TL;DR#
Generating high-fidelity 3D meshes directly remains a challenge due to their unstructured nature and the difficulty of accurately estimating spatial locations and connectivity. Existing methods often rely on indirect approaches, such as converting to intermediate representations like point clouds or voxels, which can lead to information loss or inefficiency. Furthermore, scaling up these methods for large-scale pre-training is often difficult.
This paper presents MeshXL, a family of generative pre-trained models that directly generates high-quality 3D meshes. MeshXL utilizes a novel Neural Coordinate Field (NeurCF) representation, which effectively represents the explicit 3D coordinates with implicit neural embeddings. This allows for a simple yet effective sequence representation of 3D meshes, facilitating autoregressive generation and pre-training. The model is trained on a large-scale dataset of 2.5 million 3D meshes, achieving state-of-the-art performance and demonstrating scalability.
Key Takeaways#
Why does it matter?#
This paper is significant because it introduces MeshXL, a novel approach to 3D mesh generation using a neural coordinate field. This addresses a crucial challenge in the field: generating high-quality 3D meshes from limited data. Its application to large language models opens new avenues for research in efficient and controllable 3D asset generation. The pre-training on large-scale datasets, along with the novel representation, significantly improves the quality and diversity of generated meshes, surpassing previous state-of-the-art methods. This offers substantial benefits for various downstream applications in gaming, virtual reality, and more.
Visual Insights#

🔼 This figure illustrates the MeshXL’s mesh representation method using Neural Coordinate Fields (NeurCF). NeurCF encodes 3D coordinates implicitly using neural embeddings, allowing for efficient representation of mesh data. A pre-defined ordering strategy enables autoregressive generation of unstructured 3D meshes directly, eliminating the need for intermediate representations.
read the caption
Figure 2: Mesh Representation. We present the Neural Coordinate Field (NeurCF) to encode the discretized coordinates in the Euclidean space. Benefiting from NeurCF and a pre-defined ordering strategy, our proposed MeshXL can directly generate the unstructured 3D mesh auto-regressively.
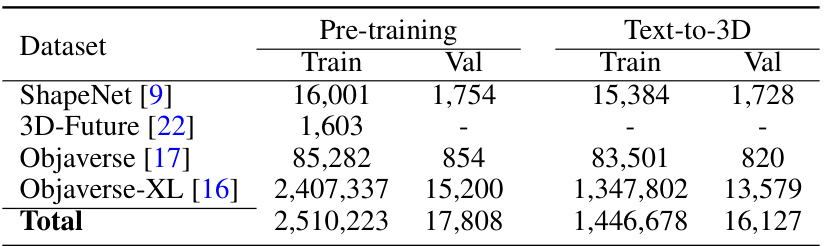
🔼 This table presents the number of 3D meshes used for training and validation of the MeshXL models. The data is sourced from four datasets: ShapeNet, 3D-Future, Objaverse, and Objaverse-XL. The table is split into two sections: Pre-training and Text-to-3D, indicating the data used for each respective training phase. The total number of meshes used across both training phases is approximately 2.5 million.
read the caption
Table 1: Statistics for the Training Data and Validation Data. After combining four data sources, our proposed MeshXL models are trained on approximately 2.5 million 3D meshes.
In-depth insights#
NeurCF: Mesh Encoding#
The proposed NeurCF (Neural Coordinate Field) offers a novel approach to mesh encoding for generative 3D models. Instead of relying on traditional methods that treat meshes as unstructured graphs or convert them to intermediate representations like point clouds, NeurCF leverages an explicit coordinate representation combined with implicit neural embeddings. This approach simplifies mesh representation into a sequence of coordinates, enabling the use of autoregressive sequence modeling techniques commonly employed in large language models. A significant advantage is the enhanced scalability of NeurCF, facilitating large-scale pre-training on vast datasets of 3D meshes, overcoming limitations of previous methods. The explicit representation, however, may necessitate pre-defined ordering strategies, impacting the overall flexibility and potentially introducing biases. Further research could investigate alternative ordering schemes and evaluate the robustness of NeurCF to various mesh topologies and complexities. The simplicity and scalability of NeurCF suggest a promising direction for future development of generative 3D models.
