TL;DR#
Current instruction tuning methods focus solely on optimizing model outputs, potentially leading to overfitting, especially with limited training data. This paper addresses this limitation by proposing INSTRUCTION MODELLING (IM), a novel approach that also incorporates loss calculation for instructions or prompts. This method is particularly beneficial when working with datasets characterized by lengthy instructions and short outputs, or in low-resource scenarios.
IM was evaluated on 21 diverse benchmarks, showcasing substantial performance improvements in many cases. The study identifies two key factors influencing IM’s effectiveness: the ratio between instruction and output lengths, and the number of training examples. Analysis suggests that IM’s improvements result from a reduction in overfitting to the instruction tuning dataset. The paper concludes by not suggesting IM as a replacement for existing methods, but rather as a helpful addition for improving the current instruction tuning techniques.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in NLP and LLMs because it offers practical guidance for instruction tuning, particularly in low-resource scenarios. It introduces a novel method, INSTRUCTION MODELLING, and identifies key factors affecting its effectiveness. This provides valuable insights for improving LLM performance and opens up new avenues for research on more efficient and effective fine-tuning techniques.
Visual Insights#
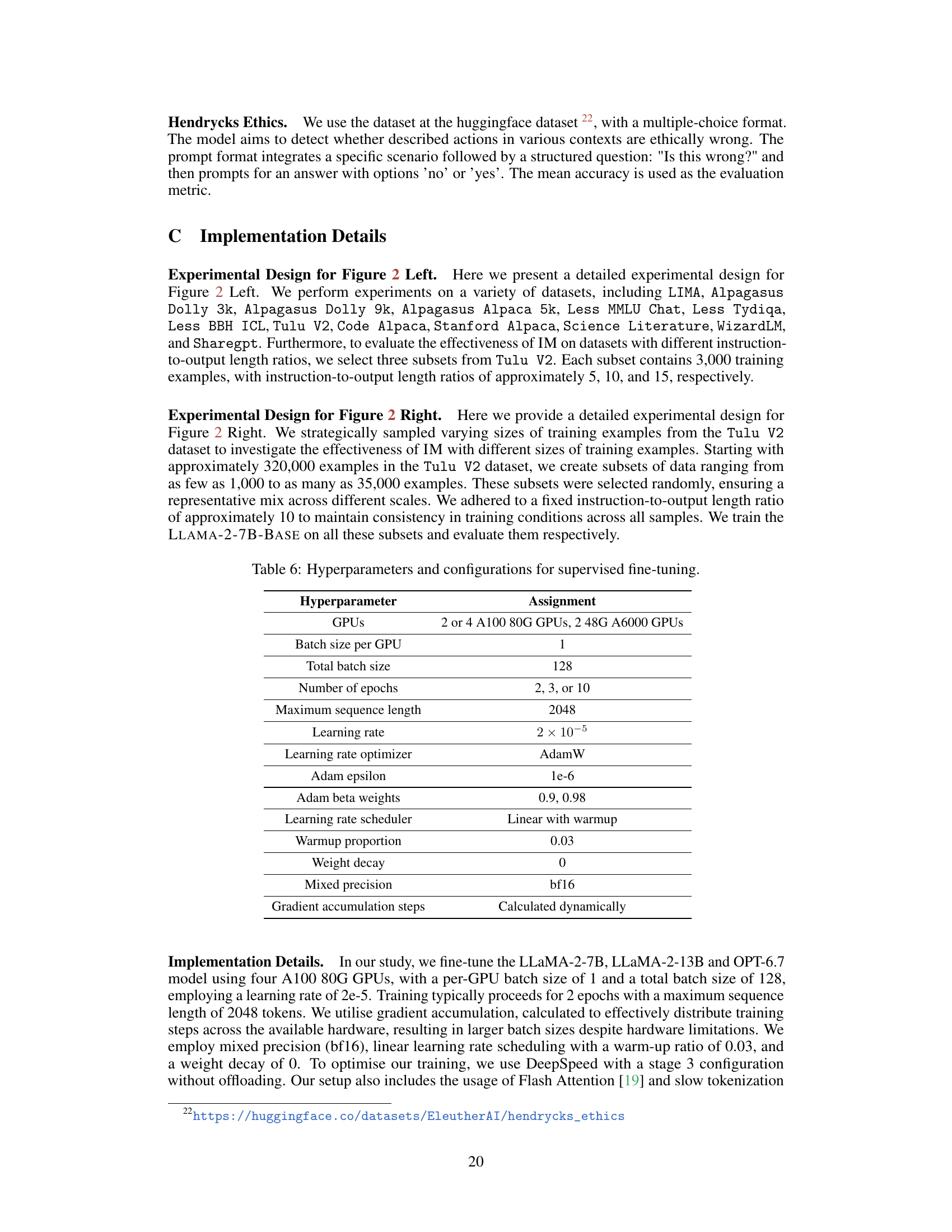
🔼 This figure compares the performance of Instruction Tuning (IT) and Instruction Modelling (IM) across various instruction tuning datasets. The left panel shows the mean performance difference between IT and IM across 18 traditional NLP tasks. The right panel shows the win rate difference between IT and IM on the AlpacaEval 1.0 benchmark. The figure highlights that IM generally outperforms IT, especially when trained on datasets with lengthy instructions and short outputs.
read the caption
Figure 1: Performance differences between INSTRUCTION TUNING (IT) and our proposed method INSTRUCTION MODELLING (IM) trained on 7 instruction tuning datasets. These datasets contain prompts and responses but do not contain preference pairs. Specifically, we use the Less datasets [68] and Alpagasus datasets [11], which are subsets of Flan V2 [14], Dolly [18], and Stanford Alpaca [61] to ensure good performance. We also report the results on the LIMA dataset. (Left) The mean performance across 18 traditional NLP tasks (see §4.1 for details). (Right) The win rate on the AlpacaEval 1.0 benchmark [37]. Please refer to §4.2 for details.
