↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Personalized talking face generation (TFG) aims to create realistic talking videos of specific individuals. Existing methods often require extensive training data per person, limiting efficiency and scalability. Furthermore, generating expressive facial motions that truly reflect the person’s talking style remains a challenge. These limitations hinder the widespread application of TFG.
MimicTalk tackles these issues. It uses a pre-trained, person-agnostic model as a foundation and adapts it to specific individuals using a novel static-dynamic hybrid pipeline. This approach greatly accelerates training. Moreover, an in-context stylized audio-to-motion model is introduced to precisely mimic individual talking styles, resulting in expressive and high-quality video output. The results demonstrate significantly faster training and improved video quality compared to prior work.
Key Takeaways#
Why does it matter?#
This paper is important because it presents MimicTalk, a novel and efficient method for personalized talking face generation. It addresses the limitations of existing methods by leveraging a person-agnostic model and a new static-dynamic adaptation pipeline, significantly improving both speed and quality. This work is relevant to current research trends in personalized video synthesis and opens new avenues for research in efficient model adaptation and expressive motion generation.
Visual Insights#
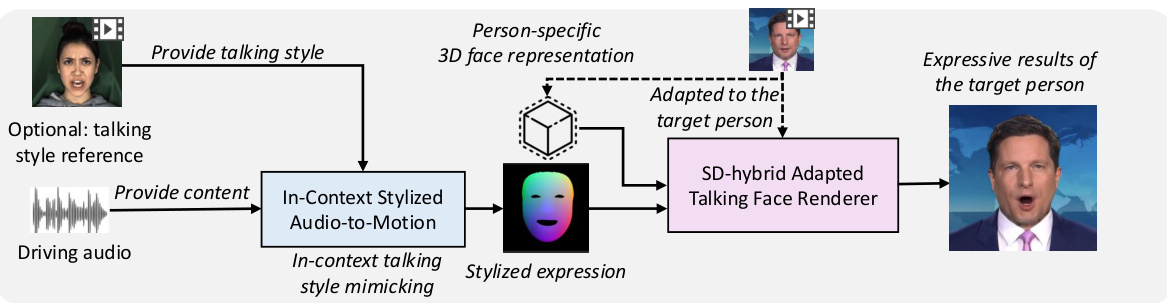
This figure illustrates the overall pipeline of MimicTalk. It begins with the user providing both driving audio and a reference video showcasing the desired talking style. This information is fed into an ‘In-Context Stylized Audio-to-Motion’ module which generates facial motion mimicking the reference video’s style. This motion data, along with a person-specific 3D face representation, is input to the ‘SD-hybrid Adapted Talking Face Renderer’, which generates the final, high-quality expressive talking face video of the target person.

