TL;DR#
Few-shot semantic segmentation struggles with cross-domain scenarios due to significant domain gaps between source and target datasets. Existing methods often fail to generalize well to unseen target domains. This paper explores a novel approach focusing on frequency components of images. It observes that filtering specific frequencies significantly improves segmentation accuracy, sometimes as much as 14%.
The researchers propose a lightweight frequency masker comprising an Amplitude-Phase Masker (APM) and an Adaptive Channel Phase Attention (ACPA) module. APM effectively reduces inter-channel correlation while ACPA enhances channel disentanglement, leading to improved robustness and larger activated regions for segmentation. The method is simple, effective, and requires minimal parameter addition, achieving state-of-the-art results on benchmark datasets. The lightweight design makes it suitable for deployment on resource-constrained devices.
Key Takeaways#
Why does it matter?#
This paper is important because it tackles the challenge of cross-domain few-shot semantic segmentation, a critical issue in computer vision. By introducing a simple yet effective frequency filtering method, the research offers a significant performance boost and new insights into how frequency components affect model generalization and robustness. The findings are relevant to various computer vision tasks and could inspire further research into frequency-based feature engineering and domain adaptation techniques.
Visual Insights#
🔼 This figure shows the impact of filtering different frequency components (phase and amplitude, high and low frequencies) on the performance of a model already trained on the source domain when tested on four different target domains. The results demonstrate that simply filtering certain frequency components significantly improves performance, with the highest improvement reaching 14% mIoU in one case. This observation motivates the research into the lightweight frequency masker proposed in the paper.
read the caption
Figure 1: For a model already trained on the source domain, we simply filter out different frequency components and plot mIoU against the maintained ones of images. P denotes Phase, A denotes Amplitude, H denotes High Frequency, and L denotes Low Frequency. We can see the performance is significantly improved in most cases compared with the baseline (Ax, Px), even as high as 14% on the Chest X-ray dataset (AL, P₄). In this paper, we delve into this phenomenon for an interpretation, and propose a lightweight frequency masker for efficient cross-domain few-shot segmentation.

🔼 This table presents the mutual information (MI) between feature channels for the best-performing and worst-performing frequency combinations shown in Figure 1 of the paper. The MI values are given for both the support and query images in a one-shot few-shot segmentation task. The table demonstrates that lower MI (reduced inter-channel correlation) is associated with improved segmentation performance, suggesting that feature disentanglement benefits cross-domain few-shot segmentation.
read the caption
Table 1: Mutual information between feature channels for the best and the worst cases in Fig. 1. We find that mutual information (MI) consistently decreases when the performance is improved.
In-depth insights#
Freq. Masker Effects#
The heading ‘Freq. Masker Effects’ suggests an exploration of how a frequency masking technique impacts various aspects of a system. A thoughtful analysis would investigate how different frequency components are treated by the masker, exploring the effects on signal fidelity, noise reduction, and feature extraction. The effectiveness of the mask is likely measured against baseline performance, and this comparison would be a central part of the discussion. Key aspects would include the impact on signal-to-noise ratio, preservation of crucial frequency bands, and the potential for artifacts or distortions introduced by the masking process. A sophisticated analysis would also address the computational cost of the frequency masking operation, and its impact on real-time applications. It’s also important to examine the generalizability of these effects across different datasets or domains, considering the potential variations in the frequency characteristics of various data types. The robustness of the frequency masking method under different conditions would also warrant investigation, perhaps evaluating its sensitivity to parameter changes or noise levels.
