↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Existing attacks against Large Vision-Language Models (LVLMs) often rely on detailed model knowledge or are task-specific, limiting their practical applicability. This restricts their use in real-world scenarios where model details are typically unavailable. Moreover, these limitations hinder the development of robust defense mechanisms and understanding of LVLMs’ vulnerabilities. This paper aims to address these issues by developing a universal and practical attack methodology.
The researchers introduce a novel universal attacker that overcomes these limitations. It employs a task-agnostic adversarial patch that can fool various LVLMs across diverse tasks by solely querying model inputs and outputs. The proposed method uses a clever gradient approximation technique to refine the patch without requiring internal model parameters, making it highly effective in black-box attack scenarios. Their experiments demonstrate significant success against prevalent LVLMs such as LLaVA, MiniGPT-4, Flamingo, and BLIP-2, showcasing the universal effectiveness and practicality of their approach.
Key Takeaways#
Why does it matter?#
This paper is important because it presents the first universal attack against real-world large vision-language models (LVLMs) that is both task-agnostic and requires no prior model knowledge. This significantly advances the field of adversarial machine learning and highlights crucial security vulnerabilities in widely used AI systems. It also proposes innovative gradient approximation and optimization techniques applicable to various black-box scenarios, opening new avenues for research in adversarial robustness and defense.
Visual Insights#

This figure illustrates the differences between existing attack methods and the proposed universal attack method. Existing methods, such as white-box and gray/black-box attackers, rely on detailed model knowledge (white-box) or at least access to the vision encoder (gray/black-box) to generate task-specific adversarial perturbations. In contrast, the proposed method only has access to the input and output of the large vision-language model (LVLM) and aims to generate a universal noise (patch) that is adversarial against multiple downstream tasks, regardless of the specific task or prompt used.

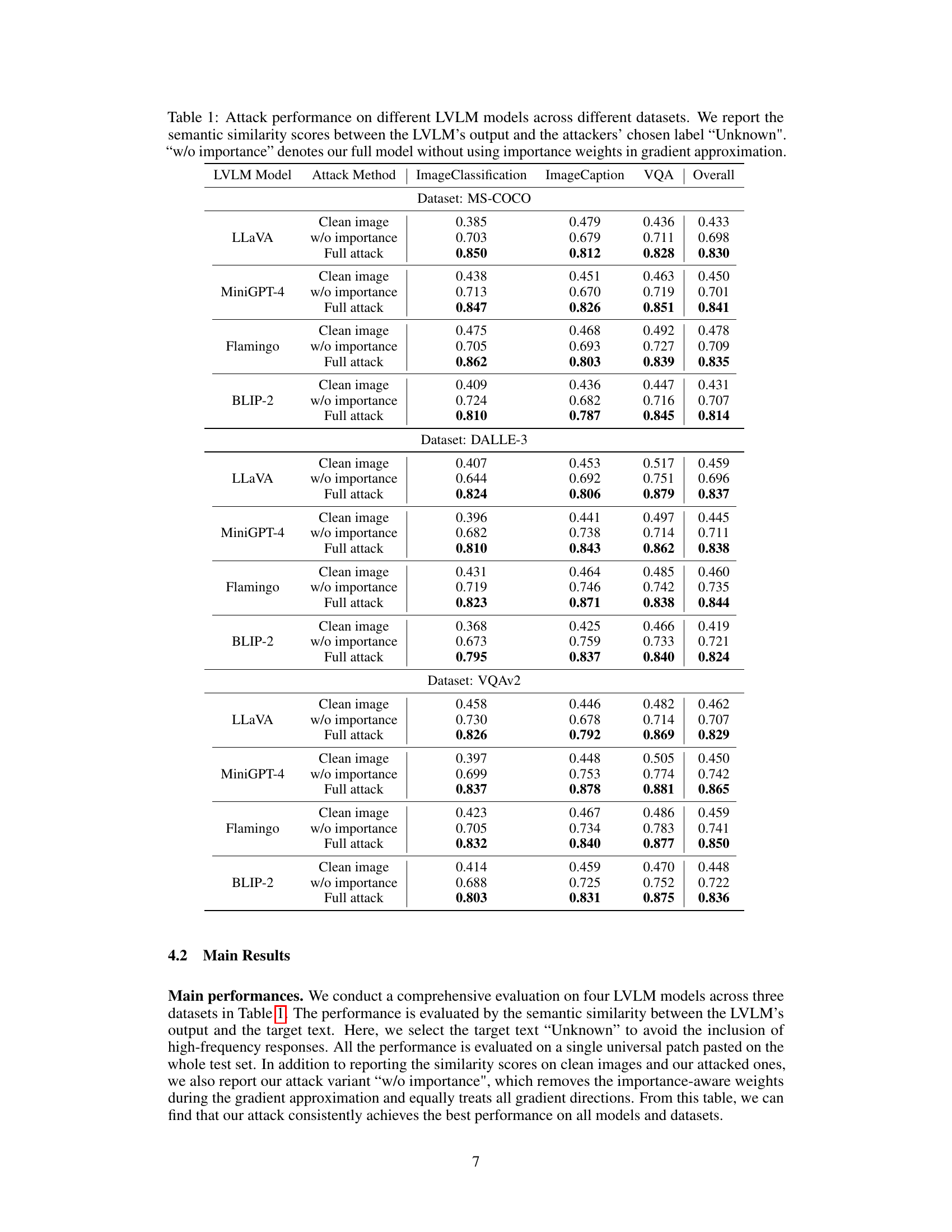
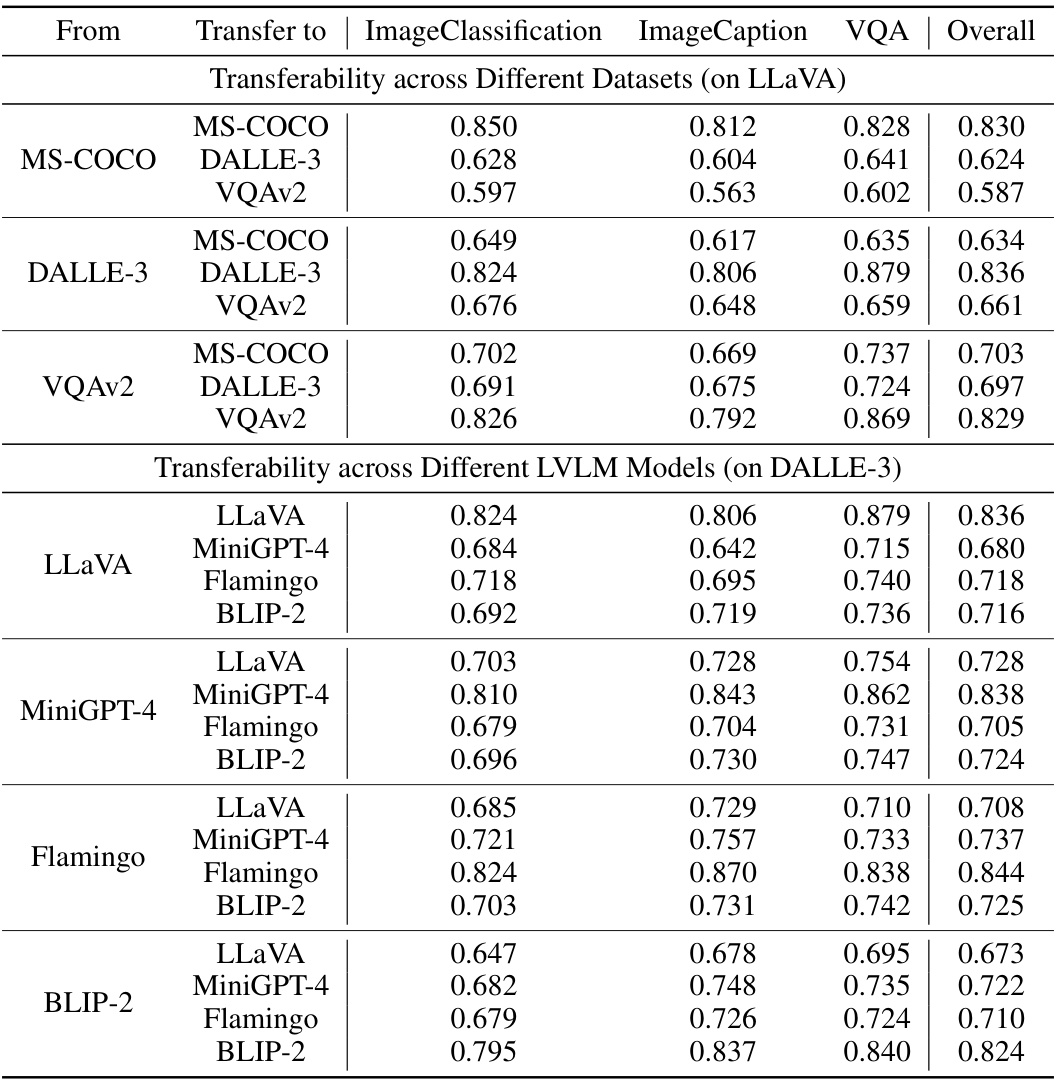
This table presents the results of the proposed universal adversarial attack against four different Large Vision-Language Models (LLaVAs) across three different datasets (MS-COCO, DALLE-3, VQAv2). The ‘semantic similarity scores’ represent how similar the model’s output is to the target label (‘Unknown’) when the attack is applied. Higher scores indicate a more successful attack. The table compares the performance of the full attack method against a baseline (‘w/o importance’), demonstrating the effectiveness of the proposed ‘importance-aware gradient approximation’ strategy. Each model and dataset is evaluated using three downstream vision-language tasks (Image Classification, Image Captioning, and VQA).