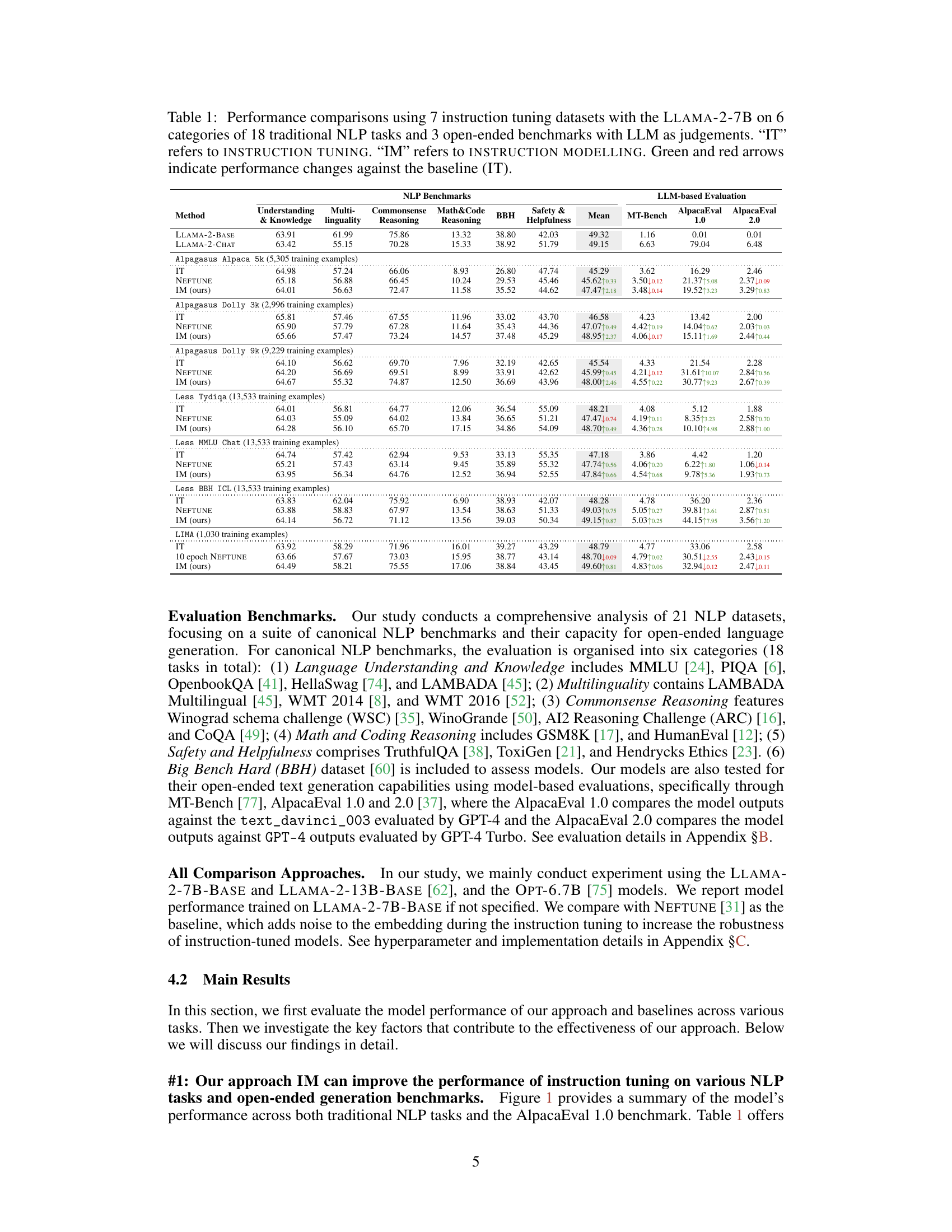
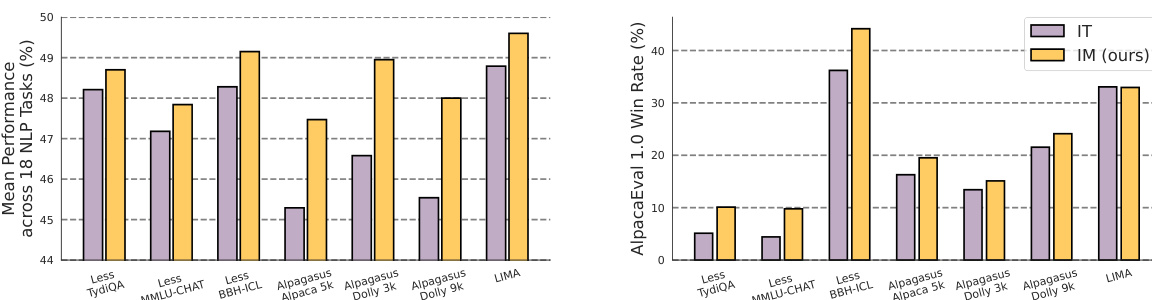
🔼 This table presents a comparison of the performance of Instruction Tuning (IT) and Instruction Modeling (IM) on 21 NLP datasets using the LLAMA-2-7B language model. The datasets are categorized into 6 groups of traditional NLP tasks and 3 open-ended benchmarks. Performance is measured using various metrics for each task category, and the table shows the mean performance across all tasks and for each specific task type. Green and red arrows indicate whether IM improved or worsened performance compared to the baseline (IT).
read the caption
Table 1: Performance comparisons using 7 instruction tuning datasets with the LLAMA-2-7B on 6 categories of 18 traditional NLP tasks and 3 open-ended benchmarks with LLM as judgements. “IT” refers to INSTRUCTION TUNING. 'IM' refers to INSTRUCTION MODELLING. Green and red arrows indicate performance changes against the baseline (IT).
In-depth insights#
IM: Loss Over Instructions#
The proposed method, Instruction Modelling (IM), introduces a novel approach to instruction tuning by incorporating loss over instructions, in addition to the loss over outputs. This is a significant departure from traditional Instruction Tuning (IT), which focuses solely on output loss. IM’s core innovation lies in its ability to improve the model’s understanding of both instructions and their corresponding outputs, leading to better performance across various NLP tasks and open-ended generation benchmarks. The experiments demonstrate that IM is especially beneficial in scenarios with lengthy instructions and short outputs, as well as under data-scarce conditions, showcasing its robustness and efficiency in low-resource settings. By considering loss over both instructions and outputs, IM effectively mitigates the problem of overfitting to training datasets, a common issue with IT, resulting in improved generalization capabilities. IM is not presented as a replacement for IT, but rather a complementary technique, offering valuable guidance in resource-constrained scenarios. Further investigation into the influence of instruction length and output length ratios, combined with the exploration of IM’s interaction with other instruction tuning techniques, promises further valuable insights in advancing language model training.
