↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Vision models traditionally update first-layer weights proportionally to input pixel values. This leads to images with high contrast having a disproportionately large influence on the training process, while low-contrast images have less impact. This uneven influence slows down training and can lead to suboptimal model performance. The paper identifies this issue and proposes an approach to improve training efficiency.
The proposed solution, TrAct, addresses this imbalance by directly optimizing the activations (embeddings) produced by the first layer. This is achieved through a closed-form solution that finds the optimal weights which minimize the squared distance to an activation proposal. Experiments show that TrAct consistently speeds up training across various model architectures (convolutional and transformer-based) and datasets, achieving speedups between 1.25x and 4x while requiring only minimal computational overhead.
Key Takeaways#
Why does it matter?#
This paper is crucial because it presents a novel and efficient training technique, TrAct, that significantly speeds up training for various vision models. It addresses a key limitation in training vision models by enabling direct optimization of first-layer activations, which leads to faster convergence and improved accuracy. The generalized approach and experimental validation across different architectures make it highly relevant to a broad audience of researchers. Furthermore, TrAct’s simplicity and compatibility with existing frameworks facilitate easy adoption and integration into existing research workflows, thus fostering wider adoption and further investigation.
Visual Insights#

This figure illustrates the core idea of TrAct by comparing the training dynamics of the first layer in language models and vision models. In language models, the embedding vectors are updated directly based on the gradients of pre-activations. However, in vision models, the weight updates are directly proportional to pixel values, leading to unequal impacts from images with varying contrasts. TrAct addresses this by modifying the gradient descent process to mimic the behavior of language model embedding layers, allowing the first-layer activations to be trained directly.
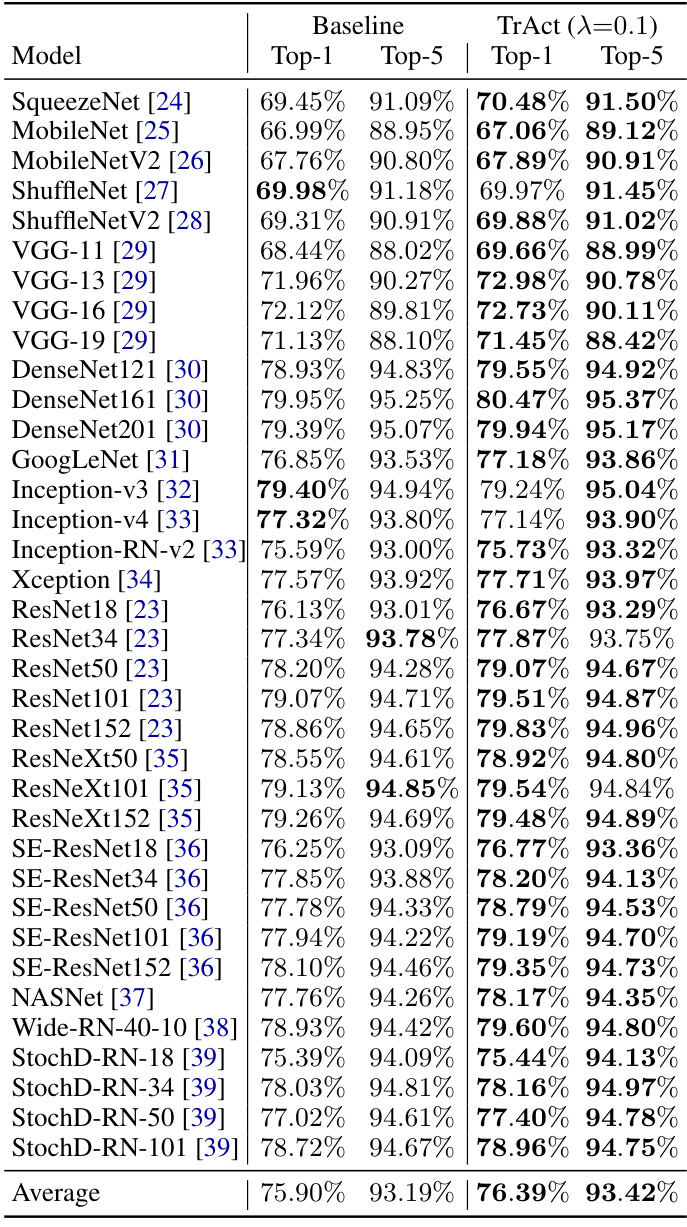
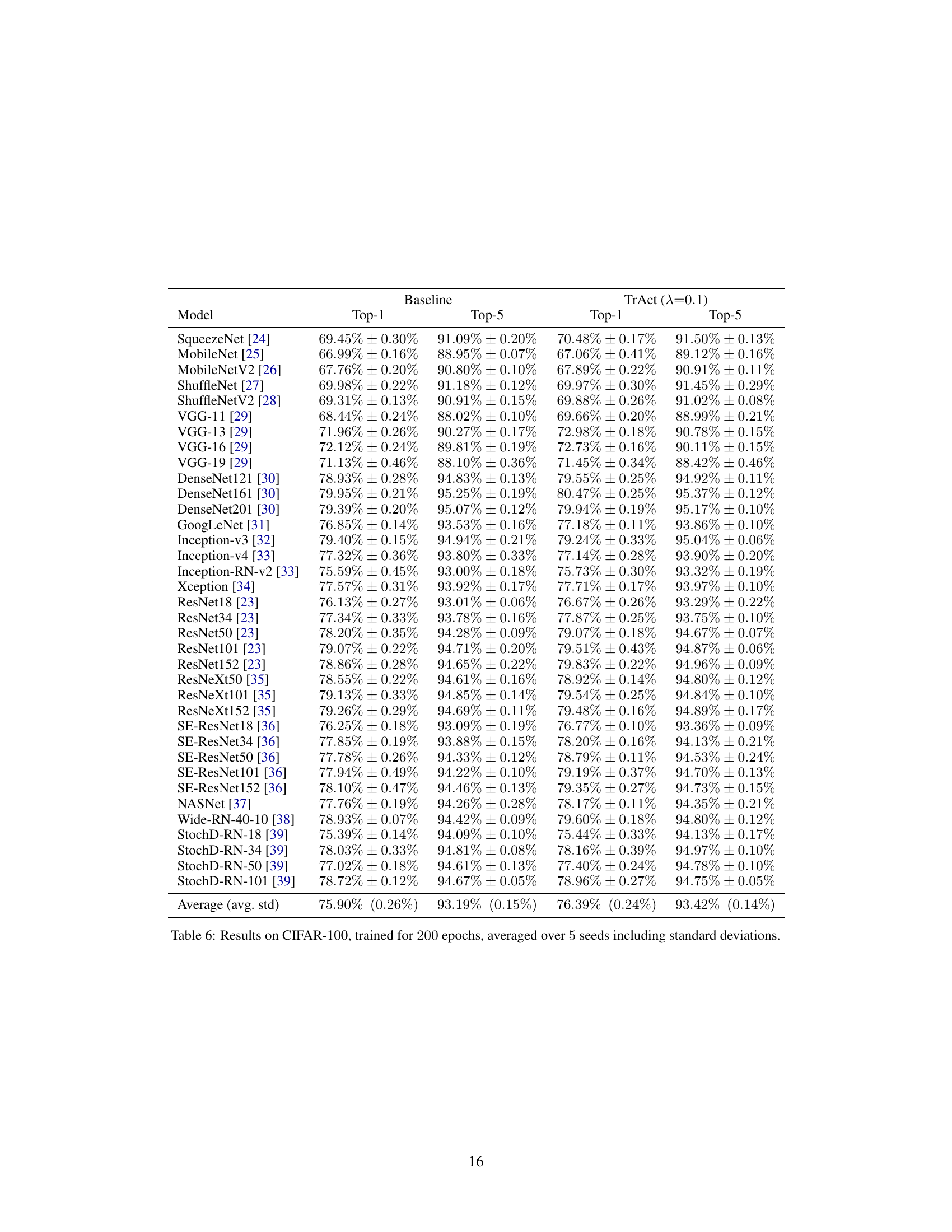
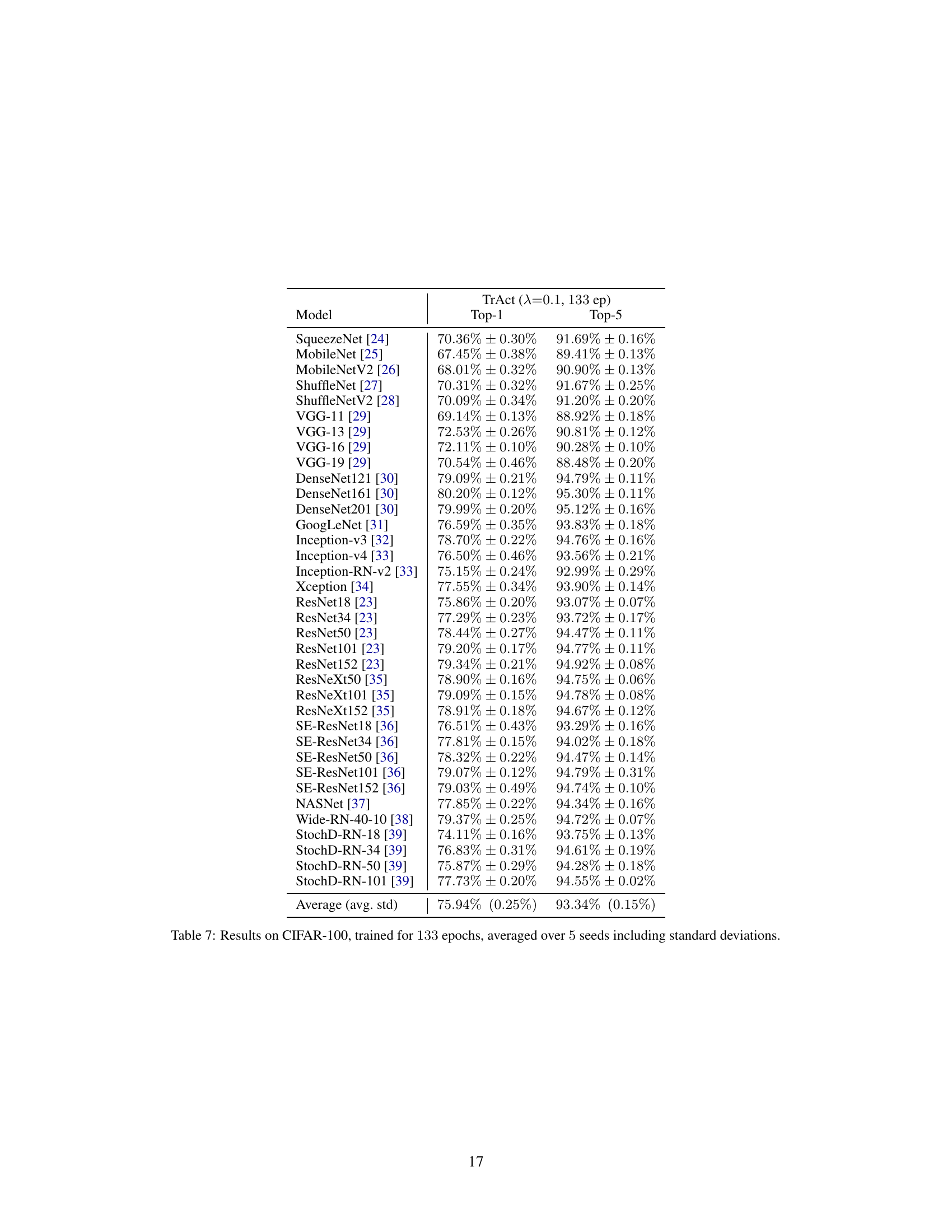
This table presents the results of training various models on the CIFAR-100 dataset for 200 epochs. It compares the performance of a baseline training method against the TrAct method (with λ=0.1). The table shows Top-1 and Top-5 accuracies for each model. Additional results using TrAct for only 133 epochs are available in supplemental material (SM).
In-depth insights#
TrAct’s Core Idea#
TrAct addresses the imbalance in gradient updates during the training of vision models’ first layers. Standard backpropagation causes gradients to be directly proportional to pixel values, leading to high-contrast images dominating the learning process. TrAct tackles this by performing gradient descent directly on the first-layer activations (pre-activations) rather than on the weights. This is conceptually similar to how embedding layers are trained in language models. To achieve this without modifying the model architecture, TrAct proposes a closed-form solution that finds the optimal weights minimizing the squared distance to the proposed activations. This efficiently speeds up training by allowing for more effective updates to the pre-activations, thereby mitigating the disproportionate influence of high-contrast inputs. The method is particularly effective in early training stages and works with different model architectures and optimizers.