MeshXL: Model Variants#
MeshXL’s exploration of model variants is crucial for understanding its scalability and performance. By training models with varying parameter counts (125M, 350M, and 1.3B), the authors demonstrate the impact of model size on generation quality. Larger models consistently show improved performance, as evidenced by lower perplexity scores. This supports the idea of using large language model techniques in 3D mesh generation. The scaling analysis is a key strength, enabling a clear understanding of the trade-off between computational cost and generation quality. This systematic evaluation also helps identify the sweet spot for practical applications, balancing performance with resource constraints. However, it remains important to explore whether other architectural variations, besides scale, could offer further improvements in efficiency or quality. Future work could explore different transformer architectures, attention mechanisms, and training strategies. The choice of model variants is well-justified, enabling a comprehensive assessment of MeshXL’s capabilities and scaling potential. The results provide valuable insights for future research on large-scale generative 3D models.
Large-Scale Pretraining#
Large-scale pre-training is crucial for achieving state-of-the-art performance in many deep learning applications, and generative 3D models are no exception. MeshXL leverages this principle by training on a massive dataset of 2.5 million 3D meshes, a significant increase over previously used datasets. This scale allows the model to learn intricate details and complex relationships within the 3D structures, leading to improved generation quality and generalization ability. The use of auto-regressive pre-training further enhances MeshXL’s capabilities by enabling the model to learn the sequential nature of mesh construction, resulting in a more coherent and structured generation process. However, the enormous computational resources required for large-scale pre-training remain a major bottleneck, underscoring the need for efficient training strategies and hardware advancements. Despite this challenge, the results demonstrate the significant benefits of this approach, paving the way for more sophisticated and realistic 3D generative models in the future. Further research could explore techniques to improve efficiency while maintaining the quality benefits of large-scale pre-training.
3D Generation: X2Mesh#
The heading “3D Generation: X2Mesh” suggests a focus on generating 3D meshes from various input modalities (represented by ‘X’). This implies the use of a generative model trained to translate diverse data types, such as images, text descriptions, or point clouds, into 3D mesh representations. The approach is likely data-driven, relying on a large dataset of paired X and mesh data for training. The system likely leverages techniques like deep learning to learn complex mappings between the input domain and the mesh space. Autoregressive models or diffusion models are plausible methods, enabling sequential or iterative generation of mesh vertices, edges, and faces. A key challenge would be handling the unstructured nature of mesh data and ensuring the generated meshes are both geometrically consistent and semantically meaningful. Successful implementation requires sophisticated techniques for managing mesh topology, resolving ambiguities in input data, and efficiently training the generative model at scale. Evaluation would probably involve comparing the generated meshes against ground truth using metrics such as Chamfer distance or Earth Mover’s Distance.
Limitations and Future#
The section titled “Limitations and Future Work” would likely discuss the inference time limitations of the MeshXL model, which is slower due to its autoregressive nature and the large number of tokens generated for each 3D mesh. Future work might explore techniques to accelerate inference, such as using more efficient RNN-related methods or modifying the model to predict multiple tokens simultaneously. Another limitation could be the reliance on a pre-defined ordering strategy for the 3D mesh; future research could investigate alternative, more flexible methods. The model’s performance may also be influenced by the quality and diversity of the training data, and more research is needed to determine the optimal data representation and scale for large-scale 3D mesh generation. Finally, exploring alternative 3D representations and the application of MeshXL to different modalities, such as image and text-conditioned generation, could also improve the quality and efficiency of the model.
More visual insights#
More on figures

🔼 This figure illustrates the Neural Coordinate Field (NeurCF) and how it is used in MeshXL for autoregressive 3D mesh generation. (a) shows NeurCF encoding the 3D mesh by embedding each discretized coordinate (x, y, z) using an embedding layer E, forming a face embedding Eface and finally a mesh embedding Emesh. (b) depicts the autoregressive generation process; MeshXL predicts the next coordinate based on the previously generated coordinates to produce the complete 3D mesh sequentially.
read the caption
Figure 2: Mesh Representation. We present the Neural Coordinate Field (NeurCF) to encode the discretized coordinates in the Euclidean space. Benefiting from NeurCF and a pre-defined ordering strategy, our proposed MeshXL can directly generate the unstructured 3D mesh auto-regressively.