IM Effectiveness Factors#
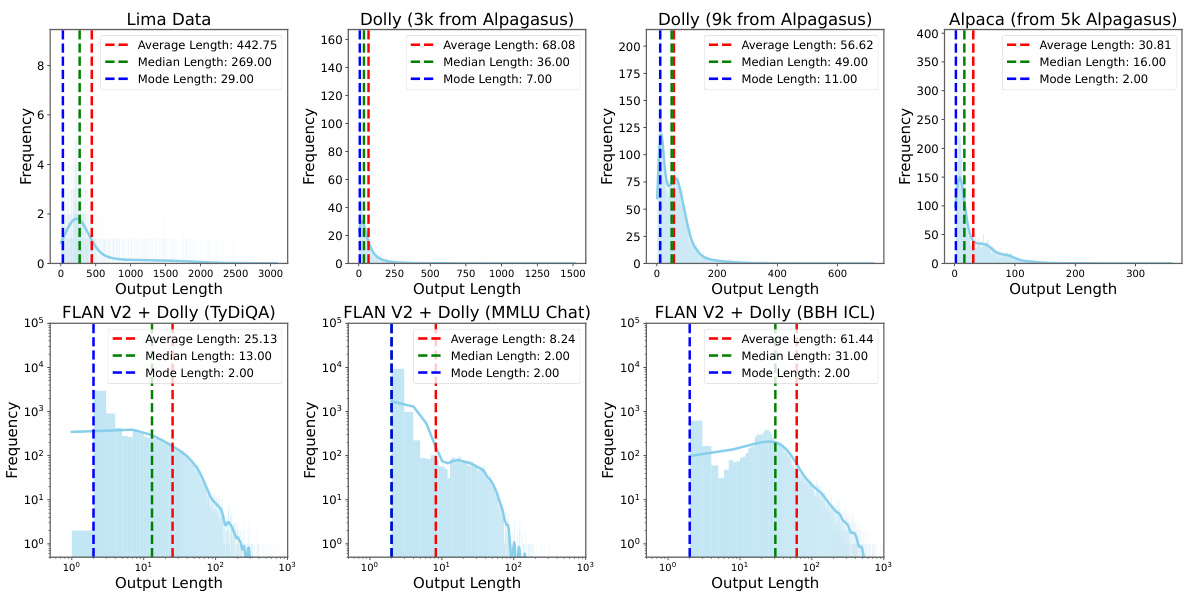
Analyzing the effectiveness of Instruction Modelling (IM), two key factors emerge: the ratio between instruction and output lengths in the training data, and the number of training examples. Longer instructions paired with shorter outputs, as seen in datasets like Code Alpaca, significantly benefit from IM, likely due to reduced overfitting to instruction-specific patterns. Conversely, IM’s advantage diminishes when output lengths are comparable to instruction lengths. The number of training examples also plays a crucial role. IM proves particularly effective in low-resource scenarios (Superficial Alignment Hypothesis), showcasing its robustness when training data is scarce. This suggests IM’s ability to mitigate overfitting, which is more pronounced with limited data, enhancing the model’s generalization capabilities. Therefore, tailoring the dataset based on these factors is crucial for maximizing IM’s performance.
Overfitting Mitigation#
The concept of overfitting mitigation is central to the success of Instruction Tuning (IT) in language models. The paper explores this, showing how simply applying a loss function to the instruction and prompt, rather than just the output (INSTRUCTION MODELLING or IM), helps reduce overfitting, particularly in low-resource scenarios. IM’s effectiveness is linked to the ratio of instruction to output length and the number of training examples: lengthy instructions paired with short outputs or fewer training examples, aligns better with the Superficial Alignment Hypothesis and shows significant improvements with IM. The mitigated overfitting is demonstrated through lower test losses despite higher training losses, lower BLEU scores (indicating less memorization of training data), and improved performance stability across training epochs. This suggests IM enhances generalization capabilities by encouraging the model to focus less on mimicking training data and more on understanding and following the instructions themselves. The findings underscore that while IM isn’t a replacement for IT, it offers a valuable strategy, especially when resources are limited, for better instruction tuning outcomes.
Low-Resource Tuning#
Low-resource tuning in NLP focuses on adapting large language models (LLMs) to perform well with limited training data. This is crucial because acquiring substantial, high-quality datasets can be expensive and time-consuming. Effective low-resource techniques are essential for democratizing access to advanced NLP capabilities, especially in low-resource languages or domains. Methods often involve techniques like data augmentation, to artificially increase the size of the training set, and transfer learning, leveraging knowledge from models trained on larger, related datasets. Careful selection of training data is also paramount to maximize performance with limited resources; this often involves filtering for high-quality examples and prioritizing informative instances. Instruction tuning, a popular method, helps align the model’s output to specific user instructions using a smaller number of examples. Successful low-resource methods generally involve a combination of these approaches to achieve satisfactory performance, which is vital to bridge the gap between resource-rich and resource-poor environments in NLP.