Activation Training#
Activation Training presents a novel approach to enhance the training of neural networks, particularly focusing on the initial layers of vision models. The core idea revolves around directly training the activations (pre-activations) of the first layer, rather than indirectly influencing them through weight updates. This is inspired by the direct training of embeddings in language models. The method cleverly addresses the challenge of having gradients directly proportional to input pixel values (high contrast images dominate training), by proposing a closed-form solution to minimize the distance between a gradient descent step on activations and the optimal weights. This allows for more even gradient updates, enhancing the model’s ability to learn from all parts of an image, rather than being dominated by high contrast regions. Empirically, Activation Training consistently speeds up training while requiring only minor modifications to the training process. It is a versatile method applicable to diverse architectures, demonstrating a significant improvement in training efficiency across a broad range of experiments. The technique’s relative simplicity and effectiveness make it a compelling addition to the neural network training toolbox.
Vision Model Impact#
Analyzing the impact of vision models reveals a complex interplay of factors. Data bias significantly influences model performance and fairness, with skewed datasets leading to inaccurate or discriminatory outputs. Model architecture choices, from convolutional networks to transformers, impact efficiency and accuracy, but also determine computational costs and environmental footprint. The intended application of the model is crucial; a model effective for image classification might be inadequate for object detection or image generation. Deployment considerations include resource constraints (hardware, energy), explainability needs, and potential vulnerabilities to adversarial attacks. Finally, the broader societal impacts, both positive (e.g., medical diagnosis, environmental monitoring) and negative (e.g., privacy violations, bias amplification) must be carefully evaluated to ensure responsible development and use.
TrAct Efficiency#