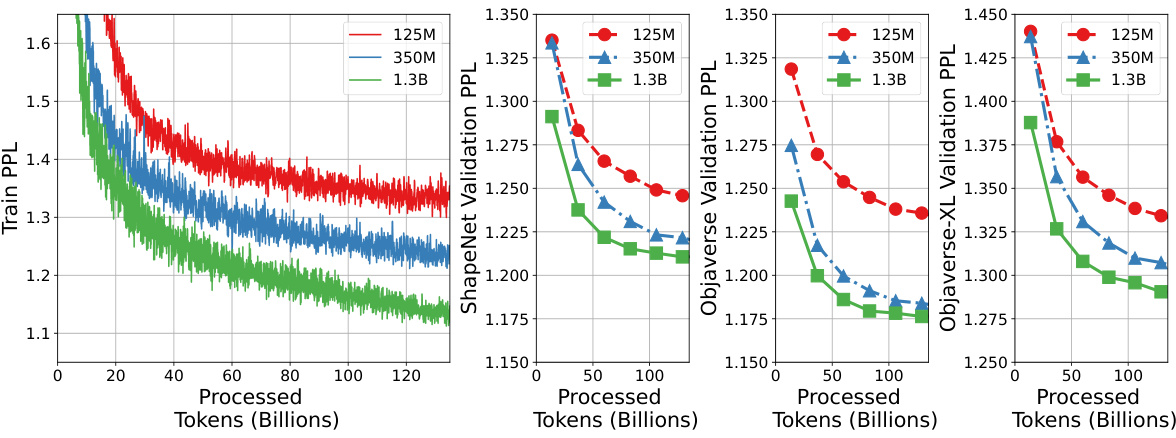
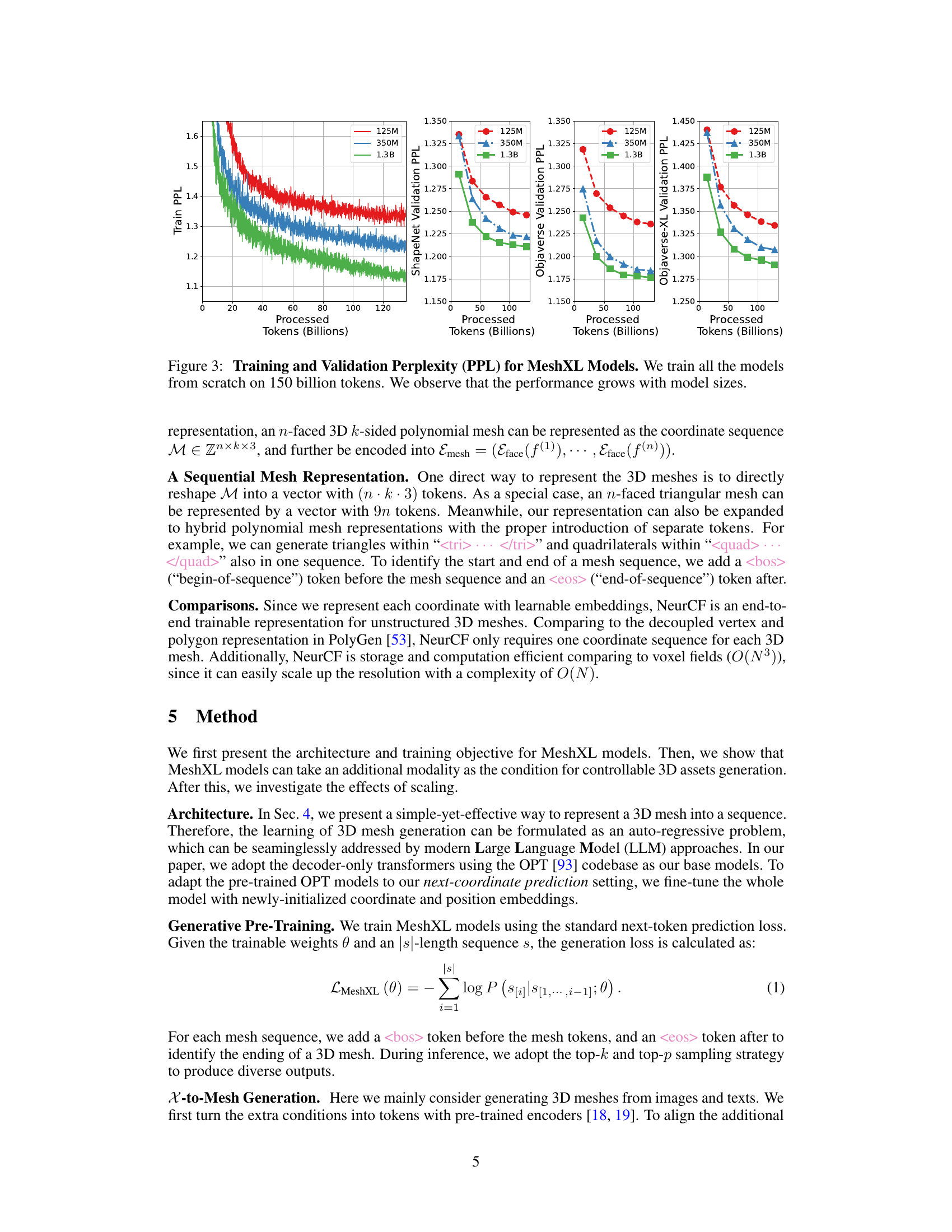
🔼 This figure shows the training and validation perplexity (PPL) for MeshXL models of different sizes (125M, 350M, and 1.3B parameters). The models were trained from scratch using 150 billion tokens. The plots demonstrate that as model size increases, both training and validation PPL decrease, indicating improved performance and generalization ability.