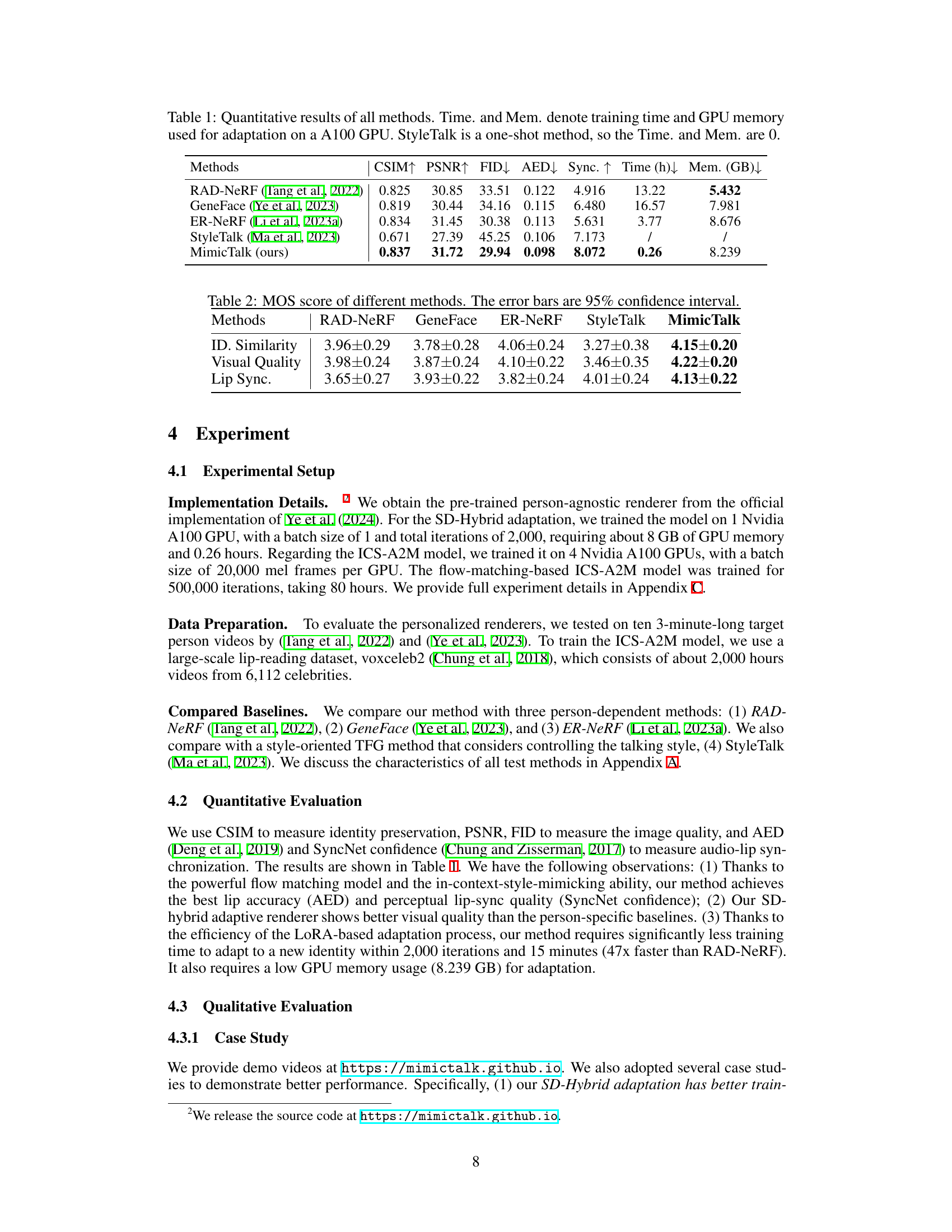
This table presents a quantitative comparison of different talking face generation methods. Metrics include CSIM (identity similarity), PSNR (peak signal-to-noise ratio), FID (Fréchet inception distance), AED (audio-expression distance), and Sync. (lip synchronization accuracy). It also shows the training time (in hours) and GPU memory (in GB) required for model adaptation. The results highlight that MimicTalk achieves high performance with significantly reduced computational demands.
In-depth insights#
Personalized TFG#
Personalized Talking Face Generation (TFG) aims to create realistic talking videos of a specific individual, prioritizing perceptual identity similarity. Existing methods often train individual models for each person, resulting in high quality but poor generalizability and efficiency due to limited training data and the per-person training framework. A key challenge is balancing the need for high-fidelity personalization with the desire for efficient and generalizable models. This necessitates exploring alternative approaches that leverage pre-trained models or incorporate techniques such as few-shot learning to reduce computational demands and enhance the ability to create personalized talking videos rapidly for novel individuals. The tradeoff between personalization accuracy and computational efficiency is central to future research in this area. Future work should focus on developing techniques that efficiently adapt pre-trained models to new individuals, thus achieving both personalized results and scalability. Another important aspect will be enhancing expressiveness and reducing any artifacts generated during synthesis.
