TL;DR#
Large language model (LLM) fine-tuning often suffers from catastrophic forgetting and suboptimal performance compared to full fine-tuning. Existing parameter-efficient fine-tuning (PEFT) methods struggle to maintain world knowledge while adapting to new tasks. These methods typically build adapters without considering task context, resulting in less-than-optimal results.
CorDA tackles this by using context-oriented weight decomposition. It leverages singular value decomposition (SVD) on pre-trained LLM weights, guided by the covariance matrix of input activations from a few representative samples from the target task. This allows CorDA to capture task context, leading to more effective adapters. CorDA offers two modes: knowledge preservation and instruction-previewed adaptation, which focus on preserving world knowledge or improving task performance, respectively. Experiments demonstrate CorDA’s superior performance and ability to mitigate catastrophic forgetting compared to state-of-the-art PEFT methods.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces a novel parameter-efficient fine-tuning method, CorDA, that addresses the limitations of existing methods by incorporating task context. This is highly relevant to current research trends in large language model optimization and opens up new avenues for improving the efficiency and performance of fine-tuning, particularly in mitigating catastrophic forgetting. CorDA’s flexibility in balancing fine-tuning performance and knowledge preservation makes it valuable to a wide range of researchers.
Visual Insights#
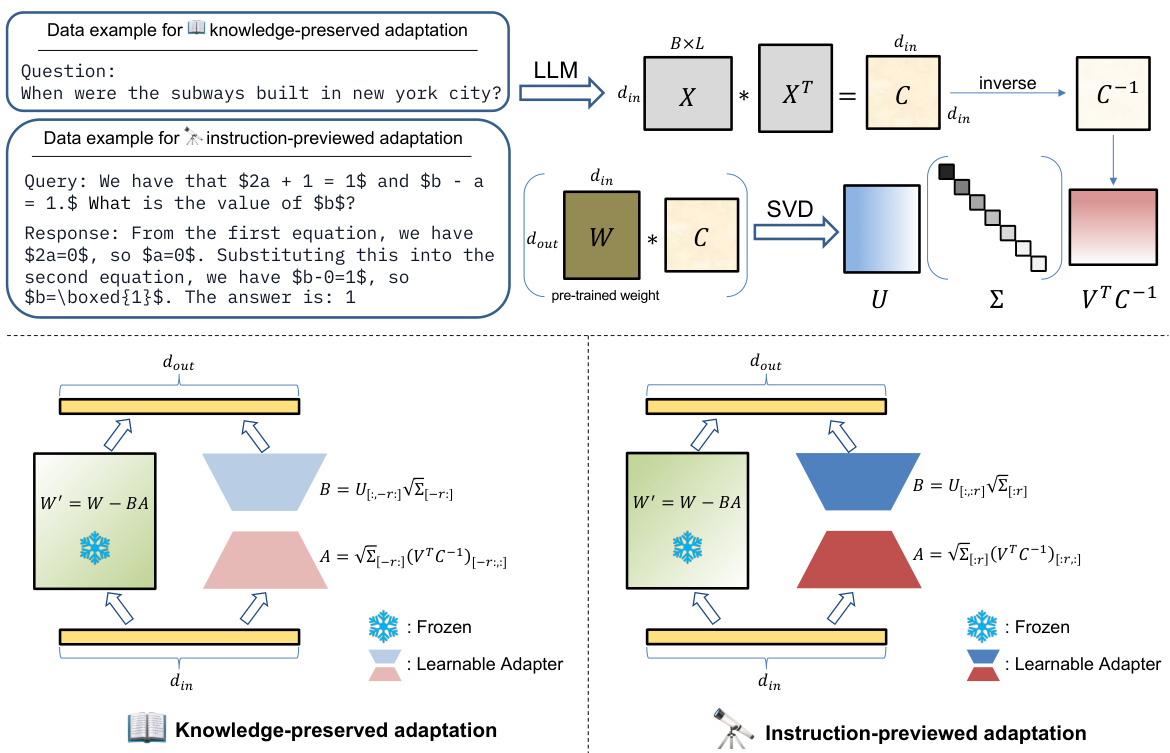
🔼 This figure illustrates the CorDA method. The top part shows the singular value decomposition (SVD) process using the covariance matrix to capture task context. The bottom left shows the knowledge-preserved adaptation, where the components with the smallest singular values are used to initialize a learnable adapter, while others are frozen to preserve world knowledge. The bottom right shows the instruction-previewed adaptation, where the components with the largest singular values are used to initialize a learnable adapter, focusing on enhancing fine-tuning performance. The color-coding of adapters highlights the distinction between frozen and learnable components.
read the caption
Figure 1: An overall illustration of our proposed method. We perform singular value decomposition oriented by the covariance matrix to aggregate task context into the principle components (up), which are frozen for maintaining world knowledge (down left) or utilized to initialize the learnable adapter for better fine-tuning performance (down right). The dark-colored adapter refers to the components with the largest r singular values, while the light one is composed of the smallest r components.

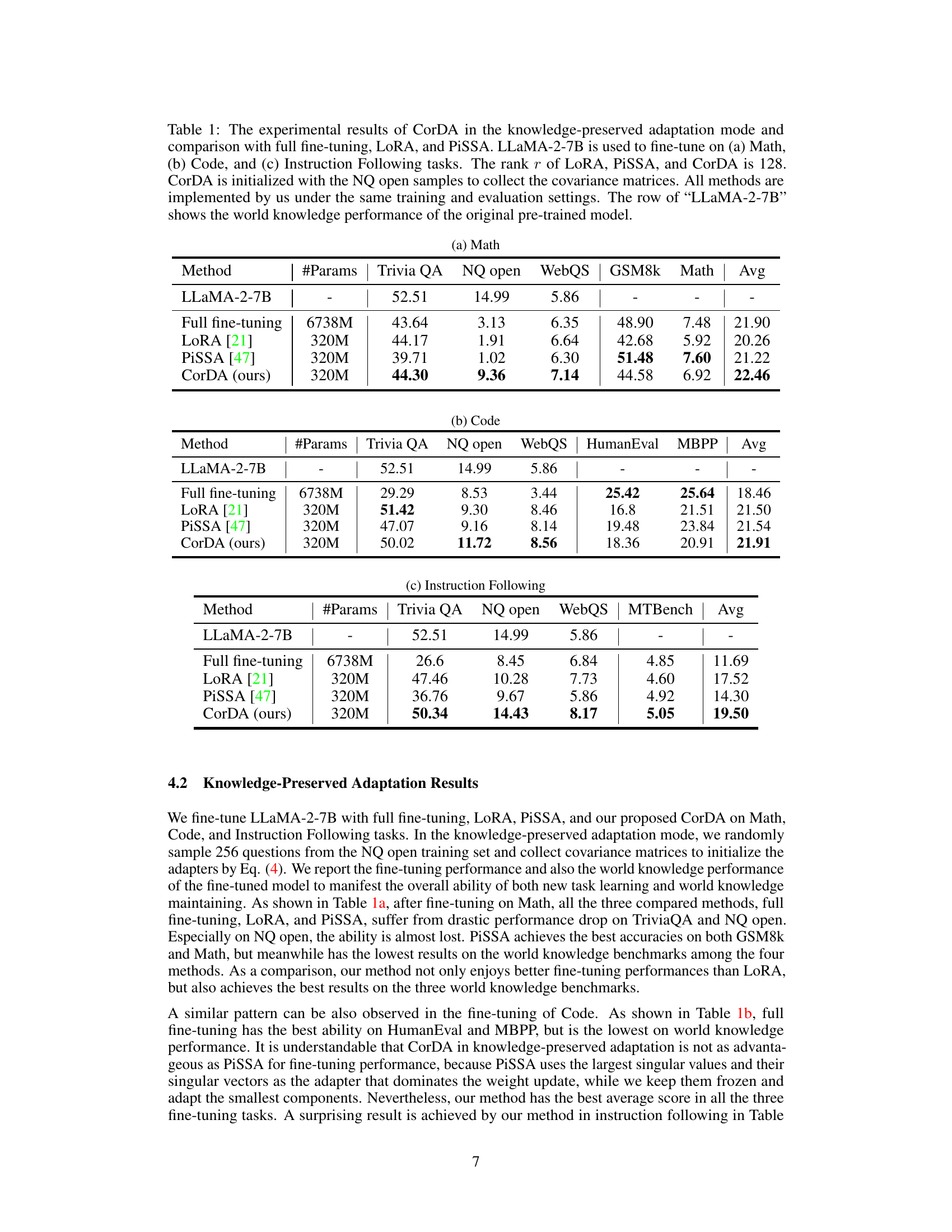
🔼 This table presents the experimental results of CorDA (Context-oriented Decomposition Adaptation), a parameter-efficient fine-tuning method, compared against full fine-tuning, LoRA, and PiSSA. The experiments are performed on three tasks: Math, Code, and Instruction Following, using the LLaMA-2-7B language model. The table shows the performance on these tasks, measured by metrics like accuracy and exact match scores, and also assesses the preservation of world knowledge using metrics from TriviaQA, NQ open, and WebQS. The rank parameter (r) in LoRA, PiSSA, and CorDA is set to 128, and CorDA is initialized using samples from the NQ open dataset to generate covariance matrices. All experiments are conducted under the same training and evaluation parameters for a fair comparison.