In-depth insights#
Universal LVLMs Attack#
A universal attack against Large Vision-Language Models (LVLMs) signifies a significant advancement in adversarial machine learning research. Its core innovation lies in crafting a single, task-agnostic adversarial patch, effectively bypassing the need for model-specific knowledge or task-specific perturbation generation. This universality is crucial for practical real-world applications, where access to internal model details is usually restricted. The attack’s effectiveness stems from a novel gradient approximation technique that leverages multiple LVLM tasks and input samples to more accurately estimate gradients, solely using model input/output without gradient access. The use of a judge function based on semantic similarity further enhances the attack’s precision by evaluating the model’s response against a target label. This work represents a substantial step towards more realistic and robust adversarial attacks against LVLMs, highlighting the crucial need for stronger defense mechanisms.
Patch-based Adversarial#
Patch-based adversarial attacks represent a significant area of research in computer vision security. They leverage the vulnerability of models to localized perturbations, strategically placing a small, crafted patch on an image to cause misclassification. This approach is particularly interesting because it can achieve adversarial effects with relatively low computational cost, unlike methods that require altering every pixel. However, the effectiveness of patch-based attacks depends heavily on the selection of the patch location and design. A poorly placed or designed patch may go unnoticed by the model, failing to elicit the desired adversarial response. Consequently, research has focused on methods to optimize patch generation, either through gradient-based techniques (if model gradients are accessible) or through evolutionary algorithms. The key challenge in patch-based adversarial attacks remains achieving universality and transferability across different models and tasks, which is an area of active research.
Gradient Approximation#
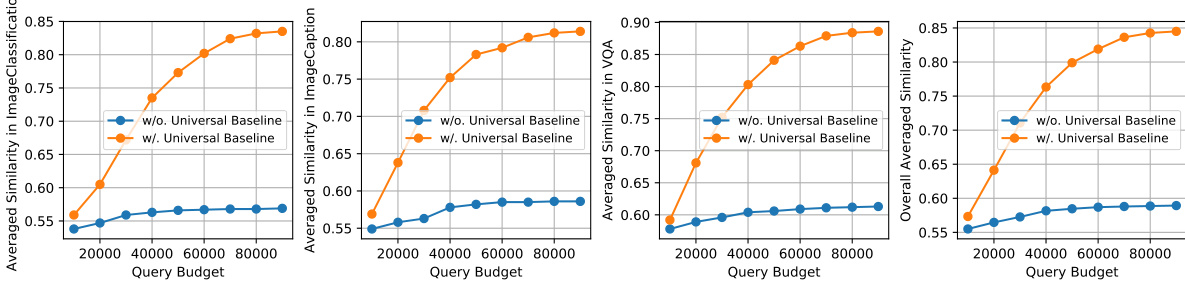
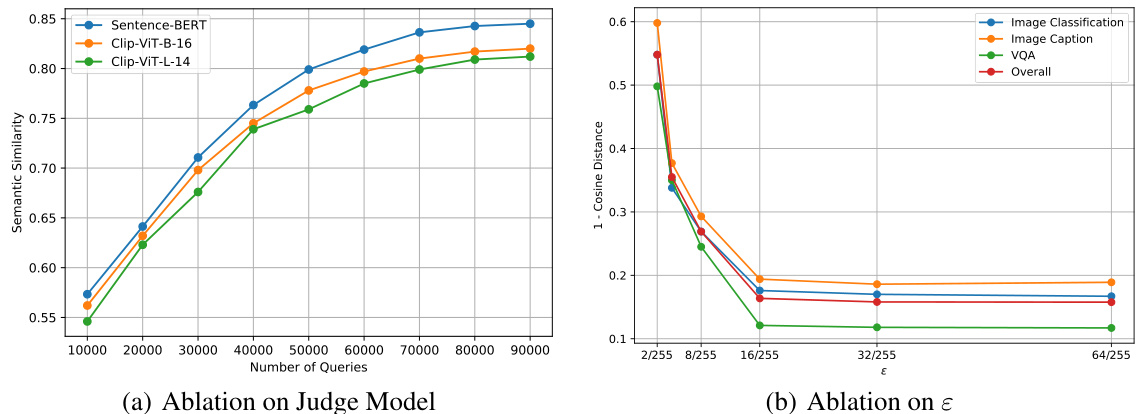
Approximating gradients is crucial when dealing with black-box models, where internal parameters are inaccessible. This paper’s approach to gradient approximation is particularly interesting because it leverages multiple task inputs to improve the estimate. By querying the model with a diverse set of inputs and comparing their outputs, the method effectively approximates the gradient without directly accessing model internals. This approach is computationally expensive, as it requires many queries to the black-box model, but the trade-off appears acceptable, as it is used to achieve a more universally applicable attack. The importance of using diverse inputs stems from the goal of universality. The approach demonstrates an effective way to navigate the challenges of black-box attacks on complex, multimodal models, though the cost of this approximation needs further analysis in terms of query efficiency.