CD-FSS Enhancements#
CD-FSS Enhancements represent a crucial area in bridging the domain gap in few-shot semantic segmentation. Effective strategies focus on improving the model’s robustness and adaptability to unseen target domains. This may involve techniques that disentangle feature representations, mitigating the negative effects of domain shift on feature correlations. Lightweight frequency-based methods have shown promise by selectively filtering frequency components that either hinder cross-domain performance or enhance the model’s generalization capabilities. Amplitude-Phase Masker (APM) and Adaptive Channel Phase Attention (ACPA) modules are examples of such techniques that address these issues with minimal computational overhead. Improved channel disentanglement and larger activated regions for segmentation are key benefits derived from these frequency-domain manipulations, leading to significant performance gains. Future research directions should explore more sophisticated frequency filtering approaches and the potential of integrating frequency-based methods with other domain adaptation techniques to further enhance CD-FSS performance.
Channel Disentanglement#
Channel disentanglement, a crucial concept in deep learning, focuses on decorrelating feature channels within a neural network’s feature maps. This process aims to improve model interpretability and robustness by ensuring that each channel represents a distinct and independent feature. Reduced inter-channel correlation enhances the model’s ability to generalize across different domains by mitigating redundancy and promoting the learning of more diverse semantic patterns. Furthermore, disentangled channels facilitate the detection of larger, more comprehensive regions of interest during segmentation tasks, as each channel contributes unique information without overlapping with other channels. Frequency filtering has emerged as a powerful technique to achieve channel disentanglement; by selectively modifying frequency components of input images, we can effectively decouple channels. This approach demonstrates that the frequency domain offers a powerful way to manipulate and control channel interactions, resulting in models that are more robust to domain shifts and more accurate in their predictions. Ultimately, the goal of channel disentanglement is to improve both the efficiency and the effectiveness of deep learning models, resulting in improved performance on various tasks.
APM & ACPA Modules#
The Amplitude-Phase Masker (APM) and Adaptive Channel Phase Attention (ACPA) modules represent a novel approach to enhancing cross-domain few-shot segmentation. APM directly addresses the challenge of domain shift by operating in the frequency domain, effectively disentangling feature channels and reducing inter-channel correlation. This disentanglement improves robustness by enabling the model to capture a wider range of semantic patterns. Crucially, APM is lightweight, adding minimal computational overhead. The ACPA module further refines this process by selectively focusing on channels containing the most informative phase information, thereby aligning the feature representations of support and query sets. This dual approach synergistically enhances performance, significantly outperforming state-of-the-art methods while remaining computationally efficient. The effectiveness of both modules is clearly demonstrated through experimental results and supported by mathematical derivations, highlighting their significant contribution to the field of few-shot learning.
Future Work#
The paper’s core contribution is a lightweight frequency masker for cross-domain few-shot semantic segmentation. Future work could focus on several promising directions. First, exploring more sophisticated frequency filtering techniques beyond simple amplitude and phase masking could yield further performance gains. Adaptive frequency filtering based on the specific characteristics of the target domain would be particularly valuable. Second, the current method uses a fixed encoder trained on a source domain. Investigating the benefits of incorporating a domain-adaptive encoder or a more advanced meta-learning framework to improve generalization could significantly enhance its robustness. Expanding the dataset size and diversity, particularly for the target domains, would allow for better model training and evaluation. Finally, investigating the applicability of the proposed approach to other few-shot learning tasks, such as few-shot object detection and few-shot image classification, would demonstrate its broader impact and utility.