read the caption
Table 1: The experimental results of CorDA in the knowledge-preserved adaptation mode and comparison with full fine-tuning, LoRA, and PiSSA. LLaMA-2-7B is used to fine-tune on (a) Math, (b) Code, and (c) Instruction Following tasks. The rank r of LoRA, PiSSA, and CorDA is 128. CorDA is initialized with the NQ open samples to collect the covariance matrices. All methods are implemented by us under the same training and evaluation settings. The row of “LLaMA-2-7B
In-depth insights#
PEFT: LoRA Enhancements#
PEFT methods, particularly LoRA, offer significant advantages in fine-tuning large language models (LLMs) by drastically reducing the number of trainable parameters. LoRA’s low-rank adaptation elegantly approximates weight updates, maintaining architectural integrity and minimizing inference overhead. However, enhancements are crucial to address limitations. Improved low-rank estimations could enhance accuracy by more precisely capturing the weight changes needed for specific tasks. Adapting the rank dynamically based on the complexity of the downstream task is another promising avenue. Furthermore, exploring alternative decomposition techniques beyond low-rank, or integrating them with LoRA, could yield superior performance. Contextual information, perhaps through data-driven initialization or task-specific adaptation of the adapter matrices, holds potential to further improve accuracy and mitigate catastrophic forgetting. Addressing these aspects is key to advancing PEFT and maximizing the efficiency and effectiveness of LoRA-based fine-tuning for LLMs.
CorDA: Task-Aware PEFT#
CorDA, presented as a task-aware parameter-efficient fine-tuning (PEFT) method, offers a novel approach to addressing limitations in existing PEFT methods. CorDA’s core innovation lies in its context-oriented weight decomposition. Unlike methods that build adapters agnostically, CorDA leverages the context of the downstream task or crucial knowledge to be preserved, influencing the decomposition orientation. This is achieved by using singular value decomposition on the weights, informed by a covariance matrix derived from a small set of representative samples. The decomposition allows for two key adaptations: knowledge-preserved adaptation, prioritizing the retention of pre-trained knowledge by freezing the least relevant components, and instruction-previewed adaptation, focusing on rapidly learning a new task by training only the most task-relevant components. By incorporating task context directly into the adapter creation, CorDA aims to bridge the performance gap between PEFT and full fine-tuning while mitigating catastrophic forgetting. The results suggest that CorDA effectively achieves both goals, surpassing state-of-the-art PEFT methods on various benchmarks.
Context-Oriented SVD#
The core idea behind “Context-Oriented SVD” is to leverage the covariance matrix of input activations to guide the singular value decomposition (SVD) of a large language model’s (LLM) weight matrices. This is a significant departure from traditional SVD-based methods, which often treat the weight matrices in isolation. By incorporating the covariance matrix, which reflects the statistical relationships among input data points, the SVD process is explicitly informed by the context of the downstream task. This allows for a more targeted decomposition, potentially capturing task-relevant information more effectively. The key insight is that different tasks or modalities likely activate different patterns within the LLM’s weights, and the covariance matrix provides a way to quantify and utilize this activation pattern information during the decomposition. As a result, the learned adapters, initialized using this context-oriented SVD, are likely to be more effective and less prone to catastrophic forgetting, thereby improving downstream task performance and preserving world knowledge in the LLM.
Knowledge Preservation#
The concept of knowledge preservation in the context of large language model (LLM) fine-tuning is crucial. Catastrophic forgetting, where the model loses previously learned knowledge when adapting to new tasks, is a significant challenge. Parameter-efficient fine-tuning (PEFT) methods aim to mitigate this by only updating a small subset of parameters, but this often leads to incomplete adaptation and some knowledge loss. Effective knowledge preservation strategies require careful consideration of how to selectively update parameters while freezing those crucial to maintaining prior knowledge. This could involve identifying and protecting the parts of the model that encode essential knowledge representations, such as the embedding layer or certain subnetworks, or perhaps applying techniques like knowledge distillation to explicitly preserve relevant information from the pre-trained model. The success of a knowledge preservation approach hinges on its ability to balance between retaining old knowledge and learning new information. Further research should focus on developing robust metrics for evaluating knowledge preservation and on exploring techniques that go beyond simply freezing parameters, actively preserving and transferring knowledge during the fine-tuning process.
Future Work: Adapter Init#
Future research on adapter initialization methods for parameter-efficient fine-tuning (PEFT) of large language models (LLMs) is crucial. Exploring alternative initialization strategies beyond random or task-agnostic methods is key. Investigating context-aware initialization, perhaps by leveraging information from the downstream task or pre-training data, could significantly improve performance and knowledge retention. Developing methods that dynamically adjust adapter initialization based on task characteristics would enhance adaptability. Furthermore, research should focus on efficient algorithms for these more complex initialization schemes, as computational cost is a major concern in PEFT. Finally, rigorous empirical evaluation comparing different initialization techniques across diverse downstream tasks and LLM architectures is needed to establish clear best practices.