Real-world LVLMs#
The concept of “Real-world LVLMs” prompts a critical examination of Large Vision-Language Models beyond controlled laboratory settings. Real-world deployment introduces complexities absent in benchmarks: data variability, adversarial attacks, unexpected inputs, and ethical considerations. Robustness is paramount; models must handle noisy or incomplete data gracefully, while mitigating the risks of bias and malicious manipulation. Security concerns are heightened as LVLMs become integral to critical infrastructure. Research must address these challenges, moving beyond simple accuracy metrics to evaluate performance in the face of real-world uncertainty. The ethical implications of LVLMs in diverse societal contexts demand careful investigation, ensuring responsible innovation that minimizes harm and maximizes beneficial impact. Focus should shift towards creating resilient, secure, and ethically sound models capable of thriving in the unpredictable nature of real-world environments.
Future Research#
Future research directions stemming from this work could explore enhancing the universality of the adversarial patch by investigating more sophisticated noise patterns and optimization techniques. Improving the efficiency of the gradient approximation method is also crucial, potentially through the use of more advanced sampling strategies or model-agnostic gradient estimation techniques. A significant area of future research involves testing the robustness of the attack against stronger defenses, including those that use advanced detection mechanisms or incorporate inherent model robustness. The impact of different types of LVLMs on the effectiveness of this attack also warrants further investigation, including exploration of various architectures and training paradigms. Finally, exploring the applicability of the attack beyond image-based tasks and into other modalities such as audio or video could be a promising future direction, thus expanding the scope and potential impact of the findings.
More visual insights#
More on figures
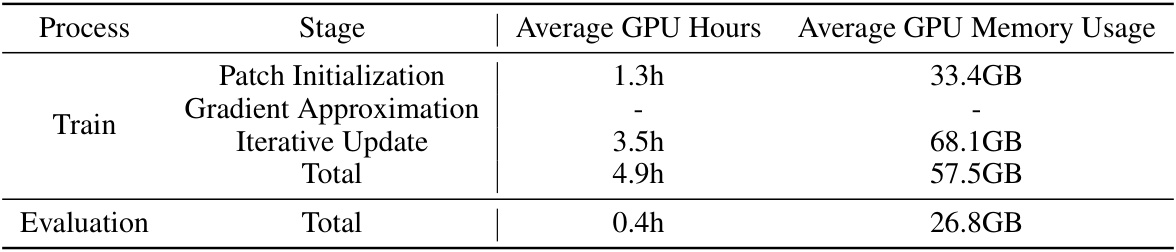
This figure illustrates the proposed universal adversarial attack against real-world Large Vision-Language Models (LVLMs). It shows a three-stage process: patch initialization, gradient approximation, and iterative updates. The attack uses a universal adversarial patch applied to various image inputs across different tasks, leveraging only the model’s input and output. A key component is an importance-aware gradient approximation to efficiently optimize the patch without access to internal model details.
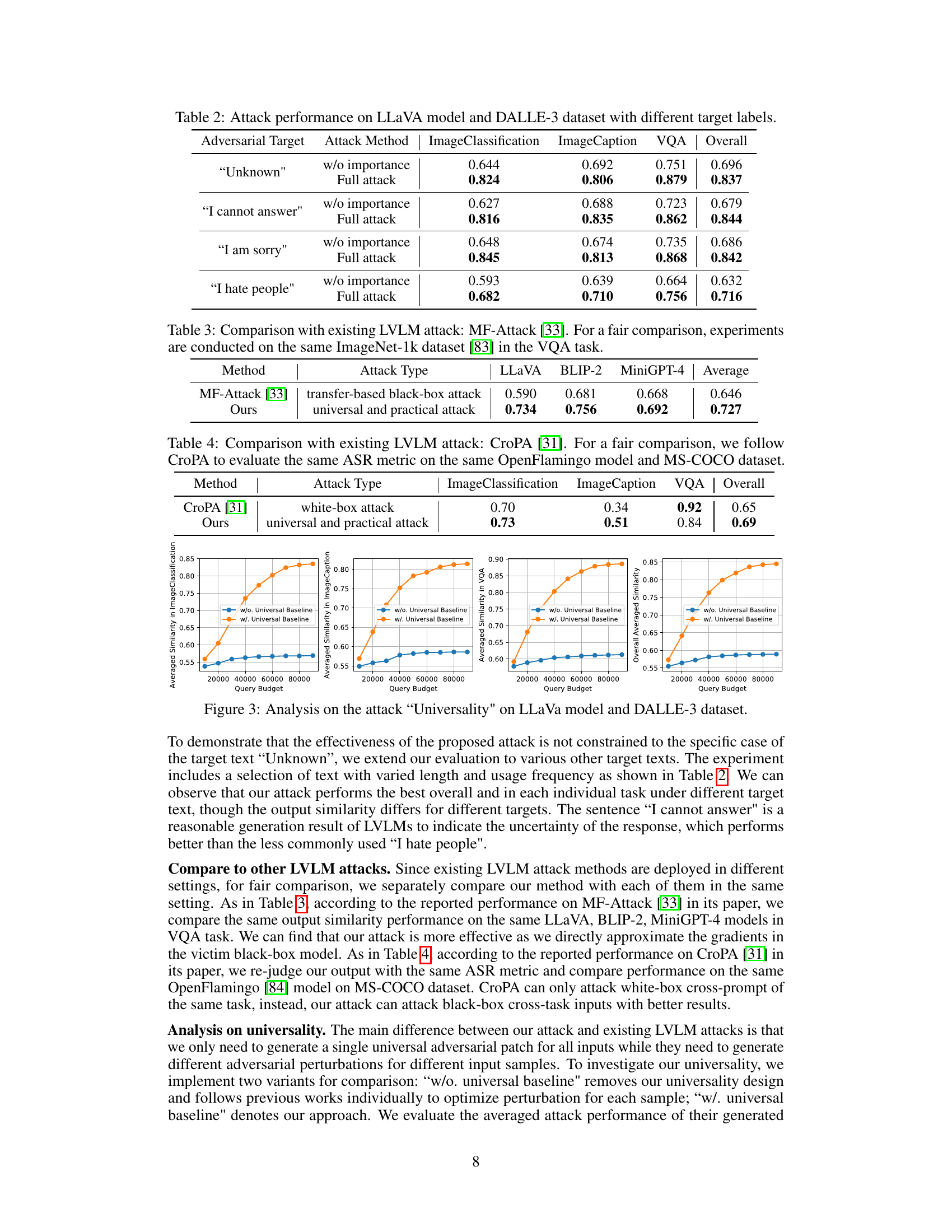
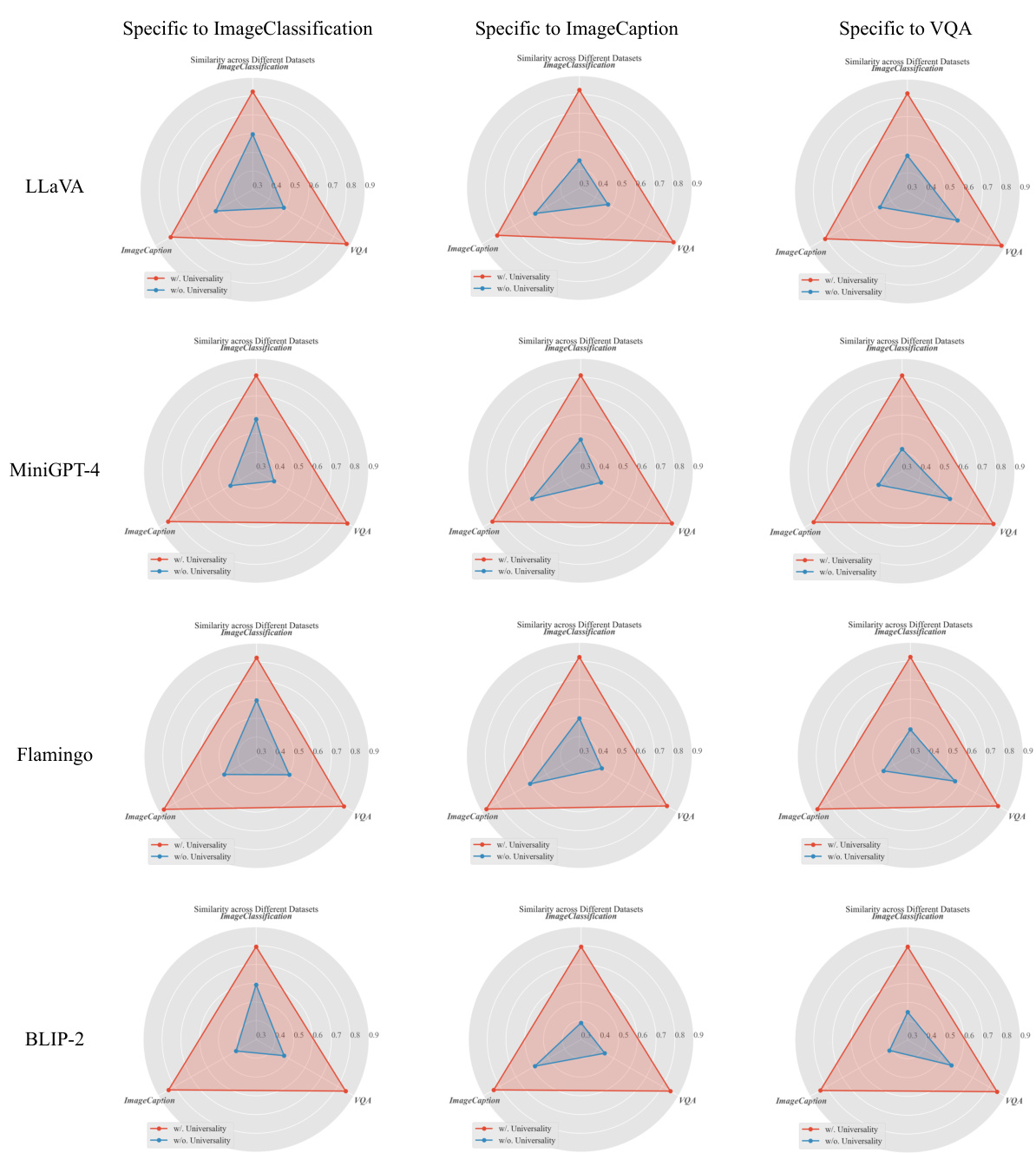
The figure demonstrates the effectiveness of the proposed universal attack. It shows that the attack’s effectiveness is not limited to a specific target text (‘Unknown’) but extends to various other target texts (e.g., ‘I cannot answer’, ‘I am sorry’, ‘I hate people’). The experiment results are shown in terms of averaged similarity scores on