TrAct’s efficiency stems from its clever modification of the training process, not the model architecture. By directly optimizing first-layer activations, it bypasses the indirect weight updates inherent in standard backpropagation. This leads to faster convergence and a reduction in training epochs needed to achieve comparable performance. The method’s efficiency is demonstrated across various model architectures and datasets, showing speedups ranging from 1.25x to 4x. While there’s a minor computational overhead for small models due to matrix inversion, this becomes negligible for larger models. The single hyperparameter (λ) is easily tuned, requiring minimal additional effort, contributing to the overall efficiency and ease of implementation. This makes TrAct a practical and impactful improvement, especially considering its minimal architectural changes, allowing easy integration into existing training pipelines.
Future of TrAct#
The “Future of TrAct” holds exciting possibilities. TrAct’s closed-form solution and minimal architectural changes offer broad applicability across various vision models. Its efficiency gains, demonstrated across numerous architectures and datasets, suggest potential integration into existing training pipelines with minimal disruption. Future research should explore TrAct’s performance on even larger-scale datasets like JFT-300M and its compatibility with emerging vision model architectures. Investigating TrAct’s effectiveness in conjunction with other optimization techniques and its impact on generalization and robustness would further enhance its value. Extending TrAct’s theoretical framework to encompass deeper layers and understanding its effect on feature representations are important avenues for investigation. Finally, exploring the practical implications of TrAct for specific applications, such as medical image analysis and autonomous driving, could demonstrate its real-world impact. The hyperparameter’s insensitivity also suggests potential for automation or adaptive tuning mechanisms in future implementations, enhancing usability and streamlining adoption.
More visual insights#
More on figures
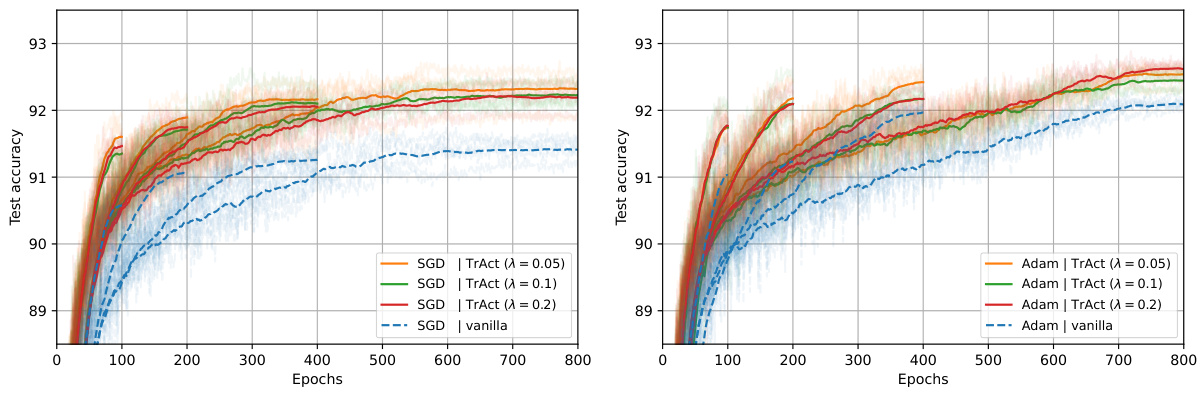
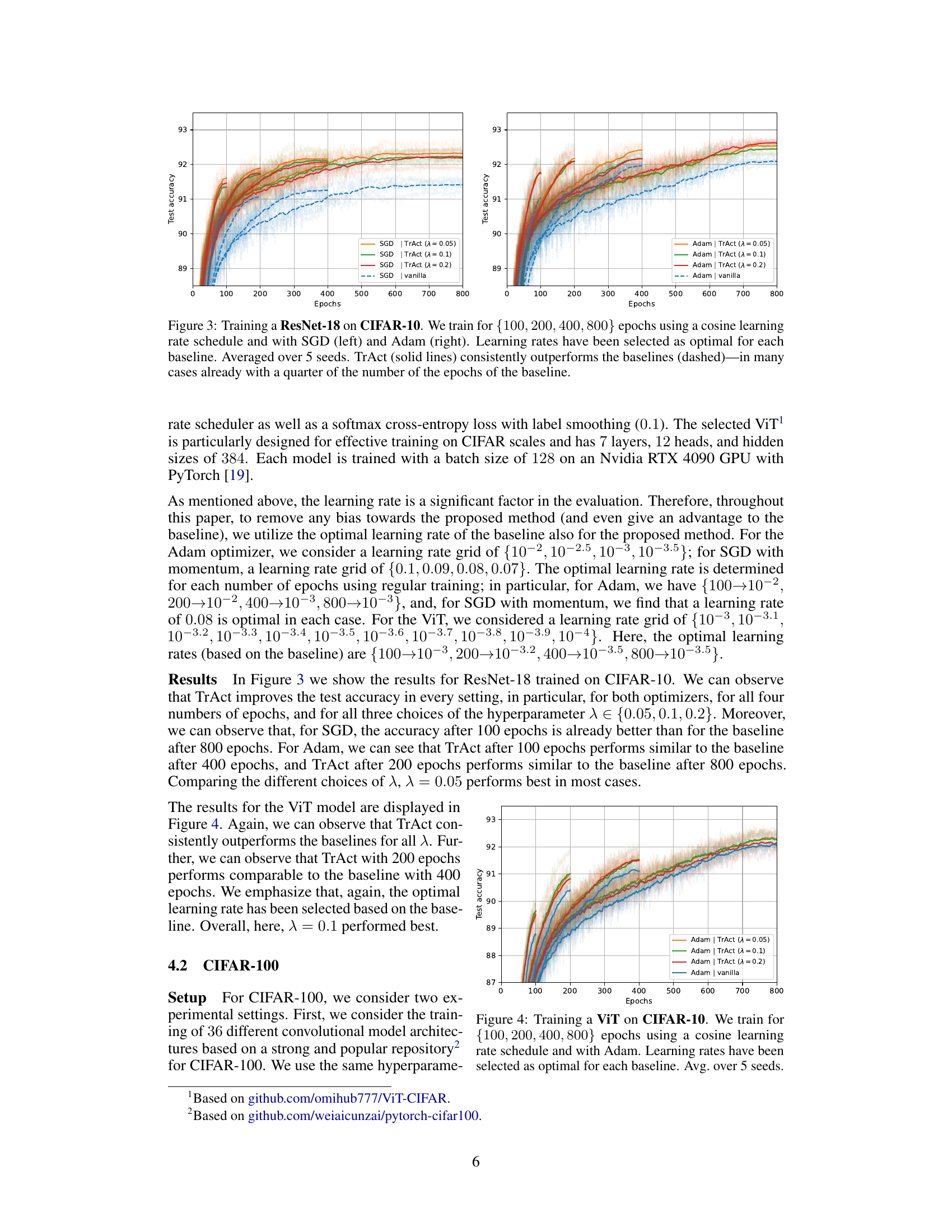
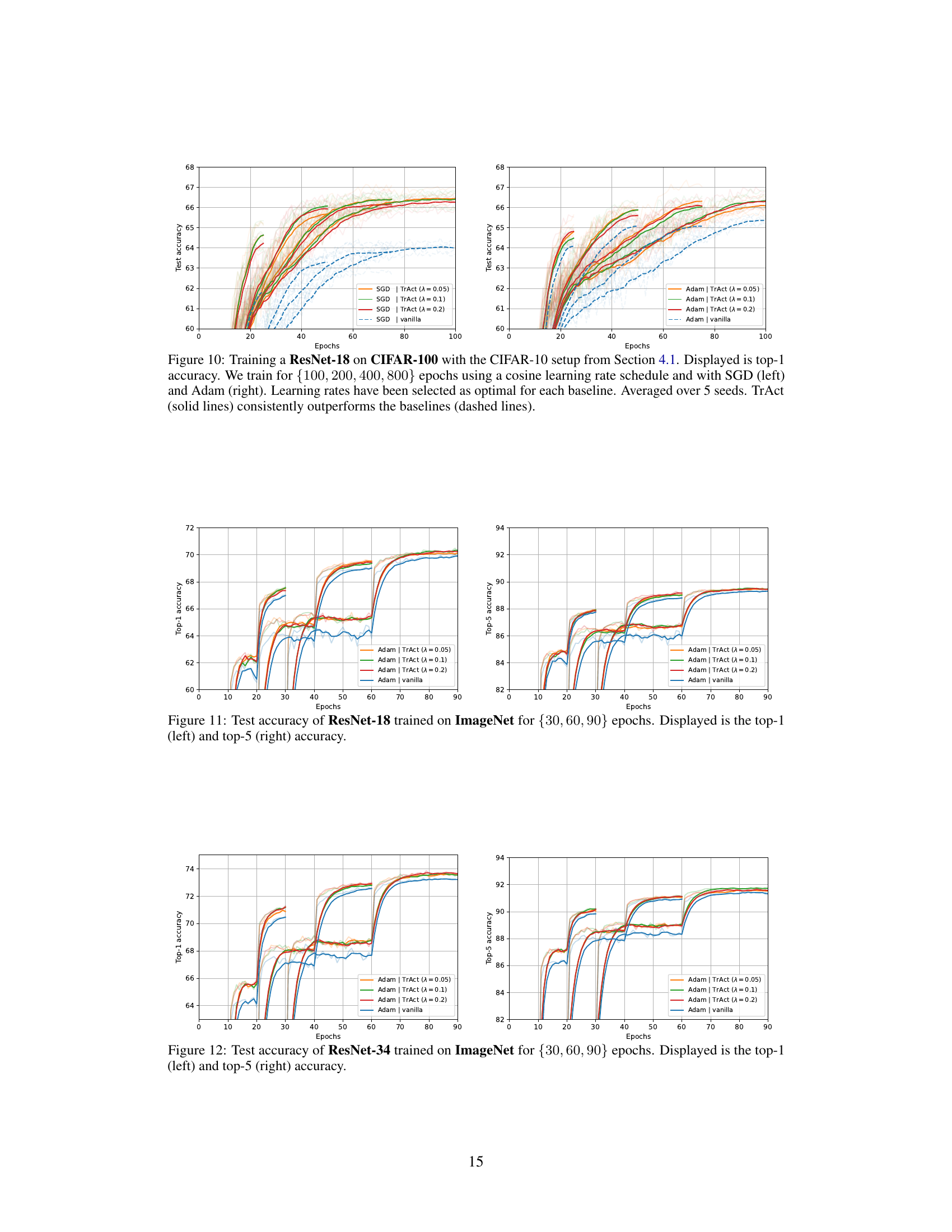
The figure shows the training curves of ResNet-18 on CIFAR-10 dataset using SGD and Adam optimizers with and without TrAct. Four different training epochs (100, 200, 400, 800) are tested. The results are averaged over 5 different seeds. The solid lines represent the performance with TrAct while the dashed lines are without TrAct. The results demonstrate that TrAct consistently outperforms the baseline methods, often achieving comparable or better results in a significantly shorter number of training epochs.