More visual insights#
More on figures
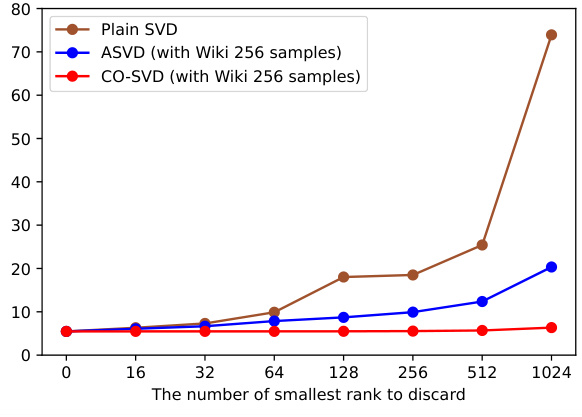
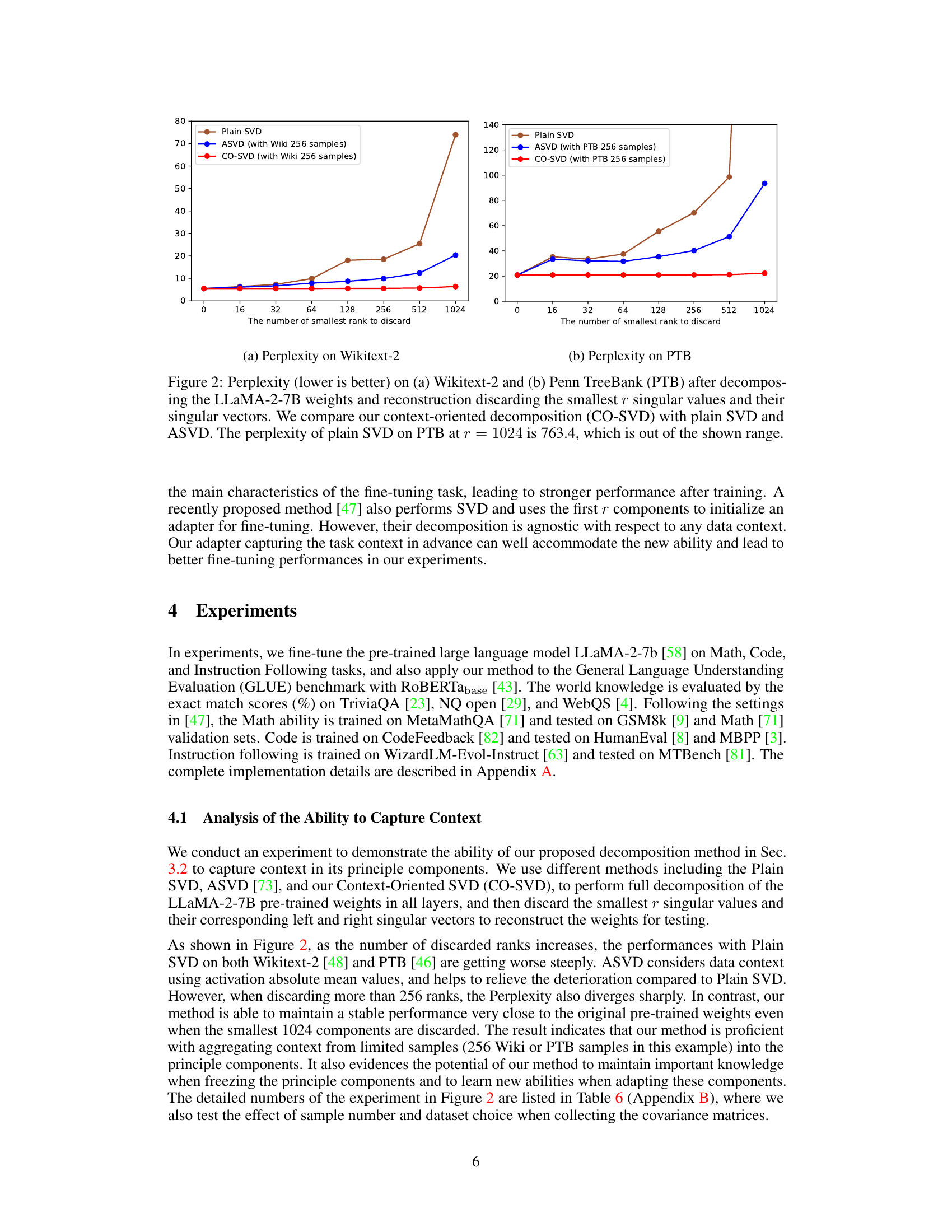
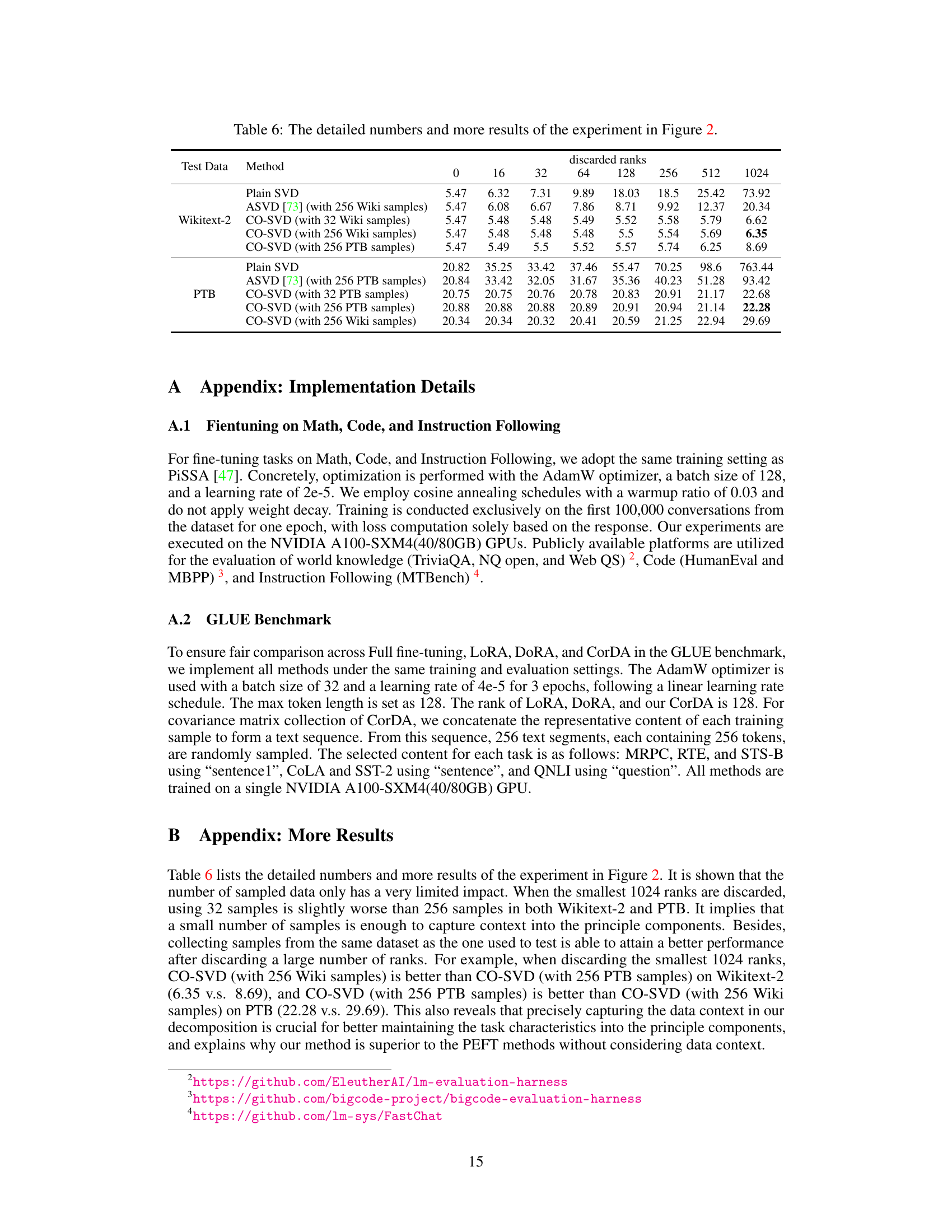
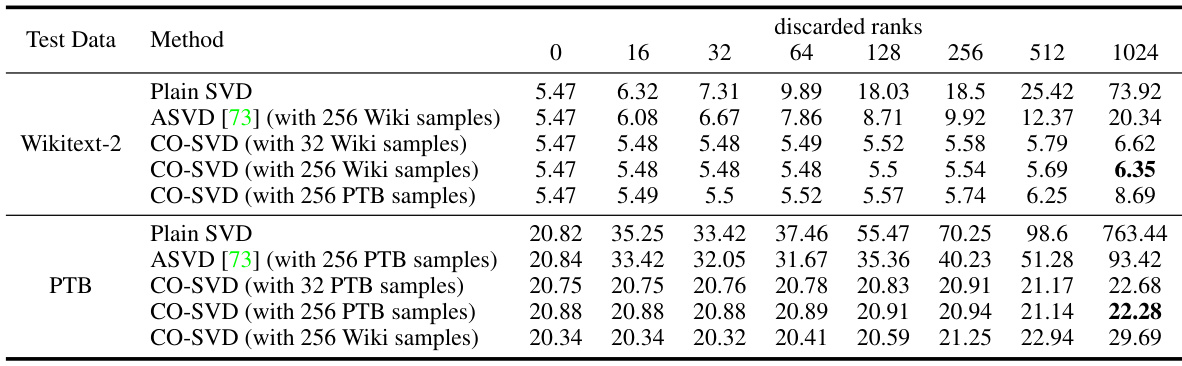
🔼 This figure shows the perplexity results on Wikitext-2 and Penn TreeBank (PTB) datasets after applying different decomposition methods. The x-axis represents the number of smallest singular values discarded during reconstruction of the LLaMA-2-7B model weights. The y-axis shows the perplexity. Three methods are compared: Plain SVD, ASVD, and the proposed CO-SVD. CO-SVD shows significantly better performance in maintaining low perplexity even after discarding a large number of singular values, demonstrating its ability to preserve important information during weight decomposition. Note the scale difference between the two subplots.