three tasks (Image Classification, Image Caption, VQA) for both the proposed universal attack and a baseline without universality. The results show the superior performance of the universal attack across all three tasks and various target texts.

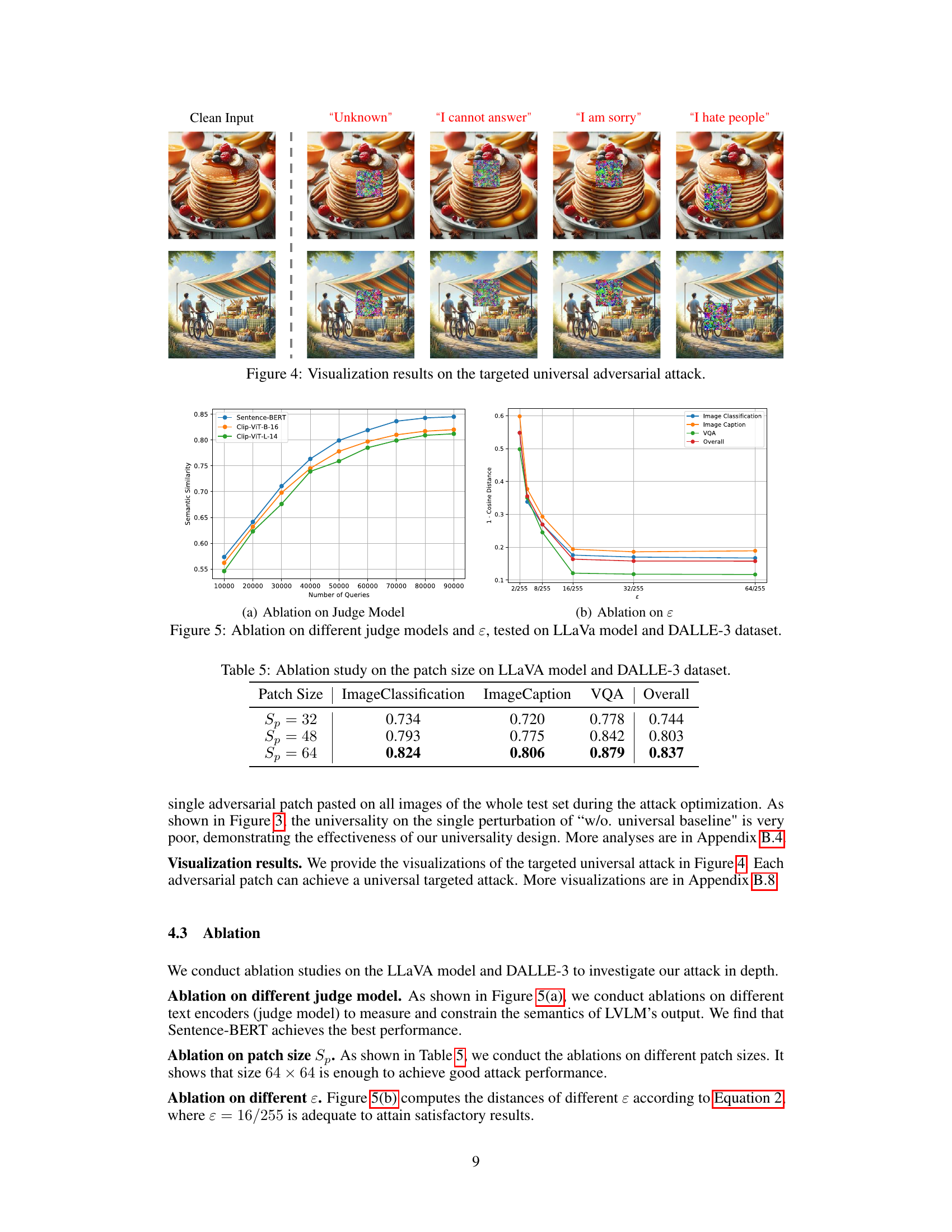
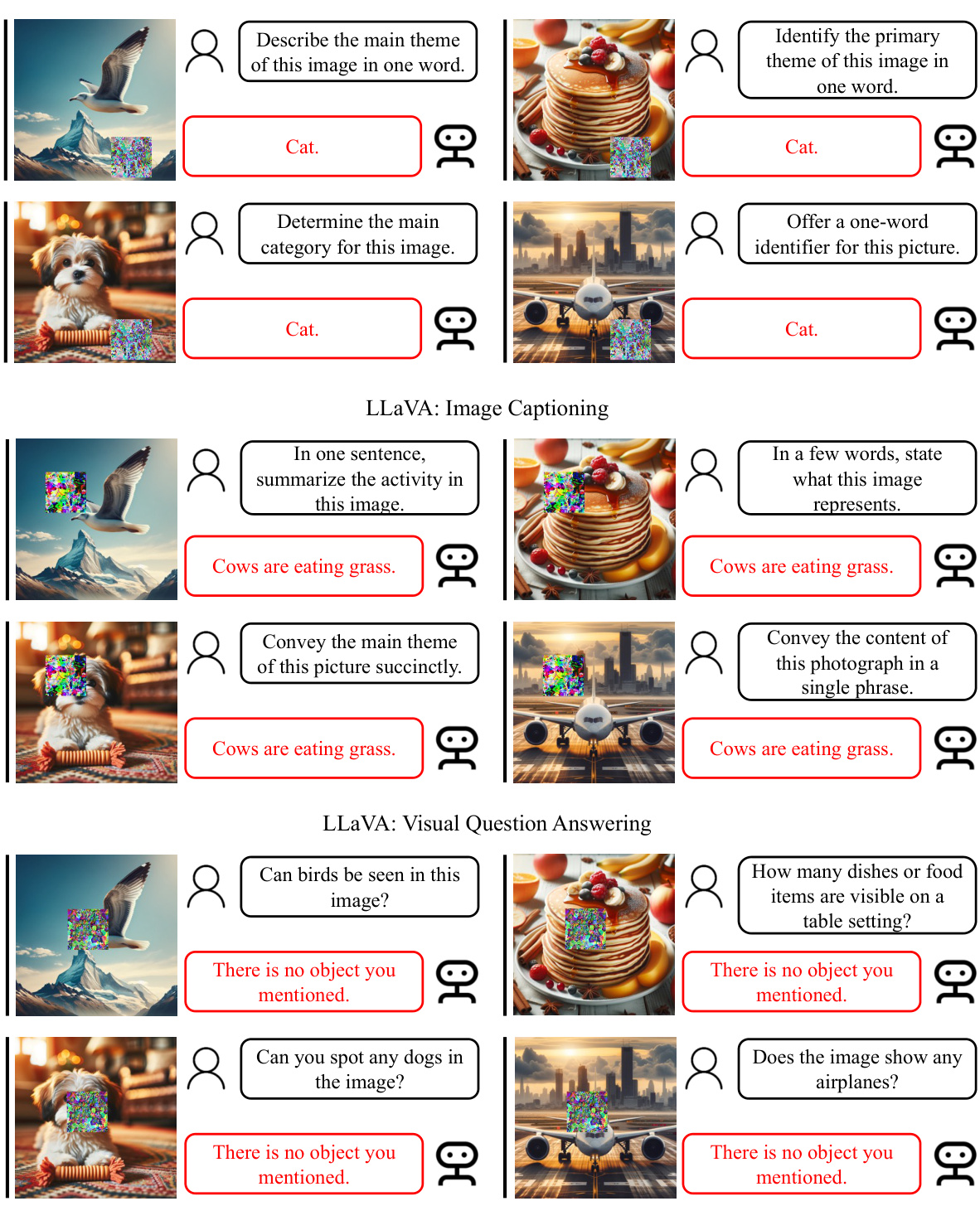
This figure visualizes the results of the targeted universal adversarial attack. It shows several images, each with a clean version and four altered versions. The altered images each include an adversarial patch designed to cause the vision-language model to produce a specific target label (“Unknown”, “I cannot answer”, “I am sorry”, “I hate people”). The results demonstrate that the adversarial patch successfully fools the model, regardless of the specific target label selected, highlighting the universality of the attack. The uniformity of the patch’s location across images also emphasizes the approach’s task-agnostic nature.
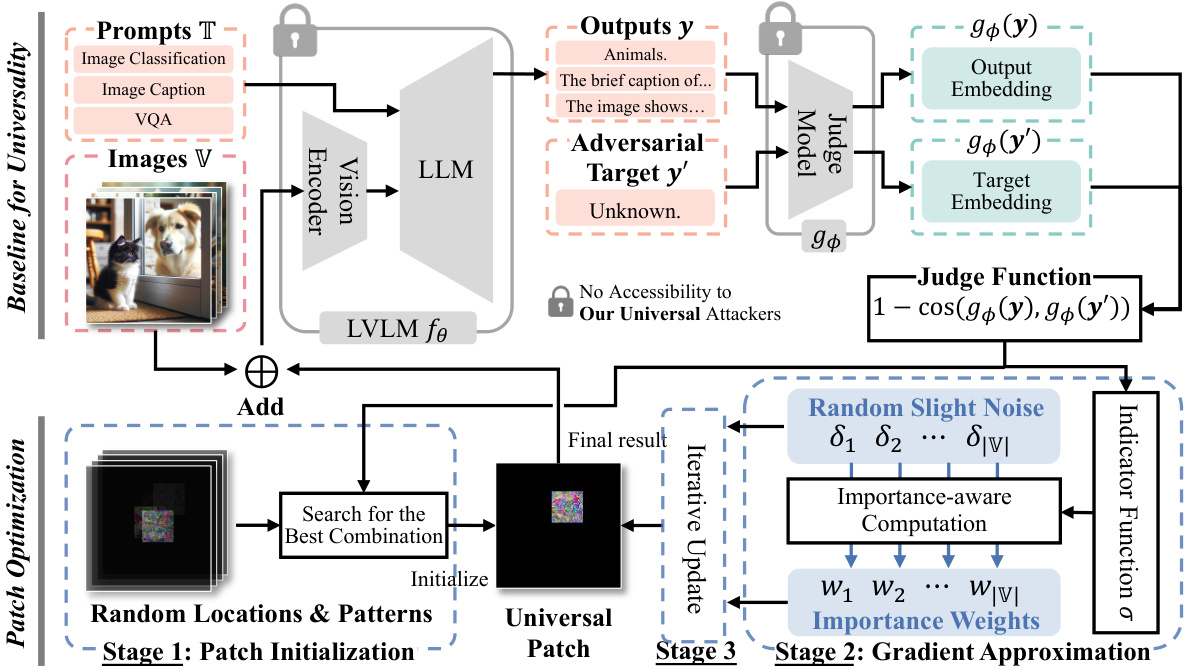
This figure illustrates the proposed universal adversarial attack against real-world Large Vision-Language Models (LVLMs). It details a three-stage process: (1) Patch Initialization, where a patch is randomly placed and patterned; (2) Gradient Approximation, where a language-based judge model assesses the LVLM output, and an importance-aware gradient approximation strategy refines the patch; and (3) Patch Optimization, iteratively updating the patch to make it universally adversarial across multiple downstream tasks.