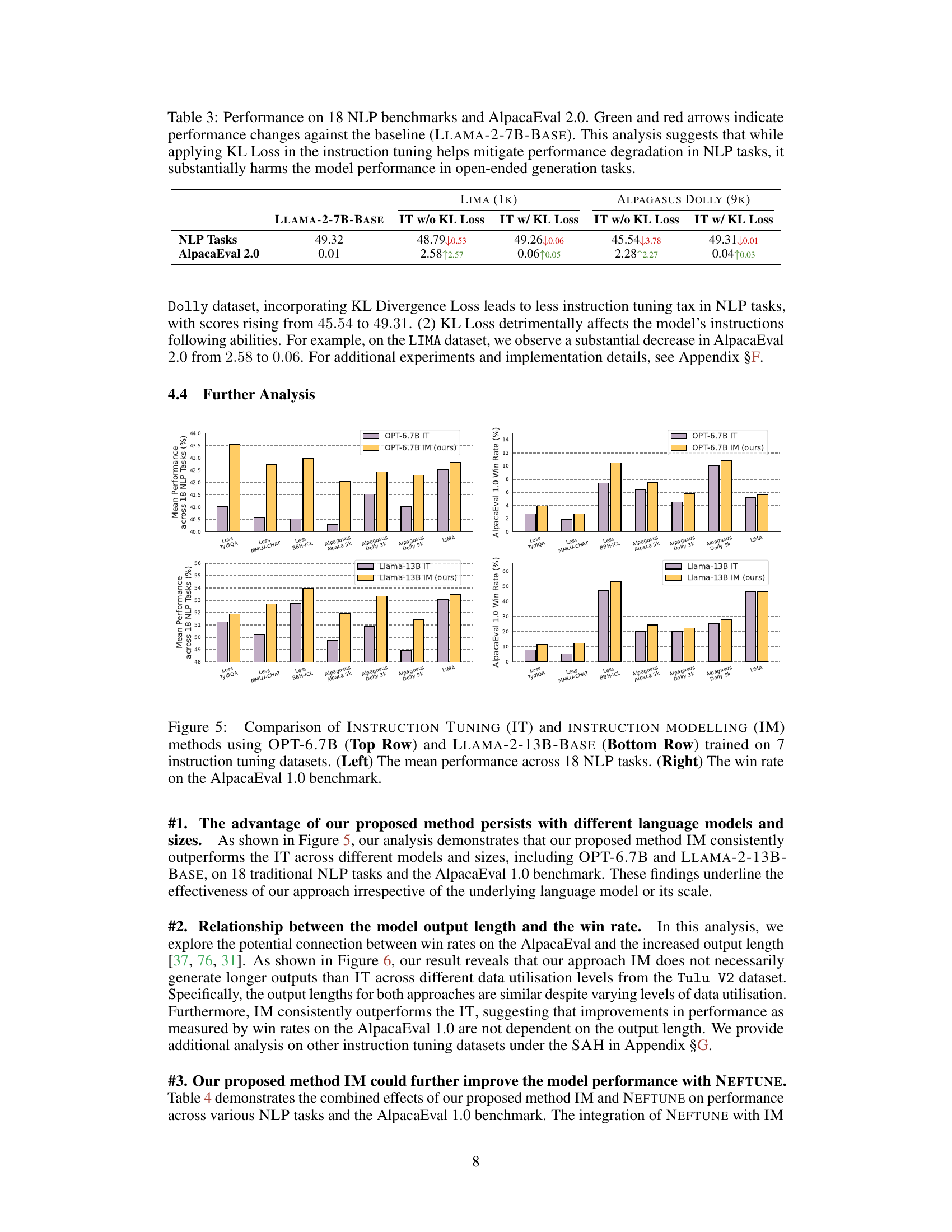
Future Work: KL Divergence#
Future research exploring KL divergence as a regulariser in instruction tuning presents exciting possibilities. Initial findings suggest that while KL divergence can mitigate overfitting on traditional NLP tasks, it can detrimentally impact performance on open-ended generation benchmarks. This highlights the nuanced relationship between regularisation strength and the specific characteristics of instruction-tuning datasets. Future work should investigate optimal KL divergence weighting strategies for various datasets, possibly incorporating adaptive methods that adjust weighting based on factors such as instruction and output length ratios. A more comprehensive exploration of the impact of KL divergence on model calibration and robustness is needed. It’s crucial to understand how different KL divergence implementations affect the balance between model fidelity to instructions and its ability to generate creative, diverse outputs. Furthermore, research could explore combining KL divergence with other regularisation techniques to achieve a superior balance between mitigating overfitting and preserving model capabilities.
More visual insights#
More on figures
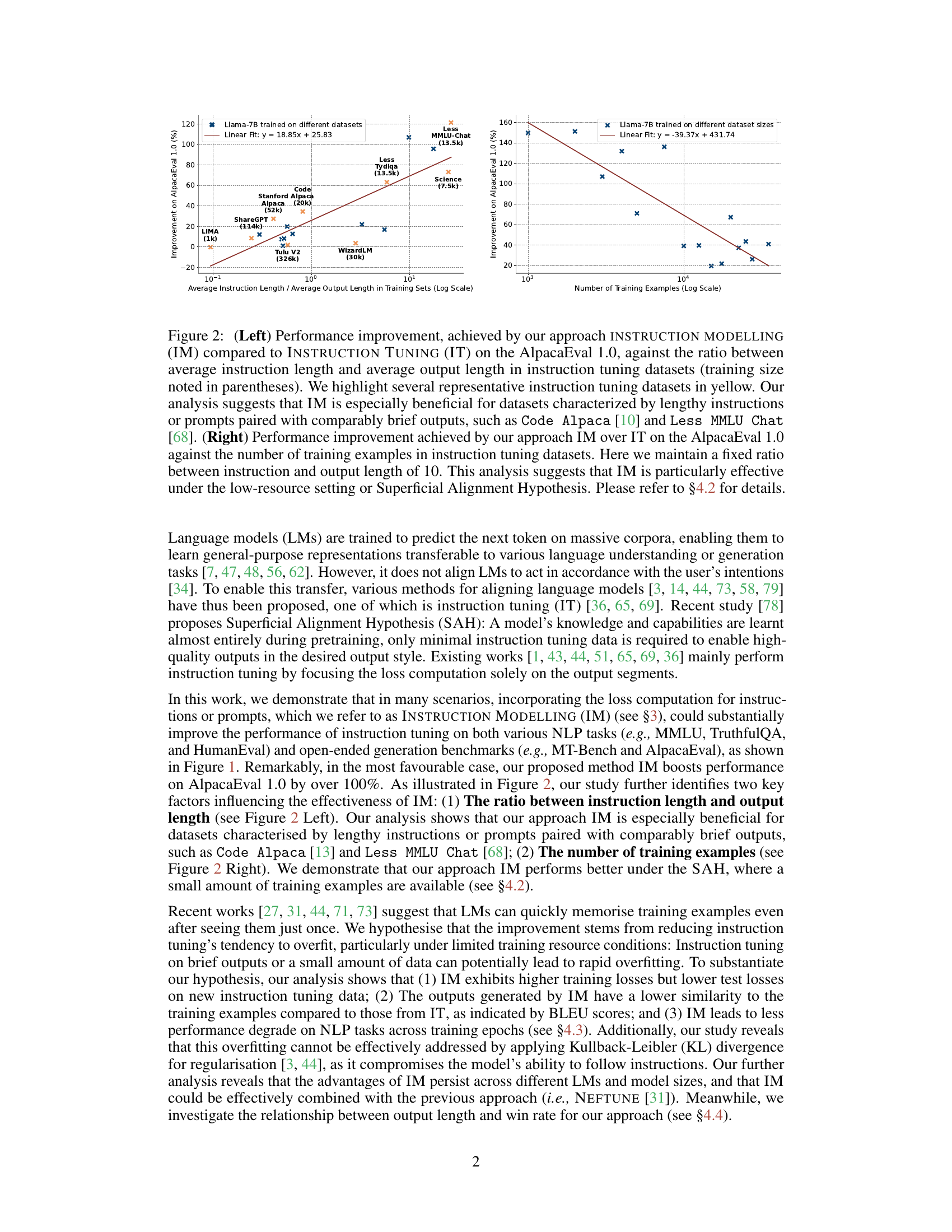
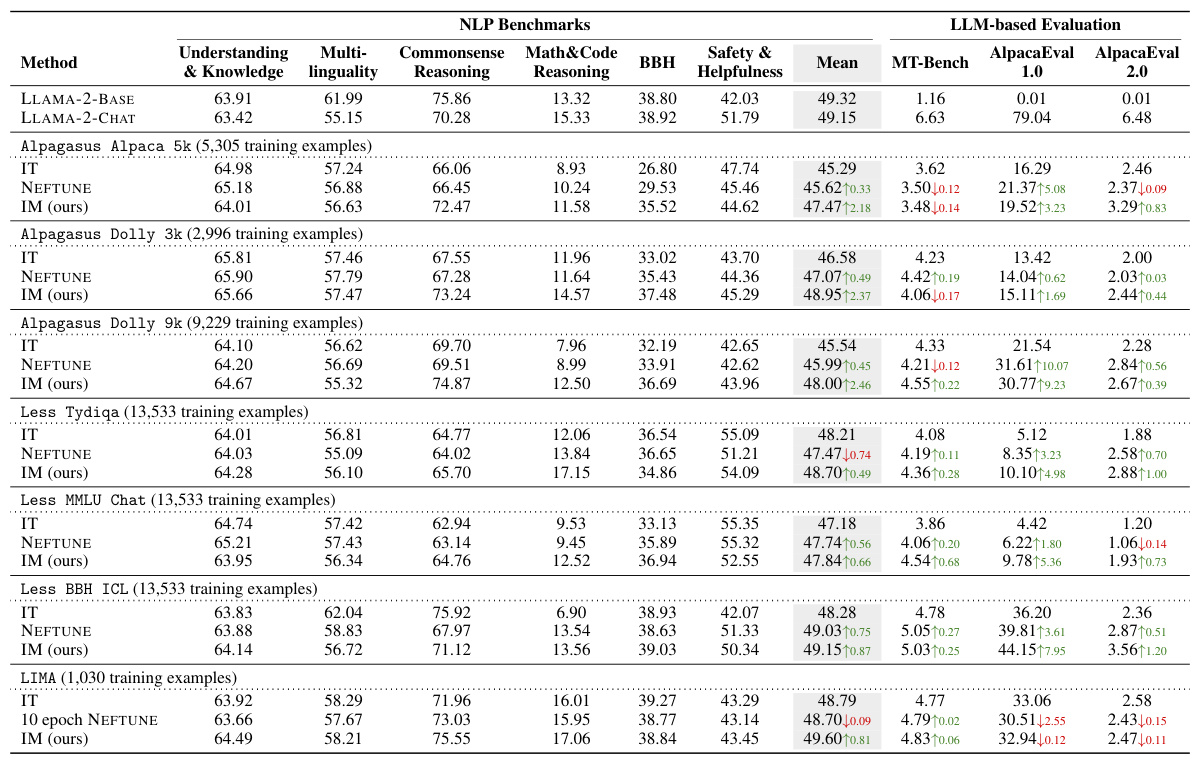