SD-Hybrid Adapt.#
The proposed ‘SD-Hybrid Adapt.’ method cleverly tackles the challenge of personalized talking face generation by leveraging a pre-trained person-agnostic model. This approach cleverly combines static and dynamic adaptation to achieve efficient and effective personalization. The static adaptation, using tri-plane inversion, focuses on capturing detailed texture and geometry. The dynamic aspect uses low-rank adaptation (LoRA) to adjust the model for individual speaking styles, minimizing the risk of catastrophic forgetting. This hybrid approach is significant because it balances the strengths of both person-agnostic (generalizability) and person-specific methods (accuracy), enabling faster training and improved results compared to existing purely person-dependent approaches. This highlights the method’s key innovation: efficiently transferring knowledge from a generic model to individual identities. The efficiency gains are crucial for practical applications, where speed and resource constraints are significant factors.
ICS-A2M Model#
The proposed ICS-A2M (In-Context Stylized Audio-to-Motion) model is a crucial component of the MimicTalk framework, addressing the challenge of generating expressive and personalized facial motion. Its core innovation lies in its ability to mimic the implicit talking style from a reference video without explicit style representation, leveraging in-context learning. This is achieved through an audio-guided motion-filling task, which trains the model to predict missing motion segments by exploiting the surrounding context and audio. The adoption of a flow-matching model enables the generation of high-quality and temporally consistent motions, improving lip synchronization. Conditional flow matching (CFM) optimizes the accuracy of the predicted motion by minimizing the difference between the predicted velocity and the ground truth velocity. Further enhancing stylistic control, classifier-free guidance (CFG) allows for the adjustment of talking style intensity during the inference phase. By integrating these techniques, ICS-A2M effectively bridges the gap between generating generic and personalized talking styles, resulting in more expressive and realistic talking face videos.
Efficiency Gains#
Achieving efficiency gains in personalized talking face generation (TFG) is crucial for real-world applications. MimicTalk’s approach leverages a pre-trained person-agnostic model, significantly reducing the need for extensive per-person training. This hybrid adaptation strategy, combining static and dynamic adjustments, allows for quick personalization, achieving comparable results to person-dependent models in a fraction of the time (47x faster). The efficiency is further enhanced by the novel in-context stylized audio-to-motion (ICS-A2M) model, eliminating the need for explicit style representation and speeding up the motion generation process. The overall efficiency gains stem from a shift in paradigm, moving away from individual model training to a knowledge transfer approach, making MimicTalk a practical and scalable solution for personalized TFG.
Future Work#
The paper’s ‘Future Work’ section hints at several promising avenues. Improving the realism of non-facial elements like hair and torso is crucial; current methods are relatively simplistic and could benefit from techniques like conditional video diffusion models. Increasing the expressiveness of generated videos requires addressing limitations in current motion generation. Incorporating more nuanced elements such as eye movements and hand gestures would significantly enhance realism. Efficiency improvements are also important; the current model’s inference speed isn’t ideal for real-time applications. Exploring more efficient network structures, like Gaussian splatting, could drastically improve performance. Finally, mitigating ethical concerns associated with deepfakes is paramount. The authors acknowledge the potential for misuse and suggest safeguards like visible and invisible watermarks to help prevent malicious applications.