This figure shows the training results for a ResNet-18 model trained on the CIFAR-10 dataset using both SGD and Adam optimizers. The experiment compares the performance of the proposed TrAct method against standard training methods for different numbers of training epochs (100, 200, 400, 800). The results demonstrate that TrAct consistently outperforms standard training, often achieving comparable or better accuracy with significantly fewer epochs.
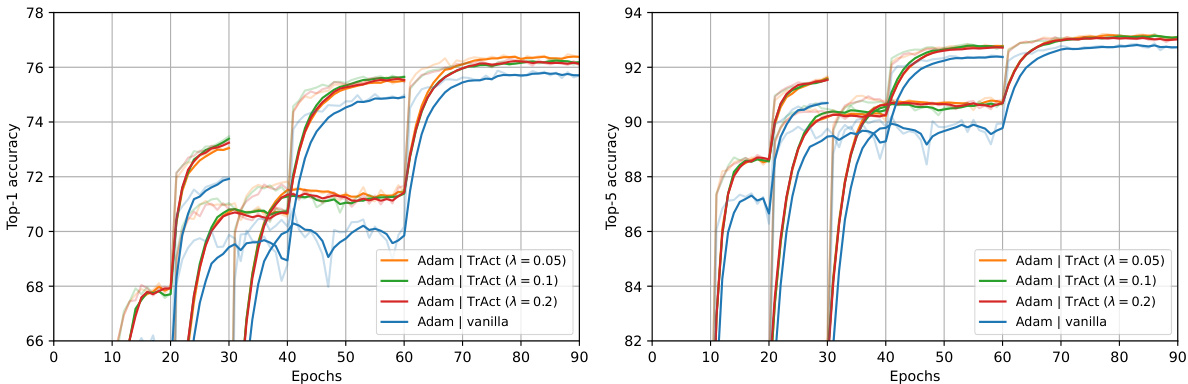
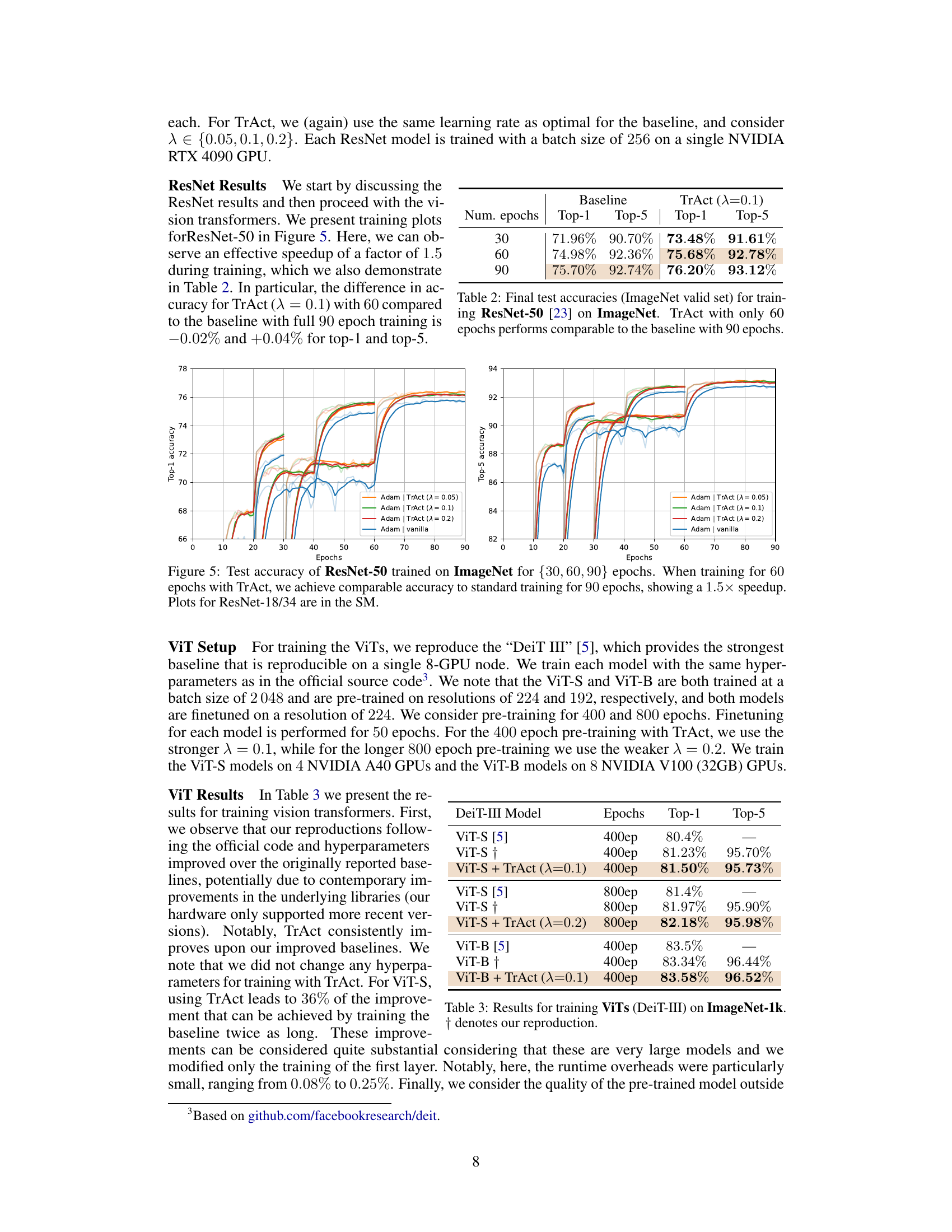
The figure shows the training curves for ResNet-50 on ImageNet for different numbers of training epochs (30, 60, 90). The curves compare the standard training approach with the TrAct method for different values of the hyperparameter λ. It demonstrates that TrAct achieves comparable accuracy to standard training using fewer epochs which translates to a significant speedup (1.5x in this case) in training time.