More visual insights#
More on figures

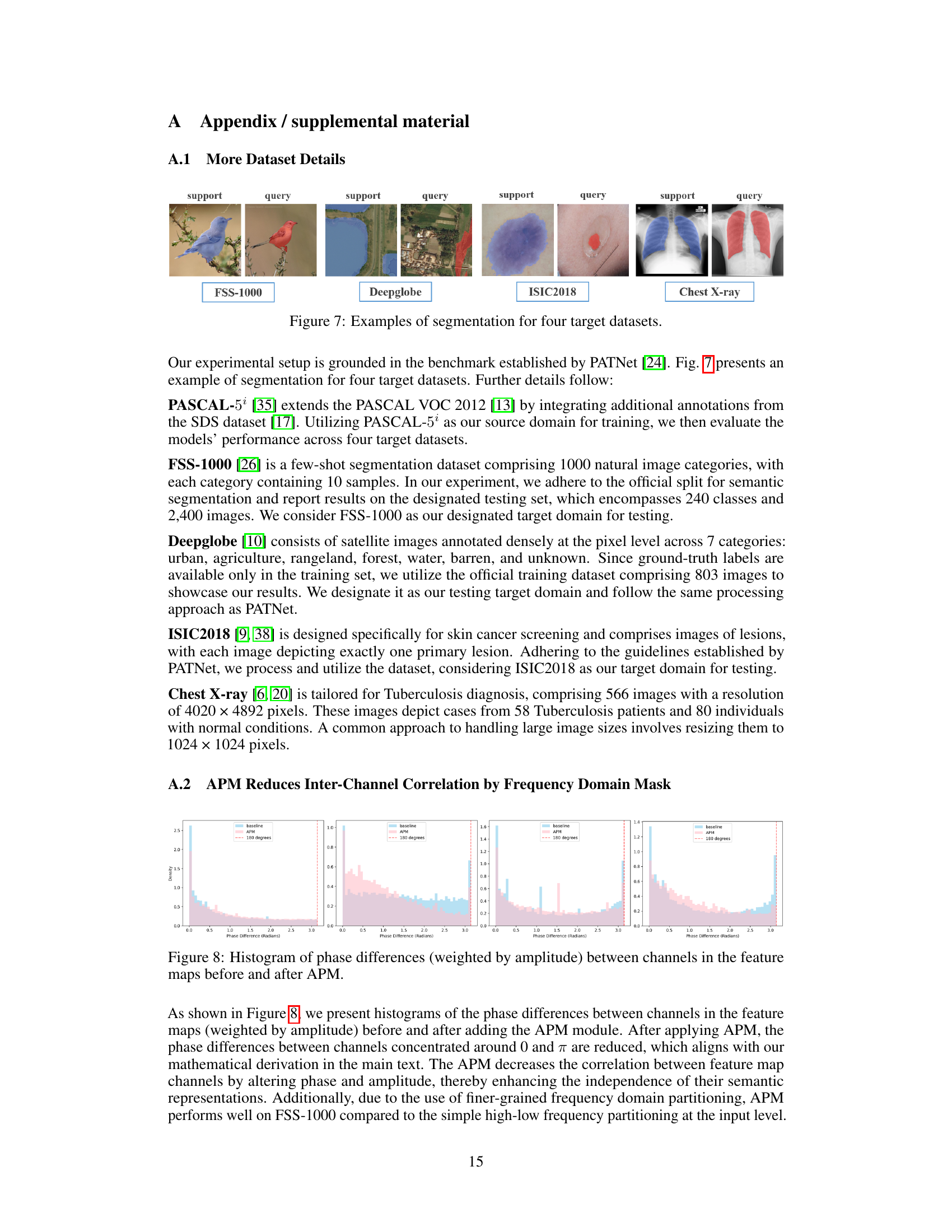
🔼 This figure displays the Mean Magnitude of Channels (MMC) for the best-performing frequency filtering scenario from Figure 1, across four different datasets. The MMC represents the average magnitude of activation across all channels within the feature maps for each image in the datasets. The graph plots the MMC values against the channel index. By comparing the MMC curves with and without frequency masking, it demonstrates that for datasets where the masking improved performance, the resulting MMC curve is lower, indicating a more uniform activation across channels after filtering. This uniformity across channels suggests a reduction in channel redundancy and improved generalizability.
read the caption
Figure 2: Mean Magnitude of Channels (MMC) for the best case in Fig. 1 on four target datasets. For domains with improved performance, their curves are lower than the baseline after masking.
