↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Current methods for 3D object removal struggle with multi-view inconsistencies, leading to artifacts and low-fidelity results. Diffusion models, while effective in 2D inpainting, often exacerbate these issues when applied to multi-view 3D data. This limitation stems from the variability in the initial sampled and intermediate latents predicted during the denoising process.
The proposed “In-N-Out” approach directly addresses this by aligning both the initial and intermediate latents. It uses a pre-trained NeRF to align initial latents, establishing a consistent foundational structure. A cross-view attention mechanism aligns intermediate latents during the denoising process, improving consistency across views. A patch-based hybrid loss further enhances the rendering results by optimizing the NeRF. The results demonstrate that “In-N-Out” significantly improves the quality of inpainted 3D representations.
Key Takeaways#
Why does it matter?#
This paper is significant because it presents a novel approach to 3D object removal that effectively addresses the challenges of multi-view inconsistencies inherent in existing methods. By leveraging the strengths of 2D diffusion models and Neural Radiance Fields, it offers a significant advancement in the field of 3D scene editing. The results demonstrate a substantial improvement in fidelity and coherence of the inpainted 3D representations, opening new avenues for research in 3D image editing and scene manipulation.
Visual Insights#

This figure shows a comparison of image inpainting results using Stable Diffusion and the proposed method. The top row displays View #1, and the bottom row displays View #2. For each view, there are three images: (a) the original image with the object to be removed; (b) the image inpainted using Stable Diffusion, demonstrating inconsistencies between the two views; and (c) the image inpainted using the proposed method, showing improved consistency between the views. The inpainted areas are highlighted with red and green boxes to clearly show the differences.

This table presents a quantitative comparison of different methods for 3D object removal, evaluating their performance based on three metrics: LPIPS (lower is better), FID (lower is better), and MUSIQ (higher is better). LPIPS measures the perceptual difference between the generated and ground truth images. FID assesses the quality of the generated images by comparing them to a reference dataset. MUSIQ evaluates the sharpness of the images. The results show that the proposed method significantly outperforms the baselines across all three metrics.
In-depth insights#
2D Prior Lifting#
The concept of “2D Prior Lifting” in the context of 3D object removal is a crucial innovation. It leverages the power and diversity of 2D diffusion models, which are already excellent at image inpainting, to tackle the more challenging task of 3D scene completion. The core idea is to utilize the strong 2D inpainting capabilities as a foundation for generating plausible 3D completions. This approach bypasses the difficulties of training 3D diffusion models directly, which require extensive and often unavailable 3D data. By using 2D priors, training becomes simpler, as it relies on abundant and readily available 2D image datasets. The key challenge, then, becomes aligning the 2D inpainted results across multiple views to create consistent and coherent 3D representations. This requires techniques to establish cross-view consistency, thereby enhancing the fidelity and realism of the final 3D output. However, naive application may lead to inconsistent 3D results. Thus, careful alignment techniques that focus on both initial latents and intermediate latents during the denoising process are essential for success. Successful methods of “2D prior lifting” represent a significant step toward enhancing the realism and effectiveness of 3D scene editing.
Latent Alignment#
The concept of ‘Latent Alignment’ in the context of the provided research paper is crucial for bridging the gap between 2D diffusion models and 3D scene reconstruction. The core idea revolves around aligning the latent representations of the inpainted areas across multiple views, thereby ensuring consistency and coherence in the final 3D model. This alignment happens on two levels: explicitly aligning initial latent samples using a pre-trained Neural Radiance Field (NeRF) to establish a consistent foundational structure and implicitly aligning intermediate latent representations predicted during the denoising process by employing cross-view attention. This two-pronged approach directly addresses the challenge of high variance in diffusion models’ outputs, which often leads to misalignment and inconsistency across multiple views when applied to 3D scenarios. By aligning latent spaces, the method promotes a view-consistent inpainting process, leading to more realistic and coherent 3D scene reconstruction, particularly when dealing with object removal tasks.
Hybrid Loss#
The concept of a ‘Hybrid Loss’ in the context of 3D inpainting from a research paper suggests a combined loss function designed to address the inherent challenges of this task. The paper likely utilizes this approach to reconcile the conflicting demands of maintaining high-frequency details and achieving spatial consistency across multiple views. A typical hybrid loss function for this application might combine a perceptual loss (e.g., LPIPS) that focuses on the overall visual fidelity and a geometric loss (e.g., MSE on depth) to ensure the 3D structure and appearance are consistent. Moreover, an adversarial loss is often included to enhance the realism and high-frequency details of the inpainted regions. By combining different types of losses, this hybrid approach aims to strike a balance between structural accuracy and visual quality, leading to more realistic and coherent 3D inpainting results. The effectiveness of such a hybrid loss would be experimentally evaluated by comparing inpainting results with those obtained using only individual loss components, demonstrating the superior performance and efficiency of the proposed approach.
3D Inconsistency#
3D inconsistency in the context of image-based 3D reconstruction, particularly when using 2D diffusion models, is a significant challenge. Inconsistent multi-view inpainting results from applying 2D diffusion models trained on single-view images directly to multi-view data. This inconsistency arises primarily due to the variability in initial latent samples and intermediate latents predicted during the denoising process. Each view is treated independently, leading to misalignments and visual artifacts. Addressing this requires strategies that align latent representations across different views, ensuring structural and appearance consistency in the reconstructed 3D scene. Methods proposed to tackle this issue often involve sophisticated alignment techniques or multi-view optimization strategies. However, balancing consistency with high-fidelity details remains a key challenge, as overly aggressive consistency enforcement can lead to a loss of detail, and insufficient alignment can leave noticeable artifacts. The optimal approach needs to delicately manage the trade-off between achieving multi-view coherence and preserving the richness and diversity of the original 2D inpainting results.
Future Directions#
Future research could explore several promising avenues. Improving the fidelity and realism of inpainted 3D scenes remains a key challenge, potentially addressed by exploring advanced 3D generative models or incorporating more sophisticated multi-view consistency techniques. Developing methods for handling more complex occlusion scenarios and incorporating user input for more interactive and flexible editing is also crucial. Furthermore, research into the robustness and generalization capabilities of the proposed approach across diverse datasets and object types is needed. Finally, investigating potential biases present in the training data and mitigating their impact on the generated output would be critical for responsible deployment of such methods. The impact of varying latent alignment approaches should be further explored and their potential to improve results further investigated.
More visual insights#
More on figures