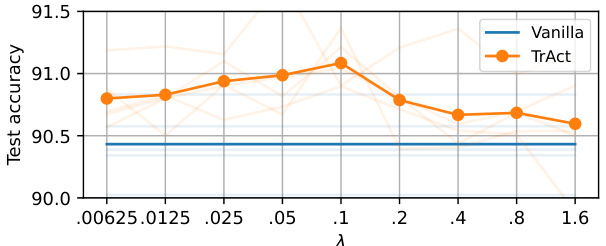
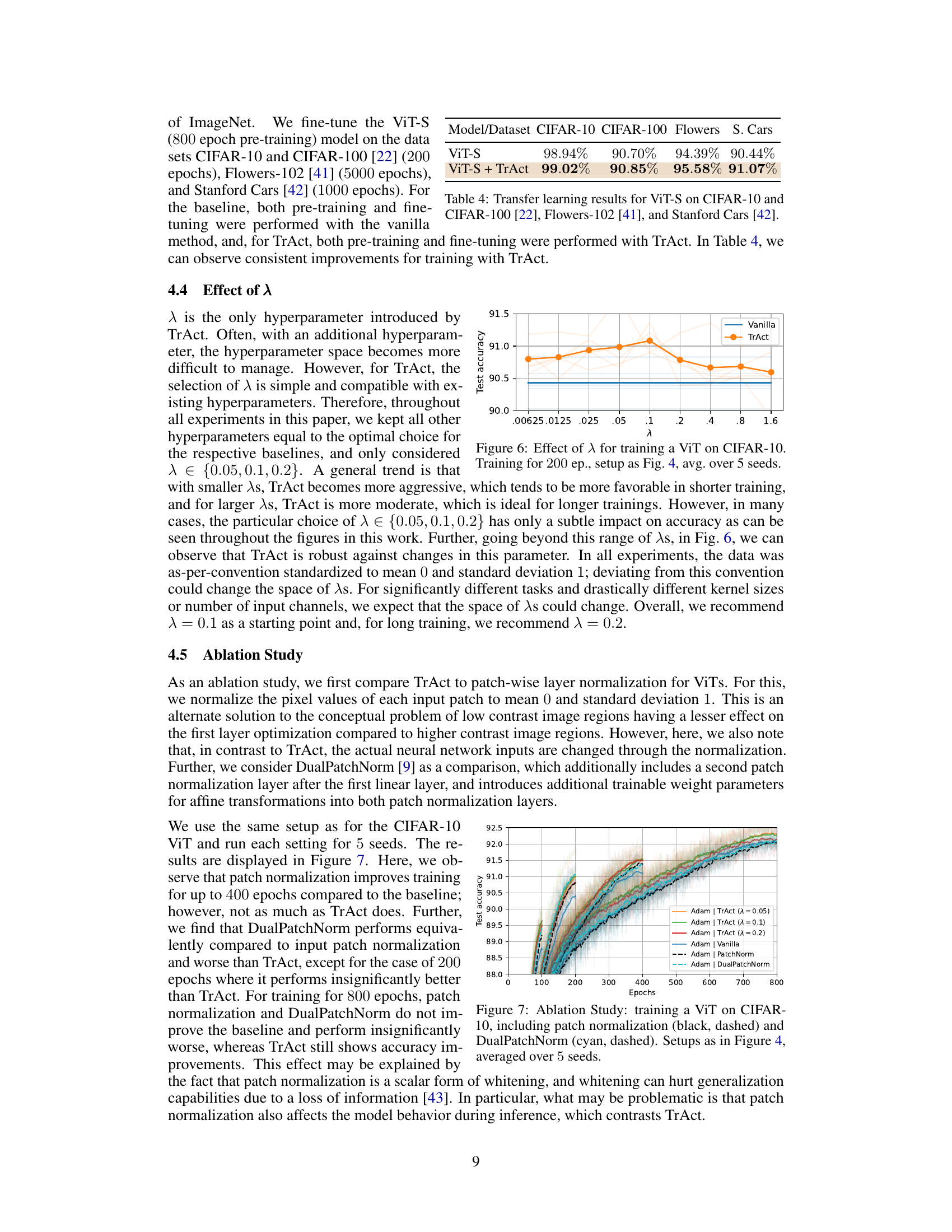
This figure shows the impact of the hyperparameter λ on the test accuracy of a Vision Transformer (ViT) model trained on the CIFAR-10 dataset. The x-axis represents different values of λ, while the y-axis shows the test accuracy. The orange line shows results for the TrAct method, and the blue line shows results for vanilla training. The shaded region around each line indicates the standard deviation over five different training runs. The plot demonstrates that TrAct is relatively robust to changes in λ, offering consistent improvement over vanilla training across different λ values.