read the caption
Figure 3: Training and Validation Perplexity (PPL) for MeshXL Models. We train all the models from scratch on 150 billion tokens. We observe that the performance grows with model sizes.

🔼 This figure showcases the MeshXL model’s ability to complete partially observed 3D meshes. The left column shows the incomplete input meshes (in white). The central columns display several different completed meshes generated by MeshXL (in blue). The right column shows the corresponding ground truth complete meshes (in green). This demonstrates MeshXL’s capacity to generate plausible and varied completions based on incomplete input data.
read the caption
Figure 4: Evaluation of Partial Mesh Completion. Given some partial observation of the 3D mesh (white), MeshXL is able to produce diverse object completion results (blue).
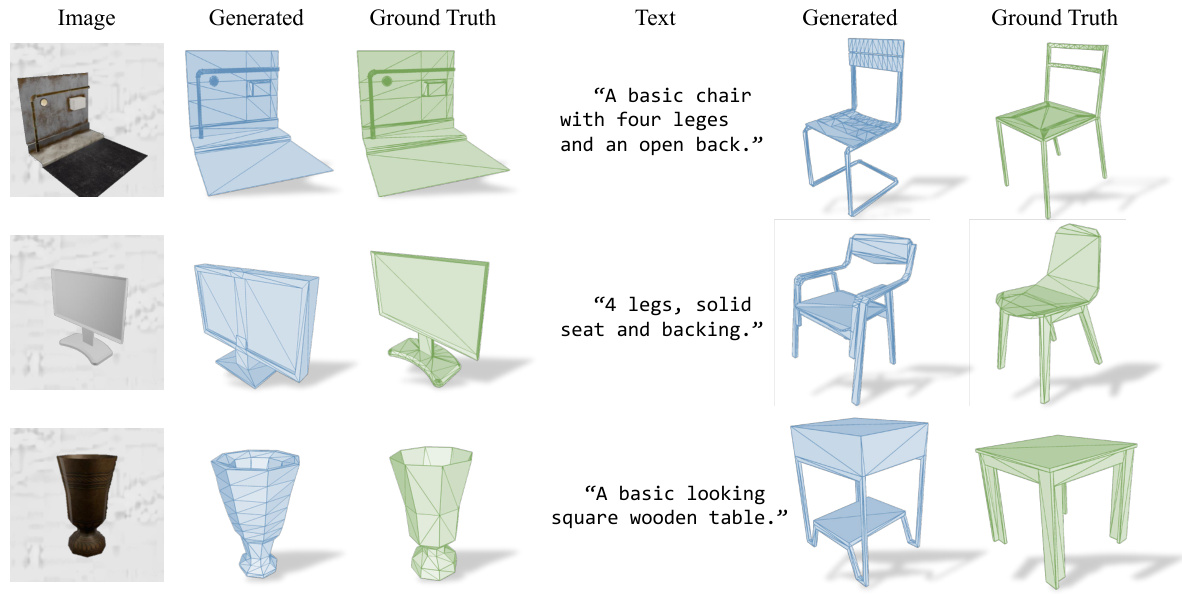
🔼 This figure demonstrates the capability of the MeshXL model to generate 3D meshes conditioned on either image or text inputs. It shows three examples: a laptop, a computer monitor, and a vase. For each example, the input image or text prompt is shown alongside the generated 3D mesh and a ground truth 3D mesh for comparison. The results highlight MeshXL’s ability to produce high-quality 3D models that align well with the given input.
read the caption
Figure 5: Evaluation of X-to-mesh generation. We show that MeshXL can generate high-quality 3D meshes given the corresponding image or text as the additional inputs.