This figure shows a schematic overview of the proposed In-N-Out method for 3D object removal. It consists of two main stages: (a) Pre-training a Neural Radiance Field (NeRF) using a single-view inpainting prior generated by a diffusion model; and (b) inpainting multiple views by aligning latent representations (explicitly for initial latents and implicitly for intermediate latents) and optimizing the NeRF with a patch-based hybrid loss. The figure highlights the key components: Stable Diffusion, the NeRF, Explicit Latent Alignment (ELA), Implicit Latent Alignment (ILA), and the patch-based loss. The process begins with a pre-trained NeRF, then proceeds to inpaint the multiple views using latent alignments and the patch-based hybrid loss to optimize the NeRF.
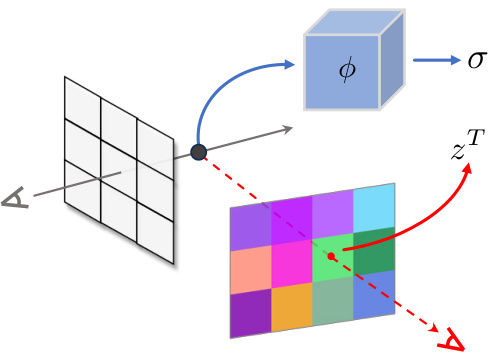
This figure illustrates the two key components of the proposed latent alignment approach: Explicit Initial Latent Alignment (ELA) and Implicit Intermediate Latents Alignment (ILA). ELA aligns the initial latent across views using geometric information derived from a pre-trained NeRF, ensuring structural consistency. ILA leverages cross-view attention in the diffusion model’s denoising process to align intermediate latents implicitly, improving appearance consistency. The diagram shows how both methods ensure consistent latent features across different views when inpainting.

This figure illustrates the two key components of the proposed latent alignment approach. (a) shows the explicit initial latent alignment (ELA), which leverages the pre-trained NeRF to align the initial latent across different views. (b) shows the implicit intermediate latent alignment (ILA), which utilizes cross-view attention to align the intermediate latents during the denoising process. The goal is to achieve consistent inpainting across multiple views by aligning both initial and intermediate latents.

This figure shows a qualitative comparison of object removal results on the SPIn-NeRF dataset using four different methods: SPIn-NeRF, NeRFiller, InFusion, and the proposed ‘In-N-Out’ method. Each row represents a different scene. The red boxes highlight the areas where the object was removed and inpainted. The figure demonstrates that SPIn-NeRF and NeRFiller, while achieving multi-view consistency, suffer from high-frequency detail loss, resulting in blurry inpainted areas. In contrast, the single-view-based InFusion method, while preserving detail, sometimes introduces geometric inconsistencies in the inpainted region. The proposed ‘In-N-Out’ method is shown to effectively mitigate the shortcomings of the other methods by maintaining both high-frequency detail and multi-view consistency.

This figure compares the qualitative results of four different methods for 3D object removal on the SPIn-NeRF dataset. The methods are SPIn-NeRF, NeRFiller, InFusion, and the proposed ‘Ours’ method. The figure shows that multi-view methods (SPIn-NeRF and NeRFiller) tend to lose high-frequency details while the single-view method (InFusion) can produce geometry artifacts. The ‘Ours’ method aims to mitigate both of these issues.

This figure shows an ablation study comparing the results of the proposed method with and without its key components: Explicit Latent Alignment (ELA) and Implicit Latent Alignment (ILA). The leftmost image shows the inpainting prior, a sample from a randomly selected view. The next three images demonstrate the effects of removing ELA, removing ILA, and the complete method respectively. It highlights the importance of both ELA and ILA for achieving high-quality and consistent inpainting results, and compares them with a naive inpainting approach using Stable Diffusion (as seen in Figure 1).