🔼 This figure shows the performance improvement of INSTRUCTION MODELLING (IM) over INSTRUCTION TUNING (IT) on the AlpacaEval 1.0 benchmark. The left panel shows the relationship between performance improvement and the ratio of average instruction length to average output length in the training dataset. The right panel shows the relationship between performance improvement and the number of training examples, while maintaining a fixed instruction-to-output length ratio of 10. The results suggest that IM is particularly effective for datasets with lengthy instructions and short outputs, and in low-resource scenarios.
read the caption
Figure 2: (Left) Performance improvement, achieved by our approach INSTRUCTION MODELLING (IM) compared to INSTRUCTION TUNING (IT) on the AlpacaEval 1.0, against the ratio between average instruction length and average output length in instruction tuning datasets (training size noted in parentheses). We highlight several representative instruction tuning datasets in yellow. Our analysis suggests that IM is especially beneficial for datasets characterized by lengthy instructions or prompts paired with comparably brief outputs, such as Code Alpaca [10] and Less MMLU Chat [68]. (Right) Performance improvement achieved by our approach IM over IT on the AlpacaEval 1.0 against the number of training examples in instruction tuning datasets. Here we maintain a fixed ratio between instruction and output length of 10. This analysis suggests that IM is particularly effective under the low-resource setting or Superficial Alignment Hypothesis. Please refer to §4.2 for details.