🔼 This figure shows the results of applying a texture generation pipeline (Paint3D) to 3D meshes generated by the MeshXL model. It demonstrates that the generated meshes are compatible with existing texturing methods, resulting in high-quality textured 3D assets. Each row displays a generated mesh, the same mesh after texturing is applied, and the UV map used in the texturing process.
read the caption
Figure 6: Texture Generation for the Generated 3D Meshes. We adopt Paint3D [91] to generate textures for 3D meshes produced by MeshXL.

🔼 This figure presents a qualitative comparison of 3D mesh generation results from four different methods: PolyGen, GET3D, MeshGPT, and MeshXL. For each method, sample outputs of chair and table models are shown, with a visualization of their normal vectors. The comparison highlights MeshXL’s ability to generate high-quality meshes with both sharp edges and smooth surfaces, contrasting it with the other methods which sometimes produce meshes with less refined details or smoother surfaces.
read the caption
Figure 7: Qualitative comparisons. We visualize the generated meshes and normal vectors. MeshXL is able to produce high-quality 3D meshes with both sharp edges and smooth surfaces.

🔼 This figure shows a gallery of additional 3D mesh generation results produced by the MeshXL model. The results demonstrate the model’s ability to generate diverse and high-quality 3D meshes for various object categories, including chairs, tables, lamps, and benches.
read the caption
Figure 8: Gallery results. Additional generation results for chair, table, lamp, and bench.

🔼 This figure shows a gallery of 3D meshes generated by the MeshXL model. The variety of shapes and styles demonstrates the model’s ability to produce diverse and high-quality outputs, ranging from simple objects to more complex structures. This visual representation highlights the model’s capability in generating realistic and detailed 3D models.
read the caption
Figure 9: Gallery results. MeshXL is able to produce diverse 3D meshes with high quality.
More on tables
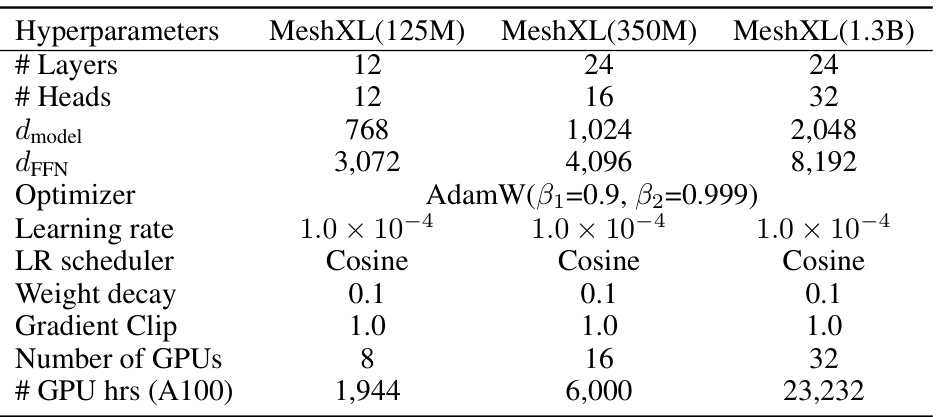
🔼 This table lists the hyperparameters used to train three different MeshXL models. The models vary in size, with 125 million, 350 million, and 1.3 billion parameters, respectively. The hyperparameters shown include the number of layers and heads, the model dimension (d_model), the feedforward network dimension (d_FFN), the optimizer (AdamW), the learning rate, the learning rate scheduler (cosine annealing), weight decay, gradient clipping, the number of GPUs used for training, and the total GPU hours used (on A100 GPUs).
read the caption
Table 2: Hyperparameters for different MeshXL Base Models. We present three MeshXL models with 125M, 350M, and 1.3B parameters, respectively.