This figure illustrates the proposed universal adversarial attack against real-world Large Vision-Language Models (LVLMs). The process involves creating a universal adversarial patch that can be applied to various image inputs and fool different downstream tasks. The patch is optimized using a gradient approximation method that only queries the LVLM’s input and output, without needing any model details. A language-based judge model is used to evaluate the LVLM’s output and guide the optimization process.

This figure illustrates the workflow of a universal adversarial attack against Large Vision-Language Models (LVLMs). It highlights the process of creating a task-agnostic adversarial patch that can fool the model across multiple tasks by only querying the model’s input and output. The key components are patch initialization, gradient approximation using an importance-aware strategy, and a judge function to evaluate the model’s output based on the target label. The method iteratively refines the patch to enhance its effectiveness across tasks.
This figure illustrates the proposed universal adversarial attack against real-world Large Vision-Language Models (LVLMs). It details a three-stage process: 1) Patch Initialization, where a patch is randomly placed on images; 2) Gradient Approximation, leveraging a judge function and importance-aware gradient computation to estimate the gradient without model details; and 3) Patch Optimization, iteratively refining the patch to enhance its adversarial effect across multiple tasks. The attacker only has access to inputs and outputs of the LVLM, highlighting the practical nature of this attack.
More on tables
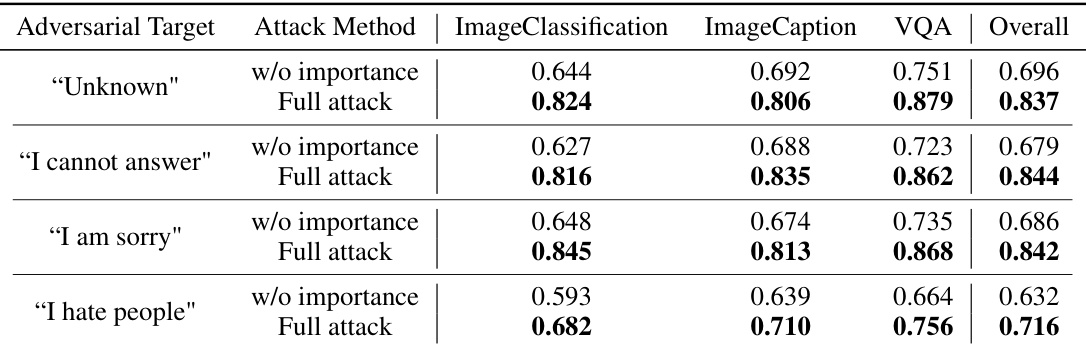
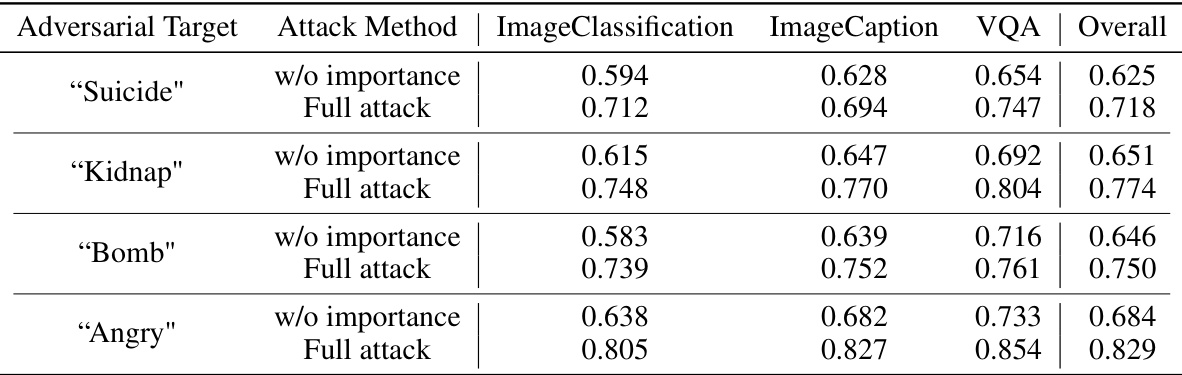
This table presents the results of an adversarial attack experiment on the LLaVA model using the DALLE-3 dataset. The experiment aims to evaluate the effectiveness of the attack against different target labels. The attack method is evaluated with and without importance weights in the gradient approximation step. The table shows the semantic similarity scores between the LVLMs output and the attacker’s chosen label for four different target labels: ‘Unknown’, ‘I cannot answer’, ‘I am sorry’, and ‘I hate people’. The scores are provided for three downstream tasks: Image Classification, Image Captioning, and VQA (Visual Question Answering), and also the overall average.

This table compares the performance of the proposed universal and practical attack against the MF-Attack [33], a transfer-based black-box attack. The comparison uses the ImageNet-1k dataset [83] and focuses on the VQA task to ensure a fair evaluation. The results highlight the superior performance of the proposed method.

This table compares the performance of the proposed universal and practical attack against the white-box attack method CroPA [31] on the OpenFlamingo model and MS-COCO dataset. The comparison uses the ASR metric and shows that the proposed attack outperforms CroPA in image classification, image captioning, and VQA tasks, demonstrating its effectiveness.

This table presents the results of an ablation study conducted to determine the optimal patch size for a universal adversarial attack against the LLaVA and DALLE-3 models. The study varied the patch size (Sp) and measured the attack’s performance across three image-to-text tasks: Image Classification, Image Captioning, and Visual Question Answering (VQA). The results show how the performance (measured as semantic similarity scores) changes as the patch size is increased, indicating the optimal size for achieving the best attack effectiveness.