More visual insights#
More on figures

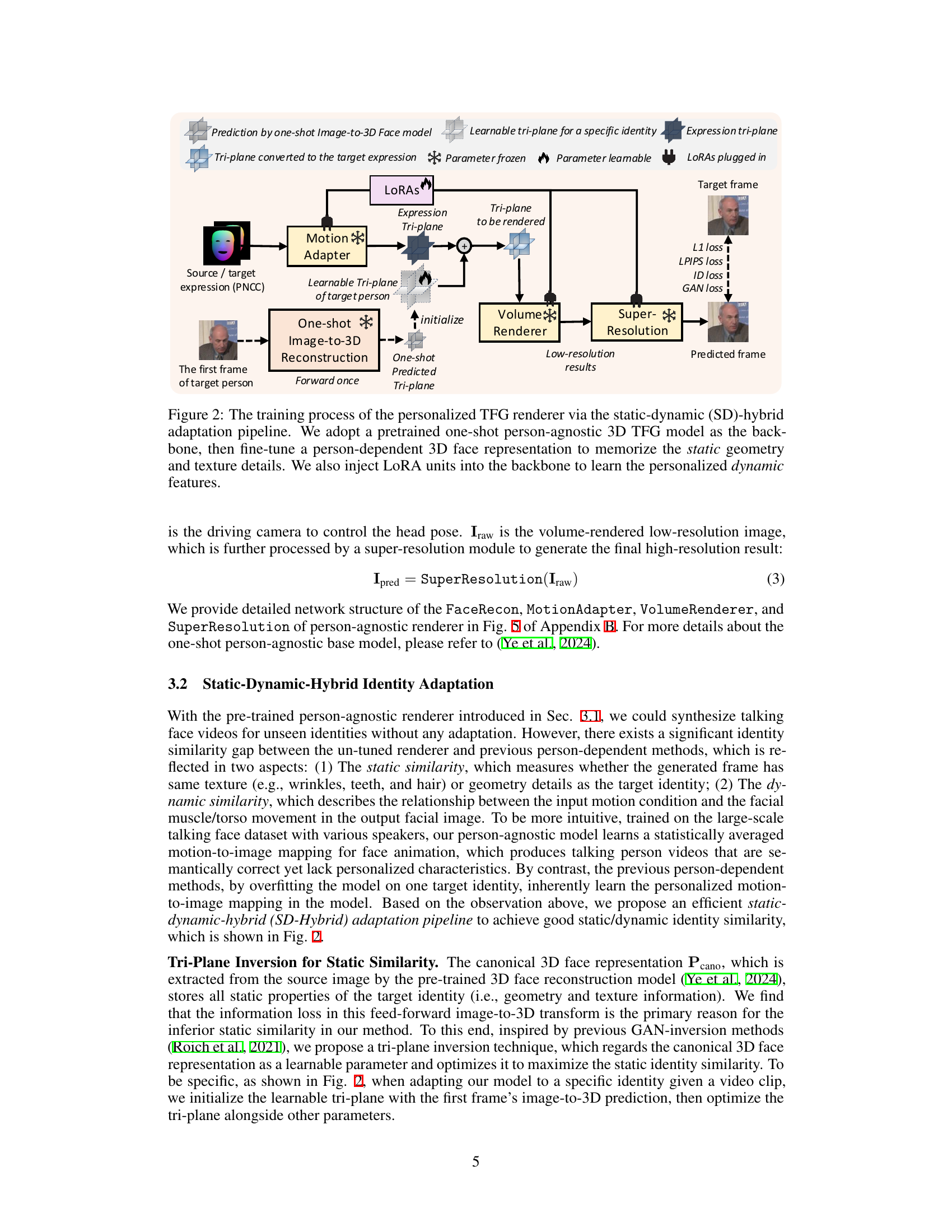
This figure illustrates the training process for the personalized talking face generation (TFG) renderer using a static-dynamic hybrid adaptation pipeline. It starts with a pre-trained one-shot person-agnostic 3D TFG model. The pipeline then fine-tunes a person-dependent 3D face representation to capture static features (geometry and texture). Low-rank adaptation (LoRA) units are injected into the model to learn the dynamic, personalized characteristics of a specific individual’s facial expressions.

This figure illustrates the inference process of the In-context Stylized Audio-to-Motion (ICS-A2M) model. The model takes as input driving audio, a talking style prompt (from a reference video), and a noisy motion representation. It uses a transformer network to predict the velocity of the noisy motion, which is then iteratively denoised via an ODE solver to generate the final stylized, context-aware motion. The talking style prompt implicitly guides the model to produce motion that matches the style of the reference video.