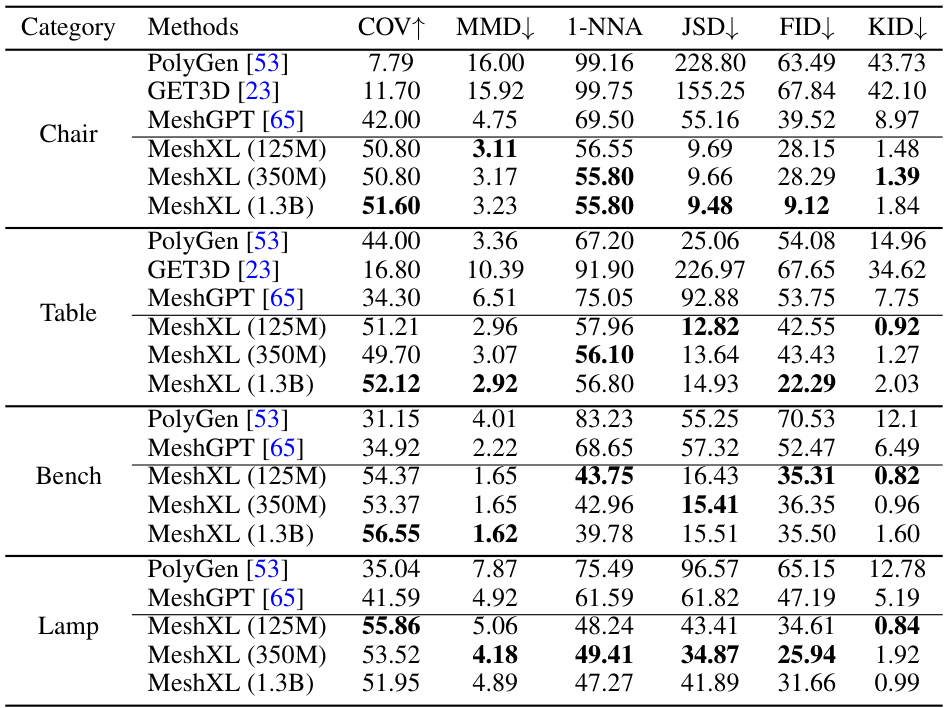
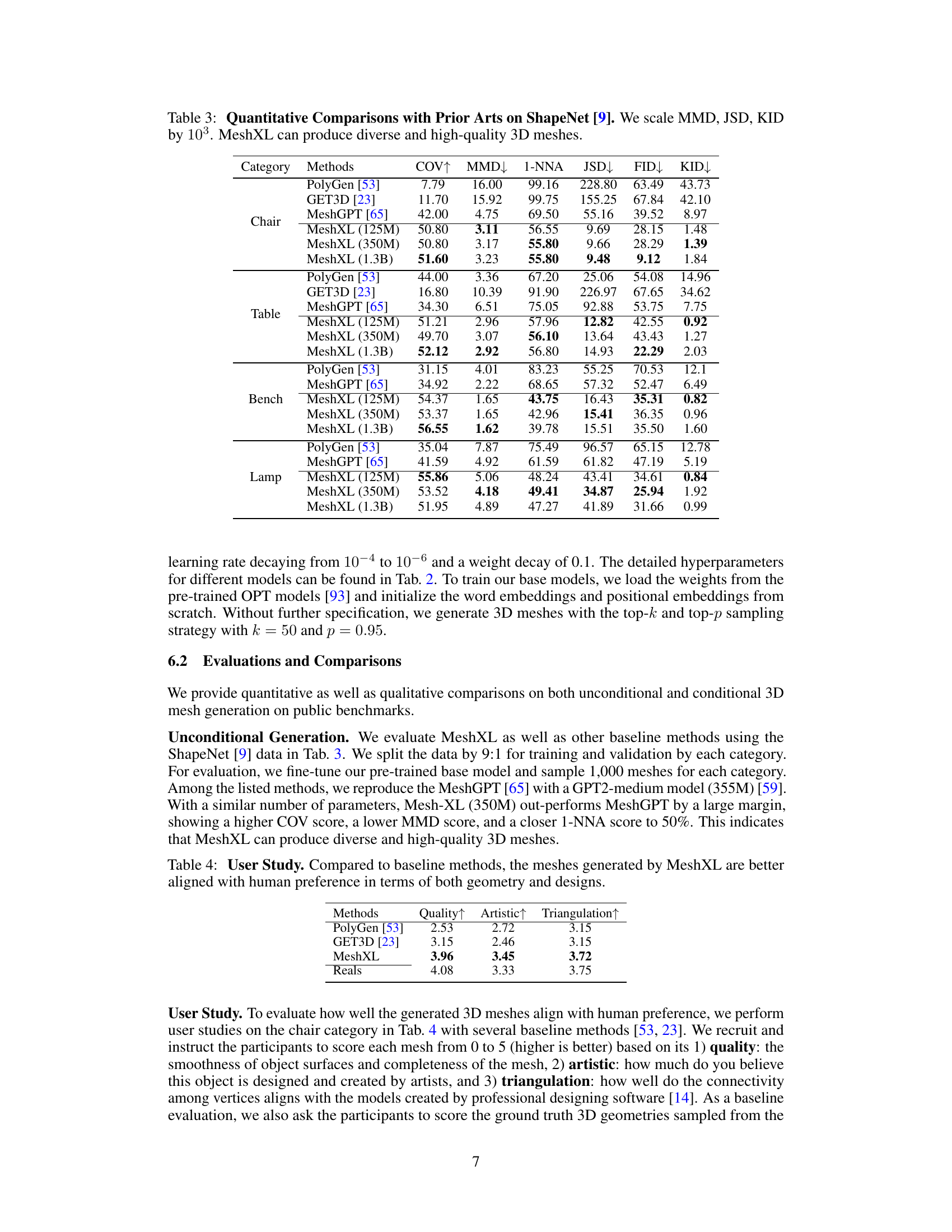
🔼 This table presents a quantitative comparison of MeshXL with other state-of-the-art methods on the ShapeNet dataset. The comparison focuses on several key metrics: Coverage (COV), which measures the diversity of generated meshes; Minimum Matching Distance (MMD), which represents the average distance to the nearest neighbor in the reference set; 1-Nearest Neighbor Accuracy (1-NNA), indicating the quality and diversity of the generated set compared to the reference set; Jensen-Shannon Divergence (JSD), assessing the similarity between distributions; and Frechet Inception Distance (FID) and Kernel Inception Distance (KID), measuring the visual similarity using rendered images. Lower MMD, JSD, and KID scores indicate better generation quality, while a higher COV score and an 1-NNA score closer to 50% suggest better diversity. The results demonstrate that MeshXL, particularly the larger models, generally outperforms previous methods across most categories.
read the caption
Table 3: Quantitative Comparisons with Prior Arts on ShapeNet [9]. We scale MMD, JSD, KID by 103. MeshXL can produce diverse and high-quality 3D meshes.
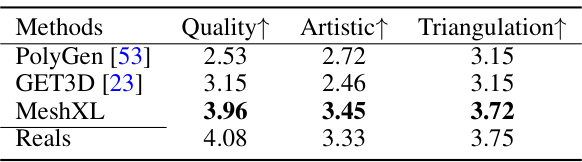
🔼 This table presents the results of a user study comparing the quality of 3D meshes generated by MeshXL to those generated by other state-of-the-art methods. Participants rated the meshes on three criteria: Quality, Artistic, and Triangulation. The results show that MeshXL outperforms the baselines on all three criteria, indicating that its generated meshes are both higher quality and more aesthetically pleasing.
read the caption
Table 4: User Study. Compared to baseline methods, the meshes generated by MeshXL are better aligned with human preference in terms of both geometry and designs.

🔼 This table presents the results of experiments evaluating the effectiveness of different model sizes (125M, 350M, and 1.3B parameters) of the MeshXL model on the Objaverse dataset. The metrics used to evaluate the model’s performance are Coverage (COV), Minimum Matching Distance (MMD), 1-Nearest Neighbor Accuracy (1-NNA), Jensen-Shannon Divergence (JSD), Fréchet Inception Distance (FID), and Kernel Inception Distance (KID). The results show that larger models generally achieve better performance across all metrics, indicating improved diversity and quality of generated 3D meshes.
read the caption
Table 5: Effectiveness of Model Sizes on Objaverse. As the model size grows, MeshXL achieves a closer 1-NNA to 50%, a larger COV and a smaller JSD, indicating better diversity and quality.