🔼 This figure compares the training and testing loss distributions of the INSTRUCTION MODELLING (IM) and INSTRUCTION TUNING (IT) methods. The left panel shows the training loss distribution on the LIMA dataset, illustrating that IM has a slightly higher mean training loss than IT. The right panel presents the test loss distribution on a 10% subset of the Tulu V2 dataset, revealing that IM achieves a lower mean test loss than IT. This difference in train and test loss suggests that IM effectively mitigates overfitting during instruction tuning.
read the caption
Figure 3: (Left) Training loss distribution for each example between our approach INSTRUCTION MODELLING (IM) and INSTRUCTION TUNING (IT) on the LIMA dataset. (Right) Test loss distribution for each example between IM and IT on the Tulu V2 dataset, using a 10% randomly sampled data for efficacy. Mean losses are marked by dashed lines. For both IM and IT, here we only compute the loss over the output part. IM has a higher train loss with lower test loss, suggesting that IM effectively mitigates the overfitting issues compared to IT. See Appendix §D for more examples.
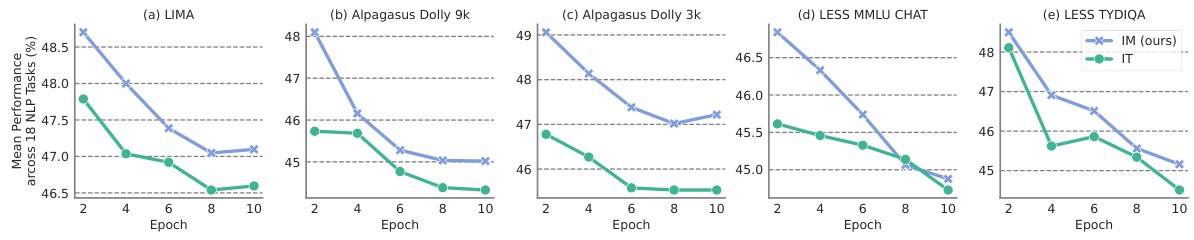
🔼 This figure compares the performance of Instruction Tuning (IT) and Instruction Modeling (IM) across seven different instruction tuning datasets. The left panel shows the average performance across 18 standard NLP tasks, while the right panel displays the win rate on the AlpacaEval 1.0 benchmark. The datasets used are subsets of Flan V2, Dolly, and Stanford Alpaca, along with the LIMA dataset. The figure highlights that IM outperforms IT in many scenarios.
read the caption
Figure 1: Performance differences between INSTRUCTION TUNING (IT) and our proposed method INSTRUCTION MODELLING (IM) trained on 7 instruction tuning datasets. These datasets contain prompts and responses but do not contain preference pairs. Specifically, we use the Less datasets [68] and Alpagasus datasets [11], which are subsets of Flan V2 [14], Dolly [18], and Stanford Alpaca [61] to ensure good performance. We also report the results on the LIMA dataset. (Left) The mean performance across 18 traditional NLP tasks (see §4.1 for details). (Right) The win rate on the AlpacaEval 1.0 benchmark [37]. Please refer to §4.2 for details.

🔼 This figure compares the performance of Instruction Tuning (IT) and Instruction Modelling (IM) across various instruction tuning datasets. The left panel shows the average performance improvement across 18 NLP tasks, while the right panel illustrates the win rate on the AlpacaEval 1.0 benchmark. The datasets used include subsets of Flan V2, Dolly, and Stanford Alpaca, along with the LIMA dataset.
read the caption
Figure 1: Performance differences between INSTRUCTION TUNING (IT) and our proposed method INSTRUCTION MODELLING (IM) trained on 7 instruction tuning datasets. These datasets contain prompts and responses but do not contain preference pairs. Specifically, we use the Less datasets [68] and Alpagasus datasets [11], which are subsets of Flan V2 [14], Dolly [18], and Stanford Alpaca [61] to ensure good performance. We also report the results on the LIMA dataset. (Left) The mean performance across 18 traditional NLP tasks (see §4.1 for details). (Right) The win rate on the AlpacaEval 1.0 benchmark [37]. Please refer to §4.2 for details.

🔼 This figure shows the performance improvement of INSTRUCTION MODELLING (IM) over INSTRUCTION TUNING (IT) on the AlpacaEval 1.0 benchmark. The left panel plots the improvement against the ratio of average instruction length to average output length in the training datasets, showing that IM is particularly beneficial for datasets with long instructions and short outputs. The right panel plots the improvement against the number of training examples, showing that IM is more effective in low-resource settings or under the Superficial Alignment Hypothesis.
read the caption
Figure 2: (Left) Performance improvement, achieved by our approach INSTRUCTION MODELLING (IM) compared to INSTRUCTION TUNING (IT) on the AlpacaEval 1.0, against the ratio between average instruction length and average output length in instruction tuning datasets (training size noted in parentheses). We highlight several representative instruction tuning datasets in yellow. Our analysis suggests that IM is especially beneficial for datasets characterized by lengthy instructions or prompts paired with comparably brief outputs, such as Code Alpaca [10] and Less MMLU Chat [68]. (Right) Performance improvement achieved by our approach IM over IT on the AlpacaEval 1.0 against the number of training examples in instruction tuning datasets. Here we maintain a fixed ratio between instruction and output length of 10. This analysis suggests that IM is particularly effective under the low-resource setting or Superficial Alignment Hypothesis. Please refer to §4.2 for details.
🔼 This figure compares the performance of Instruction Tuning (IT) and Instruction Modeling (IM) across 18 NLP tasks and AlpacaEval 1.0. Seven instruction tuning datasets (Less and Alpagasus subsets of Flan V2, Dolly, and Stanford Alpaca, plus LIMA) were used, with the left panel showing mean performance on traditional NLP tasks and the right showing the win rate on AlpacaEval 1.0. IM shows improvements in many scenarios, particularly on AlpacaEval 1.0.
read the caption
Figure 1: Performance differences between INSTRUCTION TUNING (IT) and our proposed method INSTRUCTION MODELLING (IM) trained on 7 instruction tuning datasets. These datasets contain prompts and responses but do not contain preference pairs. Specifically, we use the Less datasets [68] and Alpagasus datasets [11], which are subsets of Flan V2 [14], Dolly [18], and Stanford Alpaca [61] to ensure good performance. We also report the results on the LIMA dataset. (Left) The mean performance across 18 traditional NLP tasks (see §4.1 for details). (Right) The win rate on the AlpacaEval 1.0 benchmark [37]. Please refer to §4.2 for details.