read the caption
Figure 2: Perplexity (lower is better) on (a) Wikitext-2 and (b) Penn TreeBank (PTB) after decomposing the LLaMA-2-7B weights and reconstruction discarding the smallest r singular values and their singular vectors. We compare our context-oriented decomposition (CO-SVD) with plain SVD and ASVD. The perplexity of plain SVD on PTB at r = 1024 is 763.4, which is out of the shown range.
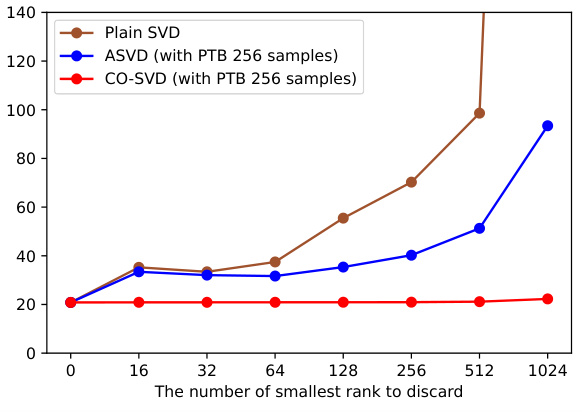
🔼 This figure compares three different methods (Plain SVD, ASVD, and CO-SVD) for decomposing the weights of a large language model (LLaMA-2-7B) and then reconstructing the model after discarding the smallest r singular values and their corresponding vectors. The perplexity, a measure of how well the model predicts the next word in a sequence, is evaluated on two datasets (Wikitext-2 and Penn TreeBank). The results show that CO-SVD is significantly more robust to the removal of singular values than the other methods, maintaining lower perplexity even when a large number of values are discarded.
read the caption
Figure 2: Perplexity (lower is better) on (a) Wikitext-2 and (b) Penn TreeBank (PTB) after decomposing the LLaMA-2-7B weights and reconstruction discarding the smallest r singular values and their singular vectors. We compare our context-oriented decomposition (CO-SVD) with plain SVD and ASVD. The perplexity of plain SVD on PTB at r = 1024 is 763.4, which is out of the shown range.
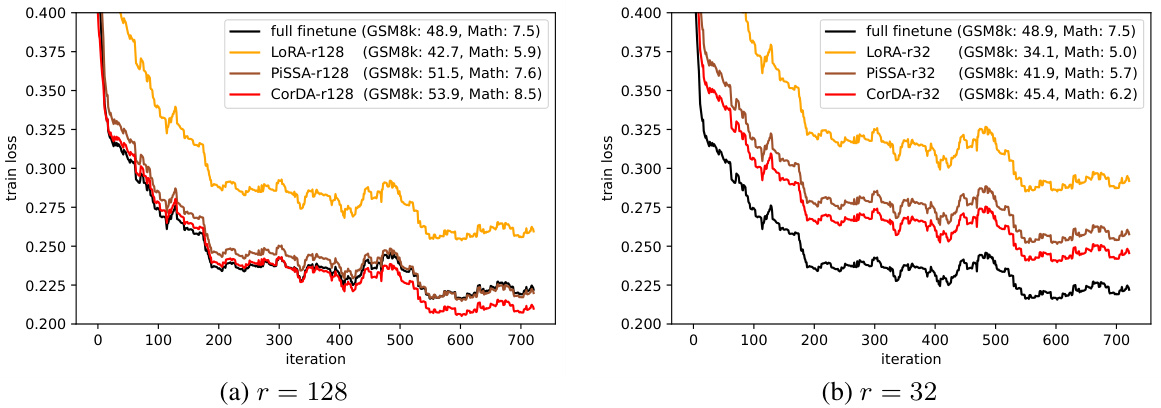
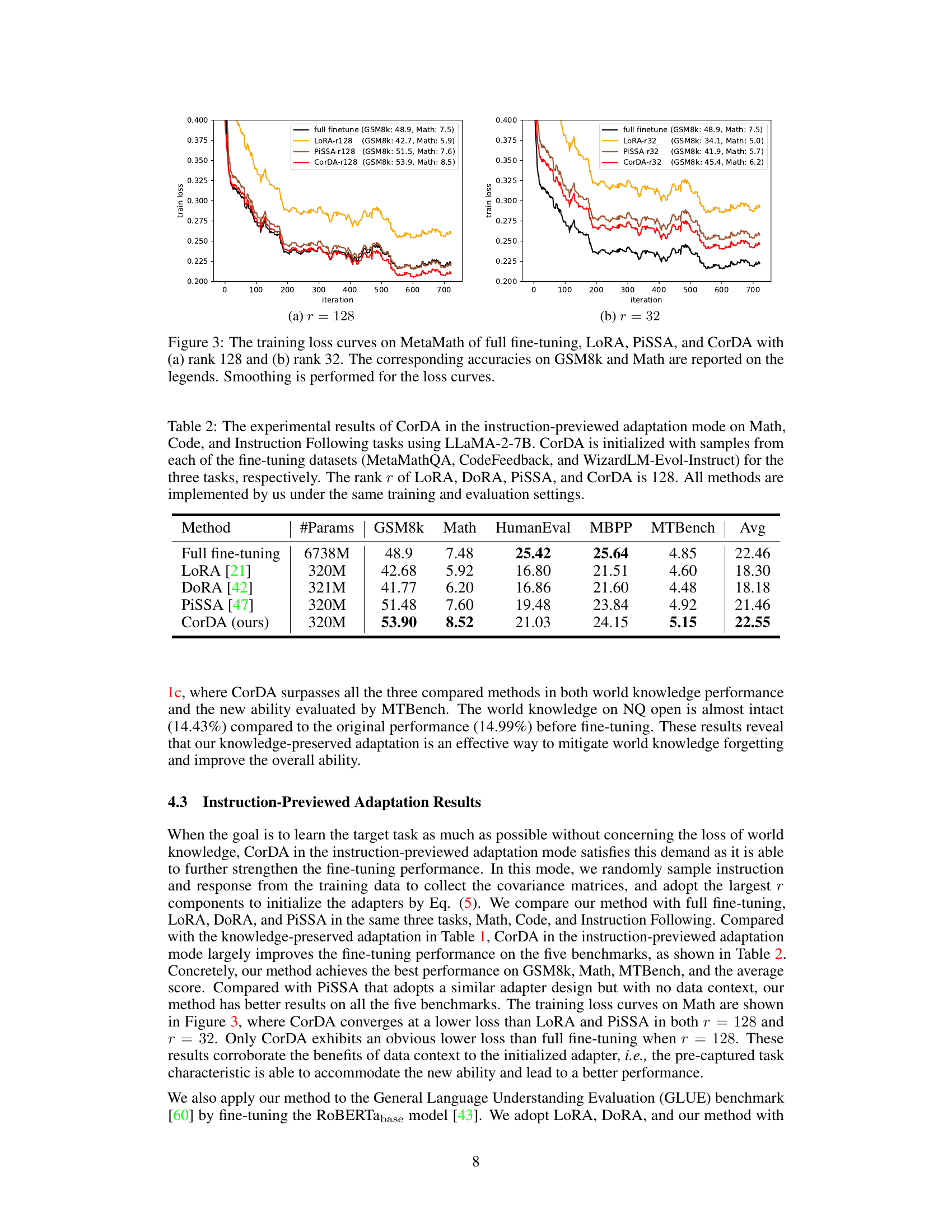
🔼 This figure shows the training loss curves for different parameter-efficient fine-tuning (PEFT) methods (LoRA, PiSSA, CorDA) and full fine-tuning on the MetaMath dataset. Two different rank values (r=128 and r=32) for the low-rank adapters are compared. The plot visualizes the convergence speed and final loss achieved by each method, with corresponding accuracies on GSM8k and Math datasets shown in the legend for better context.