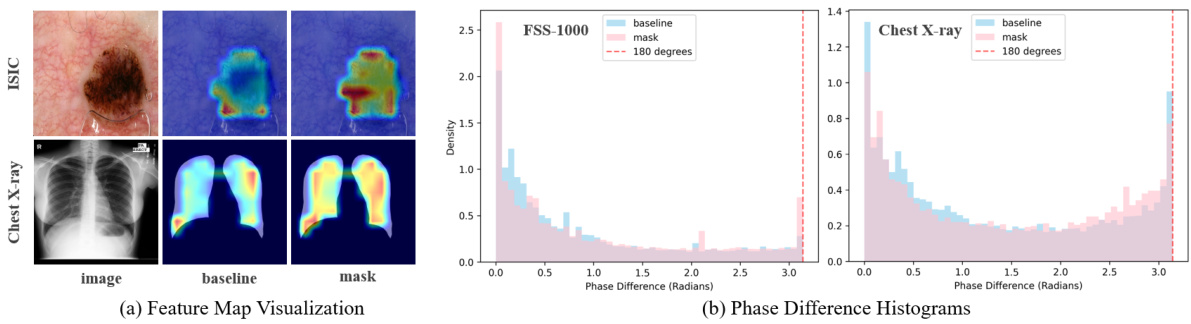
🔼 This figure presents results supporting the paper’s claim that filtering frequency components improves performance in cross-domain few-shot segmentation. Part (a) shows visualizations of feature maps, illustrating that after masking certain frequencies, the model’s attention focuses on a larger area, encompassing more object features. Part (b) shows phase difference histograms. It demonstrates that a high concentration of phase differences around 0 and π (indicating high correlation between channels) is associated with decreased performance on the FSS-1000 dataset but improved performance on the Chest X-ray dataset.
read the caption
Figure 3: (a) After masking certain frequency components, the model's attention regions are enlarged with more patterns encompassed. (b) A higher concentration of phase differences at 0 and π indicates a higher correlation, so that on FSS-1000 the performance drops but on Chest X-ray it increases.

🔼 This figure illustrates the proposed method’s architecture for a one-shot learning scenario. It shows how the feature map is processed through the Amplitude-Phase Masker (APM) and the Adaptive Channel Phase Attention (ACPA) modules. APM filters out negative frequency components adaptively based on the domain, improving feature representation. ACPA selects the most effective features by aligning the feature spaces of the support and query. The comparison module generates affinity maps used by the decoder to generate the final segmentation results.
read the caption
Figure 4: Overview of our method in a 1-shot example. After obtaining the feature map, APM is introduced to adaptively filter certain frequency components based on different domains, facilitating feature disentanglement to achieve more generalizable representations. Additionally, we propose ACPA to encourage the model to focus on more effective features while aligning the feature space of the support and query images. The internal structure of APM and ACPA is highlighted in green.
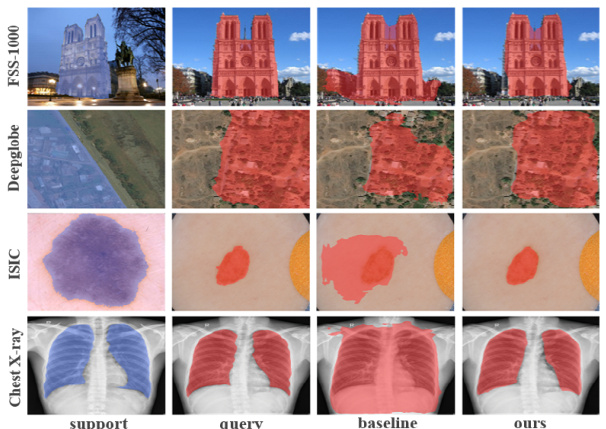
🔼 This figure shows qualitative results of the proposed method on four datasets (FSS-1000, Deepglobe, ISIC, and Chest X-ray) for both 1-shot and 5-shot settings. It compares the segmentation results of the proposed method against a baseline method, demonstrating significant improvement in generalization across different domains. The mIoU scores for APM-M are also provided, showing its superiority over the state-of-the-art.
read the caption
Figure 5: Qualitative results of our model. mIoU for the 1-shot and 5-shot settings, respectively. APM-M outperforms the state-of-the-art by 3.97% and 3.19%. Additionally, Figure 5 presents qualitative results of our method in 1-way 1-shot segmentation, highlighting a substantial enhancement in generalization across large domain gaps while maintaining comparable accuracy with similar domain shifts.