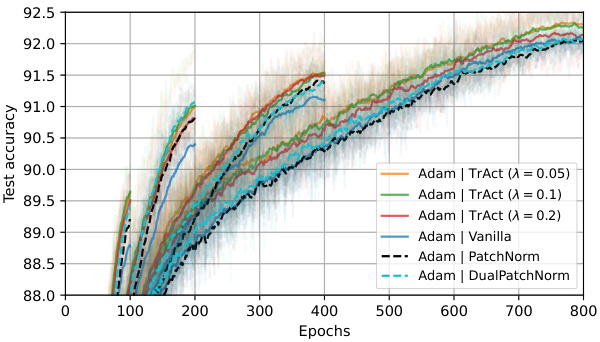
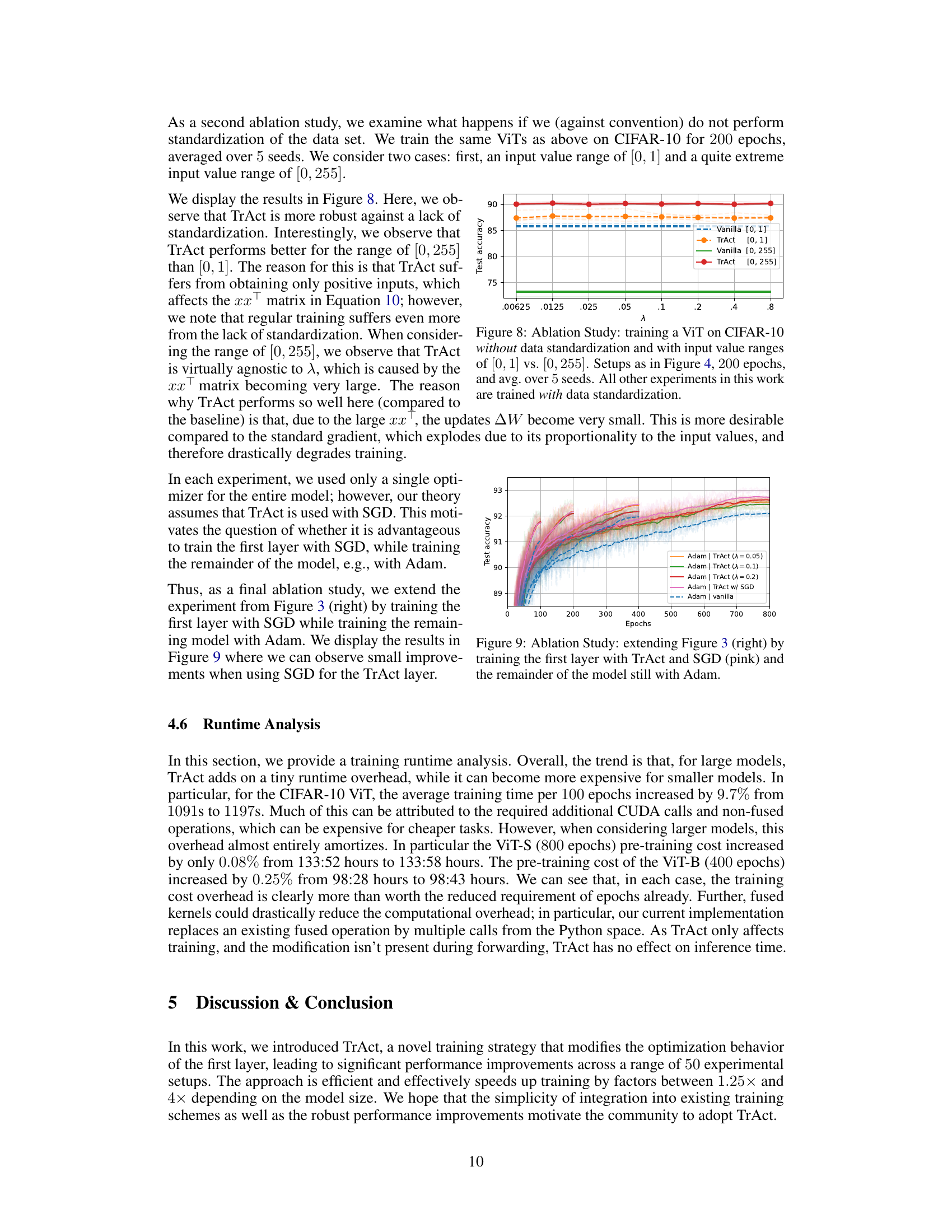
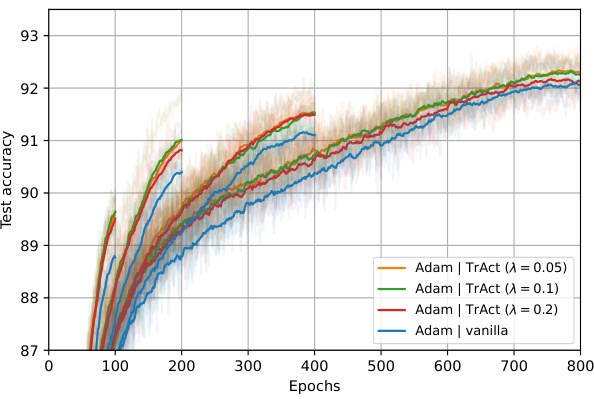
This figure displays the results of an ablation study comparing TrAct’s performance to patch-wise layer normalization and DualPatchNorm on a Vision Transformer (ViT) model trained on the CIFAR-10 dataset. The plot shows test accuracy over 800 epochs. The goal is to demonstrate that TrAct’s performance advantage is not simply due to the effect of normalization techniques on the input data. The various lines represent different training methods, including TrAct with different lambda values, standard training (vanilla), patch-wise normalization, and DualPatchNorm. The plot shows TrAct consistently outperforms the other methods.

This figure displays the test accuracy results for training a Vision Transformer (ViT) on the CIFAR-10 dataset with and without data standardization. It compares the performance of vanilla training and TrAct (Training Activations) under two different input value ranges: [0, 1] (normalized) and [0, 255] (unnormalized). The experiment shows that TrAct is more robust to the lack of standardization, performing better with the wider [0, 255] range than with the normalized [0,1] range.
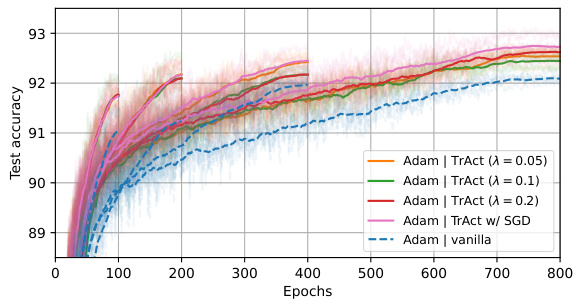
This figure displays the results of training a ResNet-18 model on the CIFAR-10 dataset using both SGD and Adam optimizers. The training was done for 100, 200, 400, and 800 epochs, each using a cosine learning rate schedule. The figure compares the performance of the baseline training methods against the TrAct method, demonstrating a consistent improvement in test accuracy by TrAct. Notably, TrAct achieves comparable or superior results with far fewer training epochs, highlighting its efficiency.
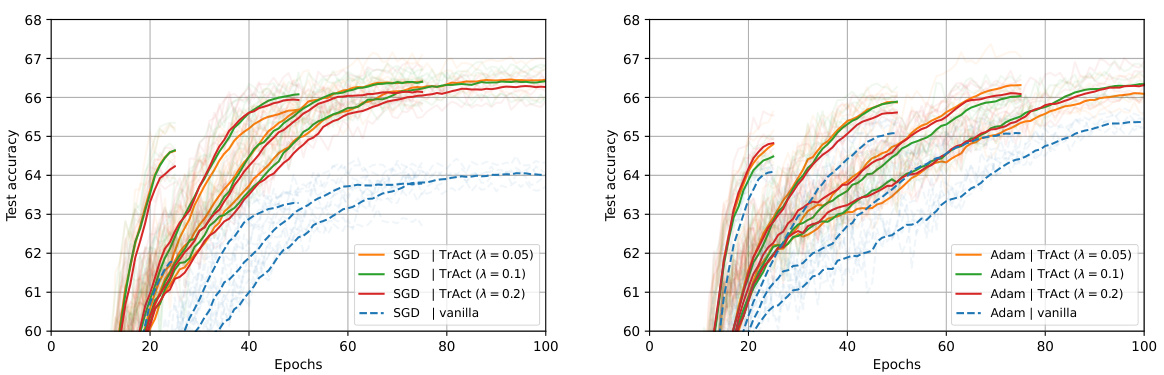
This figure displays the training results for a ResNet-18 model on the CIFAR-10 dataset, using both SGD and Adam optimizers with a cosine learning rate schedule. The experiment is run for 100, 200, 400, and 800 epochs. The results show that TrAct consistently outperforms the baseline models, often achieving comparable or better accuracy with significantly fewer epochs.