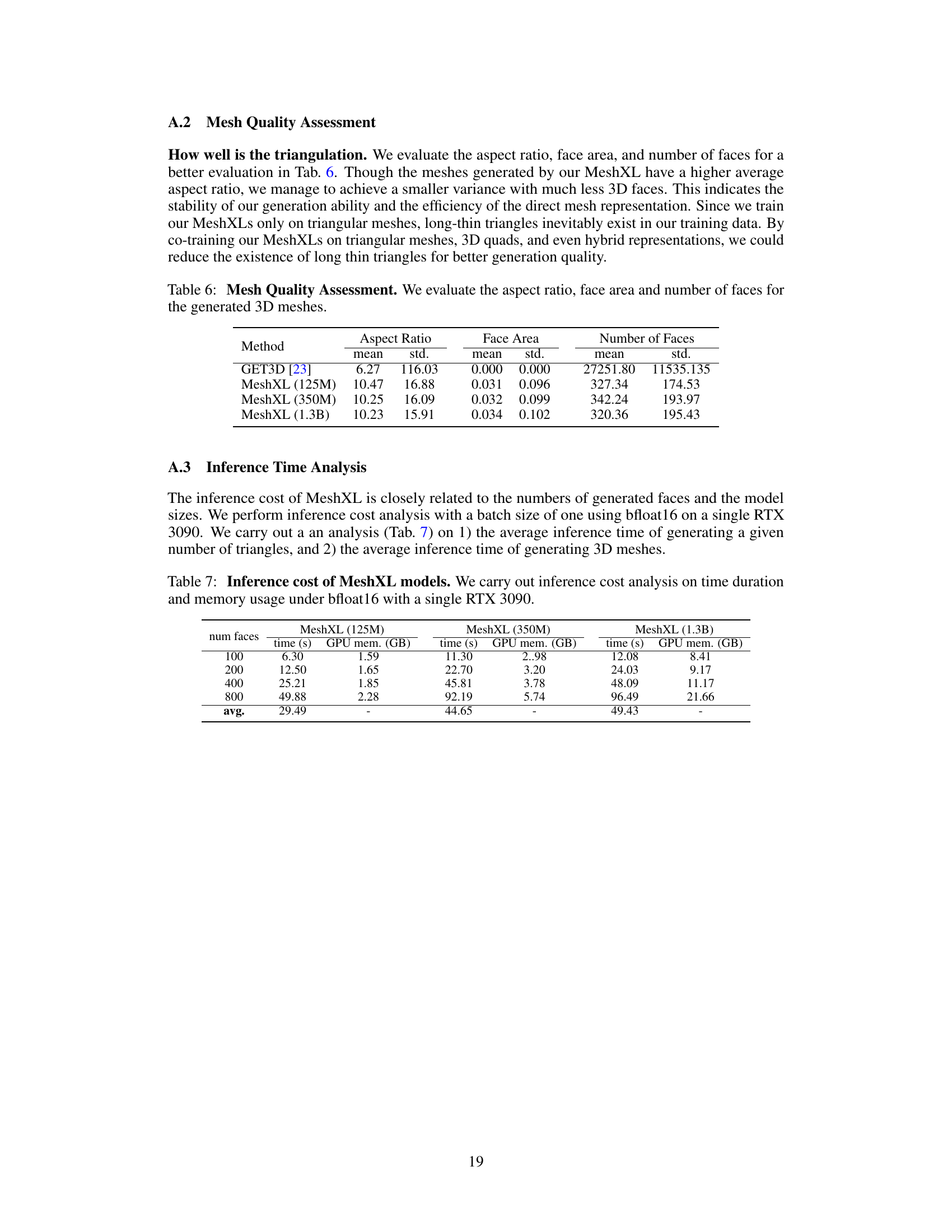
🔼 This table compares the mesh quality of 3D models generated by GET3D and MeshXL models with different sizes (125M, 350M, 1.3B parameters). The quality is assessed based on three metrics: aspect ratio (the ratio of the longest edge to the shortest edge of a triangle), face area (average area of the triangles), and the number of faces (total number of faces in the mesh). The results show that while MeshXL models have a higher average aspect ratio, they also have a significantly smaller variance and fewer faces, suggesting a more stable and efficient mesh generation process.
read the caption
Table 6: Mesh Quality Assessment. We evaluate the aspect ratio, face area and number of faces for the generated 3D meshes.

🔼 This table presents the inference time and GPU memory usage for MeshXL models of different sizes (125M, 350M, and 1.3B parameters) when generating 3D meshes with varying numbers of faces (100, 200, 400, and 800). The results are measured in seconds and gigabytes (GB) and show how these resource requirements scale with model size and mesh complexity.
read the caption
Table 7: Inference cost of MeshXL models. We carry out inference cost analysis on time duration and memory usage under bfloat16 with a single RTX 3090.
Full paper#