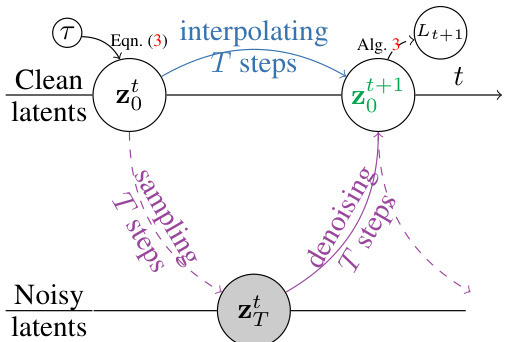
This figure illustrates the two core processes of the DINTR model: reconstruction and interpolation. The reconstruction process (purple arrows) involves a standard diffusion process where noise is added to the latent representation (z₀) and then gradually removed through denoising steps to reconstruct a clean image. The interpolation process (blue arrow) utilizes a novel mechanism that directly interpolates between two consecutive latent representations (z₀ and z₀ₜ₊₁) to predict the next frame’s latent representation. This interpolation is designed to be more efficient and stable than traditional diffusion-based approaches.
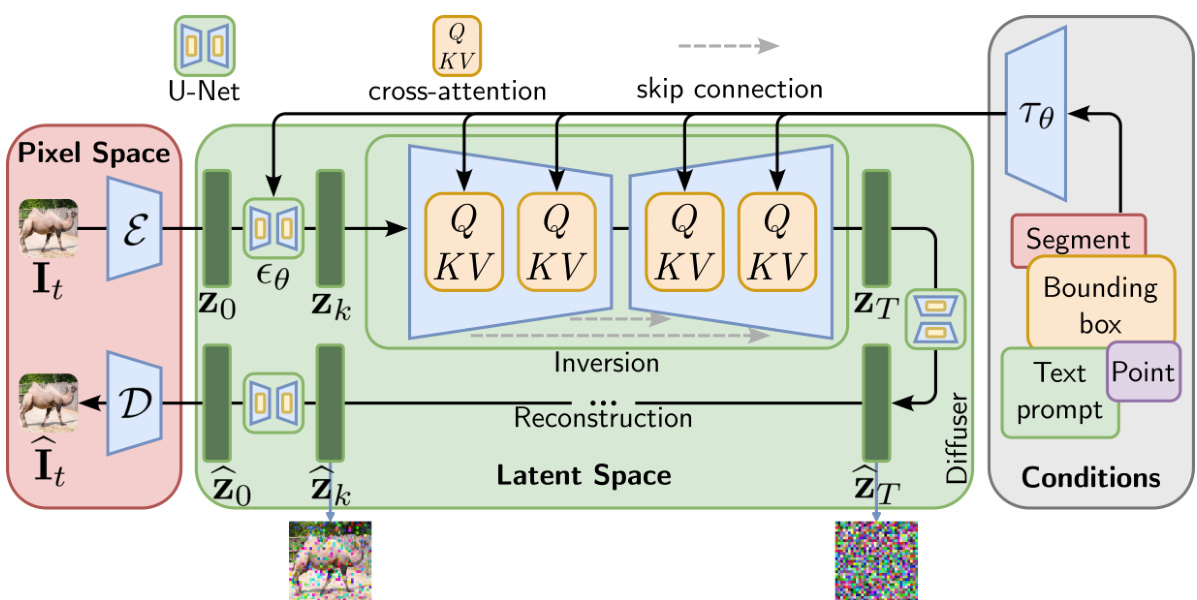
This figure illustrates the architecture of the conditional latent diffusion model (LDM) used in the paper. It shows how a clean image is converted into a noisy latent representation, then how this noisy representation is denoised and reconstructed into a clean image with well-structured regions, guided by conditional indicators. This process is detailed, showing the different blocks and branches involved. The figure highlights the key components of the LDM, such as the U-Net, the noise sampling and denoising processes, and the injection of conditions.

This figure illustrates the autoregressive framework of DINTR for temporal modeling. It shows how the current frame’s features are encoded into a latent representation, noise is added iteratively, and the reconstruction process is guided to approximate the next frame. Finally, object locations are extracted using attention maps.

This figure illustrates different diffusion-based processes used for object tracking. (a) Shows a general probabilistic diffusion process. (b) Shows a diffusion process operating on 2D coordinates. (c) Illustrates a visual diffusion approach that predicts the next frame. (d) Shows the proposed DINTR approach which interpolates between consecutive frames, enabling smooth temporal transitions and facilitating object tracking across diverse indications, shown in (e).

This figure illustrates different diffusion-based processes. (a) Shows a standard probabilistic diffusion process with noise sampling and denoising. (b) Shows a diffusion process operating in 2D coordinate space, commonly used for object tracking. (c) Demonstrates a visual diffusion method to predict the next frame in a video sequence. Finally, (d) introduces the authors’ proposed DINTR approach which interpolates between consecutive video frames to enable object tracking across various representations (e).
More on tables

This table compares state-of-the-art (SOTA) object tracking methods across different paradigms (tracking-by-regression, tracking-by-detection, etc.), mechanisms (regression, attention, etc.), and indication types (point, box, segment, text). It highlights which methods support single-target and multi-target tracking benchmarks and on which datasets they were evaluated.

This table compares different state-of-the-art (SOTA) object tracking methods based on their paradigm (e.g., regression, detection, segmentation, attention, unification), mechanism (how they work), and the types of indications they support (point, pose, box, segment, text). It also indicates which datasets each method was evaluated on. Methods supporting both single- and multi-target tracking are highlighted.