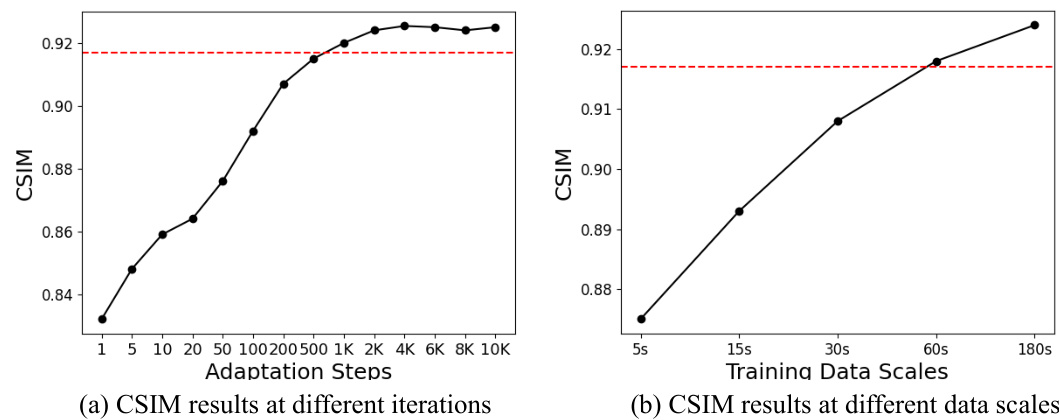
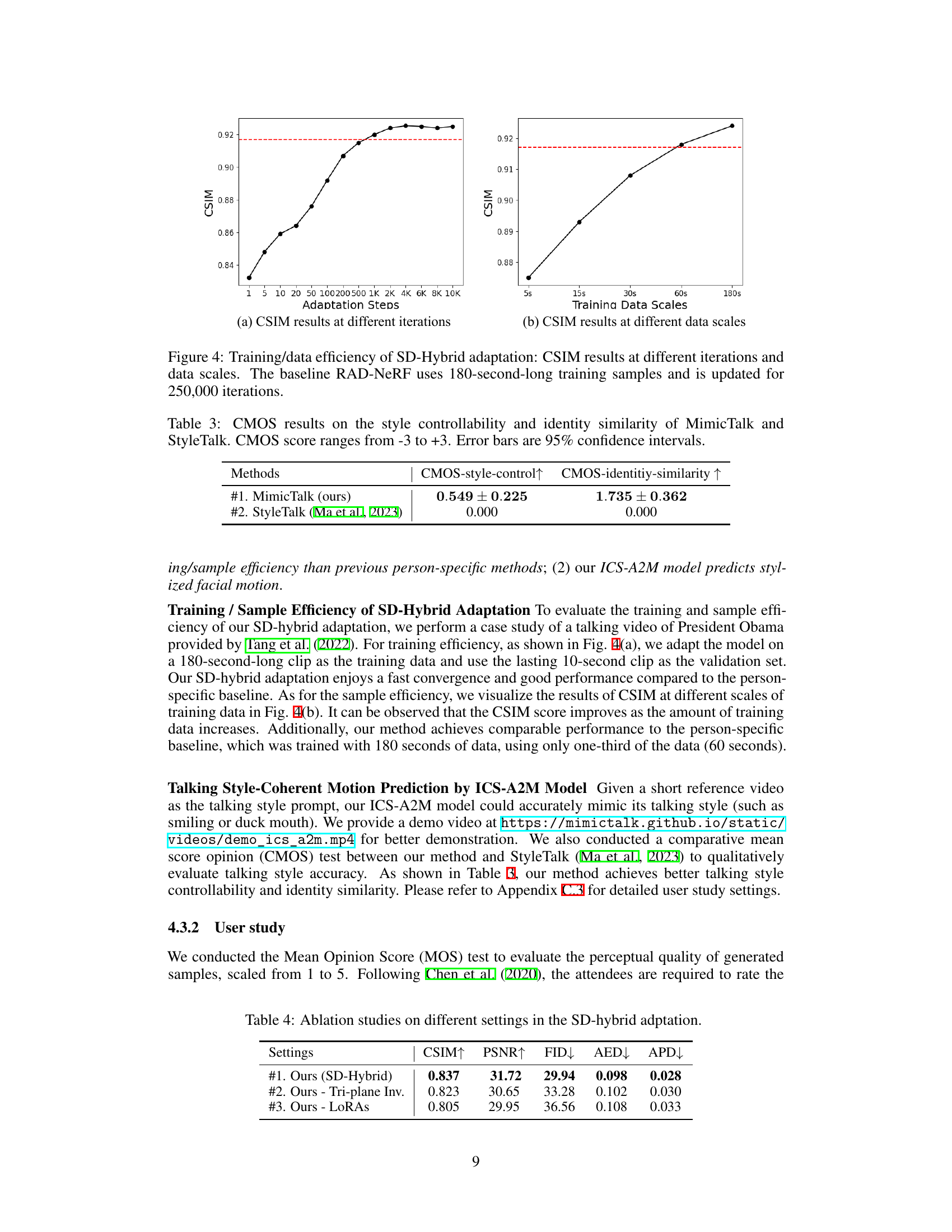
This figure demonstrates the training and data efficiency of the SD-Hybrid adaptation method used in MimicTalk. The left subplot shows how CSIM (a metric for identity similarity) improves as the number of adaptation steps (iterations during fine-tuning) increases, converging to a high similarity score. The right subplot shows the impact of varying the length of the training video on CSIM, illustrating that even short training videos yield good identity preservation. The results are compared to the baseline RAD-NeRF, which requires significantly more training data and time.
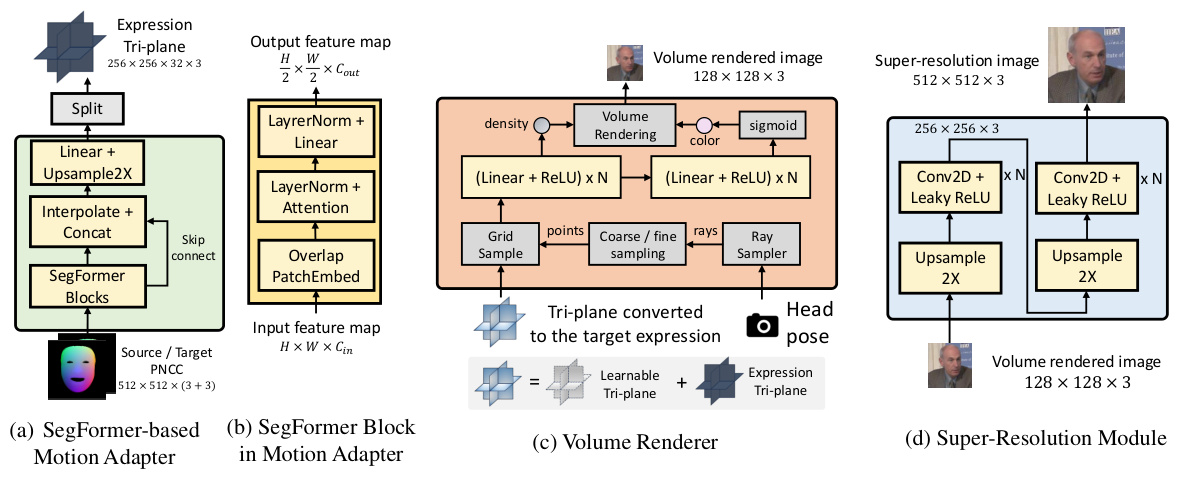
This figure shows the detailed architecture of the person-agnostic 3D talking face renderer used as the backbone in MimicTalk. It consists of four main modules: (a) a SegFormer-based motion adapter that takes source and target PNCCs (projected normalized coordinate codes) as input and generates an expression tri-plane; (b) SegFormer blocks that process the input feature map; (c) a volume renderer that combines the tri-plane with the motion adapter output to render a low-resolution volume-rendered image; and (d) a super-resolution module that upsamples the low-resolution image to a high-resolution one. The figure also illustrates the process of transforming the canonical 3D face into a target expression.