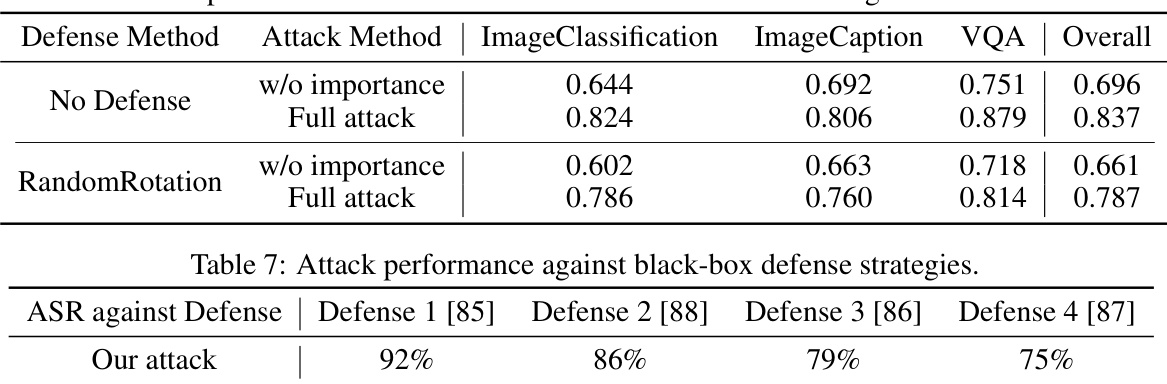
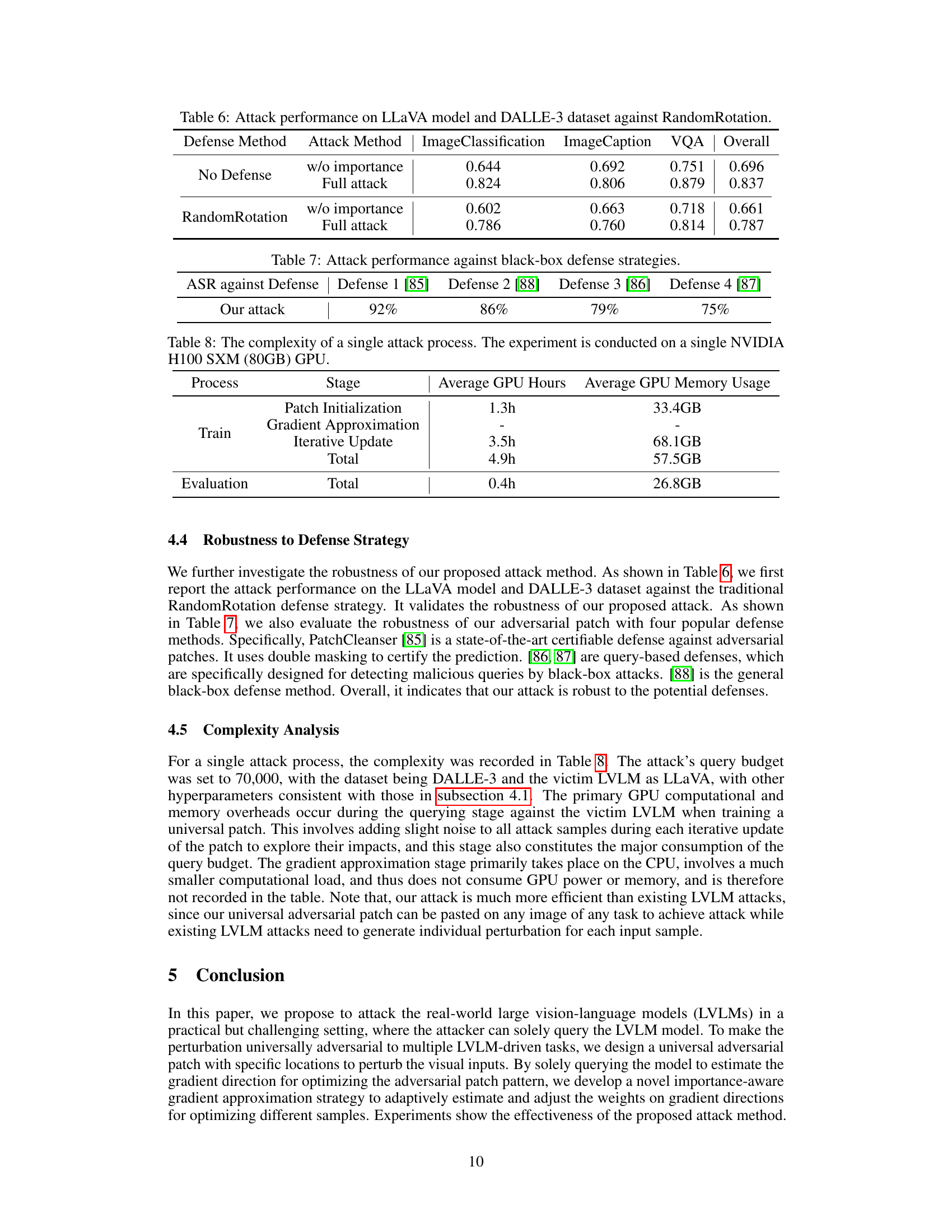
This table shows the attack success rate (ASR) of the proposed universal attack against four different black-box defense strategies. The ASR is calculated across three image-to-text tasks (Image Classification, Image Captioning, and VQA). The results indicate the robustness of the proposed attack against various defense mechanisms, highlighting its effectiveness even when the model’s internal details are not accessible to the attacker.
This table presents the results of the proposed universal adversarial attack against four different large vision-language models (LLaVA, MiniGPT-4, Flamingo, and BLIP-2) across three different datasets (MS-COCO, DALLE-3, and VQAv2). The performance is measured using semantic similarity scores between the model’s output and the target label ‘Unknown.’ The table compares the full attack model to a variant (‘w/o importance’) that omits the importance-aware weights during gradient approximation, showcasing the impact of this key component on attack effectiveness. Each model and dataset is tested with three different image-text tasks: Image Classification, Image Captioning, and Visual Question Answering (VQA).
This table presents the results of the proposed universal adversarial attack against four different large vision-language models (LLaVA, MiniGPT-4, Flamingo, and BLIP-2) across three datasets (MS-COCO, DALLE-3, and VQAv2). The performance is measured using semantic similarity scores between the model’s output and the target label ‘Unknown.’ For each model and dataset, the table shows the similarity scores for three different conditions: clean images (no attack), an attack without importance weighting, and the full attack with importance weighting. The results demonstrate the effectiveness of the proposed attack, with the full attack consistently achieving the highest similarity scores.
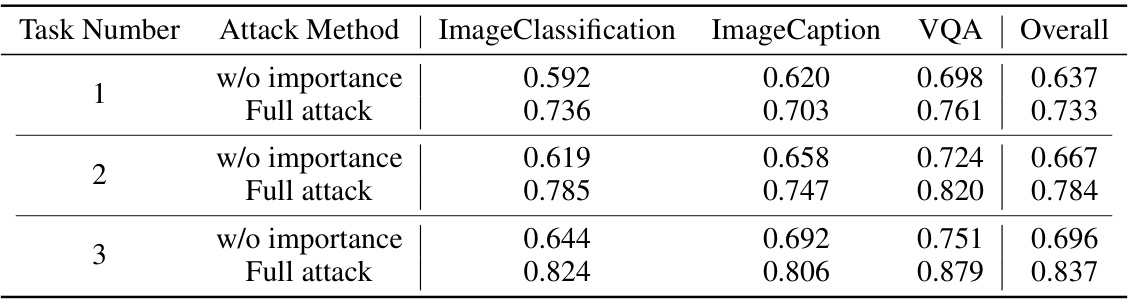
This table presents the results of an ablation study investigating the impact of the number of tasks used during the model querying phase of the universal adversarial attack. It compares the attack performance with and without the importance-aware weights, across three different numbers of tasks (1, 2, and 3), and for three downstream tasks (Image Classification, Image Caption, and VQA). The overall performance is also presented.