read the caption
Figure 3: The training loss curves on MetaMath of full fine-tuning, LoRA, PISSA, and CorDA with (a) rank 128 and (b) rank 32. The corresponding accuracies on GSM8k and Math are reported on the legends. Smoothing is performed for the loss curves.
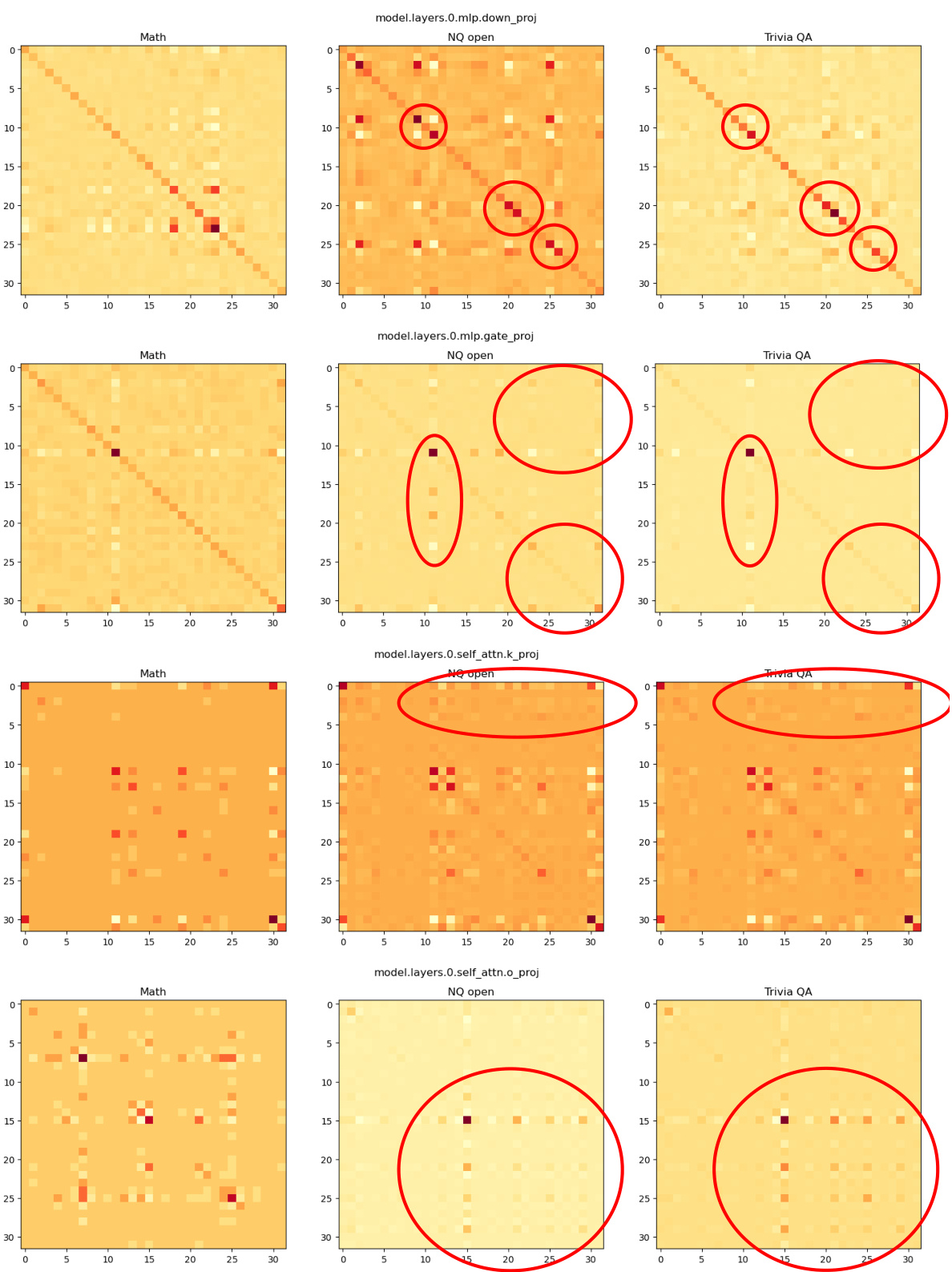
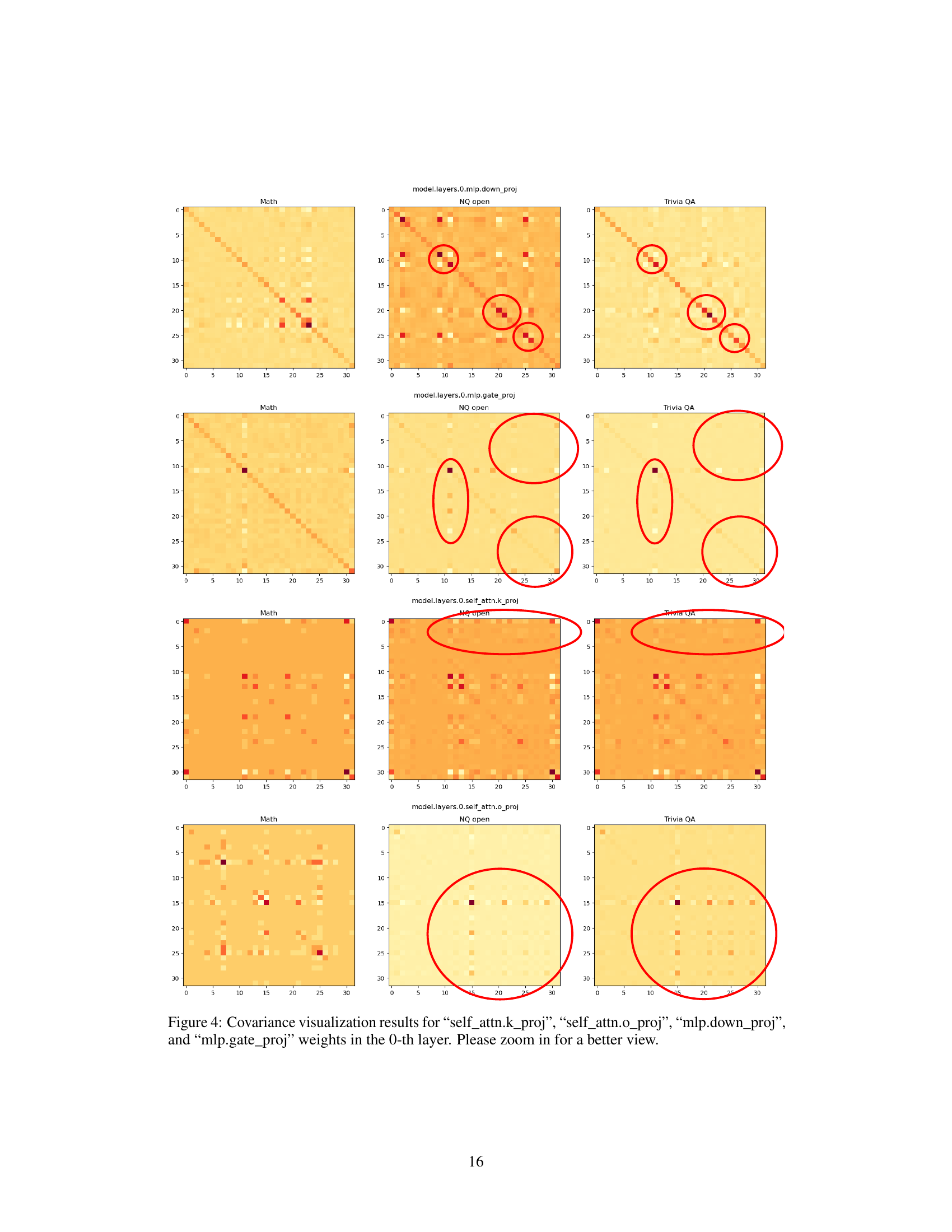
🔼 This figure visualizes the covariance matrices for four different weight matrices (self_attn.k_proj, self_attn.o_proj, mlp.down_proj, and mlp.gate_proj) within the 0th layer of the model. The visualizations are heatmaps showing the covariance between different input dimensions. The heatmaps are displayed for three different tasks: Math, NQ open, and TriviaQA. Red circles highlight outlier patterns that are similar for question answering tasks (NQ open and TriviaQA) but different for the Math task, indicating that the covariance matrices capture task-specific context.