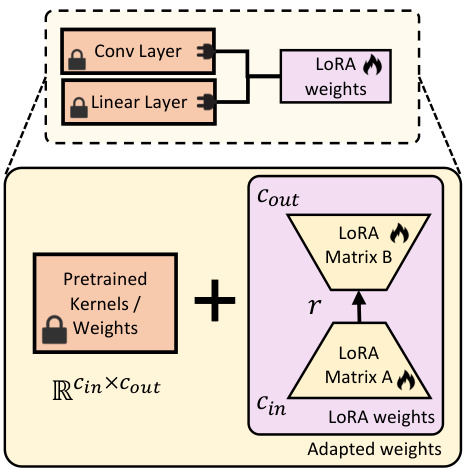
This figure illustrates how Low-Rank Adaptation (LoRA) is implemented within the person-agnostic renderer. LoRA injects low-rank matrices (A and B) into the pre-trained convolutional and linear layers. The pre-trained weights are kept frozen (indicated by locks), while only the smaller LoRA matrices are updated during training, making the adaptation process more efficient.
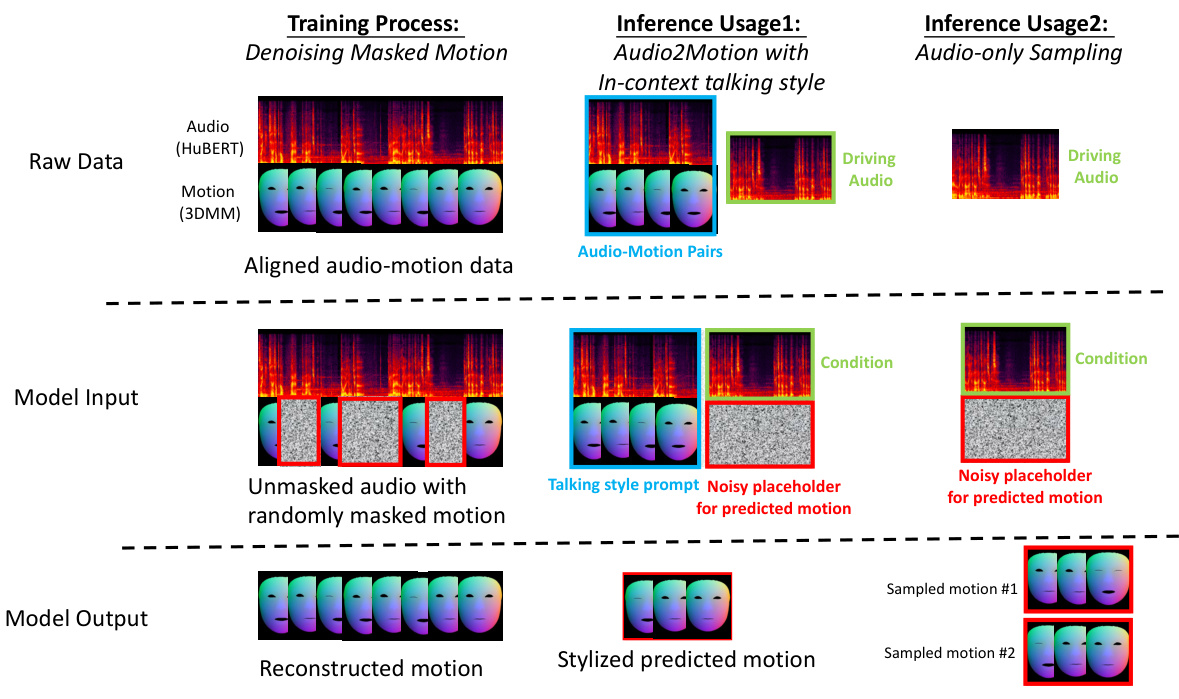
This figure illustrates the training and inference processes for the Audio-Guided Motion Infilling task. During training, the model learns to reconstruct randomly masked segments of motion tracks given the complete audio track and the surrounding unmasked motion. This allows the model to learn the talking style from context. During inference, there are two usage scenarios: 1) providing an audio-motion pair of the target speaker as a talking style prompt to mimic that style; and 2) audio-only sampling, where the model generates motions with a randomly sampled style.