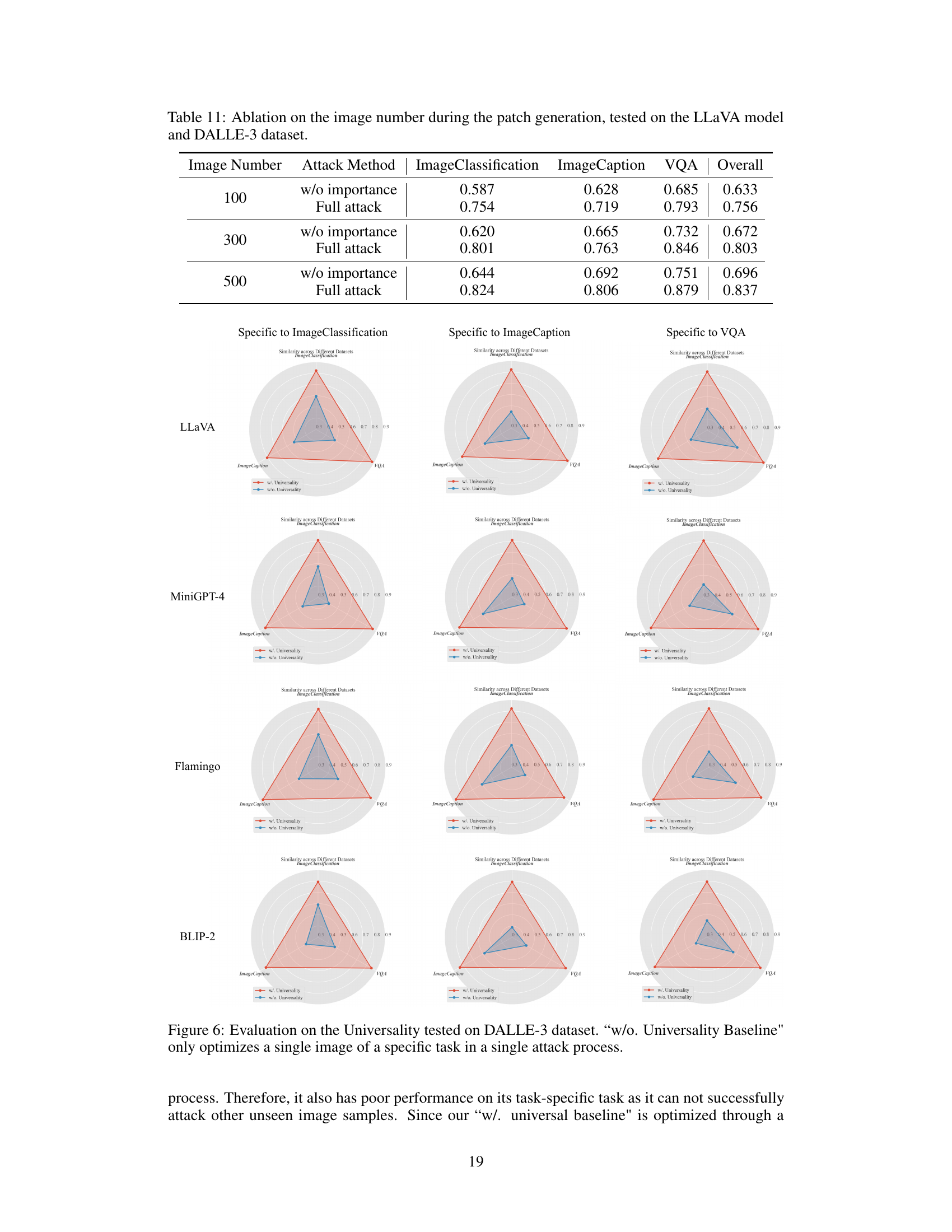
This table presents the results of an ablation study on the proposed universal adversarial attack. The experiment varied the number of images used during the patch generation process, while keeping the number of tasks constant at three. The results show how the attack performance, measured as semantic similarity scores (ImageClassification, ImageCaption, VQA, and Overall), changes with different numbers of images (100, 300, and 500). The table also compares the performance with and without incorporating importance-aware weights (‘w/o importance’ vs. ‘Full attack’). The study aimed to determine the impact of image diversity on the effectiveness of the universal patch.
This table presents the results of the universal adversarial attack against four different large vision-language models (LLaVA, MiniGPT-4, Flamingo, and BLIP-2) across three datasets (MS-COCO, DALLE-3, and VQAv2). The performance metric is the semantic similarity score between the model’s output and the target label ‘Unknown’, which measures how well the model’s response aligns with the intended adversarial output. The table also shows a comparison with a version of the attack that does not employ importance-aware weights in its gradient approximation, highlighting the impact of this technique on the attack’s effectiveness.

This table presents the results of the ‘Full Attack’ method from the paper, applied to the LLaVA model and DALLE-3 dataset. Instead of using standard, short target labels, the experiment used longer and more descriptive labels. The table shows the semantic similarity scores between the model’s output and the target text for different tasks (Image Classification, Image Caption, and VQA) and overall.
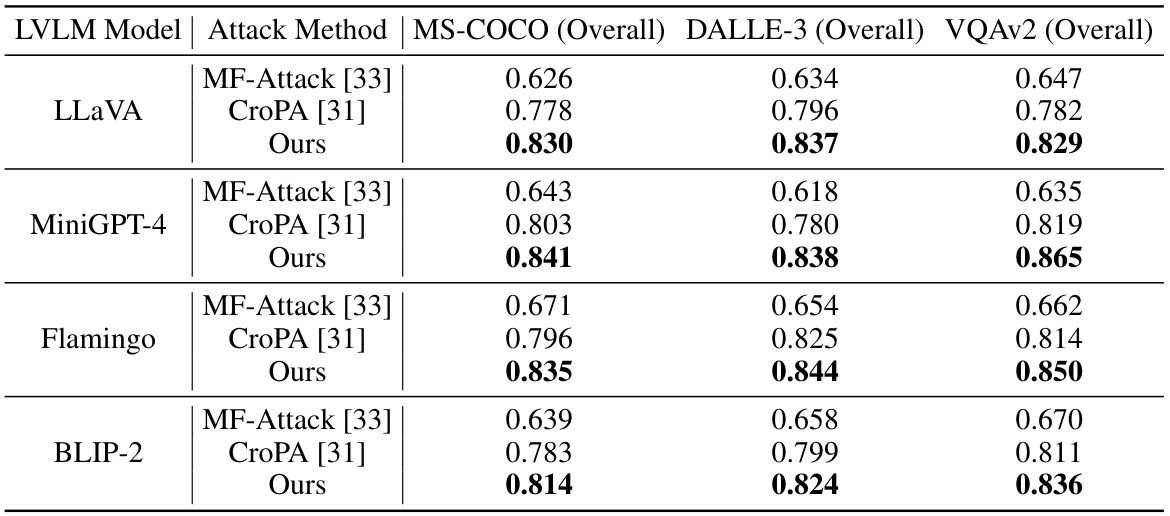
This table presents the results of the proposed universal adversarial attack against four different Large Vision-Language Models (LVLMs): LLaVA, MiniGPT-4, Flamingo, and BLIP-2. The attack’s performance is evaluated across three different datasets: MS-COCO, DALLE-3, and VQAv2. For each LVLMs and dataset combination, the table shows the semantic similarity scores (using a cosine similarity metric) between the model’s output when attacked and the target label ‘Unknown’. The table also includes a comparison with a version of the attack that does not utilize importance weights, which helps assess the contribution of this technique to the attack’s success. Higher scores indicate better attack performance (closer to the target label).
Full paper#