This figure shows the ablation study results on the rendering quality of the NeRF model by removing key components individually: ELA (Explicit Latent Alignment), ILA (Implicit Latent Alignment), the patch-based loss, the LPIPS loss, and the adversarial loss. The results show that each component plays an important role in generating high-quality, coherent inpainted 3D scenes. Removing ELA causes geometric mismatches, removing ILA leads to blurry colors, removing the patch loss results in overall poor quality, and removing the perceptual and adversarial losses impact the detail and sharpness, respectively.

This figure shows a qualitative comparison of object removal results using four different methods: SPIn-NeRF, NeRFiller, InFusion, and the proposed ‘In-N-Out’ method. The results are presented for several scenes, showcasing the impact of each approach on the preservation of high-frequency details and overall 3D scene consistency. The figure highlights the shortcomings of multi-view methods (SPIn-NeRF and NeRFiller) in preserving high-frequency details and the limitations of single-view methods (InFusion) that can sometimes lead to geometric inconsistencies. The ‘In-N-Out’ method aims to address these limitations.

This figure shows a qualitative comparison of object removal results on the SPIn-NeRF dataset using four different methods: SPIn-NeRF, NeRFiller, InFusion, and the proposed ‘In-N-Out’ method. Each row represents a different scene. The images show that multi-view methods (SPIn-NeRF and NeRFiller) tend to lose high-frequency details, while the single-view method (InFusion) can produce geometric artifacts. The proposed method aims to address these limitations by aligning latent representations across multiple views, resulting in a better balance between detail preservation and consistency.

This figure compares the inpainting results of a multi-view image using Stable Diffusion and the proposed method. The original image shows an occluded area (in red and green boxes). The middle column shows the inpainting results obtained from Stable Diffusion, which exhibits inconsistencies across views. In contrast, the right column shows the inpainting results of the proposed method, demonstrating improved multi-view consistency and fidelity.
More on tables
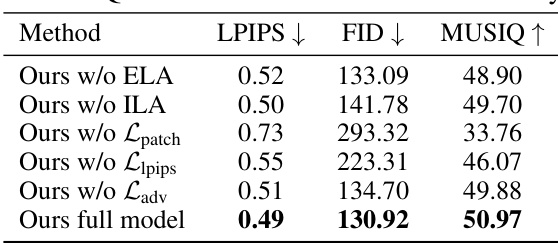
This table presents the quantitative results of the ablation study, showing the impact of removing key components (ELA, ILA, patch-based loss, perceptual loss, and adversarial loss) from the proposed method on LPIPS, FID, and MUSIQ metrics. The results demonstrate the individual contributions of each component to the overall performance.

This table presents the results of a sensitivity analysis performed to evaluate the impact of using different random seeds and different numbers of candidate views for selecting the base frame in the proposed method. The analysis focuses on the stability and robustness of the method in the presence of randomness and variations in input. The metrics reported are LPIPS, MUSIQ, and FID, which measure image quality and similarity to the ground truth. The table shows that the choice of random seed and number of candidate views has minimal impact on the overall performance, demonstrating the robustness of the method.

This table presents the results of a sensitivity analysis performed to determine the impact of the hyperparameter λα used in the Implicit Latent Alignment (ILA) component of the proposed method. The analysis varied λα across four values (0.2, 0.4, 0.6, and 0.8), and evaluated the resulting performance using three metrics: LPIPS (lower is better), MUSIQ (higher is better), and FID (lower is better). The average and standard deviation of the metrics across the four λα values are also provided. The results indicate that the model’s performance is relatively insensitive to variations in λα within the tested range.

This table shows the results of an ablation study evaluating the impact of varying the percentage of images used for subset selection in the 3D object removal task. The metrics LPIPS, MUSIQ, and FID are used to quantify the performance across different percentages (0.2, 0.4, 0.6, 0.8). The best performing subset size is highlighted in bold.
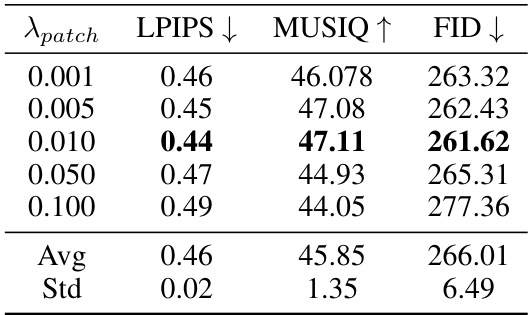
This table shows the results of ablation study on the impact of the hyperparameter λ_patch, which is a multiplier for the patch loss in the proposed method. The table shows the LPIPS, MUSIQ, and FID scores for different values of λ_patch (0.001, 0.005, 0.010, 0.050, 0.100). The best performance is highlighted in bold. The average and standard deviation of the metrics across different λ_patch values are also provided.
Full paper#



