More on tables

This table presents the Mean Opinion Score (MOS) results for different talking face generation methods across three aspects: identity similarity, visual quality, and lip synchronization. Higher scores indicate better performance. The error bars represent the 95% confidence intervals, showing the variability of the ratings.

This table presents the CMOS scores for style controllability and identity similarity, comparing MimicTalk with StyleTalk. Higher scores indicate better performance. The CMOS scale ranges from -3 to +3, with error bars representing 95% confidence intervals.

This table presents the ablation study results for the Static-Dynamic hybrid adaptation pipeline. It shows the impact of different components on the performance of the model in terms of CSIM (identity similarity), PSNR (peak signal-to-noise ratio), FID (Fréchet inception distance), AED (average expression distance), and APD (average pose distance). Comparing the full SD-Hybrid model to versions with the tri-plane inversion and LoRAs removed individually illustrates the contribution of each component.

This table presents the ablation study of the In-Context Stylized Audio-to-Motion (ICS-A2M) model. It shows the impact of different components of the model on the L2 landmark reconstruction error and audio-expression synchronization contrastive loss. The results demonstrate the effectiveness of the flow matching mechanism, the in-context learning of talking styles, and the audio-expression synchronization loss in improving the performance of the model.
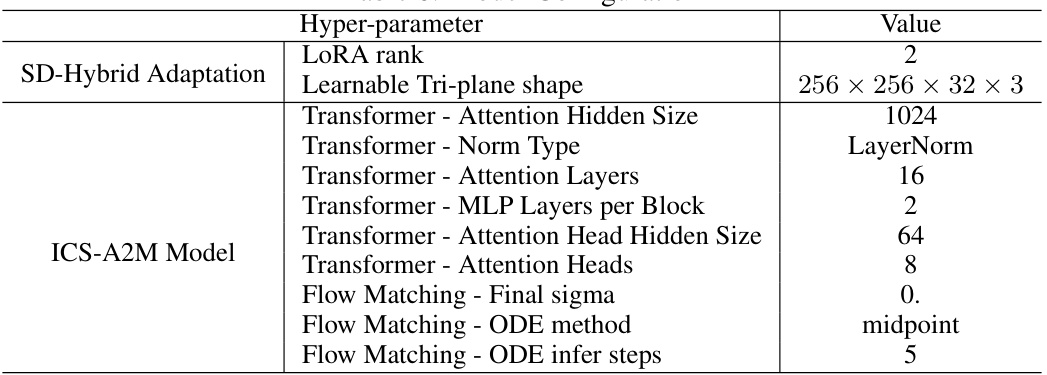
This table shows the hyperparameter settings used in the MimicTalk model. It is divided into two sections: SD-Hybrid Adaptation and ICS-A2M Model. The SD-Hybrid Adaptation section specifies parameters related to adapting the person-agnostic model to a specific identity, including the LoRA rank and the learnable tri-plane shape. The ICS-A2M Model section details parameters for the in-context stylized audio-to-motion model, encompassing transformer settings (hidden size, layers, norm type, etc.) and parameters for the flow-matching process (final sigma, ODE method, and inference steps).
Full paper#