🔼 This figure shows four cumulative distribution function (CDF) plots, one for each of the four target datasets (FSS-1000, Deepglobe, ISIC, and Chest X-ray). Each plot compares the CDF of inter-channel correlations before and after applying the Amplitude-Phase Masker (APM) module. The plots show that applying the APM consistently shifts the CDF curves to the left. This indicates that the APM effectively reduces the inter-channel correlation in the feature maps, which is a key finding of the paper. The reduction of inter-channel correlation is beneficial because it improves the model’s generalizability and allows it to capture more distinct features for semantic segmentation.
read the caption
Figure 6: Cumulative distribution function (CDF) of inter-channel correlations. After passing through APM, the CDF curve shifts to the left, indicating a decrease in inter-channel correlations.

🔼 This figure shows the effects of frequency masking on the model’s attention and phase differences. Subfigure (a) presents heatmaps visualizing how masking expands the activation regions for the model and encompasses more patterns. Subfigure (b) displays histograms of phase differences between channels. This shows how the masking operation changes inter-channel correlation, leading to improved performance in some domains but decreased performance in others, particularly FSS-1000.
read the caption
Figure 3: (a) After masking certain frequency components, the model's attention regions are enlarged with more patterns encompassed. (b) A higher concentration of phase differences at 0 and π indicates a higher correlation, so that on FSS-1000 the performance drops but on Chest X-ray it increases.

🔼 This figure shows qualitative results of the proposed method on four different datasets, demonstrating its effectiveness in few-shot semantic segmentation across domains. It compares the model’s performance (measured by mean Intersection over Union or mIoU) in 1-shot and 5-shot scenarios, highlighting the superiority of APM-M over the state-of-the-art methods by substantial margins. The visualization clearly showcases the model’s ability to generalize well across different domains while preserving reasonable accuracy.
read the caption
Figure 5: Qualitative results of our model. mIoU for the 1-shot and 5-shot settings, respectively. APM-M outperforms the state-of-the-art by 3.97% and 3.19%. Additionally, Figure 5 presents qualitative results of our method in 1-way 1-shot segmentation, highlighting a substantial enhancement in generalization across large domain gaps while maintaining comparable accuracy with similar domain shifts.

🔼 This figure shows two subfigures. Subfigure (a) visualizes the heatmaps of feature maps to show how the attention regions of the model are expanded after masking certain frequency components. Subfigure (b) shows histograms of phase differences between channels to indicate correlation changes by frequency filtering. It shows that reduced correlation is linked to better performance, specifically for Chest X-ray but not FSS-1000. The results validate the mathematical derivation showing how phase differences in the frequency domain relate to channel correlation in the spatial domain.
read the caption
Figure 3: (a) After masking certain frequency components, the model's attention regions are enlarged with more patterns encompassed. (b) A higher concentration of phase differences at 0 and π indicates a higher correlation, so that on FSS-1000 the performance drops but on Chest X-ray it increases.