This table compares various state-of-the-art (SOTA) object tracking methods across different paradigms (e.g., tracking-by-regression, tracking-by-detection, etc.). It categorizes these methods based on their mechanisms and the types of indications they use to represent the tracked objects (points, poses, boxes, segments, text). The table also notes which datasets each method was evaluated on, highlighting methods that support both single and multi-target tracking scenarios.

This table compares state-of-the-art (SOTA) object tracking methods across different paradigms (e.g., tracking-by-regression, tracking-by-detection, etc.). It shows their mechanisms, and which indication types (point, pose, box, segment, text) they support, along with the datasets used for evaluation. The color gradient highlights methods that work for both single and multi-target tracking scenarios.
This table compares several state-of-the-art (SOTA) object tracking methods across different paradigms (e.g., tracking-by-regression, tracking-by-detection, etc.). It shows the mechanism used by each method and the types of indications (point, pose, box, segment, text) they support for indicating target objects. The table also specifies which benchmark datasets each method was evaluated on, highlighting methods that support both single and multiple target tracking.
This table compares state-of-the-art (SOTA) object tracking methods across different paradigms (e.g., tracking-by-regression, tracking-by-detection), mechanisms (e.g., regression, detection, attention, diffusion), and indication types (i.e., point, pose, box, segment, text). It shows which datasets each method supports (TAP-Vid, PoseTrack, MOT, VOS, VIS, MOTS, KITTI, LaSOT, GroOT) and highlights methods that work with both single and multiple object tracking.

This table compares different state-of-the-art (SOTA) object tracking methods based on their paradigm (e.g., tracking-by-regression, tracking-by-detection), mechanism (e.g., iterative refinement, offset prediction), and the types of indications they support (e.g., point, bounding box, segment, text). It also notes which datasets each method was evaluated on and whether the method supports both single- and multi-target tracking.
This table compares different state-of-the-art (SOTA) object tracking methods based on their paradigm (e.g., tracking-by-regression, tracking-by-detection), mechanism (e.g., iterative refinement, cascade association), and the types of indications they support (e.g., points, bounding boxes, segments, text). It also indicates which datasets each method is evaluated on. The color gradient highlights methods applicable to both single and multiple target tracking benchmarks.
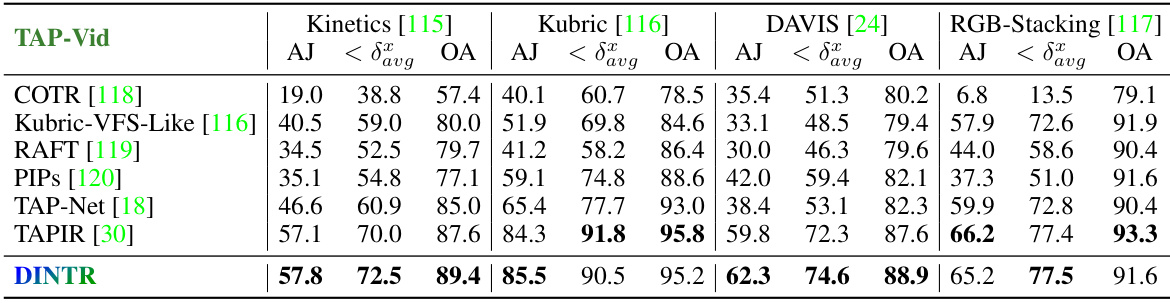
This table compares state-of-the-art (SOTA) object tracking methods across different paradigms (e.g., tracking-by-regression, tracking-by-detection), mechanisms (e.g., iterative refinement, cascade association), and indication types (point, pose, box, segment, text). It highlights which datasets each method supports (TAP-Vid, PoseTrack, MOT, VOS, VIS, MOTS, KITTI, LaSOT, GroOT) and whether they are applicable to both single- and multi-target tracking scenarios.
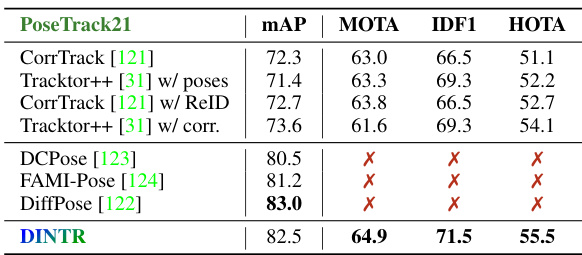
This table compares various state-of-the-art (SOTA) object tracking methods across different paradigms (e.g., tracking-by-regression, tracking-by-detection, etc.). It details the mechanisms used by each method and indicates which types of target representations (point, pose, box, segment, text) are supported by each method, along with the datasets each method was evaluated on. The color gradient helps to distinguish methods that can handle both single and multiple targets.

This table compares state-of-the-art (SOTA) object tracking methods across different paradigms (tracking-by-regression, tracking-by-detection, etc.), mechanisms, and indication types (point, pose, box, segment, text). It shows which datasets each method supports and highlights methods that work for both single and multiple object tracking.

This table compares state-of-the-art (SOTA) object tracking methods across different paradigms (e.g., tracking-by-regression, tracking-by-detection, etc.). It details the mechanisms used by each method and indicates which types of target representations (points, poses, bounding boxes, segments, text) are supported by each method. The table also notes which datasets are used for evaluating each method, differentiating between single and multi-target benchmarks. Methods supporting both single and multi-target benchmarks are highlighted using a color gradient.

This table compares several state-of-the-art (SOTA) object tracking methods based on their paradigm (e.g., tracking-by-regression, tracking-by-detection), mechanism (e.g., Regression Head, Cascade Association), and the types of indications they support (e.g., point, box, segment, text). It also indicates which datasets each method was evaluated on (TAP-Vid, PoseTrack, MOT, VOS, VIS, MOTS, KITTI, LaSOT, GroOT). The color gradient helps distinguish methods suitable for single-target versus multi-target tracking benchmarks.
Full paper#