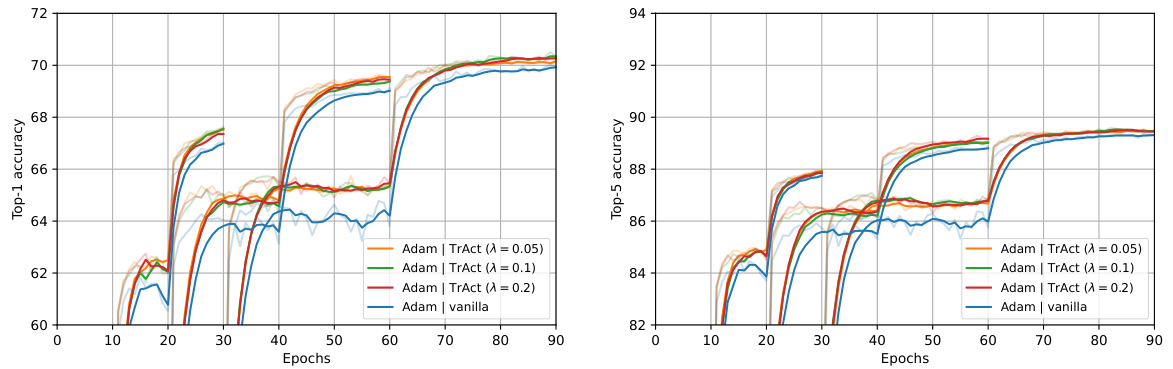
The figure shows the test accuracy (top-1 and top-5) for ResNet-50 trained on the ImageNet dataset for 30, 60, and 90 epochs using both standard training and TrAct. It demonstrates that TrAct achieves comparable accuracy with 60 epochs to that of standard training with 90 epochs, thus exhibiting a 1.5x speed-up in training.

The figure shows the training curves for ResNet-50 on ImageNet using different training epochs (30, 60, and 90). It compares the standard training approach with the TrAct method (using different lambda values). The key observation is that training with TrAct for 60 epochs achieves similar accuracy to the standard training with 90 epochs, demonstrating a significant speedup (1.5x).
More on tables
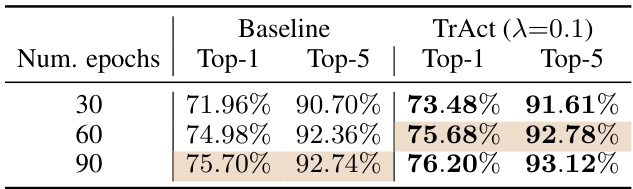
This table presents the final test accuracies on the ImageNet validation set for ResNet-50 trained using both standard training and the TrAct method. The results demonstrate that using TrAct for 60 epochs achieves comparable performance to using the standard method for 90 epochs, indicating a potential speedup in training time. Top-1 and Top-5 accuracies are shown for each training scenario.
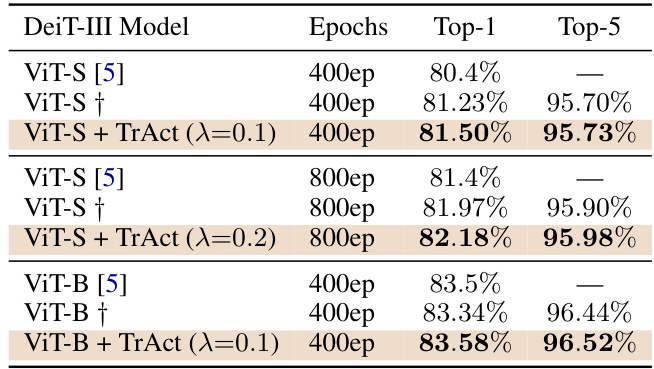
This table presents the results of training Vision Transformers (ViTs) using the DeiT-III model on the ImageNet-1k dataset. It compares the performance of the original ViT-S and ViT-B models (from the DeiT-III paper) against the authors’ reproduction and the results obtained after applying their proposed TrAct method. The table shows the Top-1 and Top-5 accuracies achieved after training for different numbers of epochs (400 and 800). The † symbol indicates that the row represents the authors’ reproduction of the baseline experiment.

This table shows the transfer learning results of a ViT-S model, pre-trained using TrAct (Training Activations), and a vanilla ViT-S model on four different datasets: CIFAR-10, CIFAR-100, Flowers-102, and Stanford Cars. The table demonstrates the performance of the TrAct-trained model compared to the vanilla model on these diverse datasets, highlighting the generalization capabilities.

This table presents the mean average precision (mAP) results for object detection on the PASCAL VOC2007 dataset using Faster R-CNN with a VGG-16 backbone. Two training methods are compared: vanilla training and training with TrAct. The results are averaged over two separate training runs, and the standard deviation is also provided to indicate the variability of the results.

This table presents the results of training various models on the CIFAR-100 dataset for 200 epochs using both baseline training and the TrAct method with λ = 0.1. The results are averaged over 5 independent training runs, and standard deviations are included to show variability in performance. The table compares the Top-1 and Top-5 accuracies achieved by each model using both training methods, providing a comprehensive performance comparison for a range of different model architectures.

This table presents the results of training various models on the CIFAR-100 dataset for 200 epochs. The results are averaged over 5 different seeds to account for variability. Each row shows the performance of a different model architecture, reporting both the Top-1 accuracy (percentage of correctly classified images) and Top-5 accuracy (percentage where the correct class is among the top 5 predictions). Standard deviations are also provided, indicating the variability across the different seeds. The table allows comparison of baseline performance against the performance achieved using TrAct (with λ=0.1).
Full paper#