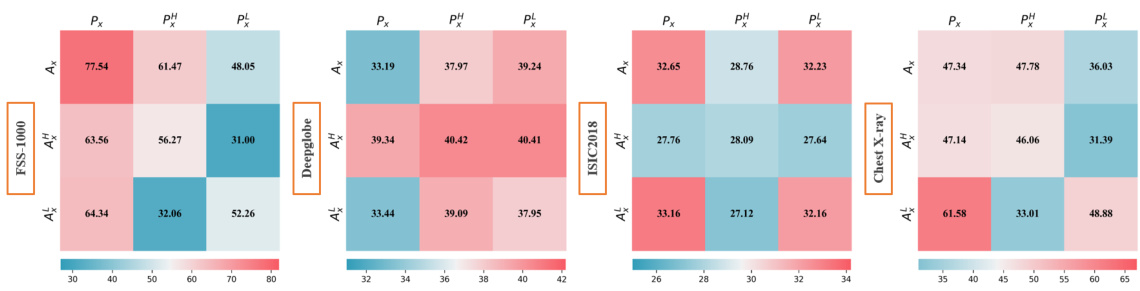
🔼 The figure visualizes the frequency components filtered by the Amplitude-Phase Masker (APM) across four different datasets: FSS-1000, Deepglobe, ISIC, and ChestX-ray. The top row shows the amplitude components, and the bottom row shows the phase components. The center of each image represents low frequencies, while the periphery represents high frequencies. White indicates that the frequency component is allowed to pass through, while black indicates that it is filtered out. The variation in the visualizations across the different datasets highlights how the APM adapts its filtering of frequency components to the specific characteristics of each dataset.
read the caption
Figure 9: The visualization of the frequency components filtered by the masker.
More on tables

🔼 This table presents the mean Intersection over Union (mIoU) scores achieved by various methods on four different cross-domain few-shot segmentation (CD-FSS) benchmark datasets. The results are shown for both 1-shot and 5-shot scenarios. The best and second-best performing methods for each dataset and setting are highlighted. The table also notes that APM-S uses a smaller parameter size than APM-M.
read the caption
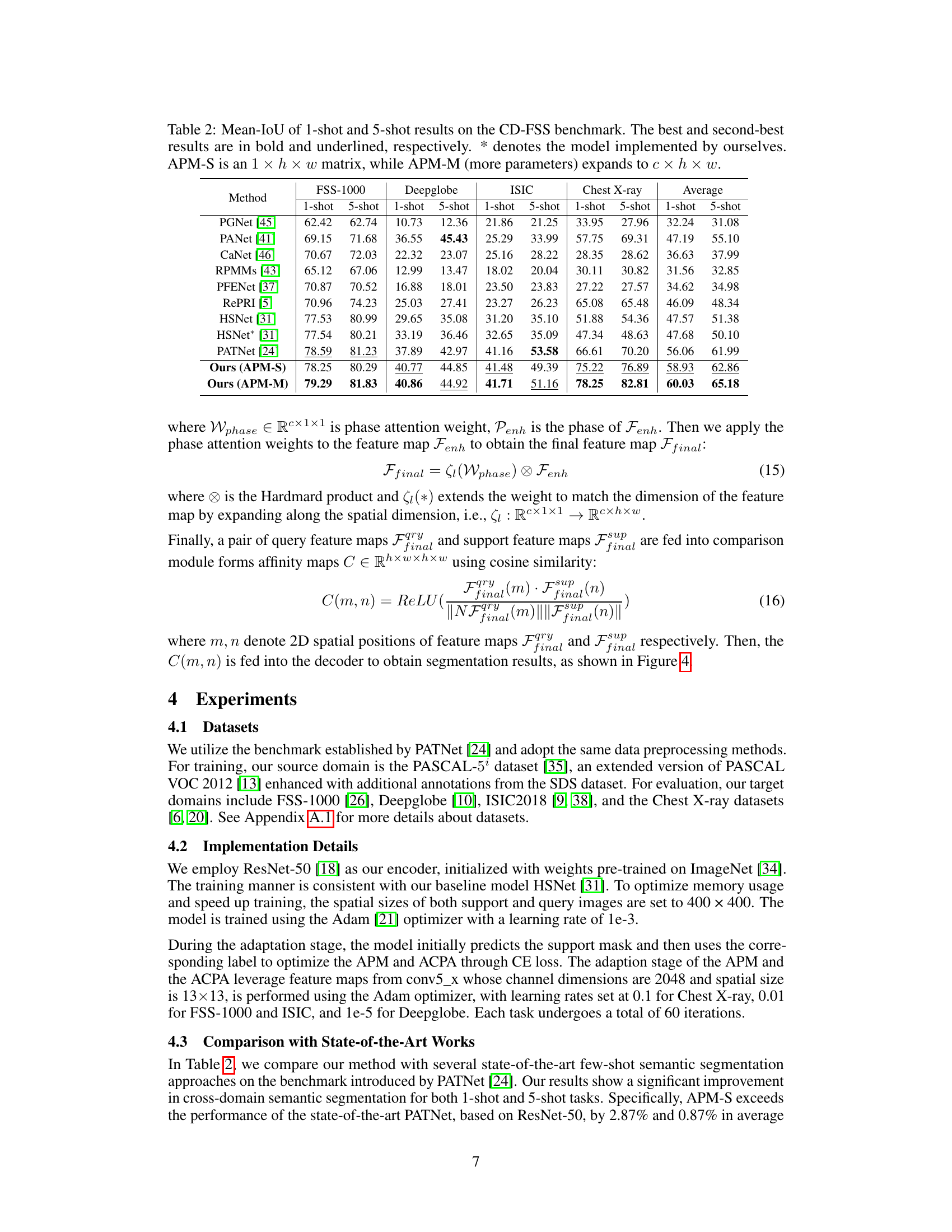