read the caption
Figure 4: Covariance visualization results for “self_attn.k_proj”, “self_attn.o_proj”, “mlp.down_proj”, and “mlp.gate_proj” weights in the 0-th layer. Please zoom in for a better view.
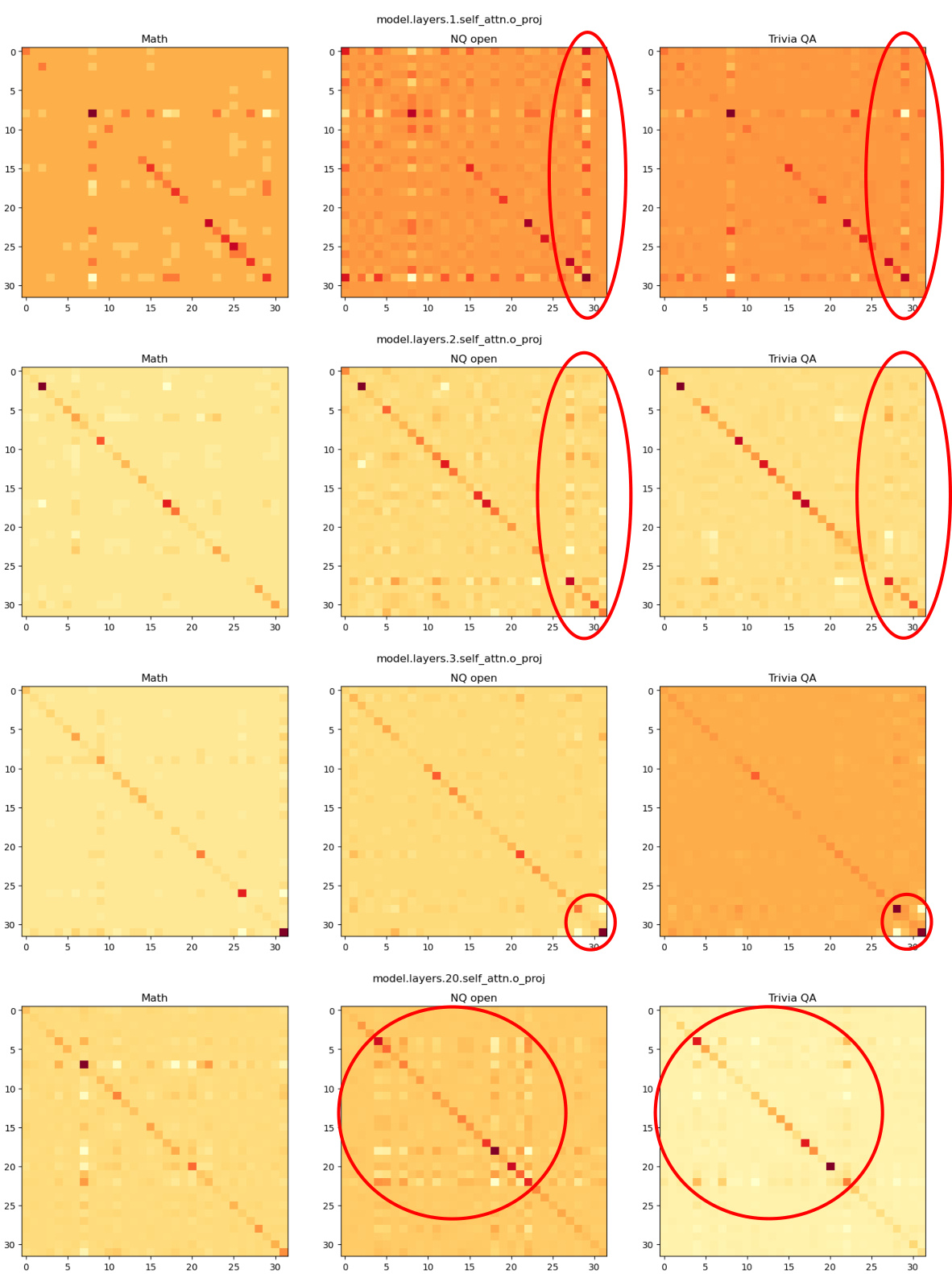
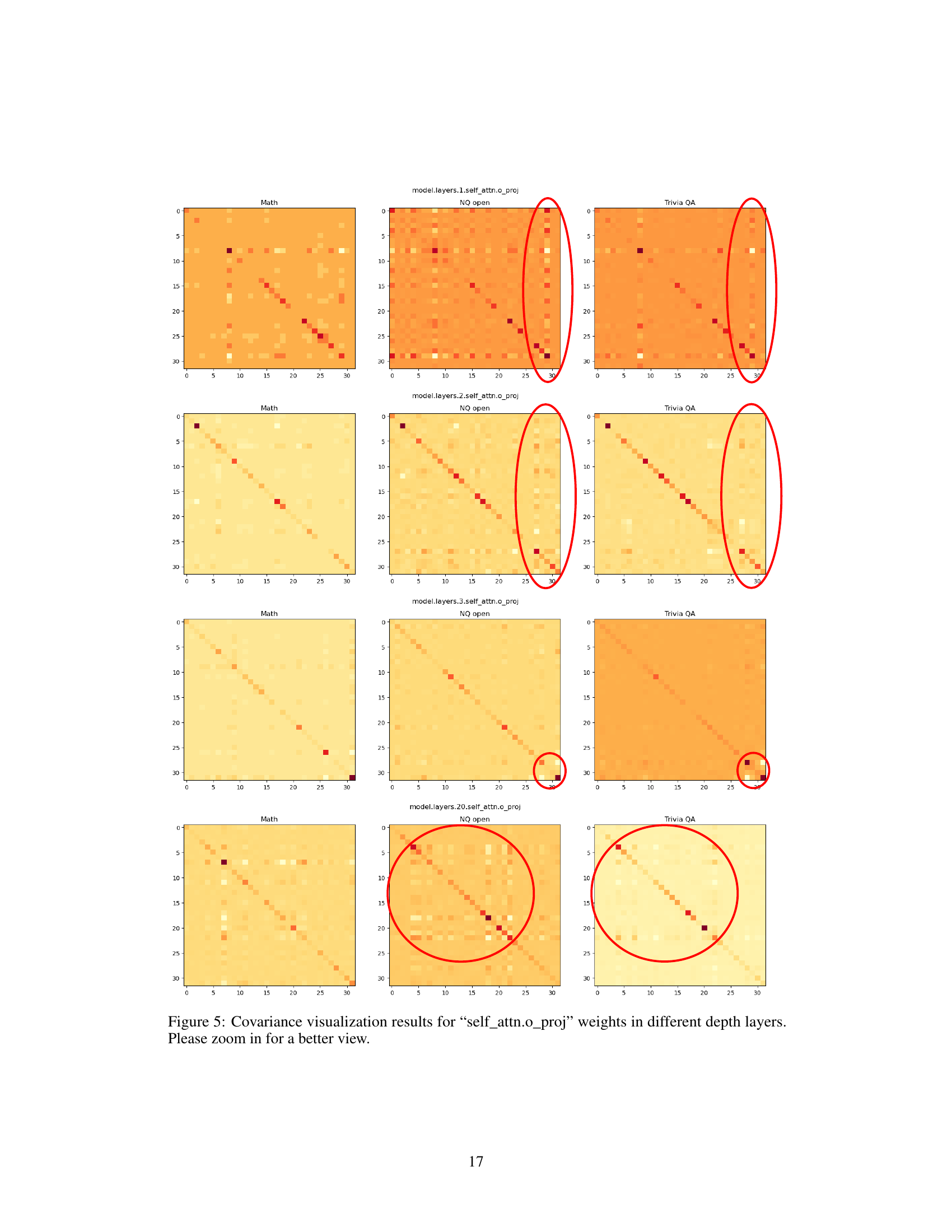
🔼 This figure visualizes the covariance matrices for different layers and weight types within a language model, using data from three tasks: Math, NQ open, and Trivia QA. The heatmaps show the covariance between different dimensions of the input activations. The red circles highlight similar patterns observed in NQ open and Trivia QA, both question-answering tasks, indicating that the covariance matrices capture task-specific context. This context is leveraged in CorDA to guide weight decomposition and adapter initialization.
read the caption
Figure 4: Covariance visualization results for “self_attn.k_proj”, “self_attn.o_proj”, “mlp.down_proj
More on tables
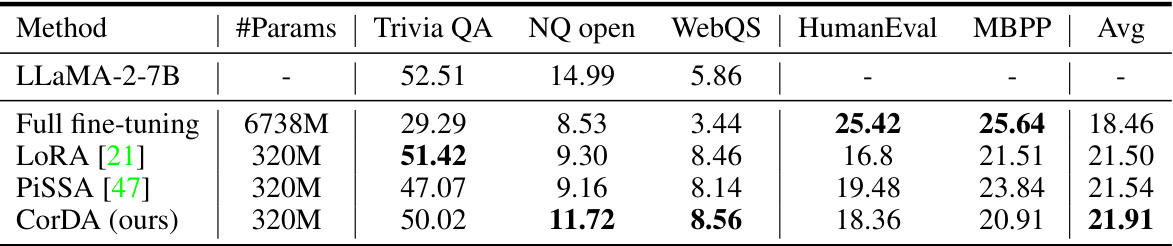
🔼 This table presents a comparison of the performance of different parameter-efficient fine-tuning (PEFT) methods on Math, Code, and Instruction Following tasks. The methods compared are full fine-tuning, LoRA, PiSSA, and the proposed CorDA method. The table shows the number of trainable parameters for each method, as well as the performance on several metrics, including those measuring world knowledge (Trivia QA, NQ open, WebQS), and task-specific performance (GSM8k, Math, HumanEval, MBPP, MTBench). The CorDA model uses the knowledge-preserved adaptation mode, where it is initialized using samples from the NQ open dataset. The results reveal that CorDA achieves better performance on world knowledge preservation while maintaining good performance on task-specific benchmarks. The rank of LoRA, PiSSA and CorDA is fixed at 128.
read the caption
Table 1: The experimental results of CorDA in the knowledge-preserved adaptation mode and comparison with full fine-tuning, LoRA, and PiSSA. LLaMA-2-7B is used to fine-tune on (a) Math, (b) Code, and (c) Instruction Following tasks. The rank r of LoRA, PiSSA, and CorDA is 128. CorDA is initialized with the NQ open samples to collect the covariance matrices. All methods are implemented by us under the same training and evaluation settings. The row of “LLaMA-2-7B