🔼 This figure shows the training and testing loss distributions for both INSTRUCTION TUNING (IT) and INSTRUCTION MODELLING (IM). The left panel displays the training loss distribution for the LIMA dataset, while the right panel shows the test loss distribution for a 10% sample of the Tulu V2 dataset. The results demonstrate that IM, while exhibiting higher training loss, achieves lower testing loss, suggesting better generalization and reduced overfitting compared to IT.
read the caption
Figure 3: (Left) Training loss distribution for each example between our approach INSTRUCTION MODELLING (IM) and INSTRUCTION TUNING (IT) on the LIMA dataset. (Right) Test loss distribution for each example between IM and IT on the Tulu V2 dataset, using a 10% randomly sampled data for efficacy. Mean losses are marked by dashed lines. For both IM and IT, here we only compute the loss over the output part. IM has a higher train loss with lower test loss, suggesting that IM effectively mitigates the overfitting issues compared to IT. See Appendix §D for more examples.
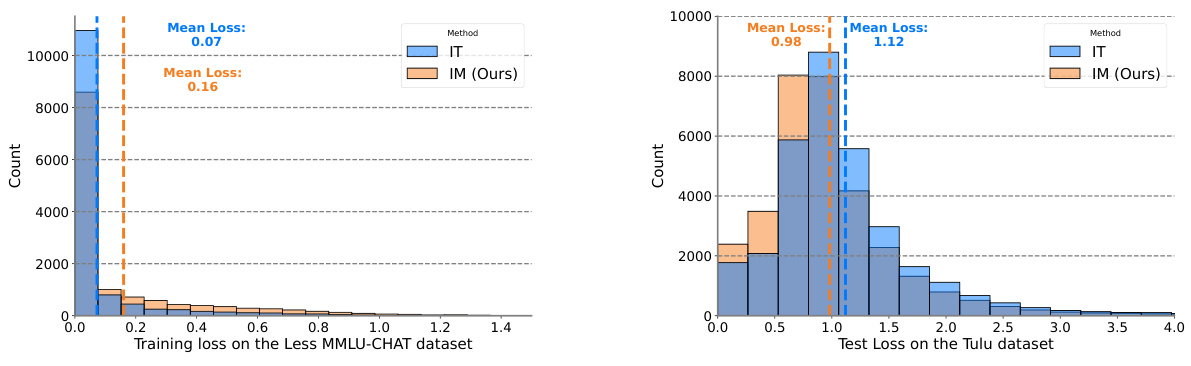
🔼 This figure shows the training and testing loss distributions for both INSTRUCTION TUNING (IT) and INSTRUCTION MODELLING (IM). The left panel displays the training loss distribution on the LIMA dataset, illustrating that IM has a higher mean training loss (1.45) than IT (1.37). This suggests IM is less prone to overfitting during training. The right panel shows the test loss distribution on a 10% sample of the Tulu V2 dataset, revealing that IM achieves a lower mean test loss (1.17) compared to IT (1.32). This demonstrates that IM generalizes better to unseen data, further highlighting its effectiveness in mitigating overfitting.
read the caption
Figure 3: (Left) Training loss distribution for each example between our approach INSTRUCTION MODELLING (IM) and INSTRUCTION TUNING (IT) on the LIMA dataset. (Right) Test loss distribution for each example between IM and IT on the Tulu V2 dataset, using a 10% randomly sampled data for efficacy. Mean losses are marked by dashed lines. For both IM and IT, here we only compute the loss over the output part. IM has a higher train loss with lower test loss, suggesting that IM effectively mitigates the overfitting issues compared to IT. See Appendix §D for more examples.

🔼 This figure compares the performance differences between Instruction Tuning (IT) and Instruction Modelling (IM) across 18 NLP tasks and AlpacaEval 1.0. The left panel shows the average performance improvement of IM over IT across 18 traditional NLP tasks using 7 different instruction tuning datasets, while the right panel illustrates the win rate (the percentage of times IM outperforms IT) on the AlpacaEval 1.0 benchmark using the same datasets. The datasets used are subsets of several popular instruction tuning datasets including Flan V2, Dolly, and Stanford Alpaca, chosen to ensure good performance.
read the caption
Figure 1: Performance differences between INSTRUCTION TUNING (IT) and our proposed method INSTRUCTION MODELLING (IM) trained on 7 instruction tuning datasets. These datasets contain prompts and responses but do not contain preference pairs. Specifically, we use the Less datasets [68] and Alpagasus datasets [11], which are subsets of Flan V2 [14], Dolly [18], and Stanford Alpaca [61] to ensure good performance. We also report the results on the LIMA dataset. (Left) The mean performance across 18 traditional NLP tasks (see §4.1 for details). (Right) The win rate on the AlpacaEval 1.0 benchmark [37]. Please refer to §4.2 for details.
More on tables

🔼 This table presents a detailed comparison of the performance of INSTRUCTION TUNING (IT) and INSTRUCTION MODELLING (IM) on various NLP tasks and open-ended generation benchmarks. It uses seven different instruction tuning datasets and the LLAMA-2-7B language model. The results are broken down into six categories of traditional NLP tasks and three open-ended benchmarks, with LLM-based evaluation metrics. Green and red arrows highlight the performance improvements and decreases, respectively, compared to the baseline (IT).
read the caption
Table 1: Performance comparisons using 7 instruction tuning datasets with the LLAMA-2-7B on 6 categories of 18 traditional NLP tasks and 3 open-ended benchmarks with LLM as judgements. “IT” refers to INSTRUCTION TUNING. 'IM' refers to INSTRUCTION MODELLING. Green and red arrows indicate performance changes against the baseline (IT).

🔼 This table presents a comparison of the performance of INSTRUCTION TUNING (IT) and INSTRUCTION MODELLING (IM) on 21 NLP tasks using the LLAMA-2-7B model. It shows the performance difference for each method across 7 instruction tuning datasets, with 18 traditional NLP tasks categorized into 6 groups and 3 open-ended benchmarks evaluated with LLMs. Green and red arrows indicate whether IM improved or worsened performance compared to IT.
read the caption
Table 1: Performance comparisons using 7 instruction tuning datasets with the LLAMA-2-7B on 6 categories of 18 traditional NLP tasks and 3 open-ended benchmarks with LLM as judgements. “IT” refers to INSTRUCTION TUNING. 'IM' refers to INSTRUCTION MODELLING. Green and red arrows indicate performance changes against the baseline (IT).