Table 2: Mean-IoU of 1-shot and 5-shot results on the CD-FSS benchmark. The best and second-best results are in bold and underlined, respectively. * denotes the model implemented by ourselves. APM-S is an 1 × h × w matrix, while APM-M (more parameters) expands to c × h × w.
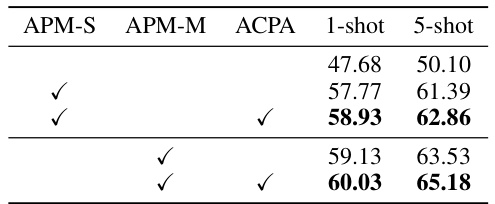
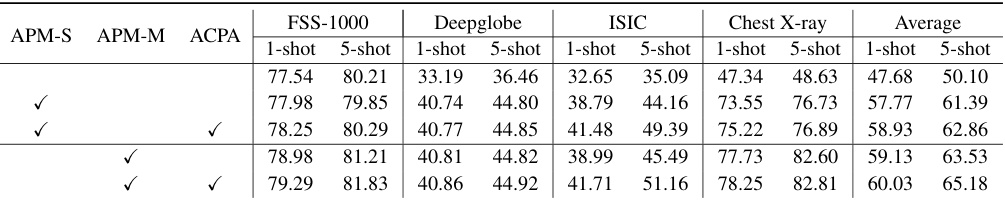
🔼 This table presents the ablation study results on different model variations. It shows the impact of including the Amplitude-Phase Masker (APM) and the Adaptive Channel Phase Attention (ACPA) modules on the 1-shot and 5-shot segmentation performance. APM-S and APM-M represent different configurations of the APM module, with APM-M having more parameters. The table demonstrates the incremental performance gains achieved by adding each module.
read the caption
Table 3: Ablation study on various designs
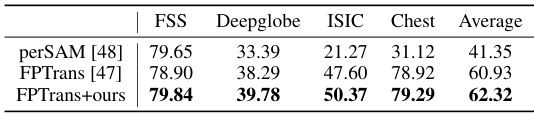
🔼 This table compares the performance of the proposed method (APM-S) integrated into a transformer-based architecture (FPTrans) against other methods. It shows that integrating APM-S into FPTrans improves performance on the Deepglobe, ISIC, and Chest X-ray datasets and gives a better average performance compared to FPTrans alone.
read the caption
Table 4: APM-S implemented in the transformer architecture.