🔼 This table presents a comparison of the performance of CorDA (in knowledge-preserved mode) against full fine-tuning, LoRA, and PiSSA on three tasks: Math, Code, and Instruction Following. It shows the performance (average score across different metrics) and the number of parameters used for each method. The results highlight the trade-off between performance and the number of trainable parameters, which is a key aspect of parameter-efficient fine-tuning.
read the caption
Table 1: The experimental results of CorDA in the knowledge-preserved adaptation mode and comparison with full fine-tuning, LoRA, and PiSSA. LLaMA-2-7B is used to fine-tune on (a) Math, (b) Code, and (c) Instruction Following tasks. The rank r of LoRA, PiSSA, and CorDA is 128. CorDA is initialized with the NQ open samples to collect the covariance matrices. All methods are implemented by us under the same training and evaluation settings. The row of “LLaMA-2-7B
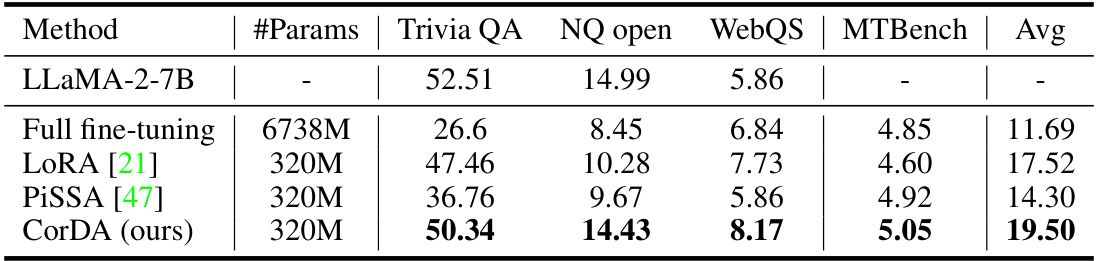
🔼 This table presents a comparison of the performance of various parameter-efficient fine-tuning methods (PEFT) on three tasks: Math, Code, and Instruction Following. The methods compared are full fine-tuning, LoRA, DORA, PiSSA, and the proposed CorDA. The table shows the number of parameters used by each method, along with the performance metrics for each task. CorDA uses a context-oriented decomposition adaptation method, and results show it outperforms other methods on instruction following tasks.
read the caption
Table 2: The experimental results of CorDA in the instruction-previewed adaptation mode on Math, Code, and Instruction Following tasks using LLaMA-2-7B. CorDA is initialized with samples from each of the fine-tuning datasets (MetaMathQA, CodeFeedback, and WizardLM-Evol-Instruct) for the three tasks, respectively. The rank r of LoRA, DORA, PiSSA, and CorDA is 128. All methods are implemented by us under the same training and evaluation settings.