🔼 This table presents a comparison of the performance of INSTRUCTION TUNING (IT) and INSTRUCTION MODELLING (IM) using the LLAMA-2-7B model. The comparison is done across 7 different instruction tuning datasets and 21 NLP benchmarks (categorized into 6 groups). The table shows the mean performance scores for each method across various NLP tasks and open-ended generation benchmarks (AlpacaEval 1.0 and 2.0, MT-Bench). Green and red arrows indicate whether IM outperforms or underperforms IT, respectively.
read the caption
Table 1: Performance comparisons using 7 instruction tuning datasets with the LLAMA-2-7B on 6 categories of 18 traditional NLP tasks and 3 open-ended benchmarks with LLM as judgements. “IT” refers to INSTRUCTION TUNING. 'IM' refers to INSTRUCTION MODELLING. Green and red arrows indicate performance changes against the baseline (IT).
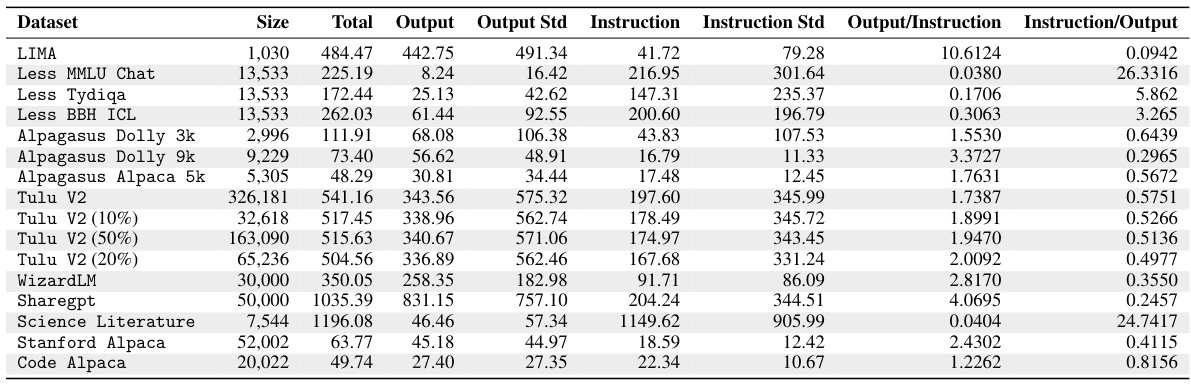
🔼 This table presents a detailed comparison of the performance of INSTRUCTION TUNING (IT) and INSTRUCTION MODELLING (IM) on various NLP tasks and open-ended generation benchmarks. It uses the LLAMA-2-7B language model and seven different instruction tuning datasets. The results are categorized into six groups of traditional NLP tasks and three open-ended benchmarks, with performance changes (improvements or reductions) compared to the baseline (IT) indicated by green and red arrows respectively. The table allows for a comprehensive evaluation of the effectiveness of IM compared to the established IT method across diverse language tasks.
read the caption
Table 1: Performance comparisons using 7 instruction tuning datasets with the LLAMA-2-7B on 6 categories of 18 traditional NLP tasks and 3 open-ended benchmarks with LLM as judgements. “IT” refers to INSTRUCTION TUNING. 'IM' refers to INSTRUCTION MODELLING. Green and red arrows indicate performance changes against the baseline (IT).
🔼 This table presents a detailed comparison of the performance of INSTRUCTION TUNING (IT) and INSTRUCTION MODELLING (IM) on various NLP tasks and open-ended generation benchmarks. Seven instruction tuning datasets were used with the LLAMA-2-7B language model. The table is organized into six categories of traditional NLP tasks and three open-ended benchmarks, with the performance of both methods displayed for each dataset and benchmark, indicated by green and red arrows representing improvements and declines compared to IT, respectively. The table provides a comprehensive evaluation of the two methods across a diverse range of tasks.
read the caption
Table 1: Performance comparisons using 7 instruction tuning datasets with the LLAMA-2-7B on 6 categories of 18 traditional NLP tasks and 3 open-ended benchmarks with LLM as judgements. “IT” refers to INSTRUCTION TUNING. 'IM' refers to INSTRUCTION MODELLING. Green and red arrows indicate performance changes against the baseline (IT).

🔼 This table presents a comparison of the performance of INSTRUCTION TUNING (IT) and INSTRUCTION MODELLING (IM) on 21 NLP benchmarks using the LLAMA-2-7B language model. It shows the performance differences for each method across six categories of 18 traditional NLP tasks and three open-ended generation benchmarks. The results are broken down by the seven instruction-tuning datasets used for training, indicating the mean performance and LLM-based evaluation metrics. Green and red arrows highlight performance improvements or decreases compared to the baseline IT method.
read the caption
Table 1: Performance comparisons using 7 instruction tuning datasets with the LLAMA-2-7B on 6 categories of 18 traditional NLP tasks and 3 open-ended benchmarks with LLM as judgements. “IT” refers to INSTRUCTION TUNING. 'IM' refers to INSTRUCTION MODELLING. Green and red arrows indicate performance changes against the baseline (IT).

🔼 This table presents a comparison of the performance of Instruction Tuning (IT) and Instruction Modelling (IM) on various NLP tasks and benchmarks using the LLAMA-2-7B language model. Seven different instruction tuning datasets were used for training, and the results are categorized into six groups of traditional NLP tasks and three open-ended benchmarks. Green arrows indicate improvements achieved by IM over IT, while red arrows indicate where IT outperformed IM. The table allows for a comprehensive assessment of the relative effectiveness of IM versus IT across diverse tasks and datasets.
read the caption
Table 1: Performance comparisons using 7 instruction tuning datasets with the LLAMA-2-7B on 6 categories of 18 traditional NLP tasks and 3 open-ended benchmarks with LLM as judgements. “IT” refers to INSTRUCTION TUNING. 'IM' refers to INSTRUCTION MODELLING. Green and red arrows indicate performance changes against the baseline (IT).
Full paper#