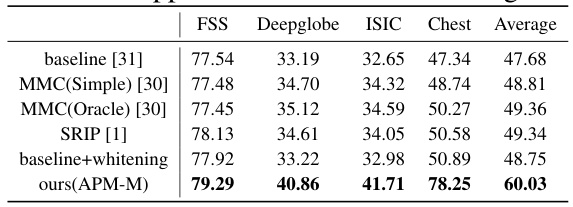
🔼 This table compares the performance of the proposed method (ours(APM-M)) against three other methods: a baseline method, a fine-tuned baseline, and a baseline with a mutual information loss added. The performance is measured on four datasets (FSS, Deepglobe, ISIC, Chest) and an average across the datasets. The results show that the proposed method significantly outperforms the other methods, highlighting its effectiveness in improving segmentation accuracy.
read the caption
Table 5: Compare our method with fine-tuning and spatial domain feature disentangle method.

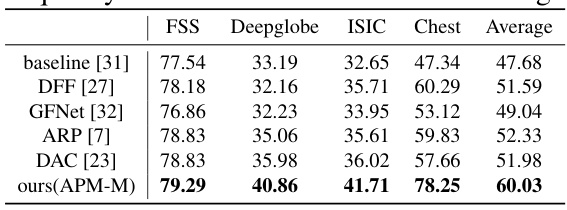
🔼 This table presents a detailed breakdown of the ablation study results for various designs of the proposed model, using ResNet-50 as the backbone. It shows the impact of different components (APM-S, APM-M, ACPA) on the 1-shot and 5-shot mIoU performance across four different datasets (FSS-1000, Deepglobe, ISIC, Chest X-ray). The table provides a quantitative assessment of each module’s contribution to the overall performance improvement.
read the caption
Table 10: Detailed ablation study results of various designs (Backbone: ResNet-50).
🔼 This table presents the mean Intersection over Union (mIoU) scores achieved by various methods on four different datasets for both 1-shot and 5-shot semantic segmentation tasks. The methods are compared on their performance in a cross-domain few-shot semantic segmentation (CD-FSS) setting. The best and second-best results are highlighted for each dataset and shot setting. The table also notes which models were implemented by the authors of the paper and details the size of the Amplitude-Phase Masker (APM) used by their method.
read the caption
Table 2: Mean-IoU of 1-shot and 5-shot results on the CD-FSS benchmark. The best and second-best results are in bold and underlined, respectively. * denotes the model implemented by ourselves. APM-S is an 1 × h × w matrix, while APM-M (more parameters) expands to c × h × w.
🔼 This table presents the mean Intersection over Union (mIoU) scores achieved by various methods on four different datasets for both 1-shot and 5-shot cross-domain few-shot semantic segmentation tasks. The methods compared include existing state-of-the-art approaches and the proposed method (with two variants: APM-S and APM-M). The table highlights the superior performance of the proposed method, especially APM-M, which shows significant improvement across all datasets.
read the caption
Table 2: Mean-IoU of 1-shot and 5-shot results on the CD-FSS benchmark. The best and second-best results are in bold and underlined, respectively. * denotes the model implemented by ourselves. APM-S is an 1 × h × w matrix, while APM-M (more parameters) expands to c × h × w.
🔼 This table presents the mean Intersection over Union (mIoU) scores achieved by various models on four different datasets for both 1-shot and 5-shot semantic segmentation tasks. It compares the proposed method (with APM-S and APM-M configurations) against several state-of-the-art (SOTA) cross-domain few-shot segmentation (CD-FSS) methods. The results highlight the performance improvement of the proposed method, especially when considering the minimal increase in the number of parameters.
read the caption
Table 2: Mean-IoU of 1-shot and 5-shot results on the CD-FSS benchmark. The best and second-best results are in bold and underlined, respectively. * denotes the model implemented by ourselves. APM-S is an 1 × h × w matrix, while APM-M (more parameters) expands to c × h × w.
Full paper#