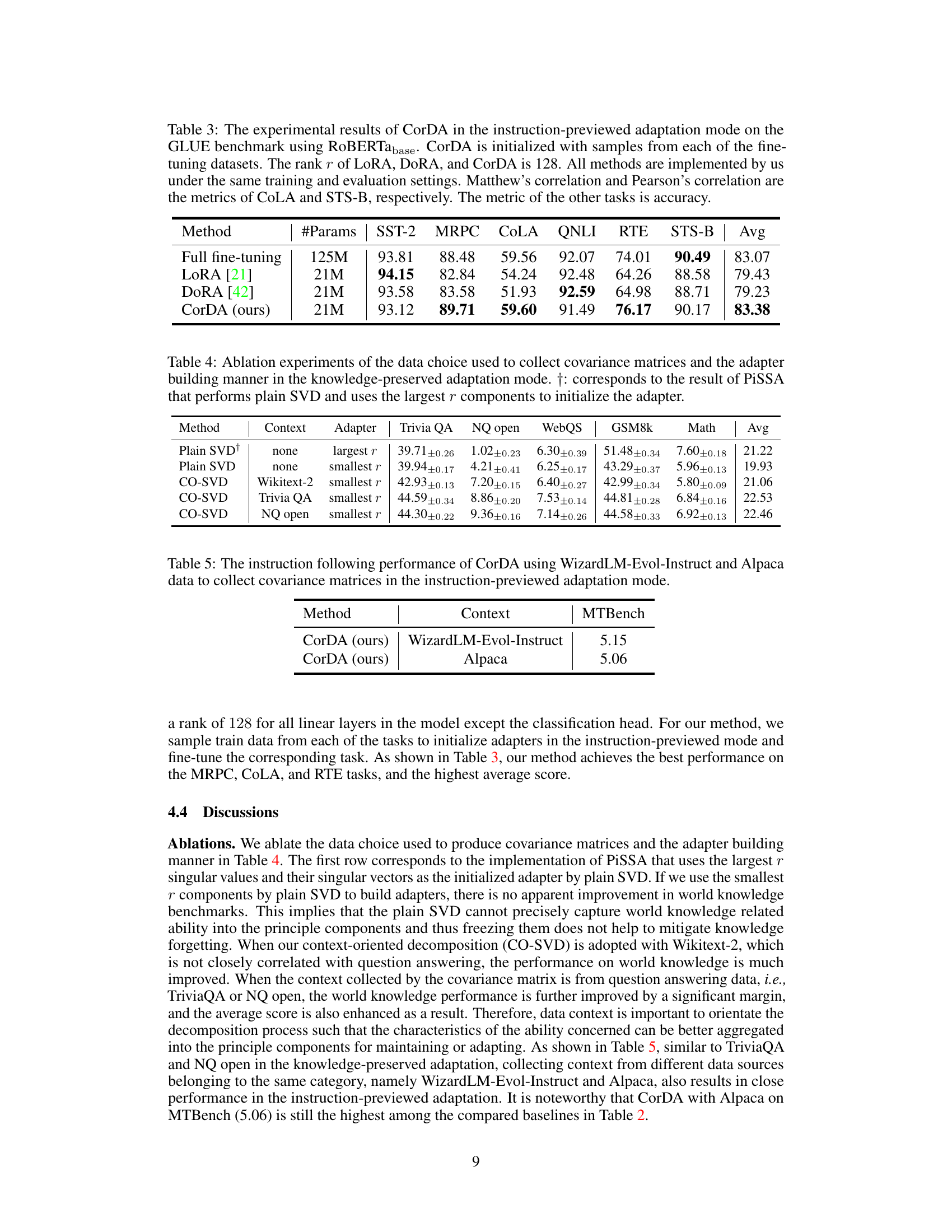
🔼 This table compares the performance of CorDA with full fine-tuning, LoRA, and DORA on the GLUE benchmark using RoBERTabase. The instruction-previewed adaptation mode of CorDA was used, initialized with samples from each fine-tuning dataset. The rank of all low-rank methods was 128. The results show accuracy for most tasks, and Matthew’s and Pearson’s correlations for CoLA and STS-B, respectively.
read the caption
Table 3: The experimental results of CorDA in the instruction-previewed adaptation mode on the GLUE benchmark using RoBERTabase. CorDA is initialized with samples from each of the fine-tuning datasets. The rank r of LoRA, DORA, and CorDA is 128. All methods are implemented by us under the same training and evaluation settings. Matthew’s correlation and Pearson’s correlation are the metrics of CoLA and STS-B, respectively. The metric of the other tasks is accuracy.

🔼 This table presents ablation study results on the knowledge-preserved adaptation mode of CorDA. It compares the performance of CorDA using different data sources (Wikitext-2, TriviaQA, NQ open) to construct covariance matrices and different adapter building methods (plain SVD using largest or smallest r components, CO-SVD using smallest r components). The results are evaluated based on TriviaQA, NQ open, WebQS, GSM8k, and Math datasets, providing insights into how different choices affect the model’s performance on knowledge preservation and new task learning.
read the caption
Table 4: Ablation experiments of the data choice used to collect covariance matrices and the adapter building manner in the knowledge-preserved adaptation mode. †: corresponds to the result of PiSSA that performs plain SVD and uses the largest r components to initialize the adapter.

🔼 This table presents the performance of the CorDA model on the MTBench benchmark for instruction following. Two versions of CorDA are shown, one initialized using data from the WizardLM-Evol-Instruct dataset and the other using data from the Alpaca dataset. The table highlights the impact of different training data on the model’s performance in this specific task.
read the caption
Table 5: The instruction following performance of CorDA using WizardLM-Evol-Instruct and Alpaca data to collect covariance matrices in the instruction-previewed adaptation mode.
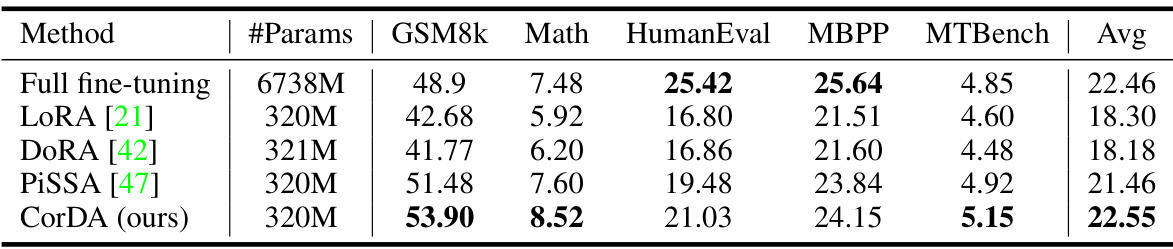
🔼 This table presents a comparison of the performance of CorDA (in knowledge-preserved mode), LoRA, PiSSA, and full fine-tuning on three tasks: Math, Code, and Instruction Following. It shows the performance on several metrics, including accuracy on the specific task and performance on world knowledge benchmarks (TriviaQA, NQ open, WebQS). The table highlights CorDA’s ability to achieve comparable or better performance while maintaining world knowledge.
read the caption
Table 1: The experimental results of CorDA in the knowledge-preserved adaptation mode and comparison with full fine-tuning, LoRA, and PiSSA. LLaMA-2-7B is used to fine-tune on (a) Math, (b) Code, and (c) Instruction Following tasks. The rank r of LoRA, PiSSA, and CorDA is 128. CorDA is initialized with the NQ open samples to collect the covariance matrices. All methods are implemented by us under the same training and evaluation settings. The row of “LLaMA-2-7B” shows the world knowledge performance of the original pre-trained model